Antimönstret Överflödig hämtning
Antimönster är vanliga designfel som kan bryta din programvara eller dina program under stresssituationer och bör inte förbises. I ett externt hämtningsskydd hämtas mer data än nödvändigt för en affärsåtgärd, vilket ofta resulterar i onödiga I/O-omkostnader och minskad svarstid.
Exempel på oskadlig hämtning av antimönster
Det här antimönstret kan förekomma om programmet försöker minimera I/O-begäranden genom att hämta alla data som den kan behöva. Det här är ofta resultatet av att överkompensera antimönstret trafikintensiva I/O. Till exempel kan ett program hämta informationen för varje produkt i databasen. Men användaren kanske bara behöver en delmängd av informationen (viss information kanske inte är relevant för kunder) och behöver troligen inte se alla produkter på en gång. Även om användaren bläddrar i hela katalogen är det klokt att sidnumrera resultatet – till exempel 20 i taget.
En annan källa till det här problemet är dåliga programmerings- eller designmetoder. Till exempel använder följande kod Entity Framework till att hämta den fullständiga informationen för varje produkt. Sedan filtreras resultaten för att returnera en delmängd av fälten och ignorera resten. Du hittar hela exemplet här.
public async Task<IHttpActionResult> GetAllFieldsAsync()
{
using (var context = new AdventureWorksContext())
{
// Execute the query. This happens at the database.
var products = await context.Products.ToListAsync();
// Project fields from the query results. This happens in application memory.
var result = products.Select(p => new ProductInfo { Id = p.ProductId, Name = p.Name });
return Ok(result);
}
}
I nästa exempel hämtar programmet data för att utföra en aggregering som kan göras av databasen istället. Programmet beräknar totalförsäljningen genom att hämta varje post för alla sålda order och sedan beräkna summan för de posterna. Du hittar hela exemplet här.
public async Task<IHttpActionResult> AggregateOnClientAsync()
{
using (var context = new AdventureWorksContext())
{
// Fetch all order totals from the database.
var orderAmounts = await context.SalesOrderHeaders.Select(soh => soh.TotalDue).ToListAsync();
// Sum the order totals in memory.
var total = orderAmounts.Sum();
return Ok(total);
}
}
I näsa exempel visas ett diskret problem som orsakas av hur Entity Framework använder LINQ to Entities.
var query = from p in context.Products.AsEnumerable()
where p.SellStartDate < DateTime.Now.AddDays(-7) // AddDays cannot be mapped by LINQ to Entities
select ...;
List<Product> products = query.ToList();
Programmet försöker hitta produkter med SellStartDate som är över en vecka gammalt. I de flesta fall skulle LINQ to Entities översätta en where-sats till en SQL-instruktion som körs av databasen. Men i det här fallet kan LINQ to Entities inte mappa metoden AddDays till SQL. Istället returneras varje rad från tabellen Product och resultatet filtreras i minnet.
Anropet till AsEnumerable antyder att det finns ett problem. Den här metoden konverterar resultatet till ett IEnumerable-gränssnitt. Trots att IEnumerable stöder filtrering görs den på klientsidan, inte i databasen. Som standard använder LINQ to Entities IQueryable, som lägger över ansvaret för filtrering på datakällan.
Så här åtgärdar du överflödigt hämtningsskyddsmönster
Undvik hämta stora mängder data som snabbt kan bli inaktuella eller som kan tas bort, och hämta bara de data som behövs för åtgärden som utförs.
Istället för att hämta varje kolumn från en tabell och sedan filtrera dem väljer du de kolumner som du behöver från databasen.
public async Task<IHttpActionResult> GetRequiredFieldsAsync()
{
using (var context = new AdventureWorksContext())
{
// Project fields as part of the query itself
var result = await context.Products
.Select(p => new ProductInfo {Id = p.ProductId, Name = p.Name})
.ToListAsync();
return Ok(result);
}
}
På liknande sätt kan du utföra aggregering i databasen och inte i programminnet.
public async Task<IHttpActionResult> AggregateOnDatabaseAsync()
{
using (var context = new AdventureWorksContext())
{
// Sum the order totals as part of the database query.
var total = await context.SalesOrderHeaders.SumAsync(soh => soh.TotalDue);
return Ok(total);
}
}
När du använder Entity Framework kontrollerar du att LINQ-frågor matchas med hjälp av IQueryable gränssnittet och inte IEnumerable. Du kan behöva justera frågan så att bara funktioner används som kan mappas till datakällan. Det tidigare exemplet kan omstruktureras så att metoden AddDays tas bort från frågan, så att filtrering kan göras av databasen.
DateTime dateSince = DateTime.Now.AddDays(-7); // AddDays has been factored out.
var query = from p in context.Products
where p.SellStartDate < dateSince // This criterion can be passed to the database by LINQ to Entities
select ...;
List<Product> products = query.ToList();
Att tänka på
I vissa fall kan du förbättra prestandan genom att partitionera data vågrätt. Om olika åtgärder använder olika attribut i data kan vågrät partitionering minska konkurrensen. Ofta körs de flesta åtgärder mot en liten delmängd data, så att sprida belastningen kan förbättra prestandan. Se Datapartitionering.
För åtgärder som måste stödja obundna frågor implementerar du sidnumrering och hämtar bara ett begränsat antal entiteter i taget. Om till exempel en kund bläddrar i en produktkatalog kan du visa en resultatsida i taget.
När det är möjligt kan du dra nytta av funktioner inbyggda i datalagret. Till exempel har SQL-databaser normalt mängdfunktioner.
Om du använder ett datalager som inte stöder en viss funktion, till exempel aggregering, kan du lagra det beräknade resultatet någon annanstans, och uppdatera värdet när poster läggs till eller uppdateras, så att programmet inte behöver räkna om värdet varje gång det behövs.
Om du ser att begäranden hämtar ett stort antal fält undersöker du källkoden för att fastställa om alla de här fälten är nödvändiga. Ibland är dessa begäranden resultatet av felaktigt utformade
SELECT *-frågor.På samma sätt kan begäranden som hämtar ett stort antal entiteter vara ett tecken på att programmet inte filtrerar data på rätt sätt. Kontrollera att alla de här entiteterna behövs. Använd filtrering på databassidan om det är möjligt, genom att använda
WHERE-satser i SQL.Att avlasta bearbetning till databasen är inte alltid det bästa alternativet. Använd bara den här strategin när databasen har utformats eller optimerats att göra det. Det flesta databassystem är mycket optimerade för vissa funktioner men är inte utformade att fungera som allmänna programmotorer. Mer information finns i Antimönstret upptagen databas.
Så här identifierar du extraneous fetching antipattern
Symtom för överflödig hämtning är lång svarstid och lågt dataflöde. Om data hämtas från ett datalager är ökad konkurrens också troligt. Slutanvändarna kommer sannolikt att rapportera utökade svarstider eller fel som orsakas av tidsgränsen för tjänsterna. Dessa fel kan returnera HTTP 500-fel (intern server) eller HTTP 503-fel (tjänsten är inte tillgänglig). Undersök händelseloggarna för webbservern, som troligen innehåller mer detaljerad information om felens orsaker och omständigheter.
Symtomen för det här antimönstret och viss telemetri som hämtas kan i hög grad likna dem från antimönstret monolitisk beständighet.
Du kan göra följande för att identifiera orsaken:
- Identifiera långsamma arbetsbelastningar eller transaktioner genom att utföra belastningstester av prestanda, processövervakning eller andra metoder för att registrera instrumenteringsdata.
- Observera systemets beteendemönster. Finns det vissa begränsningar när det gäller transaktioner per sekund eller mängden användare?
- Korrelera förekomster av långsamma arbetsbelastningar med beteendemönster.
- Identifiera datalagren som används. För varje datakälla kör du telemetri på lägre nivå för att observera beteende för åtgärder.
- Identifiera långsamma frågor som refererar till de här datakällorna.
- Utför resursspecifik analys av långsamma frågor och fastställ hur data används och förbrukas.
Titta av något av de här symtomen:
- Frekventa, stora I/O-begäranden gjorda till samma resurs eller datalager.
- Konkurrens i en delad resurs eller ett delat datalager.
- En åtgärd som ofta tar emot stora mängder data över nätverket.
- Program och tjänster som tillbringar betydande tid i väntan på att I/O ska slutföras.
Exempeldiagnos
Följande avsnitt använder de här stegen på exemplen ovan.
Identifiera långsamma arbetsbelastningar
Det här diagrammet visar prestandaresultat från ett belastningstest som simulerar upp till 400 samtidiga användare som kör metoden GetAllFieldsAsync som visades tidigare. Dataflödet minskar långsamt när belastningen ökar. Den genomsnittliga svarstiden går upp när arbetsbelastningen ökar.
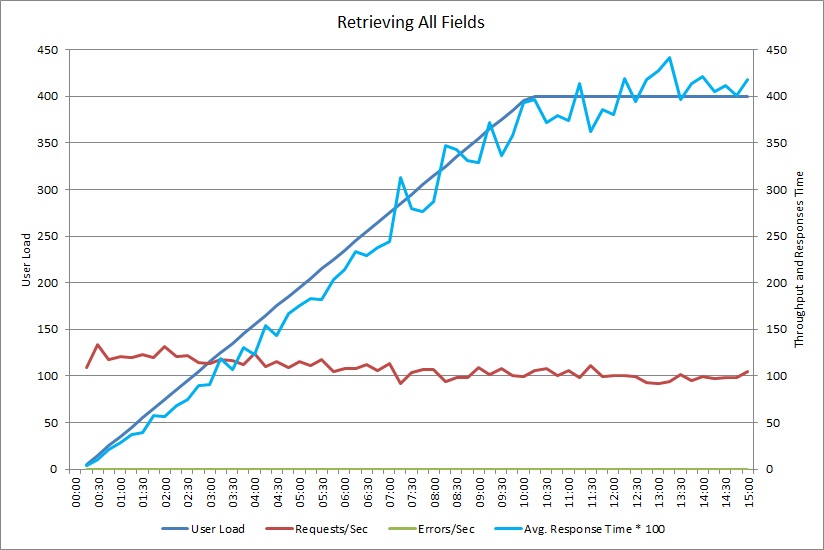
Ett belastningstest för åtgärden AggregateOnClientAsync visar ett liknande mönster. Mängden begäranden är någorlunda stabil. Den genomsnittliga svarstiden ökar med arbetsbelastningen, fast långsammare än i det tidigare diagrammet.
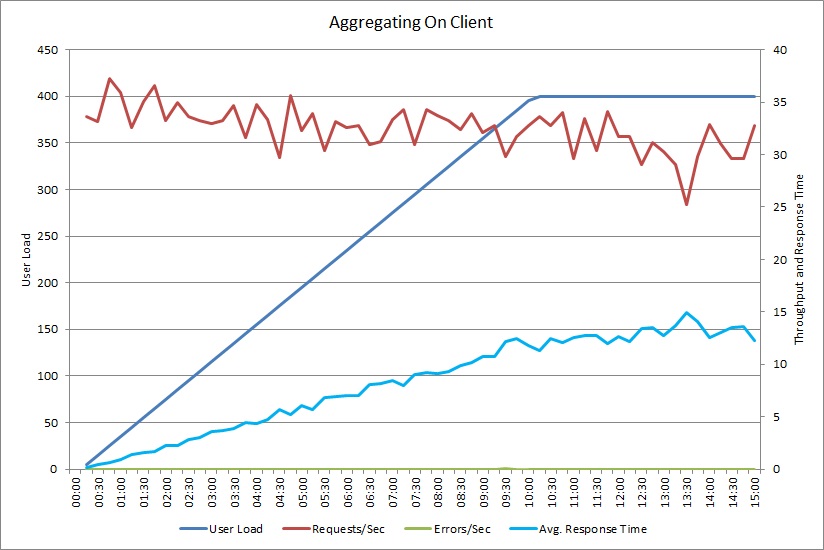
Korrelera långsamma arbetsbelastningar med beteendemönster
Alla samband mellan vanliga perioder med hög användning och långsammare prestanda kan tyda på problemområden. Undersök noga prestandaprofilen för funktionerna som misstänks vara långsamma, för att fastställa om det matchar belastningstestet som utfördes tidigare.
Belastningstesta samma funktioner med stegbaserade användarbelastningar, för att hitta den punkt då prestandan försämras betydligt eller misslyckas helt. Om den punkten faller inom gränsen för din förväntade verkliga användning undersöker du hur funktionerna implementeras.
En långsam åtgärd är inte nödvändigtvis ett problem, om den inte utförs när systemet är överbelastat, inte är tidskritisk och inte påverkar prestandan negativt för andra åtgärder. Exempel: att generera månatlig åtgärdsstatistik kan vara en långvarig åtgärd men den kan förmodligen utföras som en batchprocess och köras som ett jobb med låg prioritet. Å andra sidan är kunder som söker i produktkatalogen en affärskritisk åtgärd. Fokusera på telemetri som genererats av de här kritiska åtgärderna för att se hur prestanda varierar under perioder med hög användning.
Identifiera datakällor i långsamma arbetsbelastningar
Om du misstänker att en tjänst har sämre prestanda på grund av det sätt som den hämtar data på undersöker du hur programmet interagerar med de lagringsplatser den använder. Övervaka det aktiva systemet för att se vilka källor som används under perioder med sämre prestanda.
För varje datakälla instrumenterar du systemet att registrera följande:
- Frekvensen för åtkomst till varje datalager.
- Mängden data in i och ut ur datakällan.
- Tiden för åtgärderna, särskilt svarstiden för begäranden.
- Egenskaperna och frekvensen för fel som förekommer vid åtkomst av varje datalager under normal belastning.
Jämför den här informationen med mängden data som returneras av programmet till klienten. Spåra förhållandet mellan mängden data som returneras av datalagret och mängden data som returneras till klienten. Om det är stor skillnad undersöker du för att fastställa om programmet hämtar data som inte behövs.
Du kanske kan registrera dessa data genom att observera det aktiva systemet och spåra livscykeln för varje användarbegäran, eller så kan du modellera en serie syntetiska arbetsbelastningar och köra dem mot testsystemet.
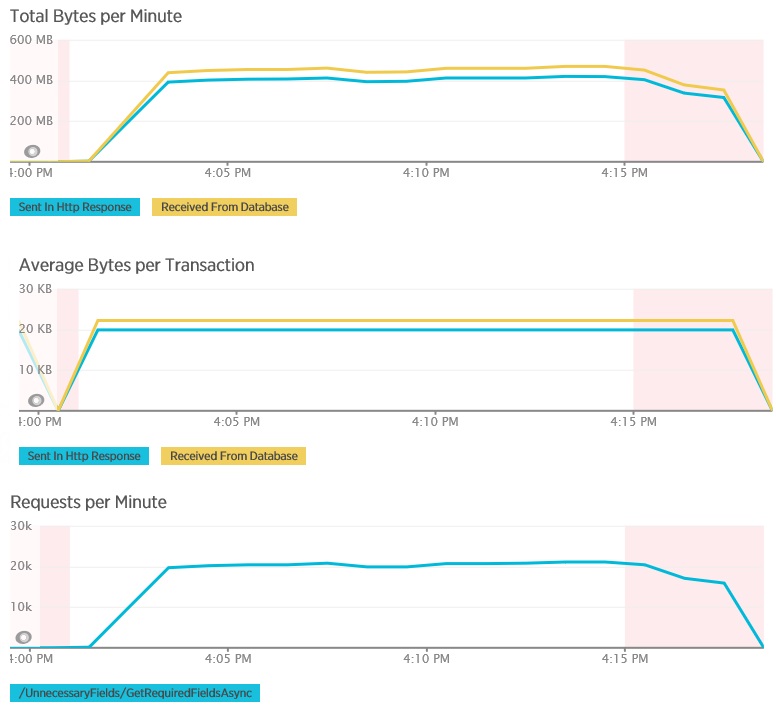
I följande diagram visas telemetri registrerad med New Relic APM under ett belastningstest för metoden GetAllFieldsAsync. Observera skillnaden mellan mängderna data som tas emot från databasen och motsvarande HTTP-svar.
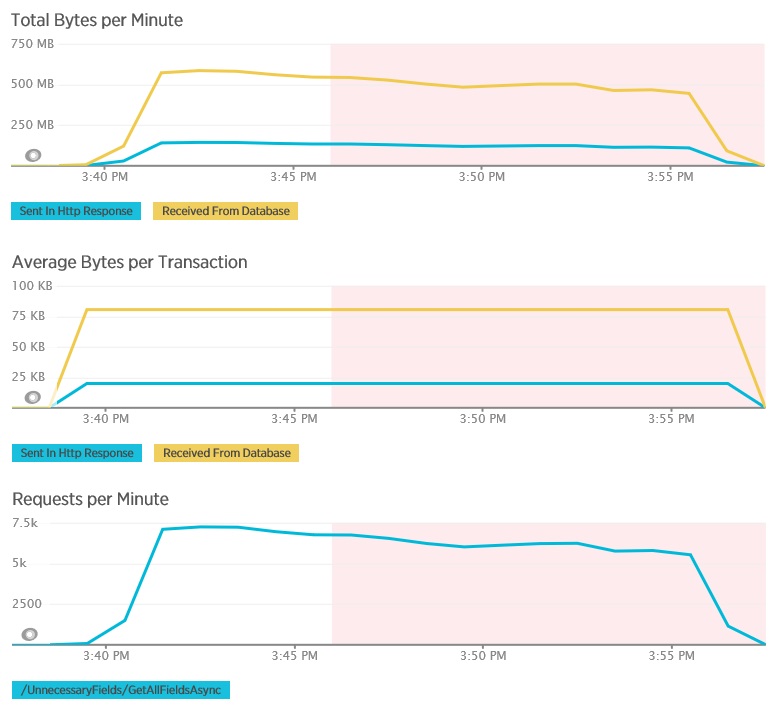
För varje begäran returnerade databasen 80 503 byte men svaret till klienten innehöll bara 19 855 byte, cirka 25 % av storleken på databassvaret. Storleken på returnerade data till klienten kan variera beroende på formatet. För det här belastningstestet begärde klienten JSON-data. Separat testning med XML (visas inte) hade en svarstid på 35 655 byte, eller 44 % av storleken på databassvaret.
Belastningstestet för metoden AggregateOnClientAsync visar mer extrema resultat. I det här fallet utförde varje test en fråga som hämtade över 280 kB data från databasen men JSON-svaret var bara på 14 byte. Den stora skillnaden beror på att metoden beräknar ett aggregerat resultat från en stor mängd data.
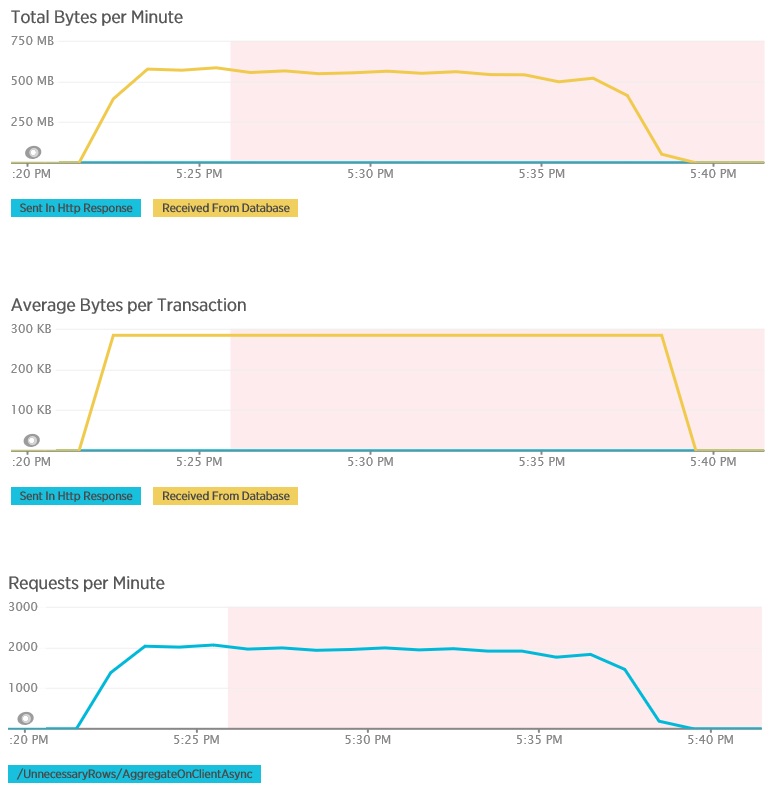
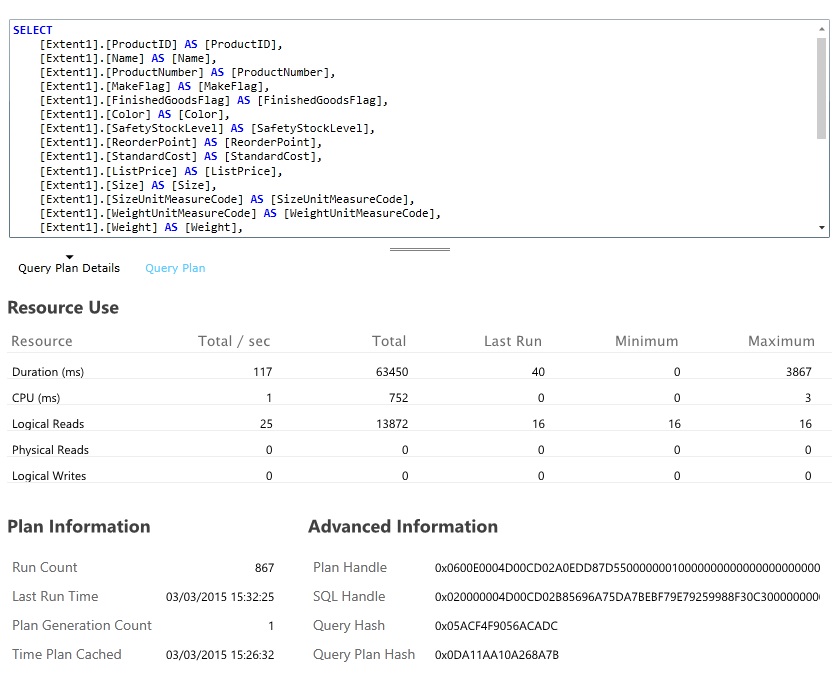
Identifiera och analysera långsamma frågor
Titta efter databasfrågor som förbrukar mest resurser och tar längst tid att utföra. Du kan lägga till instrumentering för att hitta start- och sluttider för många databasåtgärder. Många datalager har även detaljerad information om hur frågor utförs och optimeras. Till exempel kan du med fönstret Query Performance i Azure SQL Database-hanteringsportalen välja en fråga och visa detaljerad information om körningsprestanda. Här genereras frågan av åtgärden GetAllFieldsAsync:
Implementera lösningen och verifiera resultatet
Efter ändring av metoden GetRequiredFieldsAsync till att använda en SELECT-instruktion på databassidan visade belastningstestningen följande resultat.
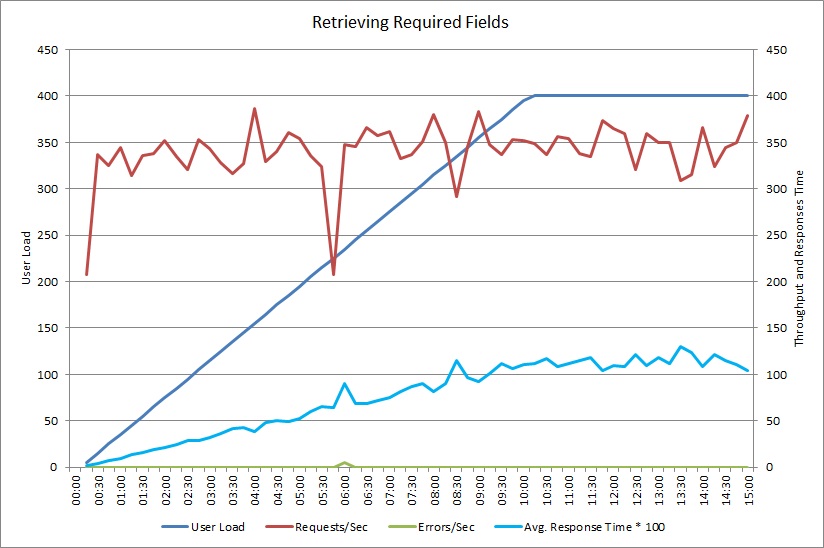
Det här belastningstestet använde samma distribution och samma simulerade arbetsbelastning på 400 samtidiga användare som tidigare. Diagrammet visar mycket kortare svarstider. Svarstiden stiger med belastning till cirka 1,3 sekunder, jämfört med 4 sekunder i det tidigare fallet. Dataflödet är också högre vid 350 begäranden jämfört med 100 tidigare. Mängden data som hämtas från databasen matchar nu nära storleken på HTTP-svarsmeddelandena.
Belastningstestning med metoden AggregateOnDatabaseAsync genererar följande resultat:
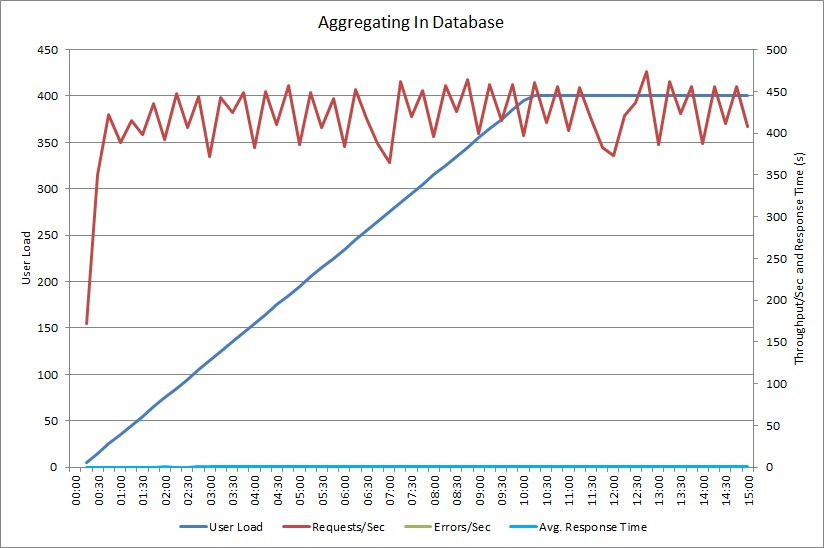
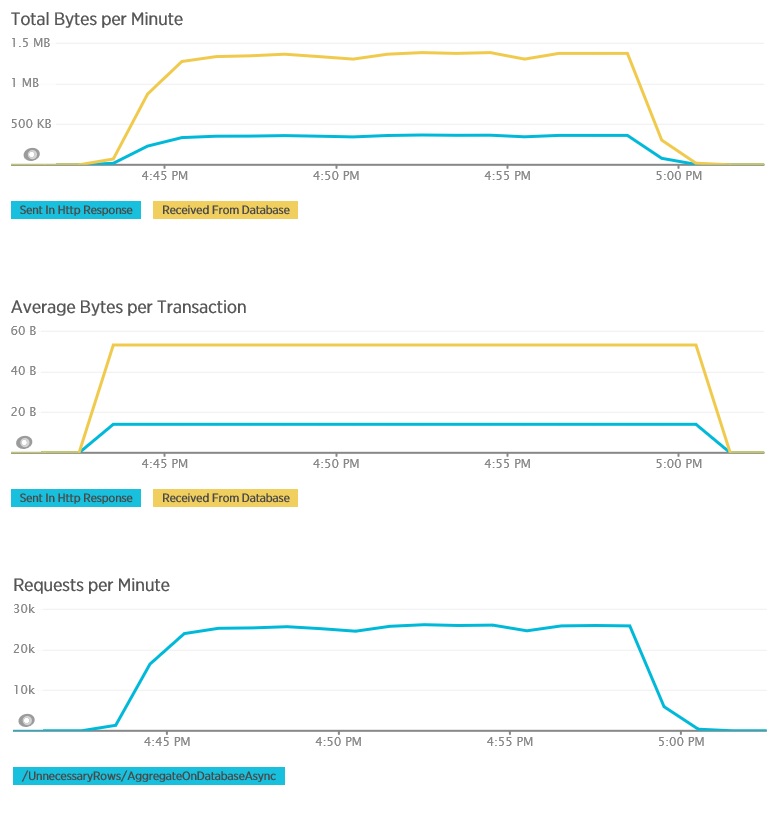
Den genomsnittliga svarstiden är nu minimal. Det här är en storleksförbättring av prestandan i, främst tack vare en stor minskning av I/O från databasen.
Här är motsvarande telemetri för metoden AggregateOnDatabaseAsync. Mängden data som hämtades från databasen minskades avsevärt, från över 280 kB per transaktion till 53 byte. Som ett resultat steg det maximala varaktiga antalet begäranden per minut från cirka 2 000 till över 25 000.
Relaterade resurser
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för