Felsök serverlösa SQL-pooler i Azure Synapse Analytics
Den här artikeln innehåller information om hur du felsöker de vanligaste problemen med en serverlös SQL-pool i Azure Synapse Analytics.
Mer information om Azure Synapse Analytics finns i Översikt och Nyheter i Azure Synapse Analytics?.
Synapse Studio
Synapse Studio är ett lättanvänt verktyg som du kan använda för att komma åt dina data med hjälp av en webbläsare utan att behöva installera verktyg för databasåtkomst. Synapse Studio är inte utformat för att läsa en stor uppsättning data eller fullständig hantering av SQL-objekt.
Serverlös SQL-pool är nedtonad i Synapse Studio
Om Synapse Studio inte kan upprätta en anslutning till en serverlös SQL-pool ser du att den serverlösa SQL-poolen är nedtonad eller visar statusen Offline.
Det här problemet uppstår vanligtvis av någon av två orsaker:
- Nätverket förhindrar kommunikation till Azure Synapse Analytics-serverdelen. Det vanligaste fallet är att TCP-port 1443 blockeras. Om du vill få en serverlös SQL-pool att fungera avblockera du den här porten. Andra problem kan också hindra serverlös SQL-pool från att fungera. Mer information finns i felsökningsguiden.
- Du har inte behörighet att logga in på en serverlös SQL-pool. För att få åtkomst måste en Azure Synapse-arbetsyteadministratör lägga till dig i rollen som arbetsyteadministratör eller SQL-administratör. Mer information finns i Åtkomstkontroll för Azure Synapse.
Websocket-anslutningen stängdes oväntat
Frågan kan misslyckas med felmeddelandet Websocket connection was closed unexpectedly. Det här meddelandet innebär att webbläsaranslutningen till Synapse Studio avbröts, till exempel på grund av ett nätverksproblem.
- Lös problemet genom att köra frågan igen.
- Prova Azure Data Studio eller SQL Server Management Studio för samma frågor i stället för Synapse Studio för ytterligare undersökning.
- Om det här meddelandet ofta inträffar i din miljö kan du få hjälp av nätverksadministratören. Du kan också kontrollera brandväggsinställningarna och kontrollera felsökningsguiden.
- Om problemet kvarstår skapar du en supportbegäran via Azure-portalen.
Serverlösa databaser visas inte i Synapse Studio
Om du inte ser de databaser som skapas i en serverlös SQL-pool kontrollerar du om din serverlösa SQL-pool har startats. Om serverlös SQL-pool inaktiveras visas inte databaserna. Kör en fråga, till exempel SELECT 1, på en serverlös SQL-pool för att aktivera den och få databaserna att visas.
Synapse Serverless SQL-pool visas som otillgänglig
Felaktig nätverkskonfiguration är ofta orsaken till det här beteendet. Kontrollera att portarna är korrekt konfigurerade. Om du använder en brandvägg eller privata slutpunkter kontrollerar du även de här inställningarna.
Kontrollera slutligen att lämpliga roller har beviljats och inte har återkallats.
Det går inte att skapa en ny databas eftersom begäran använder den gamla/utgångna nyckeln
Det här felet orsakas av ändring av kundhanterad nyckel för arbetsytor som används för kryptering. Du kan välja att kryptera om alla data på arbetsytan med den senaste versionen av den aktiva nyckeln. Om du vill kryptera om ändrar du nyckeln i Azure-portalen till en tillfällig nyckel och växlar sedan tillbaka till den nyckel som du vill använda för kryptering. Lär dig hur du hanterar arbetsytenycklarna här.
Synapse serverlös SQL-pool är inte tillgänglig efter överföring av en prenumeration till en annan Microsoft Entra-klientorganisation
Om du har flyttat en prenumeration till en annan Microsoft Entra-klientorganisation kan det uppstå problem med en serverlös SQL-pool. Skapa en supportbegäran så kontaktar Azure-supporten dig för att lösa problemet.
Lagringsåtkomst
Om du får fel när du försöker komma åt filer i Azure Storage kontrollerar du att du har behörighet att komma åt data. Du bör kunna komma åt offentligt tillgängliga filer. Om du försöker komma åt data utan autentiseringsuppgifter kontrollerar du att din Microsoft Entra-identitet kan komma åt filerna direkt.
Om du har en signaturnyckel för delad åtkomst som du bör använda för att komma åt filer kontrollerar du att du har skapat en autentiseringsuppgift på servernivå eller databasomfattning som innehåller autentiseringsuppgifterna. Autentiseringsuppgifterna krävs om du behöver komma åt data med hjälp av arbetsytans hanterade identitet och SPN (Custom Service Principal Name).
Det går inte att läsa, lista eller komma åt filer i Azure Data Lake Storage
Om du använder en Microsoft Entra-inloggning utan explicita autentiseringsuppgifter kontrollerar du att din Microsoft Entra-identitet kan komma åt filerna i lagringen. För att få åtkomst till filerna måste din Microsoft Entra-identitet ha behörigheten Blob Data Reader eller behörigheter till Lista och Läsa åtkomstkontrollistor (ACL) i ADLS. Mer information finns i Frågan misslyckas eftersom filen inte kan öppnas.
Om du får åtkomst till lagring med hjälp av autentiseringsuppgifter kontrollerar du att din hanterade identitet eller SPN har rollen Dataläsare eller Deltagare eller specifika ACL-behörigheter. Om du använde en signaturtoken för delad åtkomst kontrollerar du att den har rl behörighet och att den inte har upphört att gälla.
Om du använder en SQL-inloggning och OPENROWSET funktionen utan en datakälla kontrollerar du att du har en autentiseringsuppgift på servernivå som matchar lagrings-URI:n och har behörighet att komma åt lagringen.
Frågan misslyckas eftersom filen inte kan öppnas
Om frågan misslyckas med felet File cannot be opened because it does not exist or it is used by another process och du är säker på att båda filerna finns och inte används av en annan process, kan den serverlösa SQL-poolen inte komma åt filen. Det här problemet beror vanligtvis på att din Microsoft Entra-identitet inte har behörighet att komma åt filen eller på grund av att en brandvägg blockerar åtkomsten till filen.
Som standard försöker serverlös SQL-pool komma åt filen med hjälp av din Microsoft Entra-identitet. För att lösa det här problemet måste du ha rätt behörighet att komma åt filen. Det enklaste sättet är att ge dig själv rollen Storage Blob Data-deltagare för det lagringskonto som du försöker köra frågor mot.
Mer information finns i:
- Microsoft Entra ID-åtkomstkontroll för lagring
- Kontrollera åtkomsten till lagringskontot för serverlös SQL-pool i Synapse Analytics
Alternativ till rollen Storage Blob Data Contributor
I stället för att ge dig själv rollen Storage Blob Data Contributor kan du även ge mer detaljerade behörigheter för en delmängd filer.
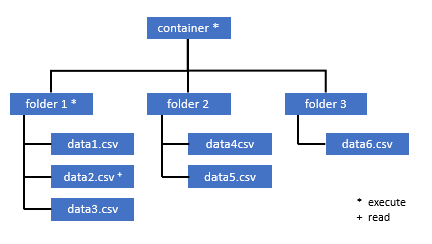
Alla användare som behöver åtkomst till vissa data i den här containern måste också ha behörigheten EXECUTE på alla överordnade mappar upp till roten (containern).
Läs mer om hur du ställer in ACL:er i Azure Data Lake Storage Gen2.
Kommentar
Kör behörighet på containernivå måste anges i Azure Data Lake Storage Gen2. Behörigheter för mappen kan anges i Azure Synapse.
Om du vill fråga data2.csv i det här exemplet krävs följande behörigheter:
- Kör behörighet för container
- Kör behörighet på mapp1
- Läsbehörighet för data2.csv
Logga in på Azure Synapse med en administratörsanvändare som har fullständig behörighet för de data som du vill komma åt.
Högerklicka på filen i datafönstret och välj Hantera åtkomst.
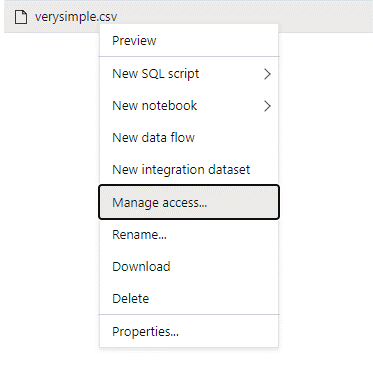
Välj minst Läsbehörighet . Ange användarens UPN eller objekt-ID, till exempel
user@contoso.com. Markera Lägga till.Bevilja läsbehörighet för den här användaren.

Kommentar
För gästanvändare måste det här steget göras direkt med Azure Data Lake eftersom det inte kan göras direkt via Azure Synapse.
Det går inte att visa innehållet i katalogen på sökvägen
Det här felet anger att den användare som kör frågor mot Azure Data Lake inte kan lista filerna i lagringen. Det finns flera scenarier där det här felet kan inträffa:
- Den Microsoft Entra-användare som använder Microsoft Entra-direktautentisering har inte behörighet att lista filerna i Data Lake Storage.
- Microsoft Entra-ID eller SQL-användare som läser data med hjälp av en signaturnyckel för delad åtkomst eller arbetsytans hanterade identitet och den nyckeln eller identiteten har inte behörighet att visa filerna i lagringen.
- Den användare som har åtkomst till Dataverse-data som inte har behörighet att köra frågor mot data i Dataverse. Det här scenariot kan inträffa om du använder SQL-användare.
- Användaren som har åtkomst till Delta Lake kanske inte har behörighet att läsa Delta Lake-transaktionsloggen.
Det enklaste sättet att lösa det här problemet är att ge dig själv rollen Storage Blob Data Contributor i lagringskontot som du försöker köra frågor mot.
Mer information finns i:
- Microsoft Entra ID-åtkomstkontroll för lagring
- Kontrollera åtkomsten till lagringskontot för serverlös SQL-pool i Synapse Analytics
Det går inte att visa innehållet i Dataverse-tabellen
Om du använder Azure Synapse Link for Dataverse för att läsa de länkade DataVerse-tabellerna måste du använda Microsoft Entra-kontot för att komma åt länkade data med hjälp av den serverlösa SQL-poolen. Mer information finns i Azure Synapse Link for Dataverse med Azure Data Lake.
Om du försöker använda en SQL-inloggning för att läsa en extern tabell som refererar till Tabellen DataVerse får du följande fel: External table '???' is not accessible because content of directory cannot be listed.
Externa Dataverse-tabeller använder alltid Microsoft Entra-genomströmningsautentisering. Du kan inte konfigurera dem att använda en signaturnyckel för delad åtkomst eller en hanterad identitet för arbetsytan.
Innehållet i Delta Lake-transaktionsloggen kan inte visas
Följande fel returneras när en serverlös SQL-pool inte kan läsa delta lake-transaktionsloggmappen:
Content of directory on path 'https://.....core.windows.net/.../_delta_log/*.json' cannot be listed.
Kontrollera att _delta_log mappen finns. Du kanske kör frågor mot vanliga Parquet-filer som inte konverteras till Delta Lake-format. Om mappen _delta_log finns kontrollerar du att du har både läs - och listbehörighet för de underliggande Delta Lake-mapparna. Försök att läsa json-filer direkt med hjälp FORMAT='csv'av . Placera din URI i BULK-parametern:
select top 10 *
from openrowset(BULK 'https://.....core.windows.net/.../_delta_log/*.json',FORMAT='csv', FIELDQUOTE = '0x0b', FIELDTERMINATOR ='0x0b',ROWTERMINATOR = '0x0b')
with (line varchar(max)) as logs
Om den här frågan misslyckas har anroparen inte behörighet att läsa de underliggande lagringsfilerna.
Frågekörning
Du kan få fel under frågekörningen i följande fall:
- Anroparen kan inte komma åt vissa objekt.
- Frågan kan inte komma åt externa data.
- Frågan innehåller vissa funktioner som inte stöds i serverlösa SQL-pooler.
Frågan misslyckas eftersom den inte kan köras på grund av aktuella resursbegränsningar
Frågan kan misslyckas med felmeddelandet This query cannot be executed due to current resource constraints. Det här meddelandet innebär att serverlös SQL-pool inte kan köras just nu. Här följer några felsökningsalternativ:
- Se till att du använder datatyper av rimlig storlek.
- Om frågan riktar sig mot Parquet-filer bör du överväga att definiera explicita typer för strängkolumner eftersom de är VARCHAR(8000) som standard. Kontrollera härledda datatyper.
- Om frågan riktar sig mot .CSV-filer bör du överväga att skapa statistik.
- Optimera frågan med hjälp av Prestandametodtips för serverlös SQL-pool.
Frågans tidsgräns har överskridits
Felet Query timeout expired returneras om frågan kördes mer än 30 minuter på en serverlös SQL-pool. Den här gränsen för serverlös SQL-pool kan inte ändras.
- Försök att optimera frågan genom att tillämpa metodtips.
- Försök att materialisera delar av dina frågor med hjälp av skapa extern tabell som välj (CETAS).
- Kontrollera om det finns en samtidig arbetsbelastning som körs på en serverlös SQL-pool eftersom de andra frågorna kan ta resurserna. I så fall kan du dela upp arbetsbelastningen på flera arbetsytor.
Ogiltigt objektnamn
Felet Invalid object name 'table name' anger att du använder ett objekt, till exempel en tabell eller vy, som inte finns i den serverlösa SQL-pooldatabasen. Prova följande alternativ:
Visa en lista över tabeller eller vyer och kontrollera om objektet finns. Använd SQL Server Management Studio eller Azure Data Studio eftersom Synapse Studio kan visa vissa tabeller som inte är tillgängliga i en serverlös SQL-pool.
Om du ser objektet kontrollerar du att du använder skiftlägeskänslig/binär databassortering. Objektnamnet kanske inte matchar det namn som du använde i frågan. Med en binär databassortering
Employeeochemployeeär två olika objekt.Om du inte ser objektet kanske du försöker köra frågor mot en tabell från en sjö eller Spark-databas. Tabellen kanske inte är tillgänglig i den serverlösa SQL-poolen eftersom:
- Tabellen har vissa kolumntyper som inte kan representeras i en serverlös SQL-pool.
- Tabellen har ett format som inte stöds i en serverlös SQL-pool. Exempel är Avro eller ORC.
Sträng- eller binärdata trunkeras
Det här felet inträffar om längden på strängen eller den binära kolumntypen (till exempel VARCHAR, VARBINARYeller NVARCHAR) är kortare än den faktiska storleken på data som du läser. Du kan åtgärda det här felet genom att öka längden på kolumntypen:
- Om strängkolumnen
VARCHAR(32)definieras som typen och texten är 60 tecken använder duVARCHAR(60)typen (eller längre) i kolumnschemat. - Om du använder schemainferensen
WITH(utan schemat) definieras alla strängkolumner automatiskt somVARCHAR(8000)typ. Om du får det här felet definierar du uttryckligen schemat i enWITHsats med den störreVARCHAR(MAX)kolumntypen för att lösa det här felet. - Om tabellen finns i Lake-databasen kan du försöka öka strängkolumnens storlek i Spark-poolen.
- Försök att
SET ANSI_WARNINGS OFFaktivera serverlös SQL-pool för att automatiskt trunkera VARCHAR-värdena, om detta inte påverkar dina funktioner.
Avmarkerat citattecken efter teckensträngen
I sällsynta fall, där du använder LIKE-operatorn i en strängkolumn eller en jämförelse med strängliteralerna, kan du få följande fel:
Unclosed quotation mark after the character string
Det här felet kan inträffa om du använder Latin1_General_100_BIN2_UTF8 sorteringen i kolumnen. Försök att ange Latin1_General_100_CI_AS_SC_UTF8 sortering i kolumnen i stället för Latin1_General_100_BIN2_UTF8 sorteringen för att lösa problemet. Om felet fortfarande returneras skapar du en supportbegäran via Azure-portalen.
Det gick inte att allokera tempdb-utrymme vid överföring av data från en distribution till en annan
Felet Could not allocate tempdb space while transferring data from one distribution to another returneras när frågekörningsmotorn inte kan bearbeta data och överföra dem mellan de noder som kör frågan. Det är ett specialfall för den allmänna frågan som misslyckas eftersom den inte kan köras på grund av aktuella resursbegränsningar . Det här felet returneras när resurserna som allokeras till tempdb databasen inte är tillräckliga för att köra frågan.
Använd metodtips innan du skapar ett supportärende.
Frågan misslyckas med ett fel vid hantering av en extern fil (maximalt antal fel har nåtts)
Om frågan misslyckas med felmeddelandet error handling external file: Max errors count reachedinnebär det att det finns ett matchningsfel av en angiven kolumntyp och de data som måste läsas in.
Om du vill ha mer information om felet och vilka rader och kolumner du ska titta på ändrar du parser-versionen från 2.0 till 1.0.
Exempel
Om du vill köra frågor mot filen names.csv med den här fråga 1 returnerar Azure Synapse serverlös SQL-pool med följande fel: Error handling external file: 'Max error count reached'. File/External table name: [filepath]. Till exempel:
Filen names.csv innehåller:
Id,first name,
1, Adam
2,Bob
3,Charles
4,David
5,Eva
Fråga 1:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Text] VARCHAR (1) COLLATE Latin1_General_BIN2
)
AS [result]
Orsak
Så snart parser-versionen har ändrats från version 2.0 till 1.0 hjälper felmeddelandena till att identifiera problemet. Det nya felmeddelandet är nu Bulk load data conversion error (truncation) for row 1, column 2 (Text) in data file [filepath].
Truncation anger att kolumntypen är för liten för att passa dina data. Det längsta förnamnet i den här names.csv filen har sju tecken. Den datatyp som ska användas ska vara minst VARCHAR(7). Felet orsakas av den här kodraden:
[Text] VARCHAR (1) COLLATE Latin1_General_BIN2
Om du ändrar frågan i enlighet med detta löser du felet. Efter felsökningen ändrar du parserversionen till 2.0 igen för att uppnå maximal prestanda.
Mer information om när du ska använda vilken parserversion finns i Använda OPENROWSET med serverlös SQL-pool i Synapse Analytics.
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Text] VARCHAR (7) COLLATE Latin1_General_BIN2
)
AS [result]
Det går inte att massinläsa eftersom filen inte kunde öppnas
Felet Cannot bulk load because the file could not be opened returneras om en fil ändras under frågekörningen. Vanligtvis kan du få ett fel som Cannot bulk load because the file {file path} could not be opened. Operating system error code 12. (The access code is invalid.)
De serverlösa SQL-poolerna kan inte läsa filer som ändras medan frågan körs. Frågan kan inte låsa filerna. Om du vet att ändringsåtgärden läggs till kan du försöka ange följande alternativ: {"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}.
Mer information finns i så här kör du frågor mot tilläggsfiler eller skapar tabeller på tilläggsfiler.
Frågan misslyckas med datakonverteringsfel
Frågan kan misslyckas med felmeddelandet Bulk load data conversion error (type mismatches or invalid character for the specified code page) for row n, column m [columnname] in the data file [filepath]. Det här meddelandet innebär att dina datatyper inte matchade faktiska data för radnummer n och kolumn m.
Om du till exempel bara förväntar dig heltal i dina data, men i rad n det finns en sträng, är det här felmeddelandet det du får.
Lös problemet genom att granska filen och de datatyper som du har valt. Kontrollera också om inställningarna för radavgränsare och fältavgränsare är korrekta. I följande exempel visas hur du kan inspektera genom att använda VARCHAR som kolumntyp.
Mer information om fältavgränsare, radavgränsare och escape-citattecken finns i Fråga CSV-filer.
Exempel
Om du vill köra frågor mot filen names.csv:
Id, first name,
1,Adam
2,Bob
3,Charles
4,David
five,Eva
Med följande fråga:
Fråga 1:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Azure Synapse-serverlös SQL-pool returnerar felet Bulk load data conversion error (type mismatch or invalid character for the specified code page) for row 6, column 1 (ID) in data file [filepath].
Det är nödvändigt att bläddra bland data och fatta ett välgrundat beslut för att hantera det här problemet. Om du vill titta på de data som orsakar det här problemet måste datatypen ändras först. I stället för att köra frågor mot ID-kolumnen med datatypen SMALLINT används NU VARCHAR(100) för att analysera det här problemet.
Med den här något ändrade fråga 2 kan data nu bearbetas för att returnera listan med namn.
Fråga 2:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Du kan observera att data har oväntade värden för ID på den femte raden. Under sådana omständigheter är det viktigt att anpassa sig till företagets ägare av data för att komma överens om hur skadade data som det här exemplet kan undvikas. Om skydd inte är möjligt på programnivå kan varchar i rimlig storlek vara det enda alternativet här.
Dricks
Försök att göra VARCHAR() så kort som möjligt. Undvik VARCHAR (MAX) om möjligt eftersom det kan försämra prestandan.
Frågeresultatet ser inte ut som förväntat
Din fråga kanske inte misslyckas, men du kanske ser att resultatuppsättningen inte är som förväntat. De resulterande kolumnerna kan vara tomma eller så kan oväntade data returneras. I det här scenariot är det troligt att en radavgränsare eller fältavgränsare har valts felaktigt.
Lös problemet genom att ta en ny titt på data och ändra inställningarna. Det är enkelt att felsöka den här frågan, som du ser i följande exempel.
Exempel
Om du vill köra frågor mot filen names.csv med frågan i Fråga 1 returnerar Azure Synapse serverlös SQL-pool med ett resultat som ser konstigt ut:
I names.csv:
Id,first name,
1, Adam
2, Bob
3, Charles
4, David
5, Eva
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
| ID | Firstname |
| ------------- |------------- |
| 1,Adam | NULL |
| 2,Bob | NULL |
| 3,Charles | NULL |
| 4,David | NULL |
| 5,Eva | NULL |
Det verkar inte finnas något värde i kolumnen Firstname. I stället hamnade alla värden i ID kolumnen. Dessa värden avgränsas med ett kommatecken. Problemet orsakades av den här kodraden eftersom det är nödvändigt att välja kommatecknet i stället för semikolonsymbolen som fältavgränsare:
FIELDTERMINATOR =';',
Om du ändrar det här enskilda tecknet löser du problemet:
FIELDTERMINATOR =',',
Resultatuppsättningen som skapas av fråga 2 ser nu ut som förväntat:
Fråga 2:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Returnerar:
| ID | Firstname |
| ------------- |------------- |
| 1 | Adam |
| 2 | Bob |
| 3 | Charles |
| 4 | David |
| 5 | Eva |
Kolumn av typen är inte kompatibel med extern datatyp
Om frågan misslyckas med felmeddelandet Column [column-name] of type [type-name] is not compatible with external data type […], är det troligt att en PARQUET-datatyp har mappats till en felaktig SQL-datatyp.
Om din Parquet-fil till exempel har ett kolumnpris med flyttalsnummer (till exempel 12,89) och du försökte mappa den till INT, är det här felmeddelandet det du får.
Lös problemet genom att granska filen och de datatyper som du har valt. Den här mappningstabellen hjälper dig att välja rätt SQL-datatyp. Som bästa praxis anger du endast mappning för kolumner som annars skulle matchas till VARCHAR-datatypen. Att undvika VARCHAR när det är möjligt leder till bättre prestanda i frågor.
Exempel
Om du vill köra frågor mot filen taxi-data.parquet med den här fråga 1 returnerar Azure Synapse serverlös SQL-pool följande fel:
Filen taxi-data.parquet innehåller:
|PassengerCount |SumTripDistance|AvgTripDistance |
|---------------|---------------|----------------|
| 1 | 2635668.66000064 | 6.72731710678951 |
| 2 | 172174.330000005 | 2.97915543404919 |
| 3 | 296384.390000011 | 2.8991352022851 |
| 4 | 12544348.58999806| 6.30581582240281 |
| 5 | 13091570.2799993 | 111.065989028627 |
Fråga 1:
SELECT
*
FROM
OPENROWSET(
BULK '<filepath>taxi-data.parquet',
FORMAT='PARQUET'
) WITh
(
PassengerCount INT,
SumTripDistance INT,
AVGTripDistance FLOAT
)
AS [result]
Column 'SumTripDistance' of type 'INT' is not compatible with external data type 'Parquet physical type: DOUBLE', please try with 'FLOAT'. File/External table name: '<filepath>taxi-data.parquet'.
Det här felmeddelandet anger att datatyper inte är kompatibla och levereras med förslaget att använda FLOAT i stället för INT. Felet orsakas av den här kodraden:
SumTripDistance INT,
Med den här något ändrade fråga 2 kan data nu bearbetas och visar alla tre kolumnerna:
Fråga 2:
SELECT
*
FROM
OPENROWSET(
BULK '<filepath>taxi-data.parquet',
FORMAT='PARQUET'
) WITh
(
PassengerCount INT,
SumTripDistance FLOAT,
AVGTripDistance FLOAT
)
AS [result]
Frågan refererar till ett objekt som inte stöds i distribuerat bearbetningsläge
Felet The query references an object that is not supported in distributed processing mode anger att du har använt ett objekt eller en funktion som inte kan användas när du frågar efter data i Azure Storage eller Azure Cosmos DB-analyslagringen.
Vissa objekt, till exempel systemvyer och funktioner, kan inte användas när du frågar efter data som lagras i Azure Data Lake eller Azure Cosmos DB-analyslagring. Undvik att använda frågor som kopplar externa data till systemvyer, läser in externa data i en temporär tabell eller använder vissa säkerhets- eller metadatafunktioner för att filtrera externa data.
WaitIOCompletion-anropet misslyckades
Felmeddelandet WaitIOCompletion call failed anger att frågan misslyckades i väntan på att slutföra I/O-åtgärden som läser data från fjärrlagringen, Azure Data Lake.
Felmeddelandet har följande mönster: Error handling external file: 'WaitIOCompletion call failed. HRESULT = ???'. File/External table name...
Kontrollera att lagringen är placerad i samma region som en serverlös SQL-pool. Kontrollera lagringsmåtten och kontrollera att det inte finns några andra arbetsbelastningar på lagringsskiktet, till exempel att ladda upp nya filer, som kan mätta I/O-begäranden.
Fältet HRESULT innehåller resultatkoden. Följande felkoder är de vanligaste tillsammans med deras potentiella lösningar.
Den här felkoden innebär att källfilen inte finns i lagringen.
Det finns orsaker till att den här felkoden kan inträffa:
- Filen har tagits bort av ett annat program.
- I det här vanliga scenariot startas frågekörningen, filerna räknas upp och filerna hittas. Senare, under frågekörningen, tas en fil bort. Den kan till exempel tas bort av Databricks, Spark eller Azure Data Factory. Frågan misslyckas eftersom filen inte hittas.
- Det här problemet kan också inträffa med Delta-formatet. Frågan kan lyckas vid återförsök eftersom det finns en ny version av tabellen och den borttagna filen inte efterfrågas igen.
- En ogiltig körningsplan cachelagras.
- Som en tillfällig lösning kör du kommandot
DBCC FREEPROCCACHE. Om problemet kvarstår skapar du en supportbegäran.
- Som en tillfällig lösning kör du kommandot
Felaktig syntax nära NOT
Felet Incorrect syntax near 'NOT' anger att det finns några externa tabeller med kolumner som innehåller VILLKORET INTE NULL i kolumndefinitionen.
- Uppdatera tabellen för att ta bort NOT NULL från kolumndefinitionen.
- Det här felet kan ibland också inträffa tillfälligt med tabeller som skapats från en CETAS-instruktion. Om problemet inte löser problemet kan du försöka släppa och återskapa den externa tabellen.
Partitionskolumnen returnerar NULL-värden
Om frågan returnerar NULL-värden i stället för att partitionera kolumner eller inte kan hitta partitionskolumnerna har du några möjliga felsökningssteg:
- Om du använder tabeller för att köra frågor mot en partitionerad datauppsättning bör du tänka på att tabeller inte stöder partitionering. Ersätt tabellen med de partitionerade vyerna.
- Om du använder partitionerade vyer med OPENROWSET som frågar partitionerade filer med hjälp av funktionen FILEPATH() kontrollerar du att du har angett jokerteckenmönstret på platsen korrekt och använt rätt index för att referera till jokertecknet.
- Om du kör frågor mot filerna direkt i den partitionerade mappen bör du tänka på att partitioneringskolumnerna inte är delar av filkolumnerna. Partitioneringsvärdena placeras i mappsökvägarna och inte i filerna. Därför innehåller filerna inte partitioneringsvärdena.
Det gick inte att infoga värdet i batchen för kolumntypen DATETIME2
Felet Inserting value to batch for column type DATETIME2 failed anger att den serverlösa poolen inte kan läsa datumvärdena från de underliggande filerna. Datetime-värdet som lagras i Parquet- eller Delta Lake-filen kan inte representeras som en DATETIME2 kolumn.
Kontrollera det minsta värdet i filen med hjälp av Spark och kontrollera att vissa datum är mindre än 0001-01-03. Om du lagrade filerna med hjälp av Spark 2.4-versionen (körningsversionen som inte stöds) eller med den högre Spark-versionen som fortfarande använder äldre datetime-lagringsformat skrivs datetime-värdena före med hjälp av den julianska kalendern som inte är anpassad till den proleptiska gregorianska kalendern som används i serverlösa SQL-pooler.
Det kan finnas en tvådagarsskillnad mellan den julianska kalendern som används för att skriva värdena i Parquet (i vissa Spark-versioner) och den proleptiska gregorianska kalendern som används i en serverlös SQL-pool. Den här skillnaden kan orsaka konvertering till ett negativt datumvärde, vilket är ogiltigt.
Försök att använda Spark för att uppdatera dessa värden eftersom de behandlas som ogiltiga datumvärden i SQL. Följande exempel visar hur du uppdaterar värden som är inaktuella för SQL-datumintervall till NULL i Delta Lake:
from delta.tables import *
from pyspark.sql.functions import *
deltaTable = DeltaTable.forPath(spark,
"abfss://my-container@myaccount.dfs.core.windows.net/delta-lake-data-set")
deltaTable.update(col("MyDateTimeColumn") < '0001-02-02', { "MyDateTimeColumn": null } )
Den här ändringen tar bort de värden som inte kan representeras. De andra datumvärdena kan vara korrekt inlästa men felaktigt representerade eftersom det fortfarande finns en skillnad mellan julianska och proleptiska gregorianska kalendrar. Du kan se oväntade datumförskjutningar även för datumen innan 1900-01-01 om du använder Spark 3.0 eller äldre versioner.
Överväg att migrera till Spark 3.1 eller senare och växla till den proleptiska gregorianska kalendern. De senaste Spark-versionerna använder som standard en proleptisk gregoriansk kalender som är anpassad till kalendern i en serverlös SQL-pool. Läs in dina äldre data igen med den högre versionen av Spark och använd följande inställning för att korrigera datumen:
spark.conf.set("spark.sql.legacy.parquet.int96RebaseModeInWrite", "CORRECTED")
Frågan misslyckades på grund av en topologiändring eller ett fel i beräkningscontainern
Det här felet kan tyda på att ett internt processproblem inträffade i en serverlös SQL-pool. Skicka in en supportbegäran med all nödvändig information som kan hjälpa Azure-supportteamet att undersöka problemet.
Beskriv allt som kan vara ovanligt jämfört med den vanliga arbetsbelastningen. Till exempel kanske ett stort antal samtidiga begäranden eller en särskild arbetsbelastning eller fråga började köras innan det här felet inträffade.
Tidsgränsen för jokerteckenexpansionen överst
Enligt beskrivningen i avsnittet Frågemappar och flera filer stöder serverlös SQL-pool läsning av flera filer/mappar med hjälp av jokertecken. Det finns en maxgräns på 10 jokertecken per fråga. Du måste vara medveten om att den här funktionen kostar något. Det tar tid för den serverlösa poolen att lista alla filer som kan matcha jokertecknet. Detta introducerar svarstid och den här svarstiden kan öka om antalet filer som du försöker köra frågor mot är högt. I det här fallet kan du stöta på följande fel:
"Wildcard expansion timed out after X seconds."
Det finns flera åtgärdssteg som du kan göra för att undvika detta:
- Tillämpa metodtips som beskrivs i Metodtips Serverlös SQL-pool.
- Försök att minska antalet filer som du försöker köra frågor mot genom att komprimera filer till större filer. Försök att hålla filstorlekarna över 100 MB.
- Kontrollera att filter över partitioneringskolumner används där det är möjligt.
- Om du använder deltafilformat använder du funktionen optimera skrivning i Spark. Detta kan förbättra prestandan för frågor genom att minska mängden data som behöver läsas och bearbetas. Hur du använder optimerad skrivning beskrivs i Använda optimerad skrivning på Apache Spark.
- Om du vill undvika några av jokertecken på den översta nivån genom att effektivt hårdkoda implicita filter över partitioneringskolumner använder du dynamisk SQL.
Kolumnen saknas vid användning av automatisk schemainferens
Du kan enkelt köra frågor mot filer utan att känna till eller ange schema genom att utelämna WITH-satsen. I så fall härleds kolumnnamn och datatyper från filerna. Tänk på att om du läser antalet filer samtidigt, kommer schemat att härledas från den första filtjänsten som hämtas från lagringen. Detta kan innebära att vissa av de förväntade kolumnerna utelämnas, allt eftersom filen som används av tjänsten för att definiera schemat inte innehöll dessa kolumner. Om du uttryckligen vill ange schemat använder du OPENROWSET WITH-satsen. Om du anger schema (med hjälp av extern tabell eller OPENROWSET WITH-sats) används standardläget för slapp sökväg. Det innebär att kolumnerna som inte finns i vissa filer returneras som NULLs (för rader från dessa filer). Information om hur sökvägsläget används finns i följande dokumentation och exempel.
Konfiguration
Med serverlösa SQL-pooler kan du använda T-SQL för att konfigurera databasobjekt. Det finns några begränsningar:
- Du kan inte skapa objekt i
masterochlakehouseeller Spark-databaser. - Du måste ha en huvudnyckel för att skapa autentiseringsuppgifter.
- Du måste ha behörighet att referera till data som används i objekten.
Det går inte att skapa en databas
Om du får felet CREATE DATABASE failed. User database limit has been already reached.har du skapat det maximala antalet databaser som stöds på en arbetsyta. Mer information finns i Begränsningar.
- Om du behöver separera objekten använder du scheman i databaserna.
- Om du behöver referera till Azure Data Lake Storage skapar du lakehouse-databaser eller Spark-databaser som ska synkroniseras i en serverlös SQL-pool.
Det gick inte att skapa eller ändra tabellen eftersom den minsta radstorleken överskrider den maximala tillåtna tabellradsstorleken på 8 060 byte
Alla tabeller kan ha upp till 8 KB storlek per rad (inklusive VARCHAR(MAX)/VARBINARY(MAX) utanför rad. Om du skapar en tabell där den totala storleken på celler i raden överskrider 8 060 byte får du följande fel:
Msg 1701, Level 16, State 1, Line 3
Creating or altering table '<table name>' failed because the minimum row size would be <???>,
including <???> bytes of internal overhead.
This exceeds the maximum allowable table row size of 8060 bytes.
Det här felet kan också inträffa i Lake-databasen om du skapar en Spark-tabell med kolumnstorlekar som överstiger 8 060 byte och den serverlösa SQL-poolen inte kan skapa en tabell som refererar till Spark-tabelldata.
Undvik att använda de fasta storlekstyperna som CHAR(N) och ersätt dem med variabelstorlekstyper VARCHAR(N) , eller minska storleken i CHAR(N). Se gruppbegränsningar på 8 000 rader i SQL Server.
Skapa en huvudnyckel i databasen eller öppna huvudnyckeln i sessionen innan du utför den här åtgärden
Om frågan misslyckas med felmeddelandet Please create a master key in the database or open the master key in the session before performing this operation.innebär det att din användardatabas för närvarande inte har någon åtkomst till en huvudnyckel.
Troligtvis har du skapat en ny användardatabas och inte skapat någon huvudnyckel ännu.
Lös problemet genom att skapa en huvudnyckel med följande fråga:
CREATE MASTER KEY [ ENCRYPTION BY PASSWORD ='strongpasswordhere' ];
Kommentar
Ersätt 'strongpasswordhere' med en annan hemlighet här.
CREATE-instruktionen stöds inte i huvuddatabasen
Om frågan misslyckas med felmeddelandet Failed to execute query. Error: CREATE EXTERNAL TABLE/DATA SOURCE/DATABASE SCOPED CREDENTIAL/FILE FORMAT is not supported in master database.innebär det att databasen i en master serverlös SQL-pool inte stöder skapandet av:
- Externa tabeller.
- Externa datakällor.
- Databasomfångsbegränsade autentiseringsuppgifter.
- Externa filformat.
Här är lösningen:
Skapa en användardatabas:
CREATE DATABASE <DATABASE_NAME>Kör en CREATE-instruktion i kontexten <för DATABASE_NAME>, som misslyckades tidigare för
masterdatabasen.Här är ett exempel på hur du skapar ett externt filformat:
USE <DATABASE_NAME> CREATE EXTERNAL FILE FORMAT [SynapseParquetFormat] WITH ( FORMAT_TYPE = PARQUET)
Det går inte att skapa Microsoft Entra-inloggning eller användare
Om du får ett fel när du försöker skapa en ny Microsoft Entra-inloggning eller användare i en databas kontrollerar du inloggningen som du använde för att ansluta till databasen. Inloggningen som försöker skapa en ny Microsoft Entra-användare måste ha behörighet att komma åt Microsoft Entra-domänen och kontrollera om användaren finns. Tänk på att:
- SQL-inloggningar har inte den här behörigheten, så du får alltid det här felet om du använder SQL-autentisering.
- Om du använder en Microsoft Entra-inloggning för att skapa nya inloggningar kontrollerar du om du har behörighet att komma åt Microsoft Entra-domänen.
Azure Cosmos DB
Med serverlösa SQL-pooler kan du köra frågor mot Azure Cosmos DB-analyslagring med hjälp OPENROWSET av funktionen. Kontrollera att azure Cosmos DB-containern har analytisk lagring. Kontrollera att du har angett kontot, databasen och containernamnet korrekt. Kontrollera också att din Azure Cosmos DB-kontonyckel är giltig. Mer information finns i Förutsättningar.
Det går inte att fråga Azure Cosmos DB med hjälp av funktionen OPENROWSET
Om du inte kan ansluta till ditt Azure Cosmos DB-konto kan du titta på förutsättningarna. Möjliga fel och felsökningsåtgärder visas i följande tabell.
| Fel | Rotorsak |
|---|---|
| Syntaxfel: – Felaktig syntax nära OPENROWSET.- ... är inte ett känt BULK OPENROWSET provideralternativ.– Felaktig syntax nära .... |
Möjliga rotorsaker: – Använder inte Azure Cosmos DB som den första parametern. – Använda en strängliteral i stället för en identifierare i den tredje parametern. – Anger inte den tredje parametern (containernamn). |
| Ett fel uppstod i Azure Cosmos DB-niska veze. | – Kontot, databasen eller nyckeln har inte angetts. – Ett alternativ i en niska veze känns inte igen. - Ett semikolon ( ;) placeras i slutet av en niska veze. |
| Det gick inte att lösa Azure Cosmos DB-sökvägen med felet "Felaktigt kontonamn" eller "Felaktigt databasnamn". | Det angivna kontonamnet, databasnamnet eller containern kan inte hittas, eller så har analyslagring inte aktiverats för den angivna samlingen. |
| Det gick inte att lösa Azure Cosmos DB-sökvägen med felet "Felaktigt hemligt värde" eller "Hemligheten är null eller tom". | Kontonyckeln är inte giltig eller saknas. |
UTF-8-sorteringsvarning returneras vid läsning av Azure Cosmos DB-strängtyper
Serverlös SQL-pool returnerar en kompileringstidsvarning om OPENROWSET kolumnsortering inte har UTF-8-kodning. Du kan enkelt ändra standardsortering för alla OPENROWSET funktioner som körs i den aktuella databasen med hjälp av T-SQL-instruktionen:
ALTER DATABASE CURRENT COLLATE Latin1_General_100_CI_AS_SC_UTF8;
Latin1_General_100_BIN2_UTF8-sortering ger bästa möjliga prestanda när du filtrerar dina data med hjälp av strängpredikat.
Rader som saknas i Azure Cosmos DB-analysarkivet
Vissa objekt från Azure Cosmos DB kanske inte returneras av OPENROWSET funktionen. Tänk på att:
- Det finns en synkroniseringsfördröjning mellan transaktions- och analysarkivet. Dokumentet som du angav i Azure Cosmos DB-transaktionsarkivet kan visas i analysarkivet efter två till tre minuter.
- Dokumentet kan bryta mot vissa schemabegränsningar.
Frågan returnerar NULL-värden i vissa Azure Cosmos DB-objekt
Azure Synapse SQL returnerar NULL i stället för de värden som visas i transaktionsarkivet i följande fall:
- Det finns en synkroniseringsfördröjning mellan transaktions- och analysarkivet. Värdet som du angav i Azure Cosmos DB-transaktionsarkivet kan visas i analysarkivet efter två till tre minuter.
- Det kan finnas fel kolumnnamn eller sökvägsuttryck i WITH-satsen. Kolumnnamnet (eller sökvägsuttrycket efter kolumntypen) i WITH-satsen måste matcha egenskapsnamnen i Azure Cosmos DB-samlingen. Jämförelse är skiftlägeskänsligt. Till exempel
productCodeochProductCodeär olika egenskaper. Kontrollera att kolumnnamnen exakt matchar azure Cosmos DB-egenskapsnamnen. - Egenskapen kanske inte flyttas till analyslagringen eftersom den bryter mot vissa schemabegränsningar, till exempel fler än 1 000 egenskaper eller fler än 127 kapslingsnivåer.
- Om du använder en väldefinierad schemarepresentation kan värdet i transaktionsarkivet ha en fel typ. Väldefinierat schema låser typerna för varje egenskap genom att ta del av dokumenten. Alla mervärden i transaktionsarkivet som inte matchar typen behandlas som ett felaktigt värde och migreras inte till analysarkivet.
- Om du använder schemarepresentation med fullständig återgivning kontrollerar du att du lägger till typsuffixet efter egenskapsnamnet som
$.price.int64. Om du inte ser något värde för den refererade sökvägen kanske den lagras under en annan typsökväg, till exempel$.price.float64. Mer information finns i Fråga Azure Cosmos DB-samlingar i schemat för fullständig återgivning.
Kolumnen är inte kompatibel med extern datatyp
Felet Column 'column name' of the type 'type name' is not compatible with the external data type 'type name'. returneras om den angivna kolumntypen i WITH-satsen inte matchar typen i Azure Cosmos DB-containern. Försök att ändra kolumntypen enligt beskrivningen i avsnittet Azure Cosmos DB till SQL-typmappningar eller använd VARCHAR-typen.
Lös: Azure Cosmos DB-sökvägen misslyckades med fel
Om du får felkontrollen Resolving Azure Cosmos DB path has failed with error 'This request is not authorized to perform this operation'. för att se om du använde privata slutpunkter i Azure Cosmos DB. Om du vill tillåta serverlös SQL-pool att komma åt ett analysarkiv med privata slutpunkter måste du konfigurera privata slutpunkter för Azure Cosmos DB-analysarkivet.
Prestandaproblem i Azure Cosmos DB
Om du får några oväntade prestandaproblem kontrollerar du att du har tillämpat metodtips, till exempel:
- Kontrollera att du har placerat klientprogrammet, den serverlösa poolen och Azure Cosmos DB-analyslagringen i samma region.
- Se till att du använder WITH-satsen med optimala datatyper.
- Kontrollera att du använder Latin1_General_100_BIN2_UTF8 sortering när du filtrerar dina data med hjälp av strängpredikat.
- Om du har upprepade frågor som kan cachelagras kan du försöka använda CETAS för att lagra frågeresultat i Azure Data Lake Storage.
Data Lake
Det finns vissa begränsningar som du kan se i Delta Lake-stöd i serverlösa SQL-pooler:
- Kontrollera att du refererar till rotmappen Delta Lake i funktionen OPENROWSET eller den externa tabellplatsen.
- Rotmappen måste ha en undermapp med namnet
_delta_log. Frågan misslyckas om det inte finns någon_delta_logmapp. Om du inte ser den mappen refererar du till vanliga Parquet-filer som måste konverteras till Delta Lake med hjälp av Apache Spark-pooler. - Ange inte jokertecken för att beskriva partitionsschemat. Delta Lake-frågan identifierar automatiskt Delta Lake-partitionerna.
- Rotmappen måste ha en undermapp med namnet
- Delta Lake-tabeller som skapas i Apache Spark-poolerna är automatiskt tillgängliga i en serverlös SQL-pool, men schemat uppdateras inte (begränsning för offentlig förhandsversion). Om du lägger till kolumner i Delta-tabellen med hjälp av en Spark-pool visas inte ändringarna i en serverlös SQL-pooldatabas.
- Externa tabeller stöder inte partitionering. Använd partitionerade vyer i Delta Lake-mappen för att använda partitionseliminering. Se kända problem och lösningar senare i artikeln.
- Serverlösa SQL-pooler stöder inte frågor om tidsresor. Använd Apache Spark-pooler i Synapse Analytics för att läsa historiska data.
- Serverlösa SQL-pooler stöder inte uppdatering av Delta Lake-filer. Du kan använda en serverlös SQL-pool för att köra frågor mot den senaste versionen av Delta Lake. Använd Apache Spark-pooler i Synapse Analytics för att uppdatera Delta Lake.
- Du kan inte lagra frågeresultat till lagring i Delta Lake-format med hjälp av CETAS-kommandot. CETAS-kommandot stöder endast Parquet och CSV som utdataformat.
- Serverlösa SQL-pooler i Synapse Analytics är kompatibla med Delta-läsare version 1.
- Serverlösa SQL-pooler i Synapse Analytics stöder inte datauppsättningarna med BLOOM-filtret. Den serverlösa SQL-poolen ignorerar BLOOM-filtren.
- Delta Lake-stöd är inte tillgängligt i dedikerade SQL-pooler. Kontrollera att du använder serverlösa SQL-pooler för att köra frågor mot Delta Lake-filer.
- Mer information om kända problem med serverlösa SQL-pooler finns i Kända problem med Azure Synapse Analytics.
Serverlöst stöd för Delta 1.0-version
Serverlösa SQL-pooler läser endast Delta Lake 1.0-versionen. Serverlösa SQL-pooler är en Delta-läsare med nivå 1 och stöder inte följande funktioner:
- Kolumnmappningar ignoreras – serverlösa SQL-pooler returnerar ursprungliga kolumnnamn.
- Borttagningsvektorer ignoreras och den gamla versionen av borttagna/uppdaterade rader returneras (eventuellt fel resultat).
- Följande Delta Lake-funktioner stöds inte: V2-kontrollpunkter, tidsstämpel utan tidszon, VACUUM-protokollkontroll
Borttagningsvektorer ignoreras
Om delta lake-tabellen har konfigurerats för att använda Delta writer version 7 kommer den att lagra borttagna rader och gamla versioner av uppdaterade rader i Ta bort vektorer (DV). Eftersom serverlösa SQL-pooler har Delta-läsare 1-nivå ignorerar de borttagningsvektorerna och ger förmodligen fel resultat när de läser Delta Lake-versionen som inte stöds.
Kolumnbyte i Delta-tabellen stöds inte
Den serverlösa SQL-poolen stöder inte frågor mot Delta Lake-tabeller med de omdöpta kolumnerna. Serverlös SQL-pool kan inte läsa data från den omdöpta kolumnen.
Värdet för en kolumn i deltatabellen är NULL
Om du använder Delta-datauppsättning som kräver en Delta-läsare version 2 eller senare och använder de funktioner som inte stöds i version 1 (till exempel byta namn på kolumner, släppa kolumner eller kolumnmappning), kanske värdena i de refererade kolumnerna inte visas.
JSON-text är inte korrekt formaterad
Det här felet anger att en serverlös SQL-pool inte kan läsa Delta Lake-transaktionsloggen. Du ser förmodligen följande fel:
Msg 13609, Level 16, State 4, Line 1
JSON text is not properly formatted. Unexpected character '' is found at position 263934.
Msg 16513, Level 16, State 0, Line 1
Error reading external metadata.
Kontrollera att din Delta Lake-datauppsättning inte är skadad. Kontrollera att du kan läsa innehållet i Delta Lake-mappen med hjälp av Apache Spark-poolen i Azure Synapse. På så sätt ser du till att _delta_log filen inte är skadad.
Lösning
Försök att skapa en kontrollpunkt i Delta Lake-datamängden med hjälp av Apache Spark-poolen och kör frågan igen. Kontrollpunkten aggregerar transaktionella JSON-loggfiler och kan lösa problemet.
Om datauppsättningen är giltig skapar du ett supportärende och ger mer information:
- Gör inga ändringar som att lägga till eller ta bort kolumnerna eller optimera tabellen eftersom den här åtgärden kan ändra tillståndet för Delta Lake-transaktionsloggfilerna.
- Kopiera innehållet i
_delta_logmappen till en ny tom mapp. Kopiera.parquet datainte filerna. - Försök att läsa innehållet som du kopierade i den nya mappen och kontrollera att du får samma fel.
- Skicka innehållet i den kopierade
_delta_logfilen till Azure-supporten.
Nu kan du fortsätta använda Delta Lake-mappen med Spark-poolen. Du kommer att tillhandahålla kopierade data till Microsoft-supporten om du får dela den här informationen. Azure-teamet undersöker innehållet i delta_log filen och ger mer information om möjliga fel och lösningar.
Det gick inte att lösa Delta-loggar
Följande fel anger att serverlös SQL-pool inte kan matcha Delta-loggar: Resolving Delta logs on path '%ls' failed with error: Cannot parse json object from log folder. Den vanligaste orsaken är att last_checkpoint_file i _delta_log mappen är större än 200 byte på grund av fältet checkpointSchema som lagts till i Spark 3.3.
Det finns två alternativ för att kringgå det här felet:
- Ändra lämplig konfiguration i Spark Notebook och generera en ny kontrollpunkt så att
last_checkpoint_fileden skapas på nytt. Om du använder Azure Databricks är konfigurationsändringen följande:spark.conf.set("spark.databricks.delta.checkpointSchema.writeThresholdLength", 0); - Nedgradera till Spark 3.2.1.
Vårt utvecklingsteam arbetar för närvarande med fullt stöd för Spark 3.3.
Deltatabellen som skapats i Spark visas inte i en serverlös pool
Kommentar
Replikering av Delta-tabeller som skapas i Spark är fortfarande i offentlig förhandsversion.
Om du har skapat en Delta-tabell i Spark och den inte visas i den serverlösa SQL-poolen kontrollerar du följande:
- Vänta en stund (vanligtvis 30 sekunder) eftersom Spark-tabellerna synkroniseras med fördröjning.
- Om tabellen inte visas i den serverlösa SQL-poolen efter en tid kontrollerar du schemat för Spark Delta-tabellen. Spark-tabeller med komplexa typer eller typer som inte stöds i serverlösa är inte tillgängliga. Försök att skapa en Spark Parquet-tabell med samma schema i en sjödatabas och kontrollera om tabellen visas i den serverlösa SQL-poolen.
- Kontrollera arbetsytans hanterade identitetsåtkomst till Delta Lake-mappen som refereras av tabellen. Serverlös SQL-pool använder arbetsytans hanterade identitet för att hämta tabellkolumninformationen från lagringen för att skapa tabellen.
Lake-databas
De Lake-databastabeller som skapas med Spark eller Synapse Designer är automatiskt tillgängliga i en serverlös SQL-pool för frågor. Du kan använda en serverlös SQL-pool för att köra frågor mot tabellerna Parquet, CSV och Delta Lake som skapas med Spark-poolen och lägga till ytterligare scheman, vyer, procedurer, tabellvärdesfunktioner och Microsoft Entra-användare i rollen i db_datareader din Lake-databas. Möjliga problem visas i det här avsnittet.
En tabell som skapats i Spark är inte tillgänglig i en serverlös pool
Tabeller som skapas kanske inte är omedelbart tillgängliga i en serverlös SQL-pool.
- Tabellerna kommer att vara tillgängliga i serverlösa pooler med viss fördröjning. Du kan behöva vänta 5–10 minuter efter att du har skapat en tabell i Spark för att se den i en serverlös SQL-pool.
- Endast de tabeller som refererar till Parquet-, CSV- och Delta-format är tillgängliga i en serverlös SQL-pool. Andra tabelltyper är inte tillgängliga.
- En tabell som innehåller vissa kolumntyper som inte stöds kommer inte att vara tillgänglig i en serverlös SQL-pool.
- Åtkomst till Delta Lake-tabeller i Lake-databaser är en offentlig förhandsversion. Kontrollera andra problem som anges i det här avsnittet eller i avsnittet Delta Lake.
En extern tabell som skapats i Spark visar oväntade resultat i en serverlös pool
Det kan hända att det finns ett matchningsfel mellan den externa spark-källtabellen och den replikerade externa tabellen i den serverlösa poolen. Detta kan inträffa om de filer som används för att skapa externa Spark-tabeller är utan tillägg. Kontrollera att alla filer är med tillägg som .parquet för att få rätt resultat.
Åtgärden tillåts inte för en replikerad databas
Det här felet returneras om du försöker ändra en Lake-databas, skapa externa tabeller, externa datakällor, databasomfattande autentiseringsuppgifter eller andra objekt i lakedatabasen. Dessa objekt kan bara skapas i SQL-databaser.
Lake-databaserna replikeras från Apache Spark-poolen och hanteras av Apache Spark. Därför kan du inte skapa objekt som i SQL Databases med hjälp av T-SQL-språk.
Endast följande åtgärder tillåts i Lake-databaserna:
- Skapa, släppa eller ändra vyer, procedurer och infogade tabellvärdesfunktioner (iTVF) i andra scheman än
dbo. - Skapa och ta bort databasanvändare från Microsoft Entra-ID.
- Lägga till eller ta bort databasanvändare från
db_datareaderschemat.
Andra åtgärder tillåts inte i Lake-databaser.
Kommentar
Om du skapar en vy, procedur eller funktion i dbo schemat (eller utelämnar schemat och använder standardschemat som vanligtvis dbo) får du felmeddelandet.
Deltatabeller i Lake-databaser är inte tillgängliga i en serverlös SQL-pool
Kontrollera att arbetsytans hanterade identitet har läsbehörighet på ADLS-lagringen som innehåller Delta-mappen. Den serverlösa SQL-poolen läser Delta Lake-tabellschemat från Delta-loggarna som placeras i ADLS och använder arbetsytans hanterade identitet för att komma åt Delta-transaktionsloggarna.
Försök att konfigurera en datakälla i en SQL Database som refererar till azure Data Lake-lagringen med hjälp av autentiseringsuppgifter för hanterad identitet och försök att skapa en extern tabell ovanpå datakällan med hanterad identitet för att bekräfta att en tabell med den hanterade identiteten kan komma åt lagringen.
Deltatabeller i Lake-databaser har inte identiskt schema i Spark- och serverlösa pooler
Med serverlösa SQL-pooler kan du komma åt Parquet-, CSV- och Delta-tabeller som skapas i Lake-databasen med spark- eller Synapse-designern. Åtkomsten till Delta-tabellerna är fortfarande i offentlig förhandsversion, och för närvarande synkroniserar serverlös en Delta-tabell med Spark vid tidpunkten för skapandet, men uppdaterar inte schemat om kolumnerna läggs till senare med hjälp av -instruktionen ALTER TABLE i Spark.
Det här är en begränsning för offentlig förhandsversion. Släpp och återskapa Delta-tabellen i Spark (om det är möjligt) i stället för att ändra tabeller för att lösa problemet.
Prestanda
Serverlös SQL-pool tilldelar resurserna till frågorna baserat på storleken på datamängden och frågekomplexiteten. Du kan inte ändra eller begränsa de resurser som tillhandahålls till frågorna. Det finns vissa fall där du kan uppleva oväntade försämringar av frågeprestanda och du kan behöva identifiera rotorsakerna.
Frågevaraktigheten är mycket lång
Om du har frågor med en frågevaraktighet som är längre än 30 minuter går det långsamt att returnera resultat till klienten. Serverlös SQL-pool har en 30-minutersgräns för körning. Mer tid ägnas åt resultatströmning. Prova följande lösningar:
- Om du använder Synapse Studio kan du försöka återskapa problemen med något annat program som SQL Server Management Studio eller Azure Data Studio.
- Om frågan är långsam när den körs med hjälp av SQL Server Management Studio, Azure Data Studio, Power BI eller något annat program kontrollerar du nätverksproblem och metodtips.
- Placera frågan i CETAS-kommandot och mät frågevaraktigheten. CETAS-kommandot lagrar resultatet till Azure Data Lake Storage och är inte beroende av klientanslutningen. Om CETAS-kommandot slutförs snabbare än den ursprungliga frågan kontrollerar du nätverksbandbredden mellan klienten och den serverlösa SQL-poolen.
Frågan är långsam när den körs med hjälp av Synapse Studio
Om du använder Synapse Studio kan du prova att använda en skrivbordsklient, till exempel SQL Server Management Studio eller Azure Data Studio. Synapse Studio är en webbklient som ansluter till en serverlös SQL-pool med hjälp av HTTP-protokollet, vilket vanligtvis är långsammare än de interna SQL-anslutningar som används i SQL Server Management Studio eller Azure Data Studio.
Frågan är långsam när den körs med hjälp av ett program
Kontrollera följande problem om du upplever långsam frågekörning:
- Kontrollera att klientprogrammen är sorterade med den serverlösa SQL-poolslutpunkten. Att köra en fråga i hela regionen kan orsaka ytterligare svarstider och långsam strömning av resultatuppsättningen.
- Kontrollera att du inte har nätverksproblem som kan orsaka långsam strömning av resultatuppsättningar
- Kontrollera att klientprogrammet har tillräckligt med resurser (till exempel att inte använda 100 % CPU).
- Kontrollera att lagringskontot eller Azure Cosmos DB-analyslagringen placeras i samma region som din serverlösa SQL-slutpunkt.
Se metodtips för att samordna resurserna.
Stora variationer i frågevaraktighet
Om du kör samma fråga och observerar variationer i frågevaraktigheterna kan det bero på flera orsaker:
- Kontrollera om det här är den första körningen av en fråga. Den första körningen av en fråga samlar in den statistik som krävs för att skapa en plan. Statistiken samlas in genom att genomsöka de underliggande filerna och kan öka frågevaraktigheten. I Synapse Studio visas frågorna om att skapa global statistik i listan med SQL-begäranden som körs före din fråga.
- Statistiken kan upphöra att gälla efter en viss tid. Med jämna mellanrum kan du se en inverkan på prestanda eftersom den serverlösa poolen måste skanna och återskapa statistiken. Du kanske ser ytterligare frågor om att skapa global statistik i listan med SQL-begäranden som körs före din fråga.
- Kontrollera om det finns en viss arbetsbelastning som körs på samma slutpunkt när du körde frågan med längre varaktighet. Den serverlösa SQL-slutpunkten allokerar resurserna till alla frågor som körs parallellt och frågan kan fördröjas.
anslutningar
Med en serverlös SQL-pool kan du ansluta med hjälp av TDS-protokollet och med hjälp av T-SQL-språket för att fråga efter data. De flesta verktyg som kan ansluta till SQL Server eller Azure SQL Database kan också ansluta till en serverlös SQL-pool.
SQL-poolen värms upp
Efter en längre period av inaktivitet inaktiveras serverlös SQL-pool. Aktiveringen sker automatiskt vid den första nästa aktiviteten, till exempel det första anslutningsförsöket. Aktiveringsprocessen kan ta lite längre tid än intervallet för ett anslutningsförsök, och då visas felmeddelandet. Det bör räcka med att försöka ansluta igen.
Bästa praxis är att använda ConnectionRetryCount och ConnectRetryInterval niska veze nyckelord för att styra återanslutningsbeteendet för klienterna som stöder det.
Om felmeddelandet kvarstår kan du skicka ett supportärende via Azure-portalen.
Det går inte att ansluta från Synapse Studio
Se avsnittet Synapse Studio.
Det går inte att ansluta till Azure Synapse-poolen från ett verktyg
Vissa verktyg kanske inte har ett explicit alternativ som du kan använda för att ansluta till den serverlösa SQL-poolen i Azure Synapse. Använd ett alternativ som du använder för att ansluta till SQL Server eller SQL Database. Anslutningsdialogrutan behöver inte märkas som "Synapse" eftersom den serverlösa SQL-poolen använder samma protokoll som SQL Server eller SQL Database.
Även om ett verktyg gör att du bara kan ange ett logiskt servernamn och fördefinierade domänen database.windows.net , placerar du namnet på Azure Synapse-arbetsytan följt av suffixet -ondemand och domänen database.windows.net .
Säkerhet
Kontrollera att en användare har behörighet att komma åt databaser, behörigheter för att köra kommandon och behörigheter för åtkomst till Azure Data Lake eller Azure Cosmos DB-lagring.
Det går inte att komma åt Azure Cosmos DB-kontot
Du måste använda en skrivskyddad Azure Cosmos DB-nyckel för att få åtkomst till analyslagringen, så se till att den inte upphör att gälla eller att den inte återskapas.
Om du får felet "Det gick inte att lösa Azure Cosmos DB-sökvägen med fel" kontrollerar du att du har konfigurerat en brandvägg.
Det går inte att komma åt Lakehouse- eller Spark-databasen
Om en användare inte kan komma åt en lakehouse- eller Spark-databas kanske användaren inte har behörighet att komma åt och läsa databasen. En användare med behörigheten KONTROLLSERVER bör ha fullständig åtkomst till alla databaser. Som en begränsad behörighet kan du försöka använda CONNECT ANY DATABASE och SELECT ALL USER SECURABLES.
SQL-användare kan inte komma åt Dataverse-tabeller
Dataverse-tabeller får åtkomst till lagring med hjälp av anroparens Microsoft Entra-identitet. En SQL-användare med hög behörighet kan försöka välja data från en tabell, men tabellen skulle inte kunna komma åt Dataverse-data. Det här scenariot stöds inte.
Inloggningsfel för Microsoft Entra-tjänstens huvudnamn när SPI skapar en rolltilldelning
Om du vill skapa en rolltilldelning för en tjänsthuvudnamnsidentifierare (SPI) eller Microsoft Entra-app med hjälp av en annan SPI, eller om du redan har skapat en och den inte kan logga in, får du förmodligen följande fel: Login error: Login failed for user '<token-identified principal>'.
För tjänstens huvudnamn ska inloggningen skapas med ett program-ID som ett säkerhets-ID (SID) inte med ett objekt-ID. Det finns en känd begränsning för tjänstens huvudnamn som hindrar Azure Synapse från att hämta program-ID:t från Microsoft Graph när en rolltilldelning skapas för en annan SPI eller app.
Lösning 1
Gå till Azure-portalen>Synapse Studio>Hantera>åtkomstkontroll och lägg till Synapse-administratör eller Synapse SQL-administratör manuellt för det önskade tjänstens huvudnamn.
Lösning 2
Du måste manuellt skapa en korrekt inloggning med SQL-kod:
use master
go
CREATE LOGIN [<service_principal_name>] FROM EXTERNAL PROVIDER;
go
ALTER SERVER ROLE sysadmin ADD MEMBER [<service_principal_name>];
go
Lösning 3
Du kan också konfigurera en Azure Synapse-administratör för tjänstens huvudnamn med hjälp av PowerShell. Du måste ha modulen Az.Synapse installerad.
Lösningen är att använda cmdleten New-AzSynapseRoleAssignment med -ObjectId "parameter". I det parameterfältet anger du program-ID:t i stället för objekt-ID:t med hjälp av autentiseringsuppgifterna för azure-tjänstens huvudnamn för arbetsytans administratör.
PowerShell-skript:
$spAppId = "<app_id_which_is_already_an_admin_on_the_workspace>"
$SPPassword = "<application_secret>"
$tenantId = "<tenant_id>"
$secpasswd = ConvertTo-SecureString -String $SPPassword -AsPlainText -Force
$cred = New-Object -TypeName System.Management.Automation.PSCredential -ArgumentList $spAppId, $secpasswd
Connect-AzAccount -ServicePrincipal -Credential $cred -Tenant $tenantId
New-AzSynapseRoleAssignment -WorkspaceName "<workspaceName>" -RoleDefinitionName "Synapse Administrator" -ObjectId "<app_id_to_add_as_admin>" [-Debug]
Validering
Anslut till den serverlösa SQL-slutpunkten och kontrollera att den externa inloggningen med SID (app_id_to_add_as_admin i föregående exempel) har skapats:
SELECT name, convert(uniqueidentifier, sid) AS sid, create_date
FROM sys.server_principals
WHERE type in ('E', 'X');
Eller prova att logga in på den serverlösa SQL-slutpunkten med hjälp av den angivna administratörsappen.
Krav
Vissa allmänna systembegränsningar kan påverka din arbetsbelastning:
| Property | Begränsning |
|---|---|
| Maximalt antal Azure Synapse-arbetsytor per prenumeration | Se gränser. |
| Maximalt antal databaser per serverlös pool | 100 (inkluderar inte databaser som synkroniserats från Apache Spark-poolen). |
| Maximalt antal databaser som synkroniserats från Apache Spark-poolen | Inte begränsat. |
| Maximalt antal databasobjekt per databas | Summan av antalet alla objekt i en databas får inte överstiga 2 147 483 647. Se Begränsningar i SQL Server-databasmotorn. |
| Maximal teckenlängd för identifierare | 128. Se Begränsningar i SQL Server-databasmotorn. |
| Maximal frågevaraktighet | 30 minuter. |
| Maximal storlek på resultatuppsättningen | Upp till 400 GB delas mellan samtidiga frågor. |
| Maximal samtidighet | Inte begränsat och beror på frågekomplexiteten och mängden data som genomsöks. En serverlös SQL-pool kan samtidigt hantera 1 000 aktiva sessioner som kör enkla frågor. Det antalet minskar om frågorna är mer komplexa eller genomsöker en större mängd data, så i så fall bör du överväga att minska samtidigheten och köra frågor under en längre tidsperiod om det är möjligt. |
| Maximal storlek på namn på extern tabell | 100 tecken. |
Det går inte att skapa en databas i en serverlös SQL-pool
Serverlösa SQL-pooler har begränsningar och du kan inte skapa fler än 100 databaser per arbetsyta. Om du behöver separera objekt och isolera dem använder du scheman.
Om du får felet CREATE DATABASE failed. User database limit has been already reached har du skapat det maximala antalet databaser som stöds på en arbetsyta.
Du behöver inte använda separata databaser för att isolera data för olika klienter. Alla data lagras externt på en datasjö och Azure Cosmos DB. Metadata som tabell, vyer och funktionsdefinitioner kan isoleras med hjälp av scheman. Schemabaserad isolering används också i Spark där databaser och scheman är samma begrepp.
Nästa steg
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för