Analysera prestanda i Azure AI Search
Den här artikeln beskriver verktyg, beteenden och metoder för att analysera fråge- och indexeringsprestanda i Azure AI Search.
Utveckla baslinjenummer
I alla stora implementeringar är det viktigt att göra ett prestandatest för din Azure AI-usluga pretrage innan du distribuerar den i produktion. Du bör testa både sökfrågebelastningen som du förväntar dig, men även de förväntade arbetsbelastningarna för datainmatning (om möjligt kör du båda arbetsbelastningarna samtidigt). Att ha referensnummer hjälper till att verifiera rätt söknivå, tjänstkonfiguration och förväntad frågesvarstid.
För att utveckla benchmarks rekommenderar vi verktyget azure-search-performance-testing (GitHub).
Om du vill isolera effekterna av en distribuerad tjänstarkitektur kan du prova att testa tjänstkonfigurationerna för en replik och en partition.
Kommentar
För lagringsoptimerade nivåer (L1 och L2) bör du förvänta dig ett lägre frågedataflöde och högre svarstid än standardnivåerna.
Använda resursloggning
Det viktigaste diagnostikverktyget som en administratör har tillgång till är resursloggning. Resursloggning är insamling av driftdata och mått om din söktjänst. Resursloggning aktiveras via Azure Monitor. Det finns kostnader för att använda Azure Monitor och lagra data, men om du aktiverar det för din tjänst kan det vara avgörande för att undersöka prestandaproblem.
Följande bild visar händelsekedjan i en frågebegäran och ett svar. Svarstid kan inträffa på vilken som helst av dem, oavsett om det är under en nätverksöverföring, bearbetning av innehåll i apptjänstlagret eller i en söktjänst. En viktig fördel med resursloggning är att aktiviteter loggas från söktjänstens perspektiv, vilket innebär att loggen kan hjälpa dig att avgöra om prestandaproblemet beror på problem med frågan eller indexeringen eller någon annan felpunkt.
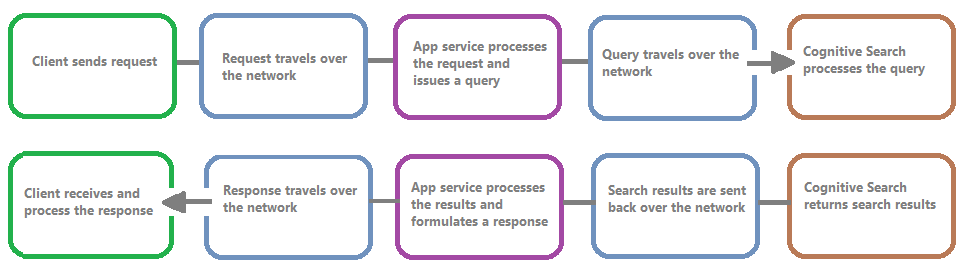
Resursloggning ger dig alternativ för att lagra loggad information. Vi rekommenderar att du använder Log Analytics så att du kan köra avancerade Kusto-frågor mot data för att besvara många frågor om användning och prestanda.
På söktjänstportalsidorna kan du aktivera loggning via diagnostikinställningar och sedan utfärda Kusto-frågor mot Log Analytics genom att välja Loggar. Information om hur du skickar resursloggar till en Log Analytics-arbetsyta där du kan analysera dem med loggfrågor finns i Samla in och analysera resursloggar från en Azure-resurs.
Begränsningsbeteenden
Begränsning sker när söktjänsten har kapacitet. Begränsning kan ske under frågor eller indexering. Från klientsidan resulterar ett API-anrop i ett 503 HTTP-svar när det har begränsats. Under indexeringen finns det också möjlighet att ta emot ett HTTP-svar från 207, vilket indikerar att ett eller flera objekt inte kunde indexeras. Det här felet är en indikator på att söktjänsten närmar sig kapaciteten.
Som tumregel försöker du kvantifiera mängden begränsning och eventuella mönster. Om en sökfråga av 500 000 till exempel begränsas kanske det inte är värt att undersöka. Men om en stor andel frågor begränsas under en period skulle detta vara ett större problem. Genom att titta på begränsning under en period hjälper det också till att identifiera tidsramar där begränsning kan uppstå mer sannolikt och hjälper dig att bestämma hur du bäst ska hantera detta.
En enkel korrigering av de flesta begränsningsproblem är att kasta fler resurser i söktjänsten (vanligtvis repliker för frågebaserad begränsning eller partitioner för indexeringsbaserad begränsning). Att öka repliker eller partitioner medför dock kostnader, vilket är anledningen till att det är viktigt att veta orsaken till att begränsning sker alls. Att undersöka de villkor som orsakar begränsning förklaras i de kommande avsnitten.
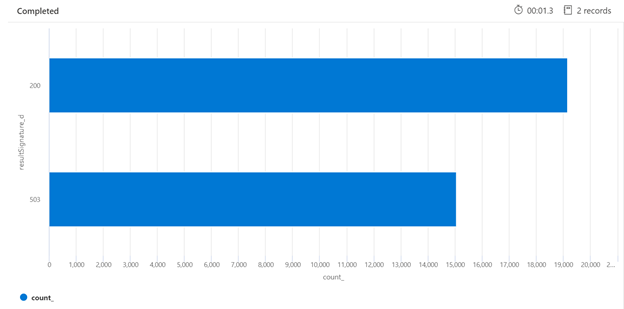
Nedan visas ett exempel på en Kusto-fråga som kan identifiera uppdelningen av HTTP-svar från söktjänsten som har lästs in. Under en sjudagarsperiod visar det renderade stapeldiagrammet att en relativt stor andel av sökfrågorna begränsades, jämfört med antalet lyckade (200) svar.
AzureDiagnostics
| where TimeGenerated > ago(7d)
| summarize count() by resultSignature_d
| render barchart
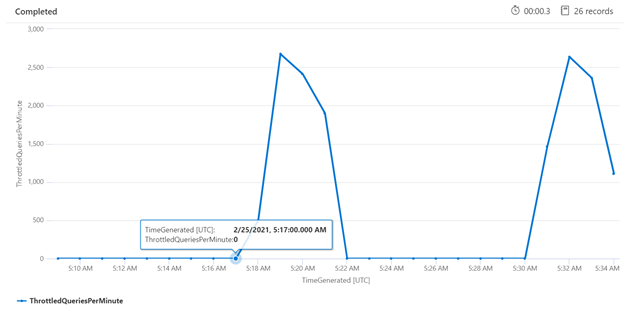
Genom att undersöka begränsning under en viss tidsperiod kan du identifiera de tider då begränsning kan ske oftare. I exemplet nedan används ett tidsseriediagram för att visa antalet begränsade frågor som inträffat under en angiven tidsram. I det här fallet utfördes de begränsade frågorna som korrelerade med tiderna i med prestandamätningen.
let ['_startTime']=datetime('2021-02-25T20:45:07Z');
let ['_endTime']=datetime('2021-03-03T20:45:07Z');
let intervalsize = 1m;
AzureDiagnostics
| where TimeGenerated > ago(7d)
| where resultSignature_d != 403 and resultSignature_d != 404 and OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete")
| summarize
ThrottledQueriesPerMinute=bin(countif(OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete") and resultSignature_d == 503)/(intervalsize/1m), 0.01)
by bin(TimeGenerated, intervalsize)
| render timechart
Mäta enskilda frågor
I vissa fall kan det vara användbart att testa enskilda frågor för att se hur de fungerar. För att göra detta är det viktigt att kunna se hur lång tid det tar för söktjänsten att slutföra arbetet, samt hur lång tid det tar att skicka begäran från klienten och tillbaka till klienten. Diagnostikloggarna kan användas för att söka efter enskilda åtgärder, men det kan vara enklare att göra allt från en REST-klient.
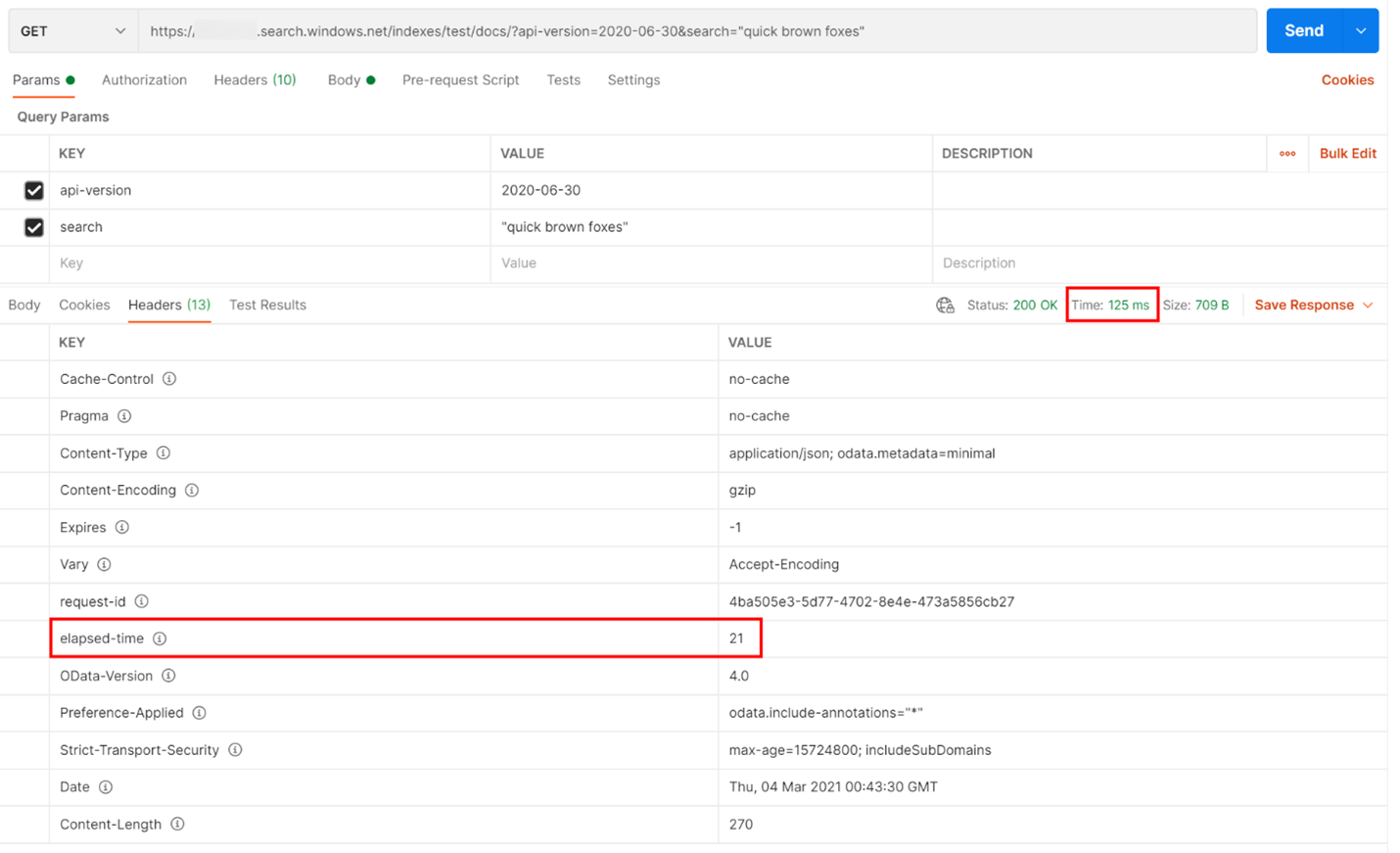
I exemplet nedan kördes en REST-baserad sökfråga. Azure AI Search innehåller i varje svar det antal millisekunder som krävs för att slutföra frågan, synlig på fliken Rubriker, i "förfluten tid". Bredvid Status överst i svaret hittar du varaktigheten för tur och retur, i det här fallet 418 millisekunder (ms). I resultatavsnittet valdes fliken "Rubriker". Med hjälp av dessa två värden, markerade med en röd ruta i bilden nedan, ser vi att söktjänsten tog 21 ms för att slutföra sökfrågan och hela klientbegäran tog 125 ms. Genom att subtrahera dessa två tal kan vi fastställa att det tog 104 ms extra tid att överföra sökfrågan till söktjänsten och överföra sökresultaten tillbaka till klienten.
Den här tekniken hjälper dig att isolera nätverksfördröjningar från andra faktorer som påverkar frågeprestanda.
Frågefrekvenser
En möjlig orsak till att din söktjänst begränsar begäranden beror på det stora antalet frågor som utförs där volymen registreras som frågor per sekund (QPS) eller frågor per minut (QPM). När din söktjänst får fler QPS tar det vanligtvis längre och längre tid att svara på dessa frågor tills den inte längre kan hänga med, vilket gör att den skickar tillbaka ett begränsningssvar på 503 HTTP.
Följande Kusto-fråga visar frågevolymen mätt i QPM, tillsammans med genomsnittlig varaktighet för en fråga i millisekunder (AvgDurationMS) och det genomsnittliga antalet dokument (AvgDocCountReturned) som returneras i var och en.
AzureDiagnostics
| where OperationName == "Query.Search" and TimeGenerated > ago(1d)
| extend MinuteOfDay = substring(TimeGenerated, 0, 16)
| project MinuteOfDay, DurationMs, Documents_d, IndexName_s
| summarize QPM=count(), AvgDuractionMs=avg(DurationMs), AvgDocCountReturned=avg(Documents_d) by MinuteOfDay
| order by MinuteOfDay desc
| render timechart
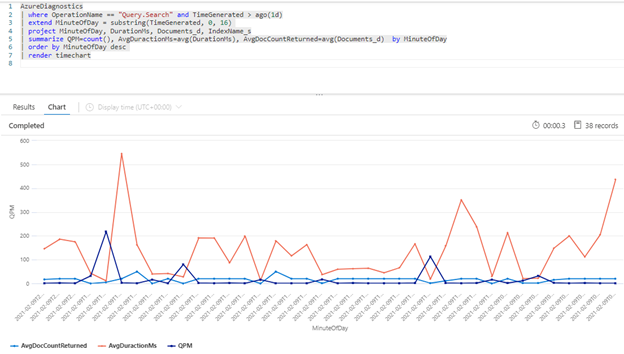
Dricks
Om du vill visa data bakom det här diagrammet tar du bort raden | render timechart och kör sedan frågan igen.
Påverkan av indexering på frågor
En viktig faktor att tänka på när du tittar på prestanda är att indexering använder samma resurser som sökfrågor. Om du indexerar en stor mängd innehåll kan du förvänta dig att svarstiden växer när tjänsten försöker hantera båda arbetsbelastningarna.
Om frågorna saktar ner tittar du på tidpunkten för indexeringsaktiviteten för att se om den sammanfaller med frågeförsämring. Till exempel kanske en indexerare kör ett dagligt jobb eller ett timjobb som korrelerar med den minskade prestandan för sökfrågorna.
Det här avsnittet innehåller en uppsättning frågor som kan hjälpa dig att visualisera sök- och indexeringsfrekvensen. I de här exemplen anges tidsintervallet i frågan. Ange Ange i fråga när du kör frågorna i Azure-portalen.
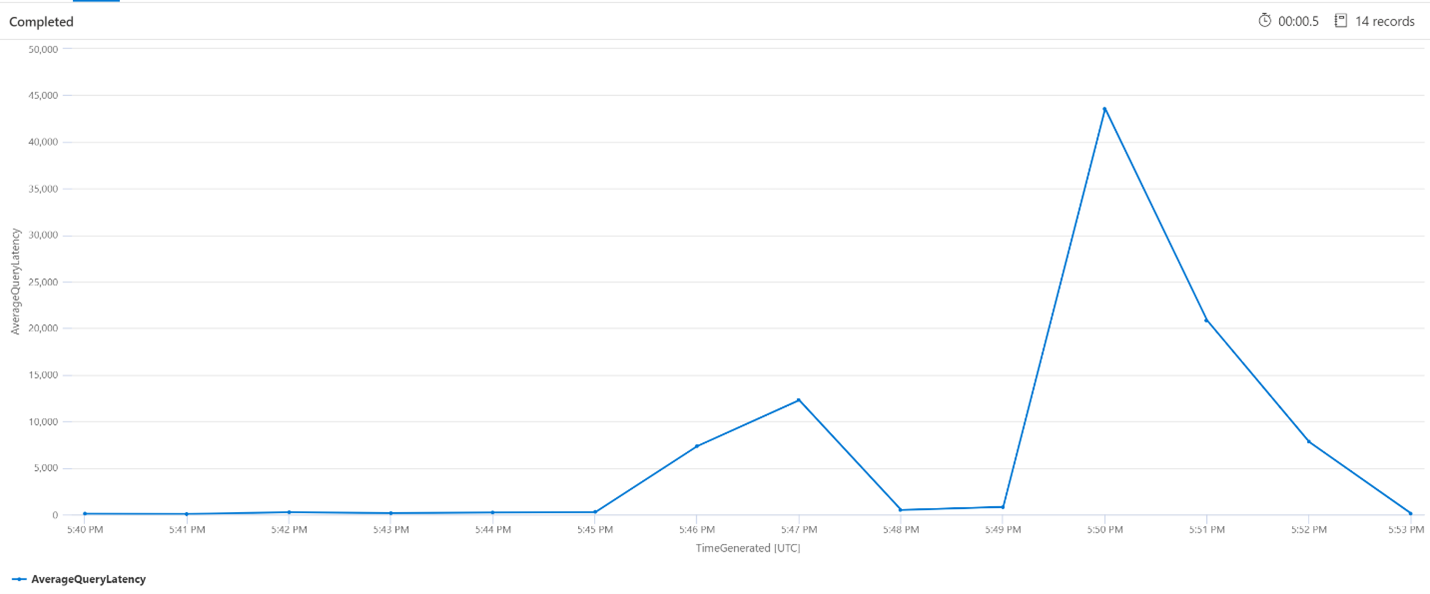
Genomsnittlig frågesvarstid
I frågan nedan används en intervallstorlek på 1 minut för att visa den genomsnittliga svarstiden för sökfrågorna. Från diagrammet kan vi se att den genomsnittliga svarstiden var låg fram till 17:45 och varade fram till 17:53.
let intervalsize = 1m;
let _startTime = datetime('2021-02-23 17:40');
let _endTime = datetime('2021-02-23 18:00');
AzureDiagnostics
| where TimeGenerated between(['_startTime']..['_endTime']) // Time range filtering
| summarize AverageQueryLatency = avgif(DurationMs, OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete"))
by bin(TimeGenerated, intervalsize)
| render timechart
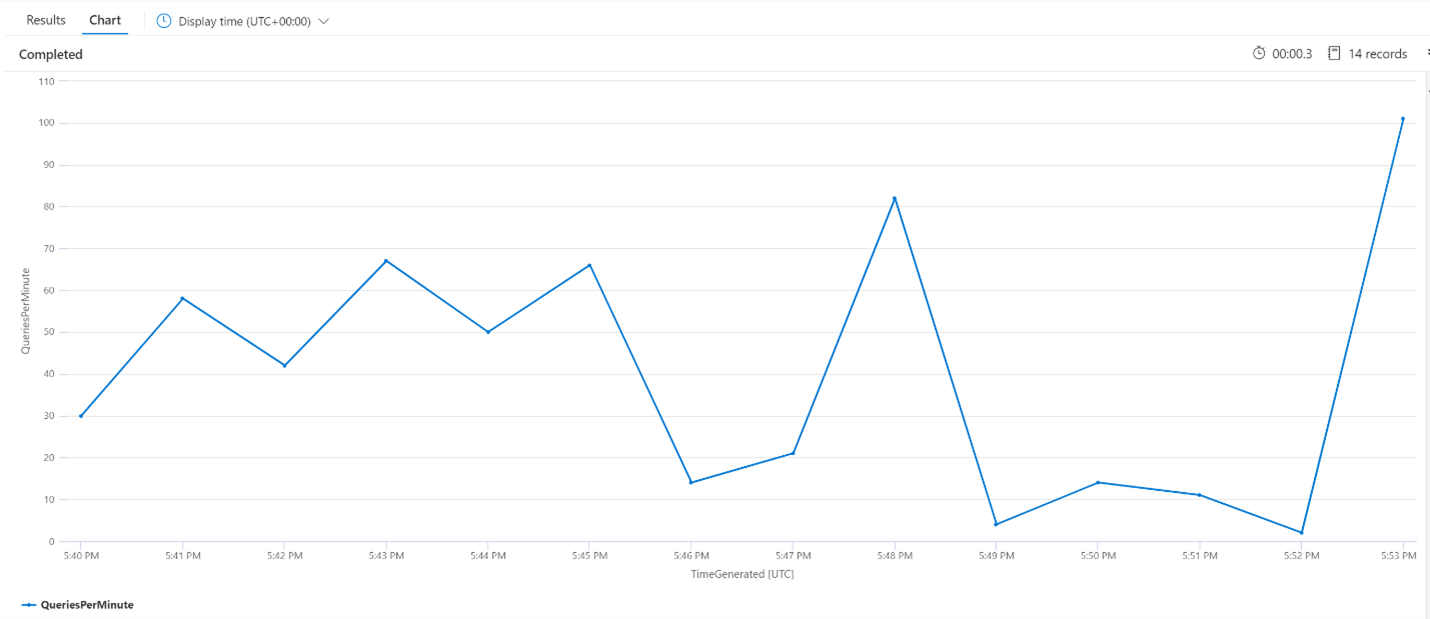
Genomsnittliga frågor per minut (QPM)
Följande fråga tittar på det genomsnittliga antalet frågor per minut för att säkerställa att det inte fanns en topp i sökbegäranden som kan ha påverkat svarstiden. I diagrammet kan vi se att det finns en viss varians, men inget som tyder på en topp i antalet begäranden.
let intervalsize = 1m;
let _startTime = datetime('2021-02-23 17:40');
let _endTime = datetime('2021-02-23 18:00');
AzureDiagnostics
| where TimeGenerated between(['_startTime'] .. ['_endTime']) // Time range filtering
| summarize QueriesPerMinute=bin(countif(OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete"))/(intervalsize/1m), 0.01)
by bin(TimeGenerated, intervalsize)
| render timechart
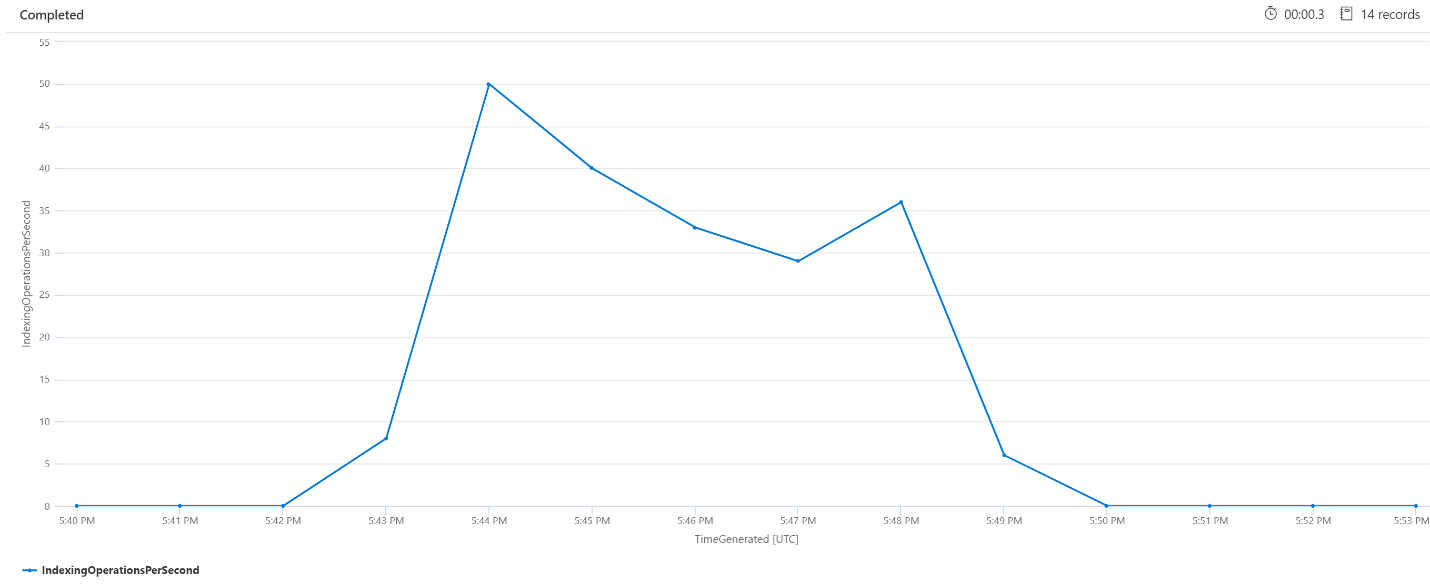
Indexeringsåtgärder per minut (OPM)
Här tittar vi på antalet indexeringsåtgärder per minut. Från diagrammet kan vi se att en stor mängd data indexerades startade kl. 17:42 och avslutades kl. 17:50. Indexeringen började 3 minuter innan sökfrågorna började bli latenta och avslutades 3 minuter innan sökfrågorna inte längre var latenta.
Utifrån den här insikten kan vi se att det tog ungefär 3 minuter för söktjänsten att bli tillräckligt upptagen för att indexering ska påverka frågesvarstiden. Vi kan också se att det tog ytterligare 3 minuter för söktjänsten att slutföra allt arbete från det nyligen indexerade innehållet och för att frågesvarstiden skulle lösas.
let intervalsize = 1m;
let _startTime = datetime('2021-02-23 17:40');
let _endTime = datetime('2021-02-23 18:00');
AzureDiagnostics
| where TimeGenerated between(['_startTime'] .. ['_endTime']) // Time range filtering
| summarize IndexingOperationsPerSecond=bin(countif(OperationName == "Indexing.Index")/ (intervalsize/1m), 0.01)
by bin(TimeGenerated, intervalsize)
| render timechart
Bearbetning av bakgrundstjänst
Det är inte ovanligt att se periodiska toppar i fråge- eller indexeringsfördröjning. Toppar kan inträffa som svar på indexering eller höga frågefrekvenser, men kan också inträffa under sammanslagningsåtgärder. Sökindex lagras i segment – eller shards. Med jämna mellanrum sammanfogar systemet mindre shards till stora shards, vilket kan hjälpa till att optimera tjänstens prestanda. Den här sammanslagningsprocessen rensar också dokument som tidigare har markerats för borttagning från indexet, vilket resulterar i återställning av lagringsutrymme.
Sammanslagning av shards är snabb, men också resursintensiv och kan därmed försämra tjänstprestanda. Om du märker korta intervall av frågesvarstid, och dessa bursts sammanfaller med de senaste ändringarna av indexerat innehåll, kan du anta att svarstiden beror på åtgärder för horisontell sammanslagning.
Nästa steg
Granska de här artiklarna om att analysera tjänstens prestanda.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för