Transformering av härledda kolumner i dataflödesmappning
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Dataflöden är tillgängliga både i Azure Data Factory och Azure Synapse Pipelines. Den här artikeln gäller för mappning av dataflöden. Om du är nybörjare på transformeringar kan du läsa den inledande artikeln Transformera data med hjälp av ett mappningsdataflöde.
Använd omvandlingen av härledda kolumner för att generera nya kolumner i dataflödet eller för att ändra befintliga fält.
Skapa och uppdatera kolumner
När du skapar en härledd kolumn kan du antingen generera en ny kolumn eller uppdatera en befintlig kolumn. I textrutan Kolumn anger du i den kolumn som du skapar. Om du vill åsidosätta en befintlig kolumn i schemat kan du använda listrutan kolumn. Om du vill skapa uttrycket för den härledda kolumnen klickar du på textrutan Returuttryck . Du kan antingen börja skriva uttrycket eller öppna uttrycksverktyget för att konstruera logiken.

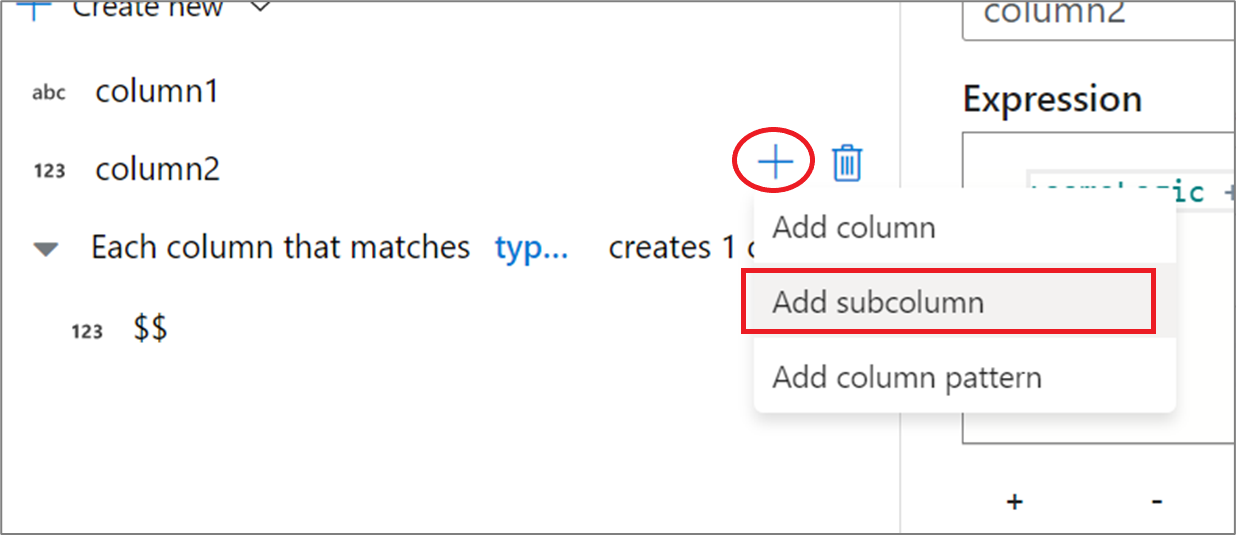
Om du vill lägga till fler härledda kolumner klickar du på Lägg till ovanför kolumnlistan eller plusikonen bredvid en befintlig härledd kolumn. Välj antingen Lägg till kolumn eller Lägg till kolumnmönster.

Kolumnmönster
Om schemat inte uttryckligen har definierats eller om du vill uppdatera en uppsättning kolumner i bulk vill du skapa kolumnmönster. Med kolumnmönster kan du matcha kolumner med hjälp av regler baserat på kolumnmetadata och skapa härledda kolumner för varje matchad kolumn. Mer information finns i skapa kolumnmönster i omvandlingen av härledda kolumner.

Skapa scheman med hjälp av uttrycksverktyget
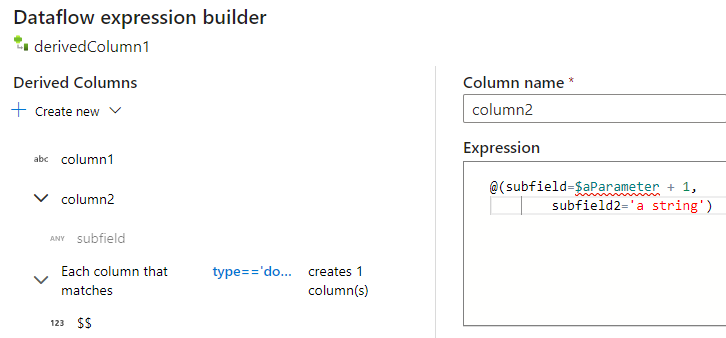
När du använder uttrycksverktyget för mappningsdataflöde kan du skapa, redigera och hantera dina härledda kolumner i avsnittet Härledda kolumner. Alla kolumner som skapas eller ändras i omvandlingen visas. Välj interaktivt vilken kolumn eller vilket mönster du redigerar genom att klicka på kolumnnamnet. Om du vill lägga till ytterligare en kolumn väljer du Skapa ny och väljer om du vill lägga till en enskild kolumn eller ett mönster.

När du arbetar med komplexa kolumner kan du skapa underkolumner. Det gör du genom att klicka på plusikonen bredvid valfri kolumn och välja Lägg till underkolumn. Mer information om hur du hanterar komplexa typer i dataflödet finns i JSON-hantering i mappning av dataflöde.
Mer information om hur du hanterar komplexa typer i dataflödet finns i JSON-hantering i mappning av dataflöde.
Dataflödesskript
Syntax
<incomingStream>
derive(
<columnName1> = <expression1>,
<columnName2> = <expression2>,
each(
match(matchExpression),
<metadataColumn1> = <metadataExpression1>,
<metadataColumn2> = <metadataExpression2>
)
) ~> <deriveTransformationName>
Exempel
Exemplet nedan är en härledd kolumn med namnet CleanData som tar en inkommande ström MoviesYear och skapar två härledda kolumner. Den första härledda kolumnen ersätter kolumnen Rating med omdömets värde som en heltalstyp. Den andra härledda kolumnen är ett mönster som matchar varje kolumn vars namn börjar med "filmer". För varje matchad kolumn skapas en kolumn movie som är lika med värdet för den matchade kolumnen med prefixet "movie_".
I användargränssnittet ser den här omvandlingen ut som bilden nedan:

Dataflödesskriptet för den här omvandlingen finns i kodfragmentet nedan:
MoviesYear derive(
Rating = toInteger(Rating),
each(
match(startsWith(name,'movies')),
'movie' = 'movie_' + toString($$)
)
) ~> CleanData