Snabbstart: Identifiera avsikter med Speech-tjänsten och LUIS
Viktigt!
LUIS dras tillbaka den 1 oktober 2025. Från och med den 1 april 2023 kan du inte skapa nya LUIS-resurser. Vi rekommenderar att du migrerar dina LUIS-program till förståelse för konversationsspråk för att dra nytta av fortsatt produktsupport och flerspråkiga funktioner.
Conversational Language Understanding (CLU) är tillgängligt för C# och C++ med Speech SDK version 1.25 eller senare. Se snabbstarten för att identifiera avsikter med Speech SDK och CLU.
Referensdokumentation Paket (NuGet) | Ytterligare exempel på GitHub |
I den här snabbstarten använder du Speech SDK och tjänsten Language Understanding (LUIS) för att identifiera avsikter från ljuddata som hämtats från en mikrofon. Mer specifikt använder du Speech SDK för att samla in tal och en fördefinierad domän från LUIS för att identifiera avsikter för hemautomatisering, till exempel att aktivera och inaktivera ett ljus.
Förutsättningar
- Azure-prenumeration – Skapa en kostnadsfritt
- Skapa en språkresurs i Azure-portalen. Du kan använda den kostnadsfria prisnivån (
F0) för att prova tjänsten och uppgradera senare till en betald nivå för produktion. Du behöver ingen Speech-resurs den här gången. - Hämta språkresursnyckeln och regionen. När språkresursen har distribuerats väljer du Gå till resurs för att visa och hantera nycklar. Mer information om Azure AI-tjänstresurser finns i Hämta nycklarna för din resurs.
Skapa en LUIS-app för avsiktsigenkänning
För att slutföra snabbstarten för avsiktsigenkänning måste du skapa ett LUIS-konto och ett projekt med hjälp av LUIS-förhandsversionsportalen. Den här snabbstarten kräver en LUIS-prenumeration i en region där avsiktsigenkänning är tillgänglig. En Speech-tjänstprenumeration krävs inte.
Det första du behöver göra är att skapa ett LUIS-konto och en app med hjälp av LUIS-förhandsversionsportalen. LUIS-appen som du skapar använder en fördefinierad domän för hemautomatisering, som innehåller avsikter, entiteter och exempelyttranden. När du är klar har du en LUIS-slutpunkt som körs i molnet som du kan anropa med hjälp av Speech SDK.
Följ de här anvisningarna för att skapa luis-appen:
När du är klar behöver du fyra saker:
- Publicera igen med talprimering aktiverat
- Din LUIS-primärnyckel
- Din LUIS-plats
- Ditt LUIS-app-ID
Här hittar du den här informationen i LUIS-förhandsversionsportalen:
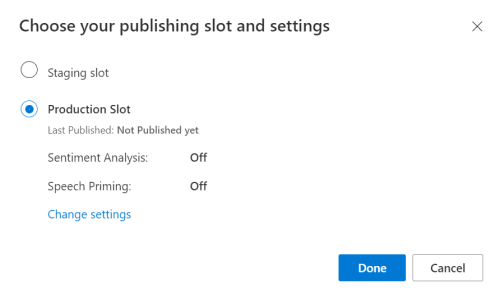
Välj din app i luis-förhandsgranskningsportalen och välj sedan knappen Publicera .
Välj produktionsplatsenom du använder
en-USvälj ändra inställningar och växla alternativet Talprimering till läget På. Välj sedan knappen Publicera .Viktigt!
Talprimering rekommenderas starkt eftersom det förbättrar taligenkänningens noggrannhet.
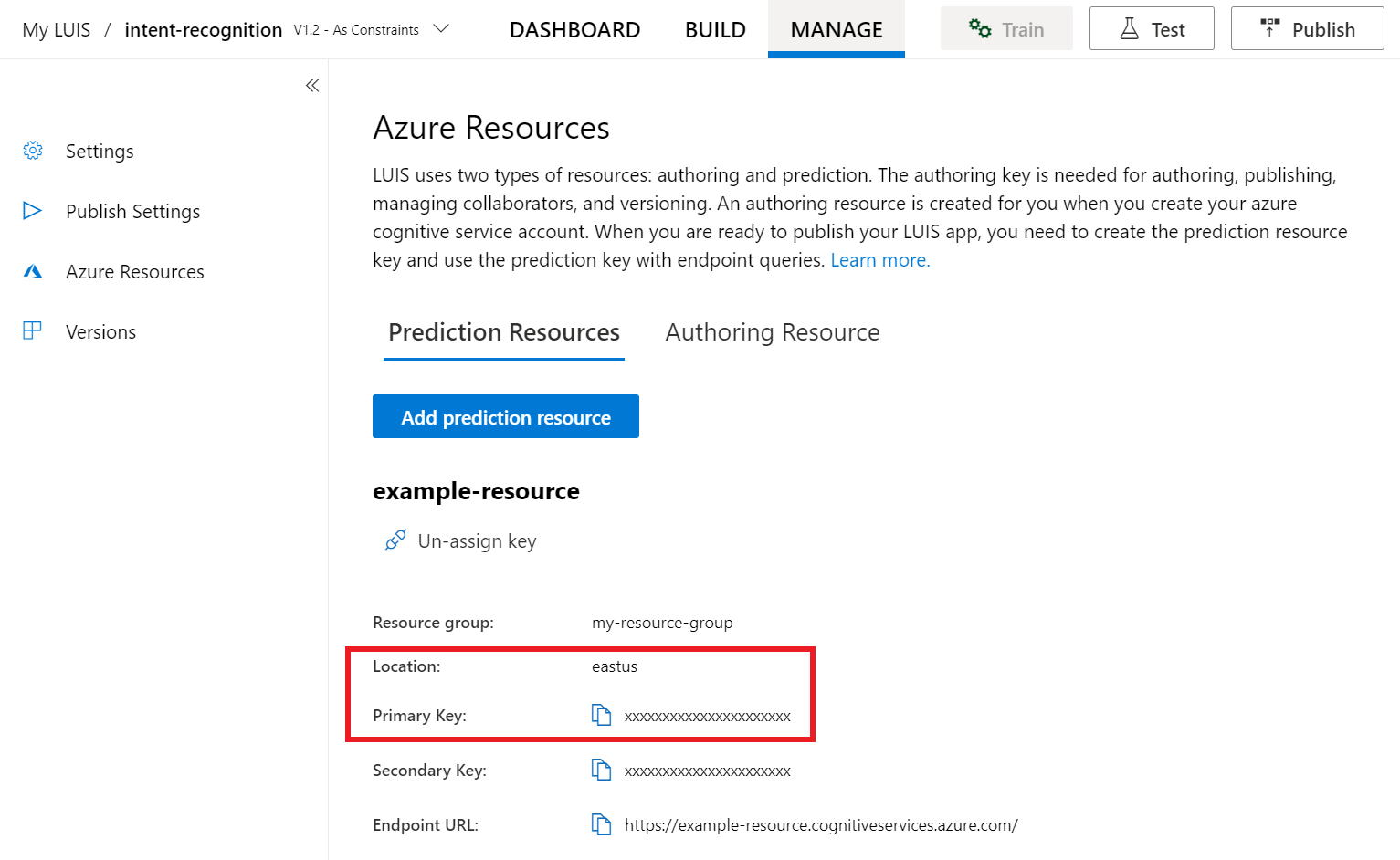
I luis-förhandsversionsportalen väljer du Hantera och sedan Azure-resurser. På den här sidan hittar du luis-nyckeln och platsen (kallas ibland region) för luis-förutsägelseresursen.
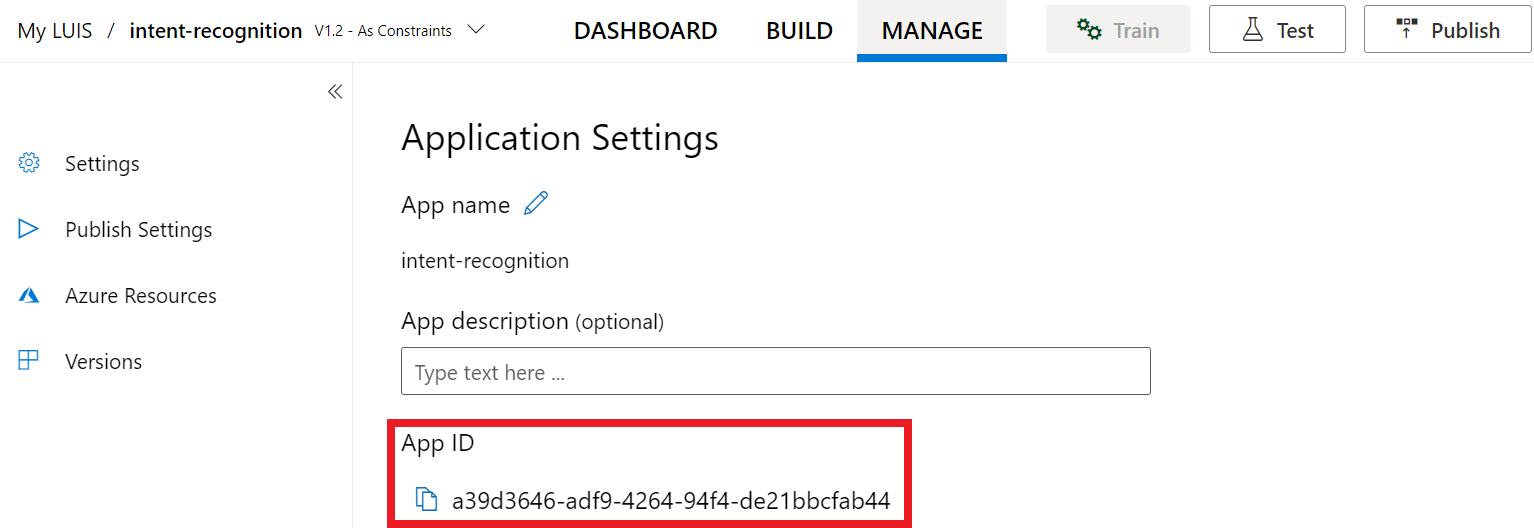
När du har fått din nyckel och plats behöver du app-ID:t. Välj Inställningar. ditt app-ID är tillgängligt på den här sidan.
Öppna projektet i Visual Studio
Öppna sedan projektet i Visual Studio.
- Starta Visual Studio 2019.
- Läs in projektet och öppna
Program.cs.
Börja med lite pannplåtskod
Nu ska vi lägga till kod som fungerar som ett skelett för vårt projekt. Observera att du har skapat en asynkron metod med namnet RecognizeIntentAsync().
using System;
using System.Threading.Tasks;
using Microsoft.CognitiveServices.Speech;
using Microsoft.CognitiveServices.Speech.Intent;
namespace helloworld
{
class Program
{
public static async Task RecognizeIntentAsync()
{
}
static async Task Main()
{
await RecognizeIntentAsync();
Console.WriteLine("Please press <Return> to continue.");
Console.ReadLine();
}
}
}
Skapa en Speech-konfiguration
Innan du kan initiera ett IntentRecognizer objekt måste du skapa en konfiguration som använder nyckeln och platsen för luis-förutsägelseresursen.
Viktigt!
Startnyckeln och redigeringsnycklarna fungerar inte. Du måste använda din förutsägelsenyckel och plats som du skapade tidigare. Mer information finns i Skapa en LUIS-app för avsiktsigenkänning.
Infoga den här koden i RecognizeIntentAsync() -metoden. Se till att du uppdaterar dessa värden:
- Ersätt
"YourLanguageUnderstandingSubscriptionKey"med din LUIS-förutsägelsenyckel. - Ersätt
"YourLanguageUnderstandingServiceRegion"med din LUIS-plats. Använd Regionidentifierare från region.
Dricks
Om du behöver hjälp med att hitta dessa värden kan du läsa Skapa en LUIS-app för avsiktsigenkänning.
Viktigt!
Kom ihåg att ta bort nyckeln från koden när du är klar och publicera den aldrig offentligt. För produktion använder du ett säkert sätt att lagra och komma åt dina autentiseringsuppgifter som Azure Key Vault. Mer information finns i säkerhetsartikeln för Azure AI-tjänster.
var config = SpeechConfig.FromSubscription(
"YourLanguageUnderstandingSubscriptionKey",
"YourLanguageUnderstandingServiceRegion");
Det här exemplet använder FromSubscription() metoden för att skapa SpeechConfig. En fullständig lista över tillgängliga metoder finns i Klassen SpeechConfig.
Speech SDK kommer som standard att känna igen med hjälp av en-us för språket, se Så här känner du igen tal för information om hur du väljer källspråket.
Initiera en IntentRecognizer
Nu ska vi skapa en IntentRecognizer. Det här objektet skapas i en using-instruktion för att säkerställa korrekt frisläppning av ohanterade resurser. Infoga den här koden i RecognizeIntentAsync() -metoden, precis under din Speech-konfiguration.
// Creates an intent recognizer using microphone as audio input.
using (var recognizer = new IntentRecognizer(config))
{
}
Lägg till en LanguageUnderstandingModel och avsikter
Du måste associera en LanguageUnderstandingModel med avsiktsigenkänningen och lägga till de avsikter som du vill ska identifieras. Vi ska använda avsikter från den fördefinierade domänen för hemautomatisering. Infoga den här koden i instruktionen using från föregående avsnitt. Se till att du ersätter "YourLanguageUnderstandingAppId" med ditt LUIS-app-ID.
Dricks
Om du behöver hjälp med att hitta det här värdet kan du läsa Skapa en LUIS-app för avsiktsigenkänning.
// Creates a Language Understanding model using the app id, and adds specific intents from your model
var model = LanguageUnderstandingModel.FromAppId("YourLanguageUnderstandingAppId");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
I det AddIntent() här exemplet används funktionen för att lägga till avsikter individuellt. Om du vill lägga till alla avsikter från en modell använder AddAllIntents(model) du och skickar modellen.
Identifiera en avsikt
Från - IntentRecognizer objektet anropar RecognizeOnceAsync() du metoden. Den här metoden låter Speech-tjänsten veta att du skickar en enda fras för igenkänning och att när frasen har identifierats för att sluta känna igen tal.
I instruktionen using lägger du till den här koden under din modell.
// Starts recognizing.
Console.WriteLine("Say something...");
// Starts intent recognition, and returns after a single utterance is recognized. The end of a
// single utterance is determined by listening for silence at the end or until a maximum of 15
// seconds of audio is processed. The task returns the recognition text as result.
// Note: Since RecognizeOnceAsync() returns only a single utterance, it is suitable only for single
// shot recognition like command or query.
// For long-running multi-utterance recognition, use StartContinuousRecognitionAsync() instead.
var result = await recognizer.RecognizeOnceAsync();
Visa igenkänningsresultat (eller fel)
När igenkänningsresultatet returneras av Speech-tjänsten vill du göra något med det. Vi ska hålla det enkelt och skriva ut resultatet till konsolen.
Lägg till den här koden i instruktionen using nedan RecognizeOnceAsync():
// Checks result.
switch (result.Reason)
{
case ResultReason.RecognizedIntent:
Console.WriteLine($"RECOGNIZED: Text={result.Text}");
Console.WriteLine($" Intent Id: {result.IntentId}.");
var json = result.Properties.GetProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult);
Console.WriteLine($" Language Understanding JSON: {json}.");
break;
case ResultReason.RecognizedSpeech:
Console.WriteLine($"RECOGNIZED: Text={result.Text}");
Console.WriteLine($" Intent not recognized.");
break;
case ResultReason.NoMatch:
Console.WriteLine($"NOMATCH: Speech could not be recognized.");
break;
case ResultReason.Canceled:
var cancellation = CancellationDetails.FromResult(result);
Console.WriteLine($"CANCELED: Reason={cancellation.Reason}");
if (cancellation.Reason == CancellationReason.Error)
{
Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}");
Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}");
Console.WriteLine($"CANCELED: Did you update the subscription info?");
}
break;
}
Kontrollera koden
Nu bör koden se ut så här:
Kommentar
Vi har lagt till några kommentarer i den här versionen.
//
// Copyright (c) Microsoft. All rights reserved.
// Licensed under the MIT license. See LICENSE.md file in the project root for full license information.
//
// <skeleton_1>
using System;
using System.Threading.Tasks;
using Microsoft.CognitiveServices.Speech;
using Microsoft.CognitiveServices.Speech.Intent;
namespace helloworld
{
class Program
{
public static async Task RecognizeIntentAsync()
{
// </skeleton_1>
// Creates an instance of a speech config with specified subscription key
// and service region. Note that in contrast to other services supported by
// the Cognitive Services Speech SDK, the Language Understanding service
// requires a specific subscription key from https://www.luis.ai/.
// The Language Understanding service calls the required key 'endpoint key'.
// Once you've obtained it, replace with below with your own Language Understanding subscription key
// and service region (e.g., "westus").
// The default language is "en-us".
// <create_speech_configuration>
var config = SpeechConfig.FromSubscription(
"YourLanguageUnderstandingSubscriptionKey",
"YourLanguageUnderstandingServiceRegion");
// </create_speech_configuration>
// <create_intent_recognizer_1>
// Creates an intent recognizer using microphone as audio input.
using (var recognizer = new IntentRecognizer(config))
{
// </create_intent_recognizer_1>
// <add_intents>
// Creates a Language Understanding model using the app id, and adds specific intents from your model
var model = LanguageUnderstandingModel.FromAppId("YourLanguageUnderstandingAppId");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
// </add_intents>
// To add all of the possible intents from a LUIS model to the recognizer, uncomment the line below:
// recognizer.AddAllIntents(model);
// <recognize_intent>
// Starts recognizing.
Console.WriteLine("Say something...");
// Starts intent recognition, and returns after a single utterance is recognized. The end of a
// single utterance is determined by listening for silence at the end or until a maximum of 15
// seconds of audio is processed. The task returns the recognition text as result.
// Note: Since RecognizeOnceAsync() returns only a single utterance, it is suitable only for single
// shot recognition like command or query.
// For long-running multi-utterance recognition, use StartContinuousRecognitionAsync() instead.
var result = await recognizer.RecognizeOnceAsync();
// </recognize_intent>
// <print_results>
// Checks result.
switch (result.Reason)
{
case ResultReason.RecognizedIntent:
Console.WriteLine($"RECOGNIZED: Text={result.Text}");
Console.WriteLine($" Intent Id: {result.IntentId}.");
var json = result.Properties.GetProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult);
Console.WriteLine($" Language Understanding JSON: {json}.");
break;
case ResultReason.RecognizedSpeech:
Console.WriteLine($"RECOGNIZED: Text={result.Text}");
Console.WriteLine($" Intent not recognized.");
break;
case ResultReason.NoMatch:
Console.WriteLine($"NOMATCH: Speech could not be recognized.");
break;
case ResultReason.Canceled:
var cancellation = CancellationDetails.FromResult(result);
Console.WriteLine($"CANCELED: Reason={cancellation.Reason}");
if (cancellation.Reason == CancellationReason.Error)
{
Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}");
Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}");
Console.WriteLine($"CANCELED: Did you update the subscription info?");
}
break;
}
// </print_results>
// <create_intent_recognizer_2>
}
// </create_intent_recognizer_2>
// <skeleton_2>
}
static async Task Main()
{
await RecognizeIntentAsync();
Console.WriteLine("Please press <Return> to continue.");
Console.ReadLine();
}
}
}
// </skeleton_2>
Skapa och köra din app
Nu är du redo att skapa din app och testa vår taligenkänning med hjälp av Speech-tjänsten.
- Kompilera koden – Från menyraden i Visual Studio väljer du Skapa>bygglösning.
- Starta din app – Välj Felsök>Starta felsökning i menyraden eller tryck på F5.
- Starta igenkänning – Du uppmanas att tala en fras på engelska. Ditt tal skickas till Speech-tjänsten, transkriberas som text och återges i konsolen.
Referensdokumentation Paket (NuGet) | Ytterligare exempel på GitHub |
I den här snabbstarten använder du Speech SDK och tjänsten Language Understanding (LUIS) för att identifiera avsikter från ljuddata som hämtats från en mikrofon. Mer specifikt använder du Speech SDK för att samla in tal och en fördefinierad domän från LUIS för att identifiera avsikter för hemautomatisering, till exempel att aktivera och inaktivera ett ljus.
Förutsättningar
- Azure-prenumeration – Skapa en kostnadsfritt
- Skapa en språkresurs i Azure-portalen. Du kan använda den kostnadsfria prisnivån (
F0) för att prova tjänsten och uppgradera senare till en betald nivå för produktion. Du behöver ingen Speech-resurs den här gången. - Hämta språkresursnyckeln och regionen. När språkresursen har distribuerats väljer du Gå till resurs för att visa och hantera nycklar. Mer information om Azure AI-tjänstresurser finns i Hämta nycklarna för din resurs.
Skapa en LUIS-app för avsiktsigenkänning
För att slutföra snabbstarten för avsiktsigenkänning måste du skapa ett LUIS-konto och ett projekt med hjälp av LUIS-förhandsversionsportalen. Den här snabbstarten kräver en LUIS-prenumeration i en region där avsiktsigenkänning är tillgänglig. En Speech-tjänstprenumeration krävs inte.
Det första du behöver göra är att skapa ett LUIS-konto och en app med hjälp av LUIS-förhandsversionsportalen. LUIS-appen som du skapar använder en fördefinierad domän för hemautomatisering, som innehåller avsikter, entiteter och exempelyttranden. När du är klar har du en LUIS-slutpunkt som körs i molnet som du kan anropa med hjälp av Speech SDK.
Följ de här anvisningarna för att skapa luis-appen:
När du är klar behöver du fyra saker:
- Publicera igen med talprimering aktiverat
- Din LUIS-primärnyckel
- Din LUIS-plats
- Ditt LUIS-app-ID
Här hittar du den här informationen i LUIS-förhandsversionsportalen:
Välj din app i luis-förhandsgranskningsportalen och välj sedan knappen Publicera .
Välj produktionsplatsenom du använder
en-USvälj ändra inställningar och växla alternativet Talprimering till läget På. Välj sedan knappen Publicera .Viktigt!
Talprimering rekommenderas starkt eftersom det förbättrar taligenkänningens noggrannhet.
I luis-förhandsversionsportalen väljer du Hantera och sedan Azure-resurser. På den här sidan hittar du luis-nyckeln och platsen (kallas ibland region) för luis-förutsägelseresursen.
När du har fått din nyckel och plats behöver du app-ID:t. Välj Inställningar. ditt app-ID är tillgängligt på den här sidan.
Öppna projektet i Visual Studio
Öppna sedan projektet i Visual Studio.
- Starta Visual Studio 2019.
- Läs in projektet och öppna
helloworld.cpp.
Börja med lite pannplåtskod
Nu ska vi lägga till kod som fungerar som ett skelett för vårt projekt. Observera att du har skapat en asynkron metod med namnet recognizeIntent().
#include "stdafx.h"
#include <iostream>
#include <speechapi_cxx.h>
using namespace std;
using namespace Microsoft::CognitiveServices::Speech;
using namespace Microsoft::CognitiveServices::Speech::Intent;
void recognizeIntent()
{
}
int wmain()
{
try
{
recognizeIntent();
}
catch (exception e)
{
cout << e.what();
}
cout << "Please press a key to continue.\n";
cin.get();
return 0;
}
Skapa en Speech-konfiguration
Innan du kan initiera ett IntentRecognizer objekt måste du skapa en konfiguration som använder nyckeln och platsen för luis-förutsägelseresursen.
Viktigt!
Startnyckeln och redigeringsnycklarna fungerar inte. Du måste använda din förutsägelsenyckel och plats som du skapade tidigare. Mer information finns i Skapa en LUIS-app för avsiktsigenkänning.
Infoga den här koden i recognizeIntent() -metoden. Se till att du uppdaterar dessa värden:
- Ersätt
"YourLanguageUnderstandingSubscriptionKey"med din LUIS-förutsägelsenyckel. - Ersätt
"YourLanguageUnderstandingServiceRegion"med din LUIS-plats. Använd Regionidentifierare från region.
Dricks
Om du behöver hjälp med att hitta dessa värden kan du läsa Skapa en LUIS-app för avsiktsigenkänning.
Viktigt!
Kom ihåg att ta bort nyckeln från koden när du är klar och publicera den aldrig offentligt. För produktion använder du ett säkert sätt att lagra och komma åt dina autentiseringsuppgifter som Azure Key Vault. Mer information finns i säkerhetsartikeln för Azure AI-tjänster.
auto config = SpeechConfig::FromSubscription(
"YourLanguageUnderstandingSubscriptionKey",
"YourLanguageUnderstandingServiceRegion");
Det här exemplet använder FromSubscription() metoden för att skapa SpeechConfig. En fullständig lista över tillgängliga metoder finns i Klassen SpeechConfig.
Speech SDK kommer som standard att känna igen med hjälp av en-us för språket, se Så här känner du igen tal för information om hur du väljer källspråket.
Initiera en IntentRecognizer
Nu ska vi skapa en IntentRecognizer. Infoga den här koden i recognizeIntent() -metoden, precis under din Speech-konfiguration.
// Creates an intent recognizer using microphone as audio input.
auto recognizer = IntentRecognizer::FromConfig(config);
Lägg till en LanguageUnderstandingModel och avsikter
Du måste associera en LanguageUnderstandingModel med avsiktsigenkänningen och lägga till de avsikter som du vill ska identifieras. Vi ska använda avsikter från den fördefinierade domänen för hemautomatisering.
Infoga den här koden under din IntentRecognizer. Se till att du ersätter "YourLanguageUnderstandingAppId" med ditt LUIS-app-ID.
Dricks
Om du behöver hjälp med att hitta det här värdet kan du läsa Skapa en LUIS-app för avsiktsigenkänning.
// Creates a Language Understanding model using the app id, and adds specific intents from your model
auto model = LanguageUnderstandingModel::FromAppId("YourLanguageUnderstandingAppId");
recognizer->AddIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer->AddIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer->AddIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
I det AddIntent() här exemplet används funktionen för att lägga till avsikter individuellt. Om du vill lägga till alla avsikter från en modell använder AddAllIntents(model) du och skickar modellen.
Identifiera en avsikt
Från - IntentRecognizer objektet anropar RecognizeOnceAsync() du metoden. Den här metoden låter Speech-tjänsten veta att du skickar en enda fras för igenkänning och att när frasen har identifierats för att sluta känna igen tal. För enkelhetens skull väntar vi på att framtiden ska slutföras.
Infoga den här koden under din modell:
cout << "Say something...\n";
// Starts intent recognition, and returns after a single utterance is recognized. The end of a
// single utterance is determined by listening for silence at the end or until a maximum of 15
// seconds of audio is processed. The task returns the recognition text as result.
// Note: Since RecognizeOnceAsync() returns only a single utterance, it is suitable only for single
// shot recognition like command or query.
// For long-running multi-utterance recognition, use StartContinuousRecognitionAsync() instead.
auto result = recognizer->RecognizeOnceAsync().get();
Visa igenkänningsresultaten (eller felen)
När igenkänningsresultatet returneras av Speech-tjänsten vill du göra något med det. Vi ska hålla det enkelt och skriva ut resultatet till konsolen.
Infoga den här koden nedan auto result = recognizer->RecognizeOnceAsync().get();:
// Checks result.
if (result->Reason == ResultReason::RecognizedIntent)
{
cout << "RECOGNIZED: Text=" << result->Text << std::endl;
cout << " Intent Id: " << result->IntentId << std::endl;
cout << " Intent Service JSON: " << result->Properties.GetProperty(PropertyId::LanguageUnderstandingServiceResponse_JsonResult) << std::endl;
}
else if (result->Reason == ResultReason::RecognizedSpeech)
{
cout << "RECOGNIZED: Text=" << result->Text << " (intent could not be recognized)" << std::endl;
}
else if (result->Reason == ResultReason::NoMatch)
{
cout << "NOMATCH: Speech could not be recognized." << std::endl;
}
else if (result->Reason == ResultReason::Canceled)
{
auto cancellation = CancellationDetails::FromResult(result);
cout << "CANCELED: Reason=" << (int)cancellation->Reason << std::endl;
if (cancellation->Reason == CancellationReason::Error)
{
cout << "CANCELED: ErrorCode=" << (int)cancellation->ErrorCode << std::endl;
cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails << std::endl;
cout << "CANCELED: Did you update the subscription info?" << std::endl;
}
}
Kontrollera koden
Nu bör koden se ut så här:
Kommentar
Vi har lagt till några kommentarer i den här versionen.
//
// Copyright (c) Microsoft. All rights reserved.
// Licensed under the MIT license. See LICENSE.md file in the project root for full license information.
//
// <skeleton_1>
#include "stdafx.h"
#include <iostream>
#include <speechapi_cxx.h>
using namespace std;
using namespace Microsoft::CognitiveServices::Speech;
using namespace Microsoft::CognitiveServices::Speech::Intent;
void recognizeIntent()
{
// </skeleton_1>
// Creates an instance of a speech config with specified subscription key
// and service region. Note that in contrast to other services supported by
// the Cognitive Services Speech SDK, the Language Understanding service
// requires a specific subscription key from https://www.luis.ai/.
// The Language Understanding service calls the required key 'endpoint key'.
// Once you've obtained it, replace with below with your own Language Understanding subscription key
// and service region (e.g., "westus").
// The default recognition language is "en-us".
// <create_speech_configuration>
auto config = SpeechConfig::FromSubscription(
"YourLanguageUnderstandingSubscriptionKey",
"YourLanguageUnderstandingServiceRegion");
// </create_speech_configuration>
// <create_intent_recognizer>
// Creates an intent recognizer using microphone as audio input.
auto recognizer = IntentRecognizer::FromConfig(config);
// </create_intent_recognizer>
// <add_intents>
// Creates a Language Understanding model using the app id, and adds specific intents from your model
auto model = LanguageUnderstandingModel::FromAppId("YourLanguageUnderstandingAppId");
recognizer->AddIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer->AddIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer->AddIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
// </add_intents>
// To add all of the possible intents from a LUIS model to the recognizer, uncomment the line below:
// recognizer->AddAllIntents(model);
// <recognize_intent>
cout << "Say something...\n";
// Starts intent recognition, and returns after a single utterance is recognized. The end of a
// single utterance is determined by listening for silence at the end or until a maximum of 15
// seconds of audio is processed. The task returns the recognition text as result.
// Note: Since RecognizeOnceAsync() returns only a single utterance, it is suitable only for single
// shot recognition like command or query.
// For long-running multi-utterance recognition, use StartContinuousRecognitionAsync() instead.
auto result = recognizer->RecognizeOnceAsync().get();
// </recognize_intent>
// <print_results>
// Checks result.
if (result->Reason == ResultReason::RecognizedIntent)
{
cout << "RECOGNIZED: Text=" << result->Text << std::endl;
cout << " Intent Id: " << result->IntentId << std::endl;
cout << " Intent Service JSON: " << result->Properties.GetProperty(PropertyId::LanguageUnderstandingServiceResponse_JsonResult) << std::endl;
}
else if (result->Reason == ResultReason::RecognizedSpeech)
{
cout << "RECOGNIZED: Text=" << result->Text << " (intent could not be recognized)" << std::endl;
}
else if (result->Reason == ResultReason::NoMatch)
{
cout << "NOMATCH: Speech could not be recognized." << std::endl;
}
else if (result->Reason == ResultReason::Canceled)
{
auto cancellation = CancellationDetails::FromResult(result);
cout << "CANCELED: Reason=" << (int)cancellation->Reason << std::endl;
if (cancellation->Reason == CancellationReason::Error)
{
cout << "CANCELED: ErrorCode=" << (int)cancellation->ErrorCode << std::endl;
cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails << std::endl;
cout << "CANCELED: Did you update the subscription info?" << std::endl;
}
}
// </print_results>
// <skeleton_2>
}
int wmain()
{
try
{
recognizeIntent();
}
catch (exception e)
{
cout << e.what();
}
cout << "Please press a key to continue.\n";
cin.get();
return 0;
}
// </skeleton_2>
Skapa och köra din app
Nu är du redo att skapa din app och testa vår taligenkänning med hjälp av Speech-tjänsten.
- Kompilera koden – Från menyraden i Visual Studio väljer du Skapa>bygglösning.
- Starta din app – Välj Felsök>Starta felsökning i menyraden eller tryck på F5.
- Starta igenkänning – Du uppmanas att tala en fras på engelska. Ditt tal skickas till Speech-tjänsten, transkriberas som text och återges i konsolen.
Referensdokumentation | Ytterligare exempel på GitHub
I den här snabbstarten använder du Speech SDK och tjänsten Language Understanding (LUIS) för att identifiera avsikter från ljuddata som hämtats från en mikrofon. Mer specifikt använder du Speech SDK för att samla in tal och en fördefinierad domän från LUIS för att identifiera avsikter för hemautomatisering, till exempel att aktivera och inaktivera ett ljus.
Förutsättningar
- Azure-prenumeration – Skapa en kostnadsfritt
- Skapa en språkresurs i Azure-portalen. Du kan använda den kostnadsfria prisnivån (
F0) för att prova tjänsten och uppgradera senare till en betald nivå för produktion. Du behöver ingen Speech-resurs den här gången. - Hämta språkresursnyckeln och regionen. När språkresursen har distribuerats väljer du Gå till resurs för att visa och hantera nycklar. Mer information om Azure AI-tjänstresurser finns i Hämta nycklarna för din resurs.
Du måste också installera Speech SDK för utvecklingsmiljön och skapa ett tomt exempelprojekt.
Skapa en LUIS-app för avsiktsigenkänning
För att slutföra snabbstarten för avsiktsigenkänning måste du skapa ett LUIS-konto och ett projekt med hjälp av LUIS-förhandsversionsportalen. Den här snabbstarten kräver en LUIS-prenumeration i en region där avsiktsigenkänning är tillgänglig. En Speech-tjänstprenumeration krävs inte.
Det första du behöver göra är att skapa ett LUIS-konto och en app med hjälp av LUIS-förhandsversionsportalen. LUIS-appen som du skapar använder en fördefinierad domän för hemautomatisering, som innehåller avsikter, entiteter och exempelyttranden. När du är klar har du en LUIS-slutpunkt som körs i molnet som du kan anropa med hjälp av Speech SDK.
Följ de här anvisningarna för att skapa luis-appen:
När du är klar behöver du fyra saker:
- Publicera igen med talprimering aktiverat
- Din LUIS-primärnyckel
- Din LUIS-plats
- Ditt LUIS-app-ID
Här hittar du den här informationen i LUIS-förhandsversionsportalen:
Välj din app i luis-förhandsgranskningsportalen och välj sedan knappen Publicera .
Välj produktionsplatsenom du använder
en-USvälj ändra inställningar och växla alternativet Talprimering till läget På. Välj sedan knappen Publicera .Viktigt!
Talprimering rekommenderas starkt eftersom det förbättrar taligenkänningens noggrannhet.
I luis-förhandsversionsportalen väljer du Hantera och sedan Azure-resurser. På den här sidan hittar du luis-nyckeln och platsen (kallas ibland region) för luis-förutsägelseresursen.
När du har fått din nyckel och plats behöver du app-ID:t. Välj Inställningar. ditt app-ID är tillgängligt på den här sidan.
Öppna ditt projekt
- Öppna önskad IDE.
- Läs in projektet och öppna
Main.java.
Börja med lite pannplåtskod
Nu ska vi lägga till kod som fungerar som ett skelett för vårt projekt.
package speechsdk.quickstart;
import com.microsoft.cognitiveservices.speech.*;
import com.microsoft.cognitiveservices.speech.intent.*;
/**
* Quickstart: recognize speech using the Speech SDK for Java.
*/
public class Main {
/**
* @param args Arguments are ignored in this sample.
*/
public static void main(String[] args) {
} catch (Exception ex) {
System.out.println("Unexpected exception: " + ex.getMessage());
assert(false);
System.exit(1);
}
}
}
Skapa en Speech-konfiguration
Innan du kan initiera ett IntentRecognizer objekt måste du skapa en konfiguration som använder nyckeln och platsen för luis-förutsägelseresursen.
Infoga den här koden i try/catch-blocket i main(). Se till att du uppdaterar dessa värden:
- Ersätt
"YourLanguageUnderstandingSubscriptionKey"med din LUIS-förutsägelsenyckel. - Ersätt
"YourLanguageUnderstandingServiceRegion"med din LUIS-plats. Använda regionidentifierare från region
Dricks
Om du behöver hjälp med att hitta dessa värden kan du läsa Skapa en LUIS-app för avsiktsigenkänning.
Viktigt!
Kom ihåg att ta bort nyckeln från koden när du är klar och publicera den aldrig offentligt. För produktion använder du ett säkert sätt att lagra och komma åt dina autentiseringsuppgifter som Azure Key Vault. Mer information finns i säkerhetsartikeln för Azure AI-tjänster.
// Replace below with with specified subscription key (called 'endpoint key' by the Language Understanding service)
String languageUnderstandingSubscriptionKey = "YourLanguageUnderstandingSubscriptionKey";
// Replace below with your own service region (e.g., "westus").
String languageUnderstandingServiceRegion = "YourLanguageUnderstandingServiceRegion";
// Creates an instance of intent recognizer with a given speech configuration.
// Recognizer is created with the default microphone audio input and default language "en-us".
try (SpeechConfig config = SpeechConfig.fromSubscription(languageUnderstandingSubscriptionKey, languageUnderstandingServiceRegion);
Det här exemplet använder FromSubscription() metoden för att skapa SpeechConfig. En fullständig lista över tillgängliga metoder finns i Klassen SpeechConfig.
Speech SDK kommer som standard att känna igen med hjälp av en-us för språket, se Så här känner du igen tal för information om hur du väljer källspråket.
Initiera en IntentRecognizer
Nu ska vi skapa en IntentRecognizer. Infoga den här koden precis under din Speech-konfiguration.
IntentRecognizer recognizer = new IntentRecognizer(config)) {
Lägg till en LanguageUnderstandingModel och avsikter
Du måste associera en LanguageUnderstandingModel med avsiktsigenkänningen och lägga till de avsikter som du vill ska identifieras. Vi ska använda avsikter från den fördefinierade domänen för hemautomatisering.
Infoga den här koden under din IntentRecognizer. Se till att du ersätter "YourLanguageUnderstandingAppId" med ditt LUIS-app-ID.
Dricks
Om du behöver hjälp med att hitta det här värdet kan du läsa Skapa en LUIS-app för avsiktsigenkänning.
// Creates a language understanding model using the app id, and adds specific intents from your model
LanguageUnderstandingModel model = LanguageUnderstandingModel.fromAppId("YourLanguageUnderstandingAppId");
recognizer.addIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer.addIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer.addIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
I det addIntent() här exemplet används funktionen för att lägga till avsikter individuellt. Om du vill lägga till alla avsikter från en modell använder addAllIntents(model) du och skickar modellen.
Identifiera en avsikt
Från - IntentRecognizer objektet anropar recognizeOnceAsync() du metoden. Den här metoden låter Speech-tjänsten veta att du skickar en enda fras för igenkänning och att när frasen har identifierats för att sluta känna igen tal.
Infoga den här koden under din modell:
System.out.println("Say something...");
// Starts recognition. It returns when the first utterance has been recognized.
IntentRecognitionResult result = recognizer.recognizeOnceAsync().get();
Visa igenkänningsresultaten (eller felen)
När igenkänningsresultatet returneras av Speech-tjänsten vill du göra något med det. Vi ska hålla det enkelt och skriva ut resultatet till konsolen.
Infoga den här koden under anropet till recognizeOnceAsync().
// Checks result.
if (result.getReason() == ResultReason.RecognizedIntent) {
System.out.println("RECOGNIZED: Text=" + result.getText());
System.out.println(" Intent Id: " + result.getIntentId());
System.out.println(" Intent Service JSON: " + result.getProperties().getProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult));
}
else if (result.getReason() == ResultReason.RecognizedSpeech) {
System.out.println("RECOGNIZED: Text=" + result.getText());
System.out.println(" Intent not recognized.");
}
else if (result.getReason() == ResultReason.NoMatch) {
System.out.println("NOMATCH: Speech could not be recognized.");
}
else if (result.getReason() == ResultReason.Canceled) {
CancellationDetails cancellation = CancellationDetails.fromResult(result);
System.out.println("CANCELED: Reason=" + cancellation.getReason());
if (cancellation.getReason() == CancellationReason.Error) {
System.out.println("CANCELED: ErrorCode=" + cancellation.getErrorCode());
System.out.println("CANCELED: ErrorDetails=" + cancellation.getErrorDetails());
System.out.println("CANCELED: Did you update the subscription info?");
}
}
Kontrollera koden
Nu bör koden se ut så här:
Kommentar
Vi har lagt till några kommentarer i den här versionen.
//
// Copyright (c) Microsoft. All rights reserved.
// Licensed under the MIT license. See LICENSE.md file in the project root for full license information.
//
// <skeleton_1>
package speechsdk.quickstart;
import com.microsoft.cognitiveservices.speech.*;
import com.microsoft.cognitiveservices.speech.intent.*;
/**
* Quickstart: recognize speech using the Speech SDK for Java.
*/
public class Main {
/**
* @param args Arguments are ignored in this sample.
*/
public static void main(String[] args) {
// </skeleton_1>
// <create_speech_configuration>
// Replace below with with specified subscription key (called 'endpoint key' by the Language Understanding service)
String languageUnderstandingSubscriptionKey = "YourLanguageUnderstandingSubscriptionKey";
// Replace below with your own service region (e.g., "westus").
String languageUnderstandingServiceRegion = "YourLanguageUnderstandingServiceRegion";
// Creates an instance of intent recognizer with a given speech configuration.
// Recognizer is created with the default microphone audio input and default language "en-us".
try (SpeechConfig config = SpeechConfig.fromSubscription(languageUnderstandingSubscriptionKey, languageUnderstandingServiceRegion);
// </create_speech_configuration>
// <create_intent_recognizer>
IntentRecognizer recognizer = new IntentRecognizer(config)) {
// </create_intent_recognizer>
// <add_intents>
// Creates a language understanding model using the app id, and adds specific intents from your model
LanguageUnderstandingModel model = LanguageUnderstandingModel.fromAppId("YourLanguageUnderstandingAppId");
recognizer.addIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer.addIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer.addIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
// </add_intents>
// To add all of the possible intents from a LUIS model to the recognizer, uncomment the line below:
// recognizer.addAllIntents(model);
// <recognize_intent>
System.out.println("Say something...");
// Starts recognition. It returns when the first utterance has been recognized.
IntentRecognitionResult result = recognizer.recognizeOnceAsync().get();
// </recognize_intent>
// <print_result>
// Checks result.
if (result.getReason() == ResultReason.RecognizedIntent) {
System.out.println("RECOGNIZED: Text=" + result.getText());
System.out.println(" Intent Id: " + result.getIntentId());
System.out.println(" Intent Service JSON: " + result.getProperties().getProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult));
}
else if (result.getReason() == ResultReason.RecognizedSpeech) {
System.out.println("RECOGNIZED: Text=" + result.getText());
System.out.println(" Intent not recognized.");
}
else if (result.getReason() == ResultReason.NoMatch) {
System.out.println("NOMATCH: Speech could not be recognized.");
}
else if (result.getReason() == ResultReason.Canceled) {
CancellationDetails cancellation = CancellationDetails.fromResult(result);
System.out.println("CANCELED: Reason=" + cancellation.getReason());
if (cancellation.getReason() == CancellationReason.Error) {
System.out.println("CANCELED: ErrorCode=" + cancellation.getErrorCode());
System.out.println("CANCELED: ErrorDetails=" + cancellation.getErrorDetails());
System.out.println("CANCELED: Did you update the subscription info?");
}
}
// </print_result>
// <skeleton_2>
} catch (Exception ex) {
System.out.println("Unexpected exception: " + ex.getMessage());
assert(false);
System.exit(1);
}
}
}
// </skeleton_2>
Skapa och köra din app
Tryck på F11 eller välj Kör>felsökning. Följande 15 sekunder av talindata från mikrofonen identifieras och loggas i konsolfönstret.
Referensdokumentation Paket (npm) | Ytterligare exempel på GitHub-bibliotekets källkod | |
I den här snabbstarten använder du Speech SDK och tjänsten Language Understanding (LUIS) för att identifiera avsikter från ljuddata som hämtats från en mikrofon. Mer specifikt använder du Speech SDK för att samla in tal och en fördefinierad domän från LUIS för att identifiera avsikter för hemautomatisering, till exempel att aktivera och inaktivera ett ljus.
Förutsättningar
- Azure-prenumeration – Skapa en kostnadsfritt
- Skapa en språkresurs i Azure-portalen. Du kan använda den kostnadsfria prisnivån (
F0) för att prova tjänsten och uppgradera senare till en betald nivå för produktion. Du behöver ingen Speech-resurs den här gången. - Hämta språkresursnyckeln och regionen. När språkresursen har distribuerats väljer du Gå till resurs för att visa och hantera nycklar. Mer information om Azure AI-tjänstresurser finns i Hämta nycklarna för din resurs.
Du måste också installera Speech SDK för utvecklingsmiljön och skapa ett tomt exempelprojekt.
Skapa en LUIS-app för avsiktsigenkänning
För att slutföra snabbstarten för avsiktsigenkänning måste du skapa ett LUIS-konto och ett projekt med hjälp av LUIS-förhandsversionsportalen. Den här snabbstarten kräver en LUIS-prenumeration i en region där avsiktsigenkänning är tillgänglig. En Speech-tjänstprenumeration krävs inte.
Det första du behöver göra är att skapa ett LUIS-konto och en app med hjälp av LUIS-förhandsversionsportalen. LUIS-appen som du skapar använder en fördefinierad domän för hemautomatisering, som innehåller avsikter, entiteter och exempelyttranden. När du är klar har du en LUIS-slutpunkt som körs i molnet som du kan anropa med hjälp av Speech SDK.
Följ de här anvisningarna för att skapa luis-appen:
När du är klar behöver du fyra saker:
- Publicera igen med talprimering aktiverat
- Din LUIS-primärnyckel
- Din LUIS-plats
- Ditt LUIS-app-ID
Här hittar du den här informationen i LUIS-förhandsversionsportalen:
Välj din app i luis-förhandsgranskningsportalen och välj sedan knappen Publicera .
Välj produktionsplatsenom du använder
en-USvälj ändra inställningar och växla alternativet Talprimering till läget På. Välj sedan knappen Publicera .Viktigt!
Talprimering rekommenderas starkt eftersom det förbättrar taligenkänningens noggrannhet.
I luis-förhandsversionsportalen väljer du Hantera och sedan Azure-resurser. På den här sidan hittar du luis-nyckeln och platsen (kallas ibland region) för luis-förutsägelseresursen.
När du har fått din nyckel och plats behöver du app-ID:t. Välj Inställningar. ditt app-ID är tillgängligt på den här sidan.
Börja med lite pannplåtskod
Nu ska vi lägga till kod som fungerar som ett skelett för vårt projekt.
<!DOCTYPE html>
<html>
<head>
<title>Microsoft Azure AI Speech SDK JavaScript Quickstart</title>
<meta charset="utf-8" />
</head>
<body style="font-family:'Helvetica Neue',Helvetica,Arial,sans-serif; font-size:13px;">
</body>
</html>
Lägga till gränssnittselement
Nu ska vi lägga till ett grundläggande användargränssnitt för indatarutor, referera till Speech SDK:s JavaScript och hämta en auktoriseringstoken om det är tillgängligt.
Viktigt!
Kom ihåg att ta bort nyckeln från koden när du är klar och publicera den aldrig offentligt. För produktion använder du ett säkert sätt att lagra och komma åt dina autentiseringsuppgifter som Azure Key Vault. Mer information finns i säkerhetsartikeln för Azure AI-tjänster.
<body style="font-family:'Helvetica Neue',Helvetica,Arial,sans-serif; font-size:13px;">
<div id="content" style="display:none">
<table width="100%">
<tr>
<td></td>
<td><h1 style="font-weight:500;">Microsoft Azure AI Speech SDK JavaScript Quickstart</h1></td>
</tr>
<tr>
<td align="right"><a href="https://learn.microsoft.com/azure/ai-services/speech-service/overview" target="_blank">Subscription</a>:</td>
<td><input id="subscriptionKey" type="text" size="40" value="subscription"></td>
</tr>
<tr>
<td align="right">Region</td>
<td><input id="serviceRegion" type="text" size="40" value="YourServiceRegion"></td>
</tr>
<tr>
<td align="right">Application ID:</td>
<td><input id="appId" type="text" size="60" value="YOUR_LANGUAGE_UNDERSTANDING_APP_ID"></td>
</tr>
<tr>
<td></td>
<td><button id="startIntentRecognizeAsyncButton">Start Intent Recognition</button></td>
</tr>
<tr>
<td align="right" valign="top">Input Text</td>
<td><textarea id="phraseDiv" style="display: inline-block;width:500px;height:200px"></textarea></td>
</tr>
<tr>
<td align="right" valign="top">Result</td>
<td><textarea id="statusDiv" style="display: inline-block;width:500px;height:100px"></textarea></td>
</tr>
</table>
</div>
<script src="microsoft.cognitiveservices.speech.sdk.bundle.js"></script>
<script>
// Note: Replace the URL with a valid endpoint to retrieve
// authorization tokens for your subscription.
var authorizationEndpoint = "token.php";
function RequestAuthorizationToken() {
if (authorizationEndpoint) {
var a = new XMLHttpRequest();
a.open("GET", authorizationEndpoint);
a.setRequestHeader("Content-Type", "application/x-www-form-urlencoded");
a.send("");
a.onload = function() {
var token = JSON.parse(atob(this.responseText.split(".")[1]));
serviceRegion.value = token.region;
authorizationToken = this.responseText;
subscriptionKey.disabled = true;
subscriptionKey.value = "using authorization token (hit F5 to refresh)";
console.log("Got an authorization token: " + token);
}
}
}
</script>
<script>
// status fields and start button in UI
var phraseDiv;
var statusDiv;
var startIntentRecognizeAsyncButton;
// subscription key, region, and appId for LUIS services.
var subscriptionKey, serviceRegion, appId;
var authorizationToken;
var SpeechSDK;
var recognizer;
document.addEventListener("DOMContentLoaded", function () {
startIntentRecognizeAsyncButton = document.getElementById("startIntentRecognizeAsyncButton");
subscriptionKey = document.getElementById("subscriptionKey");
serviceRegion = document.getElementById("serviceRegion");
appId = document.getElementById("appId");
phraseDiv = document.getElementById("phraseDiv");
statusDiv = document.getElementById("statusDiv");
startIntentRecognizeAsyncButton.addEventListener("click", function () {
startIntentRecognizeAsyncButton.disabled = true;
phraseDiv.innerHTML = "";
statusDiv.innerHTML = "";
});
if (!!window.SpeechSDK) {
SpeechSDK = window.SpeechSDK;
startIntentRecognizeAsyncButton.disabled = false;
document.getElementById('content').style.display = 'block';
document.getElementById('warning').style.display = 'none';
// in case we have a function for getting an authorization token, call it.
if (typeof RequestAuthorizationToken === "function") {
RequestAuthorizationToken();
}
}
});
</script>
Skapa en Speech-konfiguration
Innan du kan initiera ett SpeechRecognizer objekt måste du skapa en konfiguration som använder din prenumerationsnyckel och prenumerationsregion. Infoga den här koden i startRecognizeOnceAsyncButton.addEventListener() -metoden.
Kommentar
Speech SDK kommer som standard att känna igen med hjälp av en-us för språket, se Så här känner du igen tal för information om hur du väljer källspråket.
// if we got an authorization token, use the token. Otherwise use the provided subscription key
var speechConfig;
if (authorizationToken) {
speechConfig = SpeechSDK.SpeechConfig.fromAuthorizationToken(authorizationToken, serviceRegion.value);
} else {
if (subscriptionKey.value === "" || subscriptionKey.value === "subscription") {
alert("Please enter your Microsoft Azure AI Speech subscription key!");
return;
}
startIntentRecognizeAsyncButton.disabled = false;
speechConfig = SpeechSDK.SpeechConfig.fromSubscription(subscriptionKey.value, serviceRegion.value);
}
speechConfig.speechRecognitionLanguage = "en-US";
Skapa en ljudkonfiguration
Nu måste du skapa ett AudioConfig objekt som pekar på din indataenhet. Infoga den här koden i startIntentRecognizeAsyncButton.addEventListener() -metoden, precis under din Speech-konfiguration.
var audioConfig = SpeechSDK.AudioConfig.fromDefaultMicrophoneInput();
Initiera en IntentRecognizer
Nu ska vi skapa IntentRecognizer objektet med hjälp av objekten och AudioConfig som SpeechConfig skapades tidigare. Infoga den här koden i startIntentRecognizeAsyncButton.addEventListener() -metoden.
recognizer = new SpeechSDK.IntentRecognizer(speechConfig, audioConfig);
Lägg till en LanguageUnderstandingModel och avsikter
Du måste associera en LanguageUnderstandingModel med avsiktsigenkänningen och lägga till de avsikter som du vill ska identifieras. Vi ska använda avsikter från den fördefinierade domänen för hemautomatisering.
Infoga den här koden under din IntentRecognizer. Se till att du ersätter "YourLanguageUnderstandingAppId" med ditt LUIS-app-ID.
if (appId.value !== "" && appId.value !== "YOUR_LANGUAGE_UNDERSTANDING_APP_ID") {
var lm = SpeechSDK.LanguageUnderstandingModel.fromAppId(appId.value);
recognizer.addAllIntents(lm);
}
Kommentar
Speech SDK stöder endast LUIS v2.0-slutpunkter. Du måste ändra v3.0-slutpunkts-URL:en manuellt som finns i exempelfrågefältet för att använda ett v2.0-URL-mönster. LUIS v2.0-slutpunkter följer alltid något av följande två mönster:
https://{AzureResourceName}.cognitiveservices.azure.com/luis/v2.0/apps/{app-id}?subscription-key={subkey}&verbose=true&q=https://{Region}.api.cognitive.microsoft.com/luis/v2.0/apps/{app-id}?subscription-key={subkey}&verbose=true&q=
Identifiera en avsikt
Från - IntentRecognizer objektet anropar recognizeOnceAsync() du metoden. Den här metoden låter Speech-tjänsten veta att du skickar en enda fras för igenkänning och att när frasen har identifierats för att sluta känna igen tal.
Infoga den här koden under modelltillägget:
recognizer.recognizeOnceAsync(
function (result) {
window.console.log(result);
phraseDiv.innerHTML = result.text + "\r\n";
statusDiv.innerHTML += "(continuation) Reason: " + SpeechSDK.ResultReason[result.reason];
switch (result.reason) {
case SpeechSDK.ResultReason.RecognizedSpeech:
statusDiv.innerHTML += " Text: " + result.text;
break;
case SpeechSDK.ResultReason.RecognizedIntent:
statusDiv.innerHTML += " Text: " + result.text + " IntentId: " + result.intentId;
// The actual JSON returned from Language Understanding is a bit more complex to get to, but it is available for things like
// the entity name and type if part of the intent.
statusDiv.innerHTML += " Intent JSON: " + result.properties.getProperty(SpeechSDK.PropertyId.LanguageUnderstandingServiceResponse_JsonResult);
phraseDiv.innerHTML += result.properties.getProperty(SpeechSDK.PropertyId.LanguageUnderstandingServiceResponse_JsonResult) + "\r\n";
break;
case SpeechSDK.ResultReason.NoMatch:
var noMatchDetail = SpeechSDK.NoMatchDetails.fromResult(result);
statusDiv.innerHTML += " NoMatchReason: " + SpeechSDK.NoMatchReason[noMatchDetail.reason];
break;
case SpeechSDK.ResultReason.Canceled:
var cancelDetails = SpeechSDK.CancellationDetails.fromResult(result);
statusDiv.innerHTML += " CancellationReason: " + SpeechSDK.CancellationReason[cancelDetails.reason];
if (cancelDetails.reason === SpeechSDK.CancellationReason.Error) {
statusDiv.innerHTML += ": " + cancelDetails.errorDetails;
}
break;
}
statusDiv.innerHTML += "\r\n";
startIntentRecognizeAsyncButton.disabled = false;
},
function (err) {
window.console.log(err);
phraseDiv.innerHTML += "ERROR: " + err;
startIntentRecognizeAsyncButton.disabled = false;
});
Kontrollera koden
<!DOCTYPE html>
<html>
<head>
<title>Microsoft Cognitive Services Speech SDK JavaScript Quickstart</title>
<meta charset="utf-8" />
</head>
<body style="font-family:'Helvetica Neue',Helvetica,Arial,sans-serif; font-size:13px;">
<div id="warning">
<h1 style="font-weight:500;">Speech Recognition Speech SDK not found (microsoft.cognitiveservices.speech.sdk.bundle.js missing).</h1>
</div>
<div id="content" style="display:none">
<table width="100%">
<tr>
<td></td>
<td><h1 style="font-weight:500;">Microsoft Cognitive Services Speech SDK JavaScript Quickstart</h1></td>
</tr>
<tr>
<td align="right"><a href="https://docs.microsoft.com/azure/cognitive-services/speech-service/quickstarts/intent-recognition?pivots=programming-language-csharp#create-a-luis-app-for-intent-recognition" target="_blank">LUIS Primary Key</a>:</td>
<td><input id="subscriptionKey" type="text" size="40" value="subscription"></td>
</tr>
<tr>
<td align="right">LUIS Location</td>
<td><input id="serviceRegion" type="text" size="40" value="YourServiceRegion"></td>
</tr>
<tr>
<td align="right">LUIS App ID:</td>
<td><input id="appId" type="text" size="60" value="YOUR_LANGUAGE_UNDERSTANDING_APP_ID"></td>
</tr>
<tr>
<td></td>
<td><button id="startIntentRecognizeAsyncButton">Start Intent Recognition</button></td>
</tr>
<tr>
<td align="right" valign="top">Input Text</td>
<td><textarea id="phraseDiv" style="display: inline-block;width:500px;height:200px"></textarea></td>
</tr>
<tr>
<td align="right" valign="top">Result</td>
<td><textarea id="statusDiv" style="display: inline-block;width:500px;height:100px"></textarea></td>
</tr>
</table>
</div>
<!-- Speech SDK reference sdk. -->
<script src="https://aka.ms/csspeech/jsbrowserpackageraw"></script>
<!-- Speech SDK USAGE -->
<script>
// status fields and start button in UI
var phraseDiv;
var statusDiv;
var startIntentRecognizeAsyncButton;
// subscription key and region for speech services.
var subscriptionKey, serviceRegion, appId;
var SpeechSDK;
var recognizer;
document.addEventListener("DOMContentLoaded", function () {
startIntentRecognizeAsyncButton = document.getElementById("startIntentRecognizeAsyncButton");
subscriptionKey = document.getElementById("subscriptionKey");
serviceRegion = document.getElementById("serviceRegion");
appId = document.getElementById("appId");
phraseDiv = document.getElementById("phraseDiv");
statusDiv = document.getElementById("statusDiv");
startIntentRecognizeAsyncButton.addEventListener("click", function () {
startIntentRecognizeAsyncButton.disabled = true;
phraseDiv.innerHTML = "";
statusDiv.innerHTML = "";
let audioConfig = SpeechSDK.AudioConfig.fromDefaultMicrophoneInput();
if (subscriptionKey.value === "" || subscriptionKey.value === "subscription") {
alert("Please enter your Microsoft Cognitive Services Speech subscription key!");
startIntentRecognizeAsyncButton.disabled = false;
return;
}
var speechConfig = SpeechSDK.SpeechConfig.fromSubscription(subscriptionKey.value, serviceRegion.value);
speechConfig.speechRecognitionLanguage = "en-US";
recognizer = new SpeechSDK.IntentRecognizer(speechConfig, audioConfig);
// Set up a Language Understanding Model from Language Understanding Intelligent Service (LUIS).
// See https://www.luis.ai/home for more information on LUIS.
if (appId.value !== "" && appId.value !== "YOUR_LANGUAGE_UNDERSTANDING_APP_ID") {
var lm = SpeechSDK.LanguageUnderstandingModel.fromAppId(appId.value);
recognizer.addAllIntents(lm);
}
recognizer.recognizeOnceAsync(
function (result) {
window.console.log(result);
phraseDiv.innerHTML = result.text + "\r\n";
statusDiv.innerHTML += "(continuation) Reason: " + SpeechSDK.ResultReason[result.reason];
switch (result.reason) {
case SpeechSDK.ResultReason.RecognizedSpeech:
statusDiv.innerHTML += " Text: " + result.text;
break;
case SpeechSDK.ResultReason.RecognizedIntent:
statusDiv.innerHTML += " Text: " + result.text + " IntentId: " + result.intentId;
// The actual JSON returned from Language Understanding is a bit more complex to get to, but it is available for things like
// the entity name and type if part of the intent.
statusDiv.innerHTML += " Intent JSON: " + result.properties.getProperty(SpeechSDK.PropertyId.LanguageUnderstandingServiceResponse_JsonResult);
phraseDiv.innerHTML += result.properties.getProperty(SpeechSDK.PropertyId.LanguageUnderstandingServiceResponse_JsonResult) + "\r\n";
break;
case SpeechSDK.ResultReason.NoMatch:
var noMatchDetail = SpeechSDK.NoMatchDetails.fromResult(result);
statusDiv.innerHTML += " NoMatchReason: " + SpeechSDK.NoMatchReason[noMatchDetail.reason];
break;
case SpeechSDK.ResultReason.Canceled:
var cancelDetails = SpeechSDK.CancellationDetails.fromResult(result);
statusDiv.innerHTML += " CancellationReason: " + SpeechSDK.CancellationReason[cancelDetails.reason];
if (cancelDetails.reason === SpeechSDK.CancellationReason.Error) {
statusDiv.innerHTML += ": " + cancelDetails.errorDetails;
}
break;
}
statusDiv.innerHTML += "\r\n";
startIntentRecognizeAsyncButton.disabled = false;
},
function (err) {
window.console.log(err);
phraseDiv.innerHTML += "ERROR: " + err;
startIntentRecognizeAsyncButton.disabled = false;
});
});
if (!!window.SpeechSDK) {
SpeechSDK = window.SpeechSDK;
startIntentRecognizeAsyncButton.disabled = false;
document.getElementById('content').style.display = 'block';
document.getElementById('warning').style.display = 'none';
}
});
</script>
</body>
</html>
Skapa tokenkälla (valfritt)
Om du vill värdbasera webbsidan på en webbserver kan du ange en tokenkälla för demoappen. På så sätt lämnar prenumerationen aldrig servern och tillåter att användare använder talfunktioner utan att själva behöva ange en auktoriseringskod.
Skapa en ny fil med namnet token.php. I det här exemplet förutsätter vi att webbservern stöder PHP-skriptspråket med curl aktiverat. Ange följande kod:
<?php
header('Access-Control-Allow-Origin: ' . $_SERVER['SERVER_NAME']);
// Replace with your own subscription key and service region (e.g., "westus").
$subscriptionKey = 'YourSubscriptionKey';
$region = 'YourServiceRegion';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'https://' . $region . '.api.cognitive.microsoft.com/sts/v1.0/issueToken');
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, '{}');
curl_setopt($ch, CURLOPT_HTTPHEADER, array('Content-Type: application/json', 'Ocp-Apim-Subscription-Key: ' . $subscriptionKey));
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
echo curl_exec($ch);
?>
Kommentar
Auktoriseringstoken har en begränsad livslängd. Det här förenklade exemplet visar inte hur du uppdaterar auktoriseringstoken automatiskt. Som användare kan du manuellt läsa in sidan igen eller trycka på F5 för att uppdatera.
Skapa och köra exemplet lokalt
Starta appen genom att dubbelklicka på index.html-filen eller öppna index.html med valfri webbläsare. Det kommer att presentera ett enkelt GUI som gör att du kan ange din LUIS-nyckel, LUIS-region och LUIS-program-ID. När dessa fält har angetts kan du klicka på lämplig knapp för att utlösa en igenkänning med mikrofonen.
Kommentar
Den här metoden fungerar inte i Webbläsaren Safari. På Safari måste exempelwebbsidan finnas på en webbserver. Safari tillåter inte att webbplatser som läses in från en lokal fil använder mikrofonen.
Skapa och köra exemplet via en webbserver
Om du vill starta din app öppnar du din favoritwebbläsare och pekar den på den offentliga URL:en som du är värd för mappen på, anger din LUIS-region samt ditt LUIS-program-ID och utlöser en igenkänning med mikrofonen. Om det konfigureras hämtas en token från din tokenkälla och du börjar känna igen talade kommandon.
Referensdokumentation Paket (PyPi) | Ytterligare exempel på GitHub |
I den här snabbstarten använder du Speech SDK och tjänsten Language Understanding (LUIS) för att identifiera avsikter från ljuddata som hämtats från en mikrofon. Mer specifikt använder du Speech SDK för att samla in tal och en fördefinierad domän från LUIS för att identifiera avsikter för hemautomatisering, till exempel att aktivera och inaktivera ett ljus.
Förutsättningar
- Azure-prenumeration – Skapa en kostnadsfritt
- Skapa en språkresurs i Azure-portalen. Du kan använda den kostnadsfria prisnivån (
F0) för att prova tjänsten och uppgradera senare till en betald nivå för produktion. Du behöver ingen Speech-resurs den här gången. - Hämta språkresursnyckeln och regionen. När språkresursen har distribuerats väljer du Gå till resurs för att visa och hantera nycklar. Mer information om Azure AI-tjänstresurser finns i Hämta nycklarna för din resurs.
Du måste också installera Speech SDK för utvecklingsmiljön och skapa ett tomt exempelprojekt.
Skapa en LUIS-app för avsiktsigenkänning
För att slutföra snabbstarten för avsiktsigenkänning måste du skapa ett LUIS-konto och ett projekt med hjälp av LUIS-förhandsversionsportalen. Den här snabbstarten kräver en LUIS-prenumeration i en region där avsiktsigenkänning är tillgänglig. En Speech-tjänstprenumeration krävs inte.
Det första du behöver göra är att skapa ett LUIS-konto och en app med hjälp av LUIS-förhandsversionsportalen. LUIS-appen som du skapar använder en fördefinierad domän för hemautomatisering, som innehåller avsikter, entiteter och exempelyttranden. När du är klar har du en LUIS-slutpunkt som körs i molnet som du kan anropa med hjälp av Speech SDK.
Följ de här anvisningarna för att skapa luis-appen:
När du är klar behöver du fyra saker:
- Publicera igen med talprimering aktiverat
- Din LUIS-primärnyckel
- Din LUIS-plats
- Ditt LUIS-app-ID
Här hittar du den här informationen i LUIS-förhandsversionsportalen:
Välj din app i luis-förhandsgranskningsportalen och välj sedan knappen Publicera .
Välj produktionsplatsenom du använder
en-USvälj ändra inställningar och växla alternativet Talprimering till läget På. Välj sedan knappen Publicera .Viktigt!
Talprimering rekommenderas starkt eftersom det förbättrar taligenkänningens noggrannhet.
I luis-förhandsversionsportalen väljer du Hantera och sedan Azure-resurser. På den här sidan hittar du luis-nyckeln och platsen (kallas ibland region) för luis-förutsägelseresursen.
När du har fått din nyckel och plats behöver du app-ID:t. Välj Inställningar. ditt app-ID är tillgängligt på den här sidan.
Öppna ditt projekt
- Öppna önskad IDE.
- Skapa ett nytt projekt och skapa filen med namnet
quickstart.pyoch öppna det sedan.
Börja med lite pannplåtskod
Nu ska vi lägga till kod som fungerar som ett skelett för vårt projekt.
import azure.cognitiveservices.speech as speechsdk
print("Say something...")
Skapa en Speech-konfiguration
Innan du kan initiera ett IntentRecognizer objekt måste du skapa en konfiguration som använder nyckeln och platsen för luis-förutsägelseresursen.
Infoga den här koden i quickstart.py. Se till att du uppdaterar dessa värden:
- Ersätt
"YourLanguageUnderstandingSubscriptionKey"med din LUIS-förutsägelsenyckel. - Ersätt
"YourLanguageUnderstandingServiceRegion"med din LUIS-plats. Använda regionidentifierare från region
Dricks
Om du behöver hjälp med att hitta dessa värden kan du läsa Skapa en LUIS-app för avsiktsigenkänning.
Viktigt!
Kom ihåg att ta bort nyckeln från koden när du är klar och publicera den aldrig offentligt. För produktion använder du ett säkert sätt att lagra och komma åt dina autentiseringsuppgifter som Azure Key Vault. Mer information finns i säkerhetsartikeln för Azure AI-tjänster.
# Set up the config for the intent recognizer (remember that this uses the Language Understanding key, not the Speech Services key)!
intent_config = speechsdk.SpeechConfig(
subscription="YourLanguageUnderstandingSubscriptionKey",
region="YourLanguageUnderstandingServiceRegion")
Det här exemplet konstruerar SpeechConfig objektet med hjälp av LUIS-nyckel och region. En fullständig lista över tillgängliga metoder finns i Klassen SpeechConfig.
Speech SDK kommer som standard att känna igen med hjälp av en-us för språket, se Så här känner du igen tal för information om hur du väljer källspråket.
Initiera en IntentRecognizer
Nu ska vi skapa en IntentRecognizer. Infoga den här koden precis under din Speech-konfiguration.
# Set up the intent recognizer
intent_recognizer = speechsdk.intent.IntentRecognizer(speech_config=intent_config)
Lägg till en LanguageUnderstandingModel och avsikter
Du måste associera en LanguageUnderstandingModel med avsiktsigenkänningen och lägga till de avsikter som du vill ska identifieras. Vi ska använda avsikter från den fördefinierade domänen för hemautomatisering.
Infoga den här koden under din IntentRecognizer. Se till att du ersätter "YourLanguageUnderstandingAppId" med ditt LUIS-app-ID.
Dricks
Om du behöver hjälp med att hitta det här värdet kan du läsa Skapa en LUIS-app för avsiktsigenkänning.
# set up the intents that are to be recognized. These can be a mix of simple phrases and
# intents specified through a LanguageUnderstanding Model.
model = speechsdk.intent.LanguageUnderstandingModel(app_id="YourLanguageUnderstandingAppId")
intents = [
(model, "HomeAutomation.TurnOn"),
(model, "HomeAutomation.TurnOff"),
("This is a test.", "test"),
("Switch to channel 34.", "34"),
("what's the weather like", "weather"),
]
intent_recognizer.add_intents(intents)
I det add_intents() här exemplet används funktionen för att lägga till en lista över explicit definierade avsikter. Om du vill lägga till alla avsikter från en modell använder add_all_intents(model) du och skickar modellen.
Identifiera en avsikt
Från - IntentRecognizer objektet anropar recognize_once() du metoden. Den här metoden låter Speech-tjänsten veta att du skickar en enda fras för igenkänning och att när frasen har identifierats för att sluta känna igen tal.
Infoga den här koden under din modell.
intent_result = intent_recognizer.recognize_once()
Visa igenkänningsresultaten (eller felen)
När igenkänningsresultatet returneras av Speech-tjänsten vill du göra något med det. Vi ska hålla det enkelt och skriva ut resultatet till konsolen.
Lägg till den här koden under anropet till recognize_once().
# Check the results
if intent_result.reason == speechsdk.ResultReason.RecognizedIntent:
print("Recognized: \"{}\" with intent id `{}`".format(intent_result.text, intent_result.intent_id))
elif intent_result.reason == speechsdk.ResultReason.RecognizedSpeech:
print("Recognized: {}".format(intent_result.text))
elif intent_result.reason == speechsdk.ResultReason.NoMatch:
print("No speech could be recognized: {}".format(intent_result.no_match_details))
elif intent_result.reason == speechsdk.ResultReason.Canceled:
print("Intent recognition canceled: {}".format(intent_result.cancellation_details.reason))
if intent_result.cancellation_details.reason == speechsdk.CancellationReason.Error:
print("Error details: {}".format(intent_result.cancellation_details.error_details))
Kontrollera koden
Nu bör koden se ut så här.
Kommentar
Vi har lagt till några kommentarer i den här versionen.
# Copyright (c) Microsoft. All rights reserved.
# Licensed under the MIT license. See LICENSE.md file in the project root for full license information.
# <skeleton>
import azure.cognitiveservices.speech as speechsdk
print("Say something...")
# </skeleton>
"""performs one-shot intent recognition from input from the default microphone"""
# <create_speech_configuration>
# Set up the config for the intent recognizer (remember that this uses the Language Understanding key, not the Speech Services key)!
intent_config = speechsdk.SpeechConfig(
subscription="YourLanguageUnderstandingSubscriptionKey",
region="YourLanguageUnderstandingServiceRegion")
# </create_speech_configuration>
# <create_intent_recognizer>
# Set up the intent recognizer
intent_recognizer = speechsdk.intent.IntentRecognizer(speech_config=intent_config)
# </create_intent_recognizer>
# <add_intents>
# set up the intents that are to be recognized. These can be a mix of simple phrases and
# intents specified through a LanguageUnderstanding Model.
model = speechsdk.intent.LanguageUnderstandingModel(app_id="YourLanguageUnderstandingAppId")
intents = [
(model, "HomeAutomation.TurnOn"),
(model, "HomeAutomation.TurnOff"),
("This is a test.", "test"),
("Switch to channel 34.", "34"),
("what's the weather like", "weather"),
]
intent_recognizer.add_intents(intents)
# </add_intents>
# To add all of the possible intents from a LUIS model to the recognizer, uncomment the line below:
# intent_recognizer.add_all_intents(model)
# Starts intent recognition, and returns after a single utterance is recognized. The end of a
# single utterance is determined by listening for silence at the end or until a maximum of 15
# seconds of audio is processed. It returns the recognition text as result.
# Note: Since recognize_once() returns only a single utterance, it is suitable only for single
# shot recognition like command or query.
# For long-running multi-utterance recognition, use start_continuous_recognition() instead.
# <recognize_intent>
intent_result = intent_recognizer.recognize_once()
# </recognize_intent>
# <print_results>
# Check the results
if intent_result.reason == speechsdk.ResultReason.RecognizedIntent:
print("Recognized: \"{}\" with intent id `{}`".format(intent_result.text, intent_result.intent_id))
elif intent_result.reason == speechsdk.ResultReason.RecognizedSpeech:
print("Recognized: {}".format(intent_result.text))
elif intent_result.reason == speechsdk.ResultReason.NoMatch:
print("No speech could be recognized: {}".format(intent_result.no_match_details))
elif intent_result.reason == speechsdk.ResultReason.Canceled:
print("Intent recognition canceled: {}".format(intent_result.cancellation_details.reason))
if intent_result.cancellation_details.reason == speechsdk.CancellationReason.Error:
print("Error details: {}".format(intent_result.cancellation_details.error_details))
# </print_results>
Skapa och köra din app
Kör exemplet från konsolen eller i din IDE:
python quickstart.py
Följande 15 sekunder av talindata från mikrofonen identifieras och loggas i konsolfönstret.
Referensdokumentation Paket (Go) | Ytterligare exempel på GitHub |
Speech SDK för Go stöder inte avsiktsigenkänning. Välj ett annat programmeringsspråk eller Go-referensen och exempel som är länkade från början av den här artikeln.
Referensdokumentationspaket (ladda ned) | Ytterligare exempel på GitHub |
Speech SDK för Objective-C stöder avsiktsigenkänning, men vi har ännu inte tagit med någon guide här. Välj ett annat programmeringsspråk för att komma igång och lära dig mer om begreppen, eller se Objective-C-referensen och exemplen som är länkade från början av den här artikeln.
Referensdokumentationspaket (ladda ned) | Ytterligare exempel på GitHub |
Speech SDK för Swift stöder avsiktsigenkänning, men vi har ännu inte tagit med någon guide här. Välj ett annat programmeringsspråk för att komma igång och lära dig mer om begreppen, eller se Swift-referensen och exemplen som är länkade från början av den här artikeln.
REST API för tal till text refererar | till REST API för tal till text för kort ljudreferens | Ytterligare exempel på GitHub
Du kan använda REST-API:et för avsiktsigenkänning, men vi har ännu inte tagit med någon guide här. Välj ett annat programmeringsspråk för att komma igång och lära dig mer om begreppen.
Cli (Speech Command Line Interface) stöder avsiktsigenkänning, men vi har ännu inte tagit med någon guide här. Välj ett annat programmeringsspråk för att komma igång och lära dig mer om begreppen, eller se Översikt över Speech CLI för mer information om CLI.