Om du vill träna en modell startar du ett träningsjobb. Endast slutförda jobb skapar en modell. Träningsjobb upphör att gälla efter sju dagar, efter den här tiden kommer du inte längre att kunna hämta jobbinformationen. Om ditt träningsjobb har slutförts och en modell har skapats påverkas det inte av att jobbet upphör att gälla. Du kan bara ha ett träningsjobb i taget och du kan inte starta andra jobb i samma projekt.
Träningstiderna kan vara allt från några sekunder när du hanterar enkla projekt, upp till ett par timmar när du når den maximala gränsen för yttranden.
Modellutvärderingen utlöses automatiskt när träningen har slutförts. Utvärderingsprocessen börjar med att använda den tränade modellen för att köra förutsägelser på yttrandena i testuppsättningen och jämför de förväntade resultaten med de angivna etiketterna (som upprättar en baslinje för sanning). Resultaten returneras så att du kan granska modellens prestanda.
Innan du påbörjar träningsprocessen delas märkta yttranden i projektet in i en träningsuppsättning och en testuppsättning. Var och en av dem har olika funktioner.
Träningsuppsättningen används för att träna modellen. Det här är den uppsättning som modellen lär sig de märkta yttrandena från.
Testuppsättningen är en blinduppsättning som inte introduceras i modellen under träning utan bara under utvärderingen.
När modellen har tränats kan modellen användas för att göra förutsägelser från yttrandena i testuppsättningen. Dessa förutsägelser används för att beräkna utvärderingsmått.
Vi rekommenderar att du ser till att alla avsikter är korrekt representerade i både tränings- och testuppsättningen.
Orchestration-arbetsflödet stöder två metoder för datadelning:
Dela automatiskt upp testuppsättningen från träningsdata: Systemet delar dina taggade data mellan tränings- och testuppsättningarna, enligt de procentandelar du väljer. Den rekommenderade procentuella uppdelningen är 80 % för träning och 20 % för testning.
Anteckning
Om du väljer alternativet Dela upp testuppsättningen automatiskt från träningsdata delas endast de data som är tilldelade till träningsuppsättningen upp enligt de procentsatser som anges.
Använd en manuell uppdelning av tränings- och testdata: Med den här metoden kan användarna definiera vilka yttranden som ska tillhöra vilken uppsättning. Det här steget aktiveras bara om du har lagt till yttranden i testuppsättningen under etikettering.
Anteckning
Du kan bara lägga till yttranden i träningsdatauppsättningen endast för icke-anslutna avsikter.
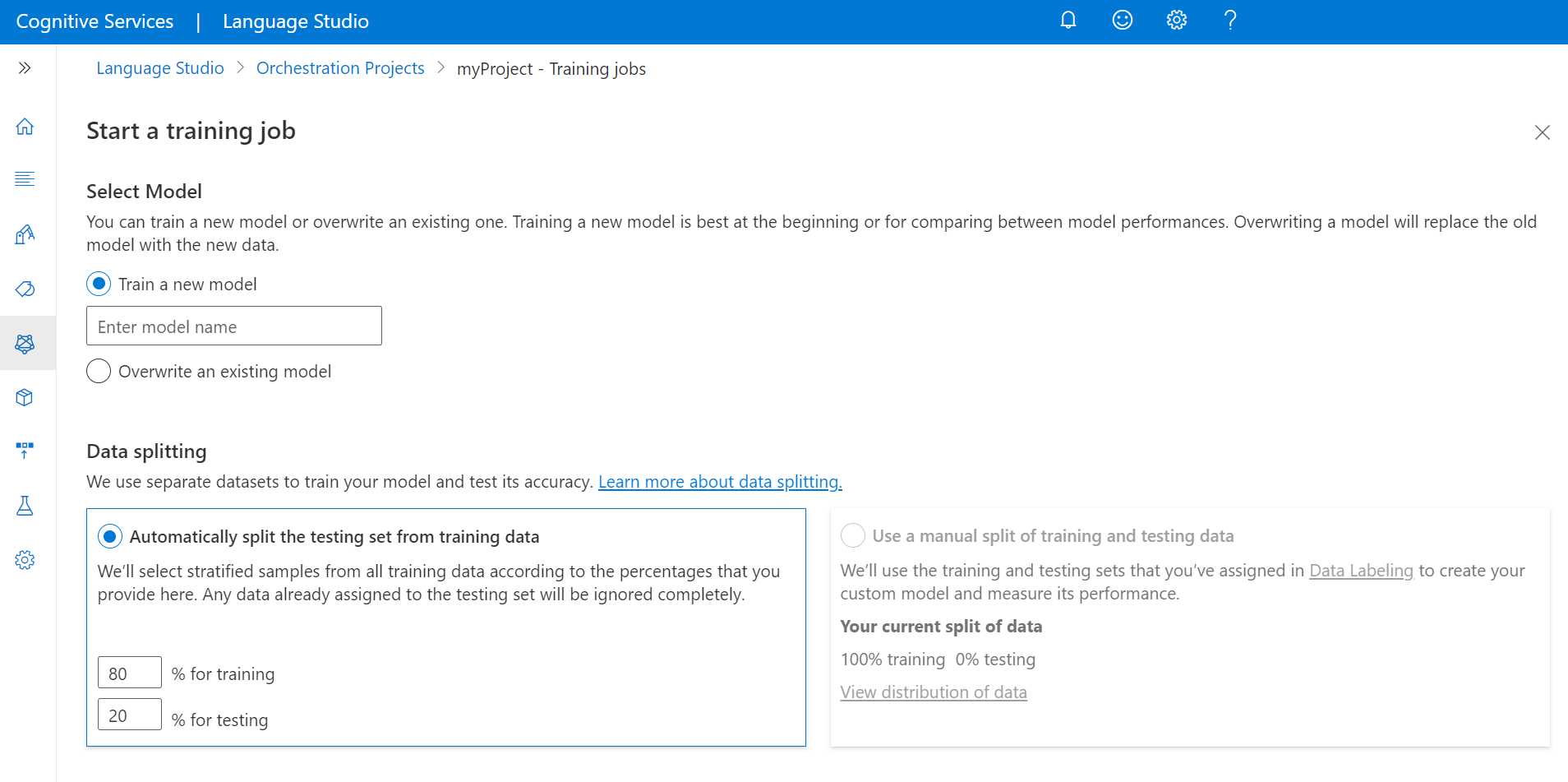
Välj Starta ett träningsjobb på den översta menyn.
Välj Träna en ny modell och skriv in modellnamnet i textrutan. Du kan också skriva över en befintlig modell genom att välja det här alternativet och välja den modell som du vill skriva över från den nedrullningsbara menyn. Det går inte att ångra att skriva över en tränad modell, men det påverkar inte dina distribuerade modeller förrän du distribuerar den nya modellen.
Dela automatiskt upp testuppsättningen från träningsdata: Dina taggade yttranden delas slumpmässigt mellan tränings- och testuppsättningarna, enligt de procentandelar du väljer. Standardprocentdelningen är 80 % för träning och 20 % för testning. Om du vill ändra dessa värden väljer du vilken uppsättning du vill ändra och skriver in det nya värdet.
Anteckning
Om du väljer alternativet Dela upp testuppsättningen automatiskt från träningsdata delas endast yttrandena i träningsuppsättningen upp enligt de procentsatser som anges.
Använd en manuell uppdelning av tränings- och testdata: Tilldela varje yttrande till antingen tränings- eller testuppsättningen under taggningssteget i projektet.
Anteckning
Använd en manuell uppdelning av alternativet tränings- och testdata aktiveras endast om du lägger till yttranden i testuppsättningen på taggdatasidan. Annars inaktiveras den.
Välj knappen Träna .
Anteckning
Endast slutförda träningsjobb genererar modeller.
Träningen kan ta lite tid mellan ett par minuter och ett par timmar baserat på storleken på dina taggade data.
Du kan bara köra ett träningsjobb i taget. Du kan inte starta ett annat träningsjobb med samma projekt förrän det pågående jobbet har slutförts.
Skapa en POST-begäran med hjälp av följande URL, rubriker och JSON-brödtext för att skicka ett träningsjobb.
Begärans-URL
Använd följande URL när du skapar din API-begäran. Ersätt platshållarvärdena nedan med dina egna värden.
Träningsläge. Endast ett läge för träning är tillgängligt i orkestrering, vilket är standard.
standard
trainingConfigVersion
{CONFIG-VERSION}
Träningskonfigurationsmodellens version. Som standard används den senaste modellversionen .
2022-05-01
kind
percentage
Delningsmetoder. Möjliga värden är percentage eller manual. Mer information finns i hur du tränar en modell .
percentage
trainingSplitPercentage
80
Procentandel av dina taggade data som ska ingå i träningsuppsättningen. Rekommenderat värde är 80.
80
testingSplitPercentage
20
Procentandel av dina taggade data som ska ingå i testuppsättningen. Rekommenderat värde är 20.
20
Anteckning
Och trainingSplitPercentagetestingSplitPercentage krävs endast om Kind anges till percentage och summan av båda procentandelarna ska vara lika med 100.
När du har skickat din API-begäran får du ett 202 svar som anger att det har lyckats. Extrahera värdet i svarshuvudena operation-location . Den formateras så här:
Välj träningsjobbets ID i listan. Ett sidofönster visas där du kan kontrollera träningsförloppet, jobbstatusen och annan information för det här jobbet.
Träningen kan ta någon gång beroende på storleken på dina träningsdata och schemats komplexitet. Du kan använda följande begäran för att behålla avsökningsstatusen för träningsjobbet tills det har slutförts.
Använd följande GET-begäran för att hämta status för modellens träningsförlopp. Ersätt platshållarvärdena nedan med dina egna värden.
Om du vill avbryta ett träningsjobb från Language Studio går du till sidan Träna modell . Välj det träningsjobb som du vill avbryta och välj Avbryt på den översta menyn.
Skapa en POST-begäran med hjälp av följande URL, rubriker och JSON-brödtext för att avbryta ett träningsjobb.
Begärans-URL
Använd följande URL när du skapar din API-begäran. Ersätt platshållarvärdena nedan med dina egna värden.
Använd följande rubrik för att autentisera din begäran.
Tangent
Värde
Ocp-Apim-Subscription-Key
Nyckeln till resursen. Används för att autentisera dina API-begäranden.
När du skickar din API-begäran får du ett 202-svar som anger att du har lyckats, vilket innebär att ditt träningsjobb har avbrutits. Ett lyckat anrop resulterar i ett Operation-Location-huvud som används för att kontrollera jobbets status.
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.