Not
Åtkomst till denna sida kräver auktorisation. Du kan prova att logga in eller byta katalog.
Åtkomst till denna sida kräver auktorisation. Du kan prova att byta katalog.
Använd den här artikeln om du vill lära dig hur du konfigurerar kraven för att börja med anpassad textklassificering och skapa ett projekt.
Förutsättningar
Innan du börjar använda anpassad textklassificering behöver du:
- En Azure-prenumeration – Skapa en kostnadsfritt.
Skapa en språkresurs
Innan du börjar använda anpassad textklassificering behöver du en Azure Language in Foundry Tools-resurs. Vi rekommenderar att du skapar språkresursen och ansluter ett lagringskonto till den i Azure-portalen. När du skapar en resurs i Azure-portalen kan du skapa ett Azure-lagringskonto samtidigt med alla nödvändiga behörigheter förkonfigurerade. Du kan också läsa mer i artikeln om du vill lära dig hur du använder en befintlig resurs och konfigurerar den så att den fungerar med anpassad textklassificering.
Du behöver också ett Azure Storage-konto där du kan ladda upp dokument .txt som används för att träna en modell för att klassificera text.
Kommentar
- Du måste ha en ägarroll tilldelad till resursgruppen för att skapa en språkresurs.
- Om du ansluter ett befintligt lagringskonto bör en ägarroll vara tilldelad till det.
Skapa språkresurs och ansluta lagringskonto
Kommentar
Du bör inte flytta lagringskontot till en annan resursgrupp eller prenumeration när det är länkat till Azure Language-resursen.
Skapa en ny resurs från Azure Portal
Gå till Azure-portalen för att skapa en ny Azure Language in Foundry Tools-resurs.
I fönstret som visas väljer du Anpassad textklassificering och anpassad namngiven entitetsigenkänning från de anpassade funktionerna. Välj Fortsätt för att skapa resursen längst ned på skärmen.
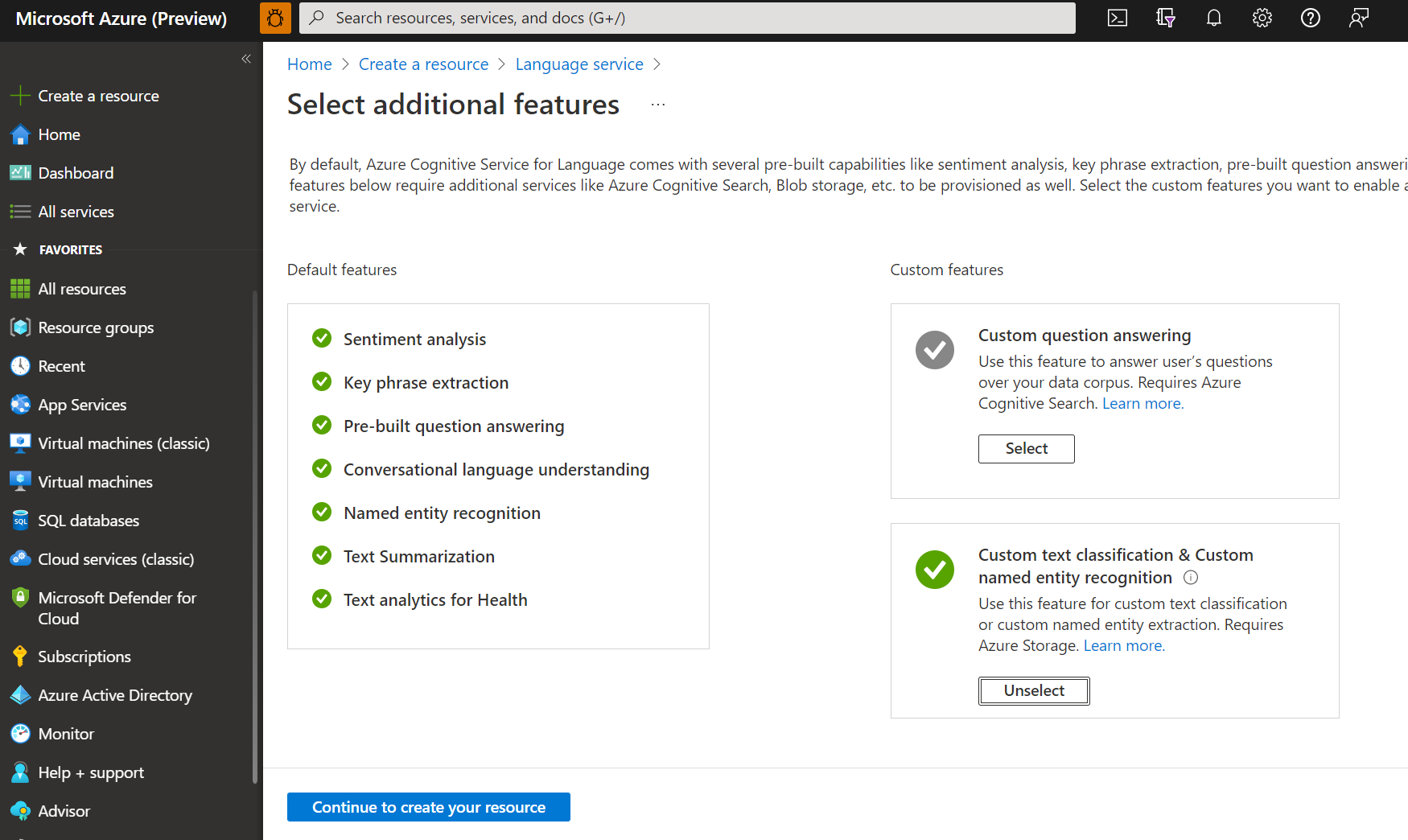
Skapa en språkresurs med följande information.
Name Obligatoriskt värde Prenumeration Din Azure-prenumeration. Resursgrupp En resursgrupp som ska innehålla din resurs. Du kan använda en befintlig eller skapa en ny. Region En av de regioner som stöds. Till exempel "USA, västra 2". Name Ett namn på resursen. Prisnivå En av de prisnivåer som stöds. Du kan använda nivån Kostnadsfri (F0) för att prova tjänsten. Om du får ett meddelande om att ditt inloggningskonto inte är ägare till det valda lagringskontots resursgrupp måste ditt konto ha en ägarroll tilldelad till resursgruppen innan du kan skapa en Språkresurs. Kontakta din Azure-prenumerationsägare om du vill ha hjälp.
Du kan fastställa din Azure-prenumerationsägare genom att söka i resursgruppen och följa länken till den associerade prenumerationen. Sedan:
- Välj fliken Åtkomstkontroll (IAM)
- Välj Rolltilldelningar
- Filtrera efter roll:Ägare.
I avsnittet Anpassad textklassificering och anpassad namngiven entitetsigenkänning väljer du ett befintligt lagringskonto eller väljer Nytt lagringskonto. Observera att dessa värden hjälper dig att komma igång och inte nödvändigtvis de lagringskontovärden som du vill använda i produktionsmiljöer. Undvik svarstider när du skapar projektet genom att ansluta till lagringskonton i samma region som språkresursen.
Lagringskontovärde Rekommenderat värde Lagringskontonamn Valfritt namn Typ av lagringskonto Standard LRS Kontrollera att meddelandet om ansvarsfull AI är markerat. Välj Granska + skapa längst ned på sidan.

Kommentar
- Processen för att ansluta ett lagringskonto till språkresursen kan inte ångras – den kan inte kopplas från senare.
- Du kan bara ansluta språkresursen till ett lagringskonto.
Använda en befintlig språkresurs
| Krav | Beskrivning |
|---|---|
| Regioner | Kontrollera att din befintliga resurs har etablerats i en av de regioner som stöds. Om du inte har en resurs måste du skapa en ny i en region som stöds. |
| Prisnivå | Prisnivån för din resurs. |
| Hanterad identitet | Kontrollera att resursens inställning för hanterad identitet är aktiverad. Annars läser du nästa avsnitt. |
Om du vill använda anpassad textklassificering måste du skapa ett Azure Storage-konto om du inte redan har ett.
Aktivera identitetshantering för din resurs
Språkresursen måste ha identitetshantering för att aktivera den med hjälp av Azure Portal:
- Gå till språkresursen
- I den vänstra menyn går du till avsnittet Resurshantering och väljer Identitet
- Från fliken Systemtilldelat ser du till att ange Status till På
Aktivera anpassad textklassificeringsfunktion
Se till att aktivera funktionen Anpassad textklassificering/anpassad namngiven entitetsigenkänning från Azure Portal.
- Gå till språkresursen i Azure Portal
- På menyn till vänster går du till avsnittet Resurshantering och väljer Funktioner
- Aktivera anpassad textklassificering/funktion för anpassad namngiven entitetsigenkänning
- Ansluta ditt lagringskonto
- Välj Använd
Viktigt!
- Kontrollera att språkresursen har tilldelats rollen som deltagare i lagringsblobdata på det lagringskonto som du ansluter.
Ange roller för din Azure Language-resurs och ditt lagringskonto
Använd följande steg för att ange de roller som krävs för språkresursen och lagringskontot.

Roller för azure-språket i Foundry Tools-resursen
Gå till lagringskontot eller språkresursen i Azure Portal.
Välj Åtkomstkontroll (IAM) i den vänstra rutan.
Välj Lägg till för att lägga till rolltilldelningar och välj lämplig roll för ditt konto.
Du bör ha rollen ägare eller deltagare tilldelad till språkresursen.
I Tilldela åtkomst till väljer du Användare, grupp eller tjänstens huvudnamn
Välj Välj medlemmar
Välj ditt användarnamn. Du kan söka efter användarnamn i fältet Välj . Upprepa detta för alla roller.
Upprepa de här stegen för alla användarkonton som behöver åtkomst till den här resursen.
Roller för ditt lagringskonto
- Gå till lagringskontosidan i Azure Portal.
- Välj Åtkomstkontroll (IAM) i den vänstra rutan.
- Välj Lägg till för att lägga till rolltilldelningar och välj rollen Lagringsblobdatadeltagare för lagringskontot.
- I Tilldela åtkomst till väljer du Hanterad identitet.
- Välj Välj medlemmar
- Välj din prenumeration och Språk som hanterad identitet. Du kan söka efter användarnamn i fältet Välj .
Viktigt!
Om du har ett virtuellt nätverk eller en privat slutpunkt måste du välja Tillåt att Azure-tjänster i listan över betrodda tjänster får åtkomst till det här lagringskontot i Azure Portal.
Aktivera CORS för ditt lagringskonto
Se till att tillåta metoder (GET, PUT, DELETE) när du aktiverar CORS (Cross-Origin Resource Sharing).
Ange fältet tillåtet ursprung till https://language.cognitive.azure.com. Tillåt alla sidhuvuden genom att lägga * till i de tillåtna rubrikvärdena och ange den maximala åldern till 500.

Skapa ett anpassat textklassificeringsprojekt (REST API)
När resursen och lagringscontainern har konfigurerats skapar du ett nytt anpassat textklassificeringsprojekt. Ett projekt är ett arbetsområde för att skapa anpassade AI-modeller baserat på dina data. Ditt projekt är bara tillgängligt för dig och andra som har åtkomst till den Azure-resurs som används. Om du har märkt data kan du importera dem för att komma igång.
Om du vill börja skapa en anpassad textklassificeringsmodell måste du skapa ett projekt. När du skapar ett projekt kan du märka data, träna, utvärdera, förbättra och distribuera dina modeller.
Kommentar
Projektnamnet är skiftlägeskänsligt för alla åtgärder.
Skapa en PATCH-begäran med hjälp av följande URL, rubriker och JSON-brödtext för att skapa projektet.
Begärans-URL
Använd följande URL för att skapa ett projekt. Ersätt platshållarvärdena med dina egna värden.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}?api-version={API-VERSION}
| Platshållare | Värde | Exempel |
|---|---|---|
{ENDPOINT} |
Slutpunkten för att autentisera din API-begäran. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Namnet på projektet. Det här värdet är skiftlägeskänsligt. | myProject |
{API-VERSION} |
Den version av API:et som du anropar. Värdet som refereras är för den senaste versionen som släppts. Mer information om andra tillgängliga API-versioner finns i Modelllivscykel . | 2022-05-01 |
Sidhuvuden
Använd följande rubrik för att autentisera din begäran.
| Tangent | Värde |
|---|---|
Ocp-Apim-Subscription-Key |
Nyckeln till resursen. Används för att autentisera dina API-begäranden. |
Brödtext
Använd följande JSON i din begäran. Ersätt platshållarvärdena med dina egna värden.
{
"projectName": "{PROJECT-NAME}",
"language": "{LANGUAGE-CODE}",
"projectKind": "customMultiLabelClassification",
"description": "Project description",
"multilingual": "True",
"storageInputContainerName": "{CONTAINER-NAME}"
}
| Tangent | Platshållare | Värde | Exempel |
|---|---|---|---|
| projektnamn | {PROJECT-NAME} |
Namnet på projektet. Det här värdet är skiftlägeskänsligt. | myProject |
| språk | {LANGUAGE-CODE} |
En sträng som anger språkkoden för de dokument som används i projektet. Om projektet är ett flerspråkigt projekt väljer du språkkoden för de flesta dokument. Mer information om språkkoder som stöds finns i språkstöd . | en-us |
| projectKind | customMultiLabelClassification |
Din projekttyp. | customMultiLabelClassification |
| flerspråkig | true |
Ett booleskt värde som gör att du kan ha dokument på flera språk i datauppsättningen och när din modell distribueras kan du fråga modellen på alla språk som stöds (inte nödvändigtvis i dina träningsdokument. Mer information om flerspråkig support finns i språkstöd . | true |
| storageInputContainerName | {CONTAINER-NAME} |
Namnet på din Azure Storage-container för dina uppladdade dokument. | myContainer |
Den här begäran returnerar ett 201-svar, vilket innebär att projektet skapas.
Den här begäran returnerar ett fel om:
- Den valda resursen har inte rätt behörighet för lagringskontot.
Importera ett anpassat textklassificeringsprojekt (REST API)
Om du redan har etiketterat data kan du använda dem för att komma igång med tjänsten. Kontrollera att dina etiketterade data följer de godkända dataformaten.
Skicka en POST-begäran med hjälp av följande URL, rubriker och JSON-brödtext för att importera din etikettfil. Kontrollera att din etikettfil följer det godkända formatet.
Om det redan finns ett projekt med samma namn ersätts data för projektet.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/:import?api-version={API-VERSION}
| Platshållare | Värde | Exempel |
|---|---|---|
{ENDPOINT} |
Slutpunkten för att autentisera din API-begäran. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Namnet på projektet. Det här värdet är skiftlägeskänsligt. | myProject |
{API-VERSION} |
Den version av API:et som du anropar. Värdet som refereras är för den senaste versionen som släppts. Läs mer om andra tillgängliga API-versioner | 2022-05-01 |
Sidhuvuden
Använd följande rubrik för att autentisera din begäran.
| Tangent | Värde |
|---|---|
Ocp-Apim-Subscription-Key |
Nyckeln till resursen. Används för att autentisera dina API-begäranden. |
Brödtext
Använd följande JSON i din begäran. Ersätt platshållarvärdena med dina egna värden.
{
"projectFileVersion": "{API-VERSION}",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectName": "{PROJECT-NAME}",
"storageInputContainerName": "{CONTAINER-NAME}",
"projectKind": "customMultiLabelClassification",
"description": "Trying out custom multi label text classification",
"language": "{LANGUAGE-CODE}",
"multilingual": true,
"settings": {}
},
"assets": {
"projectKind": "customMultiLabelClassification",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
]
},
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class2"
}
]
}
]
}
}
| Tangent | Platshållare | Värde | Exempel |
|---|---|---|---|
| api-version | {API-VERSION} |
Den version av API:et som du anropar. Den version som används här måste vara samma API-version i URL:en. Läs mer om andra tillgängliga API-versioner | 2022-05-01 |
| projektnamn | {PROJECT-NAME} |
Namnet på projektet. Det här värdet är skiftlägeskänsligt. | myProject |
| projectKind | customMultiLabelClassification |
Din projekttyp. | customMultiLabelClassification |
| språk | {LANGUAGE-CODE} |
En sträng som anger språkkoden för de dokument som används i projektet. Om projektet är ett flerspråkigt projekt väljer du språkkoden för de flesta dokumenten. Mer information om flerspråkig support finns i språkstöd . | en-us |
| flerspråkig | true |
Ett booleskt värde som gör att du kan ha dokument på flera språk i datauppsättningen och när din modell distribueras kan du fråga modellen på alla språk som stöds (inte nödvändigtvis i dina träningsdokument. Mer information om flerspråkig support finns i språkstöd . | true |
| storageInputContainerName | {CONTAINER-NAME} |
Namnet på din Azure Storage-container för dina uppladdade dokument. | myContainer |
| klasser | [] | Matris som innehåller alla klasser som du har i projektet. | [] |
| documents | [] | Matris som innehåller alla dokument i projektet och vilka klasser som är märkta för det här dokumentet. | [] |
| plats | {DOCUMENT-NAME} |
Platsen för dokumenten i lagringscontainern. Eftersom alla dokument finns i containerns rot bör det vara dokumentnamnet. | doc1.txt |
| datauppsättning | {DATASET} |
Testuppsättningen som det här dokumentet tillhör när det delas upp före träningsfasen. Se Hur man tränar en modell. Möjliga värden för det här fältet är Train och Test. |
Train |
När du har skickat din API-begäran får du ett 202 svar som anger att jobbet har skickats korrekt. I svarshuvudena extraherar du värdet operation-location formaterat så här:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} används för att identifiera din begäran, eftersom den här åtgärden är asynkron. Du använder den här URL:en för att hämta status för importjobbet.
Möjliga felscenarier för den här begäran:
- Den valda resursen har inte rätt behörigheter för lagringskontot.
- Den
storageInputContainerNameangivna finns inte. - Ogiltig språkkod används, eller om språkkodtypen inte är sträng.
-
multilingualvärdet är en sträng och inte ett booleskt värde.
Hämta projektinformation (REST API)
Om du vill få information om projektinformation för anpassad textklassificering skickar du en GET-begäran med hjälp av följande URL och rubriker. Ersätt platshållarvärdena med dina egna värden.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}?api-version={API-VERSION}
| Platshållare | Värde | Exempel |
|---|---|---|
{ENDPOINT} |
Slutpunkten för att autentisera din API-begäran. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Namnet på projektet. Det här värdet är skiftlägeskänsligt. | myProject |
{API-VERSION} |
Den version av API:et som du anropar. Värdet som refereras är för den senaste versionen av modellen. | 2022-05-01 |
Sidhuvuden
Använd följande rubrik för att autentisera din begäran.
| Tangent | Värde |
|---|---|
Ocp-Apim-Subscription-Key |
Nyckeln till resursen. Används för att autentisera dina API-begäranden. |
Svarstext
När du har skickat begäran får du följande svar.
{
"createdDateTime": "2022-04-23T13:39:09.384Z",
"lastModifiedDateTime": "2022-04-23T13:39:09.384Z",
"lastTrainedDateTime": "2022-04-23T13:39:09.384Z",
"lastDeployedDateTime": "2022-04-23T13:39:09.384Z",
"projectKind": "customSingleLabelClassification",
"storageInputContainerName": "{CONTAINER-NAME}",
"projectName": "{PROJECT-NAME}",
"multilingual": true,
"description": "Project description",
"language": "{LANGUAGE-CODE}"
}
| Värde | platshållare | Beskrivning | Exempel |
|---|---|---|---|
projectKind |
customSingleLabelClassification |
Din projekttyp. | Det här värdet kan vara customSingleLabelClassification eller customMultiLabelClassification. |
storageInputContainerName |
{CONTAINER-NAME} |
Namnet på din Azure Storage-container för dina uppladdade dokument. | myContainer |
projectName |
{PROJECT-NAME} |
Namnet på projektet. Det här värdet är skiftlägeskänsligt. | myProject |
multilingual |
Ett booleskt värde som gör att du kan ha dokument på flera språk i datauppsättningen. När din modell har distribuerats kan du fråga modellen på valfritt språk som stöds (inte nödvändigtvis i dina träningsdokument. Mer information om flerspråkigt stöd finns i språkstöd. | true |
|
language |
{LANGUAGE-CODE} |
En sträng som anger språkkoden för de dokument som används i projektet. Om projektet är ett flerspråkigt projekt väljer du språkkoden för de flesta dokumenten. Mer information om språkkoder som stöds finns i språkstöd . | en-us |
När du har skickat din API-begäran får du ett 200 svar som anger att det lyckades och en JSON-svarsstruktur med dina projektuppgifter.
Ta bort projekt (REST API)
När du inte längre behöver projektet kan du ta bort det med följande DELETE-begäran . Ersätt platshållarvärdena med dina egna värden.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}?api-version={API-VERSION}
| Platshållare | Värde | Exempel |
|---|---|---|
{ENDPOINT} |
Slutpunkten för att autentisera din API-begäran. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Namnet på projektet. Det här värdet är skiftlägeskänsligt. | myProject |
{API-VERSION} |
Den version av API:et som du anropar. Värdet som refereras är för den senaste versionen som släppts. Läs mer om andra tillgängliga API-versioner | 2022-05-01 |
Sidhuvuden
Använd följande rubrik för att autentisera din begäran.
| Tangent | Värde |
|---|---|
| Ocp-Apim-Subscription-Key | Nyckeln till resursen. Används för att autentisera dina API-begäranden. |
När du har skickat din API-begäran får du ett 202 svar som anger att projektet har slutförts, vilket innebär att projektet tas bort. Ett lyckat anrop resulterar i ett Operation-Location huvud som används för att kontrollera jobbets status.
Nästa steg
Du bör planera det projektschema som används för att märka dina data.
När projektet har skapats kan du börja märka dina data. Etikettering informerar din textklassificeringsmodell om hur text tolkas och används för träning och utvärdering.