Innehållsfiltrering i Azure AI Studio
Viktigt!
Vissa av de funktioner som beskrivs i den här artikeln kanske bara är tillgängliga i förhandsversionen. Den här förhandsversionen tillhandahålls utan ett serviceavtal och vi rekommenderar det inte för produktionsarbetsbelastningar. Vissa funktioner kanske inte stöds eller kan vara begränsade. Mer information finns i Kompletterande villkor för användning av Microsoft Azure-förhandsversioner.
Azure AI Studio innehåller ett system för innehållsfiltrering som fungerar tillsammans med kärnmodeller och DALL-E-bildgenereringsmodeller.
Viktigt!
Innehållsfiltreringssystemet tillämpas inte på frågor och slutföranden som bearbetas av Whisper-modellen i Azure OpenAI Service. Läs mer om Whisper-modellen i Azure OpenAI.
Hur det fungerar
Det här innehållsfiltreringssystemet drivs av Azure AI Content Safety och fungerar genom att köra både promptindata och slutförandeutdata via en uppsättning klassificeringsmodeller som syftar till att identifiera och förhindra utdata från skadligt innehåll. Variationer i API-konfigurationer och programdesign kan påverka slutföranden och därmed filtreringsbeteende.
Med Azure OpenAI-modelldistributioner kan du använda standardinnehållsfiltret eller skapa ett eget innehållsfilter (beskrivs senare). Standardinnehållsfiltret är också tillgängligt för andra textmodeller som har kurerats av Azure AI i modellkatalogen, men anpassade innehållsfilter är ännu inte tillgängliga för dessa modeller. Modeller som är tillgängliga via Modeller som en tjänst har innehållsfiltrering aktiverat som standard och kan inte konfigureras.
Språkstöd
Innehållsfiltreringsmodellerna har tränats och testats på följande språk: engelska, tyska, japanska, spanska, franska, italienska, portugisiska och kinesiska. Tjänsten kan dock fungera på många andra språk, men kvaliteten kan variera. I samtliga fall bör du göra dina egna tester för att säkerställa att det fungerar för ditt program.
Skapa ett innehållsfilter
För alla modelldistributioner i Azure AI Studio kan du använda standardinnehållsfiltret direkt, men du kanske vill ha mer kontroll. Du kan till exempel göra ett filter striktare eller mer överseende, eller aktivera mer avancerade funktioner som promptsköldar och skyddad materialidentifiering.
Följ dessa steg för att skapa ett innehållsfilter:
Gå till AI Studio och gå till din hubb. Välj sedan fliken Innehållsfilter i det vänstra navigeringsfältet och välj knappen Skapa innehållsfilter .

På sidan Grundläggande information anger du ett namn för innehållsfiltret. Välj en anslutning som ska associeras med innehållsfiltret. Välj sedan Nästa.
På sidan Indatafilter kan du ange filtret för indataprompten. Ange tröskelvärdet för åtgärds- och allvarlighetsgrad för varje filtertyp. Du konfigurerar både standardfilter och andra filter (till exempel Prompt Shields for jailbreak attacks) på den här sidan. Välj sedan Nästa.

Innehållet kommenteras efter kategori och blockeras enligt det tröskelvärde som du anger. För kategorierna våld, hat, sexuell och självskadebeteende justerar du skjutreglaget för att blockera innehåll av hög, medel eller låg allvarlighetsgrad.
På sidan Utdatafilter kan du konfigurera utdatafiltret, som ska tillämpas på allt utdatainnehåll som genereras av din modell. Konfigurera de enskilda filtren som tidigare. Den här sidan innehåller också alternativet Strömningsläge, vilket gör att du kan filtrera innehåll nästan i realtid eftersom det genereras av modellen, vilket minskar svarstiden. När du är klar väljer du Nästa.
Innehållet kommenteras av varje kategori och blockeras enligt tröskelvärdet. För våldsamt innehåll, hatinnehåll, sexuellt innehåll och självskadebeteende, justerar du tröskelvärdet för att blockera skadligt innehåll med samma eller högre allvarlighetsgrad.
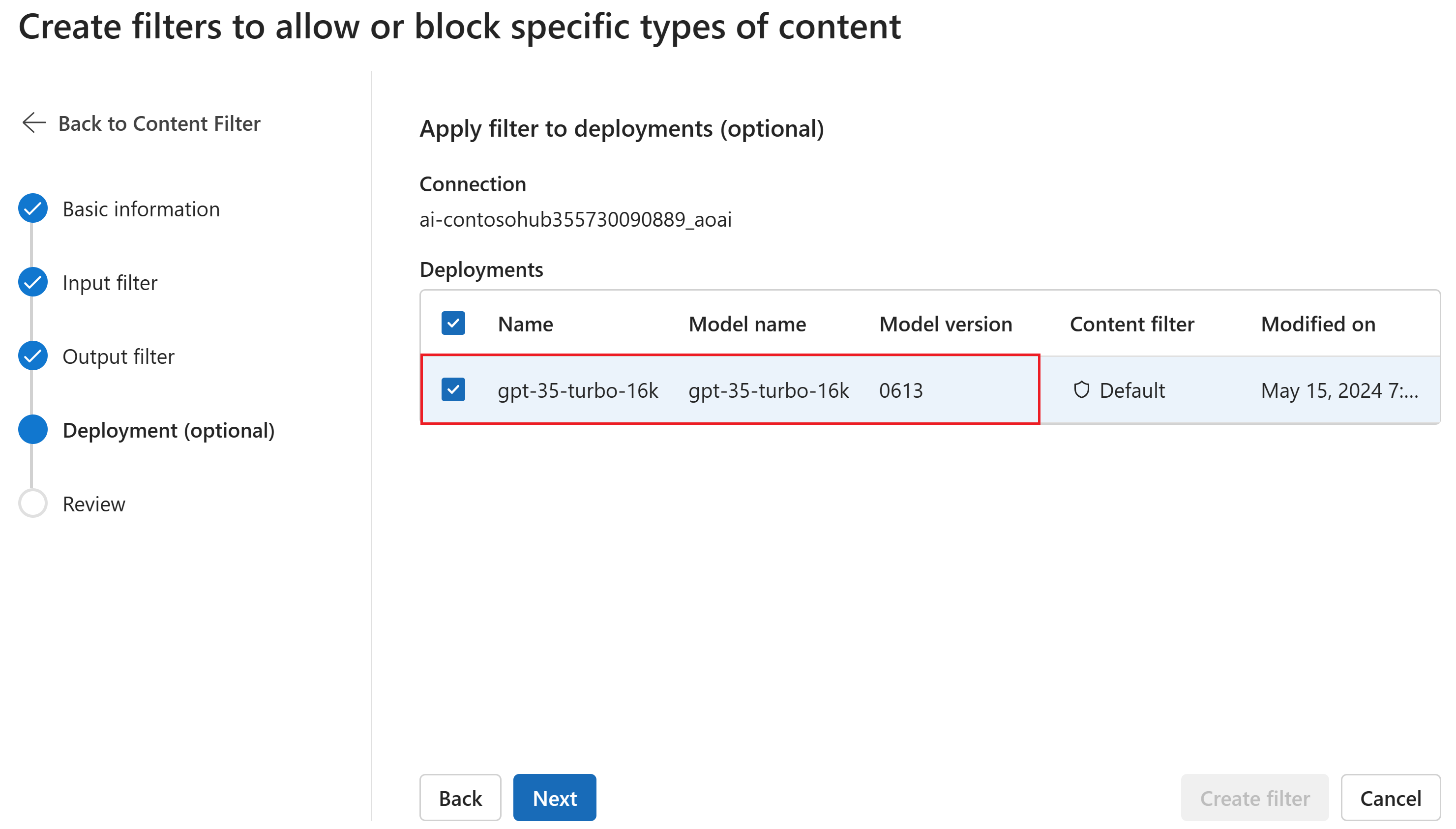
På sidan Distribution kan du också associera innehållsfiltret med en distribution. Om en vald distribution redan har ett filter kopplat måste du bekräfta att du vill ersätta den. Du kan också associera innehållsfiltret med en distribution senare. Välj Skapa.
Konfigurationer för innehållsfiltrering skapas på hubbnivå i AI Studio. Läs mer om konfigurerbarhet i Azure OpenAI-dokumenten.
På sidan Granska granskar du inställningarna och väljer sedan Skapa filter.




Använda en blockeringslista som ett filter
Du kan använda en blocklista som antingen ett indata- eller utdatafilter eller båda. Aktivera alternativet Blocklist på sidan Indatafilter och/eller Utdatafilter. Välj en eller flera blocklistor i listrutan eller använd den inbyggda listan över svordomar. Du kan kombinera flera blocklistor i samma filter.
Använda ett innehållsfilter
Processen för att skapa filter ger dig möjlighet att tillämpa filtret på de distributioner du vill använda. Du kan också ändra eller ta bort innehållsfilter från dina distributioner när som helst.
Följ dessa steg för att tillämpa ett innehållsfilter på en distribution:
Gå till AI Studio och välj ett projekt.
Välj Distributioner och välj en av dina distributioner och välj sedan Redigera.

I fönstret Uppdateringsdistribution väljer du det innehållsfilter som du vill använda för distributionen.



Nu kan du gå till lekplatsen för att testa om innehållsfiltret fungerar som förväntat.
Kategorier
| Kategori | beskrivning |
|---|---|
| Hata | Hatkategorin beskriver språkattacker eller användningsområden som inkluderar nedsättande eller diskriminerande språk med hänvisning till en person eller identitetsgrupp baserat på vissa differentieringsattribut för dessa grupper, inklusive men inte begränsat till ras, etnicitet, nationalitet, könsidentitet och uttryck, sexuell läggning, religion, invandringsstatus, förmågasstatus, personligt utseende och kroppsstorlek. |
| Sexuell | Den sexuella kategorin beskriver språk som rör anatomiska organ och könsorgan, romantiska relationer, handlingar som porträtteras i erotiska eller tillgivna termer, fysiska sexuella handlingar, inklusive de som framställs som ett övergrepp eller en tvingad sexuell våldsam handling mot ens vilja, prostitution, pornografi och övergrepp. |
| Våld | Våldskategorin beskriver språk som rör fysiska handlingar som är avsedda att skada, skada, skada eller döda någon eller något; beskriver vapen osv. |
| Självskadebeteende | Självskadekategorin beskriver språk relaterade till fysiska handlingar som syftar till att avsiktligt skada, skada eller skada ens kropp eller döda sig själv. |
Allvarlighetsgrad
| Kategori | beskrivning |
|---|---|
| Safe | Innehåll kan vara relaterat till våld, självskadebeteende, sexuella kategorier eller hatkategorier, men termerna används i allmänna, journalistiska, vetenskapliga, medicinska och liknande professionella sammanhang, som är lämpliga för de flesta målgrupper. |
| Låg | Innehåll som uttrycker fördomsfulla, dömande eller åsiktsfulla åsikter omfattar stötande användning av språk, stereotyper, användningsfall som utforskar en fiktiv värld (till exempel spel, litteratur) och skildringar med låg intensitet. |
| Medium | Innehåll som använder stötande, förolämpande, hånfullt, skrämmande eller förnedrande språk mot specifika identitetsgrupper, innehåller skildringar av att söka och utföra skadliga instruktioner, fantasier, förhärligande, främjande av skada med medelhög intensitet. |
| Högt | Innehåll som visar explicita och allvarliga skadliga instruktioner, handlingar, skador eller missbruk; omfattar godkännande, förhärligande eller främjande av allvarliga skadliga handlingar, extrema eller olagliga former av skada, radikalisering eller icke-konsensuellt maktutbyte eller missbruk. |
Konfigurerbarhet (förhandsversion)
Standardkonfigurationen för innehållsfiltrering för GPT-modellserien är inställd på att filtrera efter tröskelvärdet med medelhög allvarlighetsgrad för alla fyra innehållsskador (hat, våld, sexuellt och självskadebeteende) och gäller båda prompterna (text, multimodal text/bild) och slutföranden (text). Det innebär att innehåll som identifieras på allvarlighetsnivå medel eller hög filtreras, medan innehåll som identifieras på allvarlighetsnivå låg inte filtreras av innehållsfiltren. För DALL-E är standardtröskelvärdet för allvarlighetsgrad inställt på låg för både prompter (text) och slutföranden (bilder), så innehåll som identifieras på allvarlighetsgraderna låg, medel eller hög filtreras.
Med konfigurationsfunktionen kan kunderna justera inställningarna separat för frågor och slutföranden för att filtrera innehåll för varje innehållskategori på olika allvarlighetsnivåer enligt beskrivningen i tabellen nedan:
| Allvarlighetsgrad filtrerad | Kan konfigureras för frågor | Kan konfigureras för slutföranden | Beskrivningar |
|---|---|---|---|
| Låg, medelhög, hög | Ja | Ja | Striktast filtreringskonfiguration. Innehåll som identifieras på allvarlighetsgraderna låg, medelhög och hög filtreras. |
| Medelhög, hög | Ja | Ja | Innehåll som identifieras på allvarlighetsnivå låg filtreras inte, innehåll på medelhög och hög filtreras. |
| Högt | Ja | Ja | Innehåll som identifieras på allvarlighetsgraderna låg och medel filtreras inte. Endast innehåll på hög allvarlighetsgrad filtreras. Kräver godkännande1. |
| Inga filter | Om godkänd1 | Om godkänd1 | Inget innehåll filtreras oavsett allvarlighetsgrad som identifierats. Kräver godkännande1. |
1 För Azure OpenAI-modeller är det bara kunder som har godkänts för modifierad innehållsfiltrering som har fullständig innehållsfiltreringskontroll, inklusive att konfigurera innehållsfilter på allvarlighetsnivå som är hög eller stänga av innehållsfilter. Sök efter ändrade innehållsfilter via det här formuläret: Granskning av begränsad åtkomst i Azure OpenAI: Ändrade innehållsfilter och övervakning av missbruk (microsoft.com)
Kunderna ansvarar för att säkerställa att program som integrerar Azure OpenAI följer uppförandekoden.
Andra indatafilter
Du kan också aktivera särskilda filter för generativa AI-scenarier:
- Jailbreak-attacker: Jailbreak-attacker är användarfrågor som är utformade för att provocera Generative AI-modellen till att uppvisa beteenden som den har tränats för att undvika eller bryta mot reglerna som anges i systemmeddelandet.
- Indirekta attacker: Indirekta attacker, även kallade indirekta promptattacker eller direktinmatningsattacker mellan domäner, är en potentiell säkerhetsrisk där tredje part placerar skadliga instruktioner i dokument som Generative AI-systemet kan komma åt och bearbeta.
Andra utdatafilter
Du kan också aktivera följande särskilda utdatafilter:
- Skyddat material för text: Skyddad materialtext beskriver känt textinnehåll (till exempel sångtexter, artiklar, recept och valt webbinnehåll) som kan matas ut av stora språkmodeller.
- Skyddat material för kod: Kod för skyddat material beskriver källkod som matchar en uppsättning källkod från offentliga lagringsplatser, som kan matas ut av stora språkmodeller utan korrekt källlagringsplatser.
- Groundedness: Filtret för jordningsidentifiering identifierar om textsvaren från stora språkmodeller (LLM: er) är baserade i källmaterialet som tillhandahålls av användarna.
Nästa steg
- Läs mer om de underliggande modeller som driver Azure OpenAI.
- Azure AI Studio-innehållsfiltrering drivs av Azure AI Content Safety.
- Läs mer om att förstå och minimera risker som är kopplade till ditt program: Översikt över ansvarsfulla AI-metoder för Azure OpenAI-modeller.