Extrahering, transformering och laddning (ETL)
Ett vanligt problem som organisationer står inför är hur man samlar in data från flera källor i flera format. Sedan skulle du behöva flytta den till ett eller flera datalager. Målet kanske inte är samma typ av datalager som källan. Ofta är formatet annorlunda, eller så måste data formas eller rensas innan de läses in till slutmålet.
Olika verktyg, tjänster och processer har utvecklats under årens lopp för att hjälpa dig att hantera dessa utmaningar. Oavsett vilken process som används finns det ett gemensamt behov av att samordna arbetet och tillämpa en viss nivå av datatransformering i datapipelinen. I följande avsnitt beskrivs de vanliga metoder som används för att utföra dessa uppgifter.
Extrahera, transformera, läsa in (ETL)-process
extract, transform, load (ETL) är en datapipeline som används för att samla in data från olika källor. Sedan transformeras data enligt affärsregler och data läses in i ett måldatalager. Omvandlingsarbetet i ETL sker i en specialiserad motor, och det handlar ofta om att använda mellanlagringstabeller för att tillfälligt lagra data när de transformeras och slutligen läses in till målet.
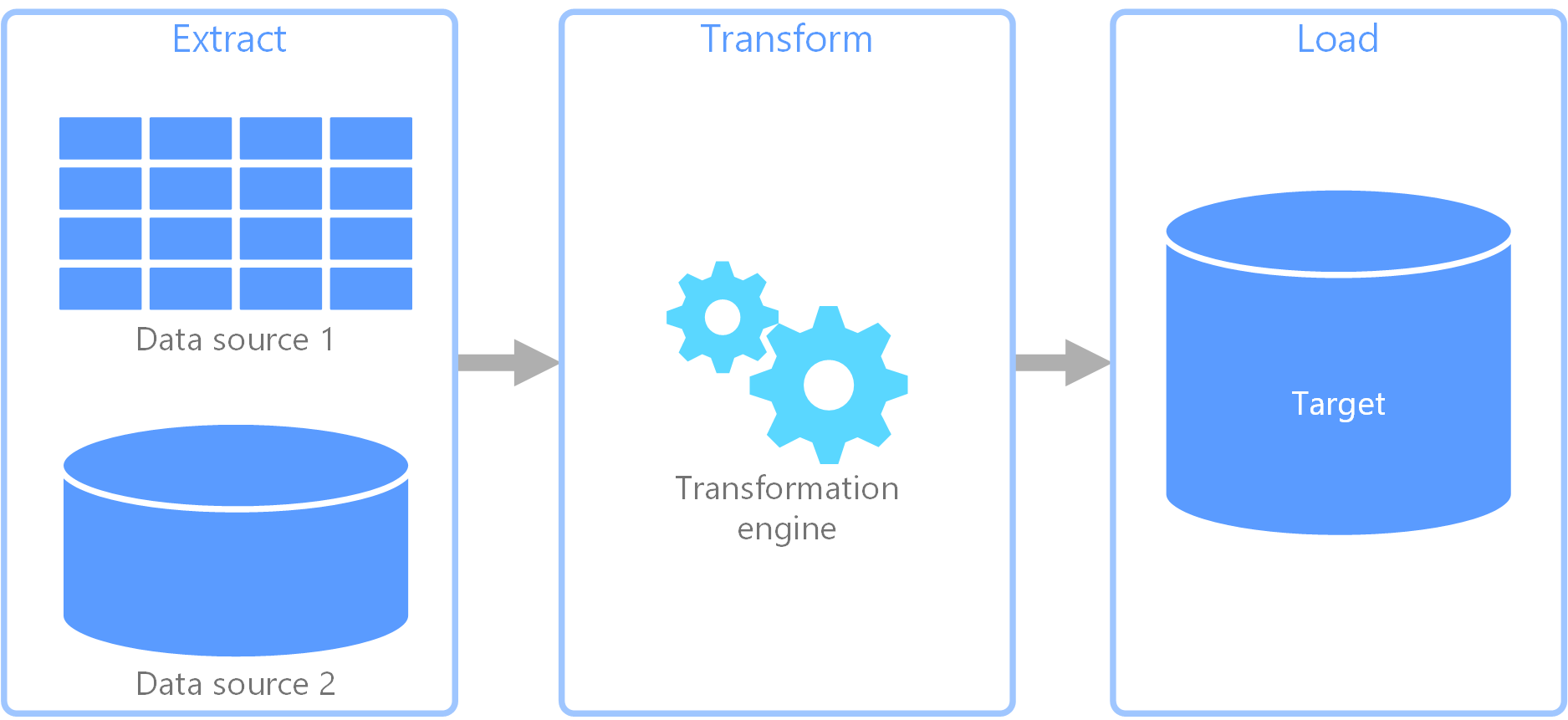
Datatransformeringen som sker omfattar vanligtvis olika åtgärder, till exempel filtrering, sortering, aggregering, sammanfogning av data, rensning av data, deduplicering och validering av data.
Ofta körs de tre ETL-faserna parallellt för att spara tid. Medan data till exempel extraheras kan en transformeringsprocess arbeta med data som redan har tagits emot och förbereda dem för inläsning, och en inläsningsprocess kan börja arbeta med förberedda data i stället för att vänta på att hela extraheringsprocessen ska slutföras.
Relevant Azure-tjänst:
Andra verktyg:
Extrahera, läsa in, transformera (ELT)
Extrahering, inläsning, transformering (ELT) skiljer sig från ETL enbart i den plats där omvandlingen sker. I ELT-pipelinen sker omvandlingen i måldatalagret. I stället för att använda en separat transformeringsmotor används bearbetningsfunktionerna i måldatalagret för att transformera data. Detta förenklar arkitekturen genom att ta bort transformeringsmotorn från pipelinen. En annan fördel med den här metoden är att skalning av måldatalagret även skalar ELT-pipelinens prestanda. ELT fungerar dock bara bra när målsystemet är tillräckligt kraftfullt för att transformera data effektivt.
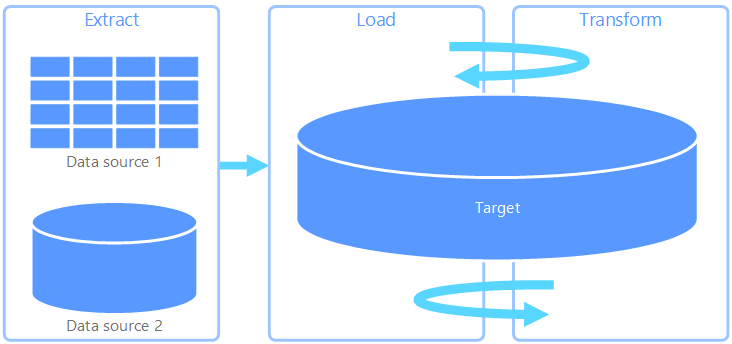
Vanliga användningsfall för ELT hör till stordatasfären. Du kan till exempel börja med att extrahera alla källdata till flata filer i skalbar lagring, till exempel ett Hadoop Distributed File System, ett Azure Blob Store eller Azure Data Lake gen 2 (eller en kombination). Tekniker som Spark, Hive eller PolyBase kan sedan användas för att köra frågor mot källdata. Den viktigaste punkten med ELT är att datalagret som används för att utföra omvandlingen är samma datalager där data slutligen förbrukas. Det här datalagret läser direkt från den skalbara lagringen i stället för att läsa in data i sin egen upphovsrättsskyddade lagring. Den här metoden hoppar över datakopieringssteget som finns i ETL, vilket ofta kan vara en tidskrävande åtgärd för stora datamängder.
I praktiken är måldatalagret ett informationslager med antingen ett Hadoop-kluster (med Hive eller Spark) eller en dedikerad SQL-pool i Azure Synapse Analytics. I allmänhet läggs ett schema över på flata fildata vid frågetillfället och lagras som en tabell, vilket gör att data kan efterfrågas som alla andra tabeller i datalagret. Dessa kallas externa tabeller eftersom data inte finns i lagring som hanteras av själva datalagret, utan på en del extern skalbar lagring, till exempel Azure Data Lake Store eller Azure Blob Storage.
Datalagret hanterar endast schemat för data och tillämpar schemat vid läsning. Ett Hadoop-kluster som använder Hive skulle till exempel beskriva en Hive-tabell där datakällan i praktiken är en sökväg till en uppsättning filer i HDFS. I Azure Synapse kan PolyBase uppnå samma resultat – skapa en tabell mot data som lagras externt i själva databasen. När källdata har lästs in kan data som finns i de externa tabellerna bearbetas med hjälp av funktionerna i datalagret. I stordatascenarier innebär det att datalagret måste kunna bearbetas massivt parallellt (MPP), vilket delar upp data i mindre segment och distribuerar bearbetningen av segmenten över flera noder parallellt.
Den sista fasen i ELT-pipelinen är vanligtvis att omvandla källdata till ett slutligt format som är mer effektivt för de typer av frågor som behöver stödjas. Data kan till exempel partitioneras. ELT kan också använda optimerade lagringsformat som Parquet, som lagrar radorienterade data på ett kolumnbaserat sätt och ger optimerad indexering.
Relevant Azure-tjänst:
- SQL-dedikerade pooler i Azure Synapse Analytics
- SQL Serverless-pooler i Azure Synapse Analytics
- HDInsight med Hive
- Azure Data Factory
- Datamarter i Power BI
Andra verktyg:
Dataflöde och kontrollflöde
I samband med datapipelines säkerställer kontrollflödet ordnad bearbetning av en uppsättning uppgifter. För att framtvinga rätt bearbetningsordning för dessa uppgifter används prioritetsbegränsningar. Du kan se dessa begränsningar som anslutningsappar i ett arbetsflödesdiagram, som du ser i bilden nedan. Varje uppgift har ett resultat, till exempel framgång, fel eller slutförande. Efterföljande aktiviteter initierar inte bearbetning förrän dess föregående har slutförts med något av dessa resultat.
Kontrollflöden kör dataflöden som en uppgift. I en dataflödesaktivitet extraheras data från en källa, transformeras eller läses in i ett datalager. Utdata från en dataflödesaktivitet kan vara indata till nästa dataflödesaktivitet och dataflöden kan köras parallellt. Till skillnad från kontrollflöden kan du inte lägga till begränsningar mellan aktiviteter i ett dataflöde. Du kan dock lägga till ett datavisningsprogram för att observera data när de bearbetas av varje uppgift.
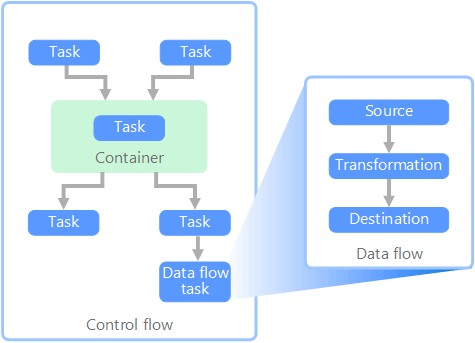
I diagrammet ovan finns det flera uppgifter i kontrollflödet, varav en är en dataflödesaktivitet. En av uppgifterna är kapslad i en container. Containrar kan användas för att tillhandahålla struktur för uppgifter, vilket ger en arbetsenhet. Ett sådant exempel är för upprepande element i en samling, till exempel filer i en mapp eller databasinstruktioner.
Relevant Azure-tjänst:
Andra verktyg:
Teknikval
- Datalager för onlinetransaktionsbearbetning (OLTP)
- OLAP-datalager (Online Analytical Processing)
- Informationslager
- Pipelineorkestrering
Nästa steg
- Integrera data med Azure Data Factory eller Azure Synapse Pipeline
- Introduktion till Azure Synapse Analytics
- Samordna dataflytt och transformering i Azure Data Factory eller Azure Synapse Pipeline
Relaterade resurser
Följande referensarkitekturer visar ELT-pipelines från slutpunkt till slutpunkt i Azure: