Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Viktigt!
- Offentliga förhandsversioner av Azure AI Language ger tidig åtkomst till funktioner som är i aktiv utveckling.
- Funktioner, metoder och processer kan ändras, före allmän tillgänglighet (GA), baserat på användarfeedback.
Azure AI Language är en molnbaserad tjänst som tillämpar NLP-funktioner (Natural Language Processing) på textbaserade data. Dokumentsammanfattningar använder naturlig språkbehandling för att generera extraktiva sammanfattningar (viktig meningsextraktion) eller abstrakta sammanfattningar (sammanfattning med kontextuell ordextraktion) för dokument. Både AbstractiveSummarization API:er och ExtractiveSummarization har stöd för intern dokumentbearbetning. Ett internt dokument refererar till det filformat som används för att skapa det ursprungliga dokumentet, till exempel Microsoft Word (docx) eller en bärbar dokumentfil (pdf). Stöd för inbyggt dokument eliminerar behovet av förbearbetning av text innan du använder Resursfunktioner för Azure AI Language. Med den inbyggda dokumentsupportfunktionen kan du skicka API-begäranden asynkront med hjälp av en HTTP POST-begärandetext för att skicka dina data och HTTP GET-frågesträngen för att hämta statusresultatet. Dina bearbetade dokument finns i din Azure Blob Storage-målcontainer.
Dokumentformat som stöds
Program använder inbyggda filformat för att skapa, spara eller öppna interna dokument. Funktionerna för PII- och dokumentsammanfattning stöder för närvarande följande interna dokumentformat:
| Filtyp | Filnamnstillägg | beskrivning |
|---|---|---|
| Text | .txt |
Ett oformaterat textdokument. |
| Adobe PDF | .pdf |
Ett dokument i portabelt dokumentfilformat. |
| Microsoft Word | .docx |
Ett Microsoft Word-dokument. |
Riktlinjer för indata
Filformat som stöds
| Typ | support och begränsningar |
|---|---|
| PDF-filer | Fullständigt skannade PDF-filer stöds inte. |
| Text i bilder | Digitala bilder med inbäddad text stöds inte. |
| Digitala tabeller | Tabeller i skannade dokument stöds inte. |
Dokumentstorlek
| Attribut | Indatagräns |
|---|---|
| Totalt antal dokument per begäran | ≤ 20 |
| Total innehållsstorlek per begäran | ≤ 10 MB |
Inkludera interna dokument med en HTTP-begäran
Nu ska vi komma igång:
För det här projektet använder vi kommandoradsverktyget cURL för att göra REST API-anrop.
Anmärkning
cURL-paketet är förinstallerat på de flesta Windows 10- och Windows 11-distributioner och de flesta macOS- och Linux-distributioner. Du kan kontrollera paketversionen med följande kommandon: Windows:
curl.exe -VmacOScurl -VLinux:curl --versionOm cURL inte är installerat finns här installationslänkar för din plattform:
Ett aktivt Azure-konto. Om du inte har någon, kan du skapa ett kostnadsfritt konto.
Ett Azure Blob Storage-konto. Du måste också skapa containrar i ditt Azure Blob Storage-konto för dina käll- och målfiler:
- Källcontainer. I den här containern laddar du upp dina interna filer för analys (krävs).
- Destinationsbehållare. I den här containern lagras dina analyserade filer (krävs).
En språkresurs med en enda tjänst (inte en Azure AI Foundry-resurs med flera tjänster):
Fyll i fälten Språkresursprojekt och instansinformation på följande sätt:
Prenumeration. Välj en av dina tillgängliga Azure-prenumerationer.
Resursgrupp. Du kan skapa en ny resursgrupp eller lägga till resursen i en befintlig resursgrupp som delar samma livscykel, behörigheter och principer.
Resursregion. Välj Global om inte ditt företag eller program kräver en viss region. Om du planerar att använda en systemtilldelad hanterad identitet för autentisering väljer du en geografisk region som USA, västra.
Namn. Ange det namn som du valde för resursen. Namnet du väljer måste vara unikt i Azure.
Prisnivå. Du kan använda den kostnadsfria prisnivån (
Free F0) för att prova tjänsten och uppgradera senare till en betald nivå för produktion.Välj Översikt + skapa.
Granska tjänstvillkoren och välj Skapa för att distribuera resursen.
När resursen har distribuerats väljer du Gå till resurs.
Hämta din nyckel och språktjänstslutpunkt
Begäranden till språktjänsten kräver en skrivskyddad nyckel och en anpassad slutpunkt för att autentisera åtkomsten.
Om du har skapat en ny resurs väljer du Gå till resurs när den har distribuerats. Om du har en befintlig språktjänstresurs går du direkt till resurssidan.
Välj Nycklar och slutpunkt under Resurshantering i det vänstra spåret.
Du kan kopiera och klistra in din
keyoch dinlanguage service instance endpointi kodexemplen för att autentisera din begäran till språktjänsten. Endast en nyckel krävs för att göra ett API-anrop.
Skapa Azure Blob Storage-containrar
Skapa containrar i ditt Azure Blob Storage-konto för käll- och målfiler.
- Källcontainer. I den här containern laddar du upp dina interna filer för analys (krävs).
- Destinationsbehållare. I den här containern lagras dina analyserade filer (krävs).
autentisering
Språkresursen måste beviljas åtkomst till ditt lagringskonto innan den kan skapa, läsa eller ta bort blobar. Det finns två primära metoder som du kan använda för att bevilja åtkomst till dina lagringsdata:
SAS-token (Signatur för delad åtkomst). SAS-token för användardelegering skyddas med Microsoft Entra-autentiseringsuppgifter. SAS-token ger säker, delegerad åtkomst till resurser i ditt Azure Storage-konto.
Rollbaserad åtkomstkontroll (RBAC) för hanterade identiteter. Hanterade identiteter för Azure-resurser är tjänstens huvudnamn som skapar en Microsoft Entra-identitet och specifika behörigheter för Azure-hanterade resurser.
För det här projektet autentiserar vi åtkomst till source location och target location URL:er med SAS-token (Signatur för delad åtkomst) som läggs till som frågesträngar. Varje token tilldelas till en specifik blob (fil).

- Din källcontainer eller blob måste vara inställd på läs och lista åtkomst.
- Din målcontainer eller blob måste ha skriv- och liståtkomst.
API:et för extraherande sammanfattning använder bearbetningstekniker för naturligt språk för att hitta viktiga meningar i ett ostrukturerat textdokument. Dessa meningar förmedlar tillsammans huvudtanken med dokumentet.
Extraheringssammanfattning returnerar en rangpoäng som en del av systemsvaret tillsammans med extraherade meningar och deras position i de ursprungliga dokumenten. En rangpoäng är en indikator på hur relevant en mening bestäms vara, till huvudidén i ett dokument. Modellen ger en poäng mellan 0 och 1 (inklusive) för varje mening och returnerar de högst poängsatta meningarna per begäran. Om du till exempel begär en sammanfattning med tre meningar returnerar tjänsten de tre högst poängsatta meningarna.
Det finns en annan funktion i Azure AI Language, extrahering av nyckelfraser, som kan extrahera viktig information. Här är användbara överväganden för att avgöra mellan extrahering av nyckelfraser och extraheringssammanfattning:
- Extrahering av nyckelfraser returnerar fraser medan extraheringssammanfattning returnerar meningar.
- Extraheringssammanfattning returnerar meningar tillsammans med en rankningspoäng och de högst rankade meningarna returneras per begäran.
- Extraheringssammanfattning returnerar också följande positionsinformation:
- Förskjutning: Startpositionen för varje extraherad mening.
- Längd: Längden på varje extraherad mening.
Bestämma hur data ska bearbetas (valfritt)
Skicka data
Du skickar dokument till API:et som textsträngar. Analysen utförs när begäran har tagits emot. Eftersom API:et är asynkront kan det uppstå en fördröjning mellan att skicka en API-begäran och att ta emot resultatet.
När du använder den här funktionen är API-resultaten tillgängliga i 24 timmar från den tidpunkt då begäran matades in och anges i svaret. Efter den här tidsperioden rensas resultaten och är inte längre tillgängliga för hämtning.
Hämta textsammanfattningsresultat
När du får resultat från språkidentifiering kan du strömma resultatet till ett program eller spara utdata till en fil i det lokala systemet.
Här är ett exempel på innehåll som du kan skicka in för sammanfattning, som extraheras med hjälp av Microsoft-bloggartikeln En holistisk representation mot integrativ AI. Den här artikeln är bara ett exempel. API:et kan acceptera längre indatatext. Mer information finns idata- och tjänstbegränsningar.
"På Microsoft har vi varit på jakt efter att utveckla AI utöver befintliga tekniker genom att ta ett mer holistiskt, mänskligt centrerad tillvägagångssätt för lärande och förståelse. Som Chief Technology Officer för Azure AI-tjänster har jag arbetat med ett team med fantastiska forskare och ingenjörer för att förverkliga detta uppdrag. I min roll har jag ett unikt perspektiv när jag visar relationen mellan tre attribut för mänsklig kognition: enspråkig text (X), ljud- eller visuella sensoriska signaler, (Y) och flerspråkig (Z). I skärningspunkten mellan alla tre finns det magi – det vi kallar XYZ-kod som illustreras i bild 1 – en gemensam representation för att skapa kraftfullare AI som kan tala, höra, se och förstå människor bättre. Vi tror att XYZ-kod gör det möjligt för oss att uppfylla vår långsiktiga vision: överföringsinlärning mellan domäner, som omfattar modaliteter och språk. Målet är att ha förtränat modeller som gemensamt kan lära sig representationer för att stödja ett brett spektrum av underordnade AI-uppgifter, mycket på det sätt som människor gör idag. Under de senaste fem åren har vi uppnått mänsklig prestanda på riktmärken inom konversationstaligenkänning, maskinöversättning, samtalsfrågasvar, maskinläsningsförståelse och bildtexter. Dessa fem genombrott gav oss starka signaler mot vår mer ambitiösa strävan att skapa ett språng i AI-funktioner och uppnå multisensorisk och flerspråkig inlärning som ligger närmare i linje med hur människor lär sig och förstår. Jag tror att den gemensamma XYZ-koden är en grundläggande komponent i denna strävan, om den baseras på externa kunskapskällor i underordnad AI-uppgifter."
API-begäran för textsammanfattning bearbetas när begäran tas emot genom att ett jobb skapas för API-serverdelen. Om jobbet lyckades returneras utdata från API:et. Utdata är tillgängliga för hämtning i 24 timmar. Efter denna tid rensas data. På grund av flerspråkigt och emoji-stöd kan svaret innehålla textförskjutningar. För mer information, sehur man bearbetar förskjutningar.
När du använder föregående exempel kan API:et returnera dessa sammanfattade meningar:
Extraktiv sammanfattning:
- "På Microsoft har vi varit på jakt efter att utveckla AI utöver befintliga tekniker genom att använda en mer holistisk, mänskligt centrerad strategi för lärande och förståelse."
- "Vi tror att XYZ-kod gör det möjligt för oss att uppfylla vår långsiktiga vision: överföringsinlärning mellan domäner, som omfattar modaliteter och språk."
- "Målet är att ha förtränat modeller som gemensamt kan lära sig representationer för att stödja ett brett spektrum av underordnade AI-uppgifter, mycket på det sätt som människor gör idag."
Abstrakt sammanfattning:
- "Microsoft har ett mer holistiskt, mänskligt centrerad sätt att lära sig och förstå. Vi tror att XYZ-kod gör det möjligt för oss att uppfylla vår långsiktiga vision: överföringsinlärning mellan domäner, som omfattar modaliteter och språk. Under de senaste fem åren har vi uppnått mänskliga resultat på riktmärken i."
Prova textutdragssammanfattning
Du kan använda textextraheringssammanfattning för att få sammanfattningar av artiklar, artiklar eller dokument. Ett exempel finns i snabbstartsartikeln.
Du kan använda parametern sentenceCount för att vägleda hur många meningar som returneras, med 3 standardvärdet. Intervallet är från 1 till 20.
Du kan också använda parametern sortby för att ange i vilken ordning de extraherade meningarna returneras – antingen Offset eller Rank, med Offset standardvärdet.
| parametervärde | beskrivning |
|---|---|
| Rangordning | Ordna meningar efter deras relevans för det givna dokumentet, enligt vad tjänsten har bestämt. |
| Avräkning | Behåller den ursprungliga ordningen där meningarna visas i indatadokumentet. |
Prova abstrakt sammanfattning av text
I följande exempel kommer du igång med abstrakt sammanfattning av text:
- Kopiera följande kommando till en textredigerare. Bash-exemplet använder radfortsättningstecknet
\. Om konsolen eller terminalen använder ett annat radfortsättningstecken använder du det tecknet i stället.
curl -i -X POST https://<your-language-resource-endpoint>/language/analyze-text/jobs?api-version=2023-04-01 \
-H "Content-Type: application/json" \
-H "Ocp-Apim-Subscription-Key: <your-language-resource-key>" \
-d \
'
{
"displayName": "Text Abstractive Summarization Task Example",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "en",
"text": "At Microsoft, we have been on a quest to advance AI beyond existing techniques, by taking a more holistic, human-centric approach to learning and understanding. As Chief Technology Officer of Azure AI services, I have been working with a team of amazing scientists and engineers to turn this quest into a reality. In my role, I enjoy a unique perspective in viewing the relationship among three attributes of human cognition: monolingual text (X), audio or visual sensory signals, (Y) and multilingual (Z). At the intersection of all three, there's magic—what we call XYZ-code as illustrated in Figure 1—a joint representation to create more powerful AI that can speak, hear, see, and understand humans better. We believe XYZ-code enables us to fulfill our long-term vision: cross-domain transfer learning, spanning modalities and languages. The goal is to have pretrained models that can jointly learn representations to support a broad range of downstream AI tasks, much in the way humans do today. Over the past five years, we have achieved human performance on benchmarks in conversational speech recognition, machine translation, conversational question answering, machine reading comprehension, and image captioning. These five breakthroughs provided us with strong signals toward our more ambitious aspiration to produce a leap in AI capabilities, achieving multi-sensory and multilingual learning that is closer in line with how humans learn and understand. I believe the joint XYZ-code is a foundational component of this aspiration, if grounded with external knowledge sources in the downstream AI tasks."
}
]
},
"tasks": [
{
"kind": "AbstractiveSummarization",
"taskName": "Text Abstractive Summarization Task 1",
}
]
}
'
Gör följande ändringar i kommandot där det behövs:
- Ersätt värdet
your-language-resource-keymed din nyckel. - Ersätt den första delen av begärande-URL:en
your-language-resource-endpointmed din slutpunkts-URL.
- Ersätt värdet
Öppna ett kommandotolksfönster (till exempel: BASH).
Klistra in kommandot från textredigeraren i kommandotolken och kör sedan kommandot .
Hämta
operation-locationfrån svarshuvudet. Värdet ser ut ungefär som följande URL:
https://<your-language-resource-endpoint>/language/analyze-text/jobs/12345678-1234-1234-1234-12345678?api-version=2022-10-01-preview
- Använd följande cURL-kommando för att hämta resultatet av begäran. Ersätt
<my-job-id>med det numeriska ID-värdet som du fick från föregåendeoperation-locationsvarsrubrik:
curl -X GET https://<your-language-resource-endpoint>/language/analyze-text/jobs/<my-job-id>?api-version=2022-10-01-preview \
-H "Content-Type: application/json" \
-H "Ocp-Apim-Subscription-Key: <your-language-resource-key>"
JSON-svar för abstrakt textsammanfattning
{
"jobId": "cd6418fe-db86-4350-aec1-f0d7c91442a6",
"lastUpdateDateTime": "2022-09-08T16:45:14Z",
"createdDateTime": "2022-09-08T16:44:53Z",
"expirationDateTime": "2022-09-09T16:44:53Z",
"status": "succeeded",
"errors": [],
"displayName": "Text Abstractive Summarization Task Example",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "AbstractiveSummarizationLROResults",
"taskName": "Text Abstractive Summarization Task 1",
"lastUpdateDateTime": "2022-09-08T16:45:14.0717206Z",
"status": "succeeded",
"results": {
"documents": [
{
"summaries": [
{
"text": "Microsoft is taking a more holistic, human-centric approach to AI. We've developed a joint representation to create more powerful AI that can speak, hear, see, and understand humans better. We've achieved human performance on benchmarks in conversational speech recognition, machine translation, ...... and image captions.",
"contexts": [
{
"offset": 0,
"length": 247
}
]
}
],
"id": "1"
}
],
"errors": [],
"modelVersion": "latest"
}
}
]
}
}
| parameter | beskrivning |
|---|---|
-X POST <endpoint> |
Anger din språkresursslutpunkt för åtkomst till API:et. |
--header Content-Type: application/json |
Innehållstypen för att skicka JSON-data. |
--header "Ocp-Apim-Subscription-Key:<key> |
Anger språkresursnyckeln för åtkomst till API:et. |
-data |
JSON-filen som innehåller de data som du vill skicka med din begäran. |
Följande cURL-kommandon körs från ett BASH-gränssnitt. Redigera dessa kommandon med ditt eget resursnamn, resursnyckel och JSON-värden. Försök att analysera ursprungliga dokument genom att välja projektexempel med Personally Identifiable Information (PII) eller Document Summarization koden:
Sammanfattningsexempeldokument
För det här projektet behöver du ett källdokument som laddats upp till källcontainern. Du kan ladda ned vårt Microsoft Word-exempeldokument eller Adobe PDF för den här snabbstarten. Källspråket är engelska.
Skapa POST-begäran
Använd din föredragna redigerare eller IDE och skapa en ny katalog för din app med namnet
native-document.Skapa en ny json-fil med namnet document-summarization.json i din interna dokumentkatalog.
Kopiera och klistra in exempel på dokumentsammanfattningsbegäran i
document-summarization.jsonfilen. Ersätt{your-source-container-SAS-URL}och{your-target-container-SAS-URL}med värden från din Azure Portal Storage-kontocontainerinstans:
Exempel på begäran
{
"tasks": [
{
"kind": "ExtractiveSummarization",
"parameters": {
"sentenceCount": 6
}
}
],
"analysisInput": {
"documents": [
{
"source": {
"location": "{your-source-blob-SAS-URL}"
},
"targets": {
"location": "{your-target-container-SAS-URL}"
}
}
]
}
}
Kör POST-begäran
Ersätt och {your-language-resource-endpoint} med slutpunktsvärdet från Language-resursinstansen i Azure Portal innan du kör {your-key}.
Viktigt!
Kom ihåg att ta bort nyckeln från koden när du är klar och publicera den aldrig offentligt. För produktion använder du ett säkert sätt att lagra och komma åt dina autentiseringsuppgifter som Azure Key Vault. Mer information finns i Säkerhet för Azure AI-tjänster.
PowerShell
cmd /c curl "{your-language-resource-endpoint}/language/analyze-documents/jobs?api-version=2024-11-15-preview" -i -X POST --header "Content-Type: application/json" --header "Ocp-Apim-Subscription-Key: {your-key}" --data "@document-summarization.json"
kommandotolk/terminal
curl -v -X POST "{your-language-resource-endpoint}/language/analyze-documents/jobs?api-version=2024-11-15-preview" --header "Content-Type: application/json" --header "Ocp-Apim-Subscription-Key: {your-key}" --data "@document-summarization.json"
Exempelsvar:
HTTP/1.1 202 Accepted
Content-Length: 0
operation-location: https://{your-language-resource-endpoint}/language/analyze-documents/jobs/f1cc29ff-9738-42ea-afa5-98d2d3cabf94?api-version=2024-11-15-preview
apim-request-id: e7d6fa0c-0efd-416a-8b1e-1cd9287f5f81
x-ms-region: West US 2
Date: Thu, 25 Jan 2024 15:12:32 GMT
POST-svar (jobbId)
Du får ett 202-svar (Framgång) som innehåller en skrivskyddad Operation-Location-header. Värdet för denna header innehåller ett jobId som kan begäras för att få status för den asynkrona operationen och hämta resultaten med en GET-begäran.
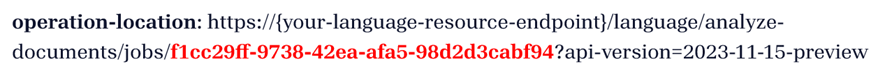
Hämta analysresultat (GET-begäran)
Efter din lyckade POST-begäran avsöker du rubriken operation-location som returneras i POST-begäran för att visa bearbetade data.
Här är strukturen för GET-begäran :
GET {cognitive-service-endpoint}/language/analyze-documents/jobs/{jobId}?api-version=2024-11-15-previewInnan du kör kommandot gör du följande ändringar:
Ersätt {jobId} med rubriken Operation-Location från POST-svaret.
Ersätt {your-language-resource-endpoint} och {your-key} med värdena från language service-instansen i Azure Portal.
Hämta begäran
cmd /c curl "{your-language-resource-endpoint}/language/analyze-documents/jobs/{jobId}?api-version=2024-11-15-preview" -i -X GET --header "Content-Type: application/json" --header "Ocp-Apim-Subscription-Key: {your-key}"
curl -v -X GET "{your-language-resource-endpoint}/language/analyze-documents/jobs/{jobId}?api-version=2024-11-15-preview" --header "Content-Type: application/json" --header "Ocp-Apim-Subscription-Key: {your-key}"
Granska svaret
Du får ett svar på 200 (lyckades) med JSON-utdata. Statusfältet anger resultatet av åtgärden. Om åtgärden inte är slutförd är värdet av status "igång" eller "notStarted" och du bör anropa API:et igen, antingen manuellt eller genom ett skript. Vi rekommenderar ett intervall på en sekund eller mer mellan anrop.
Exempelsvar
{
"jobId": "f1cc29ff-9738-42ea-afa5-98d2d3cabf94",
"lastUpdatedDateTime": "2024-01-24T13:17:58Z",
"createdDateTime": "2024-01-24T13:17:47Z",
"expirationDateTime": "2024-01-25T13:17:47Z",
"status": "succeeded",
"errors": [],
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "ExtractiveSummarizationLROResults",
"lastUpdateDateTime": "2024-01-24T13:17:58.33934Z",
"status": "succeeded",
"results": {
"documents": [
{
"id": "doc_0",
"source": {
"kind": "AzureBlob",
"location": "https://myaccount.blob.core.windows.net/sample-input/input.pdf"
},
"targets": [
{
"kind": "AzureBlob",
"location": "https://myaccount.blob.core.windows.net/sample-output/df6611a3-fe74-44f8-b8d4-58ac7491cb13/ExtractiveSummarization-0001/input.result.json"
}
],
"warnings": []
}
],
"errors": [],
"modelVersion": "2023-02-01-preview"
}
}
]
}
}
När det har slutförts:
- De analyserade dokumenten finns i målcontainern.
- Post-metoden returnerar en
202 Acceptedsvarskod som anger att tjänsten skapade batchbegäran. - POST-begäran returnerade även svarshuvuden, inklusive
Operation-Locationsom ger ett värde som används i efterföljande GET-begäranden.
Rensa resurser
Om du vill rensa och ta bort en Azure AI-tjänstprenumeration kan du ta bort resursen eller resursgruppen. Om du tar bort resursgruppen tas även alla andra resurser som är associerade med den bort.