Utveckla ett promptflöde
Viktigt!
Objekt markerade (förhandsversion) i den här artikeln är för närvarande i offentlig förhandsversion. Den här förhandsversionen tillhandahålls utan ett serviceavtal och vi rekommenderar det inte för produktionsarbetsbelastningar. Vissa funktioner kanske inte stöds eller kan vara begränsade. Mer information finns i Kompletterande villkor för användning av Microsoft Azure-förhandsversioner.
Promptflöde är ett utvecklingsverktyg som utformats för att effektivisera hela utvecklingscykeln för AI-program som drivs av stora språkmodeller (LLM). Promptflöde är en omfattande lösning som förenklar processen med prototyper, experimentering, iterering och distribution av dina AI-program.
Med promptflöde kan du:
- Dirigera körbara flöden med LLM:er, prompter och Python-verktyg via ett visualiserat diagram.
- Testa, felsöka och iterera dina flöden med lätthet.
- Skapa promptvarianter och jämför deras prestanda.
I den här artikeln får du lära dig hur du skapar och utvecklar ditt första promptflöde i Azure AI Studio.
Förutsättningar
- Om du inte redan har ett Azure AI Studio-projekt skapar du först ett projekt.
- Promptflöde kräver en beräkningssession. Om du inte har någon körning kan du skapa en i Azure AI Studio.
- Du behöver en distribuerad modell.
Skapa och utveckla ditt promptflöde
Du kan skapa ett flöde genom att antingen klona de exempel som är tillgängliga i galleriet eller skapa ett flöde från grunden. Om du redan har flödesfiler i lokal filresurs eller filresurs kan du även importera filerna för att skapa ett flöde.
Så här skapar du ett promptflöde från galleriet i Azure AI Studio:
Logga in på Azure AI Studio och välj ditt projekt.
På den komprimerade vänstra menyn väljer du Fråga flöde.
Välj + Skapa.
I panelen Standardflöde väljer du Skapa.
På sidan Skapa ett nytt flöde anger du ett mappnamn och väljer sedan Skapa.
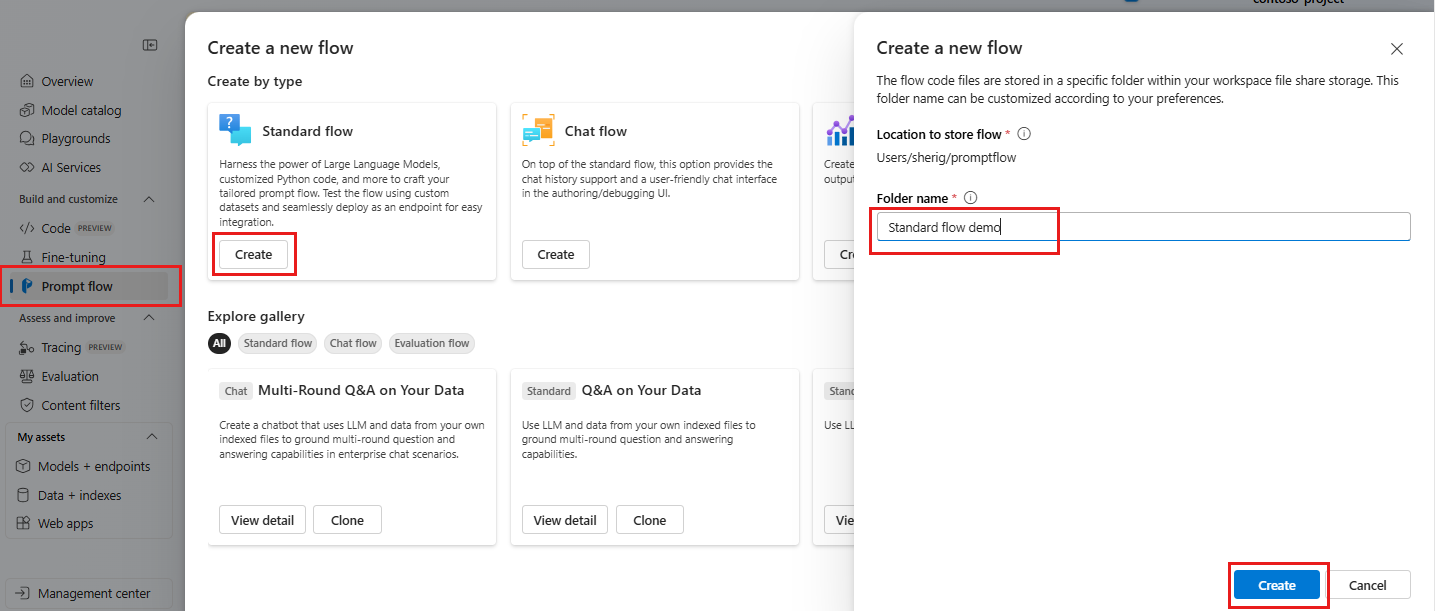
Redigeringssidan för promptflöde öppnas. Du kan börja redigera ditt flöde nu. Som standard visas ett exempelflöde. Det här exempelflödet har noder för VERKTYGEN LLM och Python.
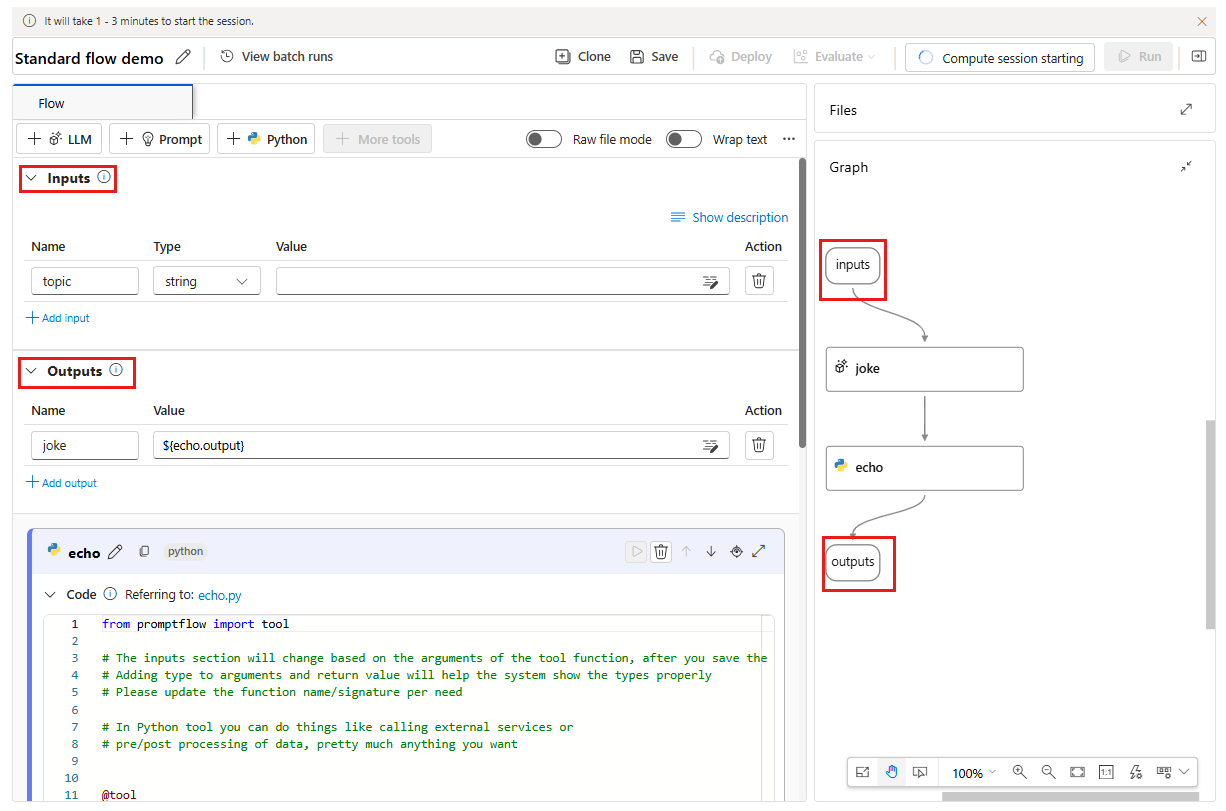
Kommentar
Endast grafvyn för visualisering. Den visar flödesstrukturen som du utvecklar. Du kan inte redigera grafvyn direkt, men du kan zooma in, zooma ut och rulla. Du kan välja en nod i grafvyn för att markera och navigera till noden i verktygsredigeringsvyn.
Du kan också lägga till fler verktyg i flödet. De synliga verktygsalternativen är LLM, Prompt och Python. Om du vill visa fler verktyg väljer du + Fler verktyg.
Välj en anslutning och distribution i LLM-verktygsredigeraren.
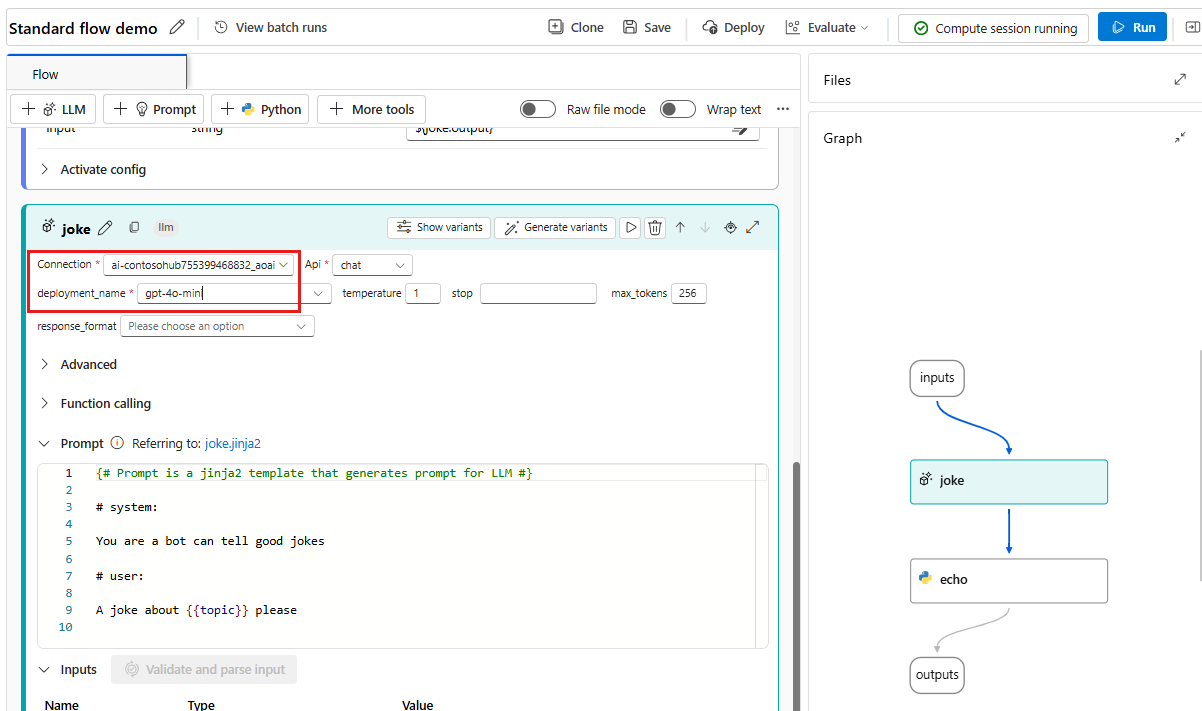
Välj Kör för att köra flödet.
Flödeskörningens status visas som Körs.
När flödeskörningen är klar väljer du Visa utdata för att visa flödesresultatet.

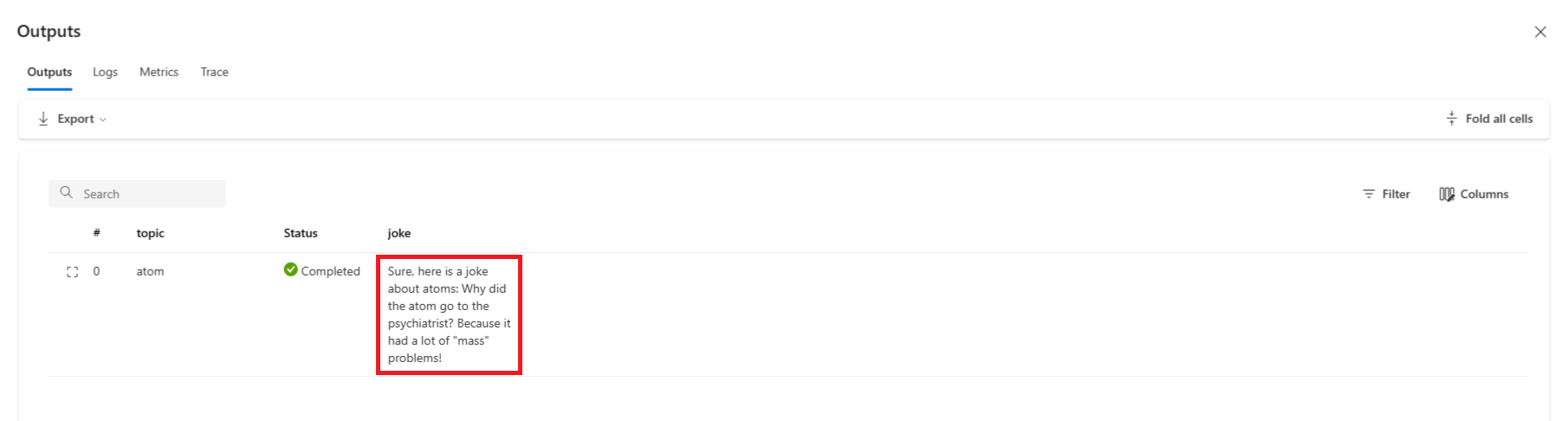
Du kan visa flödeskörningens status och utdata i avsnittet Utdata.








Redigera flödet
Varje flöde representeras av en mapp som innehåller en flow.dag.yaml-fil, källkodsfiler och systemmappar. Du kan lägga till nya filer, redigera befintliga filer och ta bort filer. Du kan också exportera filerna till lokala filer eller importera filer från lokala.
Förutom infogad redigering av noden i utplattad vy kan du även aktivera växlingsknappen Raw-filläge och välja filnamnet för att redigera filen på den öppna filfliken.
Flödesindata och utdata
Flödesindata är de data som skickas till flödet som helhet. Definiera indataschemat genom att ange namn och typ. Ange indatavärdet för varje indata för att testa flödet. Du kan referera till flödesindata senare i flödesnoderna med hjälp av ${input.[input name]} syntax.
Flödesutdata är de data som genereras av flödet som helhet, vilket sammanfattar resultatet av flödeskörningen. Du kan visa och exportera utdatatabellen när flödeskörningen eller batchkörningen har slutförts. Definiera flödesutdatavärde genom att referera till flödets enskilda nodutdata med hjälp av syntax eller ${[node name].output} ${[node name].output.[field name]}.
Länka samman noder
Genom att referera till nodutdata kan du länka samman noder. Du kan till exempel referera till LLM-nodens utdata i Python-nodens indata, så att Python-noden kan använda LLM-nodens utdata, och i grafvyn kan du se att de två noderna är länkade tillsammans.
Aktivera villkorsstyrd kontroll för flödet
Prompt Flow erbjuder inte bara ett effektivt sätt att köra flödet, utan ger också en kraftfull funktion för utvecklare – villkorsstyrd kontroll, som gör det möjligt för användare att ange villkor för körning av alla noder i ett flöde.
I grunden ger villkorsstyrd kontroll möjlighet att associera varje nod i ett flöde med en aktiverad konfiguration. Den här konfigurationen är i princip en "when"-instruktion som avgör när en nod ska köras. Kraften i den här funktionen realiseras när du har komplexa flöden där körningen av vissa uppgifter beror på resultatet av tidigare uppgifter. Med hjälp av den villkorliga kontrollen kan du konfigurera dina specifika noder så att de endast körs när de angivna villkoren uppfylls.
Mer specifikt kan du ange aktiveringskonfigurationen för en nod genom att välja knappen Aktivera konfiguration på nodkortet. Du kan lägga till "when"-instruktionen och ange villkoret.
Du kan ange villkoren genom att referera till flödesindata eller nodutdata. Du kan till exempel ange villkoret ${input.[input name]} som specifikt värde eller ${[node name].output} som specifikt värde.
Om villkoret inte uppfylls hoppas noden över. Nodstatusen visas som "Kringgåd".
Testa flödet
Du kan testa flödet på två sätt:
- Kör en nod.
- Om du vill köra en enskild nod väljer du ikonen Kör på noden i vyn Platta ut. När körningen är klar kan du snabbt kontrollera resultatet i nodutdataavsnittet.
- Kör hela flödet.
- Om du vill köra hela flödet väljer du knappen Kör längst upp till höger.
Visa testresultat och spårning (förhandsversion)
När du har kört flödet för hela flödeskörningen kan du se körningsstatusen i körningsbanderollen. Sedan kan du välja Visa spårning för att visa spårningen för att kontrollera resultatet och observera flödeskörningen, där du kan se indata och utdata för hela flödet och varje nod, tillsammans med mer detaljerad information för felsökning. Den är tillgänglig under körningen och när körningen har slutförts.
Förstå spårningsvyn
Spårningstyp för ett promptflöde har angetts som Flow. I spårningsvyn kan den tydliga sekvensen av de verktyg som används för flödesorkestrering observeras.
Varje nivå 2-span under flödesroten representerar en nod i flödet, som körs i form av ett funktionsanrop, och därför identifieras span-typen som Funktion. Du kan se varaktigheten för varje nodkörning i span-trädet.
I span-trädet kan LLM-anrop enkelt identifieras som LLM-spann . Dessa ger information om varaktigheten för LLM-anropet och den associerade tokenkostnaden.
Genom att välja ett intervall kan du se detaljerad information till höger. Detta inkluderar indata och utdata, Raw Json och Exception, som alla är användbara för observation och felsökning.

Kommentar
I prompt flow SDK definierade vi flera intervalltyper, inklusive LLM, Function, Embedding, Retrieval och Flow. Och systemet skapar automatiskt intervall med körningsinformation i avsedda attribut och händelser.
Mer information om intervalltyper finns i Spårningsintervall.
När flödeskörningen har slutförts kan du för att kontrollera resultaten välja knappen Visa testresultat för att kontrollera alla historiska körningsposter i en lista. Som standard visas de körningsposter som skapats under de senaste 7 dagarna. Du kan välja filtret för att ändra villkoret.

Du kan också välja namn på körningsposten för att visa detaljerad information i spårningsvyn.
Utveckla ett chattflöde
Chattflödet är utformat för utveckling av konversationsprogram, som bygger på funktionerna i standardflödet och ger förbättrat stöd för chattindata/utdata och hantering av chatthistorik. Med chattflöde kan du enkelt skapa en chattrobot som hanterar chattindata och utdata.
På sidan för redigering av chattflöden taggas chattflödet med en "chatt"-etikett för att skilja det från standardflöde och utvärderingsflöde. Om du vill testa chattflödet väljer du knappen "Chatt" för att utlösa en chattruta för konversation.
Chattindata/utdata och chatthistorik
De viktigaste elementen som skiljer ett chattflöde från ett standardflöde är Chat-indata, Chatthistorik och Chat-utdata.
- Chattinmatning: Chattindata refererar till de meddelanden eller frågor som skickas av användare till chattroboten. Att effektivt hantera chattindata är avgörande för en lyckad konversation, eftersom det handlar om att förstå användarnas avsikter, extrahera relevant information och utlösa lämpliga svar.
- Chatthistorik: Chatthistorik är en post för alla interaktioner mellan användaren och chattroboten, inklusive både användarindata och AI-genererade utdata. Det är viktigt att upprätthålla chatthistoriken för att hålla reda på konversationskontexten och se till att AI:n kan generera kontextuellt relevanta svar.
- Chattutdata: Chattutdata refererar till AI-genererade meddelanden som skickas till användaren som svar på deras indata. Att generera kontextuellt lämpliga och engagerande chattutdata är viktigt för en positiv användarupplevelse.
Ett chattflöde kan ha flera indata, chatthistorik och chattindata krävs i chattflödet.
I avsnittet chattflödesindata kan ett flödesindata markeras som chattindata. Sedan kan du fylla i chattens indatavärde genom att skriva i chattrutan.
Prompt flow kan hjälpa användaren att hantera chatthistorik. I
chat_historyavsnittet Indata är reserverat för att representera chatthistorik. Alla interaktioner i chattrutan, inklusive användarindata, genererade chattutdata och andra flödesindata och utdata, lagras automatiskt i chatthistoriken. Användaren kan inte manuellt ange värdetchat_historyför i avsnittet Indata. Den är strukturerad som en lista över indata och utdata:[ { "inputs": { "<flow input 1>": "xxxxxxxxxxxxxxx", "<flow input 2>": "xxxxxxxxxxxxxxx", "<flow input N>""xxxxxxxxxxxxxxx" }, "outputs": { "<flow output 1>": "xxxxxxxxxxxx", "<flow output 2>": "xxxxxxxxxxxxx", "<flow output M>": "xxxxxxxxxxxxx" } }, { "inputs": { "<flow input 1>": "xxxxxxxxxxxxxxx", "<flow input 2>": "xxxxxxxxxxxxxxx", "<flow input N>""xxxxxxxxxxxxxxx" }, "outputs": { "<flow output 1>": "xxxxxxxxxxxx", "<flow output 2>": "xxxxxxxxxxxxx", "<flow output M>": "xxxxxxxxxxxxx" } } ]
Kommentar
Möjligheten att automatiskt spara eller hantera chatthistorik är en funktion på redigeringssidan när du utför tester i chattrutan. För batchkörningar är det nödvändigt att användarna inkluderar chatthistoriken i batchkörningsdatauppsättningen. Om det inte finns någon tillgänglig chatthistorik för testning anger du helt enkelt chat_history till en tom lista [] i batchkörningsdatauppsättningen.
Redigeringsprompt med chatthistorik
Att införliva chatthistorik i dina frågor är viktigt för att skapa sammanhangsmedvetna och engagerande chattrobotsvar. I dina frågor kan du referera chat_history till för att hämta tidigare interaktioner. På så sätt kan du referera till tidigare indata och utdata för att skapa kontextuellt relevanta svar.
Använd för-loop-grammatik i Jinja-språket för att visa en lista över indata och utdata från chat_history.
{% for item in chat_history %}
user:
{{item.inputs.question}}
assistant:
{{item.outputs.answer}}
{% endfor %}
Testa med chattrutan
Chattrutan ger ett interaktivt sätt att testa ditt chattflöde genom att simulera en konversation med din chattrobot. Följ dessa steg för att testa chattflödet med hjälp av chattrutan:
- Välj knappen "Chatt" för att öppna chattrutan.
- Skriv dina testindata i chattrutan och tryck på Retur för att skicka dem till chattroboten.
- Granska chattrobotens svar för att säkerställa att de är sammanhangsberoende lämpliga och korrekta.
- Visa spårning på plats för att snabbt observera och felsöka.