Not
Åtkomst till denna sida kräver auktorisation. Du kan prova att logga in eller byta katalog.
Åtkomst till denna sida kräver auktorisation. Du kan prova att byta katalog.
Azure Front Door
Azure API Management
Azure Kubernetes Service (AKS)
Azure Application Gateway
Dynamics 365
Molnlösningens framgång beror på dess tillförlitlighet. Tillförlitlighet kan definieras brett som sannolikheten att systemet fungerar som förväntat under de angivna miljöförhållandena inom en angiven tid. SRE (Site Reliability Engineering) är en uppsättning principer och metoder för att skapa skalbara och mycket tillförlitliga programvarusystem. I allt högre grad används SRE under utformningen av digitala tjänster för att säkerställa större tillförlitlighet.
Mer information om SRE-strategier finns i AZ-400: Utveckla en SRE-strategi (Site Reliability Engineering).
Potentiella användningsfall
Begreppen i den här artikeln gäller för:
- API-baserade molntjänster.
- Offentliga webbprogram.
- IoT-baserade eller händelsebaserade arbetsbelastningar.
Arkitektur

Ladda ned en PowerPoint-fil med den här arkitekturen.
Arkitekturen som beaktas här är en skalbar API-plattform. Lösningen består av flera mikrotjänster som använder olika databaser och lagringstjänster, inklusive SaaS-lösningar (programvara som en tjänst), till exempel Dynamics 365 och Microsoft 365.
I den här artikeln beskrivs en lösning som hanterar användningsfall på hög nivå för Marketplace och e-handel för att demonstrera de block som visas i diagrammet. Användningsfallen är:
- Produktbläddring.
- Registrering och inloggning.
- Visning av innehåll som nyhetsartiklar.
- Order- och prenumerationshantering.
Klientprogram som webbappar, mobilappar och till och med tjänstprogram använder API-plattformstjänsterna via en enhetlig åtkomstväg, https://api.contoso.com.
Komponenter
- Azure Front Door tillhandahåller en säker, enhetlig startpunkt för alla begäranden till lösningen. Mer information finns i Översikt över routningsarkitektur.
- Azure API Management tillhandahåller ett styrningslager ovanpå alla publicerade API:er. Du kan använda Azure API Management-principer för att tillämpa ytterligare funktioner på API-lagret, till exempel åtkomstbegränsningar, cachelagring och datatransformering. API Management stöder automatisk skalning på Standard- och Premium-nivåer.
- Azure Kubernetes Service (AKS) är Azure-implementeringen av Kubernetes-kluster med öppen källkod. Som värdbaserad Kubernetes-tjänst hanterar Azure viktiga uppgifter som hälsoövervakning och underhåll. Eftersom Azure hanterar Kubernetes API-servern hanterar och underhåller du bara agentnoderna. I den här arkitekturen distribueras alla mikrotjänster i AKS.
- Azure Application Gateway är en tjänst för programleveranskontrollant. Den fungerar på nivå 7, programskiktet, och har olika belastningsutjämningsfunktioner. Application Gateway Ingress Controller (AGIC) är ett Kubernetes-program som gör det möjligt för Azure Kubernetes Service-kunder (AKS) att använda azure-inbyggda Application Gateway L7-lastbalanserare för att exponera molnprogramvara för Internet. Autoskalning och zonredundans stöds i v2-SKU:n.
- Azure Storage, Azure Data Lake Storage, Azure Cosmos DB och Azure SQL kan lagra både strukturerat och icke-strukturerat innehåll. Azure Cosmos DB-containrar och databaser kan skapas med autoskalningsdataflöde.
- Microsoft Dynamics 365 är ett SaaS-erbjudande (programvara som en tjänst) från Microsoft som tillhandahåller flera affärsprogram för kundtjänst, försäljning, marknadsföring och ekonomi. I den här arkitekturen används Dynamics 365 främst för att hantera produktkataloger och för kundtjänsthantering. Skalningsenheter ger återhämtning till Dynamics 365-program.
- Microsoft 365 (tidigare Office 365) används som ett innehållshanteringssystem för företag som bygger på Microsoft 365 SharePoint i Microsoft 365. Den används för att skapa, hantera och publicera innehåll som medietillgångar och dokument.
Alternativ
Eftersom den här lösningen använder en mycket skalbar mikrotjänstbaserad arkitektur bör du överväga följande alternativ för beräkningsplanet:
- Azure Functions för serverlösa API-tjänster
- Azure Spring Apps för Java-baserade mikrotjänster
Lämplig tillförlitlighet
Vilken grad av tillförlitlighet som krävs för en lösning beror på affärskontexten. En butik som är öppen i 14 timmar, och som har en systemanvändning som når sin topp inom det intervallet, har andra krav än ett onlineföretag som tar emot beställningar hela tiden. SRE-metoder kan skräddarsys för att uppnå lämplig tillförlitlighetsnivå.
Tillförlitlighet definieras och mäts med hjälp av servicenivåmål (servicenivåmål)) som definierar målnivån för tillförlitlighet för en tjänst. Att uppnå målnivån säkerställer att konsumenterna är nöjda. SLO-målen kan utvecklas eller ändras beroende på verksamhetens krav. Tjänstägarna bör dock ständigt mäta tillförlitligheten mot SLO:erna för att identifiera problem och vidta korrigerande åtgärder. SLO:er definieras vanligtvis som en procentuell prestation under en period.
En annan viktig term att notera är indikator på tjänstnivå (servicenivåindikator (SLI)), som är måttet som används för att beräkna servicenivåindikatorn. SLO:er baseras på insikter som härleds från data som samlas in när kunden använder tjänsten. SLA mäts alltid ur kundens synvinkel.
SLO:er och SLO:er går alltid hand i hand och definieras vanligtvis på ett iterativt sätt. Serviceavtal drivs av viktiga affärsmål, medan SLO:er drivs av vad som är möjligt att mäta när tjänsten implementeras.
Följande bild visar relationen mellan det övervakade måttet, SLI och SLO:
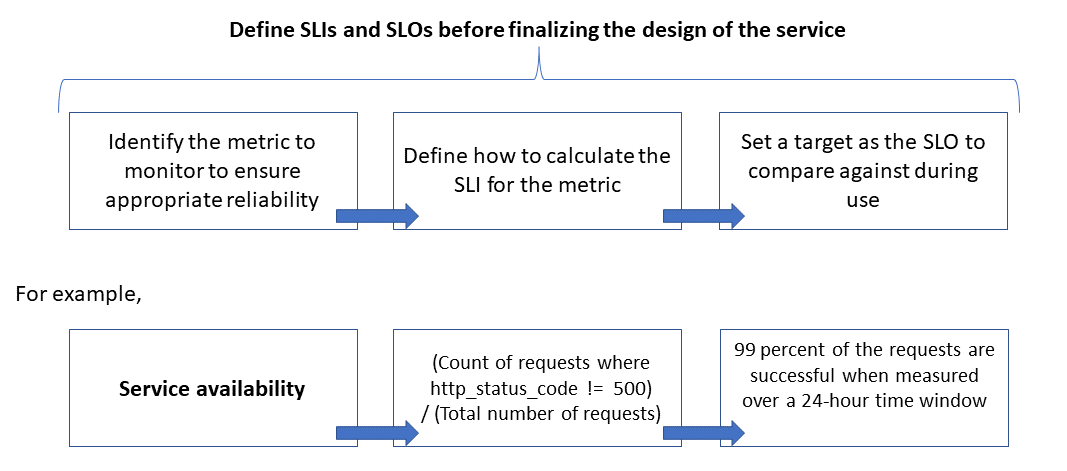
För mer information om den här processen, se Definiera SLI-mått för att beräkna SLO:er.
Modelleringsskalning och prestandaförväntningar
För ett programvarusystem refererar prestanda vanligtvis till systemets övergripande svarstider vid körning av en åtgärd inom en angiven tid, medan skalbarhet är systemets förmåga att hantera ökad användarbelastning utan att försämra prestandan.
Ett system betraktas som skalbart om de underliggande resurserna görs tillgängliga dynamiskt för att stödja en ökad belastning. Molnprogram måste utformas för skalning och trafikvolymen är svår att förutsäga ibland. Säsongstoppar kan öka skalningskraven, särskilt när en tjänst hanterar begäranden för flera klienter.
Det är en bra idé att utforma program så att molnresurserna skalas upp och ned automatiskt efter behov för att möta belastningen. I grund och botten bör systemet anpassa sig till arbetsbelastningsökningen genom att etablera eller allokera resurser på ett inkrementellt sätt för att möta efterfrågan. Skalbarhet gäller inte bara beräkningsinstanser, utan även för andra element som datalagring och meddelandeinfrastruktur.
Den här artikeln visar hur du kan säkerställa lämplig tillförlitlighet för ett molnprogram genom att utföra skalnings- och prestandamodellering av arbetsbelastningsscenarier och använda resultaten för att definiera övervakare, SLO:er och SLO:er.
Att tänka på
Mer information om hur du skapar skalbara och tillförlitliga program finns i grundpelarna Tillförlitlighet och prestandaeffektivitet i Azure Well Architected Framework.
I den här artikeln beskrivs hur du använder skalbarhets- och prestandamodelleringstekniker för att finjustera lösningsarkitekturen och designen. Dessa tekniker identifierar ändringar i transaktionsflödena för optimal användarupplevelse. Basera dina tekniska beslut på icke-funktionella krav för lösningen. Processen är följande:
- Identifiera skalbarhetskraven.
- Modellera den förväntade belastningen.
- Definiera SLO:er och SLO:er för användarscenarier.
Kommentar
Azure Application Insights, en del av Azure Monitor, är ett kraftfullt verktyg för programprestandahantering (APM) som du enkelt kan integrera med dina program för att skicka telemetri och analysera programspecifika mått. Den innehåller också färdiga instrumentpaneler och en måttutforskare som du kan använda för att analysera data för att utforska affärsbehov.
Samla in skalbarhetskrav
Anta följande mått för högsta belastning:
- Antal konsumenter som använder API-plattformen: 1,5 miljoner
- Aktiva konsumenter per timme (30 procent av 1,5 miljoner): 450 000
- Procentandel av belastningen för varje aktivitet:
- Produktbläddring: 75 procent
- Registrering inklusive skapande av profil och inloggning: 10 procent
- Hantering av beställningar och prenumerationer: 10 procent
- Innehållsvisning: 5 procent
Belastningen genererar följande skalningskrav under normal belastning för de API:er som hanteras av plattformen:
- Produktmikrotjänst: cirka 500 begäranden per sekund (RPS)
- Profilmikrotjänst: cirka 100 RPS
- Beställningar och mikrotjänst för betalning: cirka 100 RPS
- Innehållsmikrotjänst: cirka 50 RPS
Dessa skalningskrav tar inte hänsyn till säsongs- och slumpmässiga toppar och toppar under särskilda evenemang, till exempel marknadsföringskampanjer. Under toppar är skalningskravet för vissa användaraktiviteter upp till 10 gånger den normala toppbelastningen. Tänk på dessa begränsningar och förväntningar när du gör designvalen för mikrotjänsterna.
Definiera SLI-mått för att beräkna serviceavtal
SLI-mått anger i vilken grad en tjänst ger en tillfredsställande upplevelse och kan uttryckas som förhållandet mellan bra händelser och totala händelser.
För en API-tjänst refererar händelser till de programspecifika mått som samlas in under körningen som telemetri eller bearbetade data. Det här exemplet har följande SLI-mått:
| Mätvärde | Beskrivning |
|---|---|
| Tillgänglighet | Om begäran betjänades av API:et |
| Svarstid | Tid för API:et att bearbeta begäran och returnera ett svar |
| Genomflöde | Antal begäranden som API:et hanterade |
| Lyckad hastighet | Antal begäranden som API:et har hanterat |
| Felfrekvens | Antal fel för de begäranden som API:et hanterade |
| Aktualitet | Antal gånger användaren tog emot de senaste data för läsåtgärder i API:et, trots att det underliggande datalagret uppdaterades med en viss skrivfördröjning |
Kommentar
Se till att identifiera eventuella ytterligare SLO:er som är viktiga för din lösning.
Här är exempel på SLO:er:
- (Antal begäranden som har slutförts på mindre än 1 000 ms) / (Antal begäranden)
- (Antal sökresultat som inom tre sekunder returnerar alla produkter som har publicerats i katalogen) / (Antal sökningar)
När du har definierat SLO:erna avgör du vilka händelser eller telemetri som ska avbildas för att mäta dem. Om du till exempel vill mäta tillgängligheten samlar du in händelser för att ange om API-tjänsten har bearbetat en begäran. För HTTP-baserade tjänster anges lyckade eller misslyckade med HTTP-statuskoder. API-designen och implementeringen måste ange rätt koder. I allmänhet är SLI-mått en viktig indata för API-implementeringen.
För molnbaserade system kan du hämta några av måtten med hjälp av det diagnostik- och övervakningsstöd som är tillgängligt för resurserna. Azure Monitor är en omfattande lösning för att samla in, analysera och agera på telemetri från dina molntjänster. Beroende på dina SLI-krav kan du samla in mer övervakningsdata för att beräkna måtten.
Använda percentilfördelningar
Vissa SLO:er beräknas med hjälp av en percentildistributionsteknik. Detta ger bättre resultat om det finns extremvärden som kan förvränga andra tekniker, till exempel medelvärdes- eller medianfördelningar.
Tänk till exempel på att måttet är svarstid för API-begäranden och att tre sekunder är tröskelvärdet för optimal prestanda. De sorterade svarstiderna för en timmes API-begäranden visar att få begäranden tar längre tid än tre sekunder och de flesta får svar inom tröskelvärdet. Detta är systemets förväntade beteende.
Percentilfördelningen är avsedd att undanta extremvärden som orsakas av tillfälliga problem. Om rätt tjänstsvar till exempel finns i den 90:e eller 95:e percentilen anses SLO vara uppfyllt.
Välj rätt måttperioder
Mätningsperioden för att definiera ett servicenivåmål är mycket viktig. Det måste fånga aktivitet, inte inaktivitet, för att resultaten ska vara meningsfulla för användarupplevelsen. Det här fönstret kan vara fem minuter till 24 timmar beroende på hur du vill övervaka och beräkna SLI-måttet.
Upprätta en process för prestandastyrning
Prestandan för ett API måste hanteras från starten tills det är inaktuellt eller tillbakadraget. En robust styrningsprocess måste finnas på plats för att säkerställa att prestandaproblem upptäcks och åtgärdas tidigt, innan de orsakar ett stort avbrott som påverkar verksamheten.
Här är elementen i prestandastyrning:
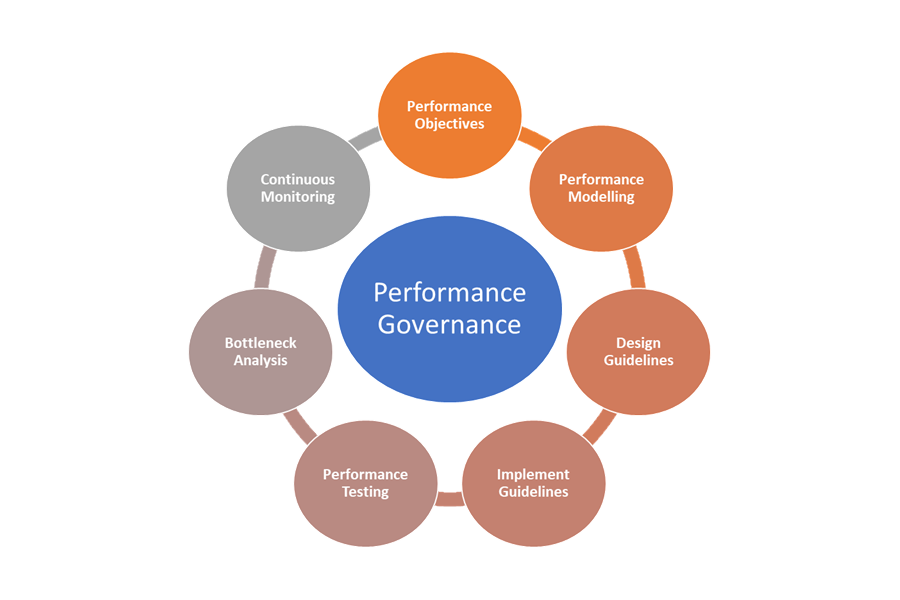
- Prestandamål: Definiera de ambitiösa prestanda-SLO:erna för affärsscenarier.
- Prestandamodellering: Identifiera affärskritiska arbetsflöden och transaktioner och utför modellering för att förstå de prestandarelaterade konsekvenserna. Samla in den här informationen på detaljerad nivå för mer exakta förutsägelser.
- Designriktlinjer: Förbered riktlinjer för prestandadesign och rekommendera lämpliga ändringar i affärsarbetsflödet. Se till att teamen förstår dessa riktlinjer.
- Implementera riktlinjer: Implementera riktlinjer för prestandadesign för lösningskomponenterna, inklusive instrumentation för att samla in mått. Genomför prestandadesigngranskningar. Det är viktigt att spåra alla dessa med hjälp av kvarvarande arkitekturobjekt för de olika teamen.
- Prestandatestning: Utför belastnings- och stresstestning i enlighet med belastningsprofilfördelningen för att samla in de mått som är relaterade till plattformshälsa. Du kan också utföra dessa tester för en begränsad belastning för att jämföra kraven på lösningsinfrastruktur.
- Flaskhalsanalys: Använd kodgranskning och kodgranskningar för att identifiera, analysera och ta bort flaskhalsar i prestanda på olika komponenter. Identifiera horisontella eller lodräta skalningsförbättringar som krävs för att stödja den högsta belastningen.
- Kontinuerlig övervakning: Upprätta en infrastruktur för kontinuerlig övervakning och avisering som en del av DevOps-processerna. Se till att de berörda teamen meddelas när svarstiderna försämras avsevärt jämfört med riktmärken.
- Prestandastyrning: Upprätta en prestandastyrning som består av väldefinierade processer och team för att upprätthålla prestanda-SLO:erna. Spåra efterlevnad efter varje version för att undvika försämring på grund av bygguppgraderingar. Utför regelbundet granskningar för att utvärdera eventuell ökad belastning för att identifiera lösningsuppgraderingar.
Se till att upprepa stegen under hela din lösningsutveckling som en del av den progressiva utvecklingsprocessen.
Spåra prestandamål och förväntningar i kvarvarande uppgifter
Spåra dina prestandamål för att säkerställa att de uppnås. Samla in detaljerade och detaljerade användarberättelser att spåra. Detta hjälper till att säkerställa att utvecklingsteamen prioriterar prestandastyrningsaktiviteter.
Upprätta ambitiösa serviceavtal för mållösningen
Här är exempel på ambitiösa SLO:er för API-plattformslösningen som övervägs:
- Svarar på 95 procent av alla READ-begäranden under en dag inom en sekund.
- Svarar på 95 procent av alla CREATE- och UPDATE-begäranden under en dag inom tre sekunder.
- Svarar på 99 procent av alla begäranden under en dag inom fem sekunder utan fel.
- Svarar på 99,9 procent av alla begäranden under en dag inom fem minuter.
- Mindre än en procent av begäranden under den högsta entimmesfönstret.
Serviceavtalen kan skräddarsys för att passa specifika programkrav. Det är dock viktigt att vara tillräckligt detaljerad för att ha klarheten för att säkerställa tillförlitligheten.
Mät initiala serviceavtal som baseras på data från loggarna
Övervakningsloggar skapas automatiskt när API-tjänsten används. Anta att en vecka med data visar följande resultat:
- Begäranden: 123 456
- Lyckade begäranden: 123 204
- Svarstid för 90:e percentilen: 497 ms
- Svarstid för 95:e percentilen: 870 ms
- 99:e percentilens svarstid: 1 024 ms
Dessa data genererar följande initiala SLO:er:
- Tillgänglighet = (123 204 / 123 456) = 99,8 procent
- Svarstid = minst 90 procent av begärandena har hanterats inom 500 ms
- Svarstid = cirka 98 procent av begärandena hanterades inom 1 000 ms
Anta att SLO-målet för den ambitiösa svarstiden under planeringen är att 90 procent av begärandena bearbetas inom 500 ms med en framgångsgrad på 99 procent under en vecka. Med loggdata kan du enkelt identifiera om SLO-målet uppfylldes. Om du gör den här typen av analys i några veckor kan du börja se trender kring SLO-efterlevnad.
Vägledning för teknisk riskreducering
Använd följande checklista med rekommenderade metoder för att minska skalbarhets- och prestandarisker:
- Design för skalning och prestanda.
- Se till att du samlar in skalningskrav för varje användarscenario och arbetsbelastning, inklusive säsongsvariationer och toppar.
- Utföra prestandamodellering för att identifiera systembegränsningar och flaskhalsar
- Hantera tekniska skulder.
- Utför omfattande spårning av prestandamått.
- Överväg att använda skript för att köra verktyg som K6.io, Karate och JMeter i din utvecklingslagringsmiljö med ett antal användarbelastningar– till exempel 50 till 100 RPS. Detta ger information i loggarna för att identifiera design- och implementeringsproblem.
- Integrera automatiserade testskript som en del av dina processer för kontinuerlig distribution (CD) för att identifiera byggbrytningar.
- Ha ett produktionstänk.
- Justera tröskelvärden för automatisk skalning enligt hälsostatistiken.
- Föredrar horisontella skalningstekniker framför lodräta.
- Var proaktiv med skalning för att hantera säsongsvariationer.
- Föredrar ringbaserad distribution.
- Använd felbudgetar för att experimentera.
Prissättning
Tillförlitlighet, prestandaeffektivitet och kostnadsoptimering går hand i hand. De Azure-tjänster som används i arkitekturen bidrar till att minska kostnaderna, eftersom de autoskalas för att hantera föränderliga användarbelastningar.
För AKS kan du börja med virtuella datorer i standardstorlek för nodpoolen. Du kan sedan övervaka resurskraven under utvecklings- eller produktionsanvändningen och justera därefter.
Kostnadsoptimering är en grundpelare i Microsoft Azure Well-Architected Framework. Mer information finns i Översikt över kostnadsoptimeringspelare. Om du vill beräkna kostnaden för Azure-produkter och -konfigurationer använder du priskalkylatorn.
Deltagare
Den här artikeln underhålls av Microsoft. Det har ursprungligen skrivits av följande medarbetare.
Huvudförfattare:
- Subhajit Chatterjee | Huvudprogramtekniker
Nästa steg
- Azure-dokumentation
- Microsoft Azure Well-Architected ramverk
- Arkitekturformat för mikrotjänster
- Design för att skala ut
- Välj en Azure-beräkningstjänst för ditt program
- Arkitektur för mikrotjänster i Azure Kubernetes Service
- Vad är Azure Front Door?
- Om API Management
- Vad är Application Gateway-ingresskontrollant?
- Azure Kubernetes Service
- Automatisk skalning och zonredundant Application Gateway v2
- Skala ett kluster automatiskt för att uppfylla programbehov i Azure Kubernetes Service (AKS)
- Skapa Azure Cosmos DB-containrar och databaser med autoskalningsdataflöde
- Dokumentation för Microsoft Dynamics 365
- Dokumentation om Microsoft 365
- Dokumentation om platstillförlitlighetsteknik
- AZ-400: Utveckla en SRE-strategi (Site Reliability Engineering)
- Baslinjewebbprogram med zonredundans