Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Azure Blob Storage
I många storskaliga lösningar delas data in i partitioner som kan hanteras och nås separat. Partitionering kan förbättra skalbarheten, minska konkurrensen och ge bästa möjliga prestanda. Det kan också ge en mekanism för att dela upp data efter användningsmönster. Du kan till exempel arkivera äldre data i billigare datalagring.
Partitioneringsstrategin måste dock väljas noggrant för att maximera fördelarna samtidigt som negativa effekter minimeras.
Anmärkning
I den här artikeln innebär termen partitionering processen att fysiskt dela upp data i separata datalager. Det är inte samma sak som SQL Server-tabellpartitionering.
Varför partitioneras data?
Förbättra skalbarheten. När du skalar upp ett enskilt databassystem når det så småningom en fysisk maskinvarugräns. Om du delar upp data mellan flera partitioner, som var och en finns på en separat server, kan du skala ut systemet nästan på obestämd tid.
Förbättra prestanda. Dataåtkomståtgärder på varje partition sker över en mindre mängd data. Partitionering kan göra systemet effektivare på rätt sätt. Åtgärder som påverkar mer än en partition kan köras parallellt.
Förbättra säkerheten. I vissa fall kan du separera känsliga och meningslösa data i olika partitioner och tillämpa olika säkerhetskontroller på känsliga data.
Ge flexibilitet i driften. Partitionering erbjuder många möjligheter för finjusteringsåtgärder, maximera administrativ effektivitet och minimera kostnader. Du kan till exempel definiera olika strategier för hantering, övervakning, säkerhetskopiering och återställning samt andra administrativa uppgifter baserat på vikten av data i varje partition.
Matcha datalagret med användningsmönstret. Partitionering gör att varje partition kan distribueras på en annan typ av datalager, baserat på kostnad och de inbyggda funktioner som datalagret erbjuder. Till exempel kan stora binära data lagras i bloblagring, medan mer strukturerade data kan lagras i en dokumentdatabas. Mer information finns i Välj rätt datalager.
Förbättra tillgängligheten. Om du separerar data mellan flera servrar undviks en felpunkt. Om en instans misslyckas är endast data i partitionen otillgängliga. Åtgärder på andra partitioner kan fortsätta. För datalager för hanterad plattform som en tjänst (PaaS) är detta mindre relevant, eftersom dessa tjänster är utformade med inbyggd redundans.
Utforma partitioner
Det finns tre vanliga strategier för partitionering av data:
Horisontell partitionering (kallas ofta sharding). I den här strategin är varje partition ett separat datalager, men alla partitioner har samma schema. Varje partition kallas för en shard och innehåller en specifik delmängd av data, till exempel alla beställningar för en specifik uppsättning kunder.
Vertikal partitionering. I den här strategin innehåller varje partition en delmängd av fälten för objekt i datalagret. Fälten delas upp enligt användningsmönstret. Till exempel kan fält som används ofta placeras i en vertikal partition och mindre ofta använda fält i en annan.
Funktionell partitionering. I den här strategin aggregeras data enligt hur de används av varje begränsad kontext i systemet. Ett e-handelssystem kan till exempel lagra fakturadata i en partition och produktinventeringsdata i en annan.
Dessa strategier kan kombineras och vi rekommenderar att du överväger dem alla när du utformar ett partitioneringsschema. Du kan till exempel dela upp data i shards och sedan använda vertikal partitionering för att ytterligare dela upp data i varje shard.
Horisontell partitionering (sharding)
Bild 1 visar horisontell partitionering eller horisontell partitionering. I det här exemplet delas produktinventeringsdata in i shards baserat på produktnyckeln. Varje shard innehåller data för ett sammanhängande intervall med shardnycklar (A-G och H-Z), ordnade i alfabetisk ordning. Horisontell partitionering sprider belastningen över fler datorer, vilket minskar konkurrensen och förbättrar prestanda.
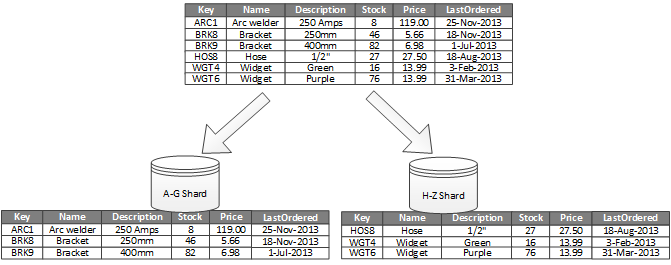
Bild 1 – Horisontell partitionering av (horisontell partitionering) data baserat på en partitionsnyckel.
Den viktigaste faktorn är valet av en partitioneringsnyckel. Det kan vara svårt att ändra nyckeln när systemet är i drift. Nyckeln måste se till att data partitioneras för att sprida arbetsbelastningen så jämnt som möjligt över fragmenten.
Fragmenten behöver inte ha samma storlek. Det är viktigare att balansera antalet begäranden. Vissa shards kan vara mycket stora, men varje objekt har ett lågt antal åtkomståtgärder. Andra shards kan vara mindre, men varje objekt används mycket oftare. Det är också viktigt att se till att en enda shard inte överskrider skalningsgränserna (när det gäller kapacitet och bearbetningsresurser) för datalagret.
Undvik att skapa "heta" partitioner som kan påverka prestanda och tillgänglighet. Om du till exempel använder den första bokstaven i en kunds namn blir distributionen obalanserad eftersom vissa bokstäver är vanligare. Använd i stället en hash för en kundidentifierare för att distribuera data jämnare över partitioner.
Välj en horisontell partitioneringsnyckel som minimerar framtida krav för att dela upp stora shards, slå samman små fragment i större partitioner eller ändra schemat. Dessa åtgärder kan vara mycket tidskrävande och kan kräva att en eller flera shards tas offline medan de utförs.
Om shards replikeras kan det vara möjligt att hålla vissa repliker online medan andra delas, sammanfogas eller konfigureras om. Systemet kan dock behöva begränsa de åtgärder som kan utföras under omkonfigurationen. Data i replikerna kan till exempel markeras som skrivskyddade för att förhindra datainkonsekvenser.
Mer information om horisontell partitionering finns i Mönster för horisontell partitionering.
Lodrät partitionering
Den vanligaste användningen för vertikal partitionering är att minska I/O- och prestandakostnaderna för att hämta objekt som används ofta. Bild 2 visar ett exempel på vertikal partitionering. I det här exemplet lagras olika egenskaper för ett objekt i olika partitioner. En partition innehåller data som används oftare, inklusive produktnamn, beskrivning och pris. En annan partition innehåller inventeringsdata: lagerantalet och senaste sorteringsdatum.
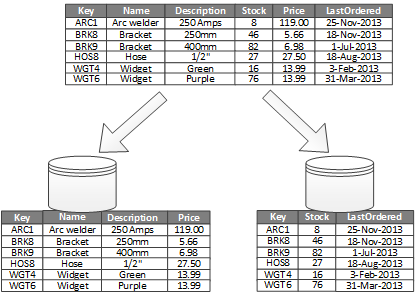
Bild 2 – Partitionera data lodrätt med dess användningsmönster.
I det här exemplet frågar programmet regelbundet produktnamnet, beskrivningen och priset när produktinformationen visas för kunderna. Lagerantal och senaste sorteringsdatum lagras i en separat partition eftersom dessa två objekt ofta används tillsammans.
Andra fördelar med vertikal partitionering:
Relativt långsamma data (produktnamn, beskrivning och pris) kan separeras från mer dynamiska data (lagernivå och senaste beställningsdatum). Långsamma data är en bra kandidat för ett program att cachas i minnet.
Känsliga data kan lagras i en separat partition med ytterligare säkerhetskontroller.
Vertikal partitionering kan minska mängden samtidig åtkomst som behövs.
Vertikal partitionering fungerar på entitetsnivå i ett datalager, vilket delvis normaliserar en entitet för att dela upp den från ett brett objekt till en uppsättning smala objekt. Den passar perfekt för kolumnorienterade datalager som HBase och Cassandra. Om data i en samling kolumner sannolikt inte kommer att ändras kan du även överväga att använda kolumnlager i SQL Server.
Funktionell partitionering
När det är möjligt att identifiera en avgränsad kontext för varje enskilt affärsområde i ett program är funktionell partitionering ett sätt att förbättra isolerings- och dataåtkomstprestanda. En annan vanlig användning för funktionell partitionering är att separera läs- och skrivdata från skrivskyddade data. Bild 3 visar en översikt över funktionell partitionering där inventeringsdata separeras från kunddata.
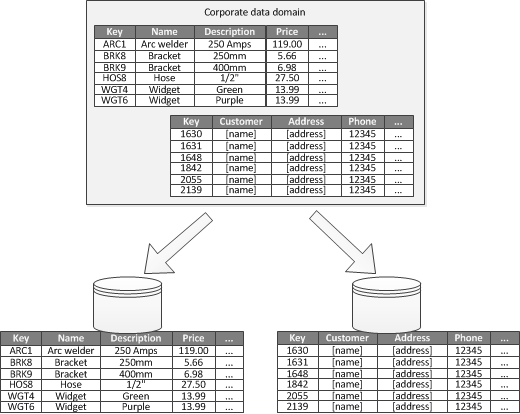
Bild 3 – Funktionell partitionering av data med begränsad kontext eller underdomän.
Den här partitioneringsstrategin kan bidra till att minska konkurrensen om dataåtkomst i olika delar av ett system.
Utforma partitioner för skalbarhet
Det är viktigt att tänka på storlek och arbetsbelastning för varje partition och balansera dem så att data distribueras för att uppnå maximal skalbarhet. Men du måste också partitionera data så att de inte överskrider skalningsgränserna för ett enda partitionslager.
Följ dessa steg när du utformar partitioner för skalbarhet:
- Analysera programmet för att förstå dataåtkomstmönstren, till exempel storleken på resultatuppsättningen som returneras av varje fråga, åtkomstfrekvensen, den inbyggda svarstiden och bearbetningskraven på serversidan. I många fall kräver några större entiteter de flesta bearbetningsresurserna.
- Använd den här analysen för att fastställa aktuella och framtida skalbarhetsmål, till exempel datastorlek och arbetsbelastning. Distribuera sedan data mellan partitionerna för att uppfylla skalbarhetsmålet. För horisontell partitionering är det viktigt att välja rätt shardnyckel för att se till att distributionen är jämn. Mer information finns i mönstret för horisontell partitionering.
- Se till att varje partition har tillräckligt med resurser för att hantera skalbarhetskraven när det gäller datastorlek och dataflöde. Beroende på datalagret kan det finnas en gräns för mängden lagringsutrymme, bearbetningskraft eller nätverksbandbredd per partition. Om kraven sannolikt överskrider dessa gränser kan du behöva förfina partitioneringsstrategin eller dela upp data ytterligare, eventuellt genom att kombinera två eller flera strategier.
- Övervaka systemet för att kontrollera att data distribueras som förväntat och att partitionerna kan hantera belastningen. Den faktiska användningen matchar inte alltid vad en analys förutsäger. I så fall kan det vara möjligt att balansera om partitionerna, eller omdesigna vissa delar av systemet för att få det nödvändiga saldot.
Vissa molnmiljöer allokerar resurser när det gäller infrastrukturgränser. Se till att gränserna för den valda gränsen ger tillräckligt med utrymme för förväntad ökning av datavolymen, när det gäller datalagring, bearbetningskraft och bandbredd.
Om du till exempel använder Azure Table Storage finns det en gräns för mängden begäranden som kan hanteras av en enskild partition under en viss tidsperiod. (Mer information finns i Skalbarhets- och prestandamål för Azure Storage.) En upptagen shard kan kräva mer resurser än en enskild partition kan hantera. I så fall kan fragmentet behöva partitioneras om för att sprida belastningen. Om den totala storleken eller dataflödet för dessa tabeller överskrider kapaciteten för ett lagringskonto kan du behöva skapa ytterligare lagringskonton och sprida tabellerna över dessa konton.
Utforma partitioner för frågeprestanda
Frågeprestanda kan ofta ökas med hjälp av mindre datamängder och genom att köra parallella frågor. Varje partition bör innehålla en liten del av hela datamängden. Den här volymminskningen kan förbättra prestandan för sökfrågor. Partitionering är dock inte ett alternativ för att utforma och konfigurera en databas på rätt sätt. Kontrollera till exempel att du har de index som behövs.
Följ dessa steg när du utformar partitioner för frågeprestanda:
Granska programmets krav och prestanda:
- Använd affärskrav för att fastställa kritiska frågor som alltid måste utföras snabbt.
- Övervaka systemet för att identifiera eventuella frågor som utförs långsamt.
- Ta reda på vilka frågor som utförs oftast. Även om en enskild fråga har en minimal kostnad kan den kumulativa resursförbrukningen vara betydande.
Partitionering av data som orsakar långsamma prestanda:
- Begränsa storleken på varje partition så att frågesvarstiden ligger inom målet.
- Om du använder horisontell partitionering utformar du shardnyckeln så att programmet enkelt kan välja rätt partition. Detta hindrar frågan från att behöva söka igenom varje partition.
- Överväg platsen för en partition. Försök om möjligt att lagra data i partitioner som är geografiskt nära de program och användare som har åtkomst till dem.
Om en entitet har dataflödes- och frågeprestandakrav använder du funktionell partitionering baserat på den entiteten. Om detta fortfarande inte uppfyller kraven tillämpar du även horisontell partitionering. I de flesta fall räcker det med en enda partitioneringsstrategi, men i vissa fall är det mer effektivt att kombinera båda strategierna.
Överväg att köra frågor parallellt mellan partitioner för att förbättra prestandan.
Utforma partitioner för tillgänglighet
Partitionering av data kan förbättra tillgängligheten för program genom att säkerställa att hela datamängden inte utgör en enskild felpunkt och att enskilda delmängder av datamängden kan hanteras oberoende av varandra.
Tänk på följande faktorer som påverkar tillgängligheten:
Hur viktiga data är för verksamheten. Identifiera vilka data som är viktig affärsinformation, till exempel transaktioner, och vilka data som är mindre kritiska driftdata, till exempel loggfiler.
Överväg att lagra kritiska data i partitioner med hög tillgänglighet med en lämplig säkerhetskopieringsplan.
Upprätta separata hanterings- och övervakningsförfaranden för de olika datauppsättningarna.
Placera data som har samma kritiska nivå i samma partition så att de kan säkerhetskopieras tillsammans med en lämplig frekvens. Partitioner som innehåller transaktionsdata kan till exempel behöva säkerhetskopieras oftare än partitioner som innehåller loggnings- eller spårningsinformation.
Hur enskilda partitioner kan hanteras. Att utforma partitioner för att stödja oberoende hantering och underhåll ger flera fördelar. Till exempel:
Om en partition misslyckas kan den återställas oberoende av varandra utan program som har åtkomst till data i andra partitioner.
Genom att partitionera data efter geografiskt område kan schemalagda underhållsaktiviteter utföras vid låg belastning för varje plats. Se till att partitionerna inte är för stora för att förhindra att planerat underhåll slutförs under den här perioden.
Om du vill replikera kritiska data mellan partitioner. Den här strategin kan förbättra tillgängligheten och prestandan, men kan också leda till konsekvensproblem. Det tar tid att synkronisera ändringar med varje replik. Under den här perioden innehåller olika partitioner olika datavärden.
Överväganden för programdesign
Partitionering ökar komplexiteten i systemets design och utveckling. Överväg att partitionera som en grundläggande del av systemdesignen även om systemet inledningsvis bara innehåller en enda partition. Om du hanterar partitionering som en eftertanke är det mer utmanande eftersom du redan har ett realtidssystem att underhålla:
- Dataåtkomstlogik måste ändras.
- Stora mängder befintliga data kan behöva migreras för att distribuera dem mellan partitioner.
- Användarna förväntar sig att kunna fortsätta använda systemet under migreringen.
I vissa fall anses partitionering inte vara viktigt eftersom den inledande datauppsättningen är liten och hanteras enkelt av en enskild server. Detta kan vara sant för vissa arbetsbelastningar, men många kommersiella system måste utökas när antalet användare ökar.
Dessutom är det inte bara stora datalager som drar nytta av partitionering. Ett litet datalager kan till exempel ha stor åtkomst till hundratals samtidiga klienter. Partitionering av data i den här situationen kan bidra till att minska konkurrensen och förbättra dataflödet.
Tänk på följande när du utformar ett datapartitioneringsschema:
Minimera dataåtkomståtgärder mellan partitioner. Om möjligt bör du hålla ihop data för de vanligaste databasåtgärderna i varje partition för att minimera dataåtkomståtgärder mellan partitioner. Att fråga mellan partitioner kan vara mer tidskrävande än att fråga inom en enda partition, men optimering av partitioner för en uppsättning frågor kan påverka andra frågeuppsättningar negativt. Om du måste fråga mellan partitioner minimerar du frågetiden genom att köra parallella frågor och aggregera resultaten i programmet. (Den här metoden kanske inte är möjlig i vissa fall, till exempel när resultatet från en fråga används i nästa fråga.)
Överväg att replikera statiska referensdata. Om frågor använder relativt statiska referensdata, till exempel postnummertabeller eller produktlistor, bör du överväga att replikera dessa data i alla partitioner för att minska separata uppslagsåtgärder i olika partitioner. Den här metoden kan också minska sannolikheten för att referensdata blir en "frekvent" datauppsättning, med tung trafik från hela systemet. Det finns dock en extra kostnad som är associerad med att synkronisera eventuella ändringar av referensdata.
Minimera kopplingar mellan partitioner. Om möjligt minimerar du kraven på referensintegritet mellan vertikala och funktionella partitioner. I dessa scheman ansvarar programmet för att upprätthålla referensintegriteten mellan partitioner. Frågor som kopplar data över flera partitioner är ineffektiva eftersom programmet vanligtvis behöver utföra frågor i följd baserat på en nyckel och sedan en sekundärnyckel. Överväg i stället att replikera eller avnormalisera relevanta data. Om det krävs kopplingar mellan partitioner kör du parallella frågor över partitionerna och ansluter data i programmet.
Ta till dig eventuell konsekvens. Utvärdera om stark konsekvens faktiskt är ett krav. En vanlig metod i distribuerade system är att implementera eventuell konsistens. Data i varje partition uppdateras separat och programlogik säkerställer att alla uppdateringar har slutförts. Den hanterar också de inkonsekvenser som kan uppstå vid frågor mot data medan en så småningom konsekvent åtgärd körs.
Fundera på hur frågor hittar rätt partition. Om en fråga måste söka igenom alla partitioner för att hitta de data som krävs har prestandan stor inverkan, även när flera parallella frågor körs. Med vertikal och funktionell partitionering kan frågor ange partitionen naturligt. Horisontell partitionering kan å andra sidan göra det svårt att hitta ett objekt, eftersom varje fragment har samma schema. En typisk lösning för att underhålla en karta som används för att leta upp shardplatsen för specifika objekt. Den här kartan kan implementeras i programmets horisontella logik eller underhållas av datalagret om den stöder transparent horisontell partitionering.
Överväg att regelbundet ombalansera shards. Med horisontell partitionering kan ombalansering av shards hjälpa till att fördela data jämnt efter storlek och arbetsbelastning för att minimera hotspots, maximera frågeprestanda och kringgå begränsningar för fysisk lagring. Detta är dock en komplex uppgift som ofta kräver användning av ett anpassat verktyg eller en anpassad process.
Replikera partitioner. Om du replikerar varje partition ger den ytterligare skydd mot fel. Om en enskild replik misslyckas kan frågor riktas mot en fungerande kopia.
Om du når de fysiska gränserna för en partitioneringsstrategi kan du behöva utöka skalbarheten till en annan nivå. Om partitioneringen till exempel är på databasnivå kan du behöva hitta eller replikera partitioner i flera databaser. Om partitionering redan är på databasnivå och fysiska begränsningar är ett problem kan det innebära att du måste hitta eller replikera partitioner på flera värdkonton.
Undvik transaktioner som har åtkomst till data i flera partitioner. Vissa datalager implementerar transaktionskonsekvens och integritet för åtgärder som ändrar data, men bara när data finns i en enda partition. Om du behöver transaktionsstöd över flera partitioner måste du förmodligen implementera det som en del av programlogik eftersom de flesta partitioneringssystem inte har inbyggt stöd.
Alla datalager kräver viss driftshanterings- och övervakningsaktivitet. Uppgifterna kan vara allt från att läsa in data, säkerhetskopiera och återställa data, omorganisera data och se till att systemet fungerar korrekt och effektivt.
Tänk på följande faktorer som påverkar driftshanteringen:
Så här implementerar du lämpliga hanterings- och driftuppgifter när data partitioneras. Dessa uppgifter kan omfatta säkerhetskopiering och återställning, arkivering av data, övervakning av systemet och andra administrativa uppgifter. Det kan till exempel vara en utmaning att upprätthålla logisk konsekvens under säkerhetskopierings- och återställningsåtgärder.
Så här läser du in data i flera partitioner och lägger till nya data som kommer från andra källor. Vissa verktyg och verktyg kanske inte stöder horisontella dataåtgärder, till exempel att läsa in data i rätt partition.
Hur du arkiverar och tar bort data regelbundet. För att förhindra överdriven tillväxt av partitioner måste du arkivera och ta bort data regelbundet (till exempel varje månad). Det kan vara nödvändigt att transformera data så att de matchar ett annat arkivschema.
Så här hittar du problem med dataintegritet. Överväg att köra en periodisk process för att hitta dataintegritetsproblem, till exempel data i en partition som refererar till information som saknas i en annan. Processen kan antingen försöka åtgärda dessa problem automatiskt eller generera en rapport för manuell granskning.
Ombalansera partitioner
När ett system mognar kan du behöva justera partitioneringsschemat. Till exempel kan enskilda partitioner börja få en oproportionerlig mängd trafik och bli heta, vilket leder till överdriven konkurrens. Eller så kanske du har underskattat mängden data i vissa partitioner, vilket gör att vissa partitioner närmar sig kapacitetsbegränsningar.
Vissa datalager, till exempel Azure Cosmos DB, kan automatiskt balansera om partitioner. I andra fall är ombalansering en administrativ uppgift som består av två steg:
Fastställ en ny partitioneringsstrategi.
- Vilka partitioner måste delas upp (eller eventuellt kombineras)?
- Vad är den nya partitionsnyckeln?
Migrera data från det gamla partitioneringsschemat till den nya uppsättningen partitioner.
Beroende på datalagret kanske du kan migrera data mellan partitioner medan de används. Detta kallas onlinemigrering. Om det inte är möjligt kan du behöva göra partitioner otillgängliga när data flyttas (offlinemigrering).
Offlinemigrering
Offlinemigrering är vanligtvis enklare eftersom det minskar risken för konkurrens. Konceptuellt fungerar offlinemigrering på följande sätt:
- Markera partitionen offline.
- Dela samman och flytta data till de nya partitionerna.
- Kontrollera uppgifterna.
- Ta de nya partitionerna i drift.
- Ta bort den gamla partitionen.
Du kan också markera en partition som skrivskyddad i steg 1, så att program fortfarande kan läsa data medan de flyttas.
Online migrering
Onlinemigrering är mer komplext att utföra men mindre störande. Processen liknar offlinemigrering, förutom att den ursprungliga partitionen inte är markerad offline. Beroende på migreringsprocessens kornighet (till exempel objekt efter objekt jämfört med shard av shard) kan dataåtkomstkoden i klientprogrammen behöva hantera läsning och skrivning av data som finns på två platser, den ursprungliga partitionen och den nya partitionen.
Nästa steg
- Lär dig mer om partitioneringsstrategier för specifika Azure-tjänster. Mer information finns i Strategier för datapartitionering.
- Skalbarhets- och prestandamål för Azure Storage
Relaterade resurser
Följande designmönster kan vara relevanta för ditt scenario:
Fragmenteringsmönstret beskriver några vanliga strategier för horisontell partitionering av data.
Indextabellmönstret visar hur du skapar sekundära index över data. Ett program kan snabbt hämta data med den här metoden genom att använda frågor som inte refererar till den primära nyckeln i en samling.
Det materialiserade vymönstret beskriver hur du genererar förifyllda vyer som sammanfattar data för att stödja snabba frågeåtgärder. Den här metoden kan vara användbar i ett partitionerat datalager om partitionerna som innehåller de data som sammanfattas distribueras på flera platser.