Intelligent cache i Azure Synapse Analytics
Intelligent Cache fungerar sömlöst i bakgrunden och cachelagrar data för att påskynda körningen av Spark när den läse från din ADLS Gen2-datasjö. Den identifierar också automatiskt ändringar i de underliggande filerna och uppdaterar automatiskt filerna i cacheminnet, vilket ger dig de senaste data och när cachestorleken når sin gräns släpper cachen automatiskt de minst lästa data för att skapa utrymme för nyare data. Den här funktionen sänker den totala ägandekostnaden genom att förbättra prestandan med upp till 65 % på efterföljande läsningar av filerna som lagras i den tillgängliga cachen för Parquet-filer och 50 % för CSV-filer.
När du kör frågor mot en fil eller tabell från datasjön anropar Apache Spark-motorn i Synapse den fjärranslutna ADLS Gen2-lagringen för att läsa de underliggande filerna. För varje frågebegäran om att läsa samma data måste Spark-motorn göra ett anrop till ADLS Gen2-fjärrlagring. Den här redundanta processen lägger till svarstid till din totala bearbetningstid. Spark tillhandahåller en cachelagringsfunktion som du måste ange manuellt cacheminnet och släppa cachen för att minimera svarstiden och förbättra övergripande prestanda. Detta kan dock leda till att resultatet har inaktuella data om underliggande data ändras.
Synapse Intelligent Cache förenklar den här processen genom att automatiskt cachelagra varje läsning i det allokerade cachelagringsutrymmet på varje Spark-nod. Varje begäran om en fil kontrollerar om filen finns i cacheminnet och jämför taggen från fjärrlagringen för att avgöra om filen är inaktuell. Om filen inte finns eller om filen är inaktuell läser Spark filen och lagrar den i cacheminnet. När cacheminnet blir fullt tas filen med den äldsta senaste åtkomsttiden bort från cacheminnet för att tillåta nyare filer.
Synapse-cachen är en enda cache per nod. Om du använder en nod med medelhög storlek och kör med två små körbara filer på en nod med en enda medelstor nod, skulle dessa två utförare dela samma cache.
Aktivera eller inaktivera cacheminnet
Cachestorleken kan justeras baserat på procentandelen av den totala diskstorleken som är tillgänglig för varje Apache Spark-pool. Som standard är cachen inställd på inaktiverad, men det är lika enkelt som att flytta skjutreglaget från 0 (inaktiverat) till önskad procentandel för din cachestorlek för att aktivera den. Vi reserverar minst 20 % av tillgängligt diskutrymme för datablandningar. För shuffle-intensiva arbetsbelastningar kan du minimera cachestorleken eller inaktivera cacheminnet. Vi rekommenderar att du börjar med en cachestorlek på 50 % och justerar efter behov. Observera att om din arbetsbelastning kräver mycket diskutrymme på den lokala SSD:en för shuffle- eller RDD-cachelagring bör du överväga att minska cachestorleken för att minska risken för fel på grund av otillräcklig lagring. Den faktiska storleken på den tillgängliga lagringen och cachestorleken på varje nod beror på nodfamiljen och nodstorleken.
Aktivera cachelagring för nya Spark-pooler
När du skapar en ny Spark-pool bläddrar du under fliken ytterligare inställningar för att hitta skjutreglaget Intelligent Cache som du kan flytta till önskad storlek för att aktivera funktionen.

Aktivera/inaktivera cacheminne för befintliga Spark-pooler
För befintliga Spark-pooler bläddrar du till skalningsinställningarna för den Apache Spark-pool som du vill aktivera genom att flytta skjutreglaget till ett värde som är mer än 0 eller inaktivera det genom att flytta skjutreglaget till 0.
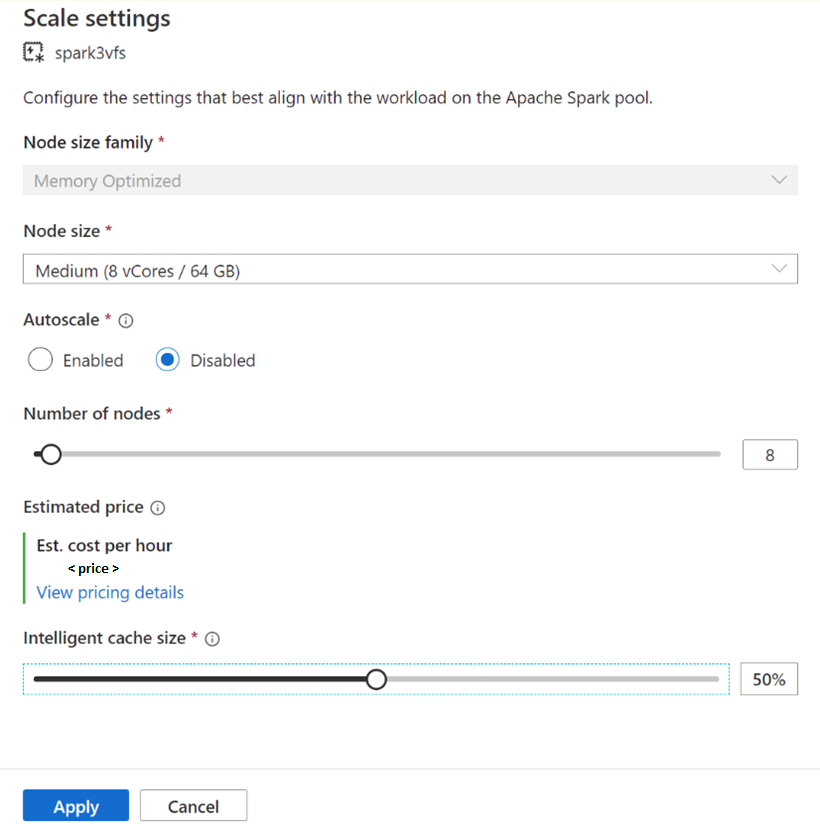
Ändra cachestorlek för befintliga Spark-pooler
Om du vill ändra storleken på Intelligent Cache för en pool måste du framtvinga en omstart om poolen har aktiva sessioner. Om Spark-poolen har en aktiv session visas Framtvinga nya inställningar. Klicka på kryssrutan och välj Använd för att starta om sessionen automatiskt.

Aktivera och inaktivera cachen i sessionen
Inaktivera enkelt Intelligent Cache i en session genom att köra följande kod i notebook-filen:
%spark
spark.conf.set("spark.synapse.vegas.useCache", "false")
%pyspark
spark.conf.set('spark.synapse.vegas.useCache', 'false')
Och aktivera genom att köra:
%spark
spark.conf.set("spark.synapse.vegas.useCache", "true")
%pyspark
spark.conf.set('spark.synapse.vegas.useCache', 'true')
När ska jag använda Intelligent Cache och när inte?
Den här funktionen kommer att gynna dig om:
Din arbetsbelastning kräver att du läser samma fil flera gånger och filstorleken får plats i cacheminnet.
Din arbetsbelastning använder Delta-tabeller, parquet-filformat och CSV-filer.
Du använder Apache Spark 3 eller senare i Azure Synapse.
Du ser inte fördelen med den här funktionen om:
Du läser en fil som överskrider cachestorleken eftersom början av filerna kan avlägsnas och efterföljande frågor måste hämta data från fjärrlagringen. I det här fallet ser du inga fördelar med Intelligent Cache och du kanske vill öka cachestorleken och/eller nodstorleken.
Din arbetsbelastning kräver stora mängder shuffle och om du inaktiverar Intelligent Cache frigörs ledigt utrymme för att förhindra att jobbet misslyckas på grund av otillräckligt lagringsutrymme.
Du använder en Spark 3.1-pool. Du måste uppgradera poolen till den senaste versionen av Spark.
Läs mer
Mer information om Apache Spark finns i följande artiklar:
- Vad är Apache Spark?
- Grundläggande begrepp för Apache Spark
- Azure Synapse Runtime för Apache Spark 3.2
- Storlekar och konfigurationer för Apache Spark-pooler
Mer information om hur du konfigurerar Spark-sessionsinställningar
- Konfigurera Inställningar för Spark-sessioner
- Så här ställer du in anpassade Konfigurationer för Spark/Pyspark
Nästa steg
En Apache Spark-pool har funktioner för stordatabearbetning med öppen källkod där data kan läsas in, modelleras, bearbetas och distribueras för snabbare analysinsikter. Mer information om hur du skapar en för att köra Dina Spark-arbetsbelastningar finns i följande självstudier:
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för