Anpassad translator för nybörjare
Med Custom Translator kan du skapa ett översättningssystem som återspeglar din affärs-, bransch- och domänspecifika terminologi och stil. Det är enkelt att träna och distribuera ett anpassat system och kräver inga programmeringskunskaper. Det anpassade översättningssystemet integreras sömlöst i dina befintliga program, arbetsflöden och webbplatser och är tillgängligt i Azure via samma molnbaserade Microsoft Text Translation API-tjänst som driver miljarder översättningar varje dag.
Plattformen gör det möjligt för användare att skapa och publicera anpassade översättningssystem till och från engelska. Custom Translator stöder fler än 60 språk som mappar direkt till de språk som är tillgängliga för NMT. En fullständig lista finns i Stöd för Translator-språk.
Är en anpassad översättningsmodell rätt val för mig?
En vältränad anpassad översättningsmodell ger mer exakta domänspecifika översättningar eftersom den förlitar sig på tidigare översatta dokument i domänen för att lära sig föredragna översättningar. Translator använder dessa termer och fraser i kontext för att producera flytande översättningar på målspråket samtidigt som kontextberoende grammatik respekteras.
Träning av en fullständig anpassad översättningsmodell kräver en stor mängd data. Om du inte har minst 10 000 meningar av tidigare tränade dokument kan du inte träna en översättningsmodell med fullständigt språk. Du kan dock antingen träna en ordlistemodell eller använda de högkvalitativa, färdiga översättningarna som är tillgängliga med API:et för textöversättning.
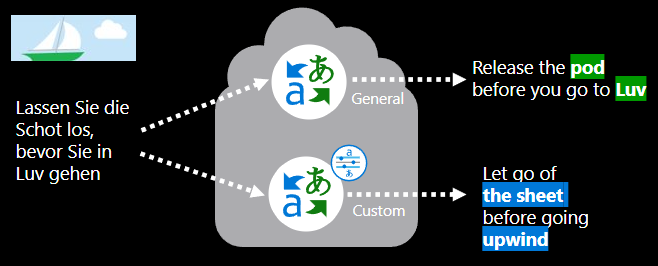
Vad innebär träning av en anpassad översättningsmodell?
För att skapa en anpassad översättningsmodell krävs följande:
Förstå ditt användningsfall.
Hämta översatta data i domänen (helst översätts av människor).
Möjlighet att utvärdera översättningskvalitet eller målspråköversättningar.
Hur utvärderar jag mitt användningsfall?
Att ha klarhet i ditt användningsfall och hur framgång ser ut är det första steget mot att få fram bra träningsdata. Här följer några saker att tänka på:
Vad är ditt önskade resultat och hur mäter du det?
Vad är din affärsdomän?
Har du meningar i domänen med liknande terminologi och stil?
Omfattar ditt användningsfall flera domäner? Om ja, bör du skapa ett översättningssystem eller flera system?
Har du krav som påverkar regionalt datahemvist i vila och under överföring?
Är målanvändare i en eller flera regioner?
Hur ska jag hämta mina data?
Att hitta kvalitetsdata i domänen är ofta en utmanande uppgift som varierar beroende på användarklassificering. Här följer några frågor som du kan ställa dig själv när du utvärderar vilka data som kan vara tillgängliga för dig:
Företag har ofta en mängd översättningsdata som har ackumulerats under många års användning av mänsklig översättning. Har ditt företag tidigare översättningsdata tillgängliga som du kan använda?
Har du en stor mängd enspråkiga data? Enspråkiga data är endast data på ett språk. Kan du i så fall få översättningar för dessa data?
Kan du crawla onlineportaler för att samla in käll meningar och syntetisera mål meningar?
Vad ska jag använda för utbildningsmaterial?
| Källa | Vad den gör | Regler att följa |
|---|---|---|
| Tvåspråkiga utbildningsdokument | Lär systemet din terminologi och stil. | Var liberal. All mänsklig översättning i domänen är bättre än maskinöversättning. Lägg till och ta bort dokument när du går och försök att förbättra BLEU-poängen. |
| Justera dokument | Tränar parametrarna för neural maskinöversättning. | Var strikt. Skriv dem för att vara optimalt representativa för vad du kommer att översätta i framtiden. |
| Testa dokument | Beräkna BLEU-poängen. | Var strikt. Skapa testdokument för att vara optimalt representativa för vad du planerar att översätta i framtiden. |
| Frasordlista | Tvingar den angivna översättningen 100 % av tiden. | Var restriktiv. En frasordlista är skiftlägeskänslig och alla ord eller fraser i listan översätts på det sätt som du anger. I många fall är det bättre att inte använda en frasordlista och låta systemet lära sig. |
| Meningsordlista | Tvingar den angivna översättningen 100 % av tiden. | Var strikt. En meningsordlista är skiftlägeskänslig och bra för vanliga korta meningar i domänen. För att en meningsordlistematchning ska inträffa måste hela den skickade meningen matcha posten i källordlistan. Om endast en del av meningen matchar matchar inte posten. |
Vad är en BLEU-poäng?
BLEU (Tvåspråkig utvärderingsunderstudy) är en algoritm för att utvärdera precisionen eller noggrannheten för text som har maskinöversatts från ett språk till ett annat. Custom Translator använder BLEU-måttet som ett sätt att förmedla översättningsnoggrannhet.
En BLEU-poäng är ett tal mellan noll och 100. En poäng på noll anger en översättning av låg kvalitet där ingenting i översättningen matchade referensen. Poängen 100 anger en perfekt översättning som är identisk med referensen. Det är inte nödvändigt att uppnå en poäng på 100 - en BLEU-poäng mellan 40 och 60 indikerar en högkvalitativ översättning.
Vad händer om jag inte skickar in justerings- eller testdata?
Justerings- och test meningar är optimalt representativa för vad du planerar att översätta i framtiden. Om du inte skickar in några justerings- eller testdata utesluter Custom Translator automatiskt meningar från dina träningsdokument som ska användas som justerings- och testdata.
| Systemgenererad | Manuell markering |
|---|---|
| Praktisk. | Möjliggör finjustering för dina framtida behov. |
| Bra, om du vet att dina träningsdata är representativa för vad du planerar att översätta. | Ger större frihet att skriva dina träningsdata. |
| Lätt att göra om när du växer eller krymper domänen. | Möjliggör mer data och bättre domäntäckning. |
| Ändrar varje träningskörning. | Förblir statisk över upprepade träningskörningar |
Hur bearbetas utbildningsmaterial av Custom Translator?
För att förbereda för träning genomgår dokumenten en rad bearbetnings- och filtreringssteg. De här stegen beskrivs nedan. Kunskap om filtreringsprocessen kan hjälpa dig att förstå antalet meningar som visas samt de steg du kan vidta för att förbereda träningsdokument för träning med Custom Translator.
Meningsjustering
Om dokumentet inte är i XLIFF-, XLSX-, TMX- eller ALIGN-format justerar Custom Translator meningarna i käll- och måldokumenten mot varandra, mening för mening. Translator utför inte dokumentjustering – det följer din namngivningskonvention för dokumenten för att hitta ett matchande dokument på det andra språket. I källtexten försöker Custom Translator hitta motsvarande mening på målspråket. Den använder dokumentmarkering som inbäddade HTML-taggar för att hjälpa till med justeringen.
Om du ser en stor avvikelse mellan antalet meningar i käll- och måldokumenten kanske källdokumentet inte är parallellt eller inte kan justeras. Dokumentet parar ihop med en stor skillnad (>10 %) av meningarna på varje sida garanterar en andra titt för att se till att de verkligen är parallella.
Extrahera justerings- och testdata
Det är valfritt att justera och testa data. Om du inte anger det tar systemet bort en lämplig procentandel från dina träningsdokument som ska användas för justering och testning. Borttagningen sker dynamiskt som en del av träningsprocessen. Eftersom det här steget sker som en del av träningen påverkas inte dina uppladdade dokument. Du kan se de sista använda meningsantalen för varje kategori av data – träning, justering, testning och ordlista – på sidan Modellinformation när träningen har slutförts.
Längdfilter
- Tar bort meningar med bara ett ord på vardera sidan.
- Tar bort meningar med mer än 100 ord på vardera sidan. Kinesiska, japanska, koreanska är undantagna.
- Tar bort meningar med färre än tre tecken. Kinesiska, japanska, koreanska är undantagna.
- Tar bort meningar med mer än 2 000 tecken för kinesiska, japanska, koreanska.
- Tar bort meningar med mindre än 1 % alfanumeriska tecken.
- Tar bort ordlisteposter som innehåller fler än 50 ord.
Tomt utrymme
- Ersätter alla sekvenser med blankstegstecken, inklusive flikar och CR/LF-sekvenser med ett enda blankstegstecken.
- Tar bort inledande eller avslutande blanksteg i meningen.
Skiljetecken för meningsslut
Ersätter flera meningssluts skiljetecken med en enda instans. Japansk teckennormalisering.
Konverterar bokstäver och siffror med full bredd till tecken med halv bredd.
Xml-taggar som inte är kapslade
Omvandlar ej kapslade taggar till undantagna taggar:
Tagg Blir < & Lt; > & Gt; & & ampere; Ogiltiga tecken
Custom Translator tar bort meningar som innehåller Unicode-tecknet U+FFFD. Tecknet U+FFFD anger en misslyckad kodningskonvertering.
Vilka åtgärder ska jag vidta innan jag laddar upp data?
- Ta bort meningar med ogiltig kodning.
- Ta bort Unicode-kontrolltecken.
- Om möjligt justerar du meningar (källa till mål).
- Ta bort käll- och mål meningar som inte matchar käll- och målspråken.
- När käll- och mål meningar har blandade språk kontrollerar du att oöversatta ord är avsiktliga, till exempel namn på organisationer och produkter.
- Korrigera grammatiska och typografiska fel för att förhindra att dessa fel lärs ut till din modell.
- Även om vår träningsprocess hanterar käll- och målrader som innehåller flera meningar är det bättre att ha en källdom mappad till en måldom.
Hur utvärderar jag resultatet?
När din modell har tränats kan du visa modellens BLEU-poäng och baslinjemodellens BLEU-poäng på sidan med modellinformation. Vi använder samma uppsättning testdata för att generera både modellens BLEU-poäng och baslinje-BLEU-poängen. Dessa data hjälper dig att fatta ett välgrundat beslut om vilken modell som skulle vara bättre för ditt användningsfall.
Nästa steg
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för