Kopiera och transformera data i Azure Blob Storage med hjälp av Azure Data Factory eller Azure Synapse Analytics
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Den här artikeln beskriver hur du använder kopieringsaktiviteten i Azure Data Factory och Azure Synapse-pipelines för att kopiera data från och till Azure Blob Storage. Den beskriver också hur du använder dataflödesaktiviteten för att transformera data i Azure Blob Storage. Mer information finns i introduktionsartiklarna för Azure Data Factory och Azure Synapse Analytics.
Dricks
Mer information om ett migreringsscenario för en datasjö eller ett informationslager finns i artikeln Migrera data från din datasjö eller ditt informationslager till Azure.
Funktioner som stöds
Den här Azure Blob Storage-anslutningsappen stöds för följande funktioner:
| Funktioner som stöds | IR | Hanterad privat slutpunkt |
|---|---|---|
| Kopieringsaktivitet (källa/mottagare) | (1) (2) | √ Exkludera lagringskonto V1 |
| Mappa dataflöde (källa/mottagare) | (1) | √ Exkludera lagringskonto V1 |
| Sökningsaktivitet | (1) (2) | √ Exkludera lagringskonto V1 |
| GetMetadata-aktivitet | (1) (2) | √ Exkludera lagringskonto V1 |
| Ta bort aktivitet | (1) (2) | √ Exkludera lagringskonto V1 |
(1) Azure Integration Runtime (2) Lokalt installerad integrationskörning
För kopieringsaktiviteten stöder den här Blob Storage-anslutningsappen:
- Kopiera blobar till och från allmänna Azure-lagringskonton och frekvent/lågfrekvent bloblagring.
- Kopiera blobar med hjälp av en kontonyckel, en signatur för delad åtkomst (SAS), tjänstens huvudnamn eller hanterade identiteter för Azure-resursautentiseringar.
- Kopiera blobar från block-, tilläggs- eller sidblobar och kopiera data till endast blockblobar.
- Kopiera blobar som de är, eller parsa eller generera blobar med filformat som stöds och komprimeringskodexer.
- Bevarar filmetadata under kopieringen.
Kom igång
Om du vill utföra kopieringsaktiviteten med en pipeline kan du använda något av följande verktyg eller SDK:er:
- Verktyget Kopiera data
- Azure-portalen
- The .NET SDK
- The Python SDK
- Azure PowerShell
- REST-API:et
- Azure Resource Manager-mallen
Skapa en länkad Azure Blob Storage-tjänst med hjälp av användargränssnittet
Använd följande steg för att skapa en länkad Azure Blob Storage-tjänst i azure-portalens användargränssnitt.
Bläddra till fliken Hantera i Din Azure Data Factory- eller Synapse-arbetsyta och välj Länkade tjänster och välj sedan Nytt:
Sök efter blob och välj Azure Blob Storage-anslutningsappen.
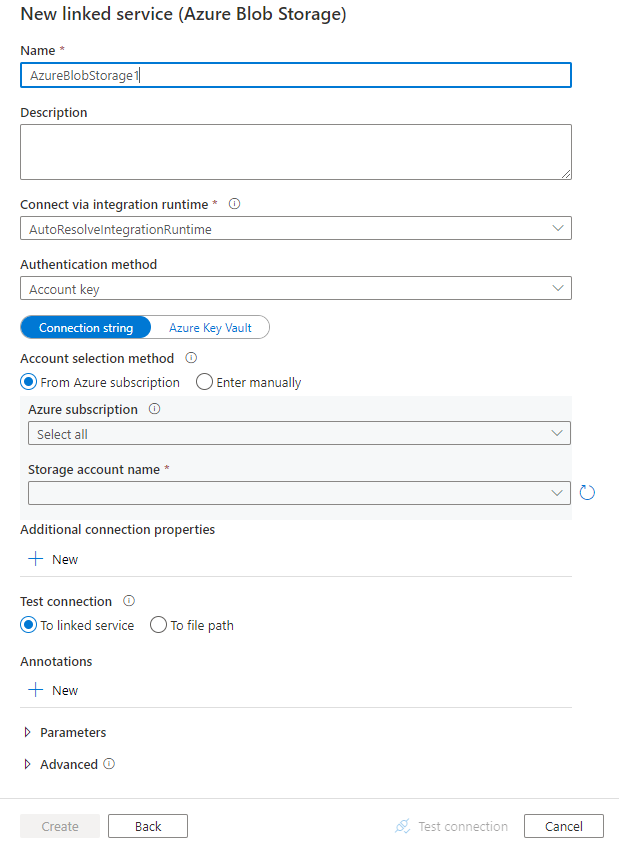
Konfigurera tjänstinformationen, testa anslutningen och skapa den nya länkade tjänsten.
Konfigurationsinformation för anslutningsprogram
Följande avsnitt innehåller information om egenskaper som används för att definiera Data Factory- och Synapse-pipelineentiteter som är specifika för Blob Storage.
Länkade tjänstegenskaper
Den här Blob Storage-anslutningsappen stöder följande autentiseringstyper. Mer information finns i motsvarande avsnitt.
- Anonym autentisering
- Kontonyckelautentisering
- Signaturautentisering för delad åtkomst
- Autentisering av tjänstens huvudnamn
- Systemtilldelad autentisering av hanterad identitet
- Användartilldelad hanterad identitetsautentisering
Kommentar
- Om du vill använda den offentliga Azure-integreringskörningen för att ansluta till bloblagringen genom att använda alternativet Tillåt betrodd Microsoft usluge att komma åt det här lagringskontoalternativet som är aktiverat i Azure Storage-brandväggen måste du använda hanterad identitetsautentisering. Mer information om inställningarna för Azure Storage-brandväggar finns i Konfigurera Azure Storage-brandväggar och virtuella nätverk.
- När du använder PolyBase- eller COPY-instruktionen för att läsa in data i Azure Synapse Analytics måste du använda hanterad identitetsautentisering som krävs av Azure Synapse om din käll- eller mellanlagringsbloblagring har konfigurerats med en Azure Virtual Network-slutpunkt. Mer konfigurationskrav finns i avsnittet Hanterad identitetsautentisering .
Kommentar
Azure HDInsight- och Azure Mašinsko učenje-aktiviteter stöder endast autentisering som använder Azure Blob Storage-kontonycklar.
Anonym autentisering
Följande egenskaper stöds för autentisering av lagringskontonycklar i Azure Data Factory eller Synapse-pipelines:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Egenskapen type måste anges till AzureBlobStorage (föreslagen) eller AzureStorage (se följande anteckningar). |
Ja |
| containerUri | Ange den Azure Blob-container-URI som har aktiverat anonym läsåtkomst genom att använda det här formatet https://<AccountName>.blob.core.windows.net/<ContainerName> och Konfigurera anonym offentlig läsåtkomst för containrar och blobar |
Ja |
| connectVia | Den integrationskörning som ska användas för att ansluta till datalagret. Du kan använda Azure Integration Runtime eller integrationskörningen med egen värd (om ditt datalager finns i ett privat nätverk). Om den här egenskapen inte har angetts använder tjänsten standardkörningen för Azure-integrering. | Nej |
Exempel:
{
"name": "AzureBlobStorageAnonymous",
"properties": {
"annotations": [],
"type": "AzureBlobStorage",
"typeProperties": {
"containerUri": "https:// <accountname>.blob.core.windows.net/ <containername>",
"authenticationType": "Anonymous"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
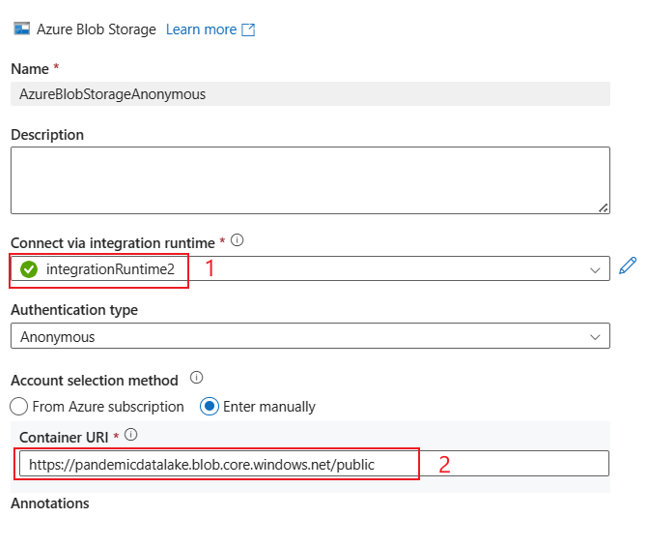
Exempel på användargränssnitt:
Användargränssnittsupplevelsen beskrivs i följande bild. Det här exemplet använder den öppna Azure-datamängden som källa. Om du vill få den öppna datamängden bing_covid-19_data.csv behöver du bara välja Autentiseringstyp som Anonym och fylla i Container-URI med https://pandemicdatalake.blob.core.windows.net/public.
Kontonyckelautentisering
Följande egenskaper stöds för autentisering av lagringskontonycklar i Azure Data Factory eller Synapse-pipelines:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Egenskapen type måste anges till AzureBlobStorage (föreslagen) eller AzureStorage (se följande anteckningar). |
Ja |
| connectionString | Ange den information som behövs för att ansluta till Storage för connectionString egenskapen. Du kan också placera kontonyckeln i Azure Key Vault och hämta konfigurationen accountKey från niska veze. Mer information finns i följande exempel och artikeln Lagra autentiseringsuppgifter i Azure Key Vault . |
Ja |
| connectVia | Den integrationskörning som ska användas för att ansluta till datalagret. Du kan använda Azure Integration Runtime eller integrationskörningen med egen värd (om ditt datalager finns i ett privat nätverk). Om den här egenskapen inte har angetts använder tjänsten standardkörningen för Azure-integrering. | Nej |
Kommentar
En sekundär blobtjänstslutpunkt stöds inte när du använder kontonyckelautentisering. Du kan använda andra autentiseringstyper.
Kommentar
Om du använder den AzureStorage länkade typen av tjänst stöds den fortfarande som den är. Men vi föreslår att du använder den nya AzureBlobStorage länkade tjänsttypen framöver.
Exempel:
{
"name": "AzureBlobStorageLinkedService",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=<accountkey>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Exempel: lagra kontonyckeln i Azure Key Vault
{
"name": "AzureBlobStorageLinkedService",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;",
"accountKey": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Signaturautentisering för delad åtkomst
En signatur för delad åtkomst ger delegerad åtkomst till resurser i ditt lagringskonto. Du kan använda en signatur för delad åtkomst för att bevilja en klient begränsad behörighet till objekt i ditt lagringskonto under en angiven tid.
Du behöver inte dela dina kontoåtkomstnycklar. Signaturen för delad åtkomst är en URI som i sina frågeparametrar innehåller all information som krävs för autentiserad åtkomst till en lagringsresurs. För att få åtkomst till lagringsresurser med signaturen för delad åtkomst behöver klienten bara skicka in signaturen för delad åtkomst till lämplig konstruktor eller metod.
Mer information om signaturer för delad åtkomst finns i Signaturer för delad åtkomst: Förstå signaturmodellen för delad åtkomst.
Kommentar
- Tjänsten stöder nu både signaturer för delad åtkomst och signaturer för delad åtkomst för konton. Mer information om signaturer för delad åtkomst finns i Bevilja begränsad åtkomst till Azure Storage-resurser med hjälp av signaturer för delad åtkomst.
- I senare konfigurationer av datauppsättningar är mappsökvägen den absoluta sökvägen från containernivån. Du måste konfigurera en som är anpassad till sökvägen i DIN SAS-URI.
Följande egenskaper stöds för användning av signaturautentisering för delad åtkomst:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Egenskapen type måste vara inställd på AzureBlobStorage (föreslagen) eller AzureStorage (se följande anmärkning). |
Ja |
| sasUri | Ange signatur-URI:n för delad åtkomst till lagringsresurserna, till exempel blob eller container. Markera det här fältet så SecureString att det lagras på ett säkert sätt. Du kan också placera SAS-token i Azure Key Vault för att använda automatisk rotation och ta bort tokendelen. Mer information finns i följande exempel och Lagra autentiseringsuppgifter i Azure Key Vault. |
Ja |
| connectVia | Den integrationskörning som ska användas för att ansluta till datalagret. Du kan använda Azure Integration Runtime eller integrationskörningen med egen värd (om ditt datalager finns i ett privat nätverk). Om den här egenskapen inte har angetts använder tjänsten standardkörningen för Azure-integrering. | Nej |
Kommentar
Om du använder den AzureStorage länkade typen av tjänst stöds den fortfarande som den är. Men vi föreslår att du använder den nya AzureBlobStorage länkade tjänsttypen framöver.
Exempel:
{
"name": "AzureBlobStorageLinkedService",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"sasUri": {
"type": "SecureString",
"value": "<SAS URI of the Azure Storage resource e.g. https://<accountname>.blob.core.windows.net/?sv=<storage version>&st=<start time>&se=<expire time>&sr=<resource>&sp=<permissions>&sip=<ip range>&spr=<protocol>&sig=<signature>>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Exempel: lagra kontonyckeln i Azure Key Vault
{
"name": "AzureBlobStorageLinkedService",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"sasUri": {
"type": "SecureString",
"value": "<SAS URI of the Azure Storage resource without token e.g. https://<accountname>.blob.core.windows.net/>"
},
"sasToken": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName with value of SAS token e.g. ?sv=<storage version>&st=<start time>&se=<expire time>&sr=<resource>&sp=<permissions>&sip=<ip range>&spr=<protocol>&sig=<signature>>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
När du skapar en signatur-URI för delad åtkomst bör du tänka på följande:
- Ange lämpliga läs-/skrivbehörigheter för objekt baserat på hur den länkade tjänsten (läsa, skriva, läsa/skriva) används.
- Ange förfallotid på rätt sätt. Kontrollera att åtkomsten till Lagringsobjekt inte upphör att gälla inom den aktiva perioden för pipelinen.
- URI:n ska skapas i rätt container eller blob baserat på behovet. Med en signatur-URI för delad åtkomst till en blob kan datafabriken eller Synapse-pipelinen komma åt den specifika bloben. Med en signatur-URI för delad åtkomst till en Blob Storage-container kan datafabriken eller Synapse-pipelinen iterera via blobar i containern. Kom ihåg att uppdatera den länkade tjänsten med den nya URI:n för att ge åtkomst till fler eller färre objekt senare eller uppdatera signaturen för delad åtkomst.
Tjänstens huvudautentisering
Allmän information om autentisering av tjänstens huvudnamn för Azure Storage finns i Autentisera åtkomst till Azure Storage med hjälp av Microsoft Entra-ID.
Följ dessa steg om du vill använda autentisering med tjänstens huvudnamn:
Registrera ett program med Microsoft platforma za identitete. Mer information finns i Snabbstart: Registrera ett program med Microsoft platforma za identitete. Anteckna dessa värden som du använder för att definiera den länkade tjänsten:
- Program-ID:t
- Programnyckel
- Klientorganisations-ID
Ge tjänstens huvudnamn rätt behörighet i Azure Blob Storage. Mer information om rollerna finns i Använda Azure-portalen för att tilldela en Azure-roll för åtkomst till blob- och ködata.
- Som källa i Åtkomstkontroll (IAM) beviljar du minst rollen Storage Blob Data Reader .
- I Åtkomstkontroll (IAM) som mottagare beviljar du minst rollen Storage Blob Data Contributor.
Dessa egenskaper stöds för en länkad Azure Blob Storage-tjänst:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen måste anges till AzureBlobStorage. | Ja |
| serviceEndpoint | Ange tjänstslutpunkten för Azure Blob Storage med mönstret https://<accountName>.blob.core.windows.net/. |
Ja |
| accountKind | Ange typen av lagringskonto. Tillåtna värden är: Lagring (generell användning v1), StorageV2 (generell användning v2), BlobStorage eller BlockBlobStorage. När du använder den länkade Azure Blob-tjänsten i dataflödet stöds inte hanterad identitet eller autentisering med tjänstens huvudnamn när kontotypen är tom eller "Lagring". Ange rätt kontotyp, välj en annan autentisering eller uppgradera ditt lagringskonto till generell användning v2. |
Nej |
| servicePrincipalId | Ange programmets klient-ID. | Ja |
| servicePrincipalCredentialType | Den typ av autentiseringsuppgifter som ska användas för autentisering med tjänstens huvudnamn. Tillåtna värden är ServicePrincipalKey och ServicePrincipalCert. | Ja |
| servicePrincipalCredential | Autentiseringsuppgifterna för tjänstens huvudnamn. När du använder ServicePrincipalKey som typ av autentiseringsuppgifter anger du programmets nyckel. Markera det här fältet som SecureString för att lagra det på ett säkert sätt eller referera till en hemlighet som lagras i Azure Key Vault. När du använder ServicePrincipalCert som autentiseringsuppgifter refererar du till ett certifikat i Azure Key Vault och kontrollerar att certifikatinnehållstypen är PKCS #12. |
Ja |
| tenant | Ange klientinformationen (domännamn eller klient-ID) som programmet finns under. Hämta den genom att hovra över det övre högra hörnet i Azure-portalen. | Ja |
| azureCloudType | För autentisering med tjänstens huvudnamn anger du vilken typ av Azure-molnmiljö som ditt Microsoft Entra-program är registrerat på. Tillåtna värden är AzurePublic, AzureChina, AzureUsGovernment och AzureGermany. Som standard används datafabriken eller Synapse-pipelinens molnmiljö. |
Nej |
| connectVia | Den integrationskörning som ska användas för att ansluta till datalagret. Du kan använda Azure Integration Runtime eller integrationskörningen med egen värd (om ditt datalager finns i ett privat nätverk). Om den här egenskapen inte har angetts använder tjänsten standardkörningen för Azure-integrering. | Nej |
Kommentar
- Om ditt blobkonto aktiverar mjuk borttagning stöds inte autentisering med tjänstens huvudnamn i Data Flow.
- Om du kommer åt bloblagringen via en privat slutpunkt med hjälp av dataflödet bör du tänka på när autentisering med tjänstens huvudnamn används. Dataflöde ansluter till ADLS Gen2-slutpunkten i stället för blobslutpunkten. Se till att du skapar motsvarande privata slutpunkt i datafabriken eller Synapse-arbetsytan för att aktivera åtkomst.
Kommentar
Autentisering med tjänstens huvudnamn stöds endast av den länkade tjänsten "AzureBlobStorage", inte den tidigare länkade tjänsten "AzureStorage".
Exempel:
{
"name": "AzureBlobStorageLinkedService",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"serviceEndpoint": "https://<accountName>.blob.core.windows.net/",
"accountKind": "StorageV2",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Systemtilldelad autentisering av hanterad identitet
En datafabrik eller Synapse-pipeline kan associeras med en systemtilldelad hanterad identitet för Azure-resurser, som representerar resursen för autentisering till andra Azure-tjänster. Du kan använda den här systemtilldelade hanterade identiteten direkt för Blob Storage-autentisering, vilket liknar att använda ditt eget huvudnamn för tjänsten. Den gör att den här avsedda resursen kan komma åt och kopiera data från eller till Blob Storage. Mer information om hanterade identiteter för Azure-resurser finns i Hanterade identiteter för Azure-resurser
Allmän information om Azure Storage-autentisering finns i Autentisera åtkomst till Azure Storage med hjälp av Microsoft Entra-ID. Följ dessa steg om du vill använda hanterade identiteter för Azure-resursautentisering:
Hämta systemtilldelad hanterad identitetsinformation genom att kopiera värdet för det systemtilldelade objekt-ID för hanterad identitet som genererats tillsammans med din fabrik eller Synapse-arbetsyta.
Ge den hanterade identiteten behörighet i Azure Blob Storage. Mer information om rollerna finns i Använda Azure-portalen för att tilldela en Azure-roll för åtkomst till blob- och ködata.
- Som källa i Åtkomstkontroll (IAM) beviljar du minst rollen Storage Blob Data Reader .
- I Åtkomstkontroll (IAM) som mottagare beviljar du minst rollen Storage Blob Data Contributor.
Dessa egenskaper stöds för en länkad Azure Blob Storage-tjänst:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen måste anges till AzureBlobStorage. | Ja |
| serviceEndpoint | Ange tjänstslutpunkten för Azure Blob Storage med mönstret https://<accountName>.blob.core.windows.net/. |
Ja |
| accountKind | Ange typen av lagringskonto. Tillåtna värden är: Lagring (generell användning v1), StorageV2 (generell användning v2), BlobStorage eller BlockBlobStorage. När du använder den länkade Azure Blob-tjänsten i dataflödet stöds inte hanterad identitet eller autentisering med tjänstens huvudnamn när kontotypen är tom eller "Lagring". Ange rätt kontotyp, välj en annan autentisering eller uppgradera ditt lagringskonto till generell användning v2. |
Nej |
| connectVia | Den integrationskörning som ska användas för att ansluta till datalagret. Du kan använda Azure Integration Runtime eller integrationskörningen med egen värd (om ditt datalager finns i ett privat nätverk). Om den här egenskapen inte har angetts använder tjänsten standardkörningen för Azure-integrering. | Nej |
Exempel:
{
"name": "AzureBlobStorageLinkedService",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"serviceEndpoint": "https://<accountName>.blob.core.windows.net/",
"accountKind": "StorageV2"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Användartilldelad hanterad identitetsautentisering
En datafabrik kan tilldelas en eller flera användartilldelade hanterade identiteter. Du kan använda den här användartilldelade hanterade identiteten för Blob Storage-autentisering, som gör det möjligt att komma åt och kopiera data från eller till Blob Storage. Mer information om hanterade identiteter för Azure-resurser finns i Hanterade identiteter för Azure-resurser
Allmän information om Azure Storage-autentisering finns i Autentisera åtkomst till Azure Storage med hjälp av Microsoft Entra-ID. Följ dessa steg om du vill använda användartilldelad hanterad identitetsautentisering:
Skapa en eller flera användartilldelade hanterade identiteter och bevilja behörighet i Azure Blob Storage. Mer information om rollerna finns i Använda Azure-portalen för att tilldela en Azure-roll för åtkomst till blob- och ködata.
- Som källa i Åtkomstkontroll (IAM) beviljar du minst rollen Storage Blob Data Reader .
- I Åtkomstkontroll (IAM) som mottagare beviljar du minst rollen Storage Blob Data Contributor.
Tilldela en eller flera användartilldelade hanterade identiteter till din datafabrik och skapa autentiseringsuppgifter för varje användartilldelad hanterad identitet.
Dessa egenskaper stöds för en länkad Azure Blob Storage-tjänst:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen måste anges till AzureBlobStorage. | Ja |
| serviceEndpoint | Ange tjänstslutpunkten för Azure Blob Storage med mönstret https://<accountName>.blob.core.windows.net/. |
Ja |
| accountKind | Ange typen av lagringskonto. Tillåtna värden är: Lagring (generell användning v1), StorageV2 (generell användning v2), BlobStorage eller BlockBlobStorage. När du använder den länkade Azure Blob-tjänsten i dataflödet stöds inte hanterad identitet eller autentisering med tjänstens huvudnamn när kontot är tomt eller "Lagring". Ange rätt kontotyp, välj en annan autentisering eller uppgradera ditt lagringskonto till generell användning v2. |
Nej |
| autentiseringsuppgifter | Ange den användartilldelade hanterade identiteten som autentiseringsobjekt. | Ja |
| connectVia | Den integrationskörning som ska användas för att ansluta till datalagret. Du kan använda Azure Integration Runtime eller integrationskörningen med egen värd (om ditt datalager finns i ett privat nätverk). Om den här egenskapen inte har angetts använder tjänsten standardkörningen för Azure-integrering. | Nej |
Exempel:
{
"name": "AzureBlobStorageLinkedService",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"serviceEndpoint": "https://<accountName>.blob.core.windows.net/",
"accountKind": "StorageV2",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Viktigt!
Om du använder PolyBase- eller COPY-instruktionen för att läsa in data från Blob Storage (som en källa eller som mellanlagring) i Azure Synapse Analytics ska du se till att du även följer steg 1 till 3 i den här vägledningen när du använder hanterad identitetsautentisering för Blob Storage. Dessa steg registrerar servern med Microsoft Entra-ID och tilldelar rollen Storage Blob Data Contributor till servern. Data Factory hanterar resten. Om du konfigurerar Blob Storage med en Azure Virtual Network-slutpunkt måste du också ha Tillåt betrodda Microsoft usluge för att få åtkomst till det här lagringskontot aktiverat under menyn Brandväggar för Azure Storage-konto och Inställningar för virtuella nätverk enligt Azure Synapse.
Kommentar
- Om ditt blobkonto aktiverar mjuk borttagning stöds inte systemtilldelad/användartilldelad hanterad identitetsautentisering i Data Flow.
- Om du får åtkomst till bloblagringen via en privat slutpunkt med dataflödet bör du tänka på när systemtilldelad/användartilldelad hanterad identitetsautentisering används Dataflöde ansluter till ADLS Gen2-slutpunkten i stället för Blob-slutpunkten. Se till att du skapar motsvarande privata slutpunkt i ADF för att aktivera åtkomst.
Kommentar
Systemtilldelad/användartilldelad hanterad identitetsautentisering stöds endast av den länkade tjänsten "AzureBlobStorage", inte den tidigare länkade tjänsten "AzureStorage".
Egenskaper för datauppsättning
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera datauppsättningar finns i artikeln Datauppsättningar .
Azure Data Factory stöder följande filformat. Se varje artikel för formatbaserade inställningar.
- Avro-format
- Binärt format
- Avgränsat textformat
- Excel-format
- JSON-format
- ORC-format
- Parquet-format
- XML-format
Följande egenskaper stöds för Azure Blob Storage under location inställningar i en formatbaserad datauppsättning:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen för platsen i datamängden måste anges till AzureBlobStorageLocation. | Ja |
| container | Blobcontainern. | Ja |
| folderPath | Sökvägen till mappen under den angivna containern. Om du vill använda ett jokertecken för att filtrera mappen hoppar du över den här inställningen och anger den i inställningarna för aktivitetskällan. | Nej |
| fileName | Filnamnet under den angivna containern och mappsökvägen. Om du vill använda jokertecken för att filtrera filer hoppar du över den här inställningen och anger det i inställningarna för aktivitetskällan. | Nej |
Exempel:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Kopiera egenskaper för aktivitet
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera aktiviteter finns i artikeln Pipelines . Det här avsnittet innehåller en lista över egenskaper som bloblagringskällan och mottagare stöder.
Bloblagring som källtyp
Azure Data Factory stöder följande filformat. Se varje artikel för formatbaserade inställningar.
- Avro-format
- Binärt format
- Avgränsat textformat
- Excel-format
- JSON-format
- ORC-format
- Parquet-format
- XML-format
Följande egenskaper stöds för Azure Blob Storage under storeSettings inställningar i en formatbaserad kopieringskälla:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen under storeSettings måste anges till AzureBlobStorageReadSettings. |
Ja |
| Leta upp filerna som ska kopieras: | ||
| ALTERNATIV 1: statisk sökväg |
Kopiera från den angivna containern eller mapp-/filsökvägen som anges i datauppsättningen. Om du vill kopiera alla blobar från en container eller mapp anger du wildcardFileName dessutom som *. |
|
| ALTERNATIV 2: blobprefix -prefix |
Prefix för blobnamnet under den angivna containern som konfigurerats i en datauppsättning för att filtrera källblobar. Blobbar vars namn börjar med container_in_dataset/this_prefix är markerade. Det använder filtret på tjänstsidan för Blob Storage, vilket ger bättre prestanda än ett jokerteckenfilter.När du använder prefix och väljer att kopiera till filbaserad mottagare med bevarad hierarki bör du notera undersökvägen efter att den sista "/" i prefixet bevarats. Du har till exempel källan container/folder/subfolder/file.txtoch konfigurerar prefixet som folder/sub, och sedan är subfolder/file.txtden bevarade filsökvägen . |
Nej |
| ALTERNATIV 3: jokertecken - jokerteckenFolderPath |
Mappsökvägen med jokertecken under den angivna containern som konfigurerats i en datauppsättning för att filtrera källmappar. Tillåtna jokertecken är: * (matchar noll eller fler tecken) och ? (matchar noll eller enskilt tecken). Använd ^ för att fly om mappnamnet har jokertecken eller det här escape-tecknet inuti. Se fler exempel i exempel på mapp- och filfilter. |
Nej |
| ALTERNATIV 3: jokertecken - jokerteckenFileName |
Filnamnet med jokertecken under den angivna containern och mappsökvägen (eller sökvägen till jokerteckenmappen) för att filtrera källfiler. Tillåtna jokertecken är: * (matchar noll eller fler tecken) och ? (matchar noll eller enskilt tecken). Använd ^ för att fly om filnamnet har ett jokertecken eller det här escape-tecknet inuti. Se fler exempel i exempel på mapp- och filfilter. |
Ja |
| ALTERNATIV 4: en lista över filer – fileListPath |
Anger att en angiven filuppsättning ska kopieras. Peka på en textfil som innehåller en lista över filer som du vill kopiera, en fil per rad, vilket är den relativa sökvägen till sökvägen som konfigurerats i datauppsättningen. När du använder det här alternativet ska du inte ange något filnamn i datauppsättningen. Se fler exempel i fillisteexempel. |
Nej |
| Ytterligare inställningar: | ||
| rekursiv | Anger om data läse rekursivt från undermapparna eller endast från den angivna mappen. Observera att när rekursivt är inställt på sant och mottagaren är ett filbaserat arkiv kopieras eller skapas inte en tom mapp eller undermapp i mottagaren. Tillåtna värden är sanna (standard) och falska. Den här egenskapen gäller inte när du konfigurerar fileListPath. |
Nej |
| deleteFilesAfterCompletion | Anger om de binära filerna kommer att tas bort från källarkivet när de har flyttats till målarkivet. Filborttagningen sker per fil. När kopieringsaktiviteten misslyckas ser du därför att vissa filer redan har kopierats till målet och tagits bort från källan, medan andra fortfarande finns kvar i källarkivet. Den här egenskapen är endast giltig i scenariot med kopiering av binära filer. Standardvärdet: false. |
Nej |
| modifiedDatetimeStart | Filer filtreras baserat på attributet: senast ändrad. Filerna väljs om deras senaste ändringstid är större än eller lika med modifiedDatetimeStart och mindre än modifiedDatetimeEnd. Tiden tillämpas på en UTC-tidszon i formatet "2018-12-01T05:00:00Z". Egenskaperna kan vara NULL, vilket innebär att inget filattributfilter tillämpas på datamängden. När modifiedDatetimeStart har ett datetime-värde men modifiedDatetimeEnd är NULL väljs de filer vars senast ändrade attribut är större än eller lika med datetime-värdet. När modifiedDatetimeEnd har ett datetime-värde men modifiedDatetimeStart är NULL väljs de filer vars senast ändrade attribut är mindre än datetime-värdet.Den här egenskapen gäller inte när du konfigurerar fileListPath. |
Nej |
| modifiedDatetimeEnd | Samma som föregående egenskap. | Nej |
| enablePartitionDiscovery | För filer som är partitionerade anger du om partitionerna ska parsas från filsökvägen och lägga till dem som extra källkolumner. Tillåtna värden är false (standard) och true. |
Nej |
| partitionRootPath | När partitionsidentifiering är aktiverat anger du den absoluta rotsökvägen för att läsa partitionerade mappar som datakolumner. Om den inte har angetts, som standard, – När du använder filsökvägen i datauppsättningen eller listan över filer på källan är partitionsrotsökvägen den sökväg som konfigurerats i datauppsättningen. – När du använder mappfilter för jokertecken är partitionsrotsökvägen undersökvägen före det första jokertecknet. – När du använder prefixet är partitionsrotsökvägen undersökvägen före den sista "/". Anta till exempel att du konfigurerar sökvägen i datauppsättningen som "root/folder/year=2020/month=08/day=27": – Om du anger partitionsrotsökväg som "root/folder/year=2020" genererar kopieringsaktiviteten ytterligare två kolumner month och day med värdet "08" respektive "27", utöver kolumnerna i filerna.– Om partitionens rotsökväg inte har angetts genereras ingen extra kolumn. |
Nej |
| maxConcurrentConnections | Den övre gränsen för samtidiga anslutningar som upprättats till datalagret under aktivitetskörningen. Ange endast ett värde när du vill begränsa samtidiga anslutningar. | Nej |
Kommentar
För Parquet/avgränsat textformat stöds blobsource-typen för den kopieringsaktivitetskälla som nämns i nästa avsnitt fortfarande som för bakåtkompatibilitet. Vi rekommenderar att du använder den nya modellen tills redigeringsgränssnittet har växlat till att generera dessa nya typer.
Exempel:
"activities":[
{
"name": "CopyFromBlob",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "AzureBlobStorageReadSettings",
"recursive": true,
"wildcardFolderPath": "myfolder*A",
"wildcardFileName": "*.csv"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Kommentar
Containern $logs , som skapas automatiskt när Storage Analytics är aktiverat för ett lagringskonto, visas inte när en containerlistningsåtgärd utförs via användargränssnittet. Filsökvägen måste anges direkt för att datafabriken eller Synapse-pipelinen ska kunna använda filer från containern $logs .
Bloblagring som mottagartyp
Azure Data Factory stöder följande filformat. Se varje artikel för formatbaserade inställningar.
Följande egenskaper stöds för Azure Blob Storage under storeSettings inställningar i en formatbaserad kopieringsmottagare:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Egenskapen type under storeSettings måste vara inställd på AzureBlobStorageWriteSettings. |
Ja |
| copyBehavior | Definierar kopieringsbeteendet när källan är filer från ett filbaserat datalager. Tillåtna värden är: – PreserveHierarchy (standard): Bevarar filhierarkin i målmappen. Källfilens relativa sökväg till källmappen är identisk med målfilens relativa sökväg till målmappen. – FlattenHierarchy: Alla filer från källmappen finns på den första nivån i målmappen. Målfilerna har automatiskt genererade namn. – MergeFiles: Sammanfogar alla filer från källmappen till en fil. Om filen eller blobnamnet anges är det kopplade filnamnet det angivna namnet. Annars är det ett automatiskt genererat filnamn. |
Nej |
| blockSizeInMB | Ange blockstorleken i megabyte som används för att skriva data för att blockera blobar. Läs mer om blockblobar. Det tillåtna värdet är mellan 4 MB och 100 MB. Som standard avgör tjänsten automatiskt blockstorleken baserat på källlagringstypen och data. För ickebinär kopiering till Blob Storage är standardblockstorleken 100 MB så att den får plats i (högst) 4,95 TB data. Det kanske inte är optimalt när dina data inte är stora, särskilt när du använder den lokalt installerade integrationskörningen med dåliga nätverksanslutningar som resulterar i timeout- eller prestandaproblem. Du kan uttryckligen ange en blockstorlek, samtidigt som du ser till att den blockSizeInMB*50000 är tillräckligt stor för att lagra data. Annars misslyckas kopieringsaktivitetskörningen. |
Nej |
| maxConcurrentConnections | Den övre gränsen för samtidiga anslutningar som upprättats till datalagret under aktivitetskörningen. Ange endast ett värde när du vill begränsa samtidiga anslutningar. | Nej |
| metadata | Ange anpassade metadata när du kopierar till mottagare. Varje objekt under matrisen metadata representerar en extra kolumn. name Definierar namnet på metadatanyckeln value och anger nyckelns datavärde. Om funktionen bevara attribut används kommer angivna metadata att kopplas/skrivas över med källfilens metadata.Tillåtna datavärden är: - $$LASTMODIFIED: en reserverad variabel anger att källfilerna senast ändrades. Gäller endast för filbaserad källa med binärt format.-Uttryck - Statiskt värde |
Nej |
Exempel:
"activities":[
{
"name": "CopyFromBlob",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Parquet output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "ParquetSink",
"storeSettings":{
"type": "AzureBlobStorageWriteSettings",
"copyBehavior": "PreserveHierarchy",
"metadata": [
{
"name": "testKey1",
"value": "value1"
},
{
"name": "testKey2",
"value": "value2"
},
{
"name": "lastModifiedKey",
"value": "$$LASTMODIFIED"
}
]
}
}
}
}
]
Exempel på mapp- och filfilter
I det här avsnittet beskrivs det resulterande beteendet för mappsökvägen och filnamnet med jokerteckenfilter.
| folderPath | fileName | rekursiv | Källmappens struktur och filterresultat (filer i fetstil hämtas) |
|---|---|---|---|
container/Folder* |
(tom, använd standard) | falskt | container MappA File1.csv File2.json Undermapp1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
container/Folder* |
(tom, använd standard) | true | container MappA File1.csv File2.json Undermapp1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
container/Folder* |
*.csv |
falskt | container MappA File1.csv File2.json Undermapp1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
container/Folder* |
*.csv |
true | container MappA File1.csv File2.json Undermapp1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Exempel på fillista
I det här avsnittet beskrivs det resulterande beteendet med att använda en sökväg för en fillista i kopieringsaktivitetskällan.
Anta att du har följande källmappstruktur och vill kopiera filerna i fetstil:
| Exempel på källstruktur | Innehåll i FileListToCopy.txt | Konfiguration |
|---|---|---|
| container MappA File1.csv File2.json Undermapp1 File3.csv File4.json File5.csv Metadata FileListToCopy.txt |
File1.csv Undermapp1/File3.csv Undermapp1/File5.csv |
I datauppsättning: -Behållare: container– Mappsökväg: FolderAI Kopieringsaktivitetskälla: – Sökväg till fillista: container/Metadata/FileListToCopy.txt Sökvägen till fillistan pekar på en textfil i samma datalager som innehåller en lista över filer som du vill kopiera. Den innehåller en fil per rad, med den relativa sökvägen till sökvägen som konfigurerats i datauppsättningen. |
Några rekursiva och copyBehavior-exempel
I det här avsnittet beskrivs det resulterande beteendet för kopieringsåtgärden för olika kombinationer av rekursiva och copyBehavior-värden .
| rekursiv | copyBehavior | Källmappsstruktur | Resulterande mål |
|---|---|---|---|
| true | preserveHierarchy | Mapp1 Fil1 Fil 2 Undermapp1 Fil 3 Fil 4 Fil5 |
Målmappen Mapp1 skapas med samma struktur som källan: Mapp1 Fil1 Fil 2 Undermapp1 Fil 3 Fil 4 Fil5 |
| true | flatHierarchy | Mapp1 Fil1 Fil 2 Undermapp1 Fil 3 Fil 4 Fil5 |
Målmappen Mapp1 skapas med följande struktur: Mapp1 autogenererat namn för File1 autogenererat namn för File2 autogenererat namn för File3 autogenererat namn för File4 autogenererat namn för File5 |
| true | mergeFiles | Mapp1 Fil1 Fil 2 Undermapp1 Fil 3 Fil 4 Fil5 |
Målmappen Mapp1 skapas med följande struktur: Mapp1 File1 + File2 + File3 + File4 + File5-innehåll sammanfogas i en fil med ett automatiskt genererat filnamn. |
| falskt | preserveHierarchy | Mapp1 Fil1 Fil 2 Undermapp1 Fil 3 Fil 4 Fil5 |
Målmappen Mapp1 skapas med följande struktur: Mapp1 Fil1 Fil 2 Undermapp1 med File3, File4 och File5 hämtas inte. |
| falskt | flatHierarchy | Mapp1 Fil1 Fil 2 Undermapp1 Fil 3 Fil 4 Fil5 |
Målmappen Mapp1 skapas med följande struktur: Mapp1 autogenererat namn för File1 autogenererat namn för File2 Undermapp1 med File3, File4 och File5 hämtas inte. |
| falskt | mergeFiles | Mapp1 Fil1 Fil 2 Undermapp1 Fil 3 Fil 4 Fil5 |
Målmappen Mapp1 skapas med följande struktur: Mapp1 Fil1 + Fil2-innehåll sammanfogas i en fil med ett automatiskt genererat filnamn. autogenererat namn för File1 Undermapp1 med File3, File4 och File5 hämtas inte. |
Bevara metadata under kopiering
När du kopierar filer från Amazon S3, Azure Blob Storage eller Azure Data Lake Storage Gen2 till Azure Data Lake Storage Gen2 eller Azure Blob Storage kan du välja att bevara filmetadata tillsammans med data. Läs mer från Bevara metadata.
Mappa dataflödesegenskaper
När du transformerar data i mappning av dataflöden kan du läsa och skriva filer från Azure Blob Storage i följande format:
Formatspecifika inställningar finns i dokumentationen för det formatet. Mer information finns i Källtransformering i mappning av dataflöde och Sink-transformering i mappning av dataflöde.
Källtransformering
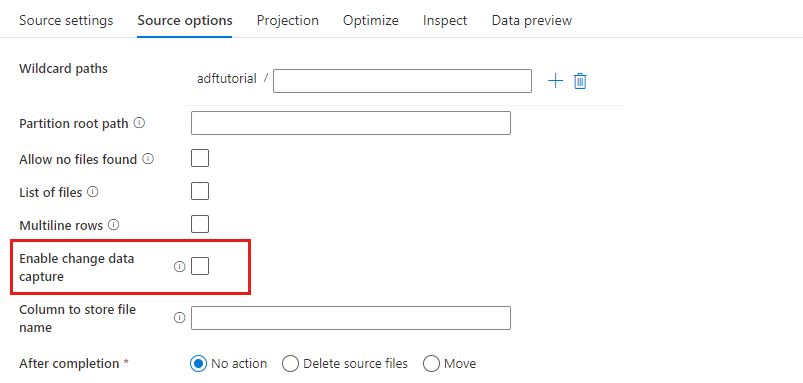
I källtransformeringen kan du läsa från en container, mapp eller enskild fil i Azure Blob Storage. Använd fliken Källalternativ för att hantera hur filerna läss.
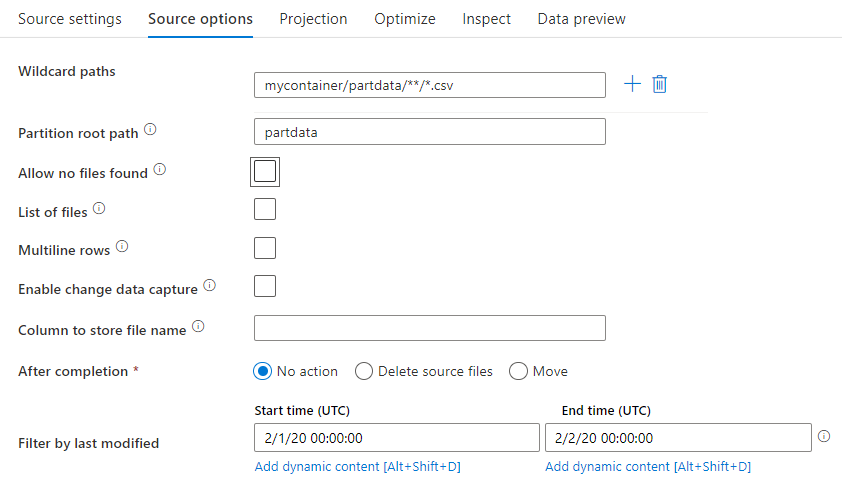
Sökvägar med jokertecken: Om du använder ett jokerteckensmönster instrueras tjänsten att loopa igenom varje matchande mapp och fil i en enda källtransformering. Det här är ett effektivt sätt att bearbeta flera filer i ett enda flöde. Lägg till flera matchande mönster med jokertecken med plustecknet som visas när du hovrar över ditt befintliga jokerteckenmönster.
Från källcontainern väljer du en serie filer som matchar ett mönster. Endast en container kan anges i datauppsättningen. Sökvägen till jokertecknet måste därför även innehålla mappsökvägen från rotmappen.
Jokerteckenexempel:
*Representerar alla teckenuppsättningar.**Representerar rekursiv katalogkapsling.?Ersätter ett tecken.[]Matchar ett eller flera tecken inom hakparenteserna./data/sales/**/*.csvHämtar alla .csv filer under /data/försäljning./data/sales/20??/**/Hämtar alla filer på 1900-talet./data/sales/*/*/*.csvHämtar .csv filer två nivåer under /data/försäljning./data/sales/2004/*/12/[XY]1?.csvHämtar alla .csv filer i december 2004 med X- eller Y-prefixet med ett tvåsiffrigt tal.
Partitionsrotsökväg: Om du har partitionerade mappar i filkällan med ett key=value format (till exempel year=2019), kan du tilldela den översta nivån i partitionsmappsträdet till ett kolumnnamn i dataflödets dataström.
Ange först ett jokertecken för att inkludera alla sökvägar som är de partitionerade mapparna plus lövfilerna som du vill läsa.
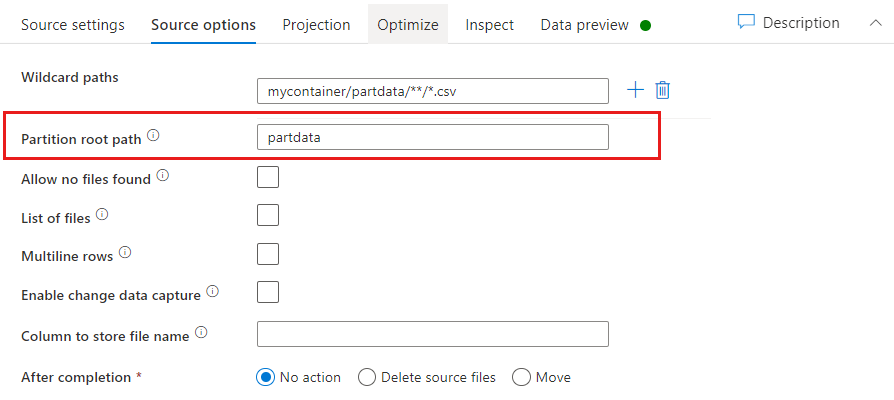
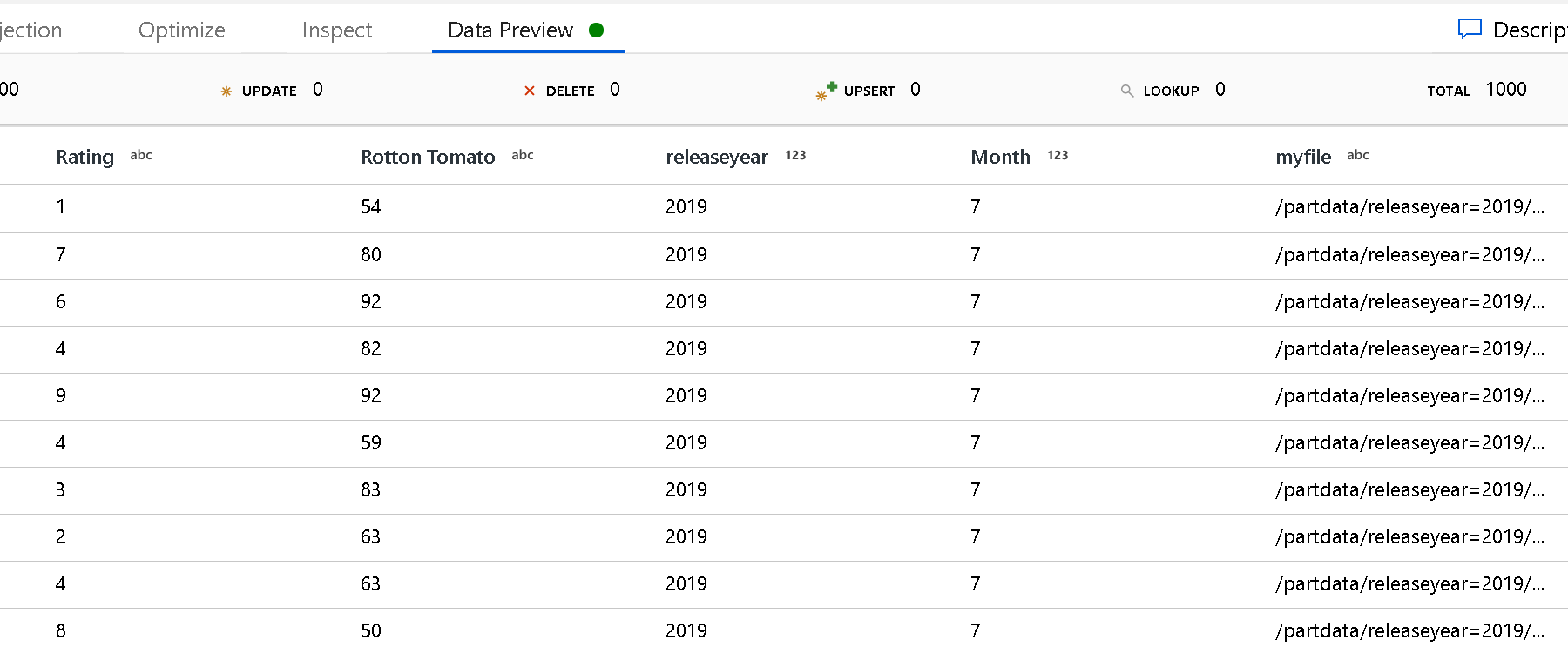
Använd inställningen Partitionsrotsökväg för att definiera vad mappstrukturens översta nivå är. När du visar innehållet i dina data via en förhandsversion av data ser du att tjänsten lägger till de lösta partitionerna som finns på var och en av dina mappnivåer.
Lista över filer: Det här är en filuppsättning. Skapa en textfil som innehåller en lista över relativa sökvägsfiler som ska bearbetas. Peka på den här textfilen.
Kolumn för lagring av filnamn: Lagra namnet på källfilen i en kolumn i dina data. Ange ett nytt kolumnnamn här för att lagra filnamnssträngen.
Efter slutförande: Välj att inte göra något med källfilen när dataflödet har körts, ta bort källfilen eller flytta källfilen. Sökvägarna för flytten är relativa.
Om du vill flytta källfiler till en annan plats efter bearbetningen väljer du först "Flytta" för filåtgärd. Ange sedan katalogen "från". Om du inte använder några jokertecken för sökvägen är inställningen "från" samma mapp som källmappen.
Om du har en källsökväg med jokertecken är syntaxen följande:
/data/sales/20??/**/*.csv
Du kan ange "från" som:
/data/sales
Och du kan ange "till" som:
/backup/priorSales
I det här fallet flyttas alla filer som hämtades under /data/sales till /backup/priorSales.
Kommentar
Filåtgärder körs endast när du startar dataflödet från en pipelinekörning (en pipeline-felsökning eller körningskörning) som använder aktiviteten Kör dataflöde i en pipeline. Filåtgärder körs inte i felsökningsläge för dataflöde.
Filtrera efter senast ändrad: Du kan filtrera de filer som ska bearbetas genom att ange ett datumintervall för när de senast ändrades. Alla datetimes finns i UTC.
Aktivera insamling av ändringsdata: Om det är sant får du bara nya eller ändrade filer från den senaste körningen. Den första inläsningen av fullständiga ögonblicksbildsdata kommer alltid att hämtas i den första körningen, följt av att samla in nya eller ändrade filer endast i nästa körningar.
Egenskaper för mottagare
I mottagartransformeringen kan du skriva till antingen en container eller en mapp i Azure Blob Storage. Använd fliken Inställningar för att hantera hur filerna skrivs.
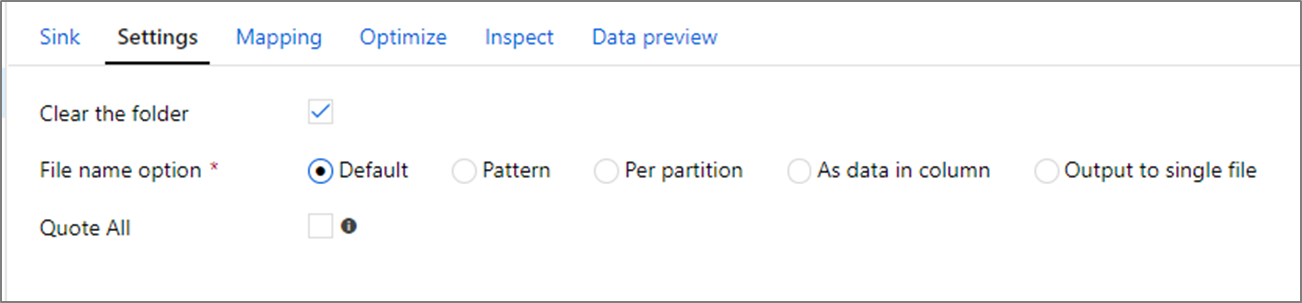
Rensa mappen: Avgör om målmappen rensas innan data skrivs.
Filnamnsalternativ: Avgör hur målfilerna namnges i målmappen. Filnamnsalternativen är:
- Standard: Tillåt att Spark namnger filer baserat på standardvärden för PART.
- Mönster: Ange ett mönster som räknar upp utdatafilerna per partition. Skapar till exempel
loans[n].csvloans1.csv,loans2.csvoch så vidare. - Per partition: Ange ett filnamn per partition.
- Som data i kolumnen: Ange utdatafilen till värdet för en kolumn. Sökvägen är relativ till datamängdscontainern, inte målmappen. Om du har en mappsökväg i datauppsättningen åsidosättas den.
- Utdata till en enda fil: Kombinera de partitionerade utdatafilerna till en enda namngiven fil. Sökvägen är relativ till datamängdsmappen. Tänk på att kopplingsåtgärden eventuellt kan misslyckas baserat på nodstorleken. Vi rekommenderar inte det här alternativet för stora datamängder.
Citattecken alla: Avgör om alla värden ska omslutas inom citattecken.
Egenskaper för uppslagsaktivitet
Mer information om egenskaperna finns i Sökningsaktivitet.
Egenskaper för GetMetadata-aktivitet
Mer information om egenskaperna finns i GetMetadata-aktiviteten.
Ta bort aktivitetsegenskaper
Information om egenskaperna finns i Ta bort aktivitet.
Äldre modeller
Kommentar
Följande modeller stöds fortfarande, precis som för bakåtkompatibilitet. Vi rekommenderar att du använder den nya modellen som nämnts tidigare. Redigeringsgränssnittet har växlat till att generera den nya modellen.
Äldre datauppsättningsmodell
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Egenskapen type för datamängden måste vara inställd på AzureBlob. |
Ja |
| folderPath | Sökväg till containern och mappen i Blob Storage. Ett jokerteckenfilter stöds för sökvägen, exklusive containernamn. Tillåtna jokertecken är: * (matchar noll eller fler tecken) och ? (matchar noll eller enskilt tecken). Använd ^ för att fly om mappnamnet har ett jokertecken eller det här escape-tecknet inuti. Ett exempel är: myblobcontainer/myblobfolder/. Se fler exempel i exempel på mapp- och filfilter. |
Ja för aktiviteten Kopiera eller Uppslag, Nej för Aktiviteten GetMetadata |
| fileName | Namn- eller jokerteckenfilter för blobarna under det angivna folderPath värdet. Om du inte anger något värde för den här egenskapen pekar datauppsättningen på alla blobar i mappen. För filtret är tillåtna jokertecken: * (matchar noll eller fler tecken) och ? (matchar noll eller enskilt tecken).- Exempel 1: "fileName": "*.csv"- Exempel 2: "fileName": "???20180427.txt"Använd ^ för att fly om filnamnet har ett jokertecken eller det här escape-tecknet inuti.När fileName inte har angetts för en utdatauppsättning och preserveHierarchy inte anges i aktivitetsmottagaren genererar kopieringsaktiviteten automatiskt blobnamnet med följande mönster: "Data.[ aktivitetskörnings-ID GUID]. [GUID om FlatHierarchy]. [format om det är konfigurerat]. [komprimering om den är konfigurerad]". Exempel: "Data.0a405f8a-93ff-4c6f-b3be-f69616f1df7a.txt.gz". Om du kopierar från en tabellkälla med hjälp av ett tabellnamn i stället för en fråga är [table name].[format].[compression if configured]namnmönstret . Exempel: "MyTable.csv". |
Nej |
| modifiedDatetimeStart | Filer filtreras baserat på attributet: senast ändrad. Filerna väljs om deras senaste ändringstid är större än eller lika med modifiedDatetimeStart och mindre än modifiedDatetimeEnd. Tiden tillämpas på UTC-tidszonen i formatet "2018-12-01T05:00:00Z". Tänk på att aktivering av den här inställningen påverkar den övergripande prestandan för dataflytt när du vill filtrera stora mängder filer. Egenskaperna kan vara NULL, vilket innebär att inget filattributfilter tillämpas på datamängden. När modifiedDatetimeStart har ett datetime-värde men modifiedDatetimeEnd är NULL, väljs de filer vars senast ändrade attribut är större än eller lika med datetime-värdet. När modifiedDatetimeEnd har ett datetime-värde men modifiedDatetimeStart är NULL, väljs de filer vars senast ändrade attribut är mindre än datetime-värdet. |
Nej |
| modifiedDatetimeEnd | Filer filtreras baserat på attributet: senast ändrad. Filerna väljs om deras senaste ändringstid är större än eller lika med modifiedDatetimeStart och mindre än modifiedDatetimeEnd. Tiden tillämpas på UTC-tidszonen i formatet "2018-12-01T05:00:00Z". Tänk på att aktivering av den här inställningen påverkar den övergripande prestandan för dataflytt när du vill filtrera stora mängder filer. Egenskaperna kan vara NULL, vilket innebär att inget filattributfilter tillämpas på datamängden. När modifiedDatetimeStart har ett datetime-värde men modifiedDatetimeEnd är NULL, väljs de filer vars senast ändrade attribut är större än eller lika med datetime-värdet. När modifiedDatetimeEnd har ett datetime-värde men modifiedDatetimeStart är NULL, väljs de filer vars senast ändrade attribut är mindre än datetime-värdet. |
Nej |
| format | Om du vill kopiera filer som de är mellan filbaserade lager (binär kopia) hoppar du över formatavsnittet i både indata- och utdatauppsättningsdefinitionerna. Om du vill parsa eller generera filer med ett visst format stöds följande filformattyper: TextFormat, JsonFormat, AvroFormat, OrcFormat och ParquetFormat. Ange typegenskapen under format till ett av dessa värden. Mer information finns i avsnitten Textformat, JSON-format, Avro-format, Orc-format och Parquet-format . |
Nej (endast för scenario med binär kopiering) |
| komprimering | Ange typ och komprimeringsnivå för data. Mer information finns i Filformat som stöds och komprimeringskodex. Typer som stöds är GZip, Deflate, BZip2 och ZipDeflate. Nivåerna som stöds är optimala och snabbaste. |
Nej |
Dricks
Om du vill kopiera alla blobar under en mapp anger du endast folderPath .
Om du vill kopiera en enskild blob med ett angivet namn anger du folderPath för mappdelen och fileName som filnamn.
Om du vill kopiera en delmängd blobar under en mapp anger du folderPath för mappdelen och fileName med ett jokerteckenfilter.
Exempel:
{
"name": "AzureBlobDataset",
"properties": {
"type": "AzureBlob",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"fileName": "*",
"modifiedDatetimeStart": "2018-12-01T05:00:00Z",
"modifiedDatetimeEnd": "2018-12-01T06:00:00Z",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
Äldre källmodell för kopieringsaktiviteten
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Egenskapen type för kopieringsaktivitetskällan måste vara inställd på BlobSource. |
Ja |
| rekursiv | Anger om data läse rekursivt från undermapparna eller endast från den angivna mappen. När recursive är inställt på true och mottagaren är ett filbaserat arkiv kopieras inte en tom mapp eller undermapp i mottagaren.Tillåtna värden är true (standard) och false. |
Nej |
| maxConcurrentConnections | Den övre gränsen för samtidiga anslutningar som upprättats till datalagret under aktivitetskörningen. Ange endast ett värde när du vill begränsa samtidiga anslutningar. | Nej |
Exempel:
"activities":[
{
"name": "CopyFromBlob",
"type": "Copy",
"inputs": [
{
"referenceName": "<Azure Blob input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "BlobSource",
"recursive": true
},
"sink": {
"type": "<sink type>"
}
}
}
]
Äldre mottagarmodell för kopieringsaktiviteten
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Egenskapen type för kopieringsaktivitetsmottagaren måste vara inställd på BlobSink. |
Ja |
| copyBehavior | Definierar kopieringsbeteendet när källan är filer från ett filbaserat datalager. Tillåtna värden är: – PreserveHierarchy (standard): Bevarar filhierarkin i målmappen. Den relativa sökvägen för källfilen till källmappen är identisk med den relativa sökvägen för målfilen till målmappen. – FlattenHierarchy: Alla filer från källmappen finns på den första nivån i målmappen. Målfilerna har automatiskt genererade namn. – MergeFiles: Sammanfogar alla filer från källmappen till en fil. Om filen eller blobnamnet anges är det kopplade filnamnet det angivna namnet. Annars är det ett automatiskt genererat filnamn. |
Nej |
| maxConcurrentConnections | Den övre gränsen för samtidiga anslutningar som upprättats till datalagret under aktivitetskörningen. Ange endast ett värde när du vill begränsa samtidiga anslutningar. | Nej |
Exempel:
"activities":[
{
"name": "CopyToBlob",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure Blob output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "BlobSink",
"copyBehavior": "PreserveHierarchy"
}
}
}
]
Registrering av ändringsdata
Azure Data Factory kan bara hämta nya eller ändrade filer från Azure Blob Storage genom att aktivera **Aktivera insamling av ändringsdata ** i mappning av dataflödeskällans omvandling. Med det här anslutningsalternativet kan du bara läsa nya eller uppdaterade filer och tillämpa transformeringar innan du läser in omvandlade data till valfria måldatauppsättningar. Mer information finns i Ändra datainsamling .
Relaterat innehåll
En lista över datalager som kopieringsaktiviteten stöder som källor och mottagare finns i Datalager som stöds.