Pipelines och aktiviteter i Azure Data Factory och Azure Synapse Analytics
GÄLLER FÖR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Viktigt!
Stödet för Azure Mašinsko učenje Studio (klassisk) upphör den 31 augusti 2024. Vi rekommenderar att du övergår till Azure Mašinsko učenje vid det datumet.
Från och med den 1 december 2021 kan du inte skapa nya Mašinsko učenje Studio-resurser (klassiska) (arbetsyta och webbtjänstplan). Till och med den 31 augusti 2024 kan du fortsätta att använda de befintliga experimenten Mašinsko učenje Studio (klassisk) och webbtjänster. Mer information finns i:
- Migrera till Azure Mašinsko učenje från Mašinsko učenje Studio (klassisk)
- Vad är Azure Machine Learning?
Mašinsko učenje Studio-dokumentationen (klassisk) dras tillbaka och kanske inte uppdateras i framtiden.
Den här artikeln hjälper dig att förstå pipelines och aktiviteter i Azure Data Factory och Azure Synapse Analytics och använda dem för att konstruera datadrivna arbetsflöden från slutpunkt till slutpunkt för dina scenarier för dataflytt och databearbetning.
Översikt
En Data Factory- eller Synapse-arbetsyta kan ha en eller flera pipelines. En pipeline är en logisk gruppering av aktiviteter som tillsammans utför en uppgift. En pipeline kan till exempel innehålla en uppsättning aktiviteter som matar in och rensar loggdata, och sedan startar ett mappningsdataflöde för att analysera loggdata. Pipelinen gör att du kan hantera aktiviteterna som en uppsättning i stället för var och en. Du distribuerar och schemalägger pipelinen i stället för aktiviteterna oberoende av varandra.
Aktiviteterna i en pipeline definierar åtgärder som ska utföras på dina data. Du kan till exempel använda en kopieringsaktivitet för att kopiera data från SQL Server till Azure Blob Storage. Använd sedan en dataflödesaktivitet eller en Databricks Notebook-aktivitet för att bearbeta och transformera data från bloblagringen till en Azure Synapse Analytics-pool ovanpå vilken business intelligence-rapporteringslösningar skapas.
Azure Data Factory och Azure Synapse Analytics har tre grupper av aktiviteter: dataflyttaktiviteter, datatransformeringsaktiviteter och kontrollaktiviteter. En aktivitet kan ha noll eller flera indatauppsättningar och kan producera en eller flera utdatauppsättningar. Följande diagram visar relationen mellan pipeline, aktivitet och datauppsättning:

En indatauppsättning representerar indata för en aktivitet i pipelinen och en utdatauppsättning representerar utdata för aktiviteten. Datauppsättningar identifierar data inom olika datalager, till exempel tabeller, filer, mappar och dokument. När du har skapat en datauppsättning kan du använda den med aktiviteter i en pipeline. Till exempel kan en datauppsättning vara en in-/utdatauppsättning för en kopieringsaktivitet eller en HDInsightHive-aktivitet. Mer information om datauppsättning finns i artikeln Datauppsättningar i Azure Data Factory.
Kommentar
Det finns en mjuk standardgräns på högst 80 aktiviteter per pipeline, vilket inkluderar inre aktiviteter för containrar.
Dataförflyttningsaktiviteter
Kopieringsaktiviteten i Data Factory kopierar data från källans datalager till mottagarens datalager. Data Factory stödjer de datalager som listas i tabellen i det här avsnittet. Data kan skrivas från valfri källa till valfri mottagare.
Mer information finns i artikeln Kopieringsaktiviteten – översikt.
Klicka på ett datalager om du vill veta hur du kopierar data till och från det datalagret.
Kommentar
Om en anslutningsapp är märkt med förhandsversion kan du testa den och sedan ge feedback till oss. Om du vill skapa ett beroende på anslutningsappar som är i förhandsversion i din lösning kontaktar du Azure-supporten.
Datatransformeringsaktiviteter
Azure Data Factory och Azure Synapse Analytics stöder följande transformeringsaktiviteter som kan läggas till antingen individuellt eller tillsammans med en annan aktivitet.
Mer information finns i artikeln om datatransformeringsaktiviteter.
| Datatransformeringsaktivitet | Compute-miljö |
|---|---|
| Dataflöde | Apache Spark-kluster som hanteras av Azure Data Factory |
| Azure-funktion | Azure Functions |
| Hive | HDInsight [Hadoop] |
| Pig | HDInsight [Hadoop] |
| MapReduce | HDInsight [Hadoop] |
| Hadoop Streaming | HDInsight [Hadoop] |
| Spark | HDInsight [Hadoop] |
| ML Studio-aktiviteter (klassisk): Batch-körning och uppdateringsresurs | Azure VM |
| Lagrad procedur | Azure SQL, Azure Synapse Analytics eller SQL Server |
| U-SQL | Azure Data Lake Analytics |
| Anpassad aktivitet | Azure Batch |
| Databricks-anteckningsbok | Azure Databricks |
| Databricks Jar-aktivitet | Azure Databricks |
| Databricks Python-aktivitet | Azure Databricks |
Kontrollflödesaktiviteter
Följande kontrollflödesaktiviteter stöds:
| Kontrollaktivitet | beskrivning |
|---|---|
| Lägg till variabel | Lägg till ett värde i en befintlig matrisvariabel. |
| Kör pipeline | Kör pipelineaktivitet gör att en Data Factory- eller Synapse-pipeline kan anropa en annan pipeline. |
| Filter | Tillämpa ett filteruttryck på en indatamatris |
| För varje | ForEach-aktiviteten definierar ett upprepat kontrollflöde i din pipeline. Den här aktiviteten används till att iterera över en samling och kör angivna aktiviteter i en loop. Implementeringen av loopen för den här aktiviteten liknar Foreach-loopstrukturen i programmeringsspråk. |
| Hämta metadata | GetMetadata-aktivitet kan användas för att hämta metadata för alla data i en Data Factory- eller Synapse-pipeline. |
| If-villkorsaktivitet | If-villkoret kan användas grenbaserat på villkor som utvärderas som sanna eller falska. If-villkoret fungerar på samma sätt som en if-sats i ett programmeringsspråk. Den utvärderar en uppsättning aktiviteter när villkoret utvärderas till true och en annan uppsättning aktiviteter när villkoret utvärderas till false. |
| Lookup-aktivitet | Lookup-aktiviteten kan användas till att läsa eller söka efter en post/ett tabellnamn/ett värde från valfri extern källa. Dessa utdata kan vidare refereras av efterföljande aktiviteter. |
| Ange variabel | Ange värdet för en befintlig variabel. |
| Until-aktivitet | Implementerar Do-Until-loop som liknar Do-Until-loopstrukturen i programmeringsspråk. En uppsättning aktiviteter körs i en loop tills det villkor som är associerat med aktiviteten utvärderas till sant. Du kan ange ett timeout-värde för aktiviteten tills. |
| Valideringsaktivitet | Se till att en pipeline endast fortsätter att köras om det finns en referensdatauppsättning, uppfyller ett angivet villkor eller om en tidsgräns har uppnåtts. |
| Wait-aktivitet | När du använder en Vänta-aktivitet i en pipeline väntar pipelinen under den angivna tiden innan du fortsätter med körningen av efterföljande aktiviteter. |
| Webbaktivitet | Webbaktivitet kan användas för att anropa en anpassad REST-slutpunkt från en pipeline. Du kan överföra datauppsättningar och länkade tjänster så att de förbrukas och används av aktiviteten. |
| Webhook-aktivitet | Använd webhook-aktiviteten, anropa en slutpunkt och skicka en motringnings-URL. Pipelinekörningen väntar på att återanropet ska anropas innan du fortsätter till nästa aktivitet. |
Skapa en pipeline med användargränssnittet
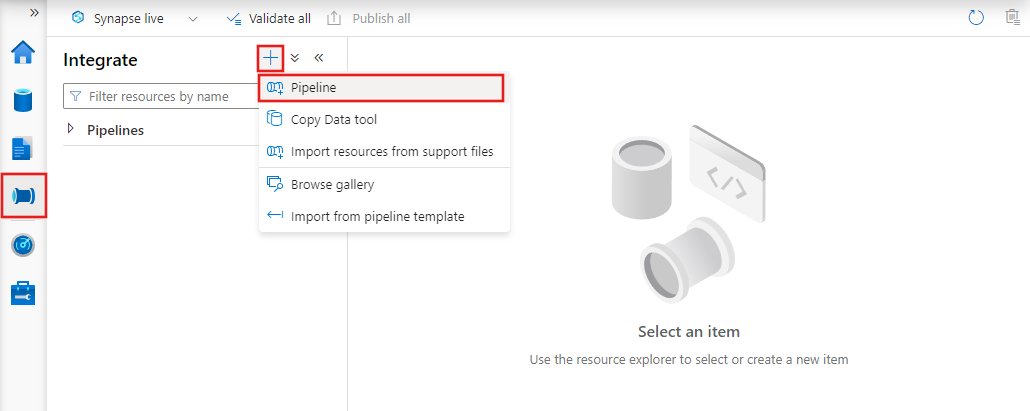
Om du vill skapa en ny pipeline går du till fliken Författare i Data Factory Studio (representeras av pennikonen), klickar på plustecknet och väljer Pipeline på menyn och Pipeline igen från undermenyn.
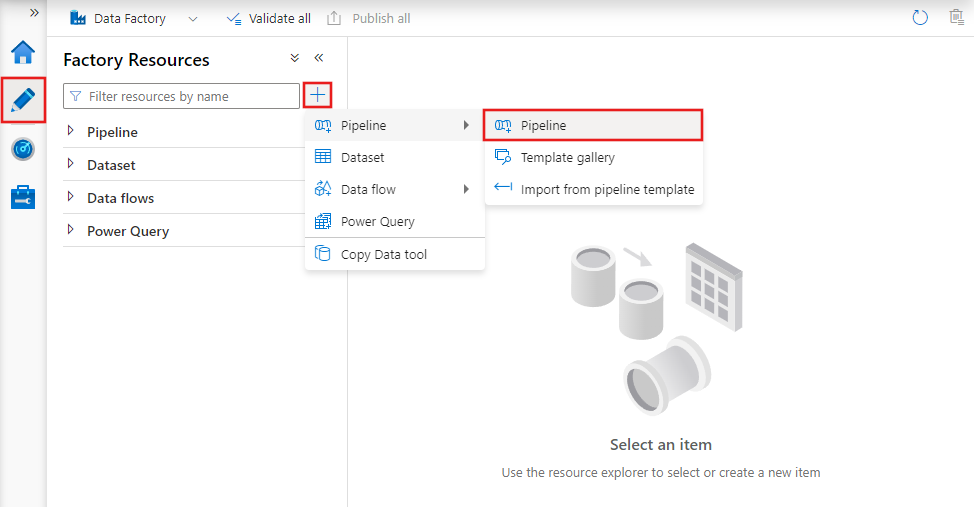
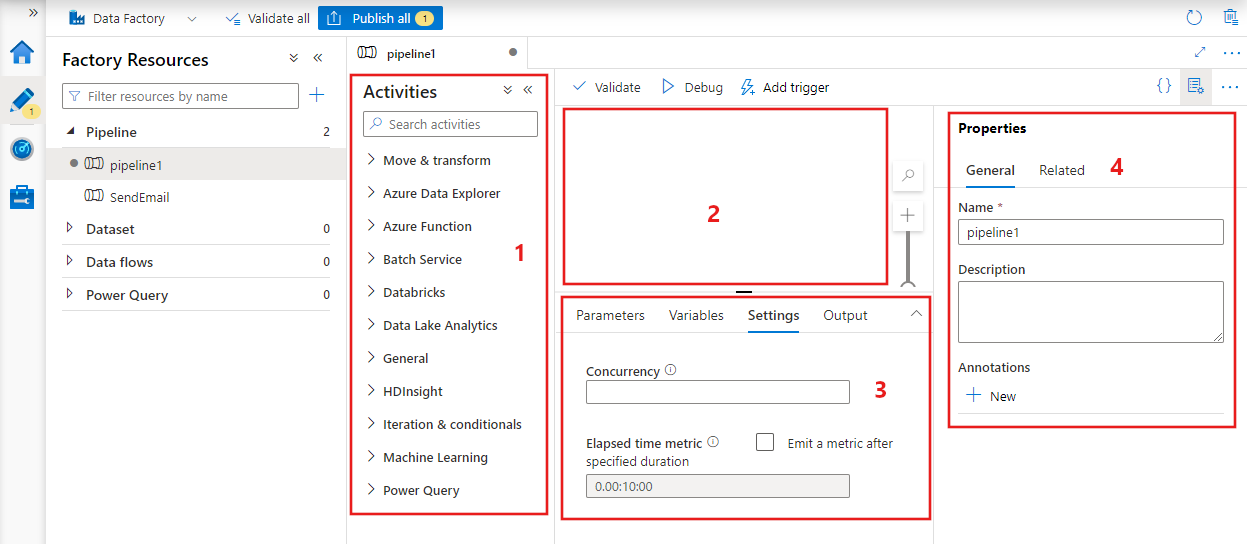
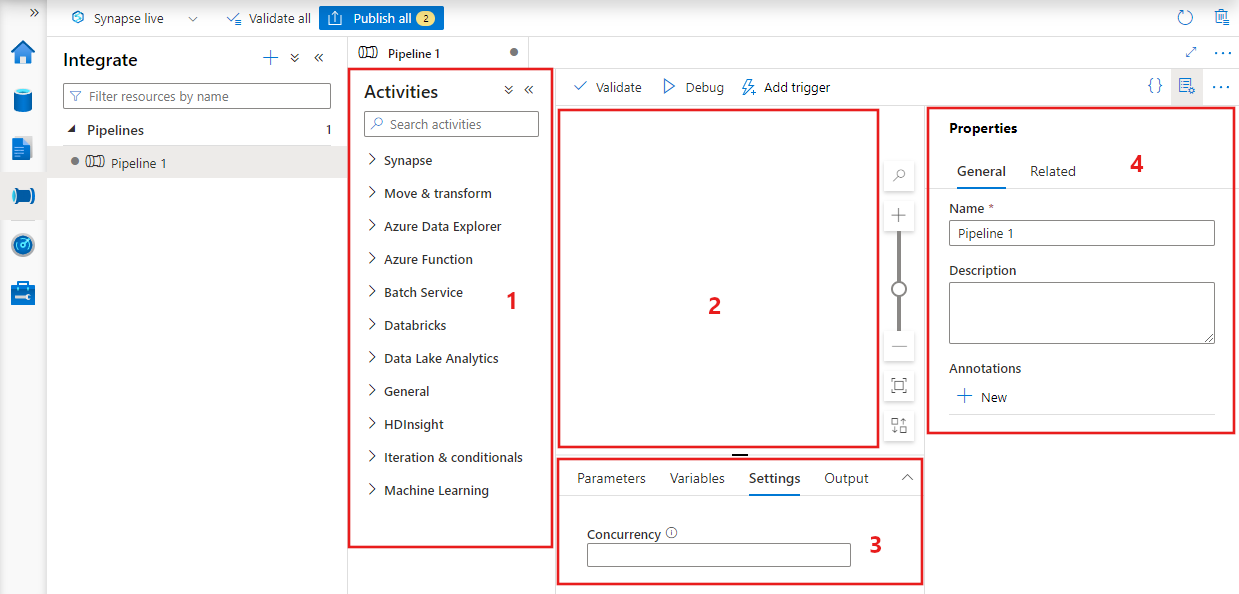
Datafabriken visar pipelineredigeraren där du hittar:
- Alla aktiviteter som kan användas i pipelinen.
- Pipelineredigerarens arbetsyta, där aktiviteter visas när de läggs till i pipelinen.
- Fönstret pipelinekonfigurationer, inklusive parametrar, variabler, allmänna inställningar och utdata.
- Fönstret pipelineegenskaper, där pipelinenamnet, den valfria beskrivningen och anteckningarna kan konfigureras. I det här fönstret visas även relaterade objekt till pipelinen i datafabriken.
Pipeline-JSON
Så här definieras en pipeline i JSON-format:
{
"name": "PipelineName",
"properties":
{
"description": "pipeline description",
"activities":
[
],
"parameters": {
},
"concurrency": <your max pipeline concurrency>,
"annotations": [
]
}
}
| Tagg | beskrivning | Typ | Obligatoriskt |
|---|---|---|---|
| name | Namnet på pipeline. Ange ett namn som representerar åtgärden som pipeline utför.
|
String | Ja |
| description | Ange texten som beskriver vad pipeline används till. | String | Nej |
| activities | Avsnittet activities kan ha en eller flera definierade aktiviteter. I avsnittet Aktivitets-JSON finns information om aktivitets-JSON-elementet. | Matris | Ja |
| parametrar | Avsnittet parameters kan ha en eller flera definierade parametrar i pipeline, vilket gör pipeline flexibel för återanvändning. | List | Nej |
| samtidighet | Det maximala antalet samtidiga körningar som pipelinen kan ha. Som standard finns det inget maximum. Om samtidighetsgränsen har nåtts placeras ytterligare pipelinekörningar i kö tills tidigare körningar har slutförts | Antal | Nej |
| Anteckningar | En lista över taggar som är associerade med pipelinen | Matris | Nej |
Aktivitets-JSON
Avsnittet activities kan ha en eller flera definierade aktiviteter. Det finns två huvudtyper av aktiviteter: körnings- och kontrollaktiviteter.
Körningsaktiviteter
I körningsaktiviteter ingår dataförflyttning och datatransformering. De har följande toppnivåstruktur:
{
"name": "Execution Activity Name",
"description": "description",
"type": "<ActivityType>",
"typeProperties":
{
},
"linkedServiceName": "MyLinkedService",
"policy":
{
},
"dependsOn":
{
}
}
I följande tabell beskrivs egenskaperna i definitionen för aktivitets-JSON:
| Tagg | beskrivning | Obligatoriskt |
|---|---|---|
| name | Namnet på aktiviteten. Ange ett namn som representerar åtgärden som aktiviteten utför.
|
Ja |
| description | Text som beskriver vad aktiviteten används till | Ja |
| type | Typ av aktivitet. Information om olika typer av aktiviteter finns i avsnitten Dataförflyttningsaktiviteter, Datatransformeringsaktiviteter och Kontrollaktiviteter. | Ja |
| linkedServiceName | Namnet på den länkade tjänst som används av aktiviteten. En aktivitet kan kräva att du anger den länkade tjänst som länkar till den nödvändiga beräkningsmiljön. |
Ja för HDInsight-aktivitet, ML Studio (klassisk) batchbedömningsaktivitet, lagrad proceduraktivitet. Nej för alla andra |
| typeProperties | Egenskaperna i avsnittet typeProperties beror på varje typ av aktivitet. Om du vill visa typegenskaper för en aktivitet klickar du på länkarna till aktiviteten i föregående avsnitt. | Nej |
| policy | Principer som påverkar körningsbeteende för aktiviteten. Den här egenskapen innehåller ett timeout- och återförsöksbeteende. Om den inte anges används standardvärden. Mer information finns i avsnittet Aktivitetsprincip. | Nej |
| dependsOn | Den här egenskapen används till att definiera aktivitetsberoenden och hur efterföljande aktiviteter beror på tidigare aktiviteter. Mer information finns i Aktivitetsberoende | Nej |
Aktivitetsprincip
Principer påverkar körningsbeteendet för en aktivitet, vilket ger konfigurationsalternativ. Aktivitetsprinciper är bar tillgängliga för körningsaktiviteter.
JSON-definition för aktivitetsprincip
{
"name": "MyPipelineName",
"properties": {
"activities": [
{
"name": "MyCopyBlobtoSqlActivity",
"type": "Copy",
"typeProperties": {
...
},
"policy": {
"timeout": "00:10:00",
"retry": 1,
"retryIntervalInSeconds": 60,
"secureOutput": true
}
}
],
"parameters": {
...
}
}
}
| JSON-namn | beskrivning | Tillåtna värden | Obligatoriskt |
|---|---|---|---|
| timeout | Anger tidsgränsen för aktivitetens körning. | Tidsintervall | Nej. Standardtidsgränsen är 12 timmar, minst 10 minuter. |
| retry | Max. antal omförsök | Integer | Nej. Standardvärdet är 0 |
| retryIntervalInSeconds | Fördröjningen mellan omförsök i sekunder | Integer | Nej. Standardvärdet är 30 sekunder |
| secureOutput | När värdet är true anses utdata från aktiviteten vara säkra och loggas inte för övervakning. | Booleskt | Nej. Standardvärdet är falskt. |
Kontrollaktivitet
Kontrollaktiviteter har följande toppnivåstruktur:
{
"name": "Control Activity Name",
"description": "description",
"type": "<ActivityType>",
"typeProperties":
{
},
"dependsOn":
{
}
}
| Tagg | beskrivning | Obligatoriskt |
|---|---|---|
| name | Namnet på aktiviteten. Ange ett namn som representerar åtgärden som aktiviteten utför.
|
Ja |
| description | Text som beskriver vad aktiviteten används till | Ja |
| type | Typ av aktivitet. Information om olika typer av aktiviteter finns i avsnitten Dataförflyttningsaktiviteter, Datatransformeringsaktiviteter och Kontrollaktiviteter. | Ja |
| typeProperties | Egenskaperna i avsnittet typeProperties beror på varje typ av aktivitet. Om du vill visa typegenskaper för en aktivitet klickar du på länkarna till aktiviteten i föregående avsnitt. | Nej |
| dependsOn | Den här egenskapen används till att definiera aktivitetsberoende och hur efterföljande aktiviteter beror på tidigare aktiviteter. Mer information finns i Aktivitetsberoende. | Nej |
Aktivitetsberoende
Aktivitetsberoende definierar hur efterföljande aktiviteter är beroende av tidigare aktiviteter, vilket avgör villkoret för om nästa aktivitet ska fortsätta att köras. En aktivitet kan vara beroende av en eller flera tidigare aktiviteter med olika beroendevillkor.
De olika beroendevillkoren är Succeeded (Lyckades), Failed (Misslyckades), Skipped (Överhoppad), Completed (Slutförd).
Om en pipeline till exempel har aktivitet A –> aktivitet B är följande olika scenarier:
- Aktivitet B har beroendevillkor på Aktivitet A med Succeeded (Lyckades): Aktivitet B körs bara om Aktivitet A har den slutgiltiga statusen Suceeded (Lyckades)
- Aktivitet B har beroendevillkor på Aktivitet A med Failed (Misslyckades): Aktivitet B körs bara om Aktivitet A har den slutgiltiga statusen Failed (Misslyckades)
- Aktivitet B har beroendevillkor på Aktivitet A med Completed (Slutförd): Aktivitet B körs om Aktivitet A har de slutgiltiga statusen Succeeded (Lyckades) eller Failed (Misslyckades)
- Aktivitet B har ett beroendevillkor för aktivitet A med överhoppad: Aktivitet B körs om aktivitet A har en slutlig status överhoppad. Överhoppad sker i scenariot Aktivitet X –> Aktivitet Y –> Aktivitet Z, där varje aktivitet endast körs om den tidigare aktiviteten lyckas. Om aktivitet X misslyckas har aktivitet Y statusen "Skipped" eftersom den aldrig körs. På samma sätt har Activity Z statusen "Skipped" också.
Exempel: Aktivitet 2 är beroende av att Aktivitet 1 lyckas
{
"name": "PipelineName",
"properties":
{
"description": "pipeline description",
"activities": [
{
"name": "MyFirstActivity",
"type": "Copy",
"typeProperties": {
},
"linkedServiceName": {
}
},
{
"name": "MySecondActivity",
"type": "Copy",
"typeProperties": {
},
"linkedServiceName": {
},
"dependsOn": [
{
"activity": "MyFirstActivity",
"dependencyConditions": [
"Succeeded"
]
}
]
}
],
"parameters": {
}
}
}
Exempel på kopieringspipeline
I följande exempel på pipeline finns det en aktivitet av typen Copy (Kopiera) i avsnittet activities. I det här exemplet kopierar kopieringsaktiviteten data från en Azure Blob Storage till en databas i Azure SQL Database.
{
"name": "CopyPipeline",
"properties": {
"description": "Copy data from a blob to Azure SQL table",
"activities": [
{
"name": "CopyFromBlobToSQL",
"type": "Copy",
"inputs": [
{
"name": "InputDataset"
}
],
"outputs": [
{
"name": "OutputDataset"
}
],
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "SqlSink",
"writeBatchSize": 10000,
"writeBatchTimeout": "60:00:00"
}
},
"policy": {
"retry": 2,
"timeout": "01:00:00"
}
}
]
}
}
Observera följande:
- I avsnittet Aktiviteter finns det bara en aktivitet vars typ anges till Kopia.
- Indata för aktiviteten är inställd på InputDataset och utdata för aktiviteten är inställd på OutputDataset. I artikeln Datauppsättningar finns information om hur du definierar datauppsättningar i JSON.
- I avsnittet för typeProperties har BlobSource angetts som källtyp och SqlSink har angetts som mottagartyp. I avsnittet för dataförflyttningsaktiviteter klickar du på det datalager som du vill använda som källa eller mottagare för att lära dig mer om hur du flyttar data till/från det datalagret.
En fullständig genomgång av hur du skapar den här pipelinen finns i Snabbstart: skapa en Data Factory.
Exempel på transfomeringspipeline
I följande exempel på pipeline finns det en aktivitet av typen HDInsightHive i avsnittet activities. I det här exemplet transformerar HDInsight Hive-aktiviteten data från Azure Blob Storage genom att köra en Hive-skriptfil på ett Azure HDInsight Hadoop-kluster.
{
"name": "TransformPipeline",
"properties": {
"description": "My first Azure Data Factory pipeline",
"activities": [
{
"type": "HDInsightHive",
"typeProperties": {
"scriptPath": "adfgetstarted/script/partitionweblogs.hql",
"scriptLinkedService": "AzureStorageLinkedService",
"defines": {
"inputtable": "wasb://adfgetstarted@<storageaccountname>.blob.core.windows.net/inputdata",
"partitionedtable": "wasb://adfgetstarted@<storageaccountname>.blob.core.windows.net/partitioneddata"
}
},
"inputs": [
{
"name": "AzureBlobInput"
}
],
"outputs": [
{
"name": "AzureBlobOutput"
}
],
"policy": {
"retry": 3
},
"name": "RunSampleHiveActivity",
"linkedServiceName": "HDInsightOnDemandLinkedService"
}
]
}
}
Observera följande:
- I activities-avsnittet finns det bara en aktivitet vars typ anges till HDInsightHive.
- Hive-skriptfilen partitionweblogs.hql lagras i Azure Storage-kontot (anges av scriptLinkedService, med namnet AzureStorageLinkedService) och i skriptmappen i containern
adfgetstarted. - Avsnittet
definesanvänds för att ange körningsinställningar som skickas till Hive-skriptet som Hive-konfigurationsvärden (till exempel ${hiveconf:inputtable},${hiveconf:partitionedtable}.
Avsnittet typeProperties är olika för varje transformeringsaktivitet. Om du vill ha mer information om vilka typegenskaper som stöds för en transformeringsaktivitet klickar du på transformeringsaktiviteten i Datatransformeringsaktiviteter.
En fullständig genomgång av hur du skapar denna pipeline finns i Självstudier: transformera data med Spark.
Flera aktiviteter i en pipeline
De två föregående exemplen innehåller bara en aktivitet. Du kan fler än en aktivitet i en pipeline. Om du har flera aktiviteter i en pipeline och efterföljande aktiviteter inte är beroende av tidigare aktiviteter kan aktiviteterna köras parallellt.
Du kan länka två aktiviteter genom att använda aktivitetsberoende, som definierar hur efterföljande aktiviteter är beroende av tidigare aktiviteter, vilket fastställer villkoret för om nästa uppgift ska köras. En aktivitet kan vara beroende av en eller flera tidigare aktiviteter med olika beroendevillkor.
Schemalägga pipelines
Pipelines schemaläggs av utlösare. Det finns olika typer av utlösare (Scheduler-utlösare, som gör att pipelines kan utlösas enligt ett schema för väggklockan, samt den manuella utlösaren som utlöser pipelines på begäran). Mer information om utlösare finns i artikeln om pipelinekörning och utlösare.
Om du vill att utlösaren startar en pipelinekörning måste du ta med en pipelinereferens i utlösardefinitionen. Pipelines och utlösare har ett n-m-förhållande. Flera utlösare kan starta en enda pipeline, och samma utlösare kan starta flera pipelines. När utlösaren har definierats måste du starta utlösaren så att den kan börja utlösa pipeline. Mer information om utlösare finns i artikeln om pipelinekörning och utlösare.
Anta till exempel att du har en Scheduler-utlösare, "Trigger A", som jag vill starta min pipeline, "MyCopyPipeline". Du definierar utlösaren enligt följande exempel:
Definition av TriggerA
{
"name": "TriggerA",
"properties": {
"type": "ScheduleTrigger",
"typeProperties": {
...
}
},
"pipeline": {
"pipelineReference": {
"type": "PipelineReference",
"referenceName": "MyCopyPipeline"
},
"parameters": {
"copySourceName": "FileSource"
}
}
}
}
Relaterat innehåll
I följande självstudier får du stegvisa instruktioner för att skapa pipelines med aktiviteter:
Så här uppnår du CI/CD (kontinuerlig integrering och leverans) med Hjälp av Azure Data Factory
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för