Felsöka flaskhalsar för prestanda i Azure Databricks
Kommentar
Den här artikeln förlitar sig på ett öppen källkod-bibliotek som finns på GitHub på: https://github.com/mspnp/spark-monitoring.
Det ursprungliga biblioteket stöder Azure Databricks Runtimes 10.x (Spark 3.2.x) och tidigare.
Databricks har bidragit med en uppdaterad version för att stödja Azure Databricks Runtimes 11.0 (Spark 3.3.x) och senare på grenen l4jv2 på: https://github.com/mspnp/spark-monitoring/tree/l4jv2.
Observera att versionen 11.0 inte är bakåtkompatibel på grund av de olika loggningssystem som används i Databricks Runtimes. Se till att använda rätt version för Databricks Runtime. Biblioteket och GitHub-lagringsplatsen är i underhållsläge. Det finns inga planer på ytterligare versioner, och problemstöd kommer endast att vara bäst. Om du vill ha ytterligare frågor om biblioteket eller översikten för övervakning och loggning av dina Azure Databricks-miljöer kan du kontakta azure-spark-monitoring-help@databricks.com.
Den här artikeln beskriver hur du använder övervakningsinstrumentpaneler för att hitta flaskhalsar i prestanda i Spark-jobb i Azure Databricks.
Azure Databricks är en Apache Spark-baserad analystjänst som gör det enkelt att snabbt utveckla och distribuera stordataanalys. Det är viktigt att övervaka och felsöka prestandaproblem vid drift av Azure Databricks-arbetsbelastningar för produktion. För att identifiera vanliga prestandaproblem är det bra att använda övervakningsvisualiseringar baserat på telemetridata.
Förutsättningar
Så här konfigurerar du Grafana-instrumentpanelerna som visas i den här artikeln:
Konfigurera databricks-klustret så att det skickar telemetri till en Log Analytics-arbetsyta med hjälp av Azure Databricks-övervakningsbiblioteket. Mer information finns i GitHub-readme.
Distribuera Grafana på en virtuell dator. Se Använda instrumentpaneler för att visualisera Azure Databricks-mått.
Grafana-instrumentpanelen som distribueras innehåller en uppsättning visualiseringar för tidsserier. Varje diagram är tidsseriediagram med mått relaterade till ett Apache Spark-jobb, jobbfaserna och uppgifter som utgör varje steg.
Översikt över Azure Databricks-prestanda
Azure Databricks baseras på Apache Spark, ett allmänt distribuerat databehandlingssystem. Programkoden, som kallas ett jobb, körs på ett Apache Spark-kluster som samordnas av klusterhanteraren. I allmänhet är ett jobb den högsta beräkningsenheten. Ett jobb representerar den fullständiga åtgärd som utförs av Spark-programmet. En typisk åtgärd omfattar att läsa data från en källa, tillämpa datatransformeringar och skriva resultaten till lagring eller något annat mål.
Jobb delas upp i faser. Jobbet avancerar genom faserna sekventiellt, vilket innebär att senare steg måste vänta tills tidigare faser har slutförts. Faser innehåller grupper med identiska uppgifter som kan köras parallellt på flera noder i Spark-klustret. Uppgifter är den mest detaljerade körningsenheten som äger rum på en delmängd av data.
I nästa avsnitt beskrivs några instrumentpanelsvisualiseringar som är användbara för prestandafelsökning.
Svarstid för jobb och steg
Jobbfördröjning är varaktigheten för en jobbkörning från när den startar tills den har slutförts. Det visas som percentiler för en jobbkörning per kluster och program-ID för att tillåta visualisering av avvikande värden. Följande diagram visar en jobbhistorik där den 90:e percentilen nådde 50 sekunder, även om den 50:e percentilen konsekvent var cirka 10 sekunder.
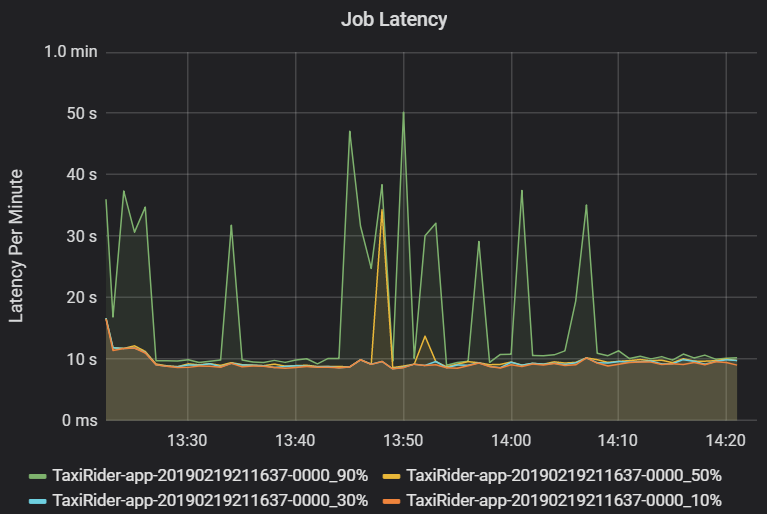
Undersök jobbkörning efter kluster och program och leta efter toppar i svarstiden. När kluster och program med hög svarstid har identifierats går du vidare för att undersöka svarstiden i fasen.
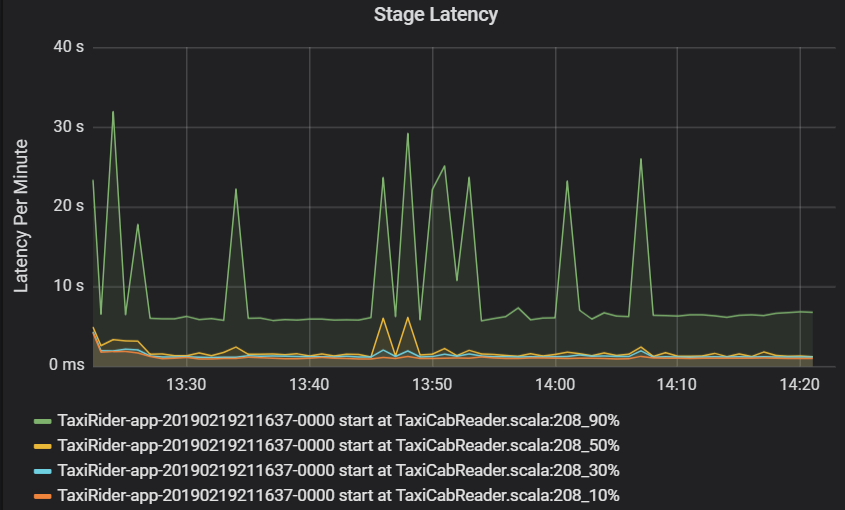
Svarstid för steg visas också som percentiler för att tillåta visualisering av extremvärden. Svarstid för steg delas upp efter kluster, program och fasnamn. Identifiera toppar i aktivitetsfördröjningen i diagrammet för att avgöra vilka aktiviteter som håller tillbaka slutförandet av fasen.
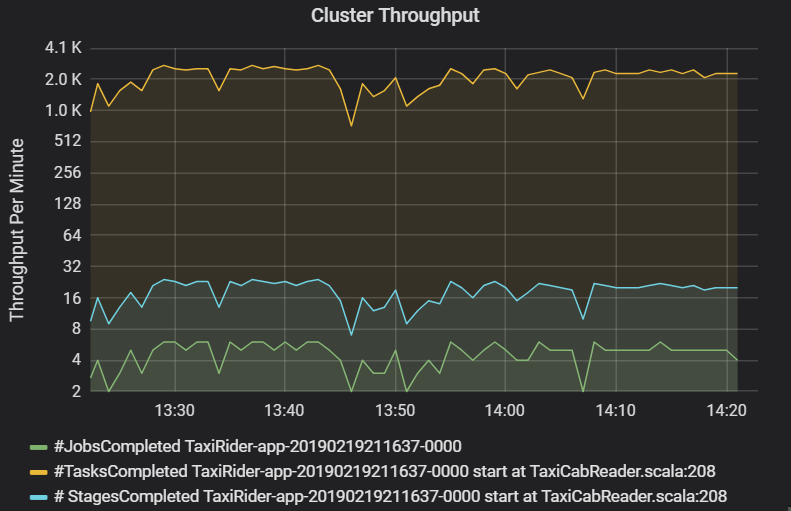
Diagrammet för klusterdataflöde visar antalet jobb, steg och uppgifter som har slutförts per minut. Detta hjälper dig att förstå arbetsbelastningen när det gäller det relativa antalet steg och uppgifter per jobb. Här kan du se att antalet jobb per minut varierar mellan 2 och 6, medan antalet faser är cirka 12–24 per minut.
Summa av svarstid för aktivitetskörning
Den här visualiseringen visar summan av svarstiden för aktivitetskörning per värd som körs i ett kluster. Använd den här grafen för att identifiera uppgifter som körs långsamt på grund av att värden saktar ner på ett kluster eller en felallokering av uppgifter per köre. I följande diagram har de flesta värdar en summa på cirka 30 sekunder. Två av värdarna har dock summor som hovrar runt 10 minuter. Antingen körs värdarna långsamt eller så är antalet uppgifter per köre felallokerat.
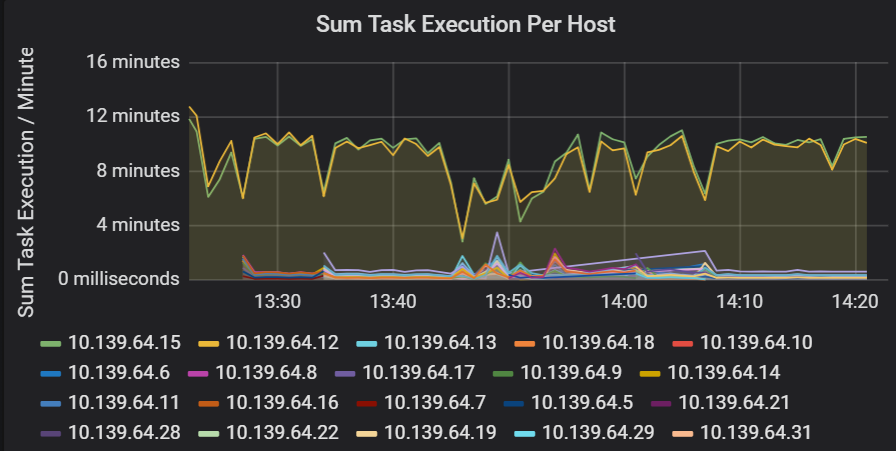
Antalet uppgifter per utförare visar att två utförare tilldelas ett oproportionerligt antal uppgifter, vilket orsakar en flaskhals.
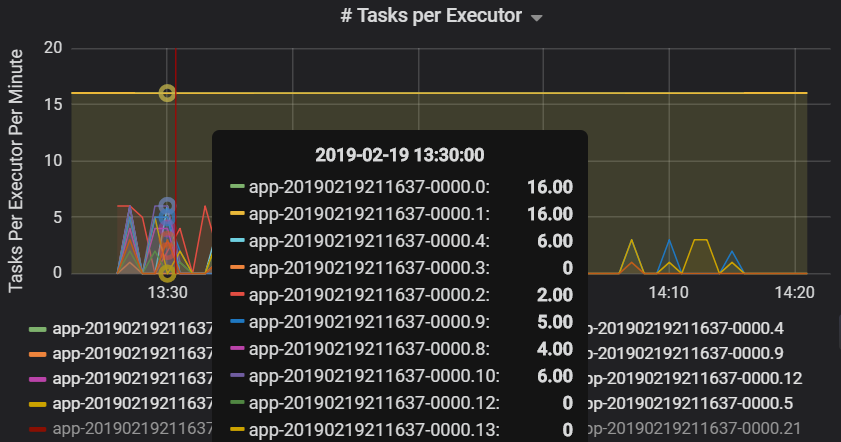
Aktivitetsmått per steg
Visualiseringen av aktivitetsmått ger kostnadsuppdelningen för en aktivitetskörning. Du kan använda den för att se den relativa tid som ägnas åt aktiviteter som serialisering och deserialisering. Dessa data kan visa möjligheter att optimera , till exempel genom att använda sändningsvariabler för att undvika leveransdata. Aktivitetsmåtten visar också shuffle-datastorleken för en aktivitet och tiden för att blanda läsning och skrivning. Om dessa värden är höga innebär det att mycket data flyttas över nätverket.
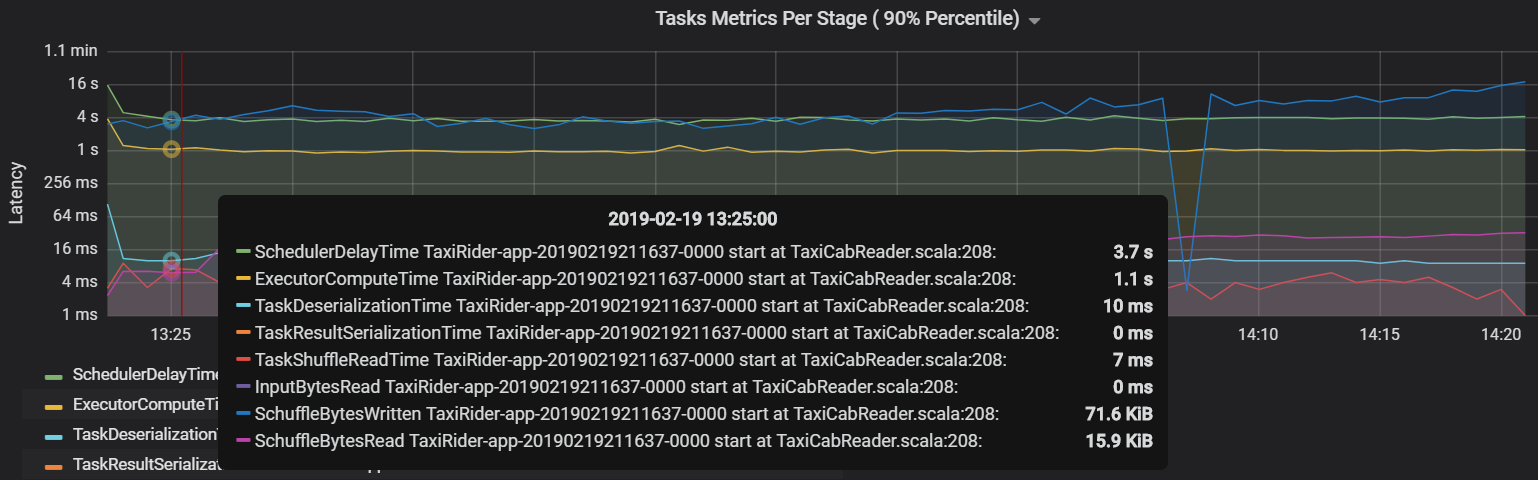
Ett annat aktivitetsmått är schemaläggarens fördröjning, som mäter hur lång tid det tar att schemalägga en aktivitet. Helst bör det här värdet vara lågt jämfört med beräkningstiden för exekutorer, vilket är den tid som faktiskt ägnas åt att utföra uppgiften.
I följande diagram visas en fördröjningstid för schemaläggaren (3,7 s) som överskrider beräkningstiden för exekutor (1,1 s). Det innebär att mer tid ägnas åt att vänta på att aktiviteter schemaläggs än att utföra det faktiska arbetet.
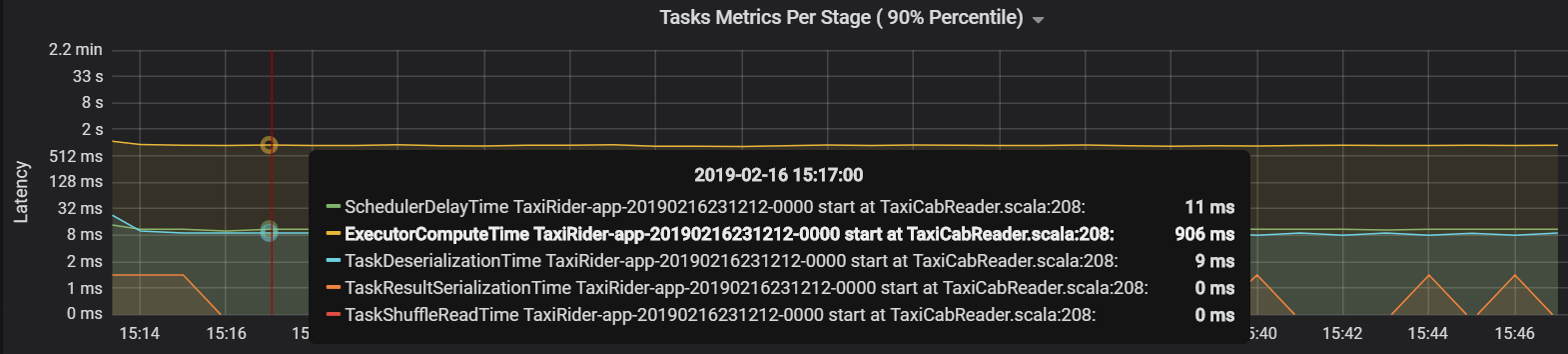
I det här fallet orsakades problemet av för många partitioner, vilket orsakade mycket omkostnader. Genom att minska antalet partitioner minskade schemaläggarens fördröjningstid. Nästa diagram visar att den mesta tiden ägnas åt att utföra uppgiften.
Strömmande dataflöde och svarstid
Strömmande dataflöde är direkt relaterat till strukturerad direktuppspelning. Det finns två viktiga mått som är associerade med strömmande dataflöde: Indatarader per sekund och bearbetade rader per sekund. Om indatarader per sekund överträffar bearbetade rader per sekund innebär det att dataströmbearbetningssystemet ligger efter. Om indata kommer från Event Hubs eller Kafka bör indatarader per sekund hålla jämna steg med datainmatningshastigheten i klientdelen.
Två jobb kan ha liknande klusterdataflöde men mycket olika strömningsmått. Följande skärmbild visar två olika arbetsbelastningar. De liknar klustrets dataflöde (jobb, steg och uppgifter per minut). Men den andra körningen bearbetar 12 000 rader per sekund jämfört med 4 000 rader per sekund.
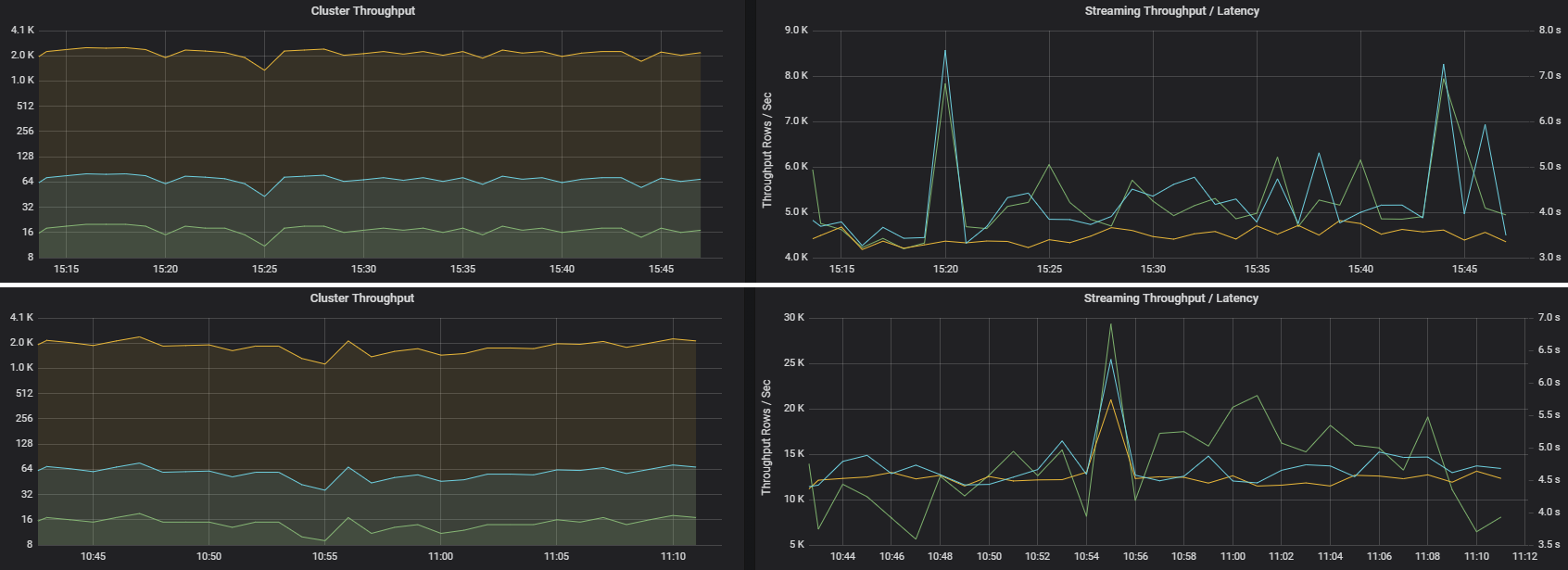
Strömmande dataflöde är ofta ett bättre affärsmått än klusterdataflöde, eftersom det mäter antalet dataposter som bearbetas.
Resursförbrukning per köre
Dessa mått hjälper till att förstå det arbete som varje utförare utför.
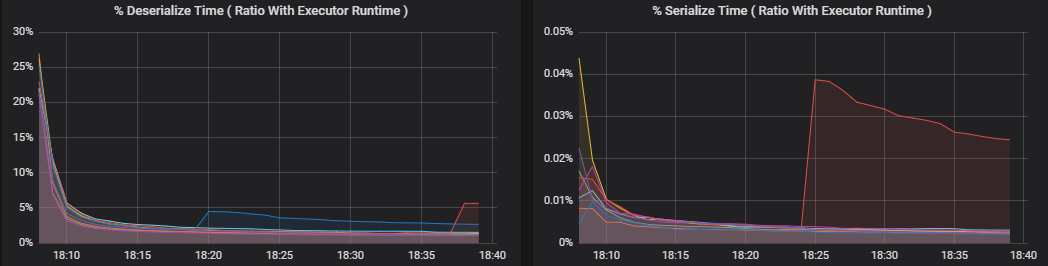
Procentmått mäter hur mycket tid en utförare lägger på olika saker, uttryckt som ett förhållande mellan tid som spenderas jämfört med den totala beräkningstiden för exekutorer. Måtten är:
- % serialisera tid
- % Deserialisera tid
- % cpu-körtid
- % JVM-tid
Dessa visualiseringar visar hur mycket vart och ett av dessa mått bidrar till den övergripande körbearbetningen.
Shuffle-mått är mått som rör datablandning mellan körarna.
- Blanda I/O
- Blanda minne
- Användning av filsystem
- Diskanvändning
Vanliga prestandaflaskhalsar
Två vanliga flaskhalsar för prestanda i Spark är aktivitetsspringlare och ett icke-optimalt antal shuffle-partitioner.
Aktivitetss stragglers
Ett jobbs olika faser körs i följd, och tidigare faser blockerar senare faser. Om en aktivitet kör en shuffle-partition långsammare än andra aktiviteter måste alla aktiviteter i klustret vänta tills den långsamma aktiviteten hinner ifatt innan fasen kan avslutas. Detta kan inträffa av följande skäl:
En värd eller grupp med värdar körs långsamt. Symtom: Hög aktivitets-, fas- eller jobbfördröjning och lågt klusterdataflöde. Sammanfattningen av svarstider för aktiviteter per värd fördelas inte jämnt. Resursförbrukningen fördelas dock jämnt mellan körarna.
Aktiviteter har en dyr aggregering att köra (datasnedvridning). Symtom: Hög svarstid för aktiviteter, svarstid i hög fas, hög jobbfördröjning eller lågt klustergenomflöde, men sammanfattningen av svarstider per värd är jämnt fördelad. Resursförbrukningen fördelas jämnt mellan körarna.
Om partitionerna är av olika storlek kan en större partition orsaka obalanserad aktivitetskörning (partitionssnedvridning). Symptom: Förbrukningen av körresurser är hög jämfört med andra köre som körs i klustret. Alla aktiviteter som körs på den köruppgiften körs långsamt och rymmer faskörningen i pipelinen. Dessa faser sägs vara scenbarriärer.
Icke-optimalt antal shuffle-partitioner
Under en strukturerad direktuppspelningsfråga är tilldelningen av en uppgift till en utförare en resursintensiv åtgärd för klustret. Om shuffle-data inte är den optimala storleken påverkar fördröjningen för en aktivitet dataflödet och svarstiden negativt. Om det finns för få partitioner kommer kärnorna i klustret att underutnyttas, vilket kan leda till ineffektivitet i bearbetningen. Om det däremot finns för många partitioner finns det en hel del hanteringskostnader för ett litet antal uppgifter.
Använd måtten för resursförbrukning för att felsöka partitionsförskjutning och felallokering av exekutorer i klustret. Om en partition är skev utökas körresurserna i jämförelse med andra köre som körs i klustret.
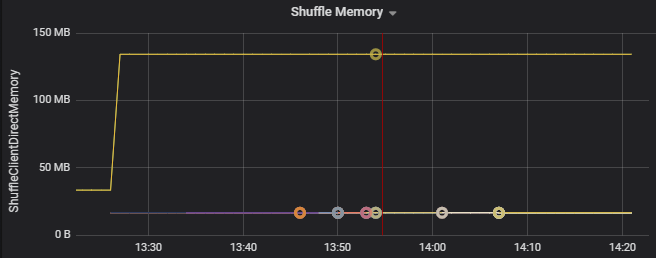
Följande diagram visar till exempel att minnet som används genom att blanda på de två första körarna är 90X större än de andra körarna:
Nästa steg
- Övervaka Azure Databricks på en Azure Log Analytics-arbetsyta
- Utbildningsväg: Skapa och använda maskininlärningslösningar med Azure Databricks
- Dokumentation om Azure Databricks
- Översikt över Azure Monitor