Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Azure HDInsight är en hanterad analystjänst med fullständigt spektrum med öppen källkod i molnet för företag. Med HDInsight kan du använda ramverk med öppen källkod som Apache Spark, Apache Hive, LLAP, Apache Kafka, Hadoop med mera i din Azure-miljö.
Vad är HDInsight och Hadoop-teknikstacken?
Azure HDInsight är en hanterad klusterplattform som gör det enkelt att köra stordataramverk som Apache Spark, Apache Hive, LLAP, Apache Kafka, Apache Hadoop och andra i din Azure-miljö. Den är utformad för att hantera stora mängder data med hög hastighet och effektivitet.
Varför ska jag använda Azure HDInsight?
| Kapacitet | beskrivning |
|---|---|
| Molnbaserat | Med Azure HDInsight kan du skapa optimerade kluster för Spark, Interaktiv fråga (LLAP), Kafka, HBase och Hadoop i Azure. HDInsight tillhandahåller även ett serviceavtal från slutpunkt till slutpunkt för alla produktionsarbetsbelastningar. |
| Billigt och skalbart | Med HDInsight kan du skala upp eller ned arbetsbelastningar. Du kan minska kostnaderna genom att skapa kluster på begäran och bara betala för det du använder. Du kan också skapa datapipelines för att operationalisera dina jobb. Fristående beräkning och lagring ger bättre prestanda och flexibilitet. |
| Säkert och följer standarder | MED HDInsight kan du skydda företagets datatillgångar med Azure Virtual Network, kryptering och integrering med Microsoft Entra ID. HDInsight uppfyller också de vanligaste efterlevnadskraven för olika branscher och myndigheter. |
| Övervakning | Azure HDInsight integreras med Azure Monitor-loggar så att du får ett enda gränssnitt som du kan använda för att övervaka alla dina kluster. |
| Global tillgänglighet | HDInsight är tillgängligt i fler regioner än något annat erbjudande för stordataanalys . Azure HDInsight är också tillgängligt i Azure Government, Kina och Tyskland så att du kan uppfylla företagets behov i viktiga områden. |
| Produktivitet | Med Azure HDInsight kan du använda omfattande produktiva verktyg för Hadoop och Spark med de utvecklingsmiljöer du föredrar. Dessa utvecklingsmiljöer omfattar stöd för Visual Studio, VS Code, Eclipse och IntelliJ för Scala, Python, Java och .NET. |
| Utökningsbarhet | Du kan utöka HDInsight-kluster med installerade komponenter (Hue, Presto och så vidare) med hjälp av skriptåtgärder, genom att lägga till kantnoder eller genom att integrera med andra stordatacertifierade program. HDInsight ger enkel integrering med de vanligaste stordatalösningarna med distribution med ett klick. |
Vad är big data?
Stordata samlas in i ständigt växande volymer, med allt högre hastighet och i fler olika format än någonsin tidigare. De kan vara historiska (lagrade) eller realtidsbaserade (vilket innebär att de strömmas från källan). Under Scenarier för att använda HDInsight kan du läsa mer om vanliga användningsområden för stordata.
Klustertyper i HDInsight
HDInsight omfattar specifika klustertyper och anpassningsmöjligheter för klustret, till exempel funktioner för att lägga till komponenter, verktyg och språk. HDInsight erbjuder följande klustertyper:
| Klustertyp | beskrivning | Kom igång |
|---|---|---|
| Apache Hadoop | Ett ramverk som använder HDFS, YARN-resurshantering och en enkel MapReduce-programmeringsmodell för att behandla och analysera batchdata parallellt. | Skapa ett Apache Hadoop-kluster |
| Apache Spark | Ett ramverk för parallellbearbetning med öppen källkod som stöder intern bearbetning för att höja prestandan hos program för stordataanalys. Se Vad är Apache Spark i HDInsight?. | Skapa ett Apache Spark-kluster |
| Apache HBase | En NoSQL-databas baserad på Hadoop som ger slumpmässig åtkomst och stark konsistens för stora mängder ostrukturerade och semi-strukturerade data – potentiellt miljarder rader och miljoner kolumner. Se Vad är HBase på HDInsight? | Skapa ett Apache HBase-kluster |
| Apache Interaktiv frågning | Minnesintern cachelagring för interaktiva och snabba Hive-frågor. Se Använd Interactive Query i HDInsight. | Skapa ett Interaktiv fråga kluster |
| Apache Kafka | En plattform med öppen källkod används för att skapa strömmande datapipelines och program. Kafka tillhandahåller även en meddelandeköfunktion med vilken du kan publicera och prenumerera på dataströmmar. Se Introduktion till Apache Kafka på HDInsight. | Skapa ett Apache Kafka-kluster |
Scenarier för att använda HDInsight
Azure HDInsight kan användas för olika scenarier vid bearbetning av stordata . Det kan vara historiska data (data som redan samlas in och lagras) eller realtidsdata (data som strömmas direkt från källan). Dessa scenarier för bearbetning av sådana data kan sammanfattas i följande kategorier:
Batchbearbetning (ETL)
Extrahering, transformering och laddning (ETL) är en process där ostrukturerade eller strukturerade data extraheras från heterogena datakällor. De transformeras sedan till ett strukturerat format och laddas in i ett datalager. Du kan använda transformerade data för datavetenskap eller datalagerhantering.
Datalagerhantering
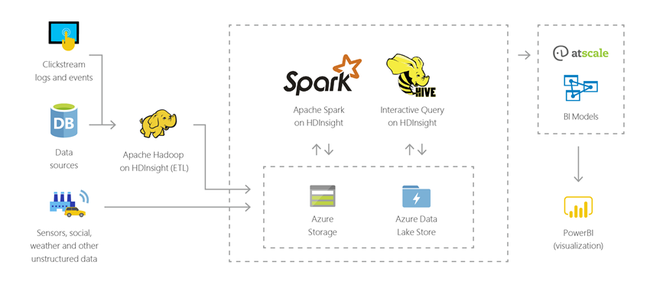
Du kan använda HDInsight för att köra interaktiva frågor i petabyte-skala på strukturerade eller ostrukturerade data i valfritt format. Du kan också skapa modeller för att koppla dem till BI-verktyg.
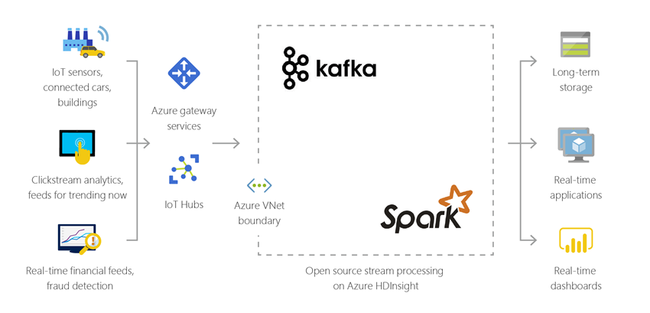
Sakernas Internet (IoT)
Du kan använda HDInsight för att bearbeta strömmande data som tas emot i realtid från olika typer av enheter. Om du vill ha mer information kan du läsa det här blogginlägget från Azure som tillkännager den offentliga förhandsversionen av Apache Kafka på HDInsight med Azure Managed Disks.
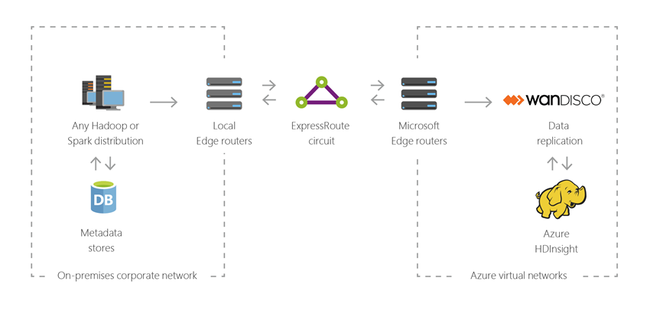
Hybrid
Du kan använda HDInsight för att utöka din befintliga lokala stordatainfrastruktur till Azure för att tillämpa de avancerade analysfunktionerna i molnet.
Komponenter med öppen källkod i HDInsight
Med Azure HDInsight kan du skapa kluster med ramverk med öppen källkod, till exempel Spark, Hive, LLAP, Kafka, Hadoop och HBase. Dessa kluster innehåller som standard olika komponenter med öppen källkod, till exempel Apache Ambari, Avro, Apache Hive 3, HCatalog, Apache Hadoop MapReduce, Apache Hadoop YARN, Apache Phoenix, Apache Pig, Apache Sqoop, Apache Tez, Apache Oozie och Apache ZooKeeper.
Programmeringsspråk i HDInsight
HDInsight-kluster, inklusive Hadoop, HBase, Kafka, Spark med flera, stöder ett antal programmeringsspråk. Vissa programmeringsspråk är inte installerade som standard. För bibliotek, moduler eller paket som inte är installerade som standard använder du en skriptåtgärd för att installera komponenten.
| Programmeringsspråk | Information |
|---|---|
| Programmeringsspråk som stöds som standard | Som standard stöder HDInsight-kluster:
|
| Java Virtual Machine-språk (JVM) | Många andra språk än Java kan köras på en Java Virtual Machine (JVM). Men om du kör några av dessa språk kan du behöva installera fler komponenter i klustret. Följande JVM-baserade språk stöds i HDInsight-kluster:
|
| Hadoop-specifika språk | HDInsight-kluster stöder följande språk som är specifika för Hadoop-teknikstacken:
|
Utvecklingsverktyg för HDInsight
Du kan använda utvecklingsverktyg för HDInsight, inklusive IntelliJ, Eclipse, Visual Studio Code och Visual Studio för att skapa och skicka HDInsight-datafrågor och -jobb med sömlös Azure-integrering.
- Azure toolkit för IntelliJ 10
- Azure Toolkit för Eclipse 6
- Azure HDInsight-verktyg för VS Code 13
- Azure Data Lake-verktyg för Visual Studio 9
Business intelligence på HDInsight
Välbekanta verktyg för Business Intelligence (BI) hämtar, analyserar och rapporterar data som integreras med HDInsight med antingen Power Query-tillägget eller ODBC-drivrutinen för Microsoft Hive:
Apache Spark BI med hjälp av datavisualiseringsverktyg med Azure HDInsight
Visualisera Apache Hive-data med Microsoft Power BI i Azure HDInsight
Visualisera Interactive Query Hive-data med Power BI i Azure HDInsight
Ansluta Excel till Apache Hadoop med Power Query (kräver Windows)
Ansluta Excel till Apache Hadoop med Microsoft Hives ODBC-drivrutin (kräver Windows)
Datahemvist i regionen
Spark, Hadoop och LLAP lagrar inte kunddata, så dessa tjänster uppfyller automatiskt kraven för datahemvist i regionen som anges på den globala infrastrukturplatsen i Azure.
Kafka och HBase lagrar kunddata. Dessa data lagras automatiskt av Kafka och HBase i en enda region, så den här tjänsten uppfyller kraven för datahemvist i regionen som anges på den globala infrastrukturplatsen i Azure.
Välbekanta BI-verktyg (Business Intelligence) hämtar, analyserar och rapporterar data som är integrerade med HDInsight med hjälp av antingen Power Query-tillägget eller Microsoft Hive ODBC-drivrutinen.