Beskriva ett Service Fabric-kluster med hjälp av Klusterresurshanteraren
Funktionen Cluster Resource Manager i Azure Service Fabric innehåller flera mekanismer för att beskriva ett kluster:
- Feldomäner
- Uppgradera domäner
- Nodegenskaper
- Nodkapaciteter
Under körningen använder Klusterresurshanteraren den här informationen för att säkerställa hög tillgänglighet för de tjänster som körs i klustret. När du framtvingar dessa viktiga regler försöker den också optimera resursförbrukningen i klustret.
Feldomäner
En feldomän är ett område med koordinerat fel. En enskild dator är en feldomän. Det kan misslyckas på egen hand av olika skäl, från strömförsörjningsfel till enhetsfel till felaktig inbyggd NIC-programvara.
Datorer som är anslutna till samma Ethernet-växel finns i samma feldomän. Det är även datorer som delar en enda strömkälla eller på en enda plats.
Eftersom det är naturligt att maskinvarufel överlappar varandra är feldomäner i sig hierarkiska. De representeras som URI:er i Service Fabric.
Det är viktigt att feldomäner konfigureras korrekt eftersom Service Fabric använder den här informationen för att placera tjänster på ett säkert sätt. Service Fabric vill inte placera tjänster så att förlusten av en feldomän (orsakad av ett fel i någon komponent) gör att en tjänst slutar fungera.
I Azure-miljön använder Service Fabric feldomäninformationen som tillhandahålls av miljön för att konfigurera noderna i klustret på rätt sätt åt dig. För fristående instanser av Service Fabric definieras feldomäner när klustret konfigureras.
Varning
Det är viktigt att feldomäninformationen som tillhandahålls till Service Fabric är korrekt. Anta till exempel att Service Fabric-klustrets noder körs på tio virtuella datorer som körs på fem fysiska värdar. I det här fallet, även om det finns 10 virtuella datorer, finns det bara 5 olika (toppnivå) feldomäner. Att dela samma fysiska värd gör att virtuella datorer delar samma rotfeldomän, eftersom de virtuella datorerna upplever ett samordnat fel om deras fysiska värd misslyckas.
Service Fabric förväntar sig att feldomänen för en nod inte ändras. Andra mekanismer för att säkerställa hög tillgänglighet för de virtuella datorerna, till exempel virtuella DATORER med hög tillgänglighet, kan orsaka konflikter med Service Fabric. Dessa mekanismer använder transparent migrering av virtuella datorer från en värd till en annan. De konfigurerar inte om eller meddelar den kod som körs på den virtuella datorn. Därför stöds de inte som miljöer för att köra Service Fabric-kluster.
Service Fabric bör vara den enda teknik med hög tillgänglighet som används. Mekanismer som direktmigrering av virtuella datorer och SAN-nätverk är inte nödvändiga. Om dessa mekanismer används tillsammans med Service Fabric minskar de programmets tillgänglighet och tillförlitlighet. Anledningen är att de medför ytterligare komplexitet, lägger till centraliserade felkällor och använder tillförlitlighets- och tillgänglighetsstrategier som står i konflikt med dem i Service Fabric.
I följande bild färgar vi alla entiteter som bidrar till feldomäner och listar alla olika feldomäner som resulterar. I det här exemplet har vi datacenter ("DC"), rack ("R" och blad ("B"). Om varje blad innehåller mer än en virtuell dator kan det finnas ett annat lager i feldomänhierarkin.
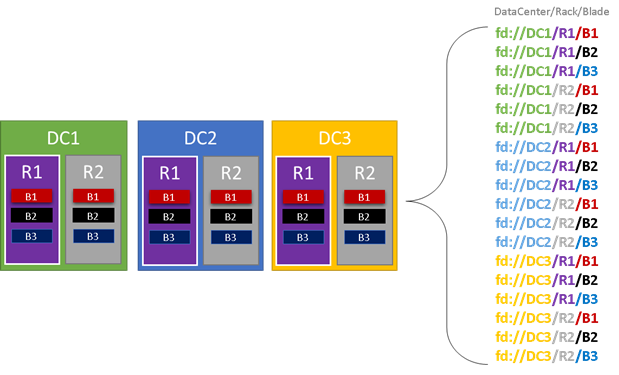
Under körningen tar Service Fabric Cluster Resource Manager hänsyn till feldomänerna i kluster- och abonnemangslayouterna. Tillståndskänsliga repliker eller tillståndslösa instanser för en tjänst distribueras så att de finns i separata feldomäner. Om tjänsten distribueras mellan feldomäner ser du till att tjänstens tillgänglighet inte äventyras när en feldomän misslyckas på någon nivå i hierarkin.
Klusterresurshanteraren bryr sig inte om hur många lager det finns i feldomänhierarkin. Den försöker se till att förlusten av en del av hierarkin inte påverkar tjänster som körs i den.
Det är bäst om samma antal noder finns på varje djupnivå i feldomänhierarkin. Om "trädet" för feldomäner är obalanserat i klustret är det svårare för Klusterresurshanteraren att ta reda på den bästa allokeringen av tjänster. Obalanserade feldomänlayouter innebär att förlusten av vissa domäner påverkar tillgängligheten för tjänster mer än andra domäner. Därför slits Klusterresurshanteraren mellan två mål:
- Den vill använda datorerna i den "tunga" domänen genom att placera tjänster på dem.
- Den vill placera tjänster i andra domäner så att förlusten av en domän inte orsakar problem.
Hur ser obalanserade domäner ut? Följande diagram visar två olika klusterlayouter. I det första exemplet distribueras noderna jämnt över feldomänerna. I det andra exemplet har en feldomän många fler noder än de andra feldomänerna.

I Azure hanteras valet av vilken feldomän som innehåller en nod åt dig. Men beroende på antalet noder som du etablerar kan du fortfarande få feldomäner som har fler noder i sig än i andra.
Anta till exempel att du har fem feldomäner i klustret men etablerar sju noder för en nodtyp (NodeType). I det här fallet får de två första feldomänerna fler noder. Om du fortsätter att distribuera fler NodeType-instanser med bara ett par instanser blir problemet värre. Därför rekommenderar vi att antalet noder i varje nodtyp är en multipel av antalet feldomäner.
Uppgradera domäner
Uppgraderingsdomäner är en annan funktion som hjälper Service Fabric Cluster Resource Manager att förstå klustrets layout. Uppgraderingsdomäner definierar uppsättningar med noder som uppgraderas samtidigt. Uppgraderingsdomäner hjälper Cluster Resource Manager att förstå och samordna hanteringsåtgärder som uppgraderingar.
Uppgraderingsdomäner liknar feldomäner, men med några viktiga skillnader. För det första definierar områden med samordnade maskinvarufel feldomäner. Uppgraderingsdomäner definieras å andra sidan av en princip. Du får bestämma hur många du vill ha, i stället för att låta miljön diktera antalet. Du kan ha lika många uppgraderingsdomäner som noder. En annan skillnad mellan feldomäner och uppgraderingsdomäner är att uppgraderingsdomäner inte är hierarkiska. I stället är de mer som en enkel tagg.
Följande diagram visar tre uppgraderingsdomäner som är randiga över tre feldomäner. Den visar också en möjlig placering för tre olika repliker av en tillståndskänslig tjänst, där var och en hamnar i olika fel- och uppgraderingsdomäner. Den här placeringen tillåter förlust av en feldomän mitt i en tjänstuppgradering och har fortfarande en kopia av koden och data.

Det finns för- och nackdelar med att ha ett stort antal uppgraderingsdomäner. Fler uppgraderingsdomäner innebär att varje steg i uppgraderingen är mer detaljerat och påverkar ett mindre antal noder eller tjänster. Färre tjänster måste flyttas åt gången, vilket innebär mindre omsättning i systemet. Detta tenderar att förbättra tillförlitligheten eftersom mindre av tjänsten påverkas av problem som uppstår under uppgraderingen. Fler uppgraderingsdomäner innebär också att du behöver mindre tillgänglig buffert på andra noder för att hantera effekten av uppgraderingen.
Om du till exempel har fem uppgraderingsdomäner hanterar noderna i var och en ungefär 20 procent av trafiken. Om du behöver ta bort uppgraderingsdomänen för en uppgradering måste belastningen vanligtvis gå någonstans. Eftersom du har fyra återstående uppgraderingsdomäner måste var och en ha plats för cirka 25 procent av den totala trafiken. Fler uppgraderingsdomäner innebär att du behöver mindre buffert på noderna i klustret.
Tänk på om du hade 10 uppgraderingsdomäner i stället. I så fall skulle varje uppgraderingsdomän endast hantera cirka 10 procent av den totala trafiken. När en uppgradering stegar genom klustret skulle varje domän behöva ha plats för endast cirka 11 procent av den totala trafiken. Med fler uppgraderingsdomäner kan du vanligtvis köra noderna med högre användning eftersom du behöver mindre reserverad kapacitet. Detsamma gäller för feldomäner.
Nackdelen med att ha många uppgraderingsdomäner är att uppgraderingar tenderar att ta längre tid. Service Fabric väntar en kort stund efter att en uppgraderingsdomän har slutförts och utför kontroller innan du börjar uppgradera nästa. Dessa fördröjningar möjliggör identifiering av problem som introduceras av uppgraderingen innan uppgraderingen fortsätter. Kompromissen är acceptabel eftersom den förhindrar att dåliga ändringar påverkar för mycket av tjänsten i taget.
Förekomsten av för få uppgraderingsdomäner har många negativa biverkningar. Varje uppgraderingsdomän är nere och uppgraderas, men en stor del av din totala kapacitet är inte tillgänglig. Om du till exempel bara har tre uppgraderingsdomäner tar du ned ungefär en tredjedel av din totala tjänst- eller klusterkapacitet åt gången. Det är inte önskvärt att ha så mycket av tjänsten på en gång eftersom du behöver tillräckligt med kapacitet i resten av klustret för att hantera arbetsbelastningen. Att upprätthålla bufferten innebär att noderna under normal drift är mindre inlästa än de annars skulle vara. Detta ökar kostnaden för att köra tjänsten.
Det finns ingen verklig gräns för det totala antalet fel- eller uppgraderingsdomäner i en miljö, eller begränsningar för hur de överlappar varandra. Men det finns vanliga mönster:
- Feldomäner och uppgraderingsdomäner mappade 1:1
- En uppgraderingsdomän per nod (fysisk eller virtuell OS-instans)
- En "randig" eller "matris"-modell där feldomänerna och uppgraderingsdomänerna utgör en matris med datorer som vanligtvis körs på diagonalerna

Det finns inget bästa svar för vilken layout du ska välja. Var och en har för- och nackdelar. Till exempel är 1FD:1UD-modellen enkel att konfigurera. Modellen för en uppgraderingsdomän per nodmodell liknar mest vad personer är vana vid. Under uppgraderingar uppdateras varje nod separat. Det här liknar hur små uppsättningar datorer har uppgraderats manuellt tidigare.
Den vanligaste modellen är FD/UD-matrisen, där feldomänerna och uppgraderingsdomänerna utgör en tabell och noder placeras från och med diagonalen. Det här är den modell som används som standard i Service Fabric-kluster i Azure. För kluster med många noder ser allt ut som ett tätt matrismönster.
Kommentar
Service Fabric-kluster som finns i Azure har inte stöd för att ändra standardstrategin. Endast fristående kluster erbjuder den anpassningen.
Fel- och uppgraderingsdomänbegränsningar och resulterande beteende
Standardmetod
Som standard håller Klusterresurshanteraren tjänster balanserade mellan fel- och uppgraderingsdomäner. Detta modelleras som en begränsning. Begränsningen för fel- och uppgraderingsdomäner säger: "För en viss tjänstpartition bör det aldrig finnas någon skillnad större än en i antalet tjänstobjekt (tillståndslösa tjänstinstanser eller tillståndskänsliga tjänstrepliker) mellan två domäner på samma hierarkinivå."
Anta att den här begränsningen ger en "maximal skillnad"-garanti. Begränsningen för fel- och uppgraderingsdomäner förhindrar vissa flyttningar eller arrangemang som bryter mot regeln.
Anta till exempel att vi har ett kluster med sex noder, konfigurerade med fem feldomäner och fem uppgraderingsdomäner.
| FD0 | FD1 | FD2 | FD3 | FD4 | |
|---|---|---|---|---|---|
| UD0 | N1 | ||||
| UD1 | N6 | N2 | |||
| UD2 | N3 | ||||
| UD3 | N4 | ||||
| UD4 | N5 |
Anta nu att vi skapar en tjänst med värdet TargetReplicaSetSize (eller, för en tillståndslös tjänst, InstanceCount) på fem. Replikerna landar på N1-N5. I själva verket används N6 aldrig oavsett hur många tjänster som du skapar. Men varför? Nu ska vi titta på skillnaden mellan den aktuella layouten och vad som skulle hända om N6 väljs.
Här är layouten vi har och det totala antalet repliker per fel- och uppgraderingsdomän:
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | R1 | 1 | ||||
| UD1 | R2 | 1 | ||||
| UD2 | R3 | 1 | ||||
| UD3 | R4 | 1 | ||||
| UD4 | R5 | 1 | ||||
| FDTotal | 1 | 1 | 1 | 1 | 1 | - |
Den här layouten balanseras när det gäller noder per feldomän och uppgraderingsdomän. Det balanseras också när det gäller antalet repliker per fel- och uppgraderingsdomän. Varje domän har samma antal noder och samma antal repliker.
Nu ska vi titta på vad som skulle hända om vi hade använt N6 i stället för N2. Hur skulle replikerna distribueras då?
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | R1 | 1 | ||||
| UD1 | R5 | 1 | ||||
| UD2 | R2 | 1 | ||||
| UD3 | R3 | 1 | ||||
| UD4 | R4 | 1 | ||||
| FDTotal | 2 | 0 | 1 | 1 | 1 | - |
Den här layouten strider mot vår definition av "maximal skillnad"-garantin för begränsningen för feldomänen. FD0 har två repliker, medan FD1 har noll. Skillnaden mellan FD0 och FD1 är totalt två, vilket är större än den maximala skillnaden på en. Eftersom begränsningen är överträdd tillåter inte Klusterresurshanteraren det här arrangemanget.
På samma sätt, om vi valde N2 och N6 (i stället för N1 och N2), skulle vi få:
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | 0 | |||||
| UD1 | R5 | R1 | 2 | |||
| UD2 | R2 | 1 | ||||
| UD3 | R3 | 1 | ||||
| UD4 | R4 | 1 | ||||
| FDTotal | 1 | 1 | 1 | 1 | 1 | - |
Den här layouten balanseras när det gäller feldomäner. Men nu bryter den mot uppgraderingsdomänbegränsningen eftersom UD0 har noll repliker och UD1 har två. Den här layouten är också ogiltig och väljs inte av Klusterresurshanteraren.
Den här metoden för distribution av tillståndskänsliga repliker eller tillståndslösa instanser ger bästa möjliga feltolerans. Om en domän går ned går det minimala antalet repliker/instanser förlorade.
Å andra sidan kan den här metoden vara för strikt och inte tillåta att klustret använder alla resurser. För vissa klusterkonfigurationer kan vissa noder inte användas. Detta kan göra att Service Fabric inte placerar dina tjänster, vilket resulterar i varningsmeddelanden. I föregående exempel kan vissa av klusternoderna inte användas (N6 i exemplet). Även om du har lagt till noder i klustret (N7-N10) placeras repliker/instanser endast på N1–N5 på grund av begränsningar för fel- och uppgraderingsdomäner.
| FD0 | FD1 | FD2 | FD3 | FD4 | |
|---|---|---|---|---|---|
| UD0 | N1 | N10 | |||
| UD1 | N6 | N2 | |||
| UD2 | N7 | N3 | |||
| UD3 | N8 | N4 | |||
| UD4 | N9 | N5 |
Alternativ metod
Klusterresurshanteraren stöder en annan version av begränsningen för fel- och uppgraderingsdomäner. Det tillåter placering samtidigt som en lägsta säkerhetsnivå garanteras. Den alternativa begränsningen kan anges på följande sätt: "För en viss tjänstpartition bör replikdistribution mellan domäner säkerställa att partitionen inte drabbas av kvorumförlust." Anta att den här begränsningen ger en "kvorumsäker" garanti.
Kommentar
För en tillståndskänslig tjänst definierar vi kvorumförlust i en situation när en majoritet av partitionsreplikerna är nere samtidigt. Om TargetReplicaSetSize till exempel är fem representerar en uppsättning tre repliker kvorum. På samma sätt, om TargetReplicaSetSize är sex, krävs fyra repliker för kvorum. I båda fallen kan inte fler än två repliker vara nere samtidigt om partitionen vill fortsätta att fungera normalt.
För en tillståndslös tjänst finns det inget sådant som kvorumförlust. Tillståndslösa tjänster fortsätter att fungera normalt även om en majoritet av instanserna går ned samtidigt. Därför fokuserar vi på tillståndskänsliga tjänster i resten av den här artikeln.
Nu går vi tillbaka till föregående exempel. Med den "kvorumsäkra" versionen av villkoret skulle alla tre layouterna vara giltiga. Även om FD0 misslyckades i den andra layouten eller UD1 misslyckades i den tredje layouten skulle partitionen fortfarande ha kvorum. (En majoritet av replikerna skulle fortfarande vara igång.) Med den här versionen av villkoret kan N6 nästan alltid användas.
Metoden "kvorumsäker" ger mer flexibilitet än metoden "maximal skillnad". Anledningen är att det är enklare att hitta replikdistributioner som är giltiga i nästan alla klustertopologier. Den här metoden kan dock inte garantera de bästa feltoleransegenskaperna eftersom vissa fel är värre än andra.
I värsta fall kan en majoritet av replikerna gå förlorade när en domän och en ytterligare replik misslyckas. I stället för att tre fel krävs för att förlora kvorum med fem repliker eller instanser kan du nu förlora en majoritet med bara två fel.
Anpassningsbar metod
Eftersom båda metoderna har styrkor och svagheter har vi infört en anpassningsbar metod som kombinerar dessa två strategier.
Kommentar
Det här är standardbeteendet som börjar med Service Fabric version 6.2.
Den anpassningsbara metoden använder logiken "maximal skillnad" som standard och växlar endast till logiken "kvorumsäker" när det behövs. Klusterresurshanteraren räknar automatiskt ut vilken strategi som krävs genom att titta på hur klustret och tjänsterna konfigureras.
Klusterresurshanteraren bör använda logiken "kvorumbaserad" för en tjänst som båda dessa villkor är sanna:
- TargetReplicaSetSize för tjänsten är jämnt delbart med antalet feldomäner och antalet uppgraderingsdomäner.
- Antalet noder är mindre än eller lika med antalet feldomäner multiplicerat med antalet uppgraderingsdomäner.
Tänk på att Cluster Resource Manager använder den här metoden för både tillståndslösa och tillståndskänsliga tjänster, även om kvorumförlust inte är relevant för tillståndslösa tjänster.
Nu ska vi gå tillbaka till föregående exempel och anta att ett kluster nu har åtta noder. Klustret är fortfarande konfigurerat med fem feldomäner och fem uppgraderingsdomäner och värdet TargetReplicaSetSize för en tjänst som finns i klustret är fortfarande fem.
| FD0 | FD1 | FD2 | FD3 | FD4 | |
|---|---|---|---|---|---|
| UD0 | N1 | ||||
| UD1 | N6 | N2 | |||
| UD2 | N7 | N3 | |||
| UD3 | N8 | N4 | |||
| UD4 | N5 |
Eftersom alla nödvändiga villkor är uppfyllda använder Klusterresurshanteraren logiken "kvorumbaserad" när tjänsten distribueras. Detta möjliggör användning av N6-N8. En möjlig tjänstdistribution i det här fallet kan se ut så här:
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | R1 | 1 | ||||
| UD1 | R2 | 1 | ||||
| UD2 | R3 | R4 | 2 | |||
| UD3 | 0 | |||||
| UD4 | R5 | 1 | ||||
| FDTotal | 2 | 1 | 1 | 0 | 1 | - |
Om tjänstens TargetReplicaSetSize-värde minskas till fyra (till exempel) kommer Klusterresurshanteraren att märka den ändringen. Den återupptas med logiken "maximal skillnad" eftersom TargetReplicaSetSize inte längre kan divideras med antalet feldomäner och uppgraderingsdomäner. Därför sker vissa replikrörelser för att distribuera de återstående fyra replikerna på noderna N1-N5. På så sätt överträds inte den "maximala skillnaden"-versionen av feldomänen och uppgraderingsdomänlogik.
Om värdet TargetReplicaSetSize i föregående layout är fem och N1 tas bort från klustret blir antalet uppgraderingsdomäner lika med fyra. Återigen börjar Klusterresurshanteraren använda logiken "maximal skillnad" eftersom antalet uppgraderingsdomäner inte längre delar upp tjänstens TargetReplicaSetSize-värde jämnt. Därför måste replik R1, när den skapas igen, landa på N4 så att begränsningen för fel- och uppgraderingsdomänen inte överträds.
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | Saknas | Saknas | Saknas | Saknas | Saknas | Saknas |
| UD1 | R2 | 1 | ||||
| UD2 | R3 | R4 | 2 | |||
| UD3 | R1 | 1 | ||||
| UD4 | R5 | 1 | ||||
| FDTotal | 1 | 1 | 1 | 1 | 1 | - |
Konfigurera fel- och uppgraderingsdomäner
I Azure-värdbaserade Service Fabric-distributioner definieras feldomäner och uppgraderingsdomäner automatiskt. Service Fabric hämtar och använder miljöinformationen från Azure.
Om du skapar ett eget kluster (eller vill köra en viss topologi under utveckling) kan du ange feldomänen och uppgradera domäninformationen själv. I det här exemplet definierar vi ett lokalt utvecklingskluster med nio noder som sträcker sig över tre datacenter (var och en med tre rack). Det här klustret har också tre uppgraderingsdomäner som är randiga över dessa tre datacenter. Här är ett exempel på konfigurationen i ClusterManifest.xml:
<Infrastructure>
<!-- IsScaleMin indicates that this cluster runs on one box/one single server -->
<WindowsServer IsScaleMin="true">
<NodeList>
<Node NodeName="Node01" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType01" FaultDomain="fd:/DC01/Rack01" UpgradeDomain="UpgradeDomain1" IsSeedNode="true" />
<Node NodeName="Node02" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType02" FaultDomain="fd:/DC01/Rack02" UpgradeDomain="UpgradeDomain2" IsSeedNode="true" />
<Node NodeName="Node03" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType03" FaultDomain="fd:/DC01/Rack03" UpgradeDomain="UpgradeDomain3" IsSeedNode="true" />
<Node NodeName="Node04" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType04" FaultDomain="fd:/DC02/Rack01" UpgradeDomain="UpgradeDomain1" IsSeedNode="true" />
<Node NodeName="Node05" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType05" FaultDomain="fd:/DC02/Rack02" UpgradeDomain="UpgradeDomain2" IsSeedNode="true" />
<Node NodeName="Node06" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType06" FaultDomain="fd:/DC02/Rack03" UpgradeDomain="UpgradeDomain3" IsSeedNode="true" />
<Node NodeName="Node07" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType07" FaultDomain="fd:/DC03/Rack01" UpgradeDomain="UpgradeDomain1" IsSeedNode="true" />
<Node NodeName="Node08" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType08" FaultDomain="fd:/DC03/Rack02" UpgradeDomain="UpgradeDomain2" IsSeedNode="true" />
<Node NodeName="Node09" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType09" FaultDomain="fd:/DC03/Rack03" UpgradeDomain="UpgradeDomain3" IsSeedNode="true" />
</NodeList>
</WindowsServer>
</Infrastructure>
I det här exemplet används ClusterConfig.json för fristående distributioner:
"nodes": [
{
"nodeName": "vm1",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc1/r0",
"upgradeDomain": "UD1"
},
{
"nodeName": "vm2",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc1/r0",
"upgradeDomain": "UD2"
},
{
"nodeName": "vm3",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc1/r0",
"upgradeDomain": "UD3"
},
{
"nodeName": "vm4",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc2/r0",
"upgradeDomain": "UD1"
},
{
"nodeName": "vm5",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc2/r0",
"upgradeDomain": "UD2"
},
{
"nodeName": "vm6",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc2/r0",
"upgradeDomain": "UD3"
},
{
"nodeName": "vm7",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc3/r0",
"upgradeDomain": "UD1"
},
{
"nodeName": "vm8",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc3/r0",
"upgradeDomain": "UD2"
},
{
"nodeName": "vm9",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc3/r0",
"upgradeDomain": "UD3"
}
],
Kommentar
När du definierar kluster via Azure Resource Manager tilldelar Azure feldomäner och uppgraderingsdomäner. Definitionen av dina nodtyper och vm-skalningsuppsättningar i Azure Resource Manager-mallen innehåller därför inte information om feldomän eller uppgraderingsdomän.
Nodegenskaper och placeringsbegränsningar
Ibland (i själva verket för det mesta) vill du se till att vissa arbetsbelastningar endast körs på vissa typer av noder i klustret. Vissa arbetsbelastningar kan till exempel kräva GPU:er eller SSD:er, och andra kanske inte gör det.
Ett bra exempel på att rikta in sig på maskinvara för specifika arbetsbelastningar är nästan alla n-nivåarkitekturer. Vissa datorer fungerar som klientdelen eller API-serveringssidan i programmet och exponeras för klienterna eller Internet. Olika datorer, ofta med olika maskinvaruresurser, hanterar arbetet med beräknings- eller lagringsskikten. Dessa exponeras vanligtvis inte direkt för klienter eller internet.
Service Fabric förväntar sig att vissa arbetsbelastningar i vissa fall kan behöva köras på vissa maskinvarukonfigurationer. Till exempel:
- Ett befintligt n-nivåprogram har "lyfts och flyttats" till en Service Fabric-miljö.
- En arbetsbelastning måste köras på specifik maskinvara av prestanda-, skalnings- eller säkerhetsisoleringsskäl.
- En arbetsbelastning bör isoleras från andra arbetsbelastningar av princip- eller resursförbrukningsskäl.
För att stödja den här typen av konfigurationer innehåller Service Fabric taggar som du kan använda för noder. Dessa taggar kallas nodegenskaper. Placeringsbegränsningar är de instruktioner som är kopplade till enskilda tjänster som du väljer för en eller flera nodegenskaper. Placeringsbegränsningar definierar var tjänsterna ska köras. Begränsningsuppsättningen är utökningsbar. Valfritt nyckel/värde-par kan fungera.

Inbyggda nodegenskaper
Service Fabric definierar vissa standardnodegenskaper som kan användas automatiskt så att du inte behöver definiera dem. Standardegenskaperna som definieras vid varje nod är NodeType och NodeName.
Du kan till exempel skriva en placeringsbegränsning som "(NodeType == NodeType03)". NodeType är en vanlig egenskap. Det är användbart eftersom det motsvarar 1:1 med en typ av dator. Varje typ av dator motsvarar en typ av arbetsbelastning i ett traditionellt n-nivåprogram.

Placeringsbegränsningar och nodegenskapssyntax
Värdet som anges i nodegenskapen kan vara en sträng, boolesk eller signerad lång. Instruktionen i tjänsten kallas för en placeringsbegränsning eftersom den begränsar var tjänsten kan köras i klustret. Begränsningen kan vara valfri boolesk instruktion som fungerar på nodegenskaperna i klustret. Giltiga väljare i dessa booleska instruktioner är:
Villkorsstyrda kontroller för att skapa särskilda instruktioner:
Utdrag Syntax "lika med" "==" "inte lika med" "!=" "större än" ">" "större än eller lika med" ">=" "mindre än" "<" "mindre än eller lika med" "<=" Booleska instruktioner för gruppering och logiska åtgärder:
Utdrag Syntax "och" "&&" "eller" "||" "inte" "!" "group as single statement" "()"
Här följer några exempel på grundläggande villkorssatser:
"Value >= 5""NodeColor != green""((OneProperty < 100) || ((AnotherProperty == false) && (OneProperty >= 100)))"
Endast noder där den övergripande instruktionen för placeringsbegränsningar utvärderas till "True" kan få tjänsten placerad på den. Noder som inte har en definierad egenskap matchar inte någon placeringsbegränsning som innehåller egenskapen.
Anta att följande nodegenskaper har definierats för en nodtyp i ClusterManifest.xml:
<NodeType Name="NodeType01">
<PlacementProperties>
<Property Name="HasSSD" Value="true"/>
<Property Name="NodeColor" Value="green"/>
<Property Name="SomeProperty" Value="5"/>
</PlacementProperties>
</NodeType>
I följande exempel visas nodegenskaper som definierats via ClusterConfig.json för fristående distributioner eller Template.json för Azure-värdbaserade kluster.
Kommentar
I Azure Resource Manager-mallen parameteriseras vanligtvis nodtypen. Det skulle se ut som "[parameters('vmNodeType1Name')]" i stället för NodeType01.
"nodeTypes": [
{
"name": "NodeType01",
"placementProperties": {
"HasSSD": "true",
"NodeColor": "green",
"SomeProperty": "5"
},
}
],
Du kan skapa begränsningar för tjänstplacering för en tjänst på följande sätt:
FabricClient fabricClient = new FabricClient();
StatefulServiceDescription serviceDescription = new StatefulServiceDescription();
serviceDescription.PlacementConstraints = "(HasSSD == true && SomeProperty >= 4)";
// Add other required ServiceDescription fields
//...
await fabricClient.ServiceManager.CreateServiceAsync(serviceDescription);
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceType -Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton -PlacementConstraint "HasSSD == true && SomeProperty >= 4"
Om alla noder i NodeType01 är giltiga kan du också välja den nodtypen med villkoret "(NodeType == NodeType01)".
En tjänsts placeringsbegränsningar kan uppdateras dynamiskt under körningen. Om du behöver kan du flytta runt en tjänst i klustret, lägga till och ta bort krav och så vidare. Service Fabric ser till att tjänsten är tillgänglig även när de här typerna av ändringar görs.
StatefulServiceUpdateDescription updateDescription = new StatefulServiceUpdateDescription();
updateDescription.PlacementConstraints = "NodeType == NodeType01";
await fabricClient.ServiceManager.UpdateServiceAsync(new Uri("fabric:/app/service"), updateDescription);
Update-ServiceFabricService -Stateful -ServiceName $serviceName -PlacementConstraints "NodeType == NodeType01"
Placeringsbegränsningar anges för varje namngiven tjänstinstans. Uppdateringar sker alltid i stället för (skriva över) det som angavs tidigare.
Klusterdefinitionen definierar egenskaperna på en nod. Om du ändrar en nods egenskaper måste du uppgradera till klusterkonfigurationen. Om du uppgraderar en nods egenskaper måste varje berörd nod startas om för att rapportera dess nya egenskaper. Service Fabric hanterar dessa löpande uppgraderingar.
Beskriva och hantera klusterresurser
Ett av de viktigaste jobben för alla orkestrerare är att hantera resursförbrukning i klustret. Att hantera klusterresurser kan innebära ett par olika saker.
Först ser du till att datorerna inte är överbelastade. Det innebär att se till att datorerna inte kör fler tjänster än de kan hantera.
För det andra finns det balansering och optimering som är avgörande för att köra tjänster effektivt. Kostnadseffektiva eller prestandakänsliga tjänsterbjudanden kan inte tillåta att vissa noder är heta medan andra är kalla. Heta noder leder till resurskonkurration och dåliga prestanda. Kalla noder representerar bortkastade resurser och ökade kostnader.
Service Fabric representerar resurser som mått. Mått är alla logiska eller fysiska resurser som du vill beskriva för Service Fabric. Exempel på mått är "WorkQueueDepth" eller "MemoryInMb". Information om de fysiska resurser som Service Fabric kan styra på noder finns i Resursstyrning. Information om standardmått som används av Klusterresurshanteraren och hur du konfigurerar anpassade mått finns i den här artikeln.
Mått skiljer sig från placeringsbegränsningar och nodegenskaper. Nodegenskaper är statiska beskrivningar av själva noderna. Mått beskriver resurser som noder har och som tjänster använder när de körs på en nod. En nodegenskap kan vara HasSSD och kan vara inställd på sant eller falskt. Mängden tillgängligt utrymme på denna SSD och hur mycket som förbrukas av tjänster skulle vara ett mått som "DriveSpaceInMb".
Precis som för placeringsbegränsningar och nodegenskaper förstår Inte Service Fabric Cluster Resource Manager vad namnen på måtten betyder. Måttnamn är bara strängar. Det är en bra idé att deklarera enheter som en del av de måttnamn som du skapar när de kan vara tvetydiga.
Kapacitet
Om du inaktiverade all resursbalansering skulle Service Fabric Cluster Resource Manager fortfarande se till att ingen nod överskrider sin kapacitet. Det går att hantera kapacitetsöverskridanden om inte klustret är för fullt eller om arbetsbelastningen är större än någon nod. Kapacitet är en annan begränsning som Klusterresurshanteraren använder för att förstå hur mycket av en resurs en nod har. Återstående kapacitet spåras också för klustret som helhet.
Både kapaciteten och förbrukningen på tjänstnivå uttrycks i mått. Måttet kan till exempel vara "ClientConnections" och en nod kan ha en kapacitet för "ClientConnections" på 32 768. Andra noder kan ha andra gränser. En tjänst som körs på den noden kan säga att den för närvarande använder 32 256 av måttet "ClientConnections".
Under körningen spårar Cluster Resource Manager återstående kapacitet i klustret och på noder. För att spåra kapacitet subtraherar Klusterresurshanteraren varje tjänsts användning från en nods kapacitet där tjänsten körs. Med den här informationen kan Klusterresurshanteraren ta reda på var replikerna ska placeras eller flyttas så att noderna inte går över kapaciteten.

StatefulServiceDescription serviceDescription = new StatefulServiceDescription();
ServiceLoadMetricDescription metric = new ServiceLoadMetricDescription();
metric.Name = "ClientConnections";
metric.PrimaryDefaultLoad = 1024;
metric.SecondaryDefaultLoad = 0;
metric.Weight = ServiceLoadMetricWeight.High;
serviceDescription.Metrics.Add(metric);
await fabricClient.ServiceManager.CreateServiceAsync(serviceDescription);
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton –Metric @("ClientConnections,High,1024,0)
Du kan se kapaciteter som definierats i klustermanifestet. Här är ett exempel på ClusterManifest.xml:
<NodeType Name="NodeType03">
<Capacities>
<Capacity Name="ClientConnections" Value="65536"/>
</Capacities>
</NodeType>
Här är ett exempel på kapaciteter som definierats via ClusterConfig.json för fristående distributioner eller Template.json för Azure-värdbaserade kluster:
"nodeTypes": [
{
"name": "NodeType03",
"capacities": {
"ClientConnections": "65536",
}
}
],
Belastningen på en tjänst ändras ofta dynamiskt. Anta att en repliks belastning på "ClientConnections" har ändrats från 1 024 till 2 048. Noden som den kördes på hade då en kapacitet på endast 512 kvar för det måttet. Nu är replikens eller instansens placering ogiltig, eftersom det inte finns tillräckligt med utrymme på noden. Klusterresurshanteraren måste få tillbaka noden under kapaciteten. Det minskar belastningen på noden som överskrider kapaciteten genom att flytta en eller flera repliker eller instanser från noden till andra noder.
Klusterresurshanteraren försöker minimera kostnaden för att flytta repliker. Du kan lära dig mer om rörelsekostnader och om att ombalansera strategier och regler.
Klusterkapacitet
Hur hindrar Service Fabric Cluster Resource Manager det övergripande klustret från att vara för fullt? Med dynamisk belastning finns det inte mycket det kan göra. Tjänsterna kan ha sin belastningstoppar oberoende av åtgärder som Klusterresurshanteraren vidtar. Som ett resultat kan ditt kluster med gott om utrymme idag vara underbemannat om det finns en topp i morgon.
Kontroller i Cluster Resource Manager hjälper till att förhindra problem. Det första du kan göra är att förhindra att nya arbetsbelastningar skapas som gör att klustret blir fullt.
Anta att du skapar en tillståndslös tjänst och att den har en viss belastning associerad med den. Tjänsten bryr sig om måttet "DiskSpaceInMb". Tjänsten använder fem enheter "DiskSpaceInMb" för varje instans av tjänsten. Du vill skapa tre instanser av tjänsten. Det innebär att du behöver 15 enheter "DiskSpaceInMb" för att kunna finnas i klustret för att du även ska kunna skapa dessa tjänstinstanser.
Cluster Resource Manager beräknar kontinuerligt kapaciteten och förbrukningen för varje mått så att det kan fastställa den återstående kapaciteten i klustret. Om det inte finns tillräckligt med utrymme avvisar Klusterresurshanteraren anropet för att skapa en tjänst.
Eftersom kravet bara är att 15 enheter ska vara tillgängliga kan du allokera det här utrymmet på många olika sätt. Det kan till exempel finnas en återstående kapacitetsenhet på 15 olika noder eller tre återstående kapacitetsenheter på fem olika noder. Om Cluster Resource Manager kan ordna om saker så att det finns fem enheter tillgängliga på tre noder placerar tjänsten. Omorganisera klustret är vanligtvis möjligt om inte klustret är nästan fullt eller om de befintliga tjänsterna inte kan konsolideras av någon anledning.
Nodbuffert och överbokingskapacitet
Om en nodkapacitet för ett mått anges kommer Klusterresurshanteraren aldrig att placera eller flytta repliker till en nod om den totala belastningen skulle överskrida den angivna nodkapaciteten. Detta kan ibland förhindra placering av nya repliker eller ersätta misslyckade repliker om klustret är nästan full kapacitet och en replik med en stor belastning måste placeras, ersättas eller flyttas.
För att ge mer flexibilitet kan du ange nodbuffert eller överbokningskapacitet. När nodbuffert eller överbokningskapacitet har angetts för ett mått försöker Klusterresurshanteraren placera eller flytta repliker på ett sådant sätt att buffert- eller överbokningskapaciteten förblir oanvänd, men tillåter att buffert- eller överbokningskapaciteten används om det behövs för åtgärder som ökar tjänstens tillgänglighet, till exempel:
- Ny replikplacering eller ersättning av misslyckade repliker
- Placering under uppgraderingar
- Åtgärda överträdelser av mjuka och hårda begränsningar
- Defragmentering
Nodbuffertkapacitet representerar en reserverad del av kapaciteten under angiven nodkapacitet och överbokningskapacitet representerar en del av den extra kapaciteten ovanför angiven nodkapacitet. I båda fallen försöker Klusterresurshanteraren att hålla den här kapaciteten ledig.
Om en nod till exempel har en angiven kapacitet för måttet CpuUtilization på 100 och nodbuffertprocenten för det måttet är inställd på 20 %, blir den totala och obufferterade kapaciteten 100 respektive 80, och Klusterresurshanteraren placerar inte mer än 80 enheter av belastning på noden under normala omständigheter.

Nodbuffert bör användas när du vill reservera en del av nodkapaciteten som endast används för åtgärder som ökar tjänstens tillgänglighet som nämns ovan.
Om nodöverbokningsprocenten å andra sidan används och anges till 20 % blir de totala och obuffererade kapaciteterna 120 respektive 100.

Överbokningskapacitet bör användas när du vill tillåta att Klusterresurshanteraren placerar repliker på en nod även om deras totala resursanvändning skulle överskrida kapaciteten. Detta kan användas för att tillhandahålla ytterligare tillgänglighet för tjänster på bekostnad av prestanda. Om överbokning används måste användarprogramlogik kunna fungera med färre fysiska resurser än vad som kan krävas.
Om nodbuffert- eller överbokingskapacitet har angetts flyttas inte klusterresurshanteraren eller placerar repliker om den totala belastningen på målnoden skulle överskrida den totala kapaciteten (nodkapacitet vid nodbuffert och nodkapacitet + överbokningskapacitet vid överbokning).
Överbokningskapacitet kan också anges som oändlig. I det här fallet försöker Klusterresurshanteraren behålla den totala belastningen på noden under den angivna nodkapaciteten, men kan eventuellt lägga en mycket större belastning på noden, vilket kan leda till allvarlig prestandaförsämring.
Ett mått kan inte ha både nodbuffert och överbokingskapacitet angiven för det samtidigt.
Här är ett exempel på hur du anger nodbuffert- eller överbokningskapaciteter i ClusterManifest.xml:
<Section Name="NodeBufferPercentage">
<Parameter Name="SomeMetric" Value="0.15" />
</Section>
<Section Name="NodeOverbookingPercentage">
<Parameter Name="SomeOtherMetric" Value="0.2" />
<Parameter Name=”MetricWithInfiniteOverbooking” Value=”-1.0” />
</Section>
Här är ett exempel på hur du anger nodbuffert- eller överbokningskapaciteter via ClusterConfig.json för fristående distributioner eller Template.json för Azure-värdbaserade kluster:
"fabricSettings": [
{
"name": "NodeBufferPercentage",
"parameters": [
{
"name": "SomeMetric",
"value": "0.15"
}
]
},
{
"name": "NodeOverbookingPercentage",
"parameters": [
{
"name": "SomeOtherMetric",
"value": "0.20"
},
{
"name": "MetricWithInfiniteOverbooking",
"value": "-1.0"
}
]
}
]
Nästa steg
- Information om arkitekturen och informationsflödet i Klusterresurshanteraren finns i Översikt över klusterresurshanterarens arkitektur.
- Att definiera defragmenteringsmått är ett sätt att konsolidera belastningen på noder i stället för att sprida ut den. Information om hur du konfigurerar defragmentering finns i Defragmentering av mått och belastning i Service Fabric.
- Börja från början och få en introduktion till Service Fabric Cluster Resource Manager.
- Information om hur Klusterresurshanteraren hanterar och balanserar belastningen i klustret finns i Balansera ditt Service Fabric-kluster.