Visualisera Azure Databricks-mått med instrumentpaneler
Kommentar
Den här artikeln förlitar sig på ett öppen källkod-bibliotek som finns på GitHub på: https://github.com/mspnp/spark-monitoring.
Det ursprungliga biblioteket stöder Azure Databricks Runtimes 10.x (Spark 3.2.x) och tidigare.
Databricks har bidragit med en uppdaterad version för att stödja Azure Databricks Runtimes 11.0 (Spark 3.3.x) och senare på grenen l4jv2 på: https://github.com/mspnp/spark-monitoring/tree/l4jv2.
Observera att versionen 11.0 inte är bakåtkompatibel på grund av de olika loggningssystem som används i Databricks Runtimes. Se till att använda rätt version för Databricks Runtime. Biblioteket och GitHub-lagringsplatsen är i underhållsläge. Det finns inga planer på ytterligare versioner, och problemstöd kommer endast att vara bäst. Om du vill ha ytterligare frågor om biblioteket eller översikten för övervakning och loggning av dina Azure Databricks-miljöer kan du kontakta azure-spark-monitoring-help@databricks.com.
Den här artikeln visar hur du konfigurerar en Grafana-instrumentpanel för att övervaka Azure Databricks-jobb för prestandaproblem.
Azure Databricks är en snabb, kraftfull och samarbetsbaserad Apache Spark-baserad analystjänst som gör det enkelt att snabbt utveckla och distribuera lösningar för stordataanalys och artificiell intelligens (AI). Övervakning är en viktig komponent i driften av Azure Databricks-arbetsbelastningar i produktion. Det första steget är att samla in mått till en arbetsyta för analys. Den bästa lösningen för att hantera loggdata i Azure är Azure Monitor. Azure Databricks har inte inbyggt stöd för att skicka loggdata till Azure Monitor, men ett bibliotek för den här funktionen finns i GitHub.
Det här biblioteket möjliggör loggning av Azure Databricks-tjänstmått samt apache Spark-strukturuppspelning av frågehändelsemått. När du har distribuerat det här biblioteket till ett Azure Databricks-kluster kan du distribuera ytterligare en uppsättning Grafana-instrumentpaneler som du kan distribuera som en del av produktionsmiljön.
Förutsättningar
Konfigurera ditt Azure Databricks-kluster så att det använder övervakningsbiblioteket enligt beskrivningen i GitHub-läsningen.
Distribuera Azure Log Analytics-arbetsytan
Följ dessa steg för att distribuera Azure Log Analytics-arbetsytan:
Navigera till
/perftools/deployment/loganalyticskatalogen.Distribuera logAnalyticsDeploy.json Azure Resource Manager-mallen. Mer information om hur du distribuerar Resource Manager-mallar finns i Distribuera resurser med Resource Manager-mallar och Azure CLI. Mallen har följande parametrar:
- plats: Den region där Log Analytics-arbetsytan och instrumentpanelerna distribueras.
- serviceTier: Prisnivån för arbetsytan. Här finns en lista över giltiga värden.
- dataRetention (valfritt): Antalet dagar som loggdata sparas på Log Analytics-arbetsytan. Standardvärdet är 30 dagar. Om prisnivån är
Freemåste datakvarhållningen vara sju dagar. - workspaceName (valfritt): Ett namn på arbetsytan. Om den inte anges genererar mallen ett namn.
az deployment group create --resource-group <resource-group-name> --template-file logAnalyticsDeploy.json --parameters location='East US' serviceTier='Standalone'
Den här mallen skapar arbetsytan och skapar även en uppsättning fördefinierade frågor som används av instrumentpanelen.
Distribuera Grafana på en virtuell dator
Grafana är ett öppen källkod projekt som du kan distribuera för att visualisera tidsseriemåtten som lagras på Din Azure Log Analytics-arbetsyta med hjälp av Grafana-plugin-programmet för Azure Monitor. Grafana körs på en virtuell dator (VM) och kräver ett lagringskonto, ett virtuellt nätverk och andra resurser. Så här distribuerar du en virtuell dator med den bitnamicertifierade Grafana-avbildningen och tillhörande resurser:
Använd Azure CLI för att acceptera Azure Marketplace-avbildningsvillkoren för Grafana.
az vm image terms accept --publisher bitnami --offer grafana --plan defaultNavigera till
/spark-monitoring/perftools/deployment/grafanakatalogen i din lokala kopia av GitHub-lagringsplatsen.Distribuera grafanaDeploy.json Resource Manager-mallen på följande sätt:
export DATA_SOURCE="https://raw.githubusercontent.com/mspnp/spark-monitoring/master/perftools/deployment/grafana/AzureDataSource.sh" az deployment group create \ --resource-group <resource-group-name> \ --template-file grafanaDeploy.json \ --parameters adminPass='<vm password>' dataSource=$DATA_SOURCE
När distributionen är klar installeras bitnami-avbildningen av Grafana på den virtuella datorn.
Uppdatera Grafana-lösenordet
Som en del av installationsprocessen matar Installationsskriptet för Grafana ut ett tillfälligt lösenord för administratörsanvändaren. Du behöver det här tillfälliga lösenordet för att logga in. Följ dessa steg för att hämta det tillfälliga lösenordet:
- Logga in på Azure Portal.
- Välj den resursgrupp där resurserna distribuerades.
- Välj den virtuella dator där Grafana installerades. Om du använde standardparameternamnet i distributionsmallen är namnet på den virtuella datorn prefaced med sparkmonitoring-vm-grafana.
- I avsnittet Support + felsökning klickar du på Startdiagnostik för att öppna startdiagnostiksidan.
- Klicka på Seriell logg på startdiagnostiksidan.
- Sök efter följande sträng: "Ange Bitnami-programlösenord till".
- Kopiera lösenordet till en säker plats.
Ändra sedan Lösenordet för Grafana-administratören genom att följa dessa steg:
- I Azure-portalen väljer du den virtuella datorn och klickar på Översikt.
- Kopiera den offentliga IP-adressen.
- Öppna en webbläsare och gå till följande URL:
http://<IP address>:3000. - På inloggningsskärmen för Grafana anger du administratör för användarnamnet och använder Grafana-lösenordet från föregående steg.
- När du har loggat in väljer du Konfiguration (kugghjulsikonen).
- Välj Serveradministratör.
- På fliken Användare väljer du administratörsinloggning.
- Uppdatera lösenordet.
Skapa en Azure Monitor-datakälla
Skapa ett huvudnamn för tjänsten som gör att Grafana kan hantera åtkomsten till din Log Analytics-arbetsyta. Mer information finns i Skapa ett Huvudnamn för Azure-tjänsten med Azure CLI
az ad sp create-for-rbac --name http://<service principal name> \ --role "Log Analytics Reader" \ --scopes /subscriptions/mySubscriptionIDObservera värdena för appId, lösenord och klientorganisation i utdata från det här kommandot:
{ "appId": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "displayName": "azure-cli-2019-03-27-00-33-39", "name": "http://<service principal name>", "password": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "tenant": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx" }Logga in på Grafana enligt beskrivningen tidigare. Välj Konfiguration (kugghjulsikonen) och sedan Datakällor.
På fliken Datakällor klickar du på Lägg till datakälla.
Välj Azure Monitor som datakällans typ.
I avsnittet Inställningar anger du ett namn för datakällan i textrutan Namn.
I avsnittet Api-information för Azure Monitor anger du följande information:
- Prenumerations-ID: Ditt Azure-prenumerations-ID.
- Klientorganisations-ID: Klientorganisations-ID från tidigare.
- Klient-ID: Värdet för "appId" från tidigare.
- Klienthemlighet: Värdet för "lösenord" från tidigare.
I avsnittet API-information för Azure Log Analytics markerar du kryssrutan Samma information som Azure Monitor API.
Klicka på Spara och testa. Om Log Analytics-datakällan är korrekt konfigurerad visas ett meddelande om att åtgärden lyckades.
Skapa instrumentpanelen
Skapa instrumentpanelerna i Grafana genom att följa dessa steg:
Navigera till
/perftools/dashboards/grafanakatalogen i din lokala kopia av GitHub-lagringsplatsen.Kör följande skript:
export WORKSPACE=<your Azure Log Analytics workspace ID> export LOGTYPE=SparkListenerEvent_CL sh DashGen.shUtdata från skriptet är en fil med namnet SparkMonitoringDash.json.
Gå tillbaka till Grafana-instrumentpanelen och välj Skapa (plusikonen).
Välj Importera.
Klicka på Ladda upp .json fil.
Välj den SparkMonitoringDash.json fil som skapades i steg 2.
I avsnittet Alternativ går du till ALA och väljer den Azure Monitor-datakälla som skapades tidigare.
Klicka på Importera.
Visualiseringar på instrumentpanelerna
Både Azure Log Analytics- och Grafana-instrumentpanelerna innehåller en uppsättning visualiseringar för tidsserier. Varje diagram är tidsseriediagram med måttdata relaterade till ett Apache Spark-jobb, jobbfaser och uppgifter som utgör varje steg.
Visualiseringarna är:
Svarstid för jobb
Den här visualiseringen visar körningsfördröjning för ett jobb, vilket är en grov vy över jobbets övergripande prestanda. Visar jobbkörningens varaktighet från början till slut. Observera att starttiden för jobbet inte är samma som tiden för insändning av jobb. Svarstiden representeras som percentiler (10 %, 30 %, 50 %, 90 %) av jobbkörning som indexerats av kluster-ID och program-ID.
Svarstid för steg
Visualiseringen visar svarstiden för varje steg per kluster, per program och per enskild fas. Den här visualiseringen är användbar för att identifiera en viss fas som körs långsamt.
Svarstid för aktivitet
Den här visualiseringen visar svarstid för aktivitetskörning. Svarstiden representeras som en percentil av aktivitetskörning per kluster, fasnamn och program.
Summera aktivitetskörning per värd
Den här visualiseringen visar summan av svarstiden för aktivitetskörning per värd som körs i ett kluster. Om du visar svarstid för aktivitetskörning per värd identifieras värdar som har mycket högre övergripande aktivitetsfördröjning än andra värdar. Det kan innebära att aktiviteterna har distribuerats ineffektivt eller ojämnt till värdar.
Aktivitetsmått
Den här visualiseringen visar en uppsättning körningsmått för en viss aktivitets körning. Dessa mått omfattar storleken och varaktigheten för en datablandning, varaktigheten för serialiserings- och deserialiseringsåtgärder och andra. Den fullständiga uppsättningen mått finns i Log Analytics-frågan för panelen. Den här visualiseringen är användbar för att förstå de åtgärder som utgör en uppgift och identifiera resursförbrukning för varje åtgärd. Toppar i diagrammet representerar kostsamma åtgärder som bör undersökas.
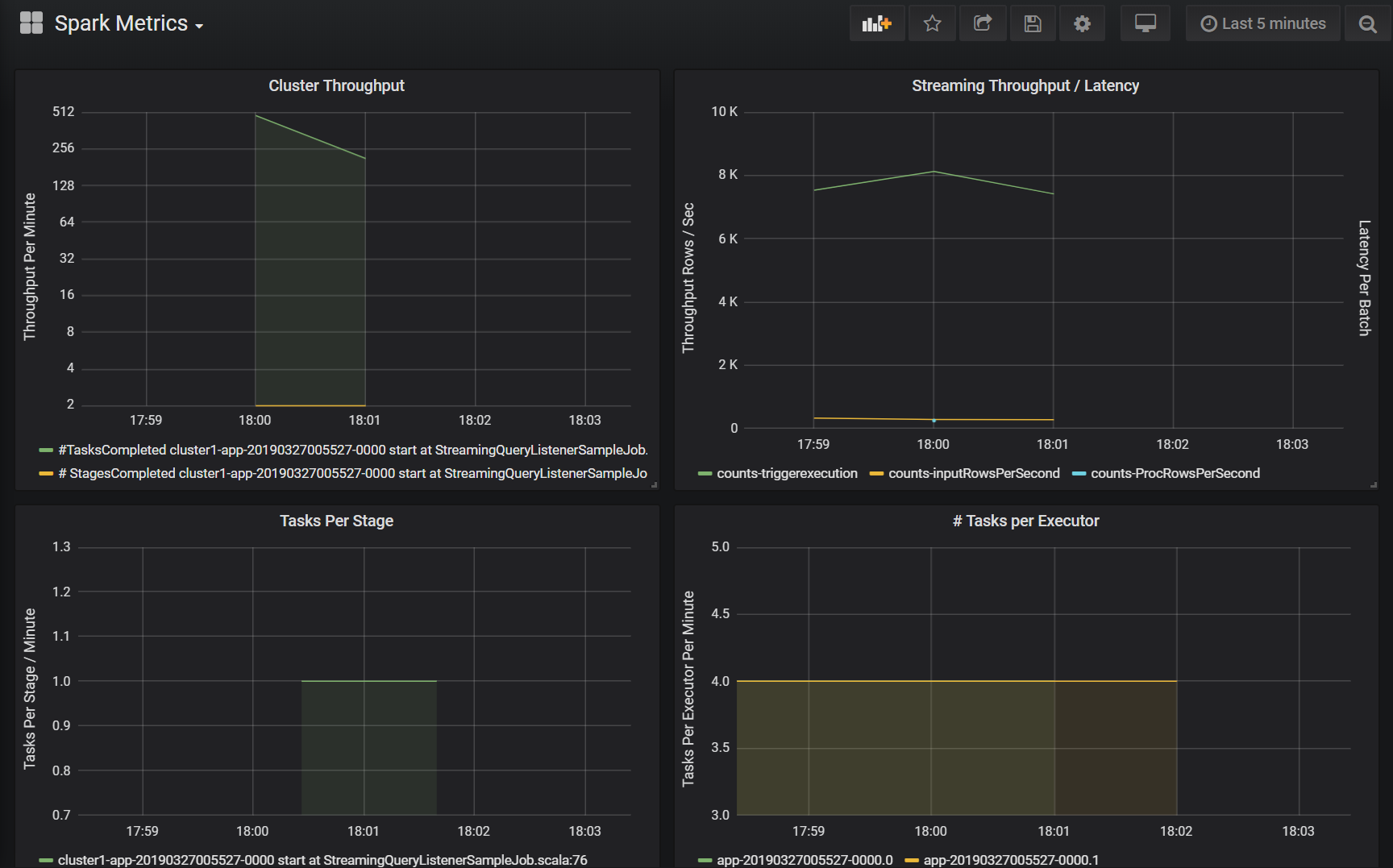
Klusterdataflöde
Den här visualiseringen är en övergripande vy över arbetsobjekt som indexerats efter kluster och program för att representera mängden arbete som utförs per kluster och program. Den visar antalet jobb, uppgifter och steg som har slutförts per kluster, program och steg i steg på en minut.
Strömmande dataflöde/svarstid
Den här visualiseringen är relaterad till de mått som är associerade med en strukturerad direktuppspelningsfråga. Diagrammet visar antalet indatarader per sekund och antalet rader som bearbetas per sekund. Strömningsmåtten representeras också per program. Dessa mått skickas när händelsen OnQueryProgress genereras när den strukturerade strömningsfrågan bearbetas och visualiseringen representerar svarstid för direktuppspelning när den tid i millisekunder som krävs för att köra en frågebatch.
Resursförbrukning per köre
Nästa är en uppsättning visualiseringar för instrumentpanelen som visar den specifika typen av resurs och hur den används per köre i varje kluster. Dessa visualiseringar hjälper dig att identifiera avvikande värden i resursförbrukning per köre. Om arbetsallokeringen för en viss köre till exempel är skev, utökas resursförbrukningen i förhållande till andra köre som körs i klustret. Detta kan identifieras med toppar i resursförbrukningen för en utförare.
Beräkningstidsmått för executor
Nästa är en uppsättning visualiseringar för instrumentpanelen som visar förhållandet mellan körnings- och serialiseringstid, deserialisera tid, CPU-tid och tid för virtuella Java-datorer till den totala beräkningstiden för exekutorer. Detta visar visuellt hur mycket vart och ett av dessa fyra mått bidrar till den övergripande körningsbearbetningen.
Blanda mått
Den sista uppsättningen visualiseringar visar de datablandningsmått som är associerade med en strukturerad direktuppspelningsfråga för alla köre. Dessa inkluderar shuffle bytes read, shuffle bytes written, shuffle memory och disk usage i frågor där filsystemet används.