Introduktion till Service Fabric-hälsoövervakning
Azure Service Fabric introducerar en hälsomodell som ger omfattande, flexibel och utökningsbar hälsoutvärdering och rapportering. Modellen tillåter nästan realtidsövervakning av klustrets tillstånd och de tjänster som körs i det. Du kan enkelt få hälsoinformation och korrigera potentiella problem innan de sprids och orsaka stora avbrott. I den typiska modellen skickar tjänster rapporter baserat på deras lokala vyer och den informationen aggregeras för att ge en övergripande vy på klusternivå.
Service Fabric-komponenter använder den här omfattande hälsomodellen för att rapportera sitt aktuella tillstånd. Du kan använda samma mekanism för att rapportera hälsotillstånd från dina program. Om du investerar i hälsorapportering av hög kvalitet som registrerar dina anpassade villkor kan du identifiera och åtgärda problem för ditt program som körs mycket enklare.
Kommentar
Vi startade hälsoundersystemet för att åtgärda behovet av övervakade uppgraderingar. Service Fabric tillhandahåller övervakade program- och klusteruppgraderingar som säkerställer full tillgänglighet, ingen stilleståndstid och minimala till inga användaråtgärder. För att uppnå dessa mål kontrollerar uppgraderingen hälsotillståndet baserat på konfigurerade uppgraderingsprinciper. En uppgradering kan bara fortsätta när hälsotillståndet respekterar önskade tröskelvärden. Annars återställs uppgraderingen automatiskt eller pausas för att ge administratörer en chans att åtgärda problemen. Mer information om programuppgraderingar finns i den här artikeln.
Hälsoarkiv
Hälsoarkivet behåller hälsorelaterad information om entiteter i klustret för enkel hämtning och utvärdering. Den implementeras som en service fabric-bevarad tillståndskänslig tjänst för att säkerställa hög tillgänglighet och skalbarhet. Hälsoarkivet är en del av programmet fabric:/System och är tillgängligt när klustret är igång.
Hälsoentiteter och hierarki
Hälsoentiteterna är ordnade i en logisk hierarki som samlar in interaktioner och beroenden mellan olika entiteter. Hälsoarkivet skapar automatiskt hälsoentiteter och hierarkier baserat på rapporter som tas emot från Service Fabric-komponenter.
Hälsoentiteterna speglar Service Fabric-entiteterna. (Entiteten hälsoprogram matchar till exempel en programinstans som distribuerats i klustret, medan entiteten hälsonod matchar en Service Fabric-klusternod.) Hälsohierarkin samlar in interaktionerna mellan systementiteterna och är grunden för avancerad hälsoutvärdering. Du kan lära dig mer om viktiga Service Fabric-begrepp i teknisk översikt över Service Fabric. Mer information om program finns i Service Fabric-programmodellen.
Hälsoentiteterna och hierarkin gör att klustret och programmen effektivt kan rapporteras, debuggas och övervakas. Hälsomodellen ger en exakt, detaljerad representation av hälsotillståndet för de många rörliga delarna i klustret.
 Hälsoentiteterna, ordnade i en hierarki baserat på överordnade och underordnade relationer.
Hälsoentiteterna, ordnade i en hierarki baserat på överordnade och underordnade relationer.
Hälsoentiteterna är:
- Kluster. Representerar hälsotillståndet för ett Service Fabric-kluster. Hälsorapporter för kluster beskriver villkor som påverkar hela klustret. Dessa villkor påverkar flera entiteter i klustret eller själva klustret. Baserat på villkoret kan reportern inte begränsa problemet till ett eller flera barn med feltillstånd. Exempel är klustrets hjärna som delas på grund av nätverkspartitionering eller kommunikationsproblem.
- Nod. Representerar hälsotillståndet för en Service Fabric-nod. Nodhälsorapporter beskriver villkor som påverkar nodfunktionen. De påverkar vanligtvis alla distribuerade entiteter som körs på den. Exempel är att noden har slut på diskutrymme (eller andra egenskaper för hela datorn, till exempel minne, anslutningar) och när en nod är nere. Nodentiteten identifieras med nodnamnet (strängen).
- Program. Representerar hälsotillståndet för en programinstans som körs i klustret. Hälsorapporter för program beskriver villkor som påverkar programmets allmänna hälsa. De kan inte begränsas till enskilda underordnade (tjänster eller distribuerade program). Exempel är interaktionen från slutpunkt till slutpunkt mellan olika tjänster i programmet. Programentiteten identifieras med programnamnet (URI).
- Tjänst. Representerar hälsotillståndet för en tjänst som körs i klustret. Ispravnost usluge rapporter beskriver villkor som påverkar tjänstens allmänna hälsa. Reportern kan inte begränsa problemet till en partition eller replik som inte är felfri. Exempel är en tjänstkonfiguration (till exempel port eller extern filresurs) som orsakar problem för alla partitioner. Tjänstentiteten identifieras av tjänstnamnet (URI).
- Partition. Representerar hälsotillståndet för en tjänstpartition. Hälsorapporter för partitioner beskriver villkor som påverkar hela replikuppsättningen. Exempel är när antalet repliker är under målantalet och när en partition är kvorumförlust. Partitionsentiteten identifieras av partitions-ID (GUID).
- Replik. Representerar hälsotillståndet för en tillståndskänslig tjänstreplik eller en tillståndslös tjänstinstans. Repliken är den minsta enhet som vakthundar och systemkomponenter kan rapportera om för ett program. Exempel för tillståndskänsliga tjänster är en primär replik som inte kan replikera åtgärder till sekundärfiler och långsam replikering. Dessutom kan en tillståndslös instans rapportera när resurserna tar slut eller har anslutningsproblem. Replikentiteten identifieras av partitions-ID (GUID) och replik- eller instans-ID :t (long).
- DeployedApplication. Representerar hälsotillståndet för ett program som körs på en nod. Distribuerade programhälsorapporter beskriver villkor som är specifika för programmet på noden som inte kan begränsas till tjänstpaket som distribueras på samma nod. Exempel är fel när programpaketet inte kan laddas ned på noden och problem med att konfigurera programsäkerhetsobjekt på noden. Det distribuerade programmet identifieras med programnamn (URI) och nodnamn (sträng).
- DeployedServicePackage. Representerar hälsotillståndet för ett tjänstpaket som körs på en nod i klustret. Den beskriver villkor som är specifika för ett tjänstpaket som inte påverkar de andra tjänstpaketen på samma nod för samma program. Exempel är ett kodpaket i tjänstpaketet som inte kan startas och ett konfigurationspaket som inte kan läsas. Det distribuerade tjänstpaketet identifieras med programnamn (URI), nodnamn (sträng), tjänstmanifestnamn (sträng) och aktiverings-ID för tjänstpaket (sträng).
Hälsomodellens kornighet gör det enkelt att identifiera och korrigera problem. Om en tjänst till exempel inte svarar är det möjligt att rapportera att programinstansen inte är felfri. Att rapportera på den nivån är dock inte idealiskt eftersom problemet kanske inte påverkar alla tjänster i programmet. Rapporten ska tillämpas på tjänsten som inte är felfri eller på en specifik underordnad partition, om mer information pekar på partitionen. Data visas automatiskt via hierarkin och en partition med fel visas på tjänst- och programnivå. Den här aggregeringen hjälper till att hitta och lösa rotorsaken till problemet snabbare.
Hälsohierarkin består av överordnade och underordnade relationer. Ett kluster består av noder och program. Program har tjänster och distribuerade program. Distribuerade program har distribuerat tjänstpaket. Tjänsterna har partitioner och varje partition har en eller flera repliker. Det finns en särskild relation mellan noder och distribuerade entiteter. En nod med feltillstånd som rapporteras av dess systemkomponent, redundanshanteraren, påverkar de distribuerade programmen, tjänstpaketen och replikerna som distribueras på den.
Hälsohierarkin representerar systemets senaste tillstånd baserat på de senaste hälsorapporterna, som nästan är realtidsinformation. Interna och externa vakthundar kan rapportera om samma entiteter baserat på programspecifik logik eller anpassade övervakade villkor. Användarrapporter samexisterar med systemrapporterna.
Planera att investera i hur du rapporterar och svarar på hälsa under utformningen av en stor molntjänst. Den här förskottsinvesteringen gör tjänsten enklare att felsöka, övervaka och använda.
Hälsotillstånd
Service Fabric använder tre hälsotillstånd för att beskriva om en entitet är felfri eller inte: OK, varning och fel. Alla rapporter som skickas till hälsoarkivet måste ange något av dessa tillstånd. Hälsoutvärderingsresultatet är ett av dessa tillstånd.
- OKEJ. Entiteten är felfri. Det finns inga kända problem rapporterade om den eller dess underordnade (i förekommande fall).
- Varning. Entiteten har vissa problem, men den kan fortfarande fungera korrekt. Det finns till exempel fördröjningar, men de orsakar inga funktionella problem ännu. I vissa fall kan varningsvillkoret åtgärda sig självt utan externa åtgärder. I dessa fall ökar hälsorapporterna medvetenheten och ger insyn i vad som händer. I andra fall kan varningsvillkoret försämras till ett allvarligt problem utan användarintervention.
- Fel. Entiteten är inte felfri. Åtgärder bör vidtas för att åtgärda tillståndet för entiteten eftersom den inte kan fungera korrekt.
- Okänt. Entiteten finns inte i hälsoarkivet. Det här resultatet kan hämtas från distribuerade frågor som sammanfogar resultat från flera komponenter. Till exempel går frågan hämta nodlista till FailoverManager, ClusterManager och HealthManager. Hämta programlistefråga går till ClusterManager och HealthManager. Dessa frågor slås samman resultat från flera systemkomponenter. Om en annan systemkomponent returnerar en entitet som inte finns i hälsoarkivet har det sammanslagna resultatet okänt hälsotillstånd. En entitet lagras inte eftersom hälsorapporter ännu inte har bearbetats eller entiteten har rensats efter borttagningen.
Hälsoprinciper
Hälsoarkivet tillämpar hälsoprinciper för att avgöra om en entitet är felfri baserat på dess rapporter och dess underordnade.
Kommentar
Hälsoprinciper kan anges i klustermanifestet (för utvärdering av kluster- och nodhälsa) eller i programmanifestet (för programutvärdering och någon av dess underordnade). Hälsoutvärderingsbegäranden kan också skickas i anpassade hälsoutvärderingsprinciper, som endast används för den utvärderingen.
Som standard tillämpar Service Fabric strikta regler (allt måste vara felfritt) för den överordnade-underordnade hierarkiska relationen. Om även ett av barnen har en felaktig händelse anses den överordnade vara inte felfri.
Hälsoprincip för kluster
Klustrets hälsoprincip används för att utvärdera klustrets hälsotillstånd och nodhälsotillstånd. Principen kan definieras i klustermanifestet. Om den inte finns används standardprincipen (noll tolererade fel).
Klustrets hälsoprincip innehåller:
ÖvervägWarningAsError. Anger om varningshälsorapporter ska behandlas som fel under hälsoutvärderingen. Standard: falskt.
MaxPercentUnhealthyApplications. Anger den maximala tillåtna procentandelen program som kan vara felfria innan klustret betraktas som fel.
MaxPercentUnhealthyNodes. Anger den maximala tillåtna procentandelen noder som kan vara felfria innan klustret betraktas som ett fel. I stora kluster är vissa noder alltid nere eller ute för reparationer, så den här procentandelen bör konfigureras för att tolerera det.
ApplicationTypeHealthPolicyMap. Mappningen för hälsoprincip för programtyp kan användas under utvärdering av klusterhälsa för att beskriva särskilda programtyper. Som standard placeras alla program i en pool och utvärderas med MaxPercentUnhealthyApplications. Om vissa programtyper ska behandlas annorlunda kan de tas bort från den globala poolen. I stället utvärderas de mot procentandelarna som är associerade med deras programtypsnamn på kartan. I ett kluster finns det till exempel tusentals program av olika typer och några kontrollprograminstanser av en särskild programtyp. Kontrollprogrammen får aldrig ha fel. Du kan ange globala MaxPercentUnhealthyApplications till 20 % för att tolerera vissa fel, men för programtypen "ControlApplicationType" anger du MaxPercentUnhealthyApplications till 0. På så sätt utvärderas klustret till Varning om några av de många programmen inte är felfria, men under den globala felprocenten. Ett varningstillstånd påverkar inte klusteruppgradering eller annan övervakning som utlöses av felhälsotillstånd. Men även ett kontrollprogram i fel skulle göra klustret felaktigt, vilket utlöser återställning eller pausar klusteruppgraderingen, beroende på uppgraderingskonfigurationen. För de programtyper som definieras på kartan tas alla programinstanser från den globala programpoolen. De utvärderas baserat på det totala antalet program av programtypen med hjälp av de specifika MaxPercentUnhealthyApplications från kartan. Alla övriga program finns kvar i den globala poolen och utvärderas med MaxPercentUnhealthyApplications.
Följande exempel är ett utdrag från ett klustermanifest. Om du vill definiera poster i programtypskartan prefixar du parameternamnet med "ApplicationTypeMaxPercentUnhealthyApplications-", följt av namnet på programtypen.
<FabricSettings> <Section Name="HealthManager/ClusterHealthPolicy"> <Parameter Name="ConsiderWarningAsError" Value="False" /> <Parameter Name="MaxPercentUnhealthyApplications" Value="20" /> <Parameter Name="MaxPercentUnhealthyNodes" Value="20" /> <Parameter Name="ApplicationTypeMaxPercentUnhealthyApplications-ControlApplicationType" Value="0" /> </Section> </FabricSettings>NodeTypeHealthPolicyMap. Mappningen av nodtypens hälsoprincip kan användas under utvärdering av klusterhälsa för att beskriva särskilda nodtyper. Nodtyperna utvärderas mot procentandelarna som är associerade med deras nodtypnamn på kartan. Inställningen av det här värdet påverkar inte den globala poolen med noder som används förMaxPercentUnhealthyNodes. Ett kluster har till exempel hundratals noder av olika typer och några nodtyper som är värdar för viktigt arbete. Inga noder i den typen ska vara nere. Du kan ange globalMaxPercentUnhealthyNodestill 20 % för att tolerera vissa fel för alla noder, men för nodtypenSpecialNodeTypeanger duMaxPercentUnhealthyNodestill 0. På så sätt, om några av de många noderna är felfria men under den globala felprocenten, utvärderas klustret som i tillståndet Varningshälsa. Ett varningstillstånd påverkar inte klusteruppgradering eller annan övervakning som utlöses av ett feltillstånd för hälsotillståndet. Men även en nod av typenSpecialNodeTypefeltillstånd skulle göra klustret inte felfri och utlösa återställning eller pausa klusteruppgraderingen, beroende på uppgraderingskonfigurationen. Om du däremot anger globalMaxPercentUnhealthyNodestill 0 och angerSpecialNodeTypemaximalt antal felfria noder till 100 med en nod av typenSpecialNodeTypei ett feltillstånd skulle klustret fortfarande hamna i ett feltillstånd eftersom den globala begränsningen är striktare i det här fallet.Följande exempel är ett utdrag från ett klustermanifest. Om du vill definiera poster i nodtypkartan prefixar du parameternamnet med "NodeTypeMaxPercentUnhealthyNodes-", följt av nodtypens namn.
<FabricSettings> <Section Name="HealthManager/ClusterHealthPolicy"> <Parameter Name="ConsiderWarningAsError" Value="False" /> <Parameter Name="MaxPercentUnhealthyApplications" Value="20" /> <Parameter Name="MaxPercentUnhealthyNodes" Value="20" /> <Parameter Name="NodeTypeMaxPercentUnhealthyNodes-SpecialNodeType" Value="0" /> </Section> </FabricSettings>
Programhälsoprincip
Programhälsoprincipen beskriver hur utvärdering av händelser och aggregering av underordnade tillstånd görs för program och deras barn. Det kan definieras i programmanifestet, ApplicationManifest.xml, i programpaketet. Om inga principer anges förutsätter Service Fabric att entiteten inte är felfri om den har en hälsorapport eller ett underordnat tillstånd vid varnings- eller felstatus. De konfigurerbara principerna är:
- ÖvervägWarningAsError. Anger om varningshälsorapporter ska behandlas som fel under hälsoutvärderingen. Standard: falskt.
- MaxPercentUnhealthyDeployedApplications. Anger den maximala tillåtna procentandelen distribuerade program som kan vara felfria innan programmet betraktas som ett fel. Den här procentandelen beräknas genom att dividera antalet ej distribuerade program över antalet noder som programmen för närvarande distribueras på i klustret. Beräkningen avrundar uppåt för att tolerera ett fel på ett litet antal noder. Standardprocent: noll.
- DefaultServiceTypeHealthPolicy. Anger standardprincipen för tjänsttypshälsa, som ersätter standardhälsoprincipen för alla tjänsttyper i programmet.
- ServiceTypeHealthPolicyMap. Innehåller en karta över tjänsthälsoprinciper per tjänsttyp. Dessa principer ersätter standardhälsoprinciperna för tjänsttyp för varje angiven tjänsttyp. Om ett program till exempel har en tillståndslös gatewaytjänsttyp och en tillståndskänslig motortjänsttyp kan du konfigurera hälsoprinciperna för utvärderingen på ett annat sätt. När du anger princip per tjänsttyp kan du få mer detaljerad kontroll över tjänstens hälsotillstånd.
Hälsoprincip för tjänsttyp
Hälsoprincipen för tjänsttyp anger hur tjänsterna och underordnade tjänster ska utvärderas och aggregeras. Principen innehåller:
- MaxPercentUnhealthyPartitionsPerService. Anger den maximala procentandelen som tolereras av partitioner som inte är felfria innan en tjänst anses vara felaktig. Standardprocent: noll.
- MaxPercentUnhealthyReplicasPerPartition. Anger den maximala tillåtna procentandelen felfria repliker innan en partition anses vara felaktig. Standardprocent: noll.
- MaxPercentUnhealthyServices. Anger den maximala tillåtna procentandelen tjänster som inte är felfria innan programmet anses vara felfritt. Standardprocent: noll.
Följande exempel är ett utdrag från ett programmanifest:
<Policies>
<HealthPolicy ConsiderWarningAsError="true" MaxPercentUnhealthyDeployedApplications="20">
<DefaultServiceTypeHealthPolicy
MaxPercentUnhealthyServices="0"
MaxPercentUnhealthyPartitionsPerService="10"
MaxPercentUnhealthyReplicasPerPartition="0"/>
<ServiceTypeHealthPolicy ServiceTypeName="FrontEndServiceType"
MaxPercentUnhealthyServices="0"
MaxPercentUnhealthyPartitionsPerService="20"
MaxPercentUnhealthyReplicasPerPartition="0"/>
<ServiceTypeHealthPolicy ServiceTypeName="BackEndServiceType"
MaxPercentUnhealthyServices="20"
MaxPercentUnhealthyPartitionsPerService="0"
MaxPercentUnhealthyReplicasPerPartition="0">
</ServiceTypeHealthPolicy>
</HealthPolicy>
</Policies>
Hälsoutvärdering
Användare och automatiserade tjänster kan när som helst utvärdera hälsotillståndet för vilken entitet som helst. För att utvärdera en entitets hälsa aggregerar hälsoarkivet alla hälsorapporter på entiteten och utvärderar alla dess underordnade (om tillämpligt). Algoritmen för hälsoaggregering använder hälsoprinciper som anger hur du utvärderar hälsorapporter och hur du aggregerar underordnade hälsotillstånd (i förekommande fall).
Sammansättning av hälsorapport
En entitet kan ha flera hälsorapporter som skickas av olika reportrar (systemkomponenter eller vakthundar) på olika egenskaper. Aggregeringen använder associerade hälsoprinciper, särskilt ConsiderWarningAsError-medlemmen i program- eller klusterhälsoprincipen. ConsiderWarningAsError anger hur du utvärderar varningar.
Det aggregerade hälsotillståndet utlöses av de värsta hälsorapporterna på entiteten. Om det finns minst en felhälsorapport är det aggregerade hälsotillståndet ett fel.

En hälsoentitet som har en eller flera felhälsorapporter utvärderas som Fel. Detsamma gäller för en hälsorapport som har upphört att gälla, oavsett hälsotillstånd.
Om det inte finns några felrapporter och en eller flera varningar är det aggregerade hälsotillståndet antingen varning eller fel, beroende på principflaggan ConsiderWarningAsError.
Aggregering av hälsorapport med varningsrapport och ConsiderWarningAsError inställt på false (standard).
Aggregering av underordnad hälsa
Den aggregerade hälsotillståndet för en entitet återspeglar underordnade hälsotillstånd (i förekommande fall). Algoritmen för att aggregera underordnade hälsotillstånd använder de hälsoprinciper som är tillämpliga baserat på entitetstypen.

Underordnad aggregering baserat på hälsoprinciper.
När hälsoarkivet har utvärderat alla underordnade grupper aggregeras deras hälsotillstånd baserat på den konfigurerade maximala procentandelen felfria underordnade. Den här procentandelen tas från principen baserat på entitet och underordnad typ.
- Om alla underordnade har OK-tillstånd är det underordnade aggregerade hälsotillståndet OK.
- Om barn har både OK- och varningstillstånd är det underordnade aggregerade hälsotillståndet varning.
- Om det finns underordnade med feltillstånd som inte respekterar den maximala tillåtna procentandelen underordnade fel är det aggregerade överordnade hälsotillståndet ett fel.
- Om underordnade med feltillstånd respekterar den maximala tillåtna procentandelen underordnade fel är det aggregerade överordnade hälsotillståndet varning.
Hälsorapportering
Systemkomponenter, System Fabric-program och interna/externa vakthundar kan rapportera mot Service Fabric-entiteter. Reportrarna gör lokala beslut om hälsotillståndet för de övervakade entiteterna, baserat på de villkor som de övervakar. De behöver inte titta på något globalt tillstånd eller aggregerade data. Det önskade beteendet är att ha enkla reportrar, och inte komplexa organismer som behöver titta på många saker för att härleda vilken information som ska skickas.
För att kunna skicka hälsodata till hälsoarkivet måste en reporter identifiera den berörda entiteten och skapa en hälsorapport. Om du vill skicka rapporten använder du API:et FabricClient.HealthClient.ReportHealth , api:er för rapporthälsa som exponeras på objekten Partition eller CodePackageActivationContext , PowerShell-cmdletarna eller REST.
Hälsorapporter
Hälsorapporterna för var och en av entiteterna i klustret innehåller följande information:
SourceId. En sträng som unikt identifierar reportern för hälsohändelsen.
Entitetsidentifierare. Identifierar entiteten där rapporten tillämpas. Den skiljer sig beroende på entitetstyp:
- Kluster. Inga.
- Nod. Nodnamn (sträng).
- Tillämpning. Programnamn (URI). Representerar namnet på den programinstans som distribuerats i klustret.
- Tjänst. Tjänstnamn (URI). Representerar namnet på tjänstinstansen som distribuerats i klustret.
- Skifte. Partitions-ID (GUID). Representerar den unika partitionsidentifieraren.
- Replik. Det tillståndskänsliga tjänstreplik-ID:t eller instans-ID:t för tillståndslös tjänst (INT64).
- DeployedApplication. Programnamn (URI) och nodnamn (sträng).
- DeployedServicePackage. Programnamn (URI), nodnamn (sträng) och tjänstmanifestnamn (sträng).
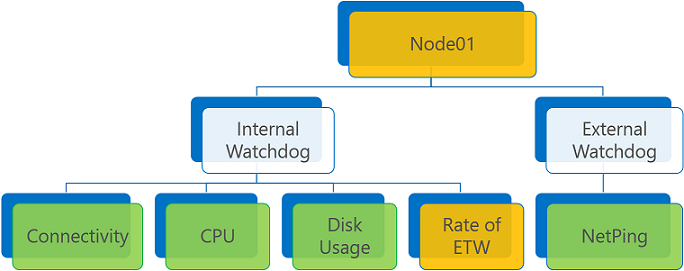
Egenskap. En sträng (inte en fast uppräkning) som gör att reportern kan kategorisera hälsohändelsen för en specifik egenskap för entiteten. Till exempel kan reporter A rapportera hälsotillståndet för egenskapen Node01 "Storage" och reporter B kan rapportera hälsotillståndet för egenskapen Node01 "Connectivity". I hälsoarkivet behandlas dessa rapporter som separata hälsohändelser för Node01-entiteten.
Beskrivning. En sträng som gör att en reporter kan ange detaljerad information om hälsohändelsen. SourceId, Property och HealthState bör helt beskriva rapporten. Beskrivningen lägger till läsbar information om rapporten. Texten gör det enklare för administratörer och användare att förstå hälsorapporten.
HealthState. En uppräkning som beskriver rapportens hälsotillstånd. De godkända värdena är OK, Varning och Fel.
TimeToLive. Ett tidsintervall som anger hur länge hälsorapporten är giltig. Tillsammans med RemoveWhenExpired låter det hälsoarkivet veta hur händelser som har upphört att gälla ska utvärderas. Som standard är värdet oändligt och rapporten är giltig för alltid.
RemoveWhenExpired. Ett booleskt. Om värdet är true tas hälsorapporten som upphört att gälla automatiskt bort från hälsoarkivet och rapporten påverkar inte utvärderingen av entitetens hälsotillstånd. Används när rapporten endast är giltig under en angiven tidsperiod, och reportern behöver inte uttryckligen rensa den. Den används också för att ta bort rapporter från hälsoarkivet (till exempel ändras en vakthund och slutar skicka rapporter med tidigare källa och egenskap). Den kan skicka en rapport med en kort TimeToLive tillsammans med RemoveWhenExpired för att rensa alla tidigare tillstånd från hälsoarkivet. Om värdet är inställt på false behandlas den utgångna rapporten som ett fel i hälsoutvärderingen. Det falska värdet signalerar till hälsoarkivet att källan regelbundet ska rapportera om den här egenskapen. Om det inte gör det, måste det vara något fel med vakthunden. Vakthundens hälsa fångas upp genom att händelsen betraktas som ett fel.
SequenceNumber. Ett positivt heltal som måste öka ständigt, det representerar ordningen på rapporterna. Det används av hälsoarkivet för att identifiera inaktuella rapporter som tas emot sent på grund av nätverksförseningar eller andra problem. En rapport avvisas om sekvensnumret är mindre än eller lika med det senast tillämpade talet för samma entitet, källa och egenskap. Om det inte anges genereras sekvensnumret automatiskt. Det är nödvändigt att bara ange sekvensnumret när du rapporterar om tillståndsövergångar. I det här fallet måste källan komma ihåg vilka rapporter den skickade och behålla informationen för återställning vid redundansväxling.
Dessa fyra delar av informationen – SourceId, entitetsidentifierare, egenskap och HealthState – krävs för varje hälsorapport. SourceId-strängen får inte börja med prefixet "System.", som är reserverat för systemrapporter. För samma entitet finns det bara en rapport för samma källa och egenskap. Flera rapporter för samma källa och egenskap åsidosätter varandra, antingen på hälsoklientsidan (om de är batchbaserade) eller på hälsoarkivsidan. Ersättningen baseras på sekvensnummer. nyare rapporter (med högre sekvensnummer) ersätter äldre rapporter.
Hälsohändelser
Internt behåller hälsoarkivet hälsohändelser, som innehåller all information från rapporterna och ytterligare metadata. Metadata inkluderar den tid då rapporten gavs till hälsoklienten och den tid då den ändrades på serversidan. Hälsohändelserna returneras av hälsofrågor.
De tillagda metadata innehåller:
- SourceUtcTimestamp. Den tid då rapporten gavs till hälsoklienten (Coordinated Universal Time).
- LastModifiedUtcTimestamp. Den tid då rapporten senast ändrades på serversidan (Coordinated Universal Time).
- IsExpired. En flagga som anger om rapporten har upphört att gälla när frågan kördes av hälsoarkivet. En händelse kan bara upphöra att gälla om RemoveWhenExpired är falskt. Annars returneras inte händelsen av frågan och tas bort från arkivet.
- LastOkTransitionAt, LastWarningTransitionAt, LastErrorTransitionAt. Senaste gången för ok-/varnings-/felövergångar. De här fälten ger historiken för hälsotillståndsövergångarna för händelsen.
Fälten för tillståndsövergång kan användas för smartare aviseringar eller "historisk" hälsohändelseinformation. De möjliggör scenarier som:
- Avisering när en egenskap har varit på varning/fel i mer än X minuter. Om du kontrollerar villkoret under en tidsperiod undviker du aviseringar om tillfälliga villkor. En avisering om hälsotillståndet har varnats i mer än fem minuter kan till exempel översättas till (HealthState == Varning och Nu – LastWarningTransitionTime > 5 minuter).
- Avisera endast om villkor som har ändrats under de senaste X-minuterna. Om en rapport redan hade ett fel före den angivna tiden kan den ignoreras eftersom den redan har signalerats tidigare.
- Om en egenskap växlar mellan varning och fel, avgör du hur länge den har varit felaktig (det vill: inte OK). En avisering om egenskapen inte har varit felfri på mer än fem minuter kan till exempel översättas till (HealthState != Ok och Nu – LastOkTransitionTime > 5 minuter).
Exempel: Rapportera och utvärdera programmets hälsa
I följande exempel skickas en hälsorapport via PowerShell i programinfrastrukturen :/WordCount från källan MyWatchdog. Hälsorapporten innehåller information om hälsoegenskapen "tillgänglighet" i ett felhälsotillstånd, med oändlig TimeToLive. Sedan frågar den programmets hälsa, som returnerar aggregerade hälsotillståndsfel och rapporterade hälsohändelser i listan över hälsohändelser.
PS C:\> Send-ServiceFabricApplicationHealthReport –ApplicationName fabric:/WordCount –SourceId "MyWatchdog" –HealthProperty "Availability" –HealthState Error
PS C:\> Get-ServiceFabricApplicationHealth fabric:/WordCount -ExcludeHealthStatistics
ApplicationName : fabric:/WordCount
AggregatedHealthState : Error
UnhealthyEvaluations :
Error event: SourceId='MyWatchdog', Property='Availability'.
ServiceHealthStates :
ServiceName : fabric:/WordCount/WordCountService
AggregatedHealthState : Error
ServiceName : fabric:/WordCount/WordCountWebService
AggregatedHealthState : Ok
DeployedApplicationHealthStates :
ApplicationName : fabric:/WordCount
NodeName : _Node_0
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_2
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_3
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_4
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_1
AggregatedHealthState : Ok
HealthEvents :
SourceId : System.CM
Property : State
HealthState : Ok
SequenceNumber : 360
SentAt : 3/22/2016 7:56:53 PM
ReceivedAt : 3/22/2016 7:56:53 PM
TTL : Infinite
Description : Application has been created.
RemoveWhenExpired : False
IsExpired : False
Transitions : Error->Ok = 3/22/2016 7:56:53 PM, LastWarning = 1/1/0001 12:00:00 AM
SourceId : MyWatchdog
Property : Availability
HealthState : Error
SequenceNumber : 131032204762818013
SentAt : 3/23/2016 3:27:56 PM
ReceivedAt : 3/23/2016 3:27:56 PM
TTL : Infinite
Description :
RemoveWhenExpired : False
IsExpired : False
Transitions : Ok->Error = 3/23/2016 3:27:56 PM, LastWarning = 1/1/0001 12:00:00 AM
Användning av hälsomodell
Hälsomodellen gör att molntjänster och den underliggande Service Fabric-plattformen kan skalas, eftersom övervaknings- och hälsobestämningar fördelas mellan de olika övervakarna i klustret. Andra system har en enda centraliserad tjänst på klusternivå som parsar all potentiellt användbar information som genereras av tjänster. Den här metoden hindrar deras skalbarhet. Det tillåter inte heller att de samlar in specifik information för att identifiera problem och potentiella problem så nära rotorsaken som möjligt.
Hälsomodellen används mycket för övervakning och diagnos, för utvärdering av kluster- och programhälsa samt för övervakade uppgraderingar. Andra tjänster använder hälsodata för att utföra automatiska reparationer, skapa klusterhälsohistorik och utfärda aviseringar under vissa villkor.
Nästa steg
Visa Service Fabric-hälsorapporter
Använda systemhälsorapporter för felsökning
Så här rapporterar och kontrollerar du tjänstens hälsa
Lägga till anpassade Service Fabric-hälsorapporter