Flytta en Azure Synapse Analytics-arbetsyta från en region till en annan
Den här artikeln är en stegvis guide som visar hur du flyttar en Azure Synapse Analytics-arbetsyta från en Azure-region till en annan.
Kommentar
Stegen i den här artikeln flyttar inte arbetsytan. Stegen visar hur du skapar en ny arbetsyta i en ny region med hjälp av Azure Synapse Analytics-dedikerade SQL-poolsäkerhetskopior och artefakter från källregionen.
Förutsättningar
- Integrera källregionens Azure Synapse-arbetsyta med Azure DevOps eller GitHub. Mer information finns i Källkontroll i Synapse Studio.
- Ha Azure PowerShell - och Azure CLI-moduler installerade på servern där skript körs.
- Se till att alla beroende tjänster, till exempel Azure Machine Learning, Azure Storage och Azure Private Link-hubbar, återskapas i målregionen eller flyttas till målregionen om tjänsten stöder en regionflytt.
- Flytta Azure Storage till en annan region. Mer information finns i Flytta ett Azure Storage-konto till en annan region.
- Kontrollera att det dedikerade SQL-poolnamnet och Apache Spark-poolnamnet är samma i källregionen och målregionens arbetsyta.
Scenarier för en regionflytt
- Nya efterlevnadskrav: Organisationer kräver att data och tjänster placeras i samma region som en del av nya efterlevnadskrav.
- Tillgänglighet för en ny Azure-region: Scenarier där en ny Azure-region är tillgänglig och det finns projekt- eller affärskrav för att flytta arbetsytan och andra Azure-resurser till den nyligen tillgängliga Azure-regionen.
- Fel region har valts: Fel region valdes när Azure-resurserna skapades.
Steg för att flytta en Azure Synapse-arbetsyta till en annan region
Att flytta en Azure Synapse-arbetsyta från en region till en annan region är en process med flera steg. Här är de övergripande stegen:
- Skapa en ny Azure Synapse-arbetsyta i målregionen tillsammans med en Spark-pool med samma konfigurationer som används i källregionens arbetsyta.
- Återställ den dedikerade SQL-poolen till målregionen med hjälp av återställningspunkter eller geo-säkerhetskopior.
- Återskapa alla nödvändiga inloggningar på den nya logiska SQL Server.
- Skapa serverlösa SQL-pooler och Spark-pooldatabaser och -objekt.
- Lägg till ett Huvudnamn för Azure DevOps-tjänsten i rollbaserad åtkomstkontroll för Azure Synapse (RBAC) Synapse Artifact Publisher om du använder en Azure DevOps-versionspipeline för att distribuera artefakterna.
- Distribuera kodartefakt (SQL-skript, notebook-filer), länkade tjänster, pipelines, datauppsättningar, Utlösare för Spark-jobbdefinitioner och autentiseringsuppgifter från Azure DevOps-versionspipelines till målregionens Azure Synapse-arbetsyta.
- Lägg till Microsoft Entra-användare eller -grupper i Azure Synapse RBAC-roller. Ge Storage Blob-deltagare åtkomst till systemtilldelad hanterad identitet (SA-MI) i Azure Storage och Azure Key Vault om du autentiserar med hjälp av hanterad identitet.
- Bevilja rollerna Storage Blob Reader eller Storage Blob Contributor till nödvändiga Microsoft Entra-användare för standardansluten lagring eller på lagringskontot som har data som ska efterfrågas med hjälp av en serverlös SQL-pool.
- Återskapa lokalt installerad integrationskörning (SHIR).
- Ladda upp alla nödvändiga bibliotek och jar-filer manuellt på Azure Synapse-målarbetsytan.
- Skapa alla hanterade privata slutpunkter om arbetsytan distribueras i ett hanterat virtuellt nätverk.
- Testa den nya arbetsytan i målregionen och uppdatera eventuella DNS-poster som pekar på källregionens arbetsyta.
- Om det finns en privat slutpunktsanslutning som skapats på källarbetsytan skapar du en på målregionens arbetsyta.
- Du kan ta bort arbetsytan i källregionen när du har testat den noggrant och dirigera alla anslutningar till målregionens arbetsyta.
Förbered
Steg 1: Skapa en Azure Synapse-arbetsyta i en målregion
I det här avsnittet skapar du Azure Synapse-arbetsytan med hjälp av Azure PowerShell, Azure CLI och Azure-portalen. Du skapar en resursgrupp tillsammans med ett Azure Data Lake Storage Gen2-konto som ska användas som standardlagring för arbetsytan som en del av PowerShell-skriptet och CLI-skriptet. Om du vill automatisera distributionsprocessen anropar du dessa PowerShell- eller CLI-skript från DevOps-versionspipelinen.
Azure Portal
Om du vill skapa en arbetsyta från Azure-portalen följer du stegen i Snabbstart: Skapa en Synapse-arbetsyta.
Azure PowerShell
Följande skript skapar resursgruppen och Azure Synapse-arbetsytan med hjälp av cmdletarna New-AzResourceGroup och New-AzSynapseWorkspace.
Skapa en resursgrupp
$storageAccountName= "<YourDefaultStorageAccountName>"
$resourceGroupName="<YourResourceGroupName>"
$regionName="<YourTargetRegionName>"
$containerName="<YourFileSystemName>" # This is the file system name
$workspaceName="<YourTargetRegionWorkspaceName>"
$sourcRegionWSName="<Your source region workspace name>"
$sourceRegionRGName="<YourSourceRegionResourceGroupName>"
$sqlUserName="<SQLUserName>"
$sqlPassword="<SQLStrongPassword>"
$sqlPoolName ="<YourTargetSQLPoolName>" #Both Source and target workspace SQL pool name will be same
$sparkPoolName ="<YourTargetWorkspaceSparkPoolName>"
$sparkVersion="2.4"
New-AzResourceGroup -Name $resourceGroupName -Location $regionName
Skapa ett Data Lake Storage Gen2-konto
#If the Storage account is already created, then you can skip this step.
New-AzStorageAccount -ResourceGroupName $resourceGroupName `
-Name $storageAccountName `
-Location $regionName `
-SkuName Standard_LRS `
-Kind StorageV2 `
-EnableHierarchicalNamespace $true
Skapa en Azure Synapse-arbetsyta
$password = ConvertTo-SecureString $sqlPassword -AsPlainText -Force
$creds = New-Object System.Management.Automation.PSCredential ($sqlUserName, $password)
New-AzSynapseWorkspace -ResourceGroupName $resourceGroupName `
-Name $workspaceName -Location $regionName `
-DefaultDataLakeStorageAccountName $storageAccountName `
-DefaultDataLakeStorageFilesystem $containerName `
-SqlAdministratorLoginCredential $creds
Om du vill skapa arbetsytan med ett hanterat virtuellt nätverk lägger du till den extra parametern "ManagedVirtualNetwork" i skriptet. Mer information om tillgängliga alternativ finns i Konfiguration av hanterat virtuellt nätverk.
#Creating a managed virtual network configuration
$config = New-AzSynapseManagedVirtualNetworkConfig -PreventDataExfiltration -AllowedAadTenantIdsForLinking ContosoTenantId
#Creating an Azure Synapse workspace
New-AzSynapseWorkspace -ResourceGroupName $resourceGroupName `
-Name $workspaceName -Location $regionName `
-DefaultDataLakeStorageAccountName $storageAccountName `
-DefaultDataLakeStorageFilesystem $containerName `
-SqlAdministratorLoginCredential $creds `
-ManagedVirtualNetwork $config
Azure CLI
Det här Azure CLI-skriptet skapar en resursgrupp, ett Data Lake Storage Gen2-konto och ett filsystem. Sedan skapas Azure Synapse-arbetsytan.
Skapa en resursgrupp
az group create --name $resourceGroupName --location $regionName
Skapa ett Data Lake Storage Gen2-konto
Följande skript skapar ett lagringskonto och en container.
# Checking if name is not used only then creates it.
$StorageAccountNameAvailable=(az storage account check-name --name $storageAccountName --subscription $subscriptionId | ConvertFrom-Json).nameAvailable
if($StorageAccountNameAvailable)
{
Write-Host "Storage account Name is available to be used...creating storage account"
#Creating a Data Lake Storage Gen2 account
$storgeAccountProvisionStatus=az storage account create `
--name $storageAccountName `
--resource-group $resourceGroupName `
--location $regionName `
--sku Standard_GRS `
--kind StorageV2 `
--enable-hierarchical-namespace $true
($storgeAccountProvisionStatus| ConvertFrom-Json).provisioningState
}
else
{
Write-Host "Storage account Name is NOT available to be used...use another name -- exiting the script..."
EXIT
}
#Creating a container in a Data Lake Storage Gen2 account
$key=(az storage account keys list -g $resourceGroupName -n $storageAccountName|ConvertFrom-Json)[0].value
$fileShareStatus=(az storage share create --account-name $storageAccountName --name $containerName --account-key $key)
if(($fileShareStatus|ConvertFrom-Json).created -eq "True")
{
Write-Host f"Successfully created the fileshare - '$containerName'"
}
Skapa en Azure Synapse-arbetsyta
az synapse workspace create `
--name $workspaceName `
--resource-group $resourceGroupName `
--storage-account $storageAccountName `
--file-system $containerName `
--sql-admin-login-user $sqlUserName `
--sql-admin-login-password $sqlPassword `
--location $regionName
Om du vill aktivera ett hanterat virtuellt nätverk tar du med parametern --enable-managed-virtual-network i föregående skript. Fler alternativ finns i Arbetsytans hanterade virtuella nätverk.
az synapse workspace create `
--name $workspaceName `
--resource-group $resourceGroupName `
--storage-account $storageAccountName `
--file-system $FileShareName `
--sql-admin-login-user $sqlUserName `
--sql-admin-login-password $sqlPassword `
--location $regionName `
--enable-managed-virtual-network true `
--allowed-tenant-ids "Contoso"
Steg 2: Skapa en brandväggsregel för Azure Synapse-arbetsytan
När arbetsytan har skapats lägger du till brandväggsreglerna för arbetsytan. Begränsa IP-adresserna till ett visst intervall. Du kan lägga till en brandvägg från Azure-portalen eller med hjälp av PowerShell eller CLI.
Azure Portal
Välj brandväggsalternativen och lägg till ip-adressintervallet enligt följande skärmbild.

Azure PowerShell
Kör följande PowerShell-kommandon för att lägga till brandväggsregler genom att ange START- och slut-IP-adresserna. Uppdatera IP-adressintervallet enligt dina behov.
$WorkspaceWeb = (Get-AzSynapseWorkspace -Name $workspaceName -ResourceGroupName $resourceGroup).ConnectivityEndpoints.Web
$WorkspaceDev = (Get-AzSynapseWorkspace -Name $workspaceName -ResourceGroupName $resourceGroup).ConnectivityEndpoints.Dev
# Adding firewall rules
$FirewallParams = @{
WorkspaceName = $workspaceName
Name = 'Allow Client IP'
ResourceGroupName = $resourceGroup
StartIpAddress = "0.0.0.0"
EndIpAddress = "255.255.255.255"
}
New-AzSynapseFirewallRule @FirewallParams
Kör följande skript för att uppdatera SQL-kontrollinställningarna för den hanterade identiteten på arbetsytan:
Set-AzSynapseManagedIdentitySqlControlSetting -WorkspaceName $workspaceName -Enabled $true
Azure CLI
az synapse workspace firewall-rule create --name allowAll --workspace-name $workspaceName `
--resource-group $resourceGroupName --start-ip-address 0.0.0.0 --end-ip-address 255.255.255.255
Kör följande skript för att uppdatera SQL-kontrollinställningarna för den hanterade identiteten på arbetsytan:
az synapse workspace managed-identity grant-sql-access `
--workspace-name $workspaceName --resource-group $resourceGroupName
Steg 3: Skapa en Apache Spark-pool
Skapa Spark-poolen med samma konfiguration som används i källregionens arbetsyta.
Azure Portal
Information om hur du skapar en Spark-pool från Azure-portalen finns i Snabbstart: Skapa en ny serverlös Apache Spark-pool med azure-portalen.
Du kan också skapa Spark-poolen från Synapse Studio genom att följa stegen i Snabbstart: Skapa en serverlös Apache Spark-pool med hjälp av Synapse Studio.
Azure PowerShell
Följande skript skapar en Spark-pool med två arbetare och en drivrutinsnod och en liten klusterstorlek med 4 kärnor och 32 GB RAM-minne. Uppdatera värdena så att de matchar spark-poolen för källregionens arbetsyta.
#Creating a Spark pool with 3 nodes (2 worker + 1 driver) and a small cluster size with 4 cores and 32 GB RAM.
New-AzSynapseSparkPool `
-WorkspaceName $workspaceName `
-Name $sparkPoolName `
-NodeCount 3 `
-SparkVersion $sparkVersion `
-NodeSize Small
Azure CLI
az synapse spark pool create --name $sparkPoolName --workspace-name $workspaceName --resource-group $resourceGroupName `
--spark-version $sparkVersion --node-count 3 --node-size small
Flytta
Steg 4: Återställa en dedikerad SQL-pool
Återställa från geo-redundanta säkerhetskopior
Information om hur du återställer de dedikerade SQL-poolerna från geo-säkerhetskopiering med hjälp av Azure-portalen och PowerShell finns i Geo-återställa en dedikerad SQL-pool i Azure Synapse Analytics.
Återställa med hjälp av återställningspunkter från källregionens dedikerade SQL-pool
Återställ den dedikerade SQL-poolen till målregionens arbetsyta med hjälp av återställningspunkten för källregionens dedikerade SQL-pool. Du kan använda Azure-portalen, Synapse Studio eller PowerShell för att återställa från återställningspunkter. Om källregionen inte är tillgänglig kan du inte återställa med det här alternativet.
Synapse Studio
Från Synapse Studio kan du återställa den dedikerade SQL-poolen från valfri arbetsyta i prenumerationen med hjälp av återställningspunkter. När du skapar den dedikerade SQL-poolen under Ytterligare inställningar väljer du Återställningspunkt och väljer arbetsytan enligt följande skärmbild. Om du har skapat en användardefinierad återställningspunkt använder du den för att återställa SQL-poolen. Annars kan du välja den senaste automatiska återställningspunkten.
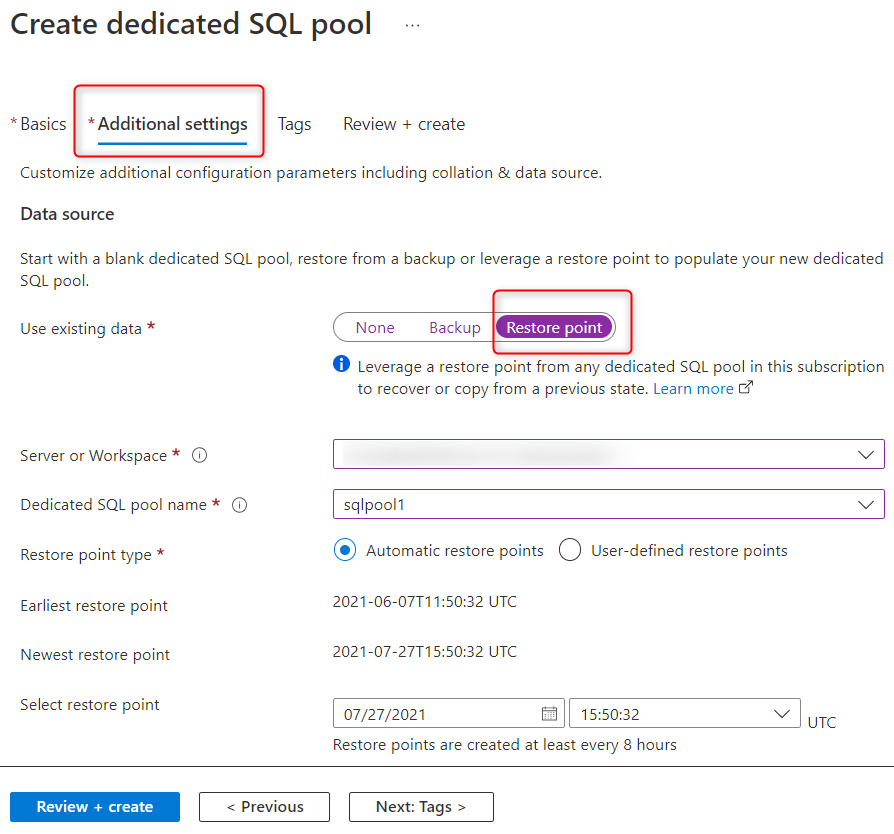
Azure PowerShell
Kör följande PowerShell-skript för att återställa arbetsytan. Det här skriptet använder den senaste återställningspunkten från källarbetsytans dedikerade SQL-pool för att återställa SQL-poolen på målarbetsytan. Innan du kör skriptet uppdaterar du prestandanivån från DW100c till det nödvändiga värdet.
Viktigt!
Det dedikerade SQL-poolnamnet ska vara detsamma på båda arbetsytorna.
Hämta återställningspunkterna:
$restorePoint=Get-AzSynapseSqlPoolRestorePoint -WorkspaceName $sourceRegionWSName -Name $sqlPoolName|Sort-Object -Property RestorePointCreationDate -Descending `
| SELECT RestorePointCreationDate -ExpandProperty RestorePointCreationDate -First 1
Omvandla resurs-ID:t för Azure Synapse SQL-poolen till SQL-databas-ID eftersom kommandot för närvarande endast accepterar SQL-databas-ID:t.
Exempelvis: /subscriptions/<SubscriptionId>/resourceGroups/<ResourceGroupName>/providers/Microsoft.Sql/servers/<WorkspaceName>/databases/<DatabaseName>
$pool = Get-AzSynapseSqlPool -ResourceGroupName $sourceRegionRGName -WorkspaceName $sourcRegionWSName -Name $sqlPoolName
$databaseId = $pool.Id `
-replace "Microsoft.Synapse", "Microsoft.Sql" `
-replace "workspaces", "servers" `
-replace "sqlPools", "databases"
$restoredPool = Restore-AzSynapseSqlPool -FromRestorePoint `
-RestorePoint $restorePoint `
-TargetSqlPoolName $sqlPoolName `
-ResourceGroupName $resourceGroupName `
-WorkspaceName $workspaceName `
-ResourceId $databaseId `
-PerformanceLevel DW100c -AsJob
Följande spårar status för återställningsåtgärden:
Get-Job | Where-Object Command -In ("Restore-AzSynapseSqlPool") | `
Select-Object Id,Command,JobStateInfo,PSBeginTime,PSEndTime,PSJobTypeName,Error |Format-Table
När den dedikerade SQL-poolen har återställts skapar du alla SQL-inloggningar i Azure Synapse. Om du vill skapa alla inloggningar följer du stegen i Skapa inloggning.
Steg 5: Skapa en serverlös SQL-pool, Spark-pooldatabas och objekt
Du kan inte säkerhetskopiera och återställa serverlösa SQL-pooldatabaser och Spark-pooler. Som en möjlig lösning kan du:
- Skapa notebook-filer och SQL-skript som har koden för att återskapa alla nödvändiga Spark-pooler, serverlösa SQL-pooldatabaser, tabeller, roller och användare med alla rolltilldelningar. Kontrollera dessa artefakter till Azure DevOps eller GitHub.
- Om namnet på lagringskontot ändras kontrollerar du att kodartefakterna pekar på rätt lagringskontonamn.
- Skapa pipelines som anropar dessa kodartefakter i en specifik sekvens. När dessa pipelines körs på målregionens arbetsyta skapas Spark SQL-databaser, serverlösa SQL-pooldatabaser, externa datakällor, vyer, roller och användare och behörigheter på arbetsytan för målregionen.
- När du integrerar källregionens arbetsyta med Azure DevOps är dessa kodartefakter en del av lagringsplatsen. Senare kan du distribuera dessa kodartefakter till målregionens arbetsyta med hjälp av DevOps-versionspipelinen enligt beskrivningen i steg 6.
- På målregionens arbetsyta utlöser du dessa pipelines manuellt.
Steg 6: Distribuera artefakter och pipelines med hjälp av CI/CD
Om du vill lära dig hur du integrerar en Azure Synapse-arbetsyta med Azure DevOps eller GitHub och hur du distribuerar artefakterna till en målregionsarbetsyta följer du stegen i Kontinuerlig integrering och kontinuerlig leverans (CI/CD) för en Azure Synapse-arbetsyta.
När arbetsytan har integrerats med Azure DevOps hittar du en gren med namnet workspace_publish. Den här grenen innehåller arbetsytemallen som innehåller definitioner för artefakter som notebook-filer, SQL-skript, datauppsättningar, länkade tjänster, pipelines, utlösare och Spark-jobbdefinitioner.
Den här skärmbilden från Azure DevOps-lagringsplatsen visar arbetsytemallfilerna för artefakterna och andra komponenter.
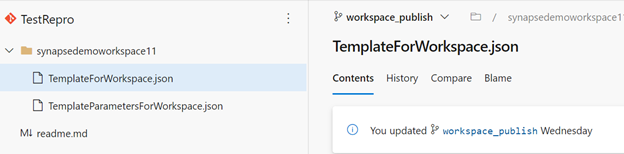
Du kan använda arbetsytemallen för att distribuera artefakter och pipelines till en arbetsyta med hjälp av Azure DevOps-versionspipelinen enligt följande skärmbild.
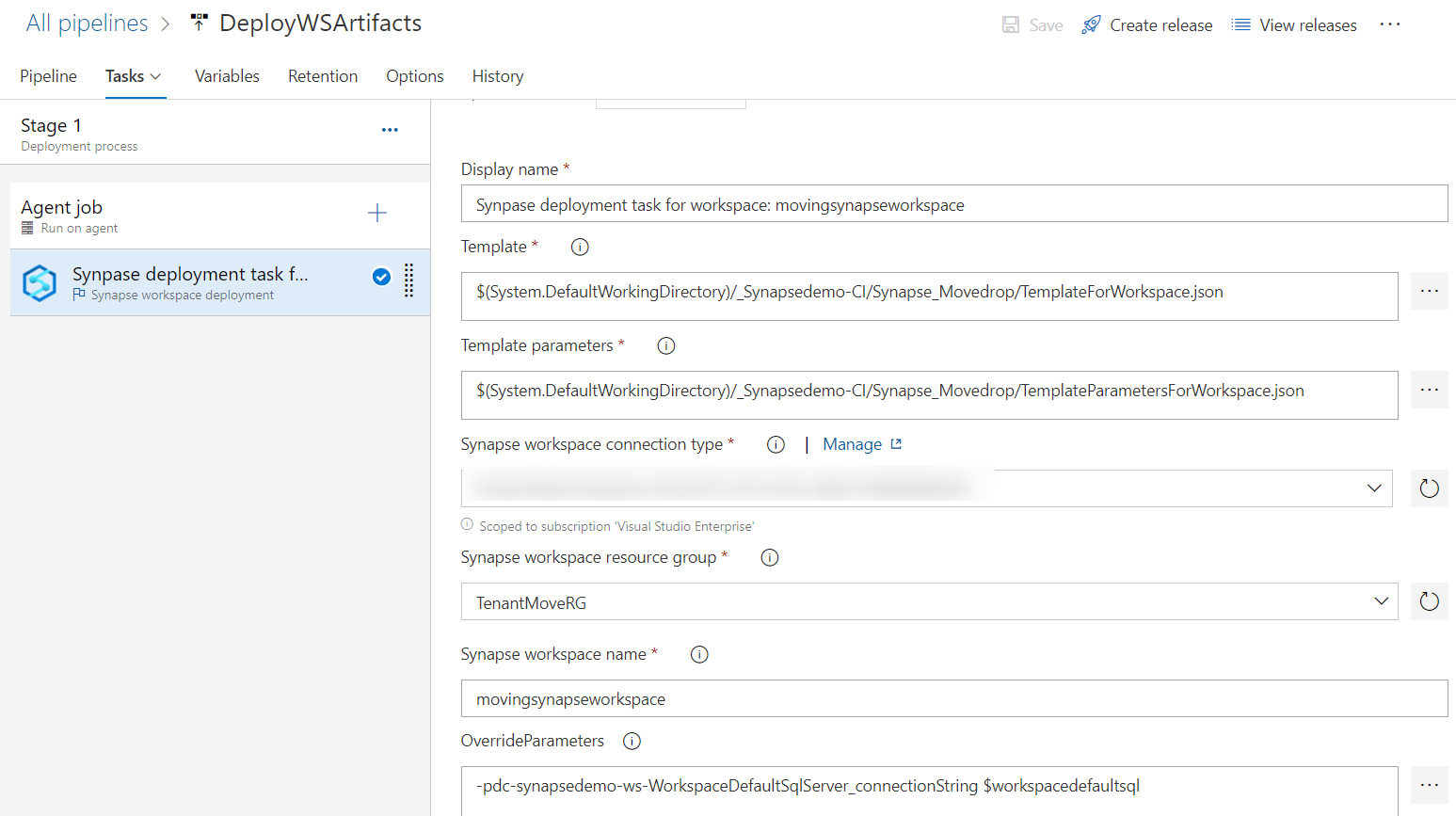
Om arbetsytan inte är integrerad med GitHub eller Azure DevOps måste du manuellt återskapa eller skriva anpassade PowerShell- eller Azure CLI-skript för att distribuera alla artefakter, pipelines, länkade tjänster, autentiseringsuppgifter, utlösare och Spark-definitioner på målregionens arbetsyta.
Kommentar
Den här processen kräver att du fortsätter att uppdatera pipelines och kodartefakter för att inkludera ändringar som gjorts i Spark och serverlösa SQL-pooler, objekt och roller i källregionens arbetsytor.
Steg 7: Skapa en delad integrationskörning
Om du vill skapa en SHIR följer du stegen i Skapa och konfigurera en lokalt installerad integrationskörning.
Steg 8: Tilldela en Azure-roll till hanterad identitet
Tilldela Storage Blob Contributor åtkomst till den hanterade identiteten för den nya arbetsytan på det standardanslutna Data Lake Storage Gen2-kontot. Tilldela även åtkomst till andra lagringskonton där SA-MI används för autentisering. Tilldela Storage Blob Contributor eller Storage Blob Reader åtkomst till Microsoft Entra-användare och -grupper för alla nödvändiga lagringskonton.
Azure Portal
Följ stegen i Bevilja behörigheter till arbetsytans hanterade identitet för att tilldela rollen Storage Blob Data Contributor till arbetsytans hanterade identitet.
Azure PowerShell
Tilldela rollen Storage Blob Data Contributor till arbetsytans hanterade identitet.
Lägga till Storage Blob Data-deltagare i arbetsytans hanterade identitet på lagringskontot. Körningen av New-AzRoleAssignment fel med meddelandet Exception of type 'Microsoft.Rest.Azure.CloudException' was thrown. skapar dock de behörigheter som krävs för lagringskontot.
$workSpaceIdentityObjectID= (Get-AzSynapseWorkspace -ResourceGroupName $resourceGroupName -Name $workspaceName).Identity.PrincipalId
$scope = "/subscriptions/$($subscriptionId)/resourceGroups/$($resourceGroupName)/providers/Microsoft.Storage/storageAccounts/$($storageAccountName)"
$roleAssignedforManagedIdentity=New-AzRoleAssignment -ObjectId $workSpaceIdentityObjectID `
-RoleDefinitionName "Storage Blob Data Contributor" `
-Scope $scope -ErrorAction SilentlyContinue
Azure CLI
Hämta rollnamn, resurs-ID och huvudnamns-ID för arbetsytans hanterade identitet och lägg sedan till Azure-rollen Storage Blob Data Contributor i SA-MI.
# Getting Role name
$roleName =az role definition list --query "[?contains(roleName, 'Storage Blob Data Contributor')].{roleName:roleName}" --output tsv
#Getting resource id for storage account
$scope= (az storage account show --name $storageAccountName|ConvertFrom-Json).id
#Getting principal ID for workspace managed identity
$workSpaceIdentityObjectID=(az synapse workspace show --name $workspaceName --resource-group $resourceGroupName|ConvertFrom-Json).Identity.PrincipalId
# Adding Storage Blob Data Contributor Azure role to SA-MI
az role assignment create --assignee $workSpaceIdentityObjectID `
--role $roleName `
--scope $scope
Steg 9: Tilldela Azure Synapse RBAC-roller
Lägg till alla användare som behöver åtkomst till målarbetsytan med separata roller och behörigheter. Följande PowerShell- och CLI-skript lägger till en Microsoft Entra-användare till rollen Synapse-administratör i målregionens arbetsyta.
Information om hur du hämtar alla RBAC-rollnamn för Azure Synapse finns i Azure Synapse RBAC-roller.
Synapse Studio
Om du vill lägga till eller ta bort Azure Synapse RBAC-tilldelningar från Synapse Studio följer du stegen i Hantera RBAC-rolltilldelningar i Azure Synapse Studio.
Azure PowerShell
Följande PowerShell-skript lägger till rolltilldelningen Synapse Administrator till en Microsoft Entra-användare eller grupp. Du kan använda -RoleDefinitionId i stället för -RoleDefinitionName med följande kommando för att lägga till användarna på arbetsytan:
New-AzSynapseRoleAssignment `
-WorkspaceName $workspaceName `
-RoleDefinitionName "Synapse Administrator" `
-ObjectId 1c02d2a6-ed3d-46ec-b578-6f36da5819c6
Get-AzSynapseRoleAssignment -WorkspaceName $workspaceName
Kör kommandot för att hämta ObjectIds och RoleIds i källregionens arbetsyta Get-AzSynapseRoleAssignment . Tilldela samma Azure Synapse RBAC-roller till Microsoft Entra-användare eller -grupper på målregionens arbetsyta.
I stället för att använda -ObjectId som parameter kan du också använda -SignInName, där du anger e-postadressen eller användarens huvudnamn. Mer information om tillgängliga alternativ finns i Azure Synapse RBAC – PowerShell-cmdlet.
Azure CLI
Hämta användarens objekt-ID och tilldela nödvändiga Azure Synapse RBAC-behörigheter till Microsoft Entra-användaren. Du kan ange e-postadressen för användaren (username@contoso.com) för parametern --assignee .
az synapse role assignment create `
--workspace-name $workspaceName `
--role "Synapse Administrator" --assignee adasdasdd42-0000-000-xxx-xxxxxxx
az synapse role assignment create `
--workspace-name $workspaceName `
--role "Synapse Contributor" --assignee "user1@contoso.com"
Mer information om tillgängliga alternativ finns i Azure Synapse RBAC – CLI.
Steg 10: Ladda upp arbetsytepaket
Ladda upp alla nödvändiga arbetsytepaket till den nya arbetsytan. Information om hur du automatiserar uppladdningen av arbetsytepaketen finns i Microsoft Azure Synapse Analytics Artifacts-klientbiblioteket.
Steg 11: Behörigheter
Om du vill konfigurera åtkomstkontrollen för målregionens Azure Synapse-arbetsyta följer du stegen i Konfigurera åtkomstkontroll för din Azure Synapse-arbetsyta.
Steg 12: Skapa hanterade privata slutpunkter
Information om hur du återskapar hanterade privata slutpunkter från källregionens arbetsyta i målregionens arbetsyta finns i Skapa en hanterad privat slutpunkt till datakällan.
Ignorera
Om du vill ta bort arbetsytan för målregionen tar du bort arbetsytan för målregionen. Om du vill göra det går du till resursgruppen från instrumentpanelen i portalen och väljer arbetsytan och väljer Ta bort överst på sidan Resursgrupp.
Rensa
Om du vill checka in ändringarna och slutföra flytten av arbetsytan tar du bort källregionens arbetsyta efter att ha testat arbetsytan i målregionen. Om du vill göra det går du till den resursgrupp som har källregionens arbetsyta från instrumentpanelen i portalen och väljer arbetsytan och väljer Ta bort överst på sidan Resursgrupp.
Nästa steg
- Läs mer om hanterade virtuella Azure Synapse-nätverk.
- Läs mer om hanterade privata Slutpunkter i Azure Synapse.
- Läs mer om hur du ansluter till arbetsyteresurser från ett begränsat nätverk.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för