Använda Apache Spark MLlib för att skapa ett maskininlärningsprogram och analysera en datauppsättning
Lär dig hur du använder Apache Spark MLlib för att skapa ett maskininlärningsprogram. Programmet utför förutsägelseanalys på en öppen datauppsättning. I Sparks inbyggda maskininlärningsbibliotek används klassificering via logistisk regression i det här exemplet.
MLlib är ett grundläggande Spark-bibliotek som tillhandahåller många verktyg som är användbara för maskininlärningsuppgifter, till exempel:
- Klassificering
- Regression
- Klustring
- Modellering
- Singulär värde nedbrytning (SVD) och huvudkomponentanalys (PCA)
- Hypotestestning och beräkning av exempelstatistik
Förstå klassificering och logistisk regression
Klassificering, en populär maskininlärningsuppgift, är processen att sortera indata i kategorier. Det är en klassificeringsalgoritms jobb att ta reda på hur du tilldelar "etiketter" till indata som du anger. Du kan till exempel tänka på en maskininlärningsalgoritm som accepterar lagerinformation som indata. Delar sedan upp aktien i två kategorier: aktier som du bör sälja och aktier som du bör behålla.
Logistisk regression är den algoritm som du använder för klassificering. Sparks logistiska regressions-API är användbart för binär klassificering eller klassificering av indata i en av två grupper. Mer information om logistiska regressioner finns i Wikipedia.
Sammanfattningsvis skapar processen för logistisk regression en logistisk funktion. Använd funktionen för att förutsäga sannolikheten för att en indatavektor tillhör den ena gruppen eller den andra.
Exempel på förutsägelseanalys av livsmedelsinspektionsdata
I det här exemplet använder du Spark för att göra en förutsägelseanalys av livsmedelsinspektionsdata (Food_Inspections1.csv). Data som hämtas via dataportalen City of Chicago. Den här datamängden innehåller information om inspektioner av livsmedelsanläggningar som genomfördes i Chicago. Inklusive information om varje anläggning, de överträdelser som hittats (om några) och resultaten av inspektionen. CSV-datafilen är redan tillgänglig i lagringskontot som är associerat med klustret på /HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections1.csv.
I följande steg utvecklar du en modell för att se vad som krävs för att klara eller misslyckas med en livsmedelsinspektion.
Skapa en Apache Spark MLlib-maskininlärningsapp
Skapa en Jupyter Notebook med hjälp av PySpark-kerneln. Anvisningarna finns i Skapa en Jupyter Notebook-fil.
Importera de typer som krävs för det här programmet. Kopiera och klistra in följande kod i en tom cell och tryck sedan på SKIFT + RETUR.
from pyspark.ml import Pipeline from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import HashingTF, Tokenizer from pyspark.sql import Row from pyspark.sql.functions import UserDefinedFunction from pyspark.sql.types import *På grund av PySpark-kerneln behöver du inte skapa några kontexter explicit. Spark- och Hive-kontexterna skapas automatiskt när du kör den första kodcellen.
Konstruera indataramen
Använd Spark-kontexten för att hämta rådata från CSV till minnet som ostrukturerad text. Använd sedan Pythons CSV-bibliotek för att parsa varje rad med data.
Kör följande rader för att skapa en resilient Distributed Dataset (RDD) genom att importera och parsa indata.
def csvParse(s): import csv from io import StringIO sio = StringIO(s) value = next(csv.reader(sio)) sio.close() return value inspections = sc.textFile('/HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections1.csv')\ .map(csvParse)Kör följande kod för att hämta en rad från RDD så att du kan ta en titt på dataschemat:
inspections.take(1)Resultatet är:
[['413707', 'LUNA PARK INC', 'LUNA PARK DAY CARE', '2049789', "Children's Services Facility", 'Risk 1 (High)', '3250 W FOSTER AVE ', 'CHICAGO', 'IL', '60625', '09/21/2010', 'License-Task Force', 'Fail', '24. DISH WASHING FACILITIES: PROPERLY DESIGNED, CONSTRUCTED, MAINTAINED, INSTALLED, LOCATED AND OPERATED - Comments: All dishwashing machines must be of a type that complies with all requirements of the plumbing section of the Municipal Code of Chicago and Rules and Regulation of the Board of Health. OBSEVERD THE 3 COMPARTMENT SINK BACKING UP INTO THE 1ST AND 2ND COMPARTMENT WITH CLEAR WATER AND SLOWLY DRAINING OUT. INST NEED HAVE IT REPAIR. CITATION ISSUED, SERIOUS VIOLATION 7-38-030 H000062369-10 COURT DATE 10-28-10 TIME 1 P.M. ROOM 107 400 W. SURPERIOR. | 36. LIGHTING: REQUIRED MINIMUM FOOT-CANDLES OF LIGHT PROVIDED, FIXTURES SHIELDED - Comments: Shielding to protect against broken glass falling into food shall be provided for all artificial lighting sources in preparation, service, and display facilities. LIGHT SHIELD ARE MISSING UNDER HOOD OF COOKING EQUIPMENT AND NEED TO REPLACE LIGHT UNDER UNIT. 4 LIGHTS ARE OUT IN THE REAR CHILDREN AREA,IN THE KINDERGARDEN CLASS ROOM. 2 LIGHT ARE OUT EAST REAR, LIGHT FRONT WEST ROOM. NEED TO REPLACE ALL LIGHT THAT ARE NOT WORKING. | 35. WALLS, CEILINGS, ATTACHED EQUIPMENT CONSTRUCTED PER CODE: GOOD REPAIR, SURFACES CLEAN AND DUST-LESS CLEANING METHODS - Comments: The walls and ceilings shall be in good repair and easily cleaned. MISSING CEILING TILES WITH STAINS IN WEST,EAST, IN FRONT AREA WEST, AND BY THE 15MOS AREA. NEED TO BE REPLACED. | 32. FOOD AND NON-FOOD CONTACT SURFACES PROPERLY DESIGNED, CONSTRUCTED AND MAINTAINED - Comments: All food and non-food contact equipment and utensils shall be smooth, easily cleanable, and durable, and shall be in good repair. SPLASH GUARDED ARE NEEDED BY THE EXPOSED HAND SINK IN THE KITCHEN AREA | 34. FLOORS: CONSTRUCTED PER CODE, CLEANED, GOOD REPAIR, COVING INSTALLED, DUST-LESS CLEANING METHODS USED - Comments: The floors shall be constructed per code, be smooth and easily cleaned, and be kept clean and in good repair. INST NEED TO ELEVATE ALL FOOD ITEMS 6INCH OFF THE FLOOR 6 INCH AWAY FORM WALL. ', '41.97583445690982', '-87.7107455232781', '(41.97583445690982, -87.7107455232781)']]Utdata ger dig en uppfattning om schemat för indatafilen. Den innehåller namnet på varje anläggning och typ av anläggning. Dessutom adress, uppgifter om inspektioner, och platsen, bland annat.
Kör följande kod för att skapa en dataram (df) och en tillfällig tabell (CountResults) med några kolumner som är användbara för förutsägelseanalysen.
sqlContextanvänds för att göra transformeringar på strukturerade data.schema = StructType([ StructField("id", IntegerType(), False), StructField("name", StringType(), False), StructField("results", StringType(), False), StructField("violations", StringType(), True)]) df = spark.createDataFrame(inspections.map(lambda l: (int(l[0]), l[1], l[12], l[13])) , schema) df.registerTempTable('CountResults')De fyra kolumnerna av intresse i dataramen är ID, namn, resultat och överträdelser.
Kör följande kod för att hämta ett litet exempel på data:
df.show(5)Resultatet är:
+------+--------------------+-------+--------------------+ | id| name|results| violations| +------+--------------------+-------+--------------------+ |413707| LUNA PARK INC| Fail|24. DISH WASHING ...| |391234| CAFE SELMARIE| Fail|2. FACILITIES TO ...| |413751| MANCHU WOK| Pass|33. FOOD AND NON-...| |413708|BENCHMARK HOSPITA...| Pass| | |413722| JJ BURGER| Pass| | +------+--------------------+-------+--------------------+
Förstå data
Nu ska vi börja få en uppfattning om vad datamängden innehåller.
Kör följande kod för att visa de distinkta värdena i resultatkolumnen:
df.select('results').distinct().show()Resultatet är:
+--------------------+ | results| +--------------------+ | Fail| |Business Not Located| | Pass| | Pass w/ Conditions| | Out of Business| +--------------------+Kör följande kod för att visualisera fördelningen av dessa resultat:
%%sql -o countResultsdf SELECT COUNT(results) AS cnt, results FROM CountResults GROUP BY resultsMagin
%%sqlföljt av-o countResultsdfsäkerställer att frågans utdata sparas lokalt på Jupyter-servern (vanligtvis huvudnoden i klustret). Utdata sparas som en Pandas-dataram med det angivna namnet countResultsdf. Mer information om magin%%sqloch andra funktioner som är tillgängliga med PySpark-kerneln finns i Kernels available on Jupyter Notebooks with Apache Spark HDInsight clusters (Kernels available on Jupyter Notebooks with Apache Spark HDInsight clusters).Resultatet är:
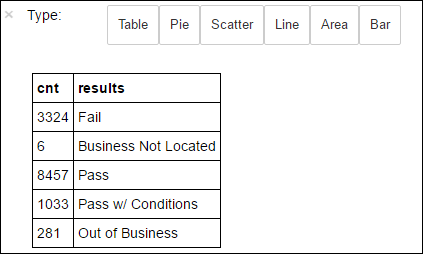
Du kan också använda Matplotlib, ett bibliotek som används för att konstruera visualisering av data, för att skapa ett diagram. Eftersom diagrammet måste skapas från den lokalt bevarade countResultsdf-dataramen måste kodfragmentet börja med magin
%%local. Den här åtgärden säkerställer att koden körs lokalt på Jupyter-servern.%%local %matplotlib inline import matplotlib.pyplot as plt labels = countResultsdf['results'] sizes = countResultsdf['cnt'] colors = ['turquoise', 'seagreen', 'mediumslateblue', 'palegreen', 'coral'] plt.pie(sizes, labels=labels, autopct='%1.1f%%', colors=colors) plt.axis('equal')För att förutsäga ett utfall av livsmedelsinspektionen måste du utveckla en modell baserat på överträdelserna. Eftersom logistisk regression är en binär klassificeringsmetod är det klokt att gruppera resultatdata i två kategorier: Fail och Pass:
Godkänd
- Godkänd
- Skicka w/ villkor
Underkänn
- Underkänn
Ignorera
- Verksamheten finns inte
- Verksamhetsspecifik
Data med de andra resultaten ("Business Not Located" eller "Out of Business") är inte användbara, och de utgör ändå en liten procentandel av resultaten.
Kör följande kod för att konvertera den befintliga dataramen(
df) till en ny dataram där varje inspektion representeras som ett etikettöverträdelsepar. I det här fallet representerar en etikett med0.0ett fel, en etikett med1.0representerar ett lyckat resultat och en etikett med-1.0representerar några resultat förutom dessa två resultat.def labelForResults(s): if s == 'Fail': return 0.0 elif s == 'Pass w/ Conditions' or s == 'Pass': return 1.0 else: return -1.0 label = UserDefinedFunction(labelForResults, DoubleType()) labeledData = df.select(label(df.results).alias('label'), df.violations).where('label >= 0')Kör följande kod för att visa en rad med etiketterade data:
labeledData.take(1)Resultatet är:
[Row(label=0.0, violations=u"41. PREMISES MAINTAINED FREE OF LITTER, UNNECESSARY ARTICLES, CLEANING EQUIPMENT PROPERLY STORED - Comments: All parts of the food establishment and all parts of the property used in connection with the operation of the establishment shall be kept neat and clean and should not produce any offensive odors. REMOVE MATTRESS FROM SMALL DUMPSTER. | 35. WALLS, CEILINGS, ATTACHED EQUIPMENT CONSTRUCTED PER CODE: GOOD REPAIR, SURFACES CLEAN AND DUST-LESS CLEANING METHODS - Comments: The walls and ceilings shall be in good repair and easily cleaned. REPAIR MISALIGNED DOORS AND DOOR NEAR ELEVATOR. DETAIL CLEAN BLACK MOLD LIKE SUBSTANCE FROM WALLS BY BOTH DISH MACHINES. REPAIR OR REMOVE BASEBOARD UNDER DISH MACHINE (LEFT REAR KITCHEN). SEAL ALL GAPS. REPLACE MILK CRATES USED IN WALK IN COOLERS AND STORAGE AREAS WITH PROPER SHELVING AT LEAST 6' OFF THE FLOOR. | 38. VENTILATION: ROOMS AND EQUIPMENT VENTED AS REQUIRED: PLUMBING: INSTALLED AND MAINTAINED - Comments: The flow of air discharged from kitchen fans shall always be through a duct to a point above the roofline. REPAIR BROKEN VENTILATION IN MEN'S AND WOMEN'S WASHROOMS NEXT TO DINING AREA. | 32. FOOD AND NON-FOOD CONTACT SURFACES PROPERLY DESIGNED, CONSTRUCTED AND MAINTAINED - Comments: All food and non-food contact equipment and utensils shall be smooth, easily cleanable, and durable, and shall be in good repair. REPAIR DAMAGED PLUG ON LEFT SIDE OF 2 COMPARTMENT SINK. REPAIR SELF CLOSER ON BOTTOM LEFT DOOR OF 4 DOOR PREP UNIT NEXT TO OFFICE.")]
Skapa en logistisk regressionsmodell från indataramen
Den sista uppgiften är att konvertera etiketterade data. Konvertera data till ett format som analyseras av logistisk regression. Indata till en logistisk regressionsalgoritm behöver en uppsättning etikett-funktionsvektorpar. Där "funktionsvektorn" är en vektor med tal som representerar indatapunkten. Därför måste du konvertera kolumnen "överträdelser", som är halvstrukturerad och innehåller många kommentarer i fritext. Konvertera kolumnen till en matris med verkliga tal som en dator enkelt kan förstå.
En standardmetod för maskininlärning för bearbetning av naturligt språk är att tilldela varje distinkt ord ett index. Skicka sedan en vektor till maskininlärningsalgoritmen. Så att varje indexvärde innehåller den relativa frekvensen för ordet i textsträngen.
MLlib är ett enkelt sätt att utföra den här åtgärden. Först "tokenisera" varje överträdelsesträng för att hämta de enskilda orden i varje sträng. Använd sedan en HashingTF för att konvertera varje uppsättning token till en funktionsvektor som sedan kan skickas till algoritmen för logistisk regression för att konstruera en modell. Du utför alla dessa steg i följd med hjälp av en pipeline.
tokenizer = Tokenizer(inputCol="violations", outputCol="words")
hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features")
lr = LogisticRegression(maxIter=10, regParam=0.01)
pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])
model = pipeline.fit(labeledData)
Utvärdera modellen med hjälp av en annan datauppsättning
Du kan använda den modell som du skapade tidigare för att förutsäga resultatet av nya inspektioner. Förutsägelserna baseras på de överträdelser som observerades. Du har tränat den här modellen på datamängden Food_Inspections1.csv. Du kan använda en andra datauppsättning, Food_Inspections2.csv, för att utvärdera modellens styrka på nya data. Den andra datauppsättningen (Food_Inspections2.csv) finns i standardlagringscontainern som är associerad med klustret.
Kör följande kod för att skapa en ny dataram, predictionsDf som innehåller förutsägelsen som genereras av modellen. Kodfragmentet skapar också en tillfällig tabell med namnet Förutsägelser baserat på dataramen.
testData = sc.textFile('wasbs:///HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections2.csv')\ .map(csvParse) \ .map(lambda l: (int(l[0]), l[1], l[12], l[13])) testDf = spark.createDataFrame(testData, schema).where("results = 'Fail' OR results = 'Pass' OR results = 'Pass w/ Conditions'") predictionsDf = model.transform(testDf) predictionsDf.registerTempTable('Predictions') predictionsDf.columnsDu bör se utdata som följande text:
['id', 'name', 'results', 'violations', 'words', 'features', 'rawPrediction', 'probability', 'prediction']Titta på en av förutsägelserna. Kör det här kodfragmentet:
predictionsDf.take(1)Det finns en förutsägelse för den första posten i testdatauppsättningen.
Metoden
model.transform()tillämpar samma transformering på alla nya data med samma schema och anländer till en förutsägelse om hur data ska klassificeras. Du kan göra lite statistik för att få en uppfattning om hur förutsägelserna var:numSuccesses = predictionsDf.where("""(prediction = 0 AND results = 'Fail') OR (prediction = 1 AND (results = 'Pass' OR results = 'Pass w/ Conditions'))""").count() numInspections = predictionsDf.count() print ("There were", numInspections, "inspections and there were", numSuccesses, "successful predictions") print ("This is a", str((float(numSuccesses) / float(numInspections)) * 100) + "%", "success rate")Utdata ser ut som följande text:
There were 9315 inspections and there were 8087 successful predictions This is a 86.8169618894% success rateMed logistisk regression med Spark får du en modell av relationen mellan beskrivningar av överträdelser på engelska. Och om ett visst företag skulle klara eller misslyckas med en livsmedelsinspektion.
Skapa en visuell representation av förutsägelsen
Nu kan du skapa en slutlig visualisering som hjälper dig att resonera kring resultatet av det här testet.
Du börjar med att extrahera de olika förutsägelserna och resultaten från den temporära tabellen Förutsägelser som skapades tidigare. Följande frågor separerar utdata som true_positive, false_positive, true_negative och false_negative. I frågorna nedan inaktiverar du visualisering med hjälp
-qav och sparar även utdata (med hjälp-oav ) som dataramar som sedan kan användas med magin%%local.%%sql -q -o true_positive SELECT count(*) AS cnt FROM Predictions WHERE prediction = 0 AND results = 'Fail'%%sql -q -o false_positive SELECT count(*) AS cnt FROM Predictions WHERE prediction = 0 AND (results = 'Pass' OR results = 'Pass w/ Conditions')%%sql -q -o true_negative SELECT count(*) AS cnt FROM Predictions WHERE prediction = 1 AND results = 'Fail'%%sql -q -o false_negative SELECT count(*) AS cnt FROM Predictions WHERE prediction = 1 AND (results = 'Pass' OR results = 'Pass w/ Conditions')Använd slutligen följande kodfragment för att generera diagrammet med hjälp av Matplotlib.
%%local %matplotlib inline import matplotlib.pyplot as plt labels = ['True positive', 'False positive', 'True negative', 'False negative'] sizes = [true_positive['cnt'], false_positive['cnt'], false_negative['cnt'], true_negative['cnt']] colors = ['turquoise', 'seagreen', 'mediumslateblue', 'palegreen', 'coral'] plt.pie(sizes, labels=labels, autopct='%1.1f%%', colors=colors) plt.axis('equal')Du bör se följande utdata:
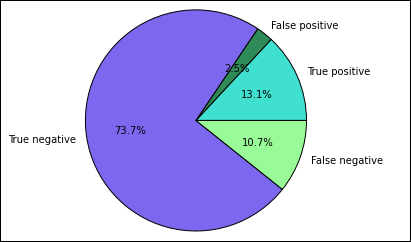
I det här diagrammet refererar ett "positivt" resultat till den misslyckade livsmedelsinspektionen, medan ett negativt resultat refererar till en godkänd inspektion.
Stäng av anteckningsboken
När du har kört programmet bör du stänga av anteckningsboken för att frigöra resurserna. Du gör det genom att välja Stäng och stoppa i anteckningsbokens Fil-meny. Åtgärden stänger anteckningsboken.
Nästa steg
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för