Använda Azure Data Factory för att migrera data från en lokal Netezza-server till Azure
GÄLLER FÖR:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Azure Data Factory tillhandahåller en högpresterande, robust och kostnadseffektiv mekanism för att migrera data i stor skala från en lokal Netezza-server till ditt Azure Storage-konto eller Azure Synapse Analytics-databas.
Den här artikeln innehåller följande information för datatekniker och utvecklare:
- Föreställning
- Kopiera motståndskraft
- Nätverkssäkerhet
- Arkitektur för högnivålösningar
- Metodtips för implementering
Prestanda
Azure Data Factory erbjuder en serverlös arkitektur som möjliggör parallellitet på olika nivåer. Om du är utvecklare innebär det att du kan skapa pipelines för att fullt ut använda både nätverks- och databasbandbredd för att maximera dataflyttens dataflöde för din miljö.
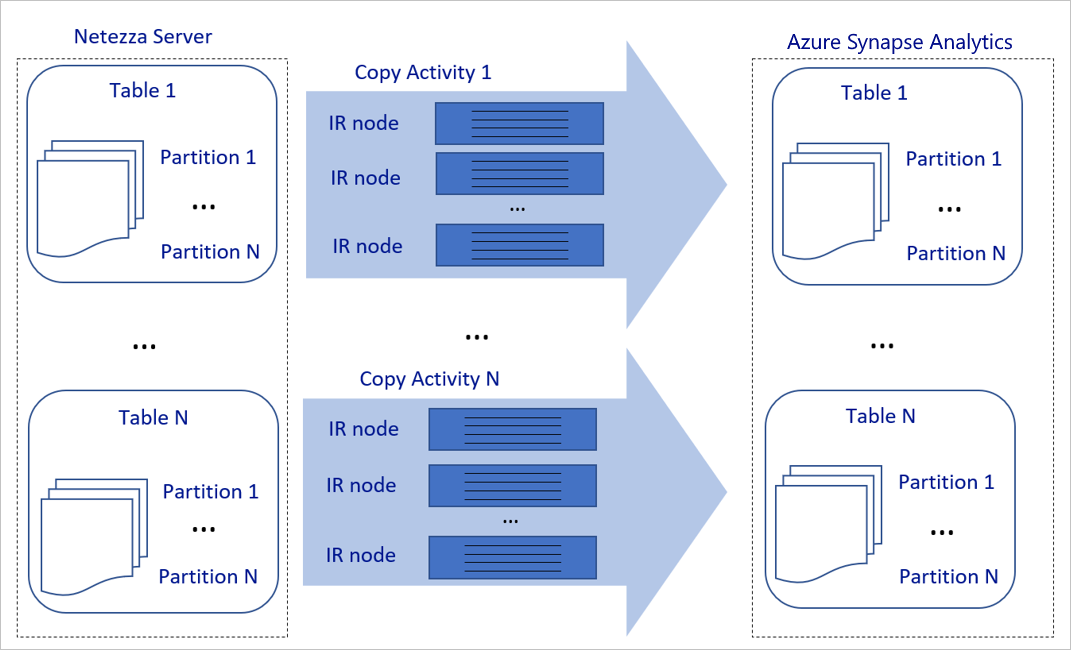
Föregående diagram kan tolkas på följande sätt:
En enskild kopieringsaktivitet kan dra nytta av skalbara beräkningsresurser. När du använder Azure Integration Runtime kan du ange upp till 256 DIUs för varje kopieringsaktivitet på ett serverlöst sätt. Med en lokalt installerad integrationskörning (lokalt installerad IR) kan du manuellt skala upp datorn eller skala ut till flera datorer (upp till fyra noder) och en enda kopieringsaktivitet distribuerar partitionen över alla noder.
En enskild kopieringsaktivitet läser från och skriver till datalagret med hjälp av flera trådar.
Azure Data Factory-kontrollflödet kan starta flera kopieringsaktiviteter parallellt. Den kan till exempel starta dem med hjälp av en For Each-loop.
Mer information finns i guiden Kopiera aktivitetsprestanda och skalbarhet.
Elasticitet
I en enda kopieringsaktivitet har Azure Data Factory en inbyggd återförsöksmekanism som gör att den kan hantera en viss nivå av tillfälliga fel i datalager eller i det underliggande nätverket.
Med Azure Data Factory-kopieringsaktivitet har du två sätt att hantera inkompatibla rader när du kopierar data mellan käll- och mottagardatalager. Du kan antingen avbryta och misslyckas med kopieringsaktiviteten eller fortsätta att kopiera resten av data genom att hoppa över de inkompatibla dataraderna. Om du vill veta orsaken till felet kan du dessutom logga de inkompatibla raderna i Azure Blob Storage eller Azure Data Lake Store, åtgärda data på datakällan och försöka kopiera igen.
Nätverkssäkerhet
Som standard överför Azure Data Factory data från den lokala Netezza-servern till ett Azure-lagringskonto eller Azure Synapse Analytics-databas med hjälp av en krypterad anslutning via Hypertext Transfer Protocol Secure (HTTPS). HTTPS tillhandahåller datakryptering under överföring och förhindrar avlyssning och man-in-the-middle-attacker.
Om du inte vill att data ska överföras via det offentliga Internet kan du också uppnå högre säkerhet genom att överföra data via en privat peeringlänk via Azure Express Route.
I nästa avsnitt beskrivs hur du uppnår högre säkerhet.
Lösningsarkitekturen
I det här avsnittet beskrivs två sätt att migrera dina data.
Migrera data via det offentliga Internet
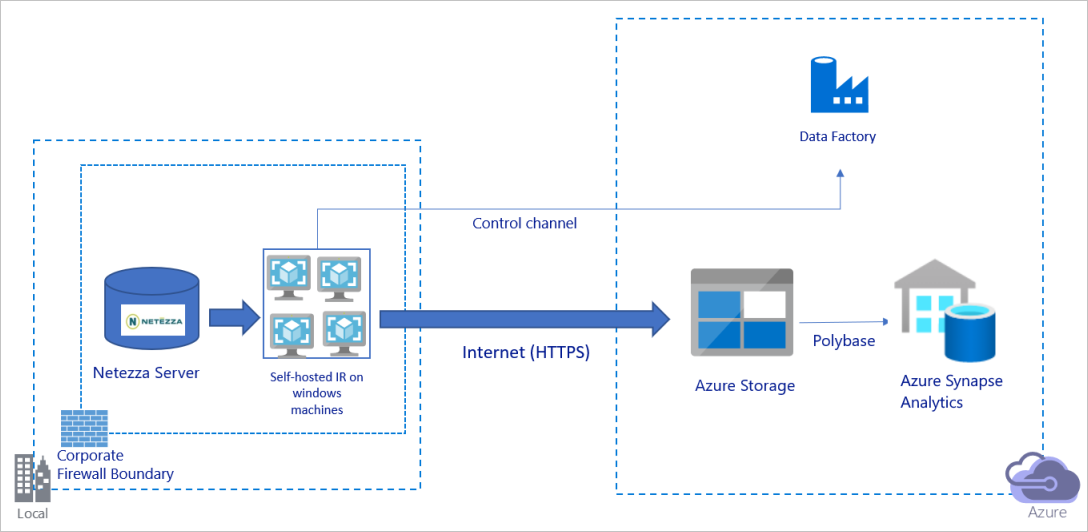
Föregående diagram kan tolkas på följande sätt:
I den här arkitekturen överför du data på ett säkert sätt med hjälp av HTTPS via det offentliga Internet.
För att uppnå den här arkitekturen måste du installera Azure Data Factory-integreringskörningen (lokalt installerad) på en Windows-dator bakom en företagsbrandvägg. Kontrollera att den här integreringskörningen har direkt åtkomst till Netezza-servern. Om du vill använda nätverket och datalagringsbandbredden till att kopiera data kan du skala upp datorn manuellt eller skala ut till flera datorer.
Med hjälp av den här arkitekturen kan du migrera både initiala ögonblicksbildsdata och deltadata.
Migrera data via ett privat nätverk
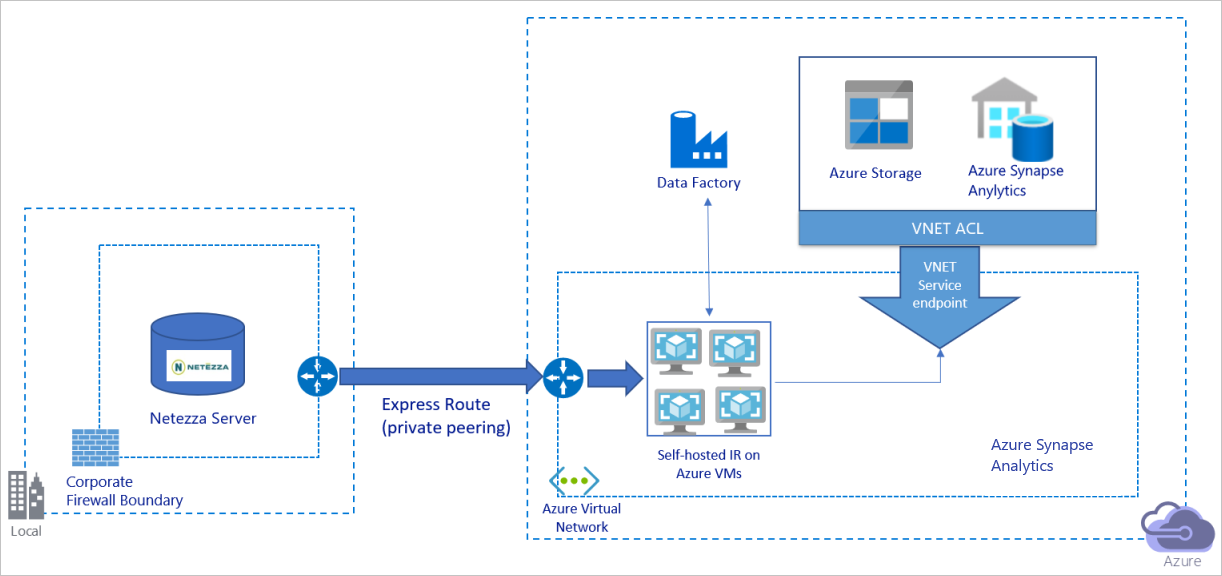
Föregående diagram kan tolkas på följande sätt:
I den här arkitekturen migrerar du data via en privat peeringlänk via Azure Express Route och data passerar aldrig via det offentliga Internet.
För att uppnå den här arkitekturen måste du installera Azure Data Factory-integreringskörningen (lokalt installerad) på en virtuell Windows-dator (VM) i ditt virtuella Azure-nätverk. Om du vill använda bandbredden för nätverket och datalagringen till att kopiera data kan du skala upp den virtuella datorn manuellt eller skala ut till flera virtuella datorer.
Med hjälp av den här arkitekturen kan du migrera både initiala ögonblicksbildsdata och deltadata.
Implementera metodtips
Hantera autentisering och autentiseringsuppgifter
Om du vill autentisera till Netezza kan du använda ODBC-autentisering via niska veze.
Så här autentiserar du till Azure Blob Storage:
Vi rekommenderar starkt att du använder hanterade identiteter för Azure-resurser. Hanterade identiteter bygger på en automatiskt hanterad Azure Data Factory-identitet i Microsoft Entra-ID och gör att du kan konfigurera pipelines utan att behöva ange autentiseringsuppgifter i definitionen för länkad tjänst.
Du kan också autentisera till Azure Blob Storage med tjänstens huvudnamn, en signatur för delad åtkomst eller en lagringskontonyckel.
Så här autentiserar du till Azure Data Lake Storage Gen2:
Vi rekommenderar starkt att du använder hanterade identiteter för Azure-resurser.
Du kan också använda tjänstens huvudnamn eller en lagringskontonyckel.
Så här autentiserar du till Azure Synapse Analytics:
Vi rekommenderar starkt att du använder hanterade identiteter för Azure-resurser.
Du kan också använda tjänstens huvudnamn eller SQL-autentisering.
När du inte använder hanterade identiteter för Azure-resurser rekommenderar vi starkt att du lagrar autentiseringsuppgifterna i Azure Key Vault för att göra det enklare att centralt hantera och rotera nycklar utan att behöva ändra länkade Azure Data Factory-tjänster. Detta är också en av metodtipsen för CI/CD.
Migrera initiala ögonblicksbilddata
För små tabeller (dvs. tabeller med en volym på mindre än 100 GB eller som kan migreras till Azure inom två timmar) kan du göra så att varje kopieringsjobb läser in data per tabell. För större dataflöde kan du köra flera Azure Data Factory-kopieringsjobb för att läsa in separata tabeller samtidigt.
För att köra parallella frågor och kopiera data efter partitioner i varje kopieringsjobb kan du också nå en viss nivå av parallellitet genom att använda egenskapsinställningen parallelCopies med något av följande alternativ för datapartition:
För att få bättre effektivitet rekommenderar vi att du börjar från en datasektor. Kontrollera att värdet i
parallelCopiesinställningen är mindre än det totala antalet partitioner för datasektorer i tabellen på Netezza-servern.Om volymen för varje datasektorpartition fortfarande är stor (till exempel 10 GB eller större) rekommenderar vi att du växlar till en partition med dynamiskt intervall. Det här alternativet ger dig större flexibilitet att definiera antalet partitioner och volymen för varje partition efter partitionskolumn, övre gräns och nedre gräns.
För större tabeller (dvs. tabeller med en volym på 100 GB eller större eller som inte kan migreras till Azure inom två timmar) rekommenderar vi att du partitionerade data efter anpassad fråga och sedan gör varje kopieringsjobb kopiera en partition i taget. För bättre dataflöde kan du köra flera Azure Data Factory-kopieringsjobb samtidigt. För varje kopieringsjobbsmål för inläsning av en partition efter anpassad fråga kan du öka dataflödet genom att aktivera parallellitet via antingen datasektor eller dynamiskt intervall.
Om ett kopieringsjobb misslyckas på grund av ett tillfälligt problem med nätverket eller datalagret kan du köra det misslyckade kopieringsjobbet igen för att läsa in den specifika partitionen från tabellen igen. Andra kopieringsjobb som läser in andra partitioner påverkas inte.
När du läser in data i en Azure Synapse Analytics-databas föreslår vi att du aktiverar PolyBase i kopieringsjobbet med Azure Blob Storage som mellanlagring.
Migrera deltadata
Om du vill identifiera de nya eller uppdaterade raderna från tabellen använder du en tidsstämpelkolumn eller en inkrementell nyckel i schemat. Du kan sedan lagra det senaste värdet som en högvattenstämpel i en extern tabell och sedan använda det för att filtrera deltadata nästa gång du läser in data.
Varje tabell kan använda en annan vattenstämpelkolumn för att identifiera sina nya eller uppdaterade rader. Vi rekommenderar att du skapar en extern kontrolltabell. I tabellen representerar varje rad en tabell på Netezza-servern med dess specifika kolumnnamn för vattenstämpel och högt vattenstämpelvärde.
Konfigurera en lokalt installerad integrationskörning
Om du migrerar data från Netezza-servern till Azure, oavsett om servern finns lokalt bakom företagets brandvägg eller i en virtuell nätverksmiljö, måste du installera en lokalt installerad IR på en Windows-dator eller virtuell dator, som är den motor som används för att flytta data. När du installerar den lokalt installerade IR:en rekommenderar vi följande metod:
För varje Windows-dator eller virtuell dator börjar du med en konfiguration på 32 vCPU och 128 GB minne. Du kan fortsätta att övervaka processor- och minnesanvändningen för IR-datorn under datamigreringen för att se om du behöver skala upp datorn ytterligare för bättre prestanda eller skala ned datorn för att spara kostnader.
Du kan också skala ut genom att associera upp till fyra noder med en enda lokalt installerad IR. Ett enda kopieringsjobb som körs mot en lokalt installerad IR tillämpar automatiskt alla VM-noder för att kopiera data parallellt. För hög tillgänglighet börjar du med fyra VM-noder för att undvika en felpunkt under datamigreringen.
Begränsa dina partitioner
Vi rekommenderar att du utför ett konceptbevis för prestanda (POC) med en representativ exempeldatauppsättning, så att du kan fastställa en lämplig partitionsstorlek för varje kopieringsaktivitet. Vi rekommenderar att du läser in varje partition till Azure inom två timmar.
Om du vill kopiera en tabell börjar du med en enda kopieringsaktivitet med en enda IR-dator med egen värd. Öka parallelCopies inställningen gradvis baserat på antalet partitioner för datasektorer i tabellen. Se om hela tabellen kan läsas in till Azure inom två timmar, enligt dataflödet som är resultatet av kopieringsjobbet.
Om den inte kan läsas in till Azure inom två timmar och kapaciteten för den lokalt installerade IR-noden och datalagret inte används fullt ut ökar du gradvis antalet samtidiga kopieringsaktiviteter tills du når gränsen för nätverket eller bandbreddsgränsen för datalagren.
Fortsätt att övervaka processor- och minnesanvändningen på den lokalt installerade IR-datorn och var redo att skala upp datorn eller skala ut till flera datorer när du ser att processorn och minnet används fullt ut.
När du stöter på begränsningsfel, som rapporterats av Azure Data Factory-kopieringsaktiviteten, kan du antingen minska samtidigheten eller parallelCopies inställningen i Azure Data Factory, eller överväga att öka IOPS-gränserna (bandbredd eller I/O-åtgärder per sekund) för nätverket och datalager.
Beräkna din prissättning
Tänk på följande pipeline, som är konstruerad för att migrera data från den lokala Netezza-servern till en Azure Synapse Analytics-databas:
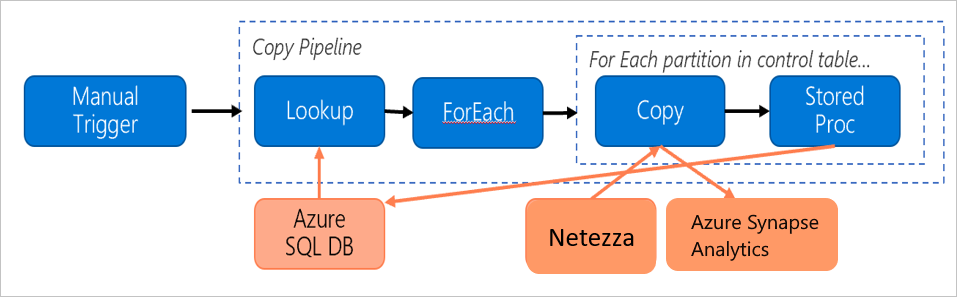
Anta att följande påståenden är sanna:
Den totala datavolymen är 50 terabyte (TB).
Vi migrerar data med hjälp av arkitekturen för den första lösningen (Netezza-servern finns lokalt bakom brandväggen).
Volymen på 50 TB är uppdelad i 500 partitioner och varje kopieringsaktivitet flyttar en partition.
Varje kopieringsaktivitet konfigureras med en lokalt installerad IR mot fyra datorer och uppnår ett dataflöde på 20 megabyte per sekund (Mbit/s). (Inom kopieringsaktiviteten
parallelCopiesanges till 4 och varje tråd för att läsa in data från tabellen uppnår ett dataflöde på 5 Mbit/s.)ForEach-samtidigheten är inställd på 3 och det aggregerade dataflödet är 60 Mbit/s.
Totalt tar det 243 timmar att slutföra migreringen.
Baserat på de föregående antagandena är här det uppskattade priset:
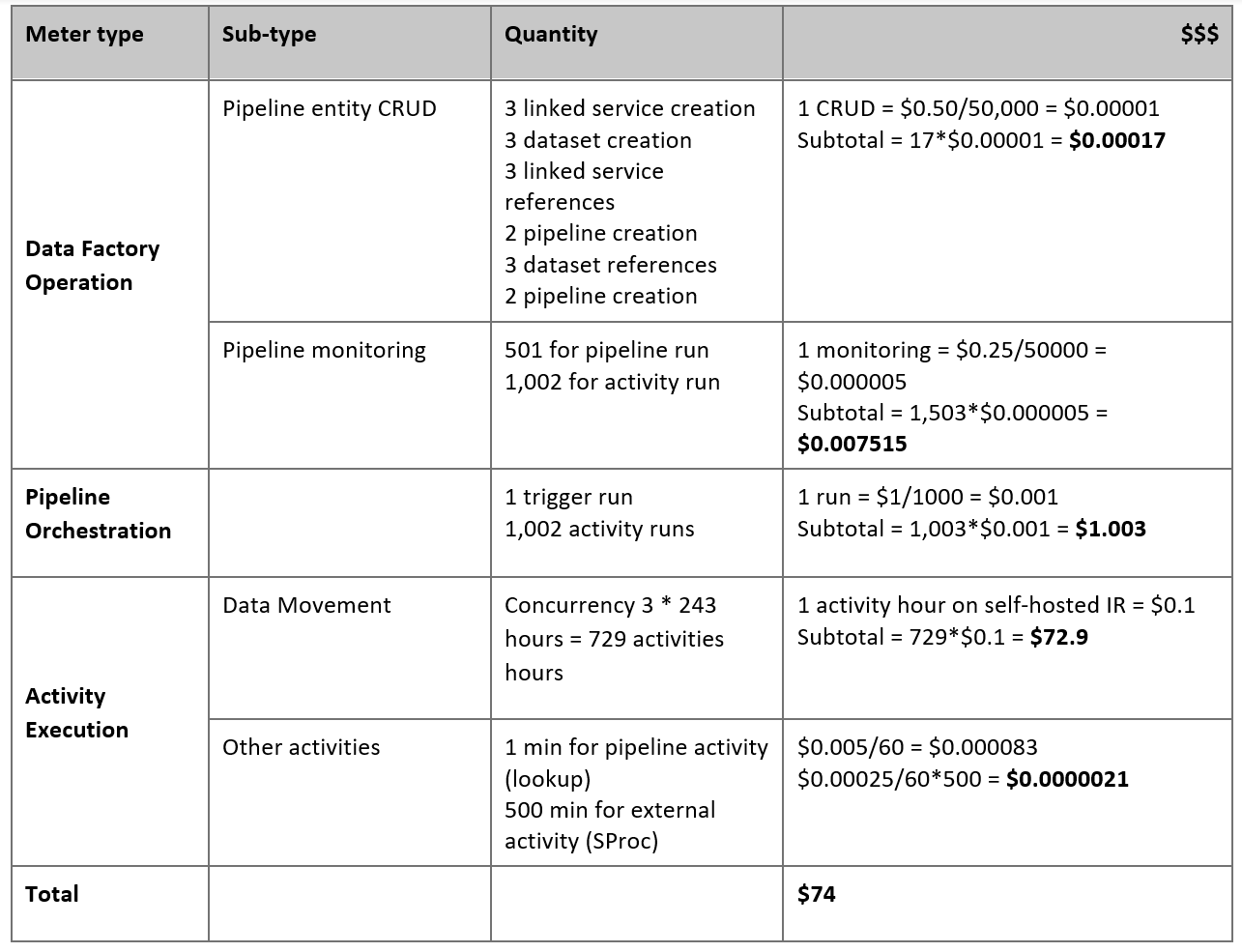
Kommentar
Prissättningen som visas i föregående tabell är hypotetisk. Din faktiska prissättning beror på det faktiska dataflödet i din miljö. Priset för Windows-datorn (med lokalt installerad IR) ingår inte.
Ytterligare referenser
Mer information finns i följande artiklar och guider:
- Netezza-anslutningsprogram
- ODBC-anslutningsprogram
- Azure Blob Storage-anslutningsprogram
- Azure Data Lake Storage Gen2-anslutningsprogram
- Azure Synapse Analytics-anslutningsprogram
- Prestandajusteringsguide för kopieringsaktivitet
- Skapa och konfigurera lokalt installerad integrationskörning
- Ha och skalbarhet för lokalt installerad integrationskörning
- Säkerhetsöverväganden för dataflytt
- Lagra autentiseringsuppgifter i Azure Key Vault
- Kopiera data stegvis från en tabell
- Kopiera data stegvis från flera tabeller
- Prissidan för Azure Data Factory
Relaterat innehåll
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för