Skapa uttryck i mappning av dataflöde
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Vid mappning av dataflöde anges många transformeringsegenskaper som uttryck. Dessa uttryck består av kolumnvärden, parametrar, funktioner, operatorer och literaler som utvärderas till en Spark-datatyp vid körning. Mappning av dataflöden har en dedikerad upplevelse som hjälper dig att skapa dessa uttryck som kallas Expression Builder. Med hjälp av IntelliSense-kodkomplettering för markering, syntaxkontroll och automatisk komplettering är uttrycksverktyget utformat för att göra det enkelt att skapa dataflöden. Den här artikeln beskriver hur du använder uttrycksverktyget för att effektivt skapa din affärslogik.

Open Expression Builder
Det finns flera startpunkter för att öppna uttrycksverktyget. Alla dessa är beroende av den specifika kontexten för dataflödestransformeringen. Det vanligaste användningsfallet är transformeringar som härledd kolumn och aggregering där användare skapar eller uppdaterar kolumner med hjälp av dataflödesuttrycksspråket. Du kan öppna uttrycksverktyget genom att välja Öppna uttrycksverktyget ovanför listan med kolumner. Du kan också välja en kolumnkontext och öppna uttrycksverktyget direkt till uttrycket.

I vissa transformeringar som filter öppnas uttrycksverktyget genom att klicka på en blå uttryckstextruta.
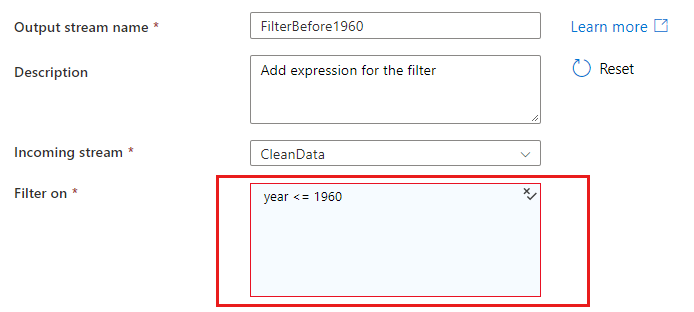
När du refererar till kolumner i ett matchande eller grupp-efter-villkor kan ett uttryck extrahera värden från kolumner. Om du vill skapa ett uttryck väljer du Beräknad kolumn.

Om ett uttryck eller ett literalvärde är giltiga indata väljer du Lägg till dynamiskt innehåll för att skapa ett uttryck som utvärderas till ett literalvärde.

Uttryckselement
Vid mappning av dataflöden kan uttryck bestå av kolumnvärden, parametrar, funktioner, lokala variabler, operatorer och literaler. Dessa uttryck måste utvärderas till en Spark-datatyp, till exempel sträng, boolesk eller heltal.

Funktioner
Mappning av dataflöden har inbyggda funktioner och operatorer som kan användas i uttryck. En lista över tillgängliga funktioner finns i referensen för mappning av dataflödesspråk.
Användardefinierade funktioner (förhandsversion)
Mappning av dataflöden stöder skapande och användning av användardefinierade funktioner. Information om hur du skapar och använder användardefinierade funktioner finns i användardefinierade funktioner.
Adressmatrisindex
När du hanterar kolumner eller funktioner som returnerar matristyper använder du hakparenteser ([]) för att få åtkomst till ett specifikt element. Om indexet inte finns utvärderas uttrycket till NULL.

Viktigt!
Vid mappning av dataflöden är matriser enbaserade, vilket innebär att det första elementet refereras till av index ett. Till exempel kommer myArray[1] att komma åt det första elementet i en matris med namnet "myArray".
Indataschema
Om dataflödet använder ett definierat schema i någon av dess källor kan du referera till en kolumn efter namn i många uttryck. Om du använder schemaavvikelse kan du referera till kolumner explicit med hjälp av byName() funktionerna eller byNames() matcha med hjälp av kolumnmönster.
Kolumnnamn med specialtecken
Om du har kolumnnamn som innehåller specialtecken eller blanksteg omger du namnet med klammerparenteser för att referera till dem i ett uttryck.
{[dbo].this_is my complex name$$$}
Parametrar
Parametrar är värden som skickas till ett dataflöde vid körning från en pipeline. Om du vill referera till en parameter väljer du antingen parametern från vyn Uttryckselement eller refererar till den med ett dollartecken framför namnet. En parameter som kallas parameter1 refereras till till exempel av $parameter1. Mer information finns i parametrisera mappning av dataflöden.
Cachelagrad sökning
Med en cachelagrad sökning kan du göra en infogad sökning av utdata från en cachelagrad mottagare. Det finns två funktioner att använda på varje mottagare och lookup() outputs(). Syntaxen för att referera till dessa funktioner är cacheSinkName#functionName(). Mer information finns i cachemottagare.
lookup() tar in matchande kolumner i den aktuella omvandlingen som parametrar och returnerar en komplex kolumn som är lika med raden som matchar nyckelkolumnerna i cachemottagaren. Den komplexa kolumn som returneras innehåller en underkolumn för varje kolumn som mappas i cachemottagaren. Om du till exempel hade en cachemottagare errorCodeCache för felkod som hade en nyckelkolumn som matchade koden och en kolumn med namnet Message. Anropet errorCodeCache#lookup(errorCode).Message returnerar meddelandet som motsvarar koden som skickas.
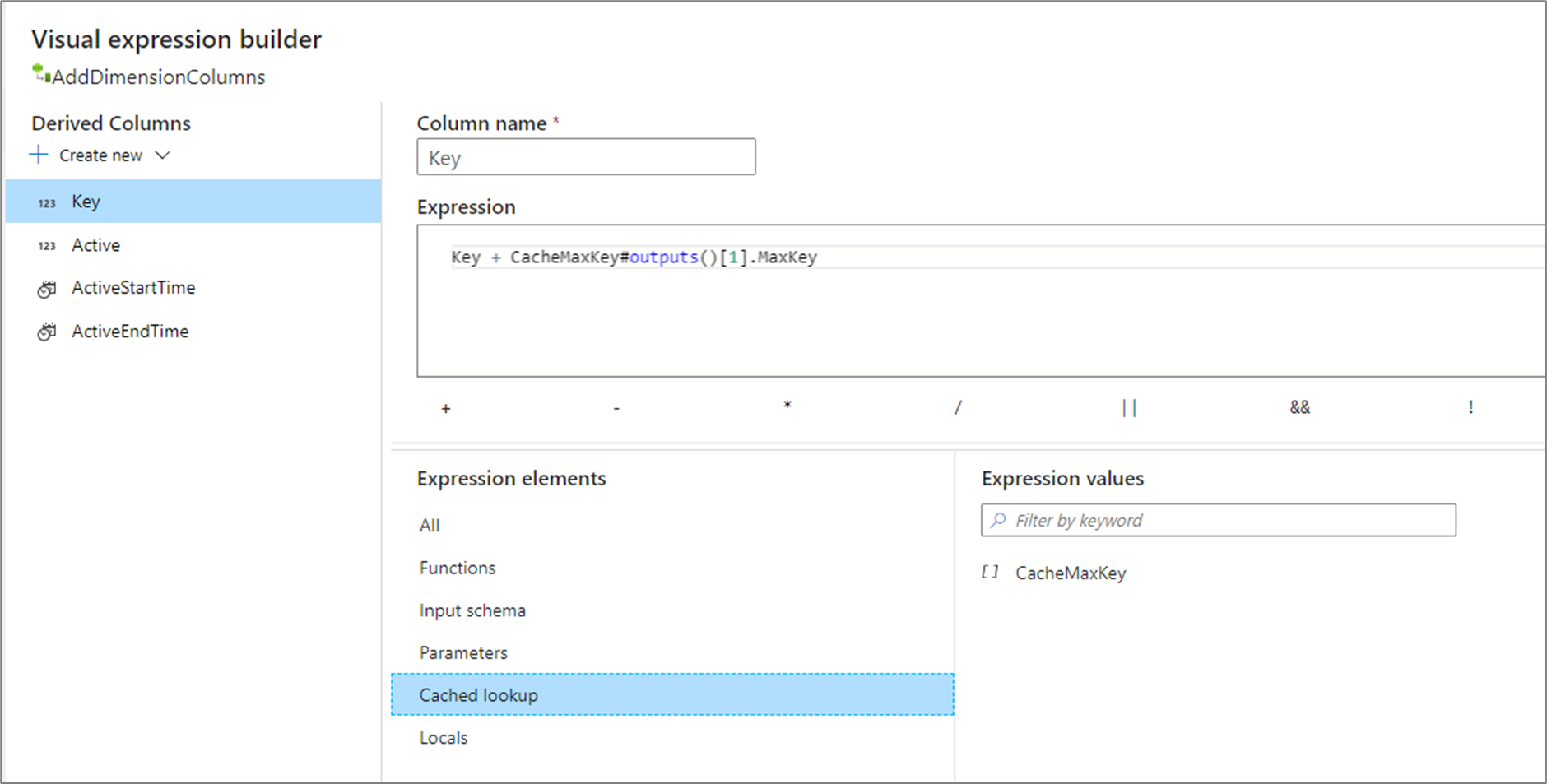
outputs() tar inga parametrar och returnerar hela cachemottagaren som en matris med komplexa kolumner. Detta kan inte anropas om nyckelkolumner anges i mottagaren och bör endast användas om det finns några rader i cachemottagaren. Ett vanligt användningsfall lägger till maxvärdet för en inkrementell nyckel. Om en cachelagrad enskild aggregerad rad CacheMaxKey innehåller en kolumn MaxKeykan du referera till det första värdet genom att anropa CacheMaxKey#outputs()[1].MaxKey.
Lokala
Om du delar logik över flera kolumner eller vill dela upp din logik kan du skapa en lokal variabel. En lokal är en uppsättning logik som inte sprids nedströms till följande transformering. Du kan skapa lokala platser i uttrycksverktyget genom att gå till Uttryckselement och välja Lokala. Skapa en ny genom att välja Skapa ny.

Lokalbefolkningen kan referera till valfritt uttryckselement, inklusive funktioner, indataschema, parametrar och andra lokala objekt. När du refererar till andra lokala platser spelar ordningen roll eftersom den refererade lokala måste vara "över" den aktuella.

Om du vill referera till en lokal i en transformering väljer du antingen den lokala filen från uttryckselementvyn eller refererar till den med ett kolon framför namnet. Till exempel skulle en lokal som heter local1 refereras av :local1. Om du vill redigera en lokal definition hovra över den i uttryckselementvyn och välj pennikonen.

Resultat av förhandsgranskningsuttryck
Om felsökningsläget är aktiverat kan du interaktivt använda felsökningsklustret för att förhandsgranska vad uttrycket utvärderas till. Välj Uppdatera bredvid dataförhandsgranskning för att uppdatera resultatet av dataförhandsgranskningen. Du kan se utdata för varje rad med tanke på indatakolumnerna.

Stränginterpolering
När du skapar långa strängar som använder uttryckselement använder du stränginterpolation för att enkelt bygga upp komplex stränglogik. Stränginterpolation undviker omfattande användning av strängsammanfogning när parametrar ingår i frågesträngar. Använd dubbla citattecken för att omsluta literalsträngstext tillsammans med uttryck. Du kan inkludera uttrycksfunktioner, kolumner och parametrar. Om du vill använda uttryckssyntax omger du det i klammerparenteser,
Några exempel på stränginterpolation:
"My favorite movie is {iif(instr(title,', The')>0,"The {split(title,', The')[1]}",title)}""select * from {$tablename} where orderyear > {$year}""Total cost with sales tax is {round(totalcost * 1.08,2)}""{:playerName} is a {:playerRating} player"
Kommentar
När du använder stränginterpolationssyntax i SQL-källfrågor måste frågesträngen finnas på en enda rad, utan '/n'.
Kommentera uttryck
Lägg till kommentarer i dina uttryck med hjälp av enrads- och flerradskommentarsyntax.
Följande exempel är giltiga kommentarer:
/* This is my comment *//* This is amulti-line comment */
Om du placerar en kommentar överst i uttrycket visas den i textrutan transformering för att dokumentera dina transformeringsuttryck.

Reguljära uttryck
Många uttrycksspråkfunktioner använder syntax för reguljära uttryck. När du använder reguljära uttrycksfunktioner försöker Expression Builder tolka ett omvänt snedstreck (\) som en escape-teckensekvens. När du använder omvänt snedstreck i det reguljära uttrycket omger du antingen hela regexen i backticks (') eller använder ett dubbelt omvänt snedstreck.
Ett exempel som använder backticks:
regex_replace('100 and 200', `(\d+)`, 'digits')
Ett exempel som använder dubbla snedstreck:
regex_replace('100 and 200', '(\\d+)', 'digits')
Kortkommandon för tangentbord
Nedan visas en lista över genvägar som är tillgängliga i uttrycksverktyget. De flesta intellisense-genvägar är tillgängliga när du skapar uttryck.
- Ctrl+K Ctrl+C: Kommentera hela raden.
- Ctrl+K Ctrl+U: Avkommentering.
- F1: Ange hjälpkommandon för redigeraren.
- Alt+Nedåtpil: Flytta ned aktuell linje.
- Alt+Up-piltangent: Flytta upp aktuell linje.
- Ctrl+Blanksteg: Visa kontexthjälp.
Vanliga uttryck
Konvertera till datum eller tidsstämplar
Om du vill inkludera strängliteraler i tidsstämpelutdata omsluter du konverteringen i toString().
toString(toTimestamp('12/31/2016T00:12:00', 'MM/dd/yyyy\'T\'HH:mm:ss'), 'MM/dd /yyyy\'T\'HH:mm:ss')
Om du vill konvertera millisekunder från epok till ett datum eller en tidsstämpel använder du toTimestamp(<number of milliseconds>). Om tiden kommer i sekunder multiplicerar du med 1 000.
toTimestamp(1574127407*1000l)
Det avslutande "l" i slutet av föregående uttryck betyder konvertering till en lång typ som infogad syntax.
Hitta tid från epok eller Unix-tid
toLong( currentTimestamp() - toTimestamp('1970-01-01 00:00:00.000', 'åååå-MM-dd HH:mm:ss. SSS)) ) * 1000l
Utvärdering av dataflödestid
Dataflödesprocesser till millisekunder. För 2018-07-31T20:00:00.2170000 visas 2018-07-31T20:00:00.217 i utdata. I portalen för tjänsten visas tidsstämpeln i den aktuella webbläsarinställningen, vilket kan eliminera 217, men när du kör dataflödet från slutpunkt till slutpunkt bearbetas även 217 (millisekunder). Du kan använda toString(myDateTimeColumn) som uttryck och se fullständiga precisionsdata i förhandsversionen. Bearbeta datetime som datetime i stället för sträng för alla praktiska ändamål.