Skapa, utveckla och underhålla Synapse-notebook-filer i Azure Synapse Analytics
En Synapse-notebook-fil är ett webbgränssnitt där du kan skapa filer som innehåller livekod, visualiseringar och narrativ text. Notebook-filer är ett bra ställe att validera idéer och använda snabba experiment för att få insikter från dina data. Notebook-filer används också ofta i dataförberedelser, datavisualisering, maskininlärning och andra stordatascenarier.
Med en Synapse-anteckningsbok kan du:
- Kom igång med noll installationsarbete.
- Skydda data med inbyggda säkerhetsfunktioner för företag.
- Analysera data mellan rådataformat (CSV, txt, JSON osv.), bearbetade filformat (parquet, Delta Lake, ORC osv.) och SQL-tabelldatafiler mot Spark och SQL.
- Var produktiv med förbättrade redigeringsfunktioner och inbyggd datavisualisering.
Den här artikeln beskriver hur du använder notebook-filer i Synapse Studio.
Skapa en notebook-fil
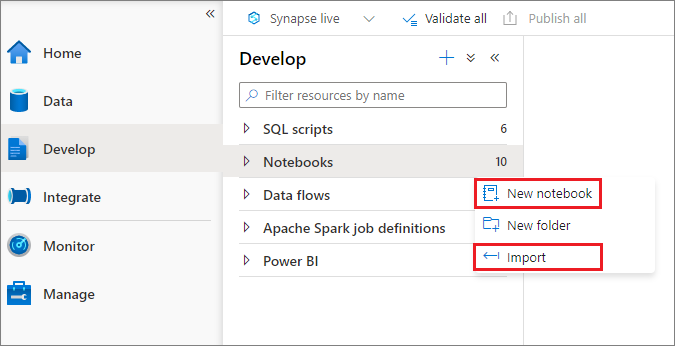
Det finns två sätt att skapa en notebook-fil. Du kan skapa en ny notebook-fil eller importera en befintlig anteckningsbok till en Synapse-arbetsyta från Object Explorer. Synapse-notebook-filer känner igen IPYNB-standardfiler för Jupyter Notebook.
Utveckla notebook-filer
Notebook-filer består av celler, som är enskilda kod- eller textblock som kan köras oberoende av varandra eller som en grupp.
Vi tillhandahåller omfattande åtgärder för att utveckla notebook-filer:
- Lägga till en cell
- Ange ett primärt språk
- Använda flera språk
- Använda temporära tabeller för att referera till data mellan språk
- IntelliSense i IDE-stil
- Kodstycken
- Formatera textcell med verktygsfältsknappar
- Ångra/gör om cellåtgärden
- Kodcellskommentering
- Flytta en cell
- Ta bort en cell
- Dölj en cellinmatning
- Dölj en cellutdata
- Anteckningsboksdisposition
Kommentar
I notebook-filerna skapas en SparkSession automatiskt åt dig, som lagras i en variabel med namnet spark. Det finns också en variabel för SparkContext som kallas sc. Användare kan komma åt dessa variabler direkt och bör inte ändra värdena för dessa variabler.
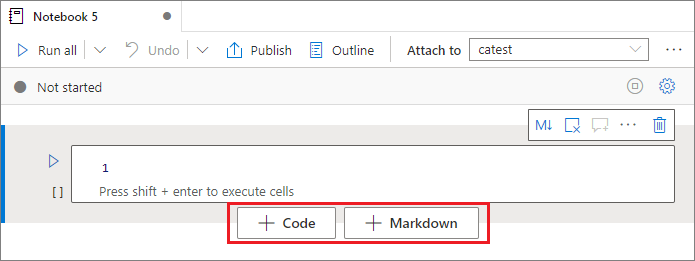
Lägga till en cell
Det finns flera sätt att lägga till en ny cell i anteckningsboken.
Hovra över utrymmet mellan två celler och välj Kod eller Markdown.
Använd aznb-kortkommandon i kommandoläge. Tryck på A för att infoga en cell ovanför den aktuella cellen. Tryck på B för att infoga en cell under den aktuella cellen.
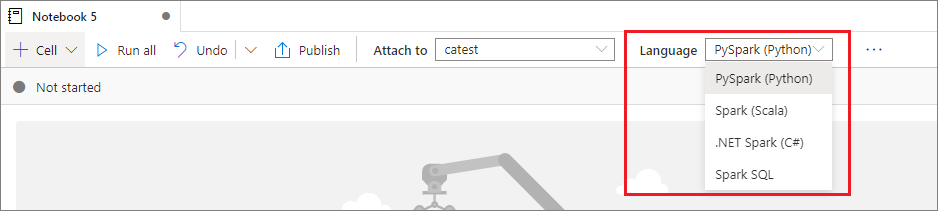
Ange ett primärt språk
Synapse-notebook-filer stöder fyra Apache Spark-språk:
- PySpark (Python)
- Spark (Scala)
- Spark SQL
- .NET Spark (C#)
- SparkR (R)
Du kan ange primärt språk för nya tillagda celler från listrutan i det översta kommandofältet.
Använda flera språk
Du kan använda flera språk i en anteckningsbok genom att ange rätt språkmagikommando i början av en cell. I följande tabell visas de magiska kommandona för att växla cellspråk.
| Magiskt kommando | Språk | beskrivning |
|---|---|---|
| %%pyspark | Python | Kör en Python-fråga mot Spark-kontext. |
| %%spark | Scala | Kör en Scala-fråga mot Spark-kontext. |
| %%sql | SparkSQL | Kör en SparkSQL-fråga mot Spark-kontext. |
| %%csharp | .NET för Spark C# | Kör en .NET för Spark C#- fråga mot Spark-kontext. |
| %%sparkr | R | Kör en R-fråga mot Spark-kontext. |
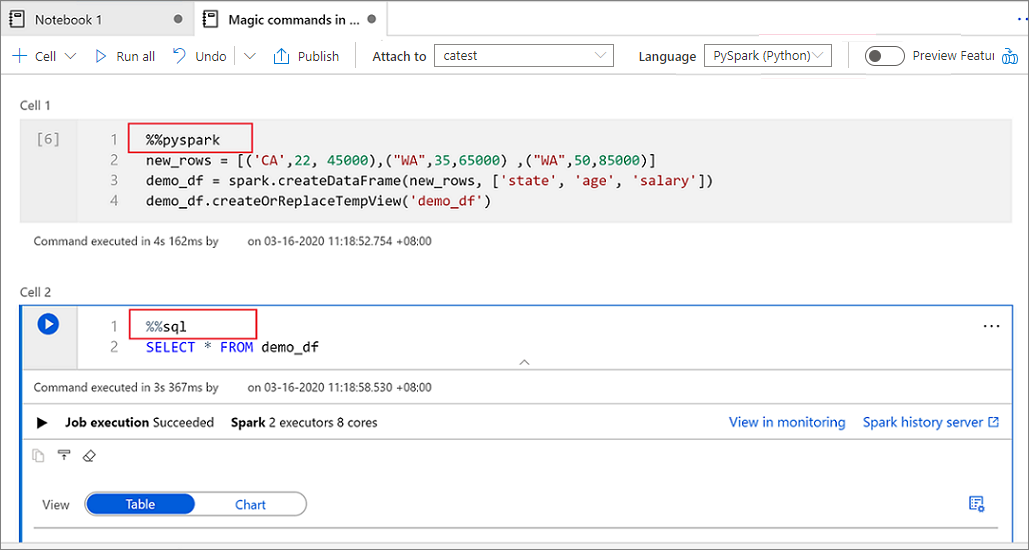
Följande bild är ett exempel på hur du kan skriva en PySpark-fråga med hjälp av det magiska kommandot %%pyspark eller en SparkSQL-fråga med kommandot %%sql magic i en Spark(Scala) -anteckningsbok. Observera att det primära språket för notebook-filen är inställt på pySpark.
Använda temporära tabeller för att referera till data mellan språk
Du kan inte referera till data eller variabler direkt på olika språk i en Synapse-anteckningsbok. I Spark kan en tillfällig tabell refereras till mellan olika språk. Här är ett exempel på hur du läser en Scala DataFrame i PySpark och SparkSQL använder en Spark temp-tabell som en lösning.
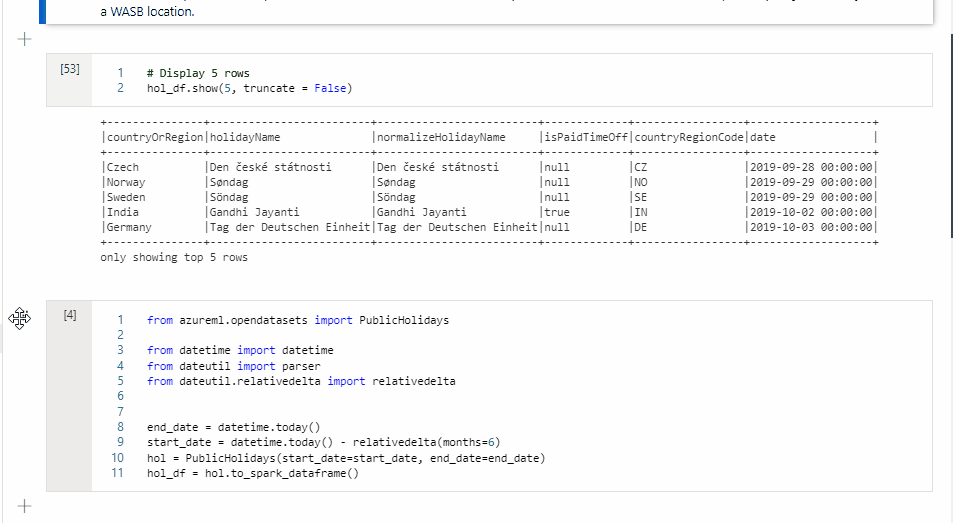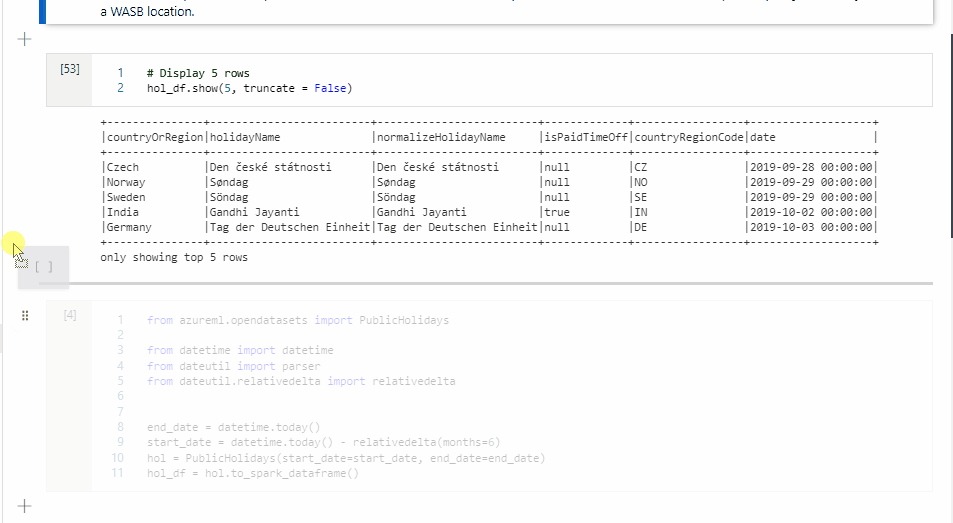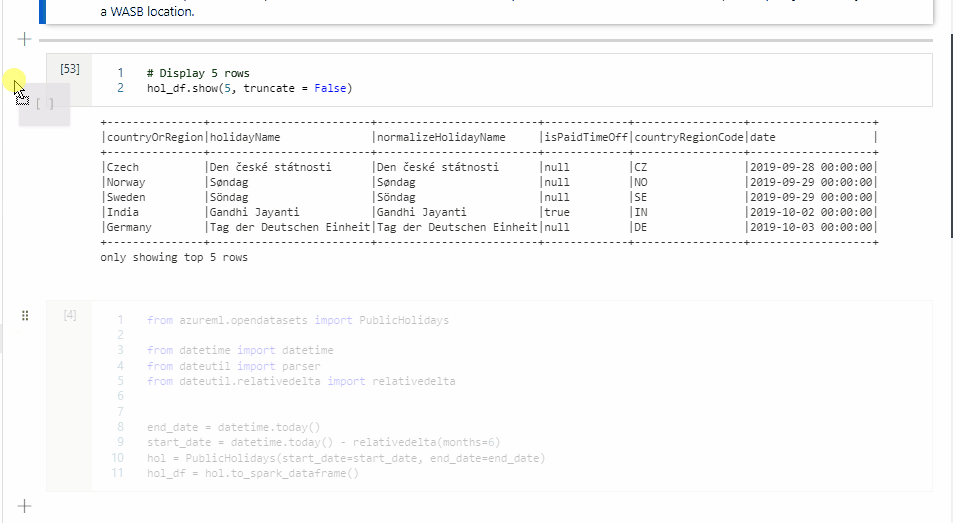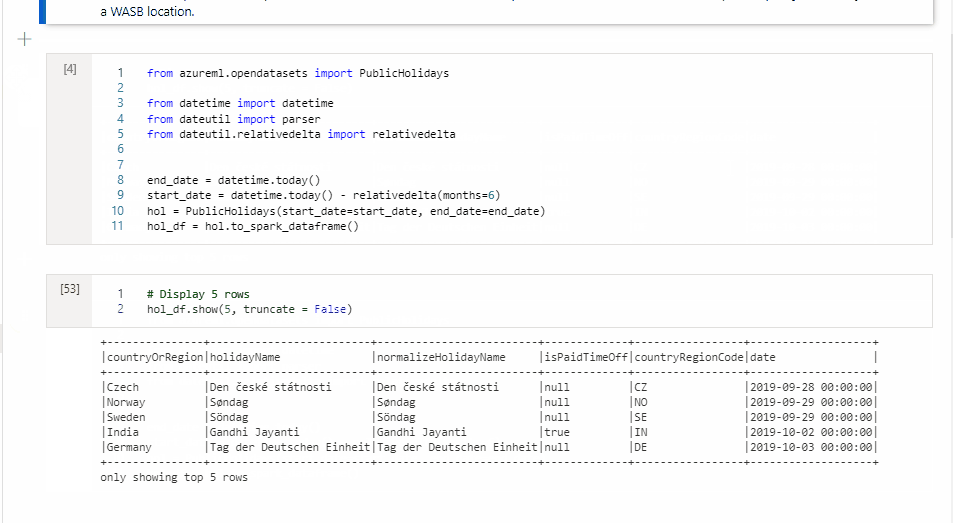
I Cell 1 läser du en DataFrame från en SQL-poolanslutning med Scala och skapar en tillfällig tabell.
%%spark val scalaDataFrame = spark.read.sqlanalytics("mySQLPoolDatabase.dbo.mySQLPoolTable") scalaDataFrame.createOrReplaceTempView( "mydataframetable" )I Cell 2 kör du frågor mot data med Hjälp av Spark SQL.
%%sql SELECT * FROM mydataframetableI Cell 3 använder du data i PySpark.
%%pyspark myNewPythonDataFrame = spark.sql("SELECT * FROM mydataframetable")
IntelliSense i IDE-stil
Synapse-notebook-filer är integrerade med Monaco-redigeraren för att ta IDE-stil IntelliSense till cellredigeraren. Syntaxmarkering, felmarkör och automatiska kodkompletteringar hjälper dig att skriva kod och identifiera problem snabbare.
IntelliSense-funktionerna har olika mognadsnivåer för olika språk. Använd följande tabell för att se vad som stöds.
| Språk | Syntaxmarkering | Syntaxfelmarkör | Slutförande av syntaxkod | Slutförande av variabelkod | Systemfunktionens kod har slutförts | Kodkomplettering av användarfunktion | Smarta indrag | Koddelegering |
|---|---|---|---|---|---|---|---|---|
| PySpark (Python) | Ja | Ja | Ja | Ja | Ja | Ja | Ja | Ja |
| Spark (Scala) | Ja | Ja | Ja | Ja | Ja | Ja | - | Ja |
| SparkSQL | Ja | Ja | Ja | Ja | Ja | - | - | - |
| .NET för Spark (C#) | Ja | Ja | Ja | Ja | Ja | Ja | Ja | Ja |
Kommentar
En aktiv Spark-session krävs för att gynna slutförande av variabelkod, slutförande av systemfunktionskod, slutförande av användarfunktionskod för .NET för Spark (C#).
Kodfragment
Synapse-notebook-filer innehåller kodfragment som gör det enklare att ange vanliga kodmönster som att konfigurera Spark-sessionen, läsa data som en Spark DataFrame eller rita diagram med matplotlib osv.
Kodfragment visas i Genvägsnycklar av IDE-format IntelliSense blandat med andra förslag. Innehållet i kodfragmenten överensstämmer med kodcellsspråket. Du kan se tillgängliga kodfragment genom att skriva kodfragment eller nyckelord som visas i kodfragmentrubriken i kodcellsredigeraren. Genom att till exempel skriva läsa kan du se listan med kodfragment för att läsa data från olika datakällor.

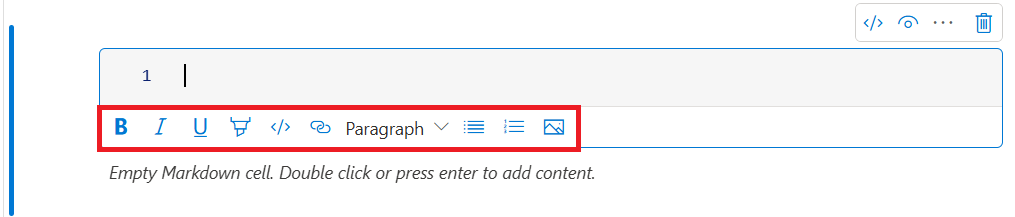
Formatera textcell med verktygsfältsknappar
Du kan använda formatknapparna i verktygsfältet för textceller för att utföra vanliga markdown-åtgärder. Den innehåller fetstil, kursiv text, stycke/rubriker via en listruta, infoga kod, infoga osorterad lista, infoga ordnad lista, infoga hyperlänk och infoga bild från URL.
Ångra/gör om cellåtgärden
Välj knappen Ångra / om eller tryck på Z / Skift+Z för att återkalla de senaste cellåtgärderna. Nu kan du ångra/göra om till de senaste 10 historiska cellåtgärderna.

Stöd för ångra cellåtgärder:
- Infoga/ta bort cell: Du kan återkalla borttagningsåtgärderna genom att välja Ångra. Textinnehållet sparas tillsammans med cellen.
- Ändra ordning på cellen.
- Växla parameter.
- Konvertera mellan kodcell och Markdown-cell.
Kommentar
Textåtgärder i cellen och kodcellskommenteringsåtgärder kan inte ångras. Nu kan du ångra/göra om till de senaste 10 historiska cellåtgärderna.
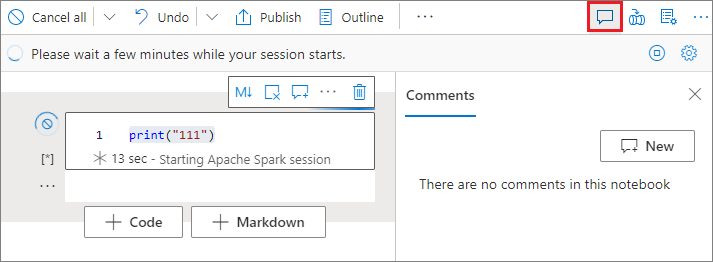
Kodcellskommentering
Välj knappen Kommentarer i anteckningsbokens verktygsfält för att öppna fönstret Kommentarer .
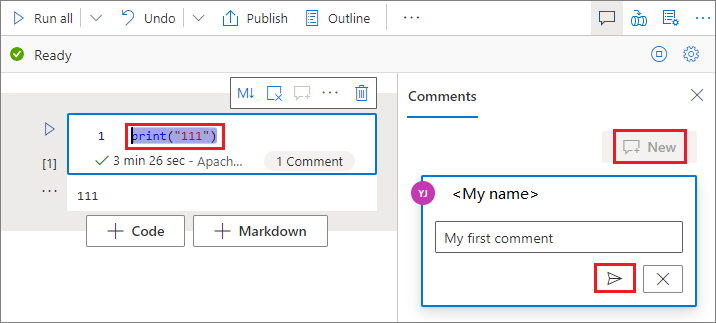
Välj kod i kodcellen, klicka på Nytt i fönstret Kommentarer , lägg till kommentarer och klicka sedan på knappen Publicera kommentar för att spara.
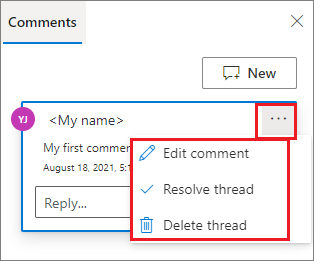
Du kan utföra Redigera kommentar, Lösa tråd eller Ta bort tråd genom att klicka på knappen Mer förutom kommentaren.
Flytta en cell
Klicka på vänster sida av en cell och dra den till önskad position.
Ta bort en cell
Om du vill ta bort en cell väljer du knappen Ta bort till höger i cellen.
Du kan också använda kortkommandon i kommandoläge. Tryck på Skift+D för att ta bort den aktuella cellen.
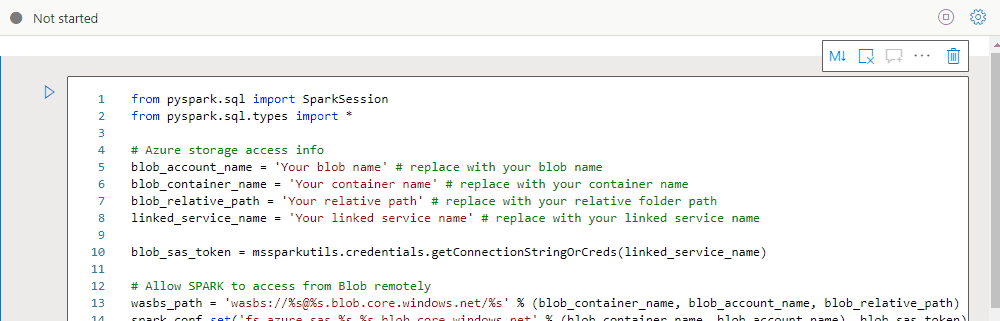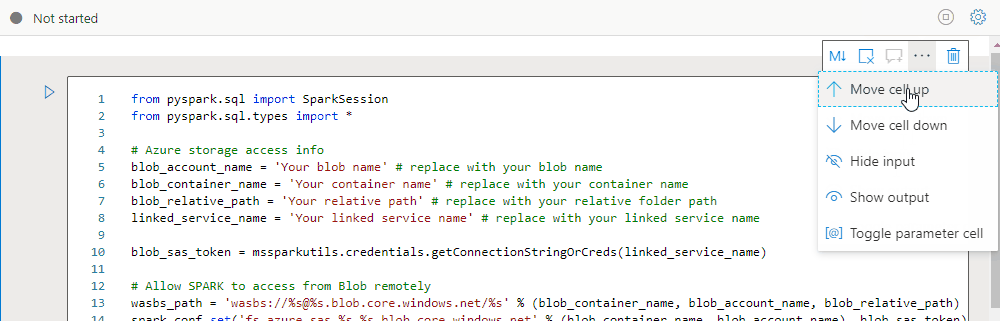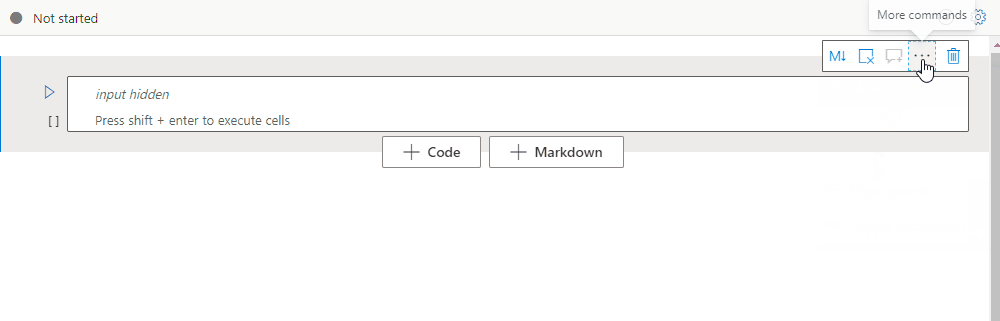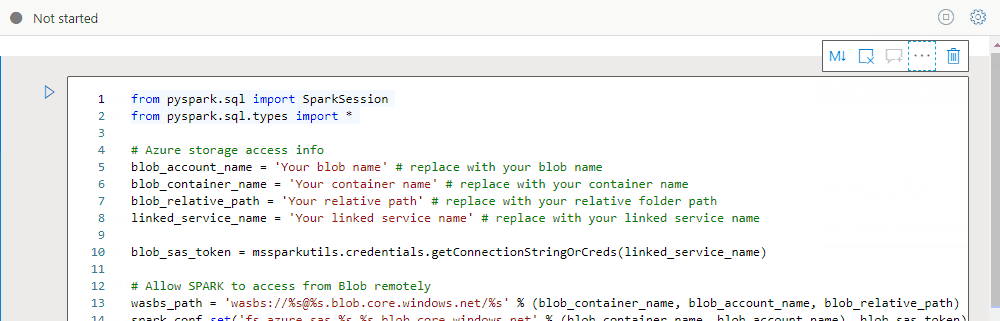
Dölj en cellinmatning
Välj ellipserna Fler kommandon (...) i cellverktygsfältet och Dölj indata för att dölja den aktuella cellens indata. Om du vill expandera den väljer du Visa indata medan cellen är komprimerad.
Dölj en cellutdata
Välj ellipserna Fler kommandon (...) i cellverktygsfältet och Dölj utdata för att dölja den aktuella cellens utdata. Om du vill expandera den väljer du Visa utdata medan cellens utdata är dolda.

Anteckningsboksdisposition
Dispositioner (innehållsförteckning) visar den första markdown-rubriken för en markdown-cell i ett sidofältsfönster för snabb navigering. Sidopanelen Dispositioner kan storleksanpassas och komprimeras så att den passar skärmen på bästa möjliga sätt. Du kan välja knappen Disposition i anteckningsbokens kommandofält för att öppna eller dölja sidofältet
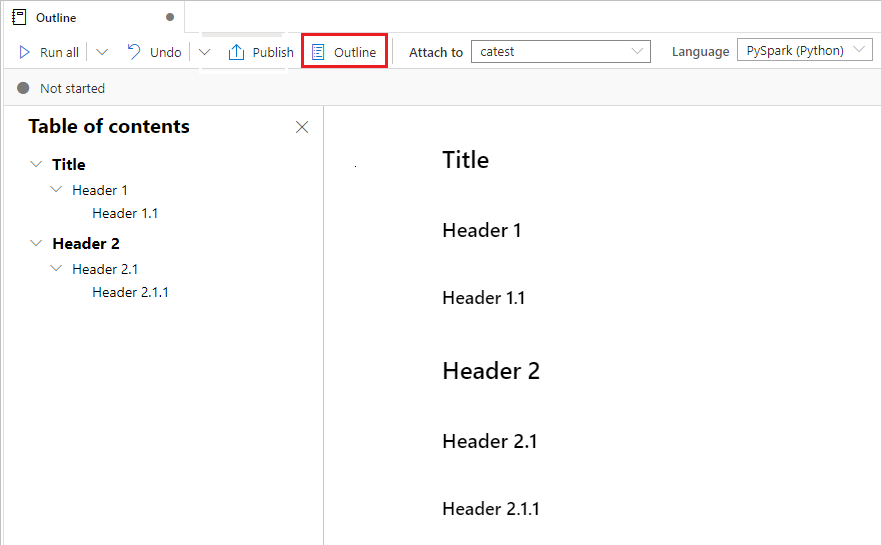
Köra notebook-filer
Du kan köra kodcellerna i anteckningsboken individuellt eller på en gång. Status och förlopp för varje cell representeras i notebook-filen.
Köra en cell
Det finns flera sätt att köra koden i en cell.
Hovra över cellen som du vill köra och välj knappen Kör cell eller tryck på Ctrl+Retur.

Använd kortkommandon i kommandoläge. Tryck på Skift+Retur för att köra den aktuella cellen och markera cellen nedan. Tryck på Alt+Retur för att köra den aktuella cellen och infoga en ny cell nedan.
Kör alla celler
Välj knappen Kör alla för att köra alla celler i den aktuella notebook-filen i följd.

Kör alla celler ovanför eller under
Expandera listrutan från knappen Kör alla och välj sedan Kör celler ovan för att köra alla celler ovanför den aktuella i sekvensen. Välj Kör celler nedan för att köra alla celler under strömmen i följd.
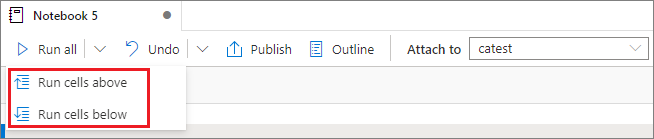
Avbryt alla celler som körs
Välj knappen Avbryt alla för att avbryta de celler som körs i kön.

Referens för notebook-fil
Du kan använda %run <notebook path> magiskt kommando för att referera till en annan notebook-fil i den aktuella notebook-filens kontext. Alla variabler som definierats i referensanteckningsboken är tillgängliga i den aktuella notebook-filen. %run magiskt kommando stöder kapslade anrop men stöder inte rekursiva anrop. Du får ett undantag om instruktionsdjupet är större än fem.
Exempel: %run /<path>/Notebook1 { "parameterInt": 1, "parameterFloat": 2.5, "parameterBool": true, "parameterString": "abc" }.
Notebook-referens fungerar i både interaktivt läge och Synapse-pipeline.
Kommentar
%runkommandot stöder för närvarande endast att skicka en absolut sökväg eller ett notebook-namn som parameter. Relativ sökväg stöds inte.%runkommandot stöder för närvarande endast 4 parametervärdetyper:int,float,bool,string, variabel ersättningsåtgärd stöds inte.- De refererade notebook-filerna måste publiceras. Du måste publicera anteckningsböckerna för att referera till dem såvida inte Den opublicerade anteckningsboken är aktiverad. Synapse Studio känner inte igen de opublicerade notebook-filerna från Git-lagringsplatsen.
- Refererade notebook-filer har inte stöd för instruktionen att djupet är större än fem.
Variabelutforskaren
Synapse Notebook innehåller en inbyggd utforskare för variabler där du kan se listan över variablernas namn, typ, längd och värde i den aktuella Spark-sessionen för PySpark-celler (Python). Fler variabler visas automatiskt när de definieras i kodcellerna. Om du klickar på varje kolumnrubrik sorteras variablerna i tabellen.
Du kan välja knappen Variabler i notebook-kommandofältet för att öppna eller dölja variabelutforskaren.
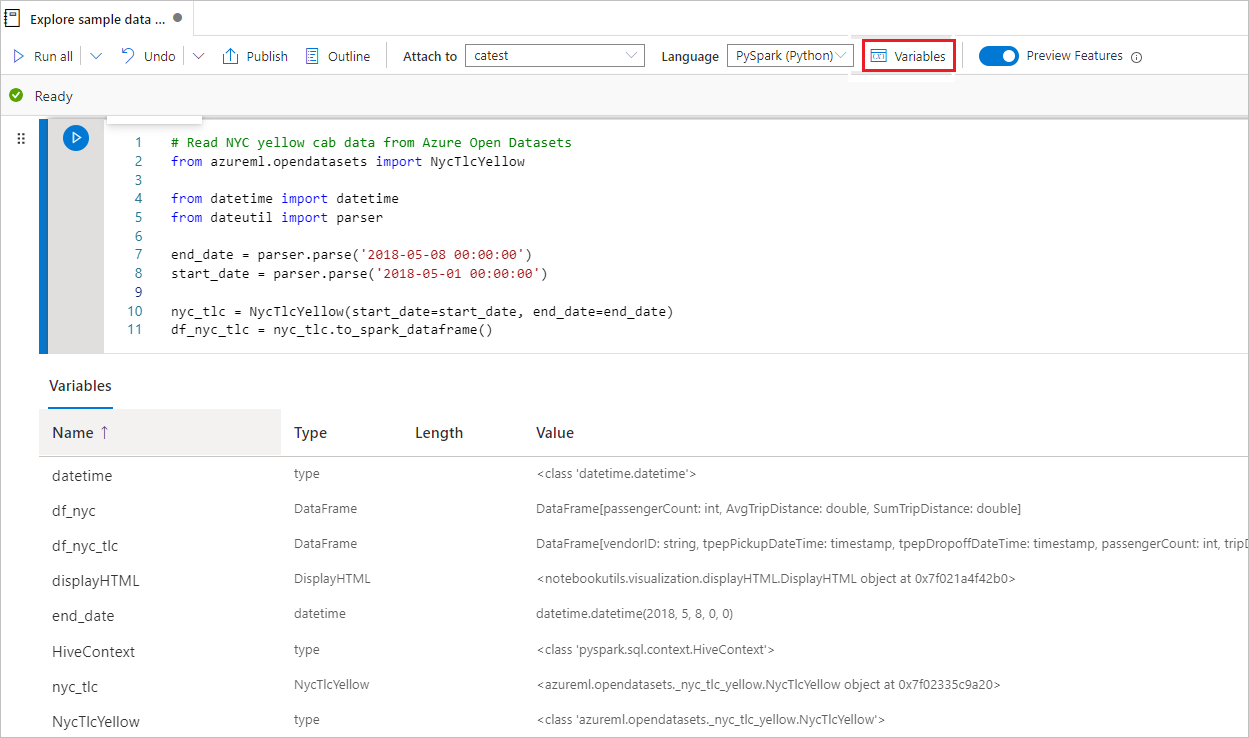
Kommentar
Variabelutforskaren stöder endast python.
Indikator för cellstatus
En steg-för-steg-cellkörningsstatus visas under cellen för att hjälpa dig att se dess aktuella förlopp. När cellkörningen är klar visas en körningssammanfattning med den totala varaktigheten och sluttiden och sparas där för framtida referens.

Indikator för Spark-förlopp
Synapse Notebook är enbart Spark-baserad. Kodceller körs på den serverlösa Apache Spark-poolen via fjärranslutning. En förloppsindikator för Spark-jobb tillhandahålls med en förloppsindikator i realtid som hjälper dig att förstå statusen för jobbkörning. Antalet uppgifter per jobb eller fas hjälper dig att identifiera den parallella nivån för ditt Spark-jobb. Du kan också öka detaljnivån för Spark-användargränssnittet för ett visst jobb (eller fas) genom att välja länken för jobbets (eller fasens) namn.
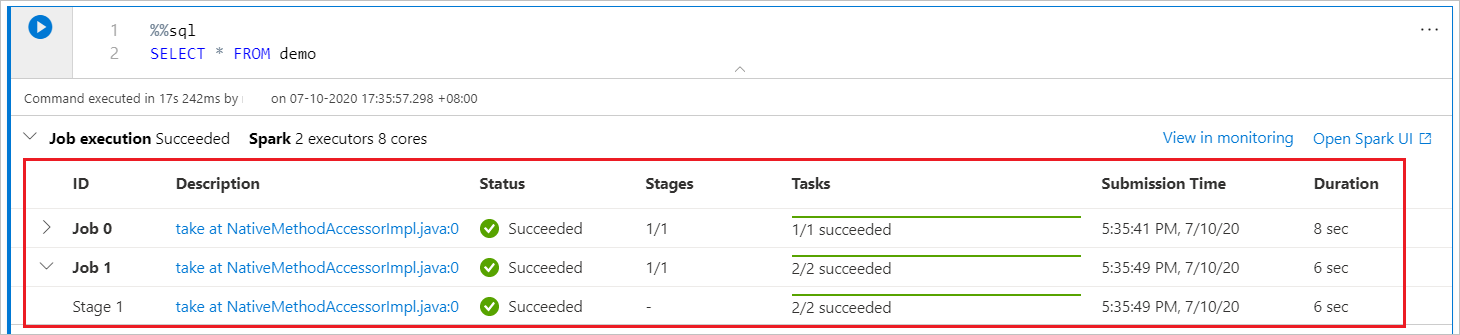
Konfiguration av Spark-sessioner
Du kan ange tidsgränsens varaktighet, antalet och storleken på de köre som ska anges för den aktuella Spark-sessionen i Konfigurera sessionen. Starta om Spark-sessionen för att konfigurationsändringar ska börja gälla. Alla cachelagrade notebook-variabler rensas.
Du kan också skapa en konfiguration från Apache Spark-konfigurationen eller välja en befintlig konfiguration. Mer information finns i Apache Spark Configuration Management.

Magiskt kommando för Spark-sessionskonfiguration
Du kan också ange inställningar för Spark-sessioner via ett magiskt kommando %%configure. Spark-sessionen måste startas om för att inställningarna ska gälla. Vi rekommenderar att du kör %%configure i början av notebook-filen. Här är ett exempel som du kan se för en https://github.com/cloudera/livy#request-body fullständig lista över giltiga parametrar.
%%configure
{
//You can get a list of valid parameters to config the session from https://github.com/cloudera/livy#request-body.
"driverMemory":"28g", // Recommended values: ["28g", "56g", "112g", "224g", "400g", "472g"]
"driverCores":4, // Recommended values: [4, 8, 16, 32, 64, 80]
"executorMemory":"28g",
"executorCores":4,
"jars":["abfs[s]://<file_system>@<account_name>.dfs.core.windows.net/<path>/myjar.jar","wasb[s]://<containername>@<accountname>.blob.core.windows.net/<path>/myjar1.jar"],
"conf":{
//Example of standard spark property, to find more available properties please visit:https://spark.apache.org/docs/latest/configuration.html#application-properties.
"spark.driver.maxResultSize":"10g",
//Example of customized property, you can specify count of lines that Spark SQL returns by configuring "livy.rsc.sql.num-rows".
"livy.rsc.sql.num-rows":"3000"
}
}
Kommentar
- "DriverMemory" och "ExecutorMemory" rekommenderas att ange samma värde i %%configure, så gör även "driverCores" och "executorCores".
- Du kan använda %%configure i Synapse-pipelines, men om den inte anges i den första kodcellen misslyckas pipelinekörningen på grund av att sessionen inte kan startas om.
- %%configure som används i mssparkutils.notebook.run ignoreras men används i %run notebook fortsätter att köras.
- Spark-standardkonfigurationsegenskaperna måste användas i "conf"-brödtexten. Vi stöder inte referens på första nivån för Spark-konfigurationsegenskaperna.
- Vissa speciella spark-egenskaper som "spark.driver.cores", "spark.executor.cores", "spark.driver.memory", "spark.executor.memory", "spark.executor.instances" börjar inte gälla i "conf"-brödtexten.
Parameteriserad sessionskonfiguration från pipeline
Med parametriserad sessionskonfiguration kan du ersätta värdet i %%configure magic med pipelinekörningsparametrar (Notebook-aktivitet). När du förbereder %%configure code cell kan du åsidosätta standardvärden (även konfigurerbara, 4 och "2000" i exemplet nedan) med ett objekt som det här:
{
"activityParameterName": "paramterNameInPipelineNotebookActivity",
"defaultValue": "defaultValueIfNoParamterFromPipelineNotebookActivity"
}
%%configure
{
"driverCores":
{
"activityParameterName": "driverCoresFromNotebookActivity",
"defaultValue": 4
},
"conf":
{
"livy.rsc.sql.num-rows":
{
"activityParameterName": "rows",
"defaultValue": "2000"
}
}
}
Notebook använder standardvärdet om du kör en notebook-fil i interaktivt läge direkt eller ingen parameter som matchar "activityParameterName" anges från pipeline notebook-aktiviteten.
Under pipelinekörningsläget kan du konfigurera aktivitetsinställningar för notebook-pipeline enligt nedan: 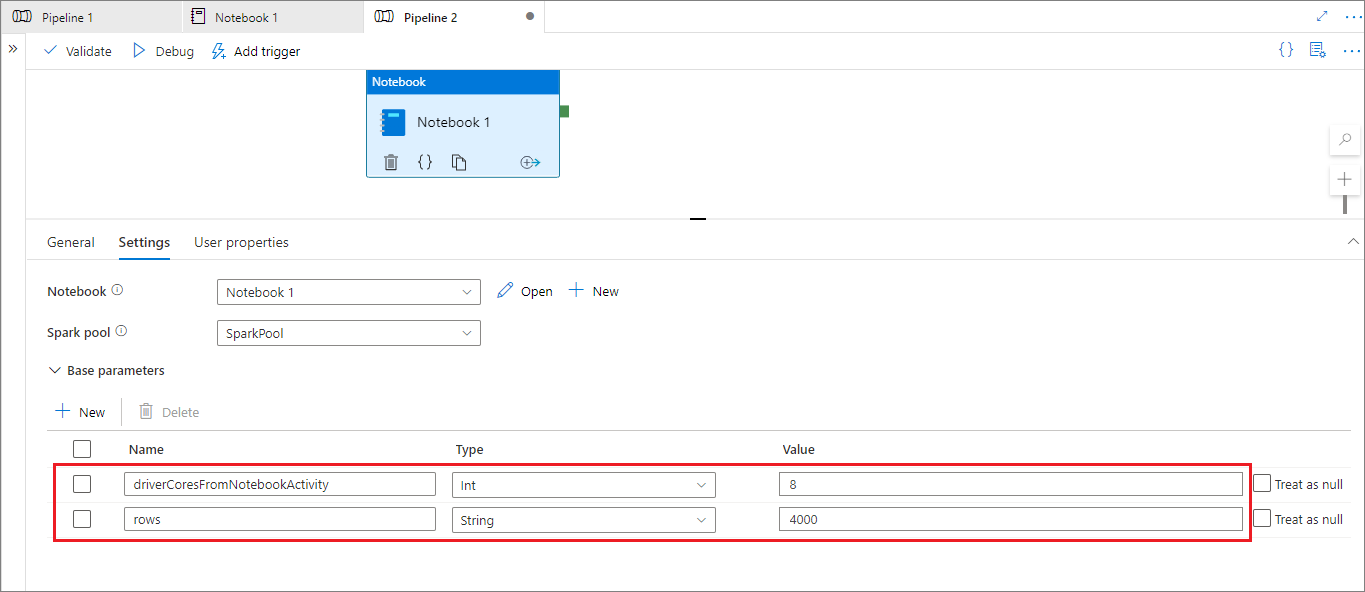
Om du vill ändra sessionskonfigurationen bör pipelinens namn på notebook-aktivitetsparametrar vara samma som activityParameterName i notebook-filen. När du kör den här pipelinen ersätts kärnor i %%configure i det här exemplet med 8 och livy.rsc.sql.num-rows ersätts med 4 000.
Kommentar
Om körningspipelinen misslyckades på grund av att den här nya %%configure-magin används kan du kontrollera mer felinformation genom att köra %%configure magic cell in the interactive mode of the notebook.if run pipeline failed because of using this new %%configure magic cell in the interactive mode of the notebook.if run pipeline failed because of using this new %%configure magic, you can check more error information by running %%configure magic cell in the interactive mode of the notebook.
Ta data till en notebook-fil
Du kan läsa in data från Azure Blob Storage, Azure Data Lake Store Gen 2 och SQL-pool enligt kodexemplen nedan.
Läsa en CSV från Azure Data Lake Store Gen2 som en Spark DataFrame
from pyspark.sql import SparkSession
from pyspark.sql.types import *
account_name = "Your account name"
container_name = "Your container name"
relative_path = "Your path"
adls_path = 'abfss://%s@%s.dfs.core.windows.net/%s' % (container_name, account_name, relative_path)
df1 = spark.read.option('header', 'true') \
.option('delimiter', ',') \
.csv(adls_path + '/Testfile.csv')
Läsa en CSV från Azure Blob Storage som en Spark DataFrame
from pyspark.sql import SparkSession
# Azure storage access info
blob_account_name = 'Your account name' # replace with your blob name
blob_container_name = 'Your container name' # replace with your container name
blob_relative_path = 'Your path' # replace with your relative folder path
linked_service_name = 'Your linked service name' # replace with your linked service name
blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
# Allow SPARK to access from Blob remotely
wasb_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path)
spark.conf.set('fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token)
print('Remote blob path: ' + wasb_path)
df = spark.read.option("header", "true") \
.option("delimiter","|") \
.schema(schema) \
.csv(wasbs_path)
Läsa data från det primära lagringskontot
Du kan komma åt data i det primära lagringskontot direkt. Du behöver inte ange de hemliga nycklarna. I Datautforskaren högerklickar du på en fil och väljer Ny anteckningsbok för att se en ny notebook-fil med automatisk extraktor för dataextraktor.
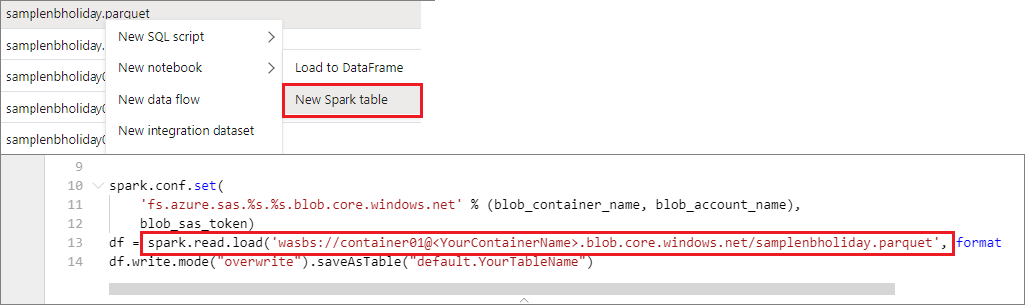
IPython Widgets
Widgetar är händelserika Python-objekt som har en representation i webbläsaren, ofta som en kontroll som ett skjutreglage, textruta osv. IPython Widgets fungerar bara i Python-miljön, det stöds inte på andra språk (till exempel Scala, SQL, C#) ännu.
Så här använder du IPython Widget
Du måste importera
ipywidgetsmodulen först för att använda Jupyter Widget-ramverket.import ipywidgets as widgetsDu kan använda funktionen på den översta nivån
displayför att återge en widget eller lämna ett uttryck av widgettyp på den sista raden i kodcellen.slider = widgets.IntSlider() display(slider)slider = widgets.IntSlider() sliderKör cellen, widgeten visas i utdataområdet.
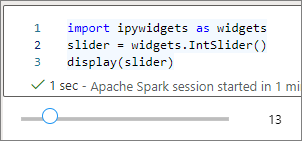
Du kan använda flera
display()anrop för att återge samma widgetinstans flera gånger, men de förblir synkroniserade med varandra.slider = widgets.IntSlider() display(slider) display(slider)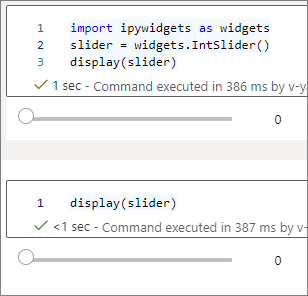
Om du vill återge två widgetar oberoende av varandra skapar du två widgetinstanser:
slider1 = widgets.IntSlider() slider2 = widgets.IntSlider() display(slider1) display(slider2)
Widgetar som stöds
| Typ av widgetar | Widgetar |
|---|---|
| Numeriska widgetar | IntSlider, FloatSlider, FloatLogSlider, IntRangeSlider, FloatRangeSlider, IntProgress, FloatProgress, BoundedIntText, BoundedFloatText, IntText, FloatText |
| Booleska widgetar | VäxlaKnapp, Kryssruta, Giltig |
| Markeringswidgetar | Listruta, RadioButtons, Select, SelectionSlider, SelectionRangeSlider, ToggleButtons, SelectMultiple |
| Strängwidgetar | Text, Textområde, Kombinationsruta, Lösenord, Etikett, HTML, HTML Math, Bild, Knapp |
| Spela upp (animering) widgetar | Datumväljare, Färgväljare, Styrenhet |
| Container-/layoutwidgetar | Box, HBox, VBox, GridBox, Accordion, Tabs, Stacked |
Kända begränsningar
Följande widgetar stöds inte än. Du kan följa motsvarande lösning enligt nedan:
Funktioner Lösning OutputWidgetDu kan använda print()funktionen i stället för att skriva text i stdout.widgets.jslink()Du kan använda widgets.link()funktionen för att länka två liknande widgetar.FileUploadWidgetInte stöd än. Den globala
displayfunktionen som tillhandahålls av Synapse stöder inte visning av flera widgetar i ett anrop (det vill sägadisplay(a, b)), vilket skiljer sig från IPython-funktionendisplay.Om du stänger en notebook-fil som innehåller IPython Widget kan du inte se eller interagera med den förrän du kör motsvarande cell igen.
Spara notebook-filer
Du kan spara en enskild notebook-fil eller alla notebook-filer på din arbetsyta.
Om du vill spara ändringar som du har gjort i en enskild notebook-fil väljer du knappen Publicera i kommandofältet för notebook-filen.

Om du vill spara alla anteckningsböcker på arbetsytan väljer du knappen Publicera alla i arbetsytans kommandofält.

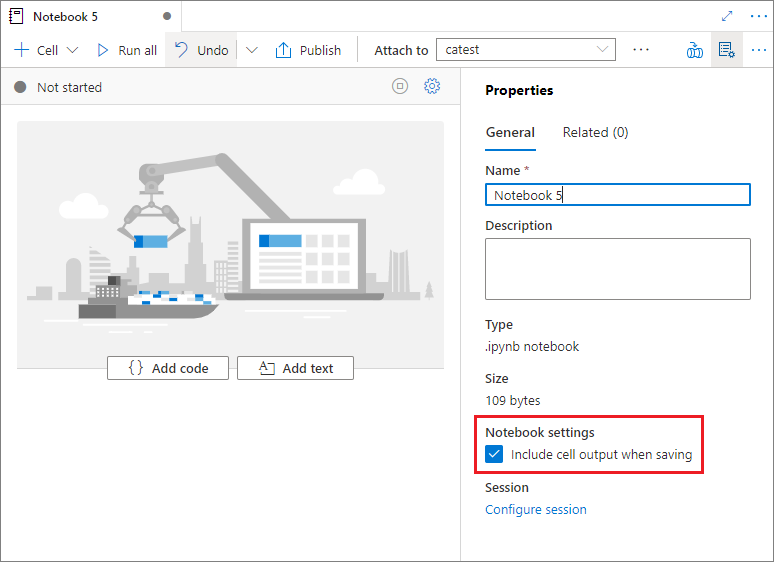
I notebook-egenskaperna kan du konfigurera om cellutdata ska inkluderas när du sparar.
Magiska kommandon
Du kan använda välbekanta Jupyter-magiska kommandon i Synapse-notebook-filer. Granska följande lista som de aktuella tillgängliga magiska kommandona. Berätta om dina användningsfall på GitHub så att vi kan fortsätta att bygga ut fler magiska kommandon för att uppfylla dina behov.
Kommentar
Endast följande magiska kommandon stöds i Synapse-pipelinen: %%pyspark, %%spark, %%csharp, %%sql.
Tillgängliga linjemagi: %lsmagic, %time, %timeit, %history, %run, %load
Tillgängliga cellmagi: %%time, %%timeit, %%capture, %%writefile, %%sql, %%pyspark, %%spark, %%csharp, %%html, %%configure
Referens för opublicerad notebook-fil
Referensavpublicerad notebook-fil är användbar när du vill felsöka "lokalt" när du aktiverar den här funktionen, notebook-körning hämtar det aktuella innehållet i webbcachen. Om du kör en cell inklusive en instruktion för referensanteckningsböcker refererar du till presentationsanteckningsböckerna i den aktuella notebook-webbläsaren i stället för sparade versioner i klustret, vilket innebär att ändringarna i notebook-redigeraren kan refereras direkt av andra notebook-filer utan att behöva publiceras (liveläge) eller checkas in( Git-läge) genom att använda den här metoden kan du enkelt undvika att vanliga bibliotek blir förorenade under utveckling eller felsökning.
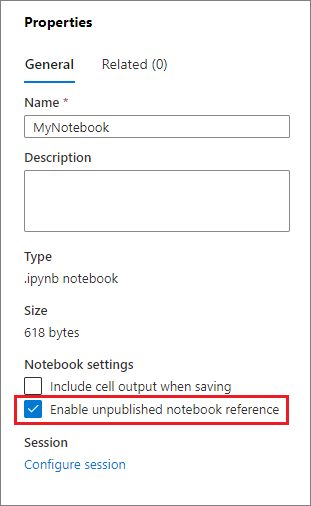
Du kan aktivera en avpublicerad referensanteckningsbok från panelen Egenskaper:
För jämförelse av olika fall, se tabellen nedan:
Observera att %run och mssparkutils.notebook.run har samma beteende här. Vi använder %run här som exempel.
| Skiftläge | Inaktivera | Aktivera |
|---|---|---|
| Liveläge | ||
- Nb1 (publicerad) %run Nb1 |
Kör publicerad version av Nb1 | Kör publicerad version av Nb1 |
- Nb1 (ny) %run Nb1 |
Fel | Kör ny Nb1 |
– Nb1 (tidigare publicerad, redigerad) %run Nb1 |
Kör publicerad version av Nb1 | Kör redigerad version av Nb1 |
| Git-läge | ||
- Nb1 (publicerad) %run Nb1 |
Kör publicerad version av Nb1 | Kör publicerad version av Nb1 |
- Nb1 (ny) %run Nb1 |
Fel | Kör ny Nb1 |
- Nb1 (inte publicerad, bekräftad) %run Nb1 |
Fel | Kör bekräftad Nb1 |
– Nb1 (tidigare publicerad, bekräftad) %run Nb1 |
Kör publicerad version av Nb1 | Kör den bekräftade versionen av Nb1 |
– Nb1 (tidigare publicerad, ny i aktuell gren) %run Nb1 |
Kör publicerad version av Nb1 | Kör ny Nb1 |
– Nb1 (Inte publicerad, tidigare bekräftad, redigerad) %run Nb1 |
Fel | Kör redigerad version av Nb1 |
– Nb1 (tidigare publicerad och bekräftad, redigerad) %run Nb1 |
Kör publicerad version av Nb1 | Kör redigerad version av Nb1 |
Slutsats
- Om du är inaktiverad kör du alltid publicerad version.
- Om den är aktiverad använder referenskörningen alltid den aktuella versionen av notebook-filen som du kan se från notebook-gränssnittet.
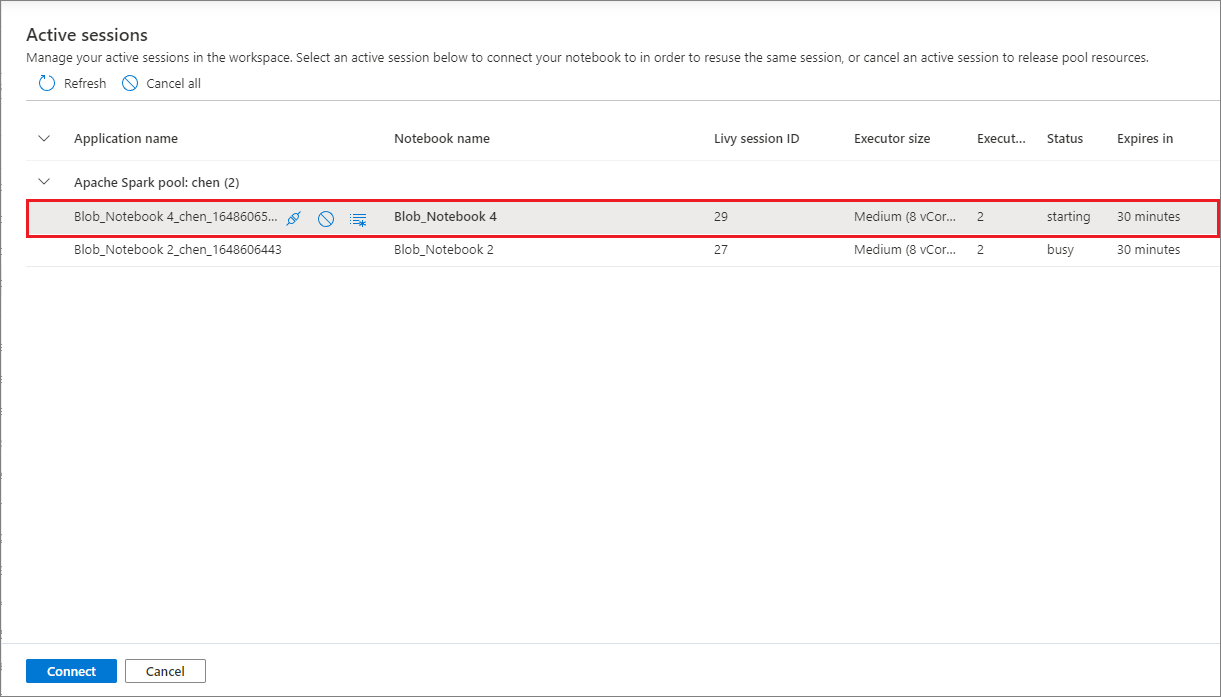
Aktiv sessionshantering
Du kan återanvända dina notebook-sessioner på ett bekvämt sätt nu utan att behöva starta nya. Synapse Notebook stöder nu hantering av aktiva sessioner i listan Hantera sessioner . Du kan se alla sessioner på den aktuella arbetsytan som du har startat från notebook-filen.
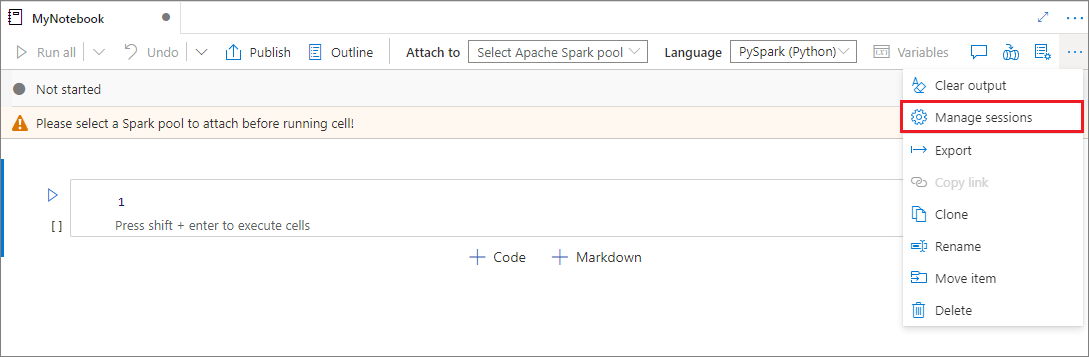
I listan Aktiva sessioner kan du se sessionsinformationen och motsvarande notebook-fil som för närvarande är kopplad till sessionen. Du kan använda Koppla från med notebook-fil, Stoppa sessionen och Visa i övervakning härifrån. Dessutom kan du enkelt ansluta den valda notebook-filen till en aktiv session i listan som startats från en annan anteckningsbok. Sessionen kopplas från den tidigare notebook-filen (om den inte är inaktiv) och ansluter sedan till den aktuella.
Python-loggning i Notebook
Du hittar Python-loggar och anger olika loggnivåer och format enligt exempelkoden nedan:
import logging
# Customize the logging format for all loggers
FORMAT = "%(asctime)s - %(name)s - %(levelname)s - %(message)s"
formatter = logging.Formatter(fmt=FORMAT)
for handler in logging.getLogger().handlers:
handler.setFormatter(formatter)
# Customize log level for all loggers
logging.getLogger().setLevel(logging.INFO)
# Customize the log level for a specific logger
customizedLogger = logging.getLogger('customized')
customizedLogger.setLevel(logging.WARNING)
# logger that use the default global log level
defaultLogger = logging.getLogger('default')
defaultLogger.debug("default debug message")
defaultLogger.info("default info message")
defaultLogger.warning("default warning message")
defaultLogger.error("default error message")
defaultLogger.critical("default critical message")
# logger that use the customized log level
customizedLogger.debug("customized debug message")
customizedLogger.info("customized info message")
customizedLogger.warning("customized warning message")
customizedLogger.error("customized error message")
customizedLogger.critical("customized critical message")
Visa historiken för indatakommandon
Synapse Notebook har stöd för magiskt kommando %history för att skriva ut indatakommandohistoriken som kördes i den aktuella sessionen, och jämföra med standardkommandot Jupyter Ipython som fungerar för kontexten %history för flera språk i notebook-filen.
%history [-n] [range [range ...]]
För alternativ:
- -n: Skriv ut körningsnummer.
Där intervallet kan vara:
- N: Skriv ut kod för Nth-körd cell.
- M-N: Skriv ut kod från cellen Mth till Nth .
Exempel:
- Skriv ut indatahistorik från 1:a till 2:a körd cell:
%history -n 1-2
Integrera en notebook-fil
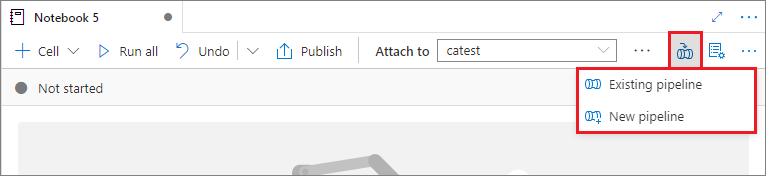
Lägga till en notebook-fil i en pipeline
Välj knappen Lägg till i pipeline i det övre högra hörnet för att lägga till en notebook-fil i en befintlig pipeline eller skapa en ny pipeline.
Ange en parametercell
Om du vill parametrisera anteckningsboken väljer du ellipserna (...) för att få åtkomst till fler kommandon i cellverktygsfältet . Välj sedan Växla parametercell för att ange cellen som parametercell.
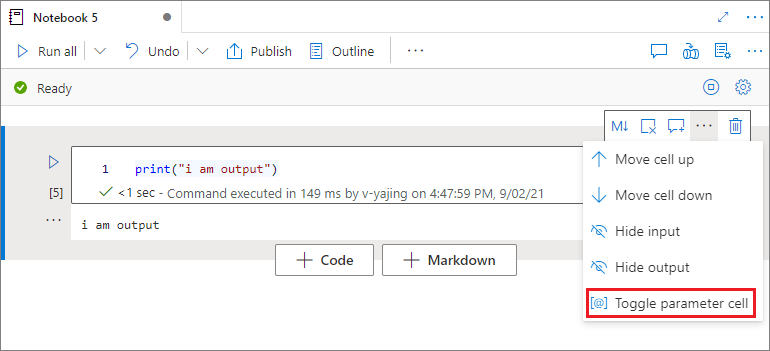
Azure Data Factory söker efter parametercellen och behandlar den här cellen som standardvärden för de parametrar som skickades in vid körningen. Körningsmotorn lägger till en ny cell under parametercellen med indataparametrar för att skriva över standardvärdena.
Tilldela parametrar värden från en pipeline
När du har skapat en notebook-fil med parametrar kan du köra den från en pipeline med aktiviteten Synapse Notebook. När du har lagt till aktiviteten i pipelinearbetsytan kan du ange parametrarnas värden under avsnittet Basparametrar på fliken Inställningar.
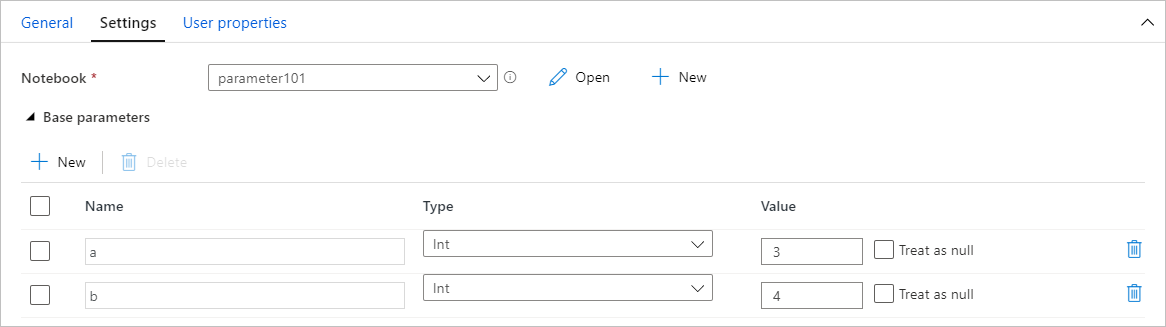
När du tilldelar parametervärden kan du använda pipelineuttrycksspråket eller systemvariablerna.
Kortkommandon
I likhet med Jupyter Notebooks har Synapse Notebooks ett modalt användargränssnitt. Tangentbordet gör olika saker beroende på vilket läge notebook-cellen befinner sig i. Synapse-notebook-filer stöder följande två lägen för en viss kodcell: kommandoläge och redigeringsläge.
En cell är i kommandoläge när det inte finns någon textmarkör som uppmanar dig att skriva. När en cell är i kommandoläge kan du redigera anteckningsboken som helhet men inte skriva in i enskilda celler. Ange kommandoläge genom att trycka
ESCeller använda musen för att välja utanför en cells redigeringsområde.
Redigeringsläget visas med en textmarkör som uppmanar dig att skriva i redigeringsområdet. När en cell är i redigeringsläge kan du skriva in i cellen. Ange redigeringsläge genom att trycka
Entereller använda musen för att välja i en cells redigeringsområde.
Kortkommandon i kommandoläge
| Åtgärd | Genvägar till Synapse-notebook-filer |
|---|---|
| Kör den aktuella cellen och välj nedan | Skift+Retur |
| Kör den aktuella cellen och infoga nedan | Alt+Retur |
| Kör aktuell cell | Ctrl+Return |
| Markera cellen ovan | Upp |
| Välj cell nedan | Ned |
| Markera föregående cell | k |
| Välj nästa cell | J |
| Infoga cell ovan | A |
| Infoga cell nedan | F |
| Ta bort markerade celler | Skift+D |
| Växla till redigeringsläge | Skriv in |
Kortkommandon under redigeringsläge
Med hjälp av följande genvägar för tangenttryckning kan du enklare navigera och köra kod i Synapse-notebook-filer när du är i redigeringsläge.
| Åtgärd | Genvägar till Synapse Notebook |
|---|---|
| Flytta markören uppåt | Upp |
| Flytta markören nedåt | Ned |
| Ångra | Ctrl + Z |
| Gör om | Ctrl + Y |
| Kommentar/avkommentering | Ctrl + / |
| Ta bort ord före | Ctrl + Backspace |
| Ta bort ord efter | Ctrl + Ta bort |
| Gå till cellstart | Ctrl + Start |
| Gå till celländen | Ctrl + Slut |
| Gå ett ord till vänster | Ctrl + vänster |
| Gå ett ord åt höger | Ctrl + höger |
| Välj alla | Ctrl + A |
| Strecksatsen | Ctrl +] |
| Dedent | Ctrl + [ |
| Växla till kommandoläge | Esc |
Nästa steg
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för