Lösningsidéer
I den här artikeln beskrivs en lösningsidé. Molnarkitekten kan använda den här vägledningen för att visualisera huvudkomponenterna för en typisk implementering av den här arkitekturen. Använd den här artikeln som utgångspunkt för att utforma en välkonstruerad lösning som överensstämmer med arbetsbelastningens specifika krav.
Implementera en anpassad nlp-lösning (natural language processing) i Azure. Använd Spark NLP för uppgifter som ämnes- och attitydidentifiering och analys.
Apache®, Apache Spark och flamlogotypen är antingen registrerade varumärken eller varumärken som tillhör Apache Software Foundation i USA och/eller andra länder. Inget godkännande från Apache Software Foundation underförstås av användningen av dessa märken.
Arkitektur

Ladda ned en Visio-fil med den här arkitekturen.
Arbetsflöde
- Azure Event Hubs, Azure Data Factory eller båda tjänsterna tar emot dokument eller ostrukturerade textdata.
- Event Hubs och Data Factory lagrar data i filformat i Azure Data Lake Storage. Vi rekommenderar att du konfigurerar en katalogstruktur som uppfyller affärskraven.
- Api:et för visuellt innehåll i Azure använder sin ocr-funktion (optisk teckenigenkänning) för att använda data. API:et skriver sedan data till bronsskiktet. Den här förbrukningsplattformen använder en lakehouse-arkitektur.
- I bronsskiktet förbearbetar olika Spark NLP-funktioner texten. Exempel är att dela, korrigera stavning, rensa och förstå grammatik. Vi rekommenderar att du kör dokumentklassificering på bronsskiktet och sedan skriver resultatet till silverskiktet.
- I silverskiktet utför avancerade Spark NLP-funktioner dokumentanalysuppgifter som namngiven entitetsigenkänning, sammanfattning och informationshämtning. I vissa arkitekturer skrivs resultatet till guldskiktet.
- I guldskiktet kör Spark NLP olika språkliga visuella analyser av textdata. Dessa analyser ger insikt i språkberoenden och hjälp med visualisering av NER-etiketter.
- Användare frågar textdata i guldskiktet som en dataram och visar resultatet i Power BI eller webbappar.
Under bearbetningsstegen används Azure Databricks, Azure Synapse Analytics och Azure HDInsight med Spark NLP för att tillhandahålla NLP-funktioner.
Komponenter
- Data Lake Storage är ett Hadoop-kompatibelt filsystem som har ett integrerat hierarkiskt namnområde och den enorma skalan och ekonomin i Azure Blob Storage.
- Azure Synapse Analytics är en analystjänst för informationslager och stordatasystem.
- Azure Databricks är en analystjänst för stordata som är enkel att använda, underlättar samarbete och baseras på Apache Spark. Azure Databricks är utformat för datavetenskap och datateknik.
- Event Hubs matar in dataströmmar som klientprogram genererar. Event Hubs lagrar strömmande data och bevarar sekvensen med mottagna händelser. Konsumenter kan ansluta till hubbslutpunkter för att hämta meddelanden för bearbetning. Event Hubs integreras med Data Lake Storage, som den här lösningen visar.
- Azure HDInsight är en hanterad analystjänst med fullständigt spektrum med öppen källkod i molnet för företag. Du kan använda ramverk med öppen källkod med Azure HDInsight, till exempel Hadoop, Apache Spark, Apache Hive, LLAP, Apache Kafka, Apache Storm och R.
- Data Factory flyttar automatiskt data mellan lagringskonton med olika säkerhetsnivåer för att säkerställa uppdelning av uppgifter.
- Visuellt innehåll använder API:er för textigenkänning för att identifiera text i bilder och extrahera den informationen. Läs-API:et använder de senaste igenkänningsmodellerna och är optimerat för stora, textintensiva dokument och brusande bilder. OCR-API:et är inte optimerat för stora dokument, men stöder fler språk än Läs-API:et. Den här lösningen använder OCR för att producera data i hOCR-format .
Information om scenario
Bearbetning av naturligt språk (NLP) har många användningsområden: attitydanalys, ämnesidentifiering, språkidentifiering, extrahering av nyckelfraser och kategorisering av dokument.
Apache Spark är ett ramverk för parallell bearbetning som stöder minnesintern bearbetning för att öka prestanda för analysprogram med stordata som NLP. Azure Synapse Analytics, Azure HDInsight och Azure Databricks ger åtkomst till Spark och drar nytta av dess bearbetningskraft.
För anpassade NLP-arbetsbelastningar fungerar Spark NLP med öppen källkod som ett effektivt ramverk för bearbetning av en stor mängd text. Den här artikeln innehåller en lösning för storskalig anpassad NLP i Azure. Lösningen använder Spark NLP-funktioner för att bearbeta och analysera text. Mer information om Spark NLP finns i Spark NLP-funktioner och pipelines senare i den här artikeln.
Potentiella användningsfall
Dokumentklassificering: Spark NLP erbjuder flera alternativ för textklassificering:
- Förbearbetning av text i Spark NLP och maskininlärningsalgoritmer som baseras på Spark ML
- Förbearbetning av text och ordinbäddning i Spark NLP- och maskininlärningsalgoritmer som GloVe, BERT och ELMo
- Förbearbetning av text och meningsinbäddning i Spark NLP och maskininlärningsalgoritmer och modeller som Universal Sentence Encoder
- Förbearbetning och klassificering av text i Spark NLP som använder klassificerarenDL-kommenteraren och som baseras på TensorFlow
Namnentitetsextrahering (NER): I Spark NLP, med några rader kod, kan du träna en NER-modell som använder BERT, och du kan uppnå den senaste precisionen. NER är en del av informationsextraheringen. NER letar upp namngivna entiteter i ostrukturerad text och klassificerar dem i fördefinierade kategorier som personnamn, organisationer, platser, medicinska koder, tidsuttryck, kvantiteter, monetära värden och procentandelar. Spark NLP använder en toppmodern NER-modell med BERT. Modellen är inspirerad av en tidigare NER-modell, dubbelriktad LSTM-CNN. Den tidigare modellen använder en ny neural nätverksarkitektur som automatiskt identifierar funktioner på ordnivå och teckennivå. För detta ändamål använder modellen en hybrid dubbelriktad LSTM- och CNN-arkitektur, så den eliminerar behovet av de flesta funktionstekniker.
Identifiering av sentiment och känslor: Spark NLP kan automatiskt identifiera positiva, negativa och neutrala aspekter av språket.
Del av tal (POS): Den här funktionen tilldelar en grammatisk etikett till varje token i indatatext.
Meningsidentifiering (SD): SD baseras på en generell neural nätverksmodell för meningsgränsidentifiering som identifierar meningar i text. Många NLP-uppgifter tar en mening som indataenhet. Exempel på dessa uppgifter är POS-taggning, beroendeparsning, namngiven entitetsigenkänning och maskinöversättning.
Spark NLP-funktioner och pipelines
Spark NLP tillhandahåller Python-, Java- och Scala-bibliotek som erbjuder alla funktioner i traditionella NLP-bibliotek som spaCy, NLTK, Stanford CoreNLP och Open NLP. Spark NLP erbjuder även funktioner som stavningskontroll, attitydanalys och dokumentklassificering. Spark NLP förbättrar tidigare insatser genom att tillhandahålla toppmodern noggrannhet, hastighet och skalbarhet.
Spark NLP är det överlägset snabbaste NLP-biblioteket med öppen källkod. Senaste offentliga riktmärken visar Spark NLP som 38 och 80 gånger snabbare än spaCy, med jämförbar noggrannhet för träning av anpassade modeller. Spark NLP är det enda bibliotek med öppen källkod som kan använda ett distribuerat Spark-kluster. Spark NLP är ett inbyggt tillägg för Spark ML som fungerar direkt på dataramar. Därför resulterar speedups i ett kluster i en annan storleksordning av prestandavinst. Eftersom varje Spark NLP-pipeline är en Spark ML-pipeline passar Spark NLP bra för att skapa enhetliga NLP- och maskininlärningspipelines som dokumentklassificering, riskförutsägelse och rekommenderade pipelines.
Förutom utmärkta prestanda levererar Spark NLP också toppmodern noggrannhet för ett växande antal NLP-uppgifter. Spark NLP-teamet läser regelbundet de senaste relevanta akademiska uppsatserna och producerar de mest exakta modellerna.
För körningsordningen för en NLP-pipeline följer Spark NLP samma utvecklingskoncept som traditionella Spark-maskininlärningsmodeller. Men Spark NLP tillämpar NLP-tekniker. Följande diagram visar kärnkomponenterna i en Spark NLP-pipeline.
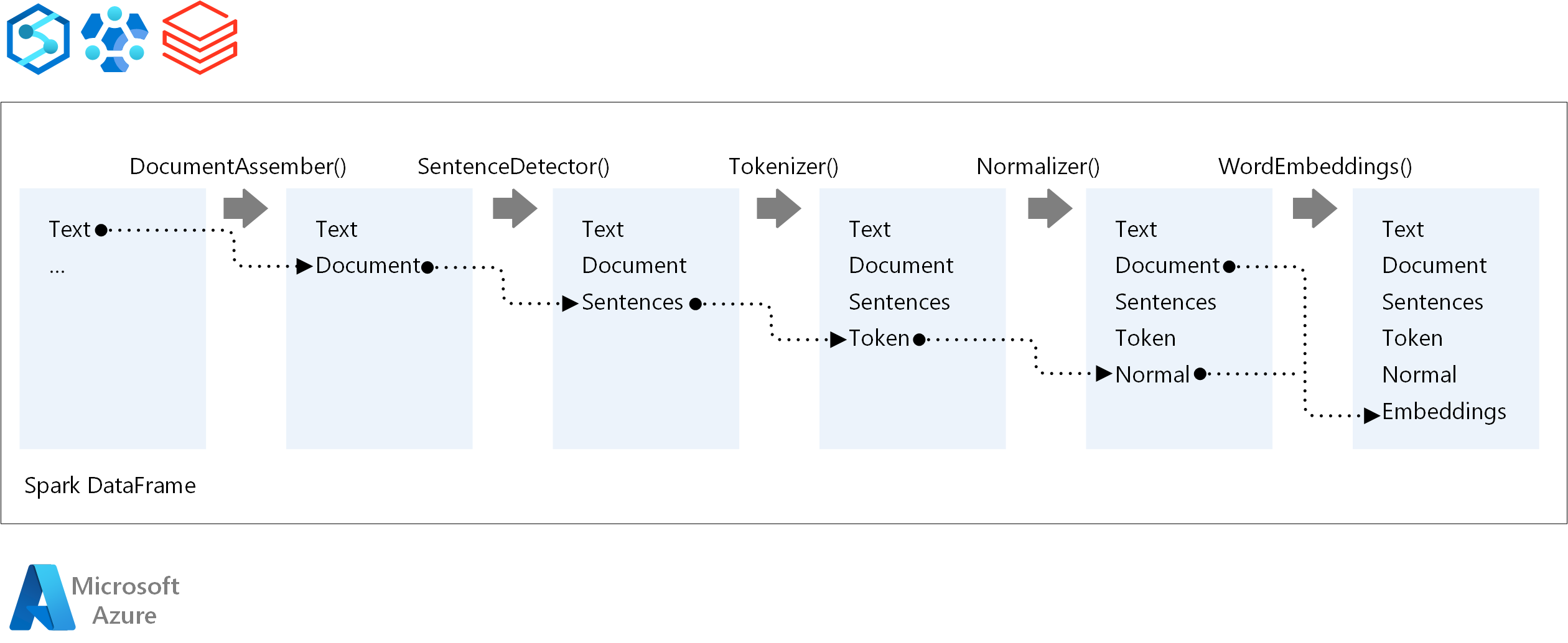
Deltagare
Den här artikeln underhålls av Microsoft. Det har ursprungligen skrivits av följande medarbetare.
Huvudförfattare:
- Moritz Steller | Senior Cloud Solution Architect
Nästa steg
Spark NLP-dokumentation:
Azure-komponenter: