Översikt över klusterresurshanterarens arkitektur
Service Fabric-klustrets Resource Manager är en central tjänst som körs i klustret. Den hanterar önskat tillstånd för tjänsterna i klustret, särskilt när det gäller resursförbrukning och eventuella placeringsregler.
Om du vill hantera resurserna i klustret måste Service Fabric-klustret Resource Manager ha flera typer av information:
- Vilka tjänster finns för närvarande
- Varje tjänsts aktuella (eller standard) resursförbrukning
- Återstående klusterkapacitet
- Kapaciteten för noderna i klustret
- Mängden resurser som förbrukas på varje nod
Resursförbrukningen för en viss tjänst kan ändras över tid, och tjänster bryr sig vanligtvis om mer än en typ av resurs. I olika tjänster kan både verkliga fysiska och fysiska resurser mätas. Tjänster kan spåra fysiska mått som minne och diskförbrukning. Vanligare är att tjänster bryr sig om logiska mått – till exempel "WorkQueueDepth" eller "TotalRequests". Både logiska och fysiska mått kan användas i samma kluster. Mått kan delas mellan många tjänster eller vara specifika för en viss tjänst.
Ytterligare överväganden
Ägare och operatörer av klustret kan skilja sig från tjänst- och programförfattare, eller åtminstone är samma personer som bär olika hattar. När du utvecklar ditt program vet du några saker om vad det kräver. Du har en uppskattning av de resurser som används och hur olika tjänster ska distribueras. Webbnivån måste till exempel köras på noder som är exponerade mot Internet, medan databastjänsterna inte ska göra det. Som ett annat exempel är webbtjänsterna förmodligen begränsade av PROCESSOR och nätverk, medan datanivåtjänsterna bryr sig mer om minne och diskförbrukning. Den person som hanterar en incident på en live-plats för tjänsten i produktion, eller som hanterar en uppgradering till tjänsten, har dock ett annat jobb att göra och kräver olika verktyg.
Både klustret och tjänsterna är dynamiska:
- Antalet noder i klustret kan växa och krympa
- Noder av olika storlekar och typer kan komma och gå
- Tjänster kan skapas, tas bort och ändra önskade resursallokeringar och placeringsregler
- Uppgraderingar eller andra hanteringsåtgärder kan rulla genom klustret i programmet på infrastrukturnivå
- Fel kan inträffa när som helst.
Komponenter och dataflöde i Klusterresurshanteraren
Klustrets Resource Manager måste spåra kraven för varje tjänst och förbrukningen av resurser för varje tjänstobjekt i dessa tjänster. Klustret Resource Manager har två konceptuella delar: agenter som körs på varje nod och en feltolerant tjänst. Agenterna på varje nod spårar belastningsrapporter från tjänster, aggregerar dem och rapporterar dem regelbundet. Tjänsten Cluster Resource Manager sammanställer all information från de lokala agenterna och reagerar baserat på dess aktuella konfiguration.
Nu ska vi titta på följande diagram:
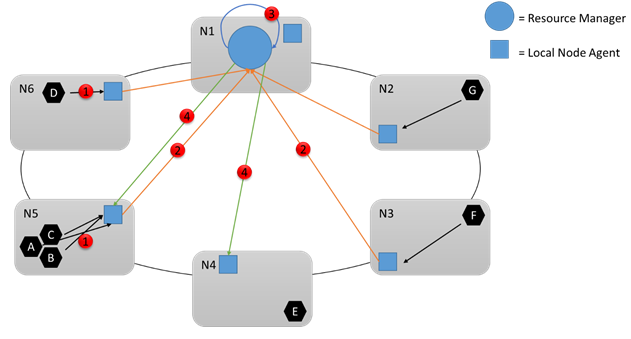
Under körningen finns det många ändringar som kan inträffa. Anta till exempel hur mycket resurser som vissa tjänster förbrukar ändringar, vissa tjänster misslyckas och vissa noder ansluter och lämnar klustret. Alla ändringar på en nod aggregeras och skickas regelbundet till tjänsten Cluster Resource Manager (1,2) där de aggregeras igen, analyseras och lagras. Med några sekunders mellanrum tittar tjänsten på ändringarna och avgör om några åtgärder är nödvändiga (3). Det kan till exempel se att vissa tomma noder har lagts till i klustret. Därför bestämmer den sig för att flytta vissa tjänster till dessa noder. Klustrets Resource Manager kan också se att en viss nod är överbelastad eller att vissa tjänster har misslyckats eller tagits bort, vilket frigör resurser någon annanstans.
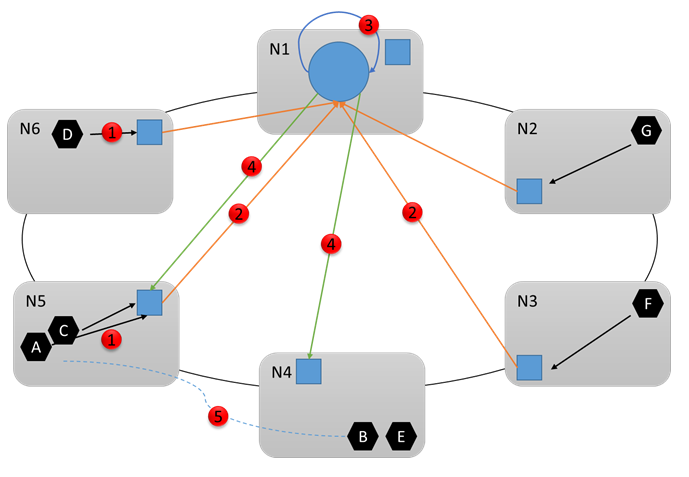
Nu ska vi titta på följande diagram och se vad som händer härnäst. Anta att klustret Resource Manager fastställer att ändringar är nödvändiga. Den samordnar med andra systemtjänster (särskilt redundanshanteraren) för att göra nödvändiga ändringar. Sedan skickas de nödvändiga kommandona till lämpliga noder (4). Anta till exempel att Resource Manager märkt att Node5 var överbelastad och därför bestämde sig för att flytta tjänsten B från Node5 till Node4. I slutet av omkonfigurationen (5) ser klustret ut så här:
Nästa steg
- Kluster Resource Manager har många alternativ för att beskriva klustret. Mer information om dem finns i den här artikeln om hur du beskriver ett Service Fabric-kluster
- Klustrets Resource Manager primära uppgifter balanserar om klustret och tillämpar placeringsregler. Mer information om hur du konfigurerar dessa beteenden finns i Balansera ditt Service Fabric-kluster
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för