Not
Åtkomst till denna sida kräver auktorisation. Du kan prova att logga in eller byta katalog.
Åtkomst till denna sida kräver auktorisation. Du kan prova att byta katalog.
Den här guiden innehåller stegvisa instruktioner för att använda anpassad namngiven entitetsigenkänning (NER) med Microsoft Foundry eller REST-API:et. MED NER kan du identifiera och kategorisera entiteter i ostrukturerad text, till exempel personer, platser, organisationer och siffror. Med anpassad NER kan du träna modeller för att identifiera entiteter som är specifika för ditt företag och anpassa dem när behoven utvecklas.
För att komma igång tillhandahålls ett exempellåneavtal som en datauppsättning för att skapa en anpassad NER-modell och extrahera dessa nyckelentiteter:
- Datum för avtalet
- Låntagarens namn, adress, ort och delstat
- Långivarens namn, adress, ort och delstat
- Låne- och räntebelopp
Kommentar
- Om du redan har ett Azure Language i Foundry Tools eller en resurs med flera tjänster – oavsett om det används på egen hand eller via Language Studio – kan du fortsätta att använda de befintliga språkresurserna i Microsoft Foundry-portalen. Mer information finns i Använda Foundry Tools i Foundry-portalen.
Förutsättningar
En prenumeration för Azure. Om du inte har en kan du skapa en kostnadsfritt.
Nödvändiga behörigheter. Kontrollera att personen som upprättar kontot och projektet har tilldelats rollen som Azure AI-kontoägare på prenumerationsnivå. Alternativt kan du inneha rollen Deltagare eller Cognitive Services-deltagare på prenumerationsnivå. Mer information finns iRollbaserad åtkomstkontroll (RBAC).
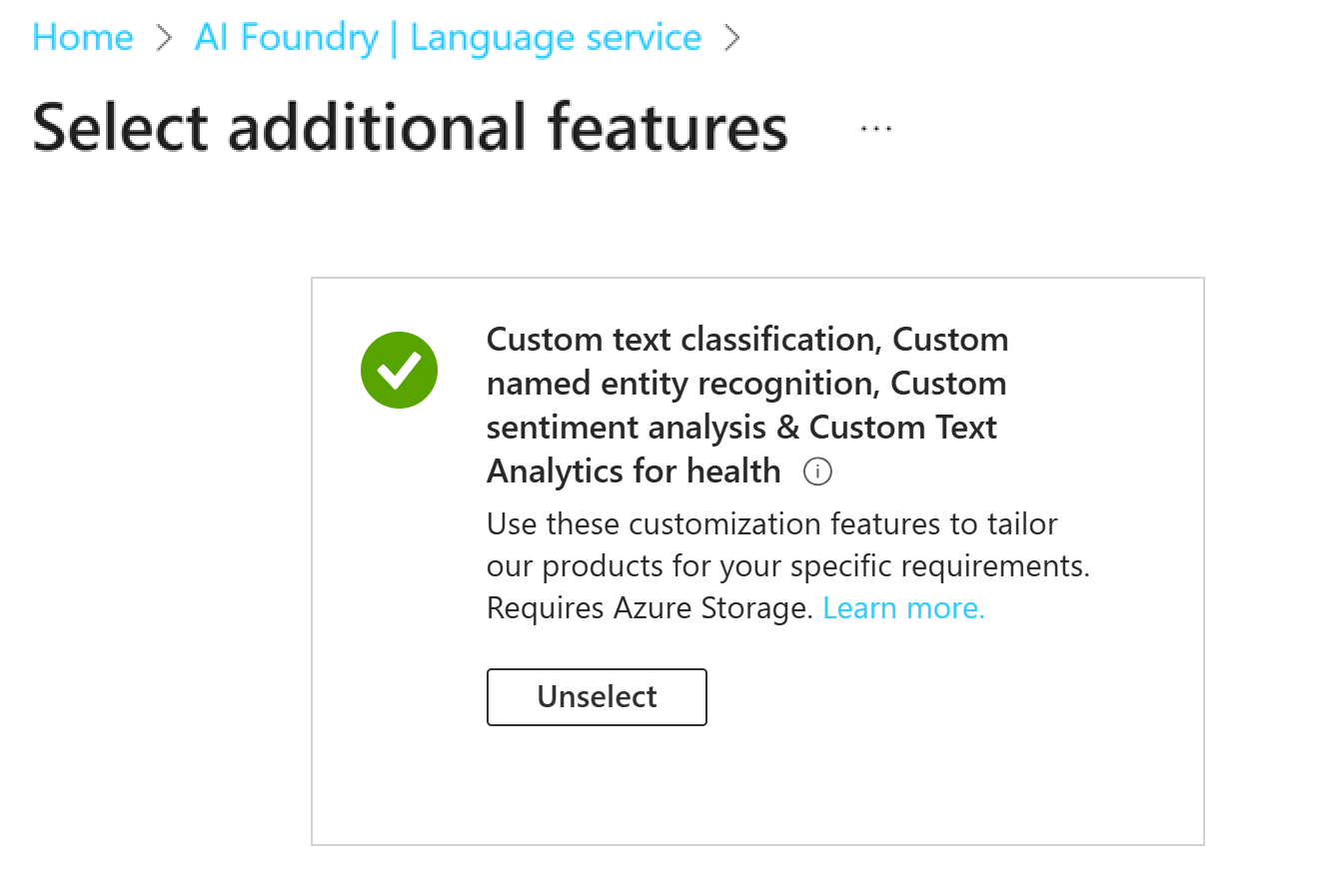
En språkresurs med ett lagringskonto. På sidan Välj ytterligare funktioner väljer du rutan Anpassad textklassificering, Anpassad namngiven entitetsigenkänning, Anpassad attitydanalys och Anpassad textanalys för hälsa för att länka ett obligatoriskt lagringskonto till den här resursen:
Kommentar
- Du måste ha en ägarroll tilldelad till resursgruppen för att skapa en språkresurs.
- Om du ansluter ett befintligt lagringskonto bör du ha en ägarroll tilldelad till det.
- Flytta inte lagringskontot till en annan resursgrupp eller prenumeration när det är länkat med Azure Language-resursen.
Ett Foundry-projekt som skapats i Foundry. Mer information finns iSkapa ett Foundry-projekt.
En anpassad NER-datauppsättning som laddats upp till din lagringscontainer. En anpassad datauppsättning för namngiven entitetsigenkänning (NER) är samlingen av märkta textdokument som används för att träna din anpassade NER-modell. Du kan ladda ned vår exempeldatauppsättning för den här snabbstarten. Källspråket är engelska.
Steg 1: Konfigurera nödvändiga roller, behörigheter och inställningar
Vi börjar med att konfigurera dina resurser.
Aktivera funktionen för anpassad namngiven entitetsigenkänning
Kontrollera att funktionen Anpassad textklassificering/anpassad namngiven entitetsigenkänning är aktiverad i Azure-portalen.
- Gå till språkresursen i Azure-portalen.
- På menyn till vänster går du till avsnittet Resurshantering och väljer Funktioner.
- Kontrollera att funktionen Anpassad textklassificering/anpassad namngiven entitetsigenkänning är aktiverad.
- Om ditt lagringskonto inte har tilldelats väljer du och ansluter ditt lagringskonto.
- Välj Använd.
Lägga till nödvändiga roller för språkresursen
- På sidan Språkresurs i Azure-portalen väljer du Åtkomstkontroll (IAM) i den vänstra rutan.
- Välj Lägg till för att lägga till rolltilldelningar och lägg till Rolltilldelning för Cognitive Services-språkägare eller Cognitive Services-deltagare för din språkresurs.
- I Tilldela åtkomst till väljer du Användare, grupp eller tjänstens huvudnamn.
- Välj Välj medlemmar.
- Välj ditt användarnamn. Du kan söka efter användarnamn i fältet Välj . Upprepa det här steget för alla roller.
- Upprepa de här stegen för alla användarkonton som behöver åtkomst till den här resursen.
Lägga till nödvändiga roller för ditt lagringskonto
- Gå till sidan för ditt lagringskonto i Azure-portalen.
- Välj Åtkomstkontroll (IAM) i den vänstra rutan.
- Välj Lägg till för att lägga till rolltilldelningar och välj rollen Lagringsblobdatadeltagare för lagringskontot.
- I Tilldela åtkomst till väljer du Hanterad identitet.
- Välj Välj medlemmar.
- Välj din prenumeration och Språk som hanterad identitet. Du kan söka efter språkresursen i fältet Välj .
Lägga till nödvändiga användarroller
Viktigt!
Om du hoppar över det här steget får du ett 403-fel när du försöker ansluta till ditt anpassade projekt. Det är viktigt att den aktuella användaren har den här rollen för åtkomst till lagringskontots blobdata, även om du är ägare till lagringskontot.
- Gå till sidan för ditt lagringskonto i Azure-portalen.
- Välj Åtkomstkontroll (IAM) i den vänstra rutan.
- Välj Lägg till för att lägga till rolltilldelningar och välj rollen Lagringsblobdatadeltagare för lagringskontot.
- I Tilldela åtkomst till väljer du Användare, grupp eller tjänstens huvudnamn.
- Välj Välj medlemmar.
- Välj din användare. Du kan söka efter användarnamn i fältet Välj .
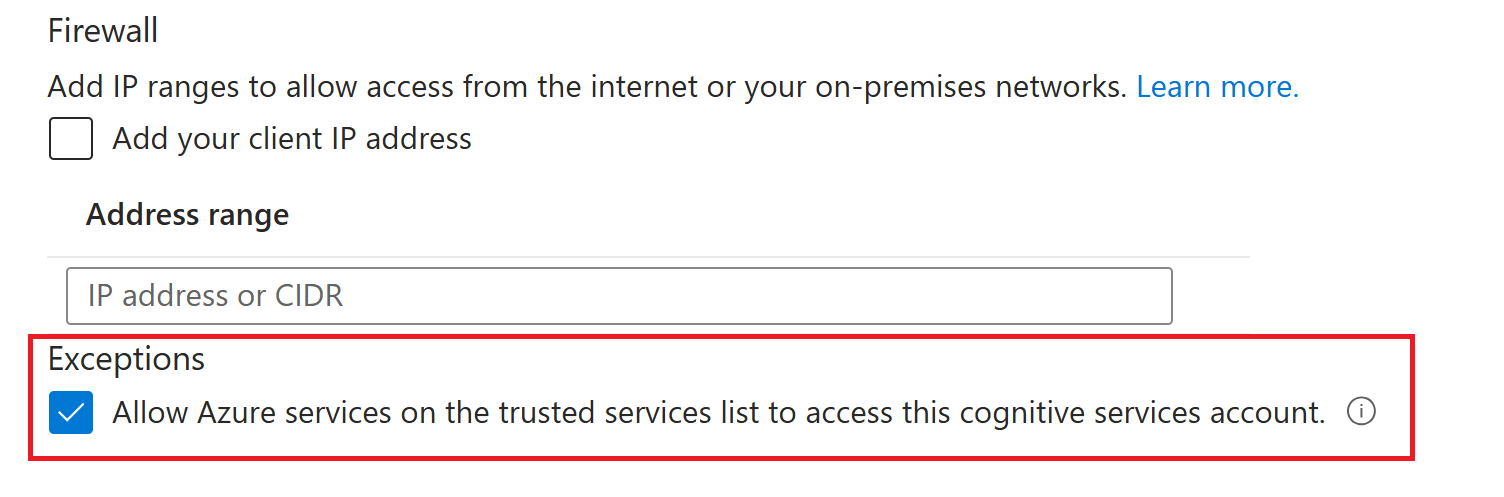
Viktigt!
Om du har en brandvägg eller ett virtuellt nätverk eller en privat slutpunkt måste du välja Tillåt att Azure-tjänster i listan över betrodda tjänster får åtkomst till det här lagringskontot under fliken Nätverk i Azure-portalen.
Steg 2: Ladda upp datauppsättningen till lagringscontainern
Nu ska vi lägga till en container och ladda upp dina datamängdsfiler direkt till rotkatalogen för lagringscontainern. Dessa dokument används för att träna din modell.
Lägg till en container i lagringskontot som är associerat med språkresursen. Mer information finns iskapa en container.
Ladda ned exempeldatauppsättningen från GitHub. Den tillhandahållna exempeldatamängden innehåller 20 låneavtal:
- Varje avtal omfattar två parter: en långivare och en låntagare.
- Du extraherar relevant information för: båda parter, avtalsdatum, lånebelopp och ränta.
Öppna filen .zip och extrahera mappen som innehåller dokumenten.
Navigera till Foundry.
Om du inte redan är inloggad uppmanar portalen dig att göra det med dina Azure-autentiseringsuppgifter.
När du har loggat in får du åtkomst till ditt befintliga Foundry-projekt för den här snabbstarten.
Välj Hanteringscenter på den vänstra navigeringsmenyn.
Välj Anslutna resurser i hubbavsnittet på menyn Hanteringscenter .
Välj sedan den bloblagring för arbetsytan som har konfigurerats för dig som en ansluten resurs.
På arbetsytans bloblagring väljer du Visa i Azure-portalen.
På sidan AzurePortal för din bloblagring väljer du Ladda upp på den översta menyn. Välj sedan filerna
.txtoch.jsonsom du laddade ned tidigare. Välj slutligen knappen Ladda upp för att lägga till filen i containern.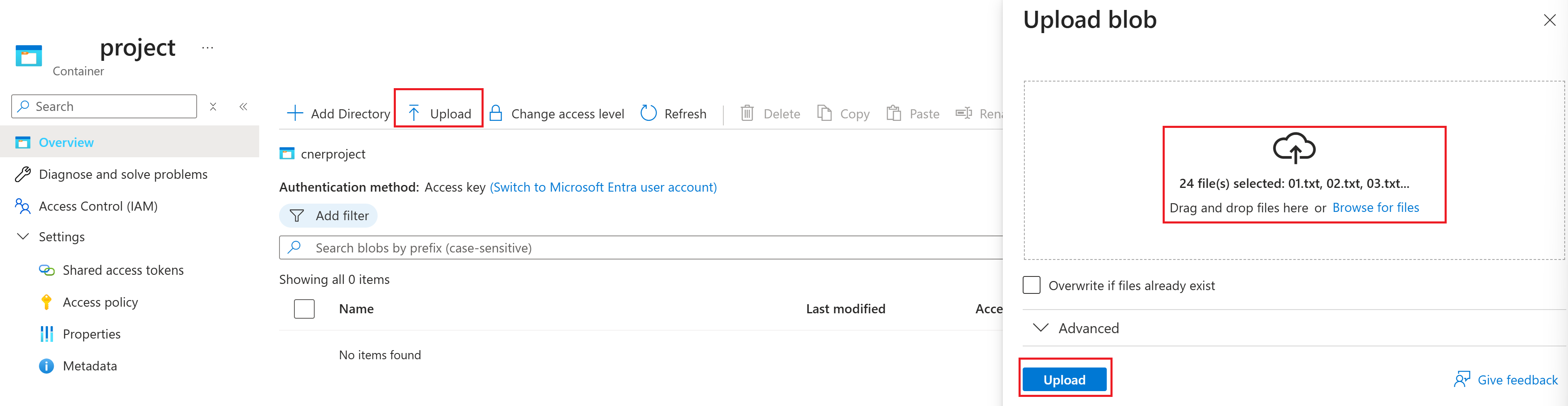
Nu när de nödvändiga Azure-resurserna har etablerats och konfigurerats i Azure-portalen ska vi använda dessa resurser i Foundry för att skapa en finjusterad anpassad NER-modell (Named Entity Recognition).
Steg 3: Anslut språkresursen
Sedan skapar vi en anslutning till språkresursen så att Foundry kan komma åt den på ett säkert sätt. Den här anslutningen ger säker identitetshantering och autentisering samt kontrollerad och isolerad åtkomst till data.
Gå tillbaka till Foundry.
Öppna ditt befintliga Foundry-projekt för den här snabbstarten.
Välj Hanteringscenter på den vänstra navigeringsmenyn.
Välj Anslutna resurser i hubbavsnittet på menyn Hanteringscenter .
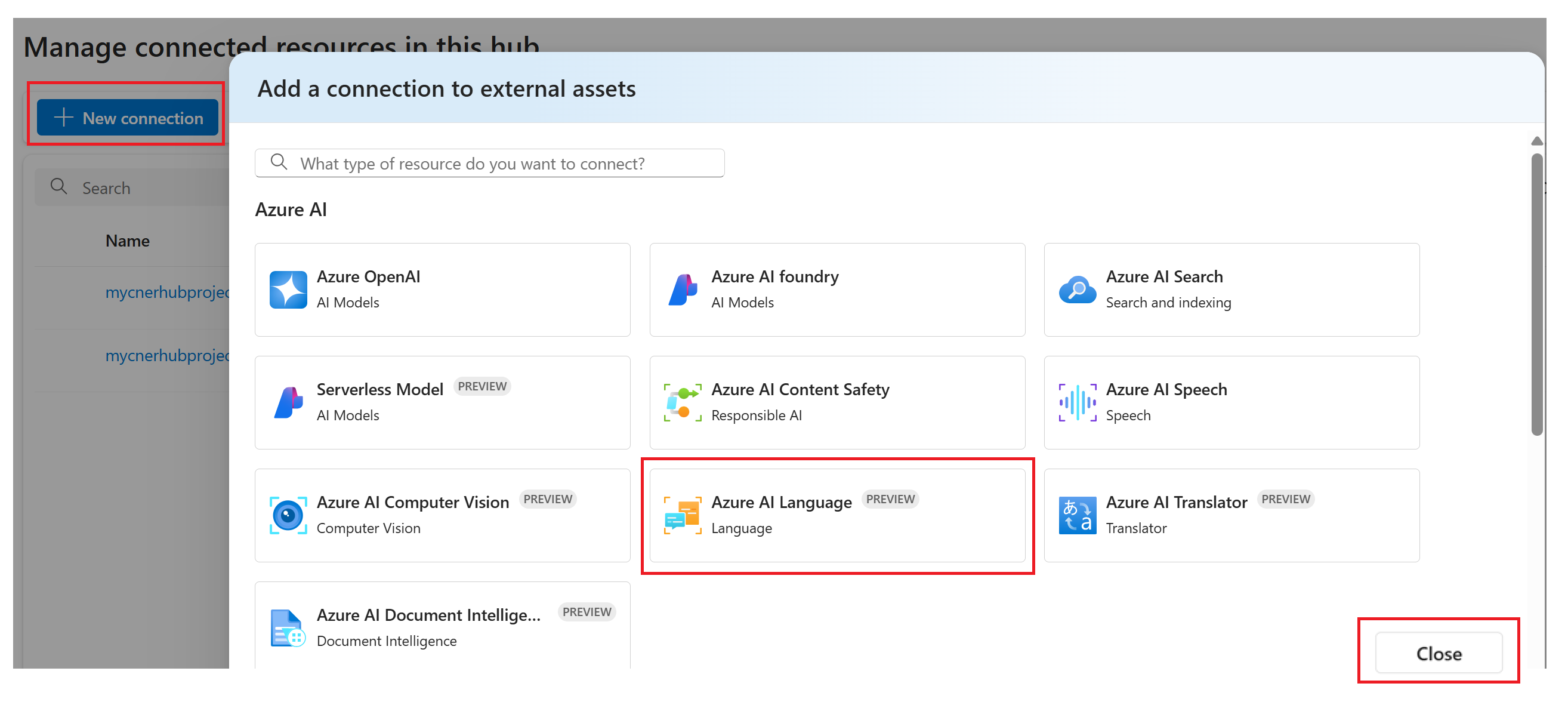
I huvudfönstret väljer du knappen + Ny anslutning .
Välj Språk i fönstret Lägg till en anslutning till externa tillgångar .
Välj Lägg till anslutning och välj sedan Stäng.
Steg 4: Finjustera din anpassade NER-modell
Nu är vi redo att skapa en anpassad NER-finjusteringsmodell.
I avsnittet Projekt på menyn Hanteringscenter väljer du Gå till projekt.
På menyn Översikt väljer du Finjustering.
I huvudfönstret väljer du fliken AI-tjänstens finjustering och sedan knappen + Finjustera .
I fönstret Skapa tjänstens finjustering väljer du fliken Anpassad namngiven entitetsigenkänning och väljer sedan Nästa.
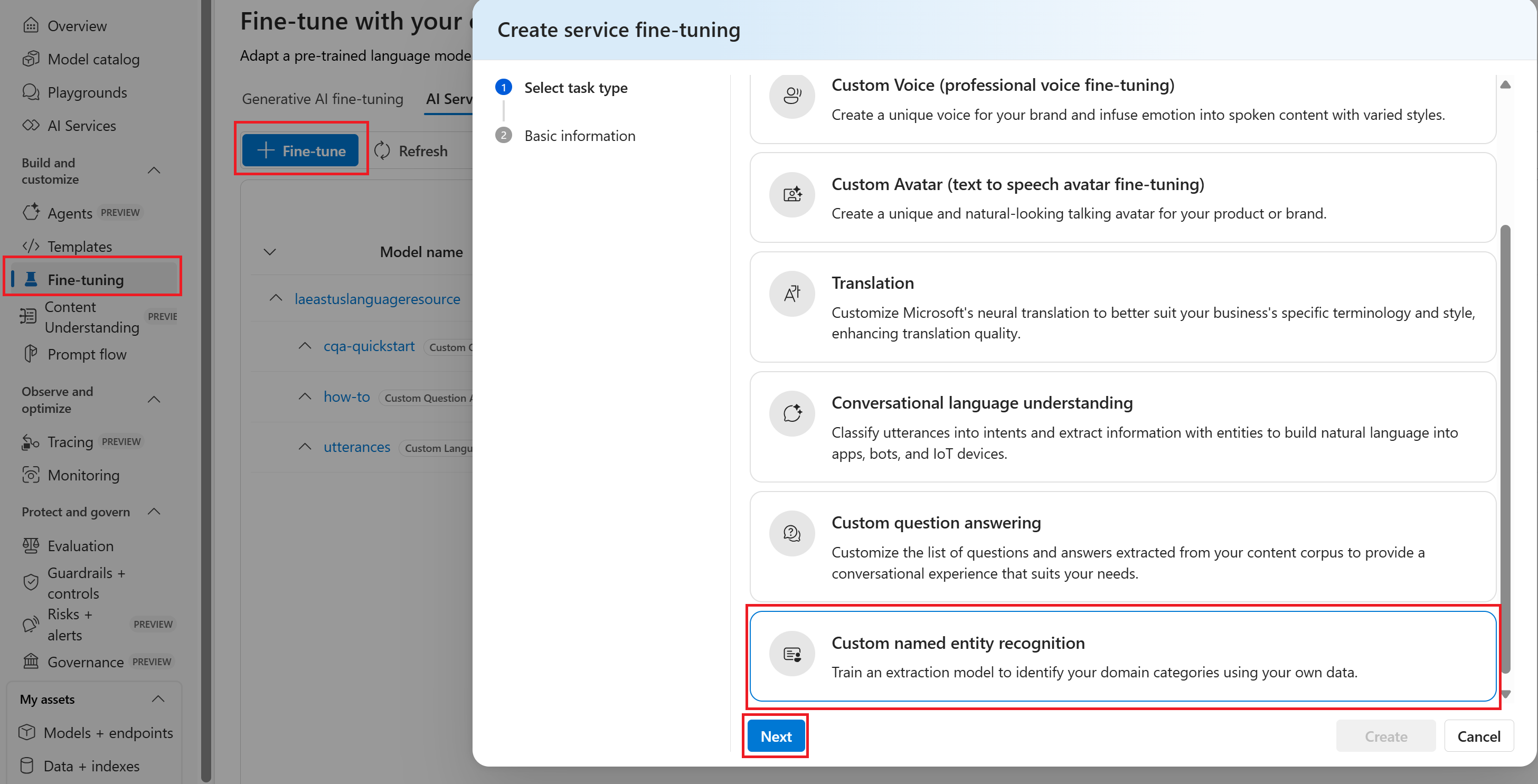
I fönstret Skapa justera tjänstinställning slutför du fälten på följande sätt:
Ansluten tjänst. Namnet på språkresursen bör redan visas i det här fältet som standard. om inte lägger du till den från den nedrullningsbara menyn.
Name. Ge ditt finjusteringsprojekt ett namn.
Språk. Engelska anges som standard och visas redan i fältet.
Description. Du kan också ange en beskrivning eller lämna fältet tomt.
Blob Store-container. Välj bloblagringscontainern för arbetsytan i steg 2 och klicka på knappen Anslut.
Välj slutligen knappen Skapa . Det kan ta några minuter innan skapandeåtgärden har slutförts.

Steg 5: Träna din modell

- På menyn Komma igång väljer du Hantera data. I fönstret Lägg till data för träning och testning ser du exempeldata som du tidigare laddade upp till din Azure Blob Storage-container.
- Välj sedan Träna modell från menyn Komma igång.
- Välj knappen + Träna modell. När fönstret Träna en ny modell visas anger du ett namn på den nya modellen och behåller standardvärdena. Välj knappen Nästa.
- I fönstret Träna en ny modell behåller du standardinställningen Dela testuppsättningen automatiskt från träningsdata som är aktiverad med den rekommenderade procentandelen inställd på 80% för träningsdata och 20% för testdata.
- Granska modellkonfigurationen och välj sedan knappen Skapa .
- När du har tränat en modell kan du välja Utvärdera modell på menyn Komma igång . Du kan välja din modell från fönstret Utvärdera modell och göra förbättringar om det behövs.
Steg 6: Distribuera din modell
När du har tränat en modell granskar du vanligtvis dess utvärderingsinformation. I den här snabbstarten kan du bara distribuera din modell och göra den tillgänglig för testning på Azure Language Playground, eller genom att anropa förutsägelse-API:et. Men om du vill kan du ta en stund att välja Utvärdera din modell från menyn till vänster och utforska den djupgående telemetrin för din modell. Slutför följande steg för att distribuera din modell i Foundry.
Välj Distribuera modell på menyn till vänster.
Välj ➕sedan Distribuera en tränad modell från fönstret Distribuera din modell .
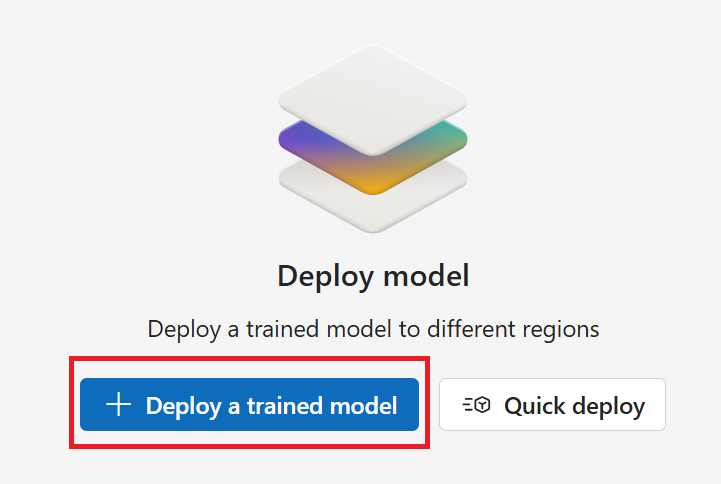
Kontrollera att knappen Skapa en ny distribution är markerad.
Slutför fälten Distribuera en tränad modellfönster :
- Distributionsnamn. Namnge din modell.
- Tilldela en modell. Välj din tränade modell på den nedrullningsbara menyn.
- Region. Välj en region i den nedrullningsbara menyn.
Välj slutligen knappen Skapa . Det kan ta några minuter innan modellen distribueras.
När distributionen har slutförts kan du visa din modells distributionsstatus på sidan Distribuera din modell . Förfallodatumet som visas markerar det datum då din distribuerade modell blir otillgänglig för förutsägelseaktiviteter. Det här datumet är vanligtvis 18 månader efter att en träningskonfiguration har distribuerats.
Skärmbild av fönstret för distributionsstatus för din modell i Foundry.
Steg 7: Prova Azure Language Playground
Language Playground tillhandahåller en sandbox-miljö för att testa och konfigurera din finjusterade modell innan du distribuerar den till produktion, allt utan att skriva kod.
- I den översta menyraden väljer du Prova på lekplatsen.
- I fönstret Azure Language Playground väljer du panelen Anpassad namngiven entitetsigenkänning .
- I avsnittet Konfiguration väljer du projektnamn och distributionsnamn i de nedrullningsbara menyerna.
- Ange en entitet och välj Kör.
- Du kan utvärdera resultaten i fönstret Information .
Det var allt, grattis!
I den här snabbstarten skapade du en finjusterad anpassad NER-modell, distribuerade den i Foundry och testade din modell i Azure Language Playground.
Rensa resurser
Om du inte längre behöver projektet kan du ta bort det från Foundry.
- Gå till startsidan för Foundry . Initiera autentiseringsprocessen genom att logga in, såvida du inte redan har slutfört det här steget och sessionen är aktiv.
- Välj det projekt som du vill ta bort från Fortsätt bygga med Foundry.
- Välj Hanteringscenter.
- Välj Ta bort projekt.
Så här tar du bort hubben tillsammans med alla dess projekt:
Gå till fliken Översikt i avsnittet Hubb .
Till höger väljer du Ta bort hubb.
Länken öppnar Azure-portalen där du kan ta bort hubben där.
Förutsättningar
- Azure-prenumeration – Skapa en kostnadsfritt
Skapa ett nytt Azure Language i Foundry Tools-resursen och Azure-lagringskontot
Innan du kan använda anpassad namngiven entitetsigenkänning (NER) måste du skapa en språkresurs som ger dig de autentiseringsuppgifter som du behöver för att skapa ett projekt och börja träna en modell. Du behöver också ett Azure Storage-konto där du kan ladda upp din datauppsättning som används för att skapa din modell.
Viktigt!
För att komma igång snabbt rekommenderar vi att du skapar en ny språkresurs. Använd stegen i den här artikeln för att skapa Azure Language-resursen och skapa och/eller ansluta ett lagringskonto samtidigt. Det är enklare att skapa båda samtidigt än att göra det senare.
Om du har en befintlig resurs som du vill använda måste du ansluta den till lagringskontot. Mer information finns i Skapa projekt .
Skapa en ny resurs från Azure Portal
Logga in på Azure-portalen för att skapa en ny Azure Language in Foundry Tools-resurs.
I fönstret som visas väljer du Anpassad textklassificering och anpassad namngiven entitetsigenkänning från de anpassade funktionerna. Välj Fortsätt för att skapa resursen längst ned på skärmen.

Skapa en språkresurs med följande information.
Name beskrivning Prenumeration Din Azure-prenumeration. Resursgrupp En resursgrupp som innehåller din resurs. Du kan använda en befintlig eller skapa en ny. Region Regionen för din språkresurs. Till exempel "West US 2". Name Ett namn på resursen. Prisnivå Prisnivån för din språkresurs. Du kan använda nivån Kostnadsfri (F0) för att prova tjänsten. Kommentar
Om du får ett meddelande om att ditt inloggningskonto inte är ägare till det valda lagringskontots resursgrupp måste ditt konto ha en ägarroll tilldelad till resursgruppen innan du kan skapa en Språkresurs. Kontakta din Azure-prenumerationsägare om du vill ha hjälp.
I avsnittet Anpassad textklassificering och anpassad namngiven entitetsigenkänning väljer du ett befintligt lagringskonto eller väljer Nytt lagringskonto. Dessa värden hjälper dig att komma igång och inte nödvändigtvis de lagringskontovärden som du vill använda i produktionsmiljöer. För att undvika svarstider när du skapar projektet ansluter du till lagringskonton i samma region som språkresursen.
Lagringskontovärde Rekommenderat värde Lagringskontonamn Valfritt namn Typ av lagringskonto Standard lokalt redundant lagring (LRS) Kontrollera att meddelandet om ansvarsfull AI är markerat. Välj Granska + skapa längst ned på sidan och välj sedan Skapa.

Ladda upp exempeldata till blobcontainer
När du har skapat ett Azure Storage-konto och anslutit det till språkresursen måste du ladda upp dokumenten från exempeldatauppsättningen till rotkatalogen i containern. Dessa dokument används för att träna din modell.
Ladda ned exempeldatauppsättningen från GitHub.
Öppna filen .zip och extrahera mappen som innehåller dokumenten.
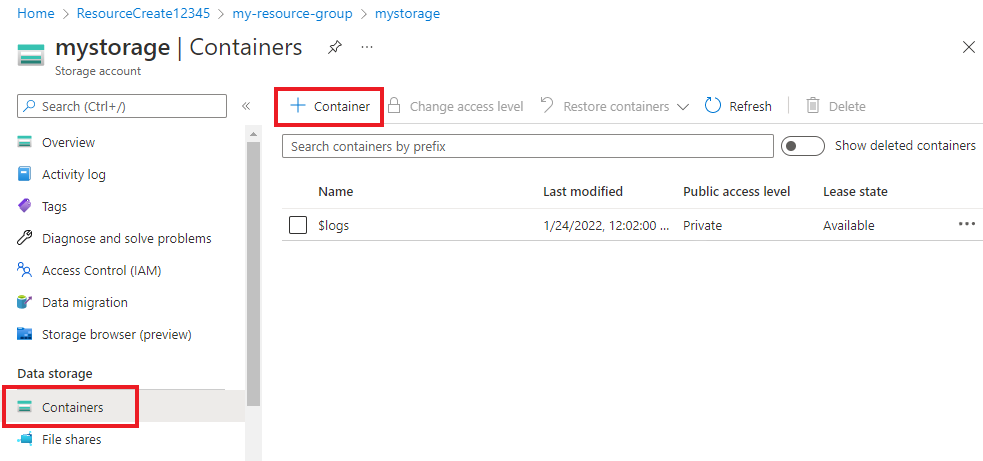
I Azure Portal navigerar du till lagringskontot som du skapade och väljer det.
I ditt lagringskonto väljer du Containrar på den vänstra menyn under Datalagring. På skärmen som visas väljer du + Container. Ge containern namnet example-data och lämna standardnivån offentlig åtkomst.
När containern har skapats väljer du den. Välj sedan knappen Ladda upp för att välja filerna
.txtoch.jsonsom du laddade ned tidigare.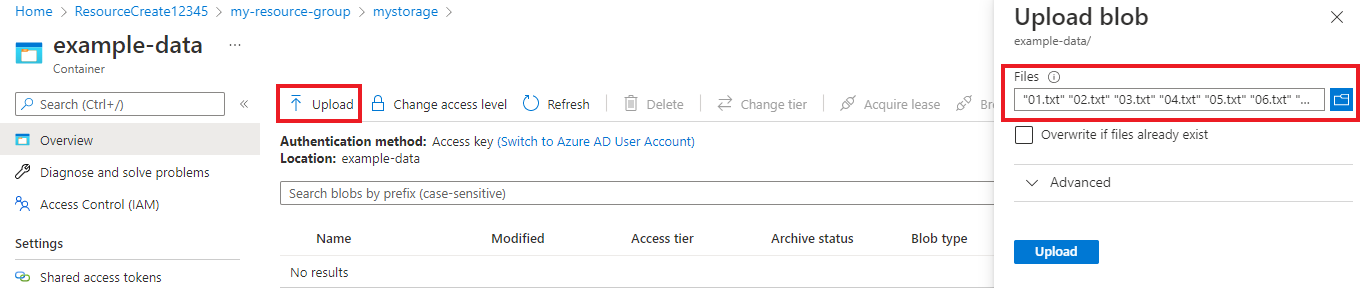


Den tillhandahållna exempeldatamängden innehåller 20 låneavtal. Varje avtal omfattar två parter: en långivare och en låntagare. Du kan använda den angivna exempelfilen för att extrahera relevant information för: båda parter, ett avtalsdatum, ett lånebelopp och en räntesats.
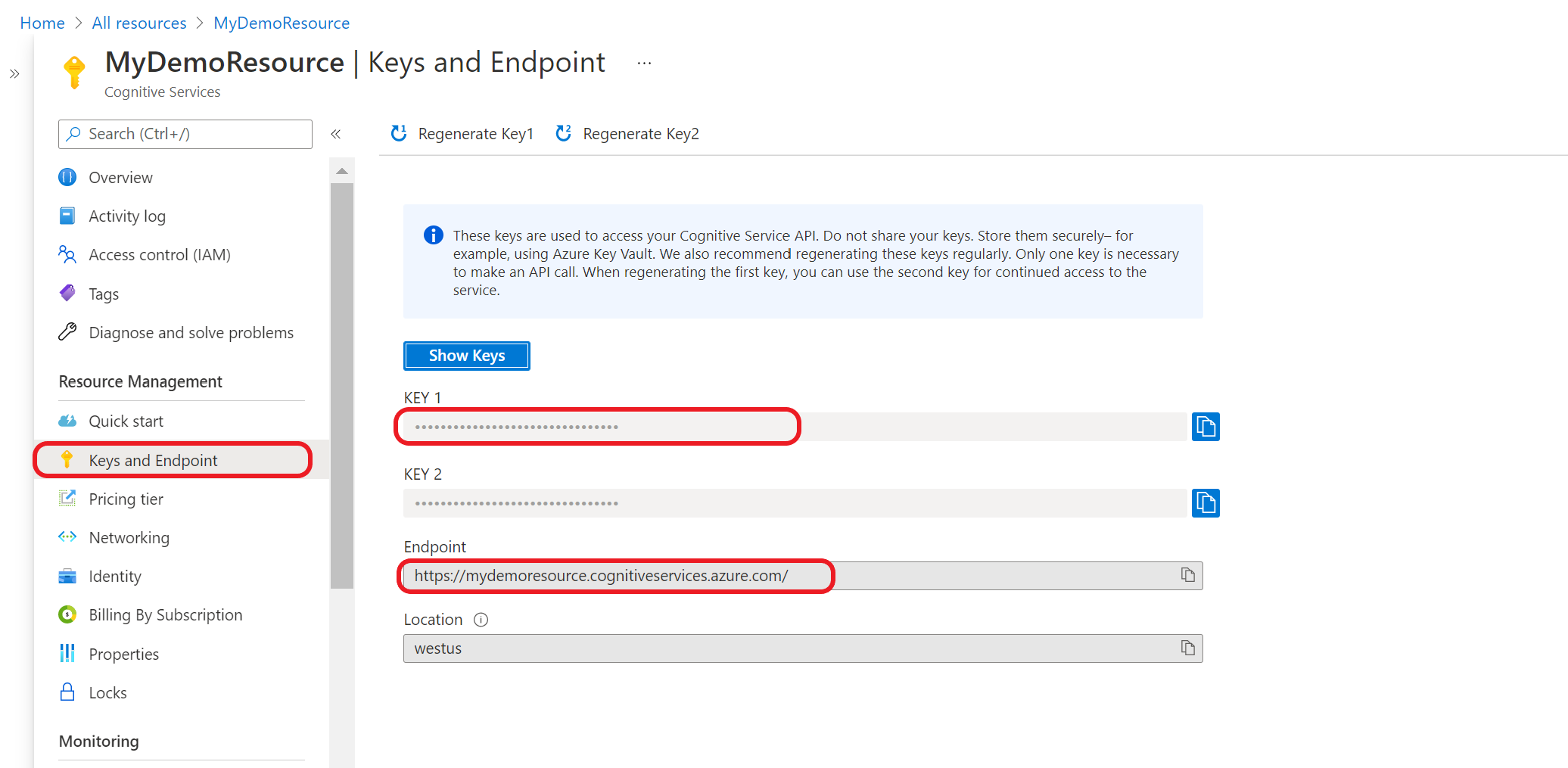
Hämta dina resursnycklar och slutpunkt
Gå till resursöversiktssidan i Azure Portal
På menyn till vänster väljer du Nycklar och Slutpunkt. Slutpunkten och nyckeln används för API-begäranden.

Skapa ett anpassat NER-projekt
När resursen och lagringskontot har konfigurerats skapar du ett nytt anpassat NER-projekt. Ett projekt är ett arbetsområde för att skapa dina anpassade ML-modeller baserat på dina data. Ditt projekt är åtkomligt för dig och andra som har åtkomst till den Azure Language-resurs som används.
Använd taggar-filen som du laddade ned från exempeldata i föregående steg och lägg till den i brödtexten i följande begäran.
Starta importprojektjobb
Skicka en POST-begäran med hjälp av följande URL, rubriker och JSON-brödtext för att importera din etikettfil. Kontrollera att din etikettfil följer det godkända formatet.
Om det redan finns ett projekt med samma namn ersätts data för projektet.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/:import?api-version={API-VERSION}
| Platshållare | Värde | Exempel |
|---|---|---|
{ENDPOINT} |
Slutpunkten för att autentisera din API-begäran. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Namnet på projektet. Det här värdet är skiftlägeskänsligt. | myProject |
{API-VERSION} |
Den version av API:et som du anropar. Värdet som refereras här är för den senaste versionen som släppts. Mer information finns iModelllivscykel. | 2022-05-01 |
Rubriker
Använd följande rubrik för att autentisera din begäran.
| Nyckel | Värde |
|---|---|
Ocp-Apim-Subscription-Key |
Nyckeln till resursen. Används för att autentisera dina API-begäranden. |
Kropp
Använd följande JSON i din begäran. Ersätt platshållarvärdena med dina egna värden.
{
"projectFileVersion": "{API-VERSION}",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectName": "{PROJECT-NAME}",
"projectKind": "CustomEntityRecognition",
"description": "Trying out custom NER",
"language": "{LANGUAGE-CODE}",
"multilingual": true,
"storageInputContainerName": "{CONTAINER-NAME}",
"settings": {}
},
"assets": {
"projectKind": "CustomEntityRecognition",
"entities": [
{
"category": "Entity1"
},
{
"category": "Entity2"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"entities": [
{
"regionOffset": 0,
"regionLength": 500,
"labels": [
{
"category": "Entity1",
"offset": 25,
"length": 10
},
{
"category": "Entity2",
"offset": 120,
"length": 8
}
]
}
]
},
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"entities": [
{
"regionOffset": 0,
"regionLength": 100,
"labels": [
{
"category": "Entity2",
"offset": 20,
"length": 5
}
]
}
]
}
]
}
}
| Nyckel | Platshållare | Värde | Exempel |
|---|---|---|---|
api-version |
{API-VERSION} |
Den version av API:et som du anropar. Den version som används här måste vara samma API-version i URL:en. Läs mer om andra tillgängliga API-versioner | 2022-03-01-preview |
projectName |
{PROJECT-NAME} |
Namnet på projektet. Det här värdet är skiftlägeskänsligt. | myProject |
projectKind |
CustomEntityRecognition |
Din projekttyp. | CustomEntityRecognition |
language |
{LANGUAGE-CODE} |
En sträng som anger språkkoden för de dokument som används i projektet. Om projektet är ett flerspråkigt projekt väljer du språkkoden för de flesta dokument. | en-us |
multilingual |
true |
Ett booleskt värde som gör att du kan ha dokument på flera språk i datauppsättningen och när din modell distribueras kan du fråga modellen på alla språk som stöds (inte nödvändigtvis i dina träningsdokument. Mer information om flerspråkig support finns i språkstöd . | true |
storageInputContainerName |
{CONTAINER-NAME} | Namnet på din Azure Storage-container som innehåller dina uppladdade dokument. | myContainer |
entities |
Matris som innehåller alla entitetstyper som du har i projektet och som extraherats från dina dokument. | ||
documents |
Matris som innehåller alla dokument i projektet och en lista över de entiteter som är märkta i varje dokument. | [] | |
location |
{DOCUMENT-NAME} |
Platsen för dokumenten i lagringscontainern. | doc1.txt |
dataset |
{DATASET} |
Testuppsättningen som denna fil går till när den delas upp innan träning. Mer information finns iTräna en modell. Möjliga värden för det här fältet är Train och Test. |
Train |
När du har skickat din API-begäran får du ett 202 svar som anger att jobbet har skickats korrekt. Extrahera operation-location-värdet från svarshuvudena. Här är ett exempel på formatet:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} används för att identifiera din begäran, eftersom den här åtgärden är asynkron. Du använder den här URL:en för att hämta status för importjobbet.
Möjliga felscenarier för den här begäran:
- Den valda resursen har inte rätt behörigheter för lagringskontot.
- Den
storageInputContainerNameangivna finns inte. - Ogiltig språkkod används, eller om språkkodtypen inte är sträng.
-
multilingualvärdet är en sträng och inte ett booleskt värde.
Hämta status för importjobb
Använd följande GET-begäran för att hämta statusen för din import av projektet. Ersätt platshållarvärdena med dina egna värden.
Begärans-URL
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
| Platshållare | Värde | Exempel |
|---|---|---|
{ENDPOINT} |
Slutpunkten för att autentisera din API-begäran. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Namnet på projektet. Det här värdet är skiftlägeskänsligt. | myProject |
{JOB-ID} |
ID:t för att hitta modellens träningsstatus. Det här värdet finns i det location rubrikvärde som du fick i föregående steg. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Den version av API:et som du anropar. Värdet som refereras är för den senaste versionen som släppts. Mer information finns iModelllivscykel. | 2022-05-01 |
Rubriker
Använd följande rubrik för att autentisera din begäran.
| Nyckel | Värde |
|---|---|
Ocp-Apim-Subscription-Key |
Nyckeln till resursen. Används för att autentisera dina API-begäranden. |
Träna din modell
När du har skapat ett projekt börjar du vanligtvis tagga de dokument som du har i containern som är ansluten till projektet. I den här snabbstarten importerade du en exempeltaggad datauppsättning och initierade projektet med JSON-exempeltaggarfilen.
Starta träningsjobbet
När projektet har importerats kan du börja träna din modell.
Skicka en POST-begäran med hjälp av följande URL, rubriker och JSON-brödtext för att skicka ett träningsjobb. Ersätt platshållarvärdena med dina egna värden.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/:train?api-version={API-VERSION}
| Platshållare | Värde | Exempel |
|---|---|---|
{ENDPOINT} |
Slutpunkten för att autentisera din API-begäran. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Namnet på projektet. Det här värdet är skiftlägeskänsligt. | myProject |
{API-VERSION} |
Den version av API:et som du anropar. Värdet som refereras är för den senaste versionen som släppts. Mer information finns iModelllivscykel. | 2022-05-01 |
Rubriker
Använd följande rubrik för att autentisera din begäran.
| Nyckel | Värde |
|---|---|
Ocp-Apim-Subscription-Key |
Nyckeln till resursen. Används för att autentisera dina API-begäranden. |
Begärandetext
Använd följande JSON i begärandetexten. Modellen ges som {MODEL-NAME} när träningen är klar. Endast lyckade träningsjobb skapar modeller.
{
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"evaluationOptions": {
"kind": "percentage",
"trainingSplitPercentage": 80,
"testingSplitPercentage": 20
}
}
| Nyckel | Platshållare | Värde | Exempel |
|---|---|---|---|
| modelLabel | {MODEL-NAME} |
Det modellnamn som tilldelas din modell när den tränats framgångsrikt. | myModel |
| Träningskonfigurationsversion | {CONFIG-VERSION} |
Det här är den modellversion som används för att träna modellen. | 2022-05-01 |
| utvärderingsalternativ | Alternativ för att dela upp dina data mellan tränings- och testuppsättningar. | {} |
|
| typ | percentage |
Dela upp metoder. Möjliga värden är percentage eller manual. Mer information finns iTräna en modell. |
percentage |
| procentuell träningdelning | 80 |
Procentandel av dina taggade data som ska ingå i träningsuppsättningen. Rekommenderat värde är 80. |
80 |
| testdelningsprocent | 20 |
Procentandel av dina taggade data som ska ingå i testuppsättningen. Rekommenderat värde är 20. |
20 |
Kommentar
Och trainingSplitPercentagetestingSplitPercentage krävs endast om Kind anges till percentage och summan av båda procentandelarna ska vara lika med 100.
När du har skickat din API-begäran får du ett 202 svar som anger att jobbet har skickats korrekt. I svarshuvudena extraherar du värdet location formaterat så här:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} används för att identifiera din begäran, eftersom den här åtgärden är asynkron. Du kan använda den här URL:en för att hämta träningsstatusen.
Hämta status för träningsjobb
Träningen kan ta mellan 10 och 30 minuter för den här exempeldatamängden. Du kan använda följande begäran för att fortsätta kontrollera statusen för träningsjobbet tills det har slutförts framgångsrikt.
Använd följande GET-begäran för att få status för din modells träningsförlopp. Ersätt platshållarvärdena med dina egna värden.
Begärans-URL
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
| Platshållare | Värde | Exempel |
|---|---|---|
{ENDPOINT} |
Slutpunkten för att autentisera din API-begäran. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Namnet på projektet. Det här värdet är skiftlägeskänsligt. | myProject |
{JOB-ID} |
ID:t för att hitta modellens träningsstatus. Det här värdet finns i det location rubrikvärde som du fick i föregående steg. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Den version av API:et som du anropar. Värdet som refereras är för den senaste versionen som släppts. Mer information finns iModelllivscykel. | 2022-05-01 |
Rubriker
Använd följande rubrik för att autentisera din begäran.
| Nyckel | Värde |
|---|---|
Ocp-Apim-Subscription-Key |
Nyckeln till resursen. Används för att autentisera dina API-begäranden. |
Svarstext
När du har skickat begäran får du följande svar.
{
"result": {
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"estimatedEndDateTime": "2022-04-18T15:47:58.8190649Z",
"trainingStatus": {
"percentComplete": 3,
"startDateTime": "2022-04-18T15:45:06.8190649Z",
"status": "running"
},
"evaluationStatus": {
"percentComplete": 0,
"status": "notStarted"
}
},
"jobId": "{JOB-ID}",
"createdDateTime": "2022-04-18T15:44:44Z",
"lastUpdatedDateTime": "2022-04-18T15:45:48Z",
"expirationDateTime": "2022-04-25T15:44:44Z",
"status": "running"
}
Distribuera din modell
När du har tränat en modell kan du granska dess utvärderingsinformation och göra förbättringar om det behövs. I den här snabbstarten distribuerar du bara din modell och gör den tillgänglig för dig att prova i Language Studio, eller så kan du anropa förutsägelse-API:et.
Starta distributionsjobbet
Skicka en PUT-begäran med hjälp av följande URL, rubriker och JSON-brödtext för att skicka ett distributionsjobb. Ersätt platshållarvärdena med dina egna värden.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/deployments/{deploymentName}?api-version={API-VERSION}
| Platshållare | Värde | Exempel |
|---|---|---|
{ENDPOINT} |
Slutpunkten för att autentisera din API-begäran. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Namnet på projektet. Det här värdet är skiftlägeskänsligt. | myProject |
{DEPLOYMENT-NAME} |
Namnet på din distribution. Det här värdet är skiftlägeskänsligt. | staging |
{API-VERSION} |
Den version av API:et som du anropar. Värdet som refereras är för den senaste versionen som släppts. Mer information finns iModelllivscykel. | 2022-05-01 |
Rubriker
Använd följande rubrik för att autentisera din begäran.
| Nyckel | Värde |
|---|---|
Ocp-Apim-Subscription-Key |
Nyckeln till resursen. Används för att autentisera dina API-begäranden. |
Begärandetext
Använd följande JSON i brödtexten i din begäran. Använd namnet på den modell som du tilldelar distributionen.
{
"trainedModelLabel": "{MODEL-NAME}"
}
| Nyckel | Platshållare | Värde | Exempel |
|---|---|---|---|
| trainedModelLabel | {MODEL-NAME} |
Modellnamnet som har tilldelats din distribution. Du kan bara tilldela modeller som tränats. Det här värdet är skiftlägeskänsligt. | myModel |
När du har skickat din API-begäran får du ett 202 svar som anger att jobbet har skickats korrekt. I svarshuvudena extraherar du värdet operation-location formaterat så här:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} används för att identifiera din begäran, eftersom den här åtgärden är asynkron. Du kan använda den här URL:en för att hämta distributionsstatusen.
Hämta status för distributionsjobb
Använd följande GET-begäran för att fråga efter status för distributionsjobbet. Du kan använda den URL som du fick från föregående steg eller ersätta platshållarvärdena med dina egna värden.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
| Platshållare | Värde | Exempel |
|---|---|---|
{ENDPOINT} |
Slutpunkten för att autentisera din API-begäran. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Namnet på projektet. Det här värdet är skiftlägeskänsligt. | myProject |
{DEPLOYMENT-NAME} |
Namnet på din distribution. Det här värdet är skiftlägeskänsligt. | staging |
{JOB-ID} |
ID:t för att hitta modellens träningsstatus. Det finns i det location rubrikvärde som du fick i föregående steg. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Den version av API:et som du anropar. Värdet som refereras är för den senaste versionen som släppts. Mer information finns iModelllivscykel. | 2022-05-01 |
Rubriker
Använd följande rubrik för att autentisera din begäran.
| Nyckel | Värde |
|---|---|
Ocp-Apim-Subscription-Key |
Nyckeln till resursen. Används för att autentisera dina API-begäranden. |
Svarstext
När du har skickat begäran får du följande svar. Fortsätt att avsöka den här slutpunkten tills statusparametern ändras till "lyckades". Du bör få en 200 kod som anger att begäran har slutförts.
{
"jobId":"{JOB-ID}",
"createdDateTime":"{CREATED-TIME}",
"lastUpdatedDateTime":"{UPDATED-TIME}",
"expirationDateTime":"{EXPIRATION-TIME}",
"status":"running"
}
Extrahera anpassade entiteter
När din modell har distribuerats kan du börja använda den för att extrahera entiteter från din text med hjälp av förutsägelse-API:et. I exempeldatauppsättningen, som laddades ned tidigare, hittar du några testdokument som du kan använda i det här steget.
Skicka en anpassad NER-uppgift
Använd den här POST-begäran för att starta en textklassificeringsuppgift.
{ENDPOINT}/language/analyze-text/jobs?api-version={API-VERSION}
| Platshållare | Värde | Exempel |
|---|---|---|
{ENDPOINT} |
Slutpunkten för att autentisera din API-begäran. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
Den version av API:et som du anropar. Värdet som refereras är för den senaste versionen som släppts. Mer information finns iModelllivscykel. | 2022-05-01 |
Rubriker
| Nyckel | Värde |
|---|---|
| Ocp-Apim-Subscription-Key | Din nyckel som ger åtkomst till det här API:et. |
Kropp
{
"displayName": "Extracting entities",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "{LANGUAGE-CODE}",
"text": "Text1"
},
{
"id": "2",
"language": "{LANGUAGE-CODE}",
"text": "Text2"
}
]
},
"tasks": [
{
"kind": "CustomEntityRecognition",
"taskName": "Entity Recognition",
"parameters": {
"projectName": "{PROJECT-NAME}",
"deploymentName": "{DEPLOYMENT-NAME}"
}
}
]
}
| Nyckel | Platshållare | Värde | Exempel |
|---|---|---|---|
displayName |
{JOB-NAME} |
Ditt jobbnamn. | MyJobName |
documents |
[{},{}] | Lista över dokument som aktiviteter ska köras på. | [{},{}] |
id |
{DOC-ID} |
Dokumentnamn eller ID. | doc1 |
language |
{LANGUAGE-CODE} |
En sträng som anger språkkoden för dokumentet. Om den här nyckeln inte anges förutsätter tjänsten standardspråket för projektet som valdes när projektet skapades. Se språkstöd för en lista över språkkoder som stöds. | en-us |
text |
{DOC-TEXT} |
Dokumentuppgift som aktiviteterna ska köras på. | Lorem ipsum dolor sit amet |
tasks |
Lista över uppgifter som vi vill utföra. | [] |
|
taskName |
CustomEntityRecognition |
Uppgiftsnamnet | Anpassad Entity-igenkänning |
parameters |
Lista över parametrar som ska skickas till uppgiften. | ||
project-name |
{PROJECT-NAME} |
Namnet på projektet. Det här värdet är skiftlägeskänsligt. | myProject |
deployment-name |
{DEPLOYMENT-NAME} |
Namnet på din distribution. Det här värdet är skiftlägeskänsligt. | prod |
Svar
Du får ett svar med statuskod 202 som anger att din uppgift har skickats framgångsrikt. I svarshuvudena extraherar du operation-location.
operation-location är formaterad så här:
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
Du kan använda den här URL:en för att fråga efter uppgiftens slutförandestatus och få resultatet när aktiviteten har slutförts.
Hämta aktivitetsresultat
Använd följande GET-begäran för att fråga efter status/resultat för den anpassade entitetsigenkänningsaktiviteten.
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
| Platshållare | Värde | Exempel |
|---|---|---|
{ENDPOINT} |
Slutpunkten för att autentisera din API-begäran. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
Den version av API:et som du anropar. Värdet som refereras är för den senaste versionen som släppts. Mer information finns iModelllivscykel. | 2022-05-01 |
Rubriker
| Nyckel | Värde |
|---|---|
| Ocp-Apim-Subscription-Key | Din nyckel som ger åtkomst till det här API:et. |
Svarstext
Svaret blir ett JSON-dokument med följande parametrar
{
"createdDateTime": "2021-05-19T14:32:25.578Z",
"displayName": "MyJobName",
"expirationDateTime": "2021-05-19T14:32:25.578Z",
"jobId": "xxxx-xxxx-xxxxx-xxxxx",
"lastUpdateDateTime": "2021-05-19T14:32:25.578Z",
"status": "succeeded",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "EntityRecognitionLROResults",
"taskName": "Recognize Entities",
"lastUpdateDateTime": "2020-10-01T15:01:03Z",
"status": "succeeded",
"results": {
"documents": [
{
"entities": [
{
"category": "Event",
"confidenceScore": 0.61,
"length": 4,
"offset": 18,
"text": "trip"
},
{
"category": "Location",
"confidenceScore": 0.82,
"length": 7,
"offset": 26,
"subcategory": "GPE",
"text": "Seattle"
},
{
"category": "DateTime",
"confidenceScore": 0.8,
"length": 9,
"offset": 34,
"subcategory": "DateRange",
"text": "last week"
}
],
"id": "1",
"warnings": []
}
],
"errors": [],
"modelVersion": "2020-04-01"
}
}
]
}
}
Rensa resurser
När du inte längre behöver projektet kan du ta bort det med följande DELETE-begäran . Ersätt platshållarvärdena med dina egna värden.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}?api-version={API-VERSION}
| Platshållare | Värde | Exempel |
|---|---|---|
{ENDPOINT} |
Slutpunkten för att autentisera din API-begäran. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Namnet på projektet. Det här värdet är skiftlägeskänsligt. | myProject |
{API-VERSION} |
Den version av API:et som du anropar. Värdet som refereras är för den senaste versionen som släppts. Mer information finns iModelllivscykel. | 2022-05-01 |
Rubriker
Använd följande rubrik för att autentisera din begäran.
| Nyckel | Värde |
|---|---|
| Ocp-Apim-Subscription-Key | Nyckeln till resursen. Används för att autentisera dina API-begäranden. |
När du har skickat din API-begäran får du ett 202 svar som anger att projektet har slutförts, vilket innebär att projektet tas bort. Ett lyckat anrop resulterar med en rubrik för Åtgärd-plats som används för att kontrollera jobbets status.
Relaterat innehåll
När du har skapat entitetsextraheringsmodellen kan du använda körnings-API:et för att extrahera entiteter.
När du skapar egna anpassade NER-projekt använder du våra instruktionsartiklar för att lära dig mer om taggning, träning och användning av din modell i detalj: