Kopiera och transformera data till och från SQL Server med hjälp av Azure Data Factory eller Azure Synapse Analytics
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Den här artikeln beskriver hur du använder kopieringsaktiviteten i Azure Data Factory- och Azure Synapse-pipelines för att kopiera data från och till SQL Server-databasen och använda Data Flow för att transformera data i SQL Server-databasen. Mer information finns i introduktionsartikeln för Azure Data Factory eller Azure Synapse Analytics.
Funktioner som stöds
Den här SQL Server-anslutningsappen stöds för följande funktioner:
| Funktioner som stöds | IR |
|---|---|
| Kopieringsaktivitet (källa/mottagare) | (1) (2) |
| Mappa dataflöde (källa/mottagare) | (1) |
| Sökningsaktivitet | (1) (2) |
| GetMetadata-aktivitet | (1) (2) |
| Skriptaktivitet | (1) (2) |
| Lagrad proceduraktivitet | (1) (2) |
(1) Azure Integration Runtime (2) Lokalt installerad integrationskörning
En lista över datalager som stöds som källor eller mottagare av kopieringsaktiviteten finns i tabellen Datalager som stöds.
Mer specifikt stöder den här SQL Server-anslutningsappen:
- SQL Server version 2005 och senare.
- Kopiera data med hjälp av SQL- eller Windows-autentisering.
- Som källa hämtar du data med hjälp av en SQL-fråga eller en lagrad procedur. Du kan också välja att kopiera parallellt från SQL Server-källan. Mer information finns i avsnittet Parallellkopia från SQL-databas .
- Som mottagare skapar du automatiskt måltabellen om den inte finns baserat på källschemat. lägga till data i en tabell eller anropa en lagrad procedur med anpassad logik under kopieringen.
SQL Server Express LocalDB stöds inte.
Viktigt!
Datakällan måste ha stöd för NVARCHAR-datatypen eftersom den påverkar datakodningen när en icke-universell kodning tillämpas på data.
Förutsättningar
Om ditt datalager finns i ett lokalt nätverk, ett virtuellt Azure-nätverk eller Amazon Virtual Private Cloud måste du konfigurera en lokalt installerad integrationskörning för att ansluta till det.
Om ditt datalager är en hanterad molndatatjänst kan du använda Azure Integration Runtime. Om åtkomsten är begränsad till IP-adresser som är godkända i brandväggsreglerna kan du lägga till Azure Integration Runtime-IP-adresser i listan över tillåtna.
Du kan också använda funktionen för integrering av hanterade virtuella nätverk i Azure Data Factory för att få åtkomst till det lokala nätverket utan att installera och konfigurera en lokalt installerad integrationskörning.
Mer information om de nätverkssäkerhetsmekanismer och alternativ som stöds av Data Factory finns i Strategier för dataåtkomst.
Kom igång
Om du vill utföra kopieringsaktiviteten med en pipeline kan du använda något av följande verktyg eller SDK:er:
- Verktyget Kopiera data
- Azure-portalen
- The .NET SDK
- The Python SDK
- Azure PowerShell
- REST-API:et
- Azure Resource Manager-mallen
Skapa en länkad SQL Server-tjänst med hjälp av användargränssnittet
Använd följande steg för att skapa en länkad SQL Server-tjänst i azure-portalens användargränssnitt.
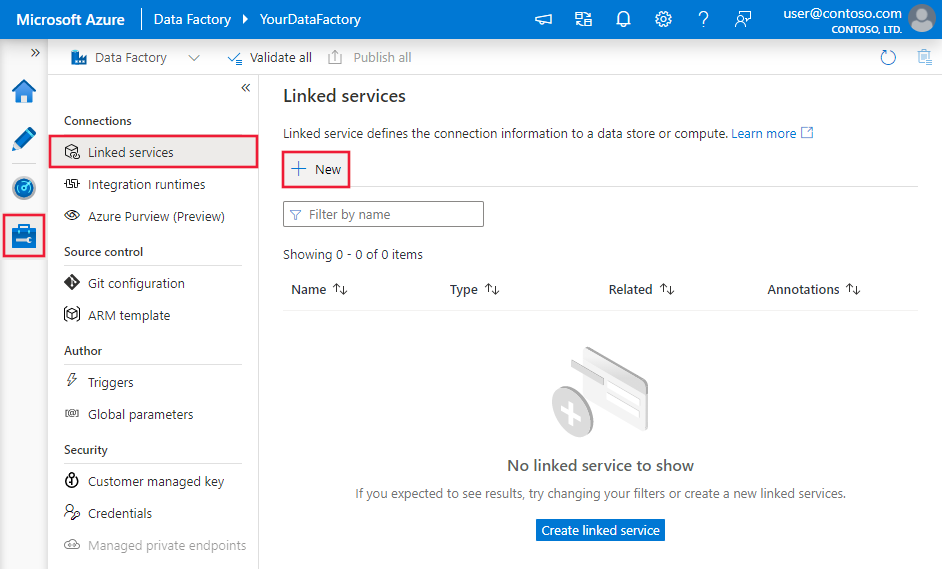
Bläddra till fliken Hantera i Din Azure Data Factory- eller Synapse-arbetsyta och välj Länkade tjänster och klicka sedan på Ny:
Sök efter SQL och välj SQL Server-anslutningsappen.

Konfigurera tjänstinformationen, testa anslutningen och skapa den nya länkade tjänsten.
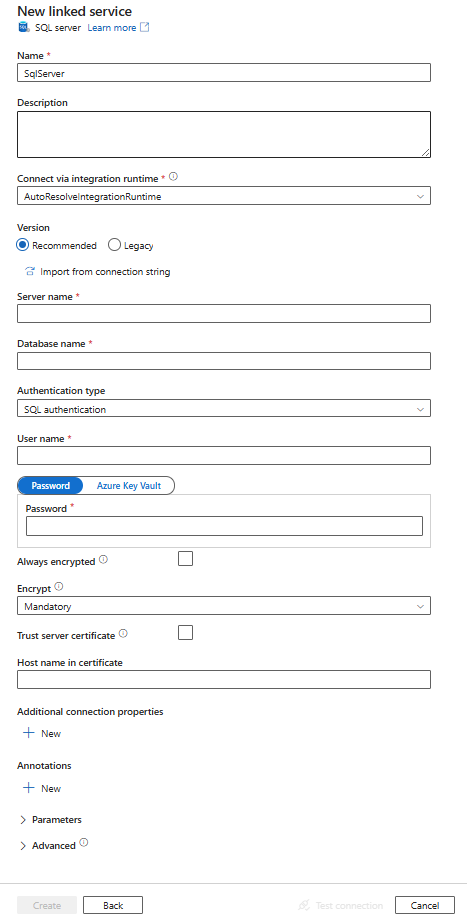
Konfigurationsinformation för anslutningsprogram
Följande avsnitt innehåller information om egenskaper som används för att definiera Data Factory- och Synapse-pipelineentiteter som är specifika för SQL Server-databasanslutningen.
Länkade tjänstegenskaper
Den rekommenderade SQL Server-versionen stöder TLS 1.3. I det här avsnittet uppgraderar du den länkade SQL Server-tjänsten om du använder äldre version. Information om egenskapen finns i motsvarande avsnitt.
Dricks
Om du stöter på ett fel med felkoden "UserErrorFailedToConnectToSqlServer" och ett meddelande som "Sessionsgränsen för databasen är XXX och har nåtts", lägger du till Pooling=false i niska veze och försöker igen.
Rekommenderad version
Dessa allmänna egenskaper stöds för en länkad SQL Server-tjänst när du använder rekommenderad version:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen måste vara inställd på SqlServer. | Ja |
| server | Namnet eller nätverksadressen för den SQL Server-instans som du vill ansluta till. | Ja |
| database | Namnet på databasen. | Ja |
| authenticationType | Den typ som används för autentisering. Tillåtna värden är SQL (standard), Windows och UserAssignedManagedIdentity (endast för SQL Server på virtuella Azure-datorer). Gå till relevant autentiseringsavsnitt om specifika egenskaper och förutsättningar. | Ja |
| alwaysEncryptedSettings | Ange alwaysencryptedsettings-information som behövs för att aktivera Always Encrypted för att skydda känsliga data som lagras i SQL Server med hjälp av antingen hanterad identitet eller tjänstens huvudnamn. Mer information finns i JSON-exemplet som följer tabellen och avsnittet Using Always Encrypted (Använda Always Encrypted ). Om den inte anges inaktiveras standardinställningen alltid krypterad. | Nej |
| kryptera | Ange om TLS-kryptering krävs för alla data som skickas mellan klienten och servern. Alternativ: obligatoriskt (för sant, standard)/valfritt (för falskt)/strikt. | Nej |
| trustServerCertificate | Ange om kanalen ska krypteras när certifikatkedjan kringgås för att verifiera förtroende. | Nej |
| hostNameInCertificate | Det värdnamn som ska användas när du verifierar servercertifikatet för anslutningen. När det inte anges används servernamnet för certifikatverifiering. | Nej |
| connectVia | Den här integreringskörningen används för att ansluta till datalagret. Läs mer i avsnittet Förutsättningar . Om det inte anges används standardkörningen för Azure-integrering. | Nej |
Ytterligare anslutningsegenskaper finns i tabellen nedan:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| applicationIntent | Programmets arbetsbelastningstyp när du ansluter till en server. Tillåtna värden är ReadOnly och ReadWrite. |
Nej |
| connectTimeout | Hur lång tid (i sekunder) det tar att vänta på en anslutning till servern innan försöket avslutas och ett fel genereras. | Nej |
| connectRetryCount | Antalet återanslutningsförsök efter identifiering av ett inaktivt anslutningsfel. Värdet ska vara ett heltal mellan 0 och 255. | Nej |
| connectRetryInterval | Hur lång tid (i sekunder) mellan varje återanslutningsförsök efter att ett inaktivt anslutningsfel har identifierats. Värdet ska vara ett heltal mellan 1 och 60. | Nej |
| loadBalanceTimeout | Den minsta tiden (i sekunder) för anslutningen att finnas i anslutningspoolen innan anslutningen förstörs. | Nej |
| commandTimeout | Standardväntetiden (i sekunder) innan du avslutar försöket att köra ett kommando och generera ett fel. | Nej |
| integratedSecurity | De tillåtna värdena är true eller false. När du falseanger anger du om userName och lösenord har angetts i anslutningen. När du trueanger anger anger du om de aktuella autentiseringsuppgifterna för Windows-kontot används för autentisering. |
Nej |
| failoverPartner | Namnet eller adressen på partnerservern som ska anslutas till om den primära servern är nere. | Nej |
| maxPoolSize | Det maximala antalet anslutningar som tillåts i anslutningspoolen för den specifika anslutningen. | Nej |
| minPoolSize | Det minsta antalet anslutningar som tillåts i anslutningspoolen för den specifika anslutningen. | Nej |
| multipleActiveResultSets | De tillåtna värdena är true eller false. När du anger truekan ett program underhålla flera aktiva resultatuppsättningar (MARS). När du anger falsemåste ett program bearbeta eller avbryta alla resultatuppsättningar från en batch innan det kan köra andra batchar på den anslutningen. |
Nej |
| multiSubnetFailover | De tillåtna värdena är true eller false. Om ditt program ansluter till en AlwaysOn-tillgänglighetsgrupp (AG) i olika undernät kan du ange att true den här egenskapen ska ge snabbare identifiering av och anslutning till den aktiva servern. |
Nej |
| packetSize | Storleken i byte för de nätverkspaket som används för att kommunicera med en serverinstans. | Nej |
| poolning | De tillåtna värdena är true eller false. När du anger truekommer anslutningen att poolas. När du anger falseöppnas anslutningen explicit varje gång anslutningen begärs. |
Nej |
SQL-autentisering
Om du vill använda SQL-autentisering anger du, förutom de allmänna egenskaper som beskrivs i föregående avsnitt, följande egenskaper:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| userName | Användarnamnet som ska användas när du ansluter till servern. | Ja |
| password | Lösenordet för användarnamnet. Markera det här fältet som SecureString för att lagra det på ett säkert sätt. Eller så kan du referera till en hemlighet som lagras i Azure Key Vault. | Nej |
Exempel: Använda SQL-autentisering
{
"name": "SqlServerLinkedService",
"properties": {
"type": "SqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Exempel: Använda SQL-autentisering med ett lösenord i Azure Key Vault
{
"name": "SqlServerLinkedService",
"properties": {
"type": "SqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Exempel: Använd Always Encrypted
{
"name": "SqlServerLinkedService",
"properties": {
"type": "SqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"alwaysEncryptedSettings": {
"alwaysEncryptedAkvAuthType": "ServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Windows-autentisering
Om du vill använda Windows-autentisering anger du, förutom de allmänna egenskaper som beskrivs i föregående avsnitt, följande egenskaper:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| userName | Ange ett användarnamn. Ett exempel är domännamn\användarnamn. | Ja |
| password | Ange ett lösenord för det användarkonto som du angav för användarnamnet. Markera det här fältet som SecureString för att lagra det på ett säkert sätt. Eller så kan du referera till en hemlighet som lagras i Azure Key Vault. | Ja |
Kommentar
Windows-autentisering stöds inte i dataflödet.
Exempel: Använda Windows-autentisering
{
"name": "SqlServerLinkedService",
"properties": {
"type": "SqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "Windows",
"userName": "<domain\\username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Exempel: Använda Windows-autentisering med ett lösenord i Azure Key Vault
{
"name": "SqlServerLinkedService",
"properties": {
"annotations": [],
"type": "SqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "Windows",
"userName": "<domain\\username>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Användartilldelad hanterad identitetsautentisering
Kommentar
Den användartilldelade hanterade identitetsautentiseringen gäller endast för SQL Server på virtuella Azure-datorer.
En datafabrik eller Synapse-arbetsyta kan associeras med en användartilldelad hanterad identitet som representerar tjänsten när den autentiseras mot andra resurser i Azure. Du kan använda den här hanterade identiteten för SQL Server på autentisering med virtuella Azure-datorer . Den avsedda fabriken eller Synapse-arbetsytan kan komma åt och kopiera data från eller till databasen med hjälp av den här identiteten.
Om du vill använda användartilldelad hanterad identitetsautentisering anger du, förutom de allmänna egenskaper som beskrivs i föregående avsnitt, följande egenskaper:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| autentiseringsuppgifter | Ange den användartilldelade hanterade identiteten som autentiseringsobjekt. | Ja |
Du måste också följa stegen nedan:
Bevilja behörigheter till din användartilldelade hanterade identitet.
Aktivera Microsoft Entra-autentisering till din SQL Server på virtuella Azure-datorer.
Skapa inneslutna databasanvändare för den användartilldelade hanterade identiteten. Anslut till databasen från eller till vilken du vill kopiera data med hjälp av verktyg som SQL Server Management Studio, med en Microsoft Entra-identitet som har minst ALTER ANY USER-behörighet. Kör följande T-SQL:
CREATE USER [your_resource_name] FROM EXTERNAL PROVIDER;Skapa en eller flera användartilldelade hanterade identiteter och ge den användartilldelade hanterade identiteten nödvändiga behörigheter som du normalt gör för SQL-användare och andra. Kör följande kod. Fler alternativ finns i det här dokumentet.
ALTER ROLE [role name] ADD MEMBER [your_resource_name];Tilldela en eller flera användartilldelade hanterade identiteter till din datafabrik och skapa autentiseringsuppgifter för varje användartilldelad hanterad identitet.
Konfigurera en länkad SQL Server-tjänst.
Exempel
{
"name": "SqlServerLinkedService",
"properties": {
"type": "SqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "UserAssignedManagedIdentity",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Äldre version
Dessa allmänna egenskaper stöds för en länkad SQL Server-tjänst när du använder äldre version:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen måste vara inställd på SqlServer. | Ja |
| alwaysEncryptedSettings | Ange alwaysencryptedsettings-information som behövs för att aktivera Always Encrypted för att skydda känsliga data som lagras i SQL Server med hjälp av antingen hanterad identitet eller tjänstens huvudnamn. Mer information finns i avsnittet Använda Always Encrypted . Om den inte anges inaktiveras standardinställningen alltid krypterad. | Nej |
| connectVia | Den här integreringskörningen används för att ansluta till datalagret. Läs mer i avsnittet Förutsättningar . Om det inte anges används standardkörningen för Azure-integrering. | Nej |
Den här SQL Server-anslutningsappen stöder följande autentiseringstyper. Mer information finns i motsvarande avsnitt.
SQL-autentisering för den äldre versionen
Om du vill använda SQL-autentisering anger du, förutom de allmänna egenskaper som beskrivs i föregående avsnitt, följande egenskaper:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| connectionString | Ange connectionString-information som behövs för att ansluta till SQL Server-databasen. Ange ett inloggningsnamn som användarnamn och se till att databasen som du vill ansluta är mappad till den här inloggningen. | Ja |
| password | Om du vill lägga till ett lösenord i Azure Key Vault kan du hämta konfigurationen password från niska veze. Mer information finns i Lagra autentiseringsuppgifter i Azure Key Vault. |
Nej |
Windows-autentisering för den äldre versionen
Om du vill använda Windows-autentisering anger du, förutom de allmänna egenskaper som beskrivs i föregående avsnitt, följande egenskaper:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| connectionString | Ange connectionString-information som behövs för att ansluta till SQL Server-databasen. | Ja |
| userName | Ange ett användarnamn. Ett exempel är domännamn\användarnamn. | Ja |
| password | Ange ett lösenord för det användarkonto som du angav för användarnamnet. Markera det här fältet som SecureString för att lagra det på ett säkert sätt. Eller så kan du referera till en hemlighet som lagras i Azure Key Vault. | Ja |
Egenskaper för datauppsättning
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera datauppsättningar finns i artikeln datauppsättningar . Det här avsnittet innehåller en lista över egenskaper som stöds av SQL Server-datauppsättningen.
Följande egenskaper stöds för att kopiera data från och till en SQL Server-databas:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Datamängdens typegenskap måste anges till SqlServerTable. | Ja |
| schema | Namnet på schemat. | Nej för källa, Ja för mottagare |
| table | Namnet på tabellen/vyn. | Nej för källa, Ja för mottagare |
| tableName | Namnet på tabellen/vyn med schemat. Den här egenskapen stöds för bakåtkompatibilitet. För ny arbetsbelastning använder du schema och table. |
Nej för källa, Ja för mottagare |
Exempel
{
"name": "SQLServerDataset",
"properties":
{
"type": "SqlServerTable",
"linkedServiceName": {
"referenceName": "<SQL Server linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
Kopiera egenskaper för aktivitet
En fullständig lista över avsnitt och egenskaper som är tillgängliga för användning för att definiera aktiviteter finns i artikeln Pipelines . Det här avsnittet innehåller en lista över egenskaper som stöds av SQL Server-källan och mottagaren.
SQL Server som källa
Dricks
Om du vill läsa in data från SQL Server effektivt med hjälp av datapartitionering kan du läsa mer från Parallell kopiering från SQL-databas.
Om du vill kopiera data från SQL Server anger du källtypen i kopieringsaktiviteten till SqlSource. Följande egenskaper stöds i avsnittet kopieringsaktivitetskälla:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen för kopieringsaktivitetskällan måste anges till SqlSource. | Ja |
| sqlReaderQuery | Använd den anpassade SQL-frågan för att läsa data. Ett exempel är select * from MyTable. |
Nej |
| sqlReaderStoredProcedureName | Den här egenskapen är namnet på den lagrade proceduren som läser data från källtabellen. Den sista SQL-instruktionen måste vara en SELECT-instruktion i den lagrade proceduren. | Nej |
| storedProcedureParameters | Dessa parametrar är för den lagrade proceduren. Tillåtna värden är namn- eller värdepar. Parametrarnas namn och hölje måste matcha namnen och höljet för de lagrade procedureparametrarna. |
Nej |
| isolationLevel | Anger transaktionslåsningsbeteendet för SQL-källan. De tillåtna värdena är: ReadCommitted, ReadUncommitted, RepeatableRead, Serializable, Snapshot. Om den inte anges används databasens standardisoleringsnivå. Mer information finns i det här dokumentet. | Nej |
| partitionOptions | Anger de datapartitioneringsalternativ som används för att läsa in data från SQL Server. Tillåtna värden är: Ingen (standard), PhysicalPartitionsOfTable och DynamicRange. När ett partitionsalternativ är aktiverat (dvs. inte None) styrs graden av parallellitet för samtidig inläsning av data från SQL Server av parallelCopies inställningen för kopieringsaktiviteten. |
Nej |
| partitionSettings | Ange gruppen med inställningarna för datapartitionering. Använd när partitionsalternativet inte Noneär . |
Nej |
Under partitionSettings: |
||
| partitionColumnName | Ange namnet på källkolumnen i heltal eller datum/datetime-typ (int, , bigintsmallint, date, smalldatetime, datetime, datetime2eller datetimeoffset) som ska användas av intervallpartitionering för parallell kopiering. Om det inte anges identifieras indexet eller den primära nyckeln i tabellen automatiskt och används som partitionskolumn.Använd när partitionsalternativet är DynamicRange. Om du använder en fråga för att hämta källdata kopplar ?DfDynamicRangePartitionCondition du in WHERE-satsen. Ett exempel finns i avsnittet Parallellkopiering från SQL-databas . |
Nej |
| partitionUpperBound | Det maximala värdet för partitionskolumnen för partitionsintervalldelning. Det här värdet används för att bestämma partitionssteget, inte för att filtrera raderna i tabellen. Alla rader i tabellen eller frågeresultatet partitioneras och kopieras. Om det inte anges identifierar kopieringsaktivitet automatiskt värdet. Använd när partitionsalternativet är DynamicRange. Ett exempel finns i avsnittet Parallellkopiering från SQL-databas . |
Nej |
| partitionLowerBound | Minimivärdet för partitionskolumnen för partitionsintervalldelning. Det här värdet används för att bestämma partitionssteget, inte för att filtrera raderna i tabellen. Alla rader i tabellen eller frågeresultatet partitioneras och kopieras. Om det inte anges identifierar kopieringsaktivitet automatiskt värdet. Använd när partitionsalternativet är DynamicRange. Ett exempel finns i avsnittet Parallellkopiering från SQL-databas . |
Nej |
Observera följande:
- Om sqlReaderQuery har angetts för SqlSource kör kopieringsaktiviteten den här frågan mot SQL Server-källan för att hämta data. Du kan också ange en lagrad procedur genom att ange sqlReaderStoredProcedureName och storedProcedureParameters om den lagrade proceduren tar parametrar.
- När du använder lagrad procedur i källan för att hämta data bör du tänka på att om den lagrade proceduren är utformad som att returnera ett annat schema när ett annat parametervärde skickas in, kan det uppstå ett fel eller ett oväntat resultat när du importerar schemat från användargränssnittet eller när du kopierar data till SQL Database med automatisk tabellskapande.
Exempel: Använda SQL-fråga
"activities":[
{
"name": "CopyFromSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<SQL Server input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
"sqlReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Exempel: Använd en lagrad procedur
"activities":[
{
"name": "CopyFromSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<SQL Server input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
"sqlReaderStoredProcedureName": "CopyTestSrcStoredProcedureWithParameters",
"storedProcedureParameters": {
"stringData": { "value": "str3" },
"identifier": { "value": "$$Text.Format('{0:yyyy}', <datetime parameter>)", "type": "Int"}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Definitionen för lagrad procedur
CREATE PROCEDURE CopyTestSrcStoredProcedureWithParameters
(
@stringData varchar(20),
@identifier int
)
AS
SET NOCOUNT ON;
BEGIN
select *
from dbo.UnitTestSrcTable
where dbo.UnitTestSrcTable.stringData != stringData
and dbo.UnitTestSrcTable.identifier != identifier
END
GO
SQL Server som mottagare
Dricks
Läs mer om de skrivbeteenden, konfigurationer och metodtips som stöds från Metodtips för inläsning av data till SQL Server.
Om du vill kopiera data till SQL Server anger du mottagartypen i kopieringsaktiviteten till SqlSink. Följande egenskaper stöds i avsnittet kopieringsaktivitetsmottagare:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen för kopieringsaktivitetsmottagaren måste anges till SqlSink. | Ja |
| preCopyScript | Den här egenskapen anger en SQL-fråga för kopieringsaktiviteten som ska köras innan data skrivs till SQL Server. Den anropas bara en gång per kopieringskörning. Du kan använda den här egenskapen för att rensa inlästa data. | Nej |
| tableOption | Anger om mottagartabellen ska skapas automatiskt om den inte finns baserat på källschemat. Automatisk tabellskapande stöds inte när mottagaren anger lagrad procedur. Tillåtna värden är: none (standard), autoCreate. |
Nej |
| sqlWriterStoredProcedureName | Namnet på den lagrade procedur som definierar hur källdata ska tillämpas i en måltabell. Den här lagrade proceduren anropas per batch. För åtgärder som bara körs en gång och inte har något att göra med källdata, till exempel ta bort eller trunkera, använder du preCopyScript egenskapen.Se exempel från Anropa en lagrad procedur från en SQL-mottagare. |
Nej |
| storedProcedureTableTypeParameterName | Parameternamnet för den tabelltyp som anges i den lagrade proceduren. | Nej |
| sqlWriterTableType | Tabelltypens namn som ska användas i den lagrade proceduren. Kopieringsaktiviteten gör data som flyttas tillgängliga i en temporär tabell med den här tabelltypen. Lagrad procedurkod kan sedan sammanfoga data som kopieras med befintliga data. | Nej |
| storedProcedureParameters | Parametrar för den lagrade proceduren. Tillåtna värden är namn- och värdepar. Namn och hölje för parametrar måste matcha namnen och höljet för de lagrade procedureparametrarna. |
Nej |
| writeBatchSize | Antal rader som ska infogas i SQL-tabellen per batch. Tillåtna värden är heltal för antalet rader. Som standard avgör tjänsten dynamiskt lämplig batchstorlek baserat på radstorleken. |
Nej |
| writeBatchTimeout | Väntetiden för att åtgärden infoga, upsert och lagrad procedur ska slutföras innan tidsgränsen uppnås. Tillåtna värden är för tidsintervallet. Ett exempel är "00:30:00" i 30 minuter. Om inget värde anges är tidsgränsen som standard "00:30:00". |
Nej |
| maxConcurrentConnections | Den övre gränsen för samtidiga anslutningar som upprättats till datalagret under aktivitetskörningen. Ange endast ett värde när du vill begränsa samtidiga anslutningar. | Nej |
| WriteBehavior | Ange skrivbeteendet för kopieringsaktiviteten för att läsa in data till SQL Server Database. Det tillåtna värdet är Insert och Upsert. Som standard använder tjänsten insert för att läsa in data. |
Nej |
| upsertSettings | Ange gruppen med inställningarna för skrivbeteende. Använd när alternativet WriteBehavior är Upsert. |
Nej |
Under upsertSettings: |
||
| useTempDB | Ange om du vill använda den globala temporära tabellen eller den fysiska tabellen som interimtabell för upsert. Tjänsten använder som standard global tillfällig tabell som interimtabell. värdet är true. |
Nej |
| interimSchemaName | Ange interimschemat för att skapa interimtabell om fysisk tabell används. Obs! Användaren måste ha behörighet att skapa och ta bort tabellen. Som standard delar interimtabellen samma schema som mottagartabellen. Använd när alternativet useTempDB är False. |
Nej |
| keys | Ange kolumnnamnen för unik radidentifiering. Antingen kan en enskild nyckel eller en serie nycklar användas. Om den inte anges används primärnyckeln. | Nej |
Exempel 1: Lägga till data
"activities":[
{
"name": "CopyToSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<SQL Server output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SqlSink",
"tableOption": "autoCreate",
"writeBatchSize": 100000
}
}
}
]
Exempel 2: Anropa en lagrad procedur under kopieringen
Läs mer i Anropa en lagrad procedur från en SQL-mottagare.
"activities":[
{
"name": "CopyToSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<SQL Server output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SqlSink",
"sqlWriterStoredProcedureName": "CopyTestStoredProcedureWithParameters",
"storedProcedureTableTypeParameterName": "MyTable",
"sqlWriterTableType": "MyTableType",
"storedProcedureParameters": {
"identifier": { "value": "1", "type": "Int" },
"stringData": { "value": "str1" }
}
}
}
}
]
Exempel 3: Upsert-data
"activities":[
{
"name": "CopyToSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<SQL Server output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SqlSink",
"tableOption": "autoCreate",
"writeBehavior": "upsert",
"upsertSettings": {
"useTempDB": true,
"keys": [
"<column name>"
]
},
}
}
}
]
Parallellkopiering från SQL-databas
SQL Server-anslutningsappen i kopieringsaktiviteten tillhandahåller inbyggd datapartitionering för att kopiera data parallellt. Du hittar alternativ för datapartitionering på fliken Källa i kopieringsaktiviteten.
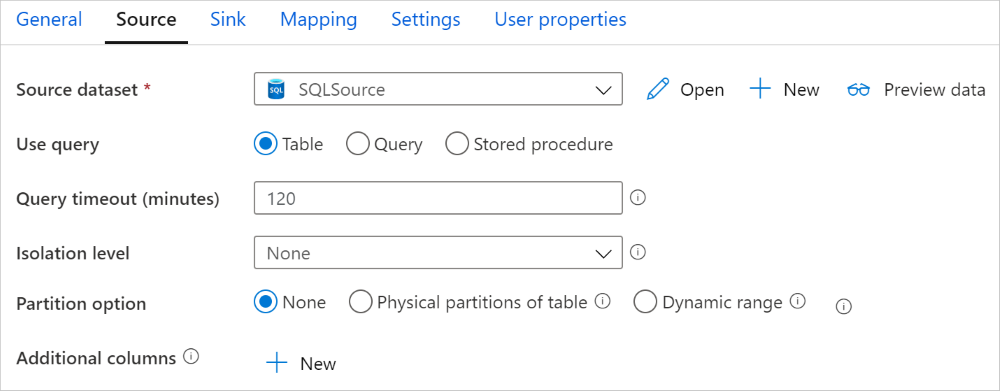
När du aktiverar partitionerad kopiering kör kopieringsaktiviteten parallella frågor mot SQL Server-källan för att läsa in data efter partitioner. Den parallella graden styrs av parallelCopies inställningen för kopieringsaktiviteten. Om du till exempel anger parallelCopies till fyra genererar och kör tjänsten samtidigt fyra frågor baserat på det angivna partitionsalternativet och inställningarna, och varje fråga hämtar en del data från SQL Server.
Du rekommenderas att aktivera parallell kopiering med datapartitionering, särskilt när du läser in stora mängder data från DIN SQL Server. Följande är föreslagna konfigurationer för olika scenarier. När du kopierar data till filbaserat datalager rekommenderar vi att du skriver till en mapp som flera filer (anger endast mappnamn), i vilket fall prestandan är bättre än att skriva till en enda fil.
| Scenario | Föreslagna inställningar |
|---|---|
| Full belastning från en stor tabell med fysiska partitioner. | Partitionsalternativ: Fysiska partitioner i tabellen. Under körningen identifierar tjänsten automatiskt de fysiska partitionerna och kopierar data efter partitioner. Om du vill kontrollera om tabellen har fysisk partition eller inte kan du läsa den här frågan. |
| Fullständig belastning från en stor tabell, utan fysiska partitioner, med ett heltal eller en datetime-kolumn för datapartitionering. | Partitionsalternativ: Partition med dynamiskt intervall. Partitionskolumn (valfritt): Ange den kolumn som används för att partitionera data. Om den inte anges används primärnyckelkolumnen. Partitionens övre gräns och partitionens nedre gräns (valfritt): Ange om du vill fastställa partitionssteget. Detta är inte för att filtrera raderna i tabellen, alla rader i tabellen partitioneras och kopieras. Om det inte anges identifierar kopieringsaktiviteten automatiskt värdena och det kan ta lång tid beroende på MIN- och MAX-värden. Vi rekommenderar att du anger övre och nedre gräns. Om partitionskolumnen "ID" till exempel har värden mellan 1 och 100 och du anger den nedre gränsen som 20 och den övre gränsen som 80, med parallell kopia som 4, hämtar tjänsten data med 4 partitioner – ID:n i intervallet <=20, [21, 50], [51, 80] >respektive =81. |
| Läs in en stor mängd data med hjälp av en anpassad fråga, utan fysiska partitioner, med ett heltal eller en date/datetime-kolumn för datapartitionering. | Partitionsalternativ: Partition med dynamiskt intervall. Fråga: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.Partitionskolumn: Ange den kolumn som används för att partitionera data. Partitionens övre gräns och partitionens nedre gräns (valfritt): Ange om du vill fastställa partitionssteget. Detta är inte för att filtrera raderna i tabellen, alla rader i frågeresultatet partitioneras och kopieras. Om det inte anges identifierar kopieringsaktivitet automatiskt värdet. Om partitionskolumnen "ID" till exempel har värden mellan 1 och 100 och du anger den nedre gränsen som 20 och den övre gränsen som 80, med parallell kopia som 4, hämtar tjänsten data med 4 partitioner – ID:n i intervallet <=20, [21, 50], [51, 80] >respektive =81. Här är fler exempelfrågor för olika scenarier: 1. Fråga hela tabellen: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition2. Fråga från en tabell med kolumnval och ytterligare where-clause-filter: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>3. Fråga med underfrågor: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>4. Fråga med partition i underfrågor: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Metodtips för att läsa in data med partitionsalternativet:
- Välj distinkt kolumn som partitionskolumn (till exempel primärnyckel eller unik nyckel) för att undvika datasnedvridning.
- Om tabellen har inbyggd partition använder du partitionsalternativet "Fysiska partitioner av tabellen" för att få bättre prestanda.
- Om du använder Azure Integration Runtime för att kopiera data kan du ange större "Data Integration Units (DIU)" (>4) för att använda mer databehandlingsresurser. Kontrollera tillämpliga scenarier där.
- "Grad av kopieringsparallellitet" styr partitionsnumren, anger det här talet för stort ibland skadar prestandan, rekommenderar att du anger det här talet som (DIU eller antalet lokalt installerade IR-noder) * (2 till 4).
Exempel: fullständig belastning från en stor tabell med fysiska partitioner
"source": {
"type": "SqlSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Exempel: fråga med partition för dynamiskt intervall
"source": {
"type": "SqlSource",
"query": "SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Exempelfråga för att kontrollera fysisk partition
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Om tabellen har en fysisk partition ser du "HasPartition" som "ja" som följande.

Bästa praxis för att läsa in data i SQL Server
När du kopierar data till SQL Server kan du kräva olika skrivbeteenden:
- Tillägg: Mina källdata har bara nya poster.
- Upsert: Mina källdata har både infogningar och uppdateringar.
- Skriv över: Jag vill läsa in hela dimensionstabellen varje gång.
- Skriv med anpassad logik: Jag behöver extra bearbetning innan den slutliga infogningen i måltabellen.
Se respektive avsnitt för hur du konfigurerar och metodtips.
Lägga till data
Att lägga till data är standardbeteendet för den här SQL Server-mottagaranslutningen. Tjänsten gör en massinfogning för att skriva till tabellen effektivt. Du kan konfigurera källan och mottagaren i enlighet med kopieringsaktiviteten.
Upserta data
Kopieringsaktiviteten stöder nu inbyggt inläsning av data i en tillfällig databastabell och uppdaterar sedan data i mottagartabellen om nyckeln finns och i övrigt infogar nya data. Mer information om upsert-inställningar i kopieringsaktiviteter finns i SQL Server som mottagare.
Skriv över hela tabellen
Du kan konfigurera egenskapen preCopyScript i en kopieringsaktivitetsmottagare. I det här fallet kör tjänsten skriptet först för varje kopieringsaktivitet som körs. Sedan körs kopian för att infoga data. Om du till exempel vill skriva över hela tabellen med de senaste data anger du ett skript för att först ta bort alla poster innan du massinläser de nya data från källan.
Skriva data med anpassad logik
Stegen för att skriva data med anpassad logik liknar de som beskrivs i avsnittet Upsert-data . När du behöver använda extra bearbetning innan du slutligen infogar källdata i måltabellen kan du läsa in till en mellanlagringstabell och sedan anropa lagrad proceduraktivitet eller anropa en lagrad procedur i kopieringsaktivitetsmottagaren för att tillämpa data.
Anropa en lagrad procedur från en SQL-mottagare
När du kopierar data till SQL Server-databasen kan du också konfigurera och anropa en användardefinierad lagrad procedur med ytterligare parametrar för varje batch i källtabellen. Funktionen lagrad procedur drar nytta av tabellvärdesparametrar. Observera att tjänsten automatiskt omsluter den lagrade proceduren i sin egen transaktion, så alla transaktioner som skapas i den lagrade proceduren blir en kapslad transaktion och kan få konsekvenser för undantagshantering.
Du kan använda en lagrad procedur när inbyggda kopieringsmekanismer inte tjänar syftet. Ett exempel är när du vill använda extra bearbetning innan källdata infogas i måltabellen. Några exempel på extra bearbetning är när du vill sammanfoga kolumner, leta upp ytterligare värden och infoga i mer än en tabell.
Följande exempel visar hur du använder en lagrad procedur för att göra en upsert till en tabell i SQL Server-databasen. Anta att indata och tabellen marknadsföring för mottagare var och en har tre kolumner: ProfileID, State och Category. Gör upsert baserat på kolumnen ProfileID och använd den bara för en specifik kategori som heter "ProductA".
I databasen definierar du tabelltypen med samma namn som sqlWriterTableType. Schemat för tabelltypen är samma som schemat som returneras av dina indata.
CREATE TYPE [dbo].[MarketingType] AS TABLE( [ProfileID] [varchar](256) NOT NULL, [State] [varchar](256) NOT NULL, [Category] [varchar](256) NOT NULL )I databasen definierar du den lagrade proceduren med samma namn som sqlWriterStoredProcedureName. Den hanterar indata från din angivna källa och sammanfogas till utdatatabellen. Parameternamnet för tabelltypen i den lagrade proceduren är detsamma som tableName som definierats i datauppsättningen.
CREATE PROCEDURE spOverwriteMarketing @Marketing [dbo].[MarketingType] READONLY, @category varchar(256) AS BEGIN MERGE [dbo].[Marketing] AS target USING @Marketing AS source ON (target.ProfileID = source.ProfileID and target.Category = @category) WHEN MATCHED THEN UPDATE SET State = source.State WHEN NOT MATCHED THEN INSERT (ProfileID, State, Category) VALUES (source.ProfileID, source.State, source.Category); ENDDefiniera avsnittet SQL-mottagare i kopieringsaktiviteten enligt följande:
"sink": { "type": "SqlSink", "sqlWriterStoredProcedureName": "spOverwriteMarketing", "storedProcedureTableTypeParameterName": "Marketing", "sqlWriterTableType": "MarketingType", "storedProcedureParameters": { "category": { "value": "ProductA" } } }
Mappa dataflödesegenskaper
När du transformerar data i dataflödet för mappning kan du läsa och skriva till tabeller från SQL Server Database. Mer information finns i källtransformering och mottagartransformation i mappning av dataflöden.
Kommentar
För att få åtkomst till lokal SQL Server måste du använda Azure Data Factory eller Synapse-arbetsytan Hanterat virtuellt nätverk med hjälp av en privat slutpunkt. Mer information finns i den här självstudien .
Källtransformering
I tabellen nedan visas de egenskaper som stöds av SQL Server-källan. Du kan redigera dessa egenskaper på fliken Källalternativ .
| Name | beskrivning | Obligatoriskt | Tillåtna värden | Egenskap för dataflödesskript |
|---|---|---|---|---|
| Register | Om du väljer Tabell som indata hämtar dataflödet alla data från tabellen som anges i datauppsättningen. | Nej | - | - |
| Fråga | Om du väljer Fråga som indata anger du en SQL-fråga för att hämta data från källan, vilket åsidosätter alla tabeller som du anger i datauppsättningen. Att använda frågor är ett bra sätt att minska antalet rader för testning eller sökningar. Order By-satsen stöds inte, men du kan ange en fullständig SELECT FROM-instruktion. Du kan också använda användardefinierade tabellfunktioner. select * from udfGetData() är en UDF i SQL som returnerar en tabell som du kan använda i dataflödet. Frågeexempel: Select * from MyTable where customerId > 1000 and customerId < 2000 |
Nej | String | query |
| Batchstorlek | Ange en batchstorlek för att segmentera stora data i läsningar. | Nej | Integer | batchSize |
| Isoleringsnivå | Välj någon av följande isoleringsnivåer: - Läs bekräftad – Läs ej genererad (standard) – Repeterbar läsning -Serialiseras – Ingen (ignorera isoleringsnivå) |
Nej | READ_COMMITTED READ_UNCOMMITTED REPEATABLE_READ SERIALISERAS INGET |
isolationLevel |
| Aktivera inkrementellt extrahering | Använd det här alternativet om du vill be ADF att endast bearbeta rader som har ändrats sedan den senaste gången pipelinen kördes. | Nej | - | - |
| Inkrementell datumkolumn | När du använder funktionen för inkrementell extrahering måste du välja den datum/tid-kolumn som du vill använda som vattenstämpel i källtabellen. | Nej | - | - |
| Aktivera intern ändringsdatainsamling (förhandsversion) | Använd det här alternativet om du vill be ADF att endast bearbeta deltadata som samlats in av SQL:s datainsamlingsteknik sedan den senaste gången pipelinen kördes. Med det här alternativet läses deltadata inklusive radinfogning, uppdatering och borttagning in automatiskt utan att någon inkrementell datumkolumn krävs. Du måste aktivera insamling av ändringsdata på SQL Server innan du använder det här alternativet i ADF. Mer information om det här alternativet i ADF finns i intern insamling av ändringsdata. | Nej | - | - |
| Börja läsa från början | Om du anger det här alternativet med inkrementellt extrahering instrueras ADF att läsa alla rader vid första körningen av en pipeline med inkrementellt extrahering aktiverat. | Nej | - | - |
Dricks
Det gemensamma tabelluttrycket (CTE) i SQL stöds inte i frågeläget för mappningsdataflödet, eftersom förutsättningen för att använda det här läget är att frågor kan användas i SQL-fråge-FROM-satsen, men DET går inte att göra detta. Om du vill använda CTE:er måste du skapa en lagrad procedur med hjälp av följande fråga:
CREATE PROC CTESP @query nvarchar(max)
AS
BEGIN
EXECUTE sp_executesql @query;
END
Använd sedan läget Lagrad procedur i källomvandlingen av dataflödet för mappning och ange @query exemplet like with CTE as (select 'test' as a) select * from CTE. Sedan kan du använda CTE:er som förväntat.
Exempel på SQL Server-källskript
När du använder SQL Server som källtyp är det associerade dataflödesskriptet:
source(allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
query: 'select * from MYTABLE',
format: 'query') ~> SQLSource
Transformering av mottagare
I tabellen nedan visas de egenskaper som stöds av SQL Server-mottagare. Du kan redigera dessa egenskaper på fliken Alternativ för mottagare.
| Name | beskrivning | Obligatoriskt | Tillåtna värden | Egenskap för dataflödesskript |
|---|---|---|---|---|
| Uppdatera metod | Ange vilka åtgärder som tillåts på databasmålet. Standardvärdet är att endast tillåta infogningar. För att uppdatera, öka eller ta bort rader krävs en Alter row-transformering för att tagga rader för dessa åtgärder. |
Ja | true eller false |
kan tas bort infogningsbar kan uppdateras upsertable |
| Nyckelkolumner | För uppdateringar, upserts och borttagningar måste nyckelkolumner anges för att avgöra vilken rad som ska ändras. Kolumnnamnet som du väljer som nyckel används som en del av den efterföljande uppdateringen, upsert, delete. Därför måste du välja en kolumn som finns i mappningen mottagare. |
Nej | Matris | keys |
| Hoppa över att skriva nyckelkolumner | Om du inte vill skriva värdet till nyckelkolumnen väljer du "Hoppa över att skriva nyckelkolumner". | Nej | true eller false |
skipKeyWrites |
| Tabellåtgärd | Avgör om du vill återskapa eller ta bort alla rader från måltabellen innan du skriver. - Ingen: Ingen åtgärd utförs i tabellen. - Återskapa: Tabellen tas bort och återskapas. Krävs om du skapar en ny tabell dynamiskt. - Trunkera: Alla rader från måltabellen tas bort. |
Nej | true eller false |
återskapa trunkera |
| Batchstorlek | Ange hur många rader som skrivs i varje batch. Större batchstorlekar förbättrar komprimering och minnesoptimering, men riskerar att få slut på minnesfel vid cachelagring av data. | Nej | Integer | batchSize |
| Pre- och Post SQL-skript | Ange sql-skript med flera rader som ska köras före (förbearbetning) och efter att (efterbearbetning) data har skrivits till mottagardatabasen. | Nej | String | preSQLs postSQLs |
Dricks
- Vi rekommenderar att du bryter enskilda batchskript med flera kommandon i flera batchar.
- Det går endast att köra instruktioner av typen Data Definition Language (DDL) och Data Manipulation Language (DML), som returnerar ett enda uppdateringsvärde, som del av en batch. Läs mer om att utföra batchåtgärder
Exempel på SQL Server-mottagarskript
När du använder SQL Server som mottagartyp är det associerade dataflödesskriptet:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:true,
updateable:true,
upsertable:true,
keys:['keyColumn'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> SQLSink
Datatypsmappning för SQL Server
När du kopierar data från och till SQL Server används följande mappningar från SQL Server-datatyper till mellanliggande datatyper i Azure Data Factory. Synapse-pipelines, som implementerar Data Factory, använder samma mappningar. Information om hur kopieringsaktiviteten mappar källschemat och datatypen till mottagaren finns i Schema- och datatypmappningar.
| SQL Server-datatyp | Data Factory interim datatyp |
|---|---|
| bigint | Int64 |
| binary | Byte[] |
| bit | Booleskt |
| char | Sträng, tecken[] |
| datum | Datum/tid |
| Datetime | Datum/tid |
| datetime2 | Datum/tid |
| Datetimeoffset | DateTimeOffset |
| Decimal | Decimal |
| FILESTREAM-attribut (varbinary(max)) | Byte[] |
| Flyttal | Dubbel |
| bild | Byte[] |
| heltal | Int32 |
| money | Decimal |
| nchar | Sträng, tecken[] |
| ntext | Sträng, tecken[] |
| numeric | Decimal |
| nvarchar | Sträng, tecken[] |
| real | Enstaka |
| rowversion | Byte[] |
| smalldatetime | Datum/tid |
| smallint | Int16 |
| smallmoney | Decimal |
| sql_variant | Objekt |
| text | Sträng, tecken[] |
| time | TimeSpan |
| timestamp | Byte[] |
| tinyint | Int16 |
| uniqueidentifier | GUID |
| varbinary | Byte[] |
| varchar | Sträng, tecken[] |
| xml | String |
Kommentar
För datatyper som mappas till interimstypen Decimal stöder kopieringsaktiviteten för närvarande precision upp till 28. Om du har data som kräver en precision som är större än 28 kan du överväga att konvertera till en sträng i en SQL-fråga.
När du kopierar data från SQL Server med Azure Data Factory mappas bitdatatypen till den booleska interimsdatatypen. Om du har data som måste behållas som bitdatatyp använder du frågor med T-SQL CAST eller CONVERT.
Egenskaper för uppslagsaktivitet
Mer information om egenskaperna finns i Sökningsaktivitet.
Egenskaper för GetMetadata-aktivitet
Mer information om egenskaperna finns i GetMetadata-aktivitet
Använda Always Encrypted
När du kopierar data från/till SQL Server med Always Encrypted följer du stegen nedan:
Lagra kolumnhuvudnyckeln (CMK) i ett Azure Key Vault. Läs mer om hur du konfigurerar Always Encrypted med hjälp av Azure Key Vault
Se till att ge åtkomst till nyckelvalvet där kolumnhuvudnyckeln (CMK) lagras. I den här artikeln finns nödvändiga behörigheter.
Skapa en länkad tjänst för att ansluta till din SQL-databas och aktivera funktionen Always Encrypted med hjälp av antingen hanterad identitet eller tjänstens huvudnamn.
Kommentar
SQL Server Always Encrypted stöder följande scenarier:
- Antingen käll- eller mottagardatalager använder hanterad identitet eller tjänstens huvudnamn som autentiseringstyp för nyckelprovider.
- Både käll- och mottagardatalager använder hanterad identitet som autentiseringstyp för nyckelprovider.
- Både käll- och mottagardatalager använder samma tjänsthuvudnamn som nyckelproviderns autentiseringstyp.
Kommentar
För närvarande stöds SQL Server Always Encrypted endast för källtransformering i mappning av dataflöden.
Intern insamling av ändringsdata
Azure Data Factory har stöd för inbyggda funktioner för insamling av ändringsdata för SQL Server, Azure SQL DB och Azure SQL MI. Ändrade data, inklusive radinfogning, uppdatering och borttagning i SQL-lager, kan automatiskt identifieras och extraheras av ADF-mappningsdataflödet. Utan kodupplevelse i mappning av dataflöde kan användarna enkelt uppnå datareplikeringsscenario från SQL-lager genom att lägga till en databas som mållager. Dessutom kan användarna också skapa datatransformeringslogik mellan för att uppnå inkrementellt ETL-scenario från SQL-lager.
Kontrollera att pipelinen och aktivitetsnamnet är oförändrade så att kontrollpunkten kan registreras av ADF så att du kan hämta ändrade data från den senaste körningen automatiskt. Om du ändrar pipelinens namn eller aktivitetsnamn återställs kontrollpunkten, vilket leder till att du börjar från början eller hämtar ändringar från och med nu i nästa körning. Om du vill ändra pipelinenamnet eller aktivitetsnamnet men ändå behålla kontrollpunkten för att hämta ändrade data från den senaste körningen automatiskt använder du din egen kontrollpunktsnyckel i dataflödesaktiviteten för att uppnå detta.
När du felsöker pipelinen fungerar den här funktionen på samma sätt. Tänk på att kontrollpunkten återställs när du uppdaterar webbläsaren under felsökningskörningen. När du är nöjd med pipelineresultatet från felsökningskörningen kan du publicera och utlösa pipelinen. När du första gången utlöser den publicerade pipelinen startas den automatiskt om från början eller hämtar ändringar från och med nu.
I övervakningsavsnittet har du alltid chansen att köra en pipeline igen. När du gör det registreras alltid ändrade data från den tidigare kontrollpunkten för den valda pipelinekörningen.
Exempel 1:
När du direkt kedjar en källtransformering som refereras till SQL CDC-aktiverad datauppsättning med en mottagartransformering som refereras till en databas i ett mappningsdataflöde, tillämpas ändringarna på SQL-källan automatiskt på måldatabasen, så att du enkelt kan få datareplikeringsscenario mellan databaser. Du kan använda uppdateringsmetoden i mottagartransformering för att välja om du vill tillåta infogning, tillåta uppdatering eller tillåta borttagning i måldatabasen. Exempelskriptet i mappningsdataflödet är som nedan.
source(output(
id as integer,
name as string
),
allowSchemaDrift: true,
validateSchema: false,
enableNativeCdc: true,
netChanges: true,
skipInitialLoad: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source1 sink(allowSchemaDrift: true,
validateSchema: false,
deletable:true,
insertable:true,
updateable:true,
upsertable:true,
keys:['id'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true,
errorHandlingOption: 'stopOnFirstError') ~> sink1
Exempel 2:
Om du vill aktivera ETL-scenario i stället för datareplikering mellan databasen via SQL CDC kan du använda uttryck i mappning av dataflöde, inklusive isInsert(1), isUpdate(1) och isDelete(1) för att särskilja raderna med olika åtgärdstyper. Följande är ett av exempelskripten för att mappa dataflöde på att härleda en kolumn med värdet: 1 för att ange infogade rader, 2 för att ange uppdaterade rader och 3 för att ange borttagna rader för underordnade transformeringar för att bearbeta deltadata.
source(output(
id as integer,
name as string
),
allowSchemaDrift: true,
validateSchema: false,
enableNativeCdc: true,
netChanges: true,
skipInitialLoad: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source1 derive(operationType = iif(isInsert(1), 1, iif(isUpdate(1), 2, 3))) ~> derivedColumn1
derivedColumn1 sink(allowSchemaDrift: true,
validateSchema: false,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> sink1
Känd begränsning:
- Endast nettoändringar från SQL CDC läses in av ADF via cdc.fn_cdc_get_net_changes_.
Felsöka anslutningsproblem
Konfigurera SQL Server-instansen så att den accepterar fjärranslutningar. Starta SQL Server Management Studio, högerklicka på servern och välj Egenskaper. Välj Anslutningar i listan och markera kryssrutan Tillåt fjärranslutningar till den här servern .
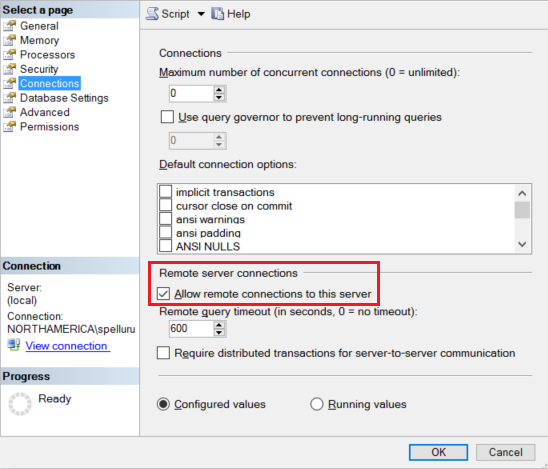
Detaljerade steg finns i Konfigurera konfigurationsalternativet för fjärråtkomstservern.
Starta Upravljač SQL Server konfiguracijom. Expandera SQL Server Network Configuration för den instans du vill använda och välj Protokoll för MSSQLSERVER. Protokoll visas i den högra rutan. Aktivera TCP/IP genom att högerklicka på TCP/IP och välja Aktivera.
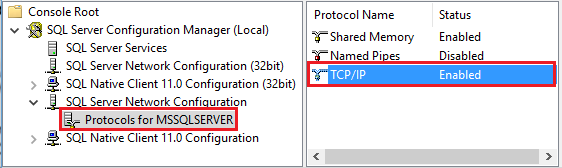
Mer information och alternativa sätt att aktivera TCP/IP-protokoll finns i Aktivera eller inaktivera ett servernätverksprotokoll.
I samma fönster dubbelklickar du på TCP/IP för att starta fönstret TCP/IP-egenskaper .
Växla till fliken IP-adresser . Rulla nedåt för att se avsnittet IPAll . Skriv ned TCP-porten. Standardvärdet är 1433.
Skapa en regel för Windows-brandväggen på datorn för att tillåta inkommande trafik via den här porten.
Verifiera anslutningen: Om du vill ansluta till SQL Server med ett fullständigt kvalificerat namn använder du SQL Server Management Studio från en annan dator. Ett exempel är
"<machine>.<domain>.corp.<company>.com,1433".
Uppgradera SQL Server-versionen
Om du vill uppgradera SQL Server-versionen går du till sidan Redigera länkad tjänst och väljer Rekommenderas under Version och konfigurerar den länkade tjänsten genom att referera till länkade tjänstegenskaper för den rekommenderade versionen.
Skillnader mellan den rekommenderade och den äldre versionen
Tabellen nedan visar skillnaderna mellan SQL Server med hjälp av den rekommenderade och äldre versionen.
| Rekommenderad version | Äldre version |
|---|---|
Stöd för TLS 1.3 via encrypt som strict. |
TLS 1.3 stöds inte. |
Relaterat innehåll
En lista över datalager som stöds som källor och mottagare av kopieringsaktiviteten finns i Datalager som stöds.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för