Varning
Den här artikeln refererar till CentOS, en Linux-distribution som är End Of Life (EOL). Överväg att använda och planera i enlighet med detta. Mer information finns i CentOS End Of Life-vägledningen.
Det här exempelscenariot visar hur du kör Apache NiFi på Azure. NiFi tillhandahåller ett system för bearbetning och distribution av data.
Apache®, Apache NiFi® och NiFi® är antingen registrerade varumärken eller varumärken som tillhör Apache Software Foundation i USA och/eller andra länder. Inget godkännande från Apache Software Foundation underförstås av användningen av dessa märken.
Arkitektur

Ladda ned en Visio-fil med den här arkitekturen.
Arbetsflöde
NiFi-programmet körs på virtuella datorer i NiFi-klusternoder. De virtuella datorerna finns i en VM-skalningsuppsättning som konfigurationen distribuerar över tillgänglighetszoner.
Apache ZooKeeper körs på virtuella datorer i ett separat kluster. NiFi använder ZooKeeper-klustret för följande ändamål:
- Så här väljer du en klusterkoordinatornod
- Samordna dataflödet
Azure Application Gateway ger layer-7 belastningsutjämning för användargränssnittet som körs på NiFi-noderna.
Övervaka och dess Log Analytics-funktion samlar in, analyserar och agerar på telemetri från NiFi-systemet. Telemetrin innehåller NiFi-systemloggar, systemhälsomått och prestandamått.
Azure Key Vault lagrar certifikat och nycklar på ett säkert sätt för NiFi-klustret.
Microsoft Entra ID tillhandahåller enkel inloggning (SSO) och multifaktorautentisering.
Komponenter
- NiFi tillhandahåller ett system för bearbetning och distribution av data.
- ZooKeeper är en server med öppen källkod som hanterar distribuerade system.
- Virtual Machines är ett IaaS-erbjudande (infrastruktur som en tjänst). Du kan använda virtuella datorer för att distribuera skalbara beräkningsresurser på begäran. Virtuella datorer ger flexibiliteten i virtualisering men eliminerar underhållskraven för fysisk maskinvara.
- Skalningsuppsättningar för virtuella Azure-datorer är ett sätt att hantera en grupp med belastningsutjämning av virtuella datorer. Antalet vm-instanser i en uppsättning kan automatiskt öka eller minska som svar på efterfrågan eller ett definierat schema.
- Tillgänglighetszoner är unika fysiska platser i en Azure-region. Dessa erbjudanden med hög tillgänglighet skyddar program och data från datacenterfel.
- Application Gateway är en lastbalanserare som hanterar trafik till webbprogram.
- Monitor samlar in och analyserar data om miljöer och Azure-resurser. Dessa data omfattar apptelemetri, till exempel prestandamått och aktivitetsloggar. Mer information finns i Övervaka överväganden senare i den här artikeln.
- Log Analytics är ett Azure Portal verktyg som kör frågor på Övervaka loggdata. Log Analytics innehåller även funktioner för diagram och statistisk analys av frågeresultat.
- Azure DevOps Services tillhandahåller tjänster, verktyg och miljöer för hantering av kodningsprojekt och distributioner.
- Key Vault lagrar och styr åtkomsten till ett systems hemligheter på ett säkert sätt, till exempel API-nycklar, lösenord, certifikat och kryptografiska nycklar.
- Microsoft Entra ID är en molnbaserad identitetstjänst som styr åtkomsten till Azure och andra molnappar.
Alternativ
- Azure Data Factory är ett alternativ till den här lösningen.
- I stället för Key Vault kan du använda en jämförbar tjänst för att lagra systemhemligheter.
- Apache Airflow. Mer information finns i Hur Airflow och NiFi skiljer sig åt.
- Det är möjligt att använda ett företag nifi-alternativ som stöds som Cloudera Apache NiFi. Cloudera-erbjudandet är tillgängligt via Azure Marketplace.
Information om scenario
I det här scenariot körs NiFi i en klustrad konfiguration över virtuella Azure-datorer i en skalningsuppsättning. Men de flesta av den här artikelns rekommendationer gäller även för scenarier som kör NiFi i eninstansläge på en enda virtuell dator (VM). Metodtipsen i den här artikeln visar en skalbar distribution med hög tillgänglighet och säker distribution.
Potentiella användningsfall
NiFi fungerar bra för att flytta data och hantera dataflödet:
- Ansluta frikopplade system i molnet
- Flytta data till och från Azure Storage och andra datalager
- Integrera program från gräns till moln och hybridmoln med Azure IoT, Azure Stack och Azure Kubernetes Service (AKS)
Därför gäller den här lösningen för många områden:
Moderna informationslager (MDW) sammanför strukturerade och ostrukturerade data i stor skala. De samlar in och lagrar data från olika källor, mottagare och format. NiFi utmärker sig för att mata in data i Azure-baserade MDW:ar av följande skäl:
- Över 200 processorer är tillgängliga för att läsa, skriva och manipulera data.
- Systemet stöder lagringstjänster som Azure Blob Storage, Azure Data Lake Storage, Azure Event Hubs, Azure Queue Storage, Azure Cosmos DB och Azure Synapse Analytics.
- Robusta funktioner för data proveniens gör det möjligt att implementera kompatibla lösningar. Information om hur du samlar in data proveniens i Log Analytics-funktionen i Azure Monitor finns i Rapporteringsöverväganden senare i den här artikeln.
NiFi kan köras fristående på små fotavtrycksenheter. I sådana fall gör NiFi det möjligt att bearbeta gränsdata och flytta dessa data till större NiFi-instanser eller kluster i molnet. NiFi hjälper till att filtrera, transformera och prioritera gränsdata i rörelse, vilket säkerställer tillförlitliga och effektiva dataflöden.
Industriella IoT-lösningar (IIoT) hanterar dataflödet från gränsen till datacentret. Det flödet börjar med datainsamling från industriella kontrollsystem och utrustning. Data flyttas sedan till datahanteringslösningar och MDW:er. NiFi erbjuder funktioner som gör det väl lämpat för datainsamling och förflyttning:
- Funktioner för bearbetning av Edge-data
- Stöd för protokoll som IoT-gatewayer och -enheter använder
- Integrering med Event Hubs och lagringstjänster
IoT-program inom områdena förebyggande underhåll och hantering av leveranskedjan kan använda den här funktionen.
Rekommendationer
Tänk på följande när du använder den här lösningen:
Rekommenderade versioner av NiFi
När du kör den här lösningen på Azure rekommenderar vi att du använder version 1.13.2+ av NiFi. Du kan köra andra versioner, men de kan kräva olika konfigurationer från dem i den här guiden.
Om du vill installera NiFi på virtuella Azure-datorer är det bäst att ladda ned binärfilerna för bekvämligheten från sidan med NiFi-nedladdningar. Du kan också skapa binärfilerna från källkoden.
Rekommenderade versioner av ZooKeeper
I det här exemplet rekommenderar vi att du använder version 3.5.5 och senare eller 3.6.x av ZooKeeper.
Du kan installera ZooKeeper på virtuella Azure-datorer med hjälp av officiella binärfiler för bekvämlighet eller källkod. Båda är tillgängliga på sidan Apache ZooKeeper-versioner.
Att tänka på
Dessa överväganden implementerar grundpelarna i Azure Well-Architected Framework, som är en uppsättning vägledande grundsatser som kan användas för att förbättra kvaliteten på en arbetsbelastning. Mer information finns i Microsoft Azure Well-Architected Framework.
Information om hur du konfigurerar NiFi finns i Administratörsguide för Apache NiFi-system. Tänk också på dessa överväganden när du implementerar den här lösningen.
Kostnadsoptimering
Kostnadsoptimering handlar om att titta på sätt att minska onödiga utgifter och förbättra drifteffektiviteten. Mer information finns i Översikt över kostnadsoptimeringspelare.
- Använd Priskalkylatorn för Azure för att beräkna kostnaden för resurserna i den här arkitekturen.
- En uppskattning som innehåller alla tjänster i den här arkitekturen förutom den anpassade aviseringslösningen finns i den här exempelkostnadsprofilen.
Överväganden för virtuella datorer
Följande avsnitt innehåller en detaljerad beskrivning av hur du konfigurerar de virtuella NiFi-datorerna:
Storlek på virtuell dator
I den här tabellen visas rekommenderade VM-storlekar att börja med. För de flesta allmänna dataflöden är Standard_D16s_v3 bäst. Men varje dataflöde i NiFi har olika krav. Testa flödet och ändra storlek efter behov baserat på flödets faktiska krav.
Överväg att aktivera accelererat nätverk på de virtuella datorerna för att öka nätverksprestandan. Mer information finns i Nätverk för skalningsuppsättningar för virtuella Azure-datorer.
| Storlek på virtuell dator | vCPU | Minne i GB | Maximalt dataflöde för oanvänd datadisk i I/O-åtgärder per sekund (IOPS) per Mbit/s* | Maximalt antal nätverksgränssnitt (NÄTVERKSKORT)/Förväntad nätverksbandbredd (Mbit/s) |
|---|---|---|---|---|
| Standard_D8s_v3 | 8 | 32 | 12,800/192 | 4/4,000 |
| Standard_D16s_v3** | 16 | 64 | 25,600/384 | 8/8,000 |
| Standard_D32s_v3 | 32 | 128 | 51,200/768 | 8/16,000 |
| Standard_M16m | 16 | 437.5 | 10,000/250 | 8/4,000 |
* Inaktivera cachelagring av datadiskskrivning för alla datadiskar som du använder på NiFi-noder.
** Vi rekommenderar den här SKU:n för de flesta allmänna dataflöden. SKU:er för virtuella Azure-datorer med liknande vCPU- och minneskonfigurationer bör också vara tillräckliga.
OPERATIVSYSTEM (VM)
Vi rekommenderar att du kör NiFi i Azure på något av följande gästoperativsystem:
- Ubuntu 18.04 LTS eller senare
- CentOS 7,9
För att uppfylla de specifika kraven för ditt dataflöde är det viktigt att justera flera inställningar på os-nivå, inklusive:
- Maximalt antal förgrenade processer.
- Maximalt antal filreferenser.
- Åtkomsttiden,
atime.
När du har justerat operativsystemet så att det passar ditt förväntade användningsfall använder du Azure VM Image Builder för att koda genereringen av dessa finjusterade avbildningar. Vägledning som är specifik för NiFi finns i Konfigurationstips i Apache NiFi-systemadministratörsguiden.
Storage
Lagra de olika NiFi-lagringsplatserna på datadiskar och inte på OS-disken av tre huvudsakliga orsaker:
- Flöden har ofta höga krav på diskgenomflöde som en enskild disk inte kan uppfylla.
- Det är bäst att separera NiFi-diskåtgärderna från os-diskåtgärderna.
- Lagringsplatserna bör inte finnas på tillfällig lagring.
I följande avsnitt beskrivs riktlinjer för att konfigurera datadiskarna. Dessa riktlinjer är specifika för Azure. Mer information om hur du konfigurerar lagringsplatserna finns i Tillståndshantering i Apache NiFi-systemadministratörsguiden.
Datadisktyp och storlek
Tänk på dessa faktorer när du konfigurerar datadiskarna för NiFi:
- Disktyp
- Diskstorlek
- Totalt antal diskar
Kommentar
Uppdaterad information om disktyper, storleksändring och priser finns i Introduktion till Hanterade Azure-diskar.
I följande tabell visas de typer av hanterade diskar som för närvarande är tillgängliga i Azure. Du kan använda NiFi med någon av dessa disktyper. Men för dataflöden med högt dataflöde rekommenderar vi Premium SSD.
| Ultra Disk Storage (NVM Express (NVMe)) | Premium SSD | Standard SSD | Standard HDD | |
|---|---|---|---|---|
| Disktyp | SSD | SSD | SSD | HDD |
| Maximal diskstorlek | 65 536 GB | 32 767 GB | 32 767 GB | 32 767 GB |
| Maximalt dataflöde | 2 000 MiB/s | 900 MiB/s | 750 MiB/s | 500 MiB/s |
| Maximalt IOPS | 160 000 | 20 000 | 6 000 | 2 000 |
Använd minst tre datadiskar för att öka dataflödets dataflöde. Metodtips för att konfigurera lagringsplatserna på diskarna finns i Lagringsplatskonfiguration senare i den här artikeln.
I följande tabell visas relevanta storleks- och dataflödesnummer för varje diskstorlek och typ.
| Standard HDD S15 | Standard HDD S20 | Standard HDD S30 | Standard SSD S15 | Standard SSD S20 | Standard SSD S30 | Premium SSD P15 | Premium SSD P20 | Premium SSD P30 | |
|---|---|---|---|---|---|---|---|---|---|
| Diskstorlek i GB | 256 | 512 | 1,024 | 256 | 512 | 1,024 | 256 | 512 | 1,024 |
| IOPS per disk | Upp till 500 | Upp till 500 | Upp till 500 | Upp till 500 | Upp till 500 | Upp till 500 | 1 100 | 2 300 | 5 000 |
| Dataflöde per disk | Upp till 60 Mbit/s | Upp till 60 Mbit/s | Upp till 60 Mbit/s | Upp till 60 Mbit/s | Upp till 60 Mbit/s | Upp till 60 Mbit/s | 125 Mbit/s | 150 Mbit/s | 200 Mbit/s |
Om systemet når VM-gränserna kanske det inte ökar dataflödet genom att lägga till fler diskar:
- IOPS- och dataflödesgränser beror på diskens storlek.
- Den vm-storlek som du väljer placerar IOPS och dataflödesgränser för den virtuella datorn på alla datadiskar.
Information om diskdataflödesgränser på VM-nivå finns i Storlekar för virtuella Linux-datorer i Azure.
Cachelagring av virtuell datordisk
På virtuella Azure-datorer hanterar funktionen Cachelagring av värddiskar cachelagring av diskar. Om du vill öka dataflödet i datadiskar som du använder för lagringsplatser inaktiverar du diskskrivningscachelagring genom att ange Värdcachelagring till None.
Konfiguration av lagringsplats
Riktlinjerna för bästa praxis för NiFi är att använda en separat disk eller diskar för var och en av dessa lagringsplatser:
- Innehåll
- FlowFile
- Härkomst
Den här metoden kräver minst tre diskar.
NiFi stöder även striping på programnivå. Den här funktionen ökar storleken eller prestandan för datalagringsplatserna.
Följande utdrag är från konfigurationsfilen nifi.properties . Den här konfigurationen partitionerar och strimlar lagringsplatserna mellan hanterade diskar som är anslutna till de virtuella datorerna:
nifi.provenance.repository.directory.stripe1=/mnt/disk1/ provenance_repository
nifi.provenance.repository.directory.stripe2=/mnt/disk2/ provenance_repository
nifi.provenance.repository.directory.stripe3=/mnt/disk3/ provenance_repository
nifi.content.repository.directory.stripe1=/mnt/disk4/ content_repository
nifi.content.repository.directory.stripe2=/mnt/disk5/ content_repository
nifi.content.repository.directory.stripe3=/mnt/disk6/ content_repository
nifi.flowfile.repository.directory=/mnt/disk7/ flowfile_repository
Mer information om hur du utformar för lagring med höga prestanda finns i Azure Premium Storage: design för höga prestanda.
Rapportering
NiFi innehåller en proveniensrapporteringsuppgift för Log Analytics-funktionen .
Du kan använda den här rapporteringsuppgiften för att avlasta provenienshändelser till kostnadseffektiv och varaktig långsiktig lagring. Log Analytics-funktionen innehåller ett frågegränssnitt för att visa och diagramföra enskilda händelser. Mer information om dessa frågor finns i Log Analytics-frågor senare i den här artikeln.
Du kan också använda den här uppgiften med lagring av flyktiga minnesintern provenienser. I många scenarier kan du sedan uppnå en ökning av dataflödet. Men den här metoden är riskabel om du behöver bevara händelsedata. Se till att flyktig lagring uppfyller dina hållbarhetskrav för provenienshändelser. Mer information finns i provenienslagringsplatsen i Apache NiFi-systemadministratörsguiden.
Innan du använder den här processen skapar du en Log Analytics-arbetsyta i din Azure-prenumeration. Det är bäst att konfigurera arbetsytan i samma region som din arbetsbelastning.
Så här konfigurerar du proveniensrapporteringsuppgiften:
- Öppna inställningarna för kontrollanten i NiFi.
- Välj menyn Rapporteringsuppgifter.
- Välj Skapa en ny rapporteringsaktivitet.
- Välj Azure Log Analytics-rapporteringsaktivitet.
Följande skärmbild visar egenskapsmenyn för den här rapporteringsaktiviteten:

Två egenskaper krävs:
- Log Analytics-arbetsytans ID
- Log Analytics-arbetsytenyckeln
Du hittar dessa värden i Azure Portal genom att navigera till din Log Analytics-arbetsyta.
Andra alternativ är också tillgängliga för att anpassa och filtrera de provenienshändelser som systemet skickar.
Säkerhet
Säkerhet ger garantier mot avsiktliga attacker och missbruk av dina värdefulla data och system. Mer information finns i Översikt över säkerhetspelare.
Du kan skydda NiFi från autentiserings - och auktoriseringssynpunkt . Du kan också skydda NiFi för all nätverkskommunikation, inklusive:
- I klustret.
- Mellan klustret och ZooKeeper.
Mer information om hur du aktiverar följande alternativ finns i Guiden för Apache NiFi-administratörer:
- Kerberos
- Lightweight Directory Access Protocol (LDAP)
- Certifikatbaserad autentisering och auktorisering
- Tvåvägs SSL (Secure Sockets Layer) för klusterkommunikation
Om du aktiverar Säker klientåtkomst för ZooKeeper konfigurerar du NiFi genom att lägga till relaterade egenskaper i konfigurationsfilen bootstrap.conf . Följande konfigurationsposter innehåller ett exempel:
java.arg.18=-Dzookeeper.clientCnxnSocket=org.apache.zookeeper.ClientCnxnSocketNetty
java.arg.19=-Dzookeeper.client.secure=true
java.arg.20=-Dzookeeper.ssl.keyStore.location=/path/to/keystore.jks
java.arg.21=-Dzookeeper.ssl.keyStore.password=[KEYSTORE PASSWORD]
java.arg.22=-Dzookeeper.ssl.trustStore.location=/path/to/truststore.jks
java.arg.23=-Dzookeeper.ssl.trustStore.password=[TRUSTSTORE PASSWORD]
Allmänna rekommendationer finns i Säkerhetsbaslinjen för Linux.
Nätverkssäkerhet
När du implementerar den här lösningen bör du tänka på följande punkter om nätverkssäkerhet:
Nätverkssäkerhetsgrupper
I Azure kan du använda nätverkssäkerhetsgrupper för att begränsa nätverkstrafiken.
Vi rekommenderar en jumpbox för att ansluta till NiFi-klustret för administrativa uppgifter. Använd den här säkerhetshärdade virtuella datorn med jit-åtkomst (just-in-time) eller Azure Bastion. Konfigurera nätverkssäkerhetsgrupper för att styra hur du beviljar åtkomst till jumpboxen eller Azure Bastion. Du kan uppnå nätverksisolering och kontroll genom att använda nätverkssäkerhetsgrupper på ett omdömesgillt sätt i arkitekturens olika undernät.
Följande skärmbild visar komponenter i ett typiskt virtuellt nätverk. Den innehåller ett gemensamt undernät för jumpboxen, vm-skalningsuppsättningen och de virtuella ZooKeeper-datorerna. Den här förenklade nätverkstopologin grupperar komponenter i ett undernät. Följ organisationens riktlinjer för uppdelning av uppgifter och nätverksdesign.
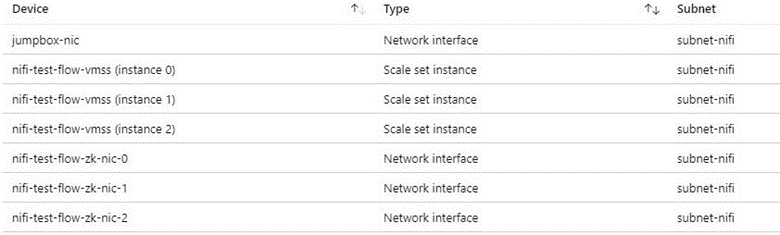
Överväganden för utgående internetåtkomst
NiFi i Azure behöver inte åtkomst till det offentliga Internet för att kunna köras. Om dataflödet inte behöver Internetåtkomst för att hämta data kan du förbättra klustrets säkerhet genom att följa dessa steg för att inaktivera utgående Internetåtkomst:
Skapa ytterligare en regel för nätverkssäkerhetsgrupp i det virtuella nätverket.
Använd de här inställningarna:
- Källa:
Any - Destination:
Internet - Handling:
Deny
- Källa:

Med den här regeln på plats kan du fortfarande komma åt vissa Azure-tjänster från dataflödet om du konfigurerar en privat slutpunkt i det virtuella nätverket. Använd Azure Private Link för det här ändamålet. Den här tjänsten är ett sätt för din trafik att färdas i Microsofts stamnätverk utan att kräva någon annan extern nätverksåtkomst. NiFi stöder för närvarande Private Link för Blob Storage- och Data Lake Storage-processorerna. Om en NTP-server (Network Time Protocol) inte är tillgänglig i ditt privata nätverk tillåter du utgående åtkomst till NTP. Detaljerad information finns i Tidssynkronisering för virtuella Linux-datorer i Azure.
Dataskydd
Det är möjligt att använda NiFi utan säkerhet, utan trådkryptering, identitets- och åtkomsthantering (IAM) eller datakryptering. Men det är bäst att skydda distributioner av produktion och offentliga moln på följande sätt:
- Kryptera kommunikation med TLS (Transport Layer Security)
- Använda en autentiserings- och auktoriseringsmekanism som stöds
- Kryptera vilande data
Azure Storage tillhandahåller transparent datakryptering på serversidan. Men från och med versionen 1.13.2 konfigurerar NiFi inte trådkryptering eller IAM som standard. Det här beteendet kan ändras i framtida versioner.
Följande avsnitt visar hur du skyddar distributioner på följande sätt:
- Aktivera trådkryptering med TLS
- Konfigurera autentisering som baseras på certifikat eller Microsoft Entra-ID
- Hantera krypterad lagring i Azure
Diskkryptering
För att förbättra säkerheten använder du Azure-diskkryptering. En detaljerad procedur finns i Kryptera operativsystem och anslutna datadiskar i en VM-skalningsuppsättning med Azure CLI. Det dokumentet innehåller också instruktioner om hur du tillhandahåller din egen krypteringsnyckel. Följande steg beskriver ett grundläggande exempel för NiFi som fungerar för de flesta distributioner:
Om du vill aktivera diskkryptering i en befintlig Key Vault-instans använder du följande Azure CLI-kommando:
az keyvault create --resource-group myResourceGroup --name myKeyVaultName --enabled-for-disk-encryptionAktivera kryptering av vm-skalningsuppsättningens datadiskar med följande kommando:
az vmss encryption enable --resource-group myResourceGroup --name myScaleSet --disk-encryption-keyvault myKeyVaultID --volume-type DATADu kan också använda en nyckelkrypteringsnyckel (KEK). Använd följande Azure CLI-kommando för att kryptera med en KEK:
az vmss encryption enable --resource-group myResourceGroup --name myScaleSet \ --disk-encryption-keyvault myKeyVaultID \ --key-encryption-keyvault myKeyVaultID \ --key-encryption-key https://<mykeyvaultname>.vault.azure.net/keys/myKey/<version> \ --volume-type DATA
Kommentar
Om du har konfigurerat vm-skalningsuppsättningen för manuellt uppdateringsläge kör update-instances du kommandot . Ta med den version av krypteringsnyckeln som du lagrade i Key Vault.
Kryptering vid överföring
NiFi stöder TLS 1.2 för kryptering under överföring. Det här protokollet ger skydd för användaråtkomst till användargränssnittet. Med kluster skyddar protokollet kommunikationen mellan NiFi-noder. Det kan också skydda kommunikationen med ZooKeeper. När du aktiverar TLS använder NiFi ömsesidig TLS (mTLS) för ömsesidig autentisering för:
- Certifikatbaserad klientautentisering om du har konfigurerat den här typen av autentisering.
- All intracluster-kommunikation.
Utför följande steg för att aktivera TLS:
Skapa ett nyckelarkiv och ett förtroendearkiv för kommunikation och autentisering mellan klient och server och intrakluster.
Konfigurera
$NIFI_HOME/conf/nifi.properties. Ange följande värden.- Värddatornamn
- Hamnar
- Egenskaper för nyckellagring
- Egenskaper för truststore
- Säkerhetsegenskaper för kluster och ZooKeeper, om tillämpligt
Konfigurera autentisering i
$NIFI_HOME/conf/authorizers.xml, vanligtvis med en första användare som har certifikatbaserad autentisering eller något annat alternativ.Du kan också konfigurera mTLS och en proxyläsningsprincip mellan NiFi och eventuella proxyservrar, lastbalanserare eller externa slutpunkter.
En fullständig genomgång finns i Skydda NiFi med TLS i Apache-projektdokumentationen.
Kommentar
Från och med version 1.13.2:
- NiFi aktiverar inte TLS som standard.
- Det finns inget out-of-the-box-stöd för anonym och enkel användaråtkomst för TLS-aktiverade NiFi-instanser.
Om du vill aktivera TLS för kryptering under överföring konfigurerar du en användargrupp och principprovider för autentisering och auktorisering i $NIFI_HOME/conf/authorizers.xml. Mer information finns i Identitets- och åtkomstkontroll senare i den här artikeln.
Certifikat, nycklar och nyckelarkiv
För att stödja TLS genererar du certifikat, lagrar dem i Java KeyStore och TrustStore och distribuerar dem över ett NiFi-kluster. Det finns två allmänna alternativ för certifikat:
- Självsignerade certifikat
- Certifikat som certifikatutfärdare signerar
Med CA-signerade certifikat är det bäst att använda en mellanliggande certifikatutfärdare för att generera certifikat för noder i klustret.
KeyStore och TrustStore är nyckel- och certifikatcontainrar i Java-plattformen. KeyStore lagrar den privata nyckeln och certifikatet för en nod i klustret. TrustStore lagrar någon av följande typer av certifikat:
- Alla betrodda certifikat för självsignerade certifikat i KeyStore
- Ett certifikat från en certifikatutfärdare för CA-signerade certifikat i KeyStore
Tänk på skalbarheten för ditt NiFi-kluster när du väljer en container. Du kanske till exempel vill öka eller minska antalet noder i ett kluster i framtiden. Välj CA-signerade certifikat i KeyStore och ett eller flera certifikat från en certifikatutfärdare i TrustStore i så fall. Med det här alternativet behöver du inte uppdatera den befintliga TrustStore i de befintliga noderna i klustret. En befintlig TrustStore litar på och accepterar certifikat från dessa typer av noder:
- Noder som du lägger till i klustret
- Noder som ersätter andra noder i klustret
NiFi-konfiguration
Om du vill aktivera TLS för NiFi använder du $NIFI_HOME/conf/nifi.properties för att konfigurera egenskaperna i den här tabellen. Se till att följande egenskaper innehåller det värdnamn som du använder för att komma åt NiFi:
nifi.web.https.hostellernifi.web.proxy.host- Värdcertifikatets avsedda namn eller alternativa ämnesnamn
Annars kan ett verifieringsfel för värdnamn eller ett verifieringsfel för HTTP HOST-huvudet leda till att du nekas åtkomst.
| Egenskapsnamn | beskrivning | Exempelvärden |
|---|---|---|
nifi.web.https.host |
Värdnamn eller IP-adress som ska användas för användargränssnittet och REST-API:et. Det här värdet bör vara internt matchbart. Vi rekommenderar att du inte använder ett offentligt tillgängligt namn. | nifi.internal.cloudapp.net |
nifi.web.https.port |
HTTPS-port som ska användas för användargränssnittet och REST-API:et. | 9443 (standard) |
nifi.web.proxy.host |
Kommaavgränsad lista över alternativa värdnamn som klienter använder för att komma åt användargränssnittet och REST-API:et. Den här listan innehåller vanligtvis alla värdnamn som anges som ett alternativt ämnesnamn (SAN) i servercertifikatet. Listan kan även innehålla alla värdnamn och portar som en lastbalanserare, proxy eller Kubernetes-ingresskontrollant använder. | 40.67.218.235, 40.67.218.235:443, nifi.westus2.cloudapp.com, nifi.westus2.cloudapp.com:443 |
nifi.security.keystore |
Sökvägen till ett JKS- eller PKCS12-nyckelarkiv som innehåller certifikatets privata nyckel. | ./conf/keystore.jks |
nifi.security.keystoreType |
Typ av nyckelarkiv. | JKS eller PKCS12 |
nifi.security.keystorePasswd |
Nyckellagringslösenordet. | O8SitLBYpCz7g/RpsqH+zM |
nifi.security.keyPasswd |
(Valfritt) Lösenordet för den privata nyckeln. | |
nifi.security.truststore |
Sökvägen till ett JKS- eller PKCS12-förtroendearkiv som innehåller certifikat eller CA-certifikat som autentiserar betrodda användare och klusternoder. | ./conf/truststore.jks |
nifi.security.truststoreType |
Typ av förtroendearkiv. | JKS eller PKCS12 |
nifi.security.truststorePasswd |
Lösenordet för truststore. | RJlpGe6/TuN5fG+VnaEPi8 |
nifi.cluster.protocol.is.secure |
Status för TLS för intraclusterkommunikation. Om nifi.cluster.is.node är trueanger du det här värdet till true för att aktivera kluster-TLS. |
true |
nifi.remote.input.secure |
Status för TLS för plats-till-plats-kommunikation. | true |
I följande exempel visas hur dessa egenskaper visas i $NIFI_HOME/conf/nifi.properties. Observera att nifi.web.http.host värdena och nifi.web.http.port är tomma.
nifi.remote.input.secure=true
nifi.web.http.host=
nifi.web.http.port=
nifi.web.https.host=nifi.internal.cloudapp.net
nifi.web.https.port=9443
nifi.web.proxy.host=40.67.218.235, 40.67.218.235:443, nifi.westus2.cloudapp.com, nifi.westus2.cloudapp.com:443
nifi.security.keystore=./conf/keystore.jks
nifi.security.keystoreType=JKS
nifi.security.keystorePasswd=O8SitLBYpCz7g/RpsqH+zM
nifi.security.keyPasswd=
nifi.security.truststore=./conf/truststore.jks
nifi.security.truststoreType=JKS
nifi.security.truststorePasswd=RJlpGe6/TuN5fG+VnaEPi8
nifi.cluster.protocol.is.secure=true
ZooKeeper-konfiguration
Anvisningar om hur du aktiverar TLS i Apache ZooKeeper för kvorumkommunikation och klientåtkomst finns i Administratörsguide för ZooKeeper. Endast version 3.5.5 eller senare stöder den här funktionen.
NiFi använder ZooKeeper för sin nollledarkluster och klustersamordning. Från och med version 1.13.0 stöder NiFi säker klientåtkomst till TLS-aktiverade instanser av ZooKeeper. ZooKeeper lagrar klustermedlemskap och klusterbegränsat processortillstånd i oformaterad text. Därför är det viktigt att använda säker klientåtkomst till ZooKeeper för att autentisera ZooKeeper-klientbegäranden. Kryptera även känsliga värden under överföring.
Om du vill aktivera TLS för NiFi-klientåtkomst till ZooKeeper anger du följande egenskaper i $NIFI_HOME/conf/nifi.properties. Om du ställer in nifi.zookeeper.client.secure true utan att konfigurera egenskaper återgår nifi.zookeeper.security NiFi till nyckelarkivet och förtroendearkivet som du anger i nifi.securityproperties.
| Egenskapsnamn | beskrivning | Exempelvärden |
|---|---|---|
nifi.zookeeper.client.secure |
Status för klientens TLS när du ansluter till ZooKeeper. | true |
nifi.zookeeper.security.keystore |
Sökvägen till ett JKS-, PKCS12- eller PEM-nyckelarkiv som innehåller den privata nyckeln för certifikatet som visas för ZooKeeper för autentisering. | ./conf/zookeeper.keystore.jks |
nifi.zookeeper.security.keystoreType |
Typ av nyckelarkiv. | JKS, PKCS12, PEMeller identifiera automatiskt med tillägg |
nifi.zookeeper.security.keystorePasswd |
Nyckellagringslösenordet. | caB6ECKi03R/co+N+64lrz |
nifi.zookeeper.security.keyPasswd |
(Valfritt) Lösenordet för den privata nyckeln. | |
nifi.zookeeper.security.truststore |
Sökvägen till ett JKS-, PKCS12- eller PEM-förtroendearkiv som innehåller certifikat eller CA-certifikat som används för att autentisera ZooKeeper. | ./conf/zookeeper.truststore.jks |
nifi.zookeeper.security.truststoreType |
Typ av förtroendearkiv. | JKS, PKCS12, PEMeller identifiera automatiskt med tillägg |
nifi.zookeeper.security.truststorePasswd |
Lösenordet för truststore. | qBdnLhsp+mKvV7wab/L4sv |
nifi.zookeeper.connect.string |
Anslutningssträng till ZooKeeper-värden eller kvorumet. Den här strängen är en kommaavgränsad lista med host:port värden. Vanligtvis är värdet secureClientPort inte detsamma som värdet clientPort . Se ZooKeeper-konfigurationen för rätt värde. |
zookeeper1.internal.cloudapp.net:2281, zookeeper2.internal.cloudapp.net:2281, zookeeper3.internal.cloudapp.net:2281 |
I följande exempel visas hur dessa egenskaper visas i $NIFI_HOME/conf/nifi.properties:
nifi.zookeeper.client.secure=true
nifi.zookeeper.security.keystore=./conf/keystore.jks
nifi.zookeeper.security.keystoreType=JKS
nifi.zookeeper.security.keystorePasswd=caB6ECKi03R/co+N+64lrz
nifi.zookeeper.security.keyPasswd=
nifi.zookeeper.security.truststore=./conf/truststore.jks
nifi.zookeeper.security.truststoreType=JKS
nifi.zookeeper.security.truststorePasswd=qBdnLhsp+mKvV7wab/L4sv
nifi.zookeeper.connect.string=zookeeper1.internal.cloudapp.net:2281,zookeeper2.internal.cloudapp.net:2281,zookeeper3.internal.cloudapp.net:2281
Mer information om hur du skyddar ZooKeeper med TLS finns i administrationsguiden för Apache NiFi.
Identitets- och åtkomstkontroll
I NiFi uppnås identitets- och åtkomstkontroll genom användarautentisering och auktorisering. För användarautentisering har NiFi flera alternativ att välja mellan: Enskild användare, LDAP, Kerberos, SAML (Security Assertion Markup Language) och OpenID Connect (OIDC). Om du inte konfigurerar ett alternativ använder NiFi klientcertifikat för att autentisera användare via HTTPS.
Om du överväger multifaktorautentisering rekommenderar vi kombinationen av Microsoft Entra ID och OIDC. Microsoft Entra ID stöder molnbaserad enkel inloggning (SSO) med OIDC. Med den här kombinationen kan användarna dra nytta av många säkerhetsfunktioner för företag:
- Loggning och aviseringar om misstänkta aktiviteter från användarkonton
- Övervakningsförsök för åtkomst till inaktiverade autentiseringsuppgifter
- Aviseringar om ovanligt kontoinloggningsbeteende
För auktorisering tillhandahåller NiFi tillämpning som baseras på användar-, grupp- och åtkomstprinciper. NiFi tillhandahåller den här tillämpningen via UserGroupProviders och AccessPolicyProviders. Som standard inkluderar leverantörerna File, LDAP, Shell och Azure Graph-baserade UserGroupProviders. Med AzureGraphUserGroupProvider kan du hämta användargrupper från Microsoft Entra-ID. Du kan sedan tilldela principer till dessa grupper. Konfigurationsinstruktioner finns i administrationsguiden för Apache NiFi.
AccessPolicyProviders som baseras på filer och Apache Ranger är för närvarande tillgängliga för hantering och lagring av användar- och grupprinciper. Detaljerad information finns i Apache NiFi-dokumentationen och Apache Ranger-dokumentationen.
Programgateway
En programgateway tillhandahåller en hanterad layer-7-lastbalanserare för NiFi-gränssnittet. Konfigurera programgatewayen så att den använder vm-skalningsuppsättningen för NiFi-noderna som serverdelspool.
För de flesta NiFi-installationer rekommenderar vi följande Application Gateway-konfiguration :
- Nivå: Standard
- SKU-storlek: medel
- Antal instanser: två eller fler
Använd en hälsoavsökning för att övervaka hälsotillståndet för webbservern på varje nod. Ta bort noder som inte är felfria från lastbalanserarens rotation. Den här metoden gör det enklare att visa användargränssnittet när det övergripande klustret är felfritt. Webbläsaren dirigerar dig bara till noder som för närvarande är felfria och svarar på begäranden.
Det finns två viktiga hälsoavsökningar att överväga. Tillsammans ger de ett regelbundet pulsslag på den övergripande hälsan för varje nod i klustret. Konfigurera den första hälsoavsökningen så att den pekar på sökvägen /NiFi. Den här avsökningen avgör hälsotillståndet för NiFi-användargränssnittet på varje nod. Konfigurera en andra hälsoavsökning för sökvägen /nifi-api/controller/cluster. Den här avsökningen anger om varje nod för närvarande är felfri och ansluten till det övergripande klustret.
Du har två alternativ för att konfigurera klientdels-IP-adressen för programgatewayen:
- Med en offentlig IP-adress
- Med ett privat undernäts IP-adress
Inkludera endast en offentlig IP-adress om användarna behöver komma åt användargränssnittet via det offentliga Internet. Om offentlig internetåtkomst för användare inte krävs kan du komma åt lastbalanserarens klientdel från en jumpbox i det virtuella nätverket eller genom peering till ditt privata nätverk. Om du konfigurerar programgatewayen med en offentlig IP-adress rekommenderar vi att du aktiverar klientcertifikatautentisering för NiFi och aktiverar TLS för NiFi-användargränssnittet. Du kan också använda en nätverkssäkerhetsgrupp i undernätet för delegerad programgateway för att begränsa källans IP-adresser.
Diagnostik och hälsoövervakning
I diagnostikinställningarna för Application Gateway finns det ett konfigurationsalternativ för att skicka mått och åtkomstloggar. Med det här alternativet kan du skicka den här informationen från lastbalanseraren till olika platser:
- Ett lagringskonto
- Event Hubs
- En Log Analytics-arbetsyta
Att aktivera den här inställningen är användbart för felsökning av problem med belastningsutjämning och för att få insikt i hälsotillståndet för klusternoder.
Följande Log Analytics-fråga visar klusternodens hälsa över tid ur ett Application Gateway-perspektiv. Du kan använda en liknande fråga för att generera aviseringar eller automatiserade reparationsåtgärder för noder som inte är felfria.
AzureDiagnostics
| summarize UnHealthyNodes = max(unHealthyHostCount_d), HealthyNodes = max(healthyHostCount_d) by bin(TimeGenerated, 5m)
| render timechart
Följande diagram över frågeresultatet visar en tidsvy över klustrets hälsotillstånd:

Tillgänglighet
När du implementerar den här lösningen bör du tänka på följande punkter om tillgänglighet:
Lastbalanserare
Använd en lastbalanserare för användargränssnittet för att öka användargränssnittets tillgänglighet under nodavbrott.
Separata virtuella datorer
Om du vill öka tillgängligheten distribuerar du ZooKeeper-klustret på separata virtuella datorer från de virtuella datorerna i NiFi-klustret. Mer information om hur du konfigurerar ZooKeeper finns i Tillståndshantering i Apache NiFi-systemadministratörsguiden.
Tillgänglighetszoner
Distribuera både vm-skalningsuppsättningen NiFi och ZooKeeper-klustret i en konfiguration mellan zoner för att maximera tillgängligheten. När kommunikationen mellan noderna i klustret korsar tillgänglighetszonerna introduceras en liten fördröjning. Men den här svarstiden har vanligtvis en minimal övergripande effekt på klustrets dataflöde.
Skalningsuppsättningar för virtuella datorer
Vi rekommenderar att du distribuerar NiFi-noderna till en enda vm-skalningsuppsättning som sträcker sig över tillgänglighetszoner där de är tillgängliga. Detaljerad information om hur du använder skalningsuppsättningar på det här sättet finns i Skapa en VM-skalningsuppsättning som använder Tillgänglighetszoner.
Övervakning
Om du vill övervaka hälsotillståndet och prestandan för ett NiFi-kluster använder du rapporteringsuppgifter.
Rapporteringsaktivitetsbaserad övervakning
För övervakning kan du använda en rapporteringsuppgift som du konfigurerar och kör i NiFi. Som diagnostik- och hälsoövervakning diskuterar tillhandahåller Log Analytics en rapporteringsuppgift i NiFi Azure-paketet. Du kan använda den rapporteringsuppgiften för att integrera övervakningen med Log Analytics och befintliga övervaknings- eller loggningssystem.
Log Analytics-frågor
Exempelfrågor i följande avsnitt kan hjälpa dig att komma igång. En översikt över hur du kör frågor mot Log Analytics-data finns i Azure Monitor-loggfrågor.
Loggfrågor i Monitor och Log Analytics använder en version av Kusto-frågespråk. Men det finns skillnader mellan loggfrågor och Kusto-frågor. Mer information finns i Kusto-frågeöversikt.
Mer strukturerad utbildning finns i de här självstudierna:
Log Analytics-rapporteringsaktivitet
Som standard skickar NiFi måttdata till nifimetrics tabellen. Men du kan konfigurera ett annat mål i rapportaktivitetens egenskaper. Rapporteringsaktiviteten samlar in följande NiFi-mått:
| Måtttyp | Måttnamn |
|---|---|
| NiFi-mått | FlowFilesReceived |
| NiFi-mått | FlowFilesSent |
| NiFi-mått | FlowFilesQueued |
| NiFi-mått | BytesReceived |
| NiFi-mått | BytesWritten |
| NiFi-mått | BytesRead |
| NiFi-mått | BytesSent |
| NiFi-mått | BytesQueued |
| Mått för portstatus | InputCount |
| Mått för portstatus | InputBytes |
| Mått för anslutningsstatus | QueuedCount |
| Mått för anslutningsstatus | QueuedBytes |
| Mått för portstatus | OutputCount |
| Mått för portstatus | OutputBytes |
| Mått för virtuella Java-datorer (JVM) | jvm.uptime |
| JVM-mått | jvm.heap_used |
| JVM-mått | jvm.heap_usage |
| JVM-mått | jvm.non_heap_usage |
| JVM-mått | jvm.thread_states.runnable |
| JVM-mått | jvm.thread_states.blocked |
| JVM-mått | jvm.thread_states.timed_waiting |
| JVM-mått | jvm.thread_states.terminated |
| JVM-mått | jvm.thread_count |
| JVM-mått | jvm.daemon_thread_count |
| JVM-mått | jvm.file_descriptor_usage |
| JVM-mått | jvm.gc.runs jvm.gc.runs.g1_old_generation jvm.gc.runs.g1_young_generation |
| JVM-mått | jvm.gc.time jvm.gc.time.g1_young_generation jvm.gc.time.g1_old_generation |
| JVM-mått | jvm.buff_pool_direct_capacity |
| JVM-mått | jvm.buff_pool_direct_count |
| JVM-mått | jvm.buff_pool_direct_mem_used |
| JVM-mått | jvm.buff_pool_mapped_capacity |
| JVM-mått | jvm.buff_pool_mapped_count |
| JVM-mått | jvm.buff_pool_mapped_mem_used |
| JVM-mått | jvm.mem_pool_code_cache |
| JVM-mått | jvm.mem_pool_compressed_class_space |
| JVM-mått | jvm.mem_pool_g1_eden_space |
| JVM-mått | jvm.mem_pool_g1_old_gen |
| JVM-mått | jvm.mem_pool_g1_survivor_space |
| JVM-mått | jvm.mem_pool_metaspace |
| JVM-mått | jvm.thread_states.new |
| JVM-mått | jvm.thread_states.waiting |
| Mått på processornivå | BytesRead |
| Mått på processornivå | BytesWritten |
| Mått på processornivå | FlowFilesReceived |
| Mått på processornivå | FlowFilesSent |
Här är en exempelfråga för måttet för BytesQueued ett kluster:
let table_name = nifimetrics_CL;
let metric = "BytesQueued";
table_name
| where Name_s == metric
| where Computer contains {ComputerName}
| project TimeGenerated, Computer, ProcessGroupName_s, Count_d, Name_s
| summarize sum(Count_d) by bin(TimeGenerated, 1m), Computer, Name_s
| render timechart
Frågan genererar ett diagram som det i den här skärmbilden:

Kommentar
När du kör NiFi i Azure är du inte begränsad till Log Analytics-rapporteringsaktiviteten. NiFi stöder rapporteringsuppgifter för många övervakningstekniker från tredje part. En lista över rapporteringsuppgifter som stöds finns i avsnittet Rapporteringsuppgifter i Apache NiFi-dokumentationsindexet.
Övervakning av NiFi-infrastruktur
Förutom rapporteringsaktiviteten installerar du Log Analytics VM-tillägget på noderna NiFi och ZooKeeper. Det här tillägget samlar in loggar, ytterligare mått på VM-nivå och mått från ZooKeeper.
Anpassade loggar för NiFi-appen, användaren, bootstrap och ZooKeeper
Följ dessa steg för att samla in fler loggar:
I Azure Portal väljer du Log Analytics-arbetsytor och sedan din arbetsyta.
Under Inställningar väljer du Anpassade loggar.

Välj Lägg till anpassad logg.
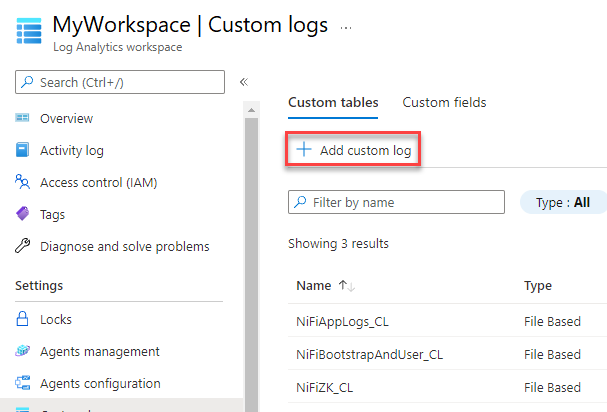
Konfigurera en anpassad logg med följande värden:
- Namn:
NiFiAppLogs - Sökvägstyp:
Linux - Sökvägsnamn:
/opt/nifi/logs/nifi-app.log

- Namn:
Konfigurera en anpassad logg med följande värden:
- Namn:
NiFiBootstrapAndUser - Första sökvägstypen:
Linux - Förnamn för sökväg:
/opt/nifi/logs/nifi-user.log - Andra sökvägstypen:
Linux - Andra sökvägens namn:
/opt/nifi/logs/nifi-bootstrap.log

- Namn:
Konfigurera en anpassad logg med följande värden:
- Namn:
NiFiZK - Sökvägstyp:
Linux - Sökvägsnamn:
/opt/zookeeper/logs/*.out

- Namn:
Här är en exempelfråga i den NiFiAppLogs anpassade tabellen som det första exemplet skapade:
NiFiAppLogs_CL
| where TimeGenerated > ago(24h)
| where Computer contains {ComputerName} and RawData contains "error"
| limit 10
Den frågan ger resultat som liknar följande resultat:

Konfiguration av infrastrukturlogg
Du kan använda Övervaka för att övervaka och hantera virtuella datorer eller fysiska datorer. Dessa resurser kan finnas i ditt lokala datacenter eller i en annan molnmiljö. Om du vill konfigurera den här övervakningen distribuerar du Log Analytics-agenten. Konfigurera agenten att rapportera till en Log Analytics-arbetsyta. Mer information finns i Översikt över Log Analytics-agenten.
Följande skärmbild visar en exempelagentkonfiguration för virtuella NiFi-datorer. Tabellen Perf lagrar insamlade data.

Här är en exempelfråga för NiFi-apploggarna Perf :
let cluster_name = {ComputerName};
// The hourly average of CPU usage across all computers.
Perf
| where Computer contains {ComputerName}
| where CounterName == "% Processor Time" and InstanceName == "_Total"
| where ObjectName == "Processor"
| summarize CPU_Time_Avg = avg(CounterValue) by bin(TimeGenerated, 30m), Computer
Frågan genererar en rapport som den i den här skärmbilden:

Aviseringar
Använd Monitor för att skapa aviseringar om hälsotillstånd och prestanda för NiFi-klustret. Exempelaviseringar är:
- Det totala antalet köer har överskridit ett tröskelvärde.
- Värdet
BytesWrittenligger under ett förväntat tröskelvärde. - Värdet
FlowFilesReceivedligger under ett tröskelvärde. - Klustret är inte felfri.
Mer information om hur du konfigurerar aviseringar i Monitor finns i Översikt över aviseringar i Microsoft Azure.
Konfigurationsparametrar
I följande avsnitt beskrivs rekommenderade konfigurationer som inte är standard för NiFi och dess beroenden, inklusive ZooKeeper och Java. De här inställningarna passar för klusterstorlekar som är möjliga i molnet. Ange egenskaperna i följande konfigurationsfiler:
$NIFI_HOME/conf/nifi.properties$NIFI_HOME/conf/bootstrap.conf$ZOOKEEPER_HOME/conf/zoo.cfg$ZOOKEEPER_HOME/bin/zkEnv.sh
Detaljerad information om tillgängliga konfigurationsegenskaper och filer finns i Administratörsguide för Apache NiFi-system och Administratörsguide för ZooKeeper.
NiFi
För en Azure-distribution bör du överväga att justera egenskaper i $NIFI_HOME/conf/nifi.properties. I följande tabell visas de viktigaste egenskaperna. Fler rekommendationer och insikter finns i Apache NiFi-e-postlistorna.
| Parameter | Description | Standard | Rekommendation |
|---|---|---|---|
nifi.cluster.node.connection.timeout |
Hur länge du ska vänta när du öppnar en anslutning till andra klusternoder. | 5 sekunder | 60 sekunder |
nifi.cluster.node.read.timeout |
Hur lång tid det tar att vänta på ett svar när du skickar en begäran till andra klusternoder. | 5 sekunder | 60 sekunder |
nifi.cluster.protocol.heartbeat.interval |
Hur ofta du skickar tillbaka pulsslag till klusterkoordinatorn. | 5 sekunder | 60 sekunder |
nifi.cluster.node.max.concurrent.requests |
Vilken parallellitetsnivå som ska användas vid replikering av HTTP-anrop som REST API-anrop till andra klusternoder. | 100 | 500 |
nifi.cluster.node.protocol.threads |
Ursprunglig storlek på trådpoolen för kommunikation mellan kluster/replikerade. | 10 | 50 |
nifi.cluster.node.protocol.max.threads |
Maximalt antal trådar som ska användas för kommunikation mellan kluster/replikerade. | 50 | 75 |
nifi.cluster.flow.election.max.candidates |
Antal noder som ska användas när du bestämmer vad det aktuella flödet är. Det här värdet kortsluter omröstningen med det angivna talet. | empty | 75 |
nifi.cluster.flow.election.max.wait.time |
Hur lång tid det är att vänta på noder innan du bestämmer vad det aktuella flödet är. | 5 minuter | 5 minuter |
Klusterbeteende
Tänk på följande när du konfigurerar kluster.
Timeout
För att säkerställa det övergripande hälsotillståndet för ett kluster och dess noder kan det vara fördelaktigt att öka tidsgränserna. Den här metoden hjälper till att garantera att fel inte beror på tillfälliga nätverksproblem eller höga belastningar.
I ett distribuerat system varierar prestandan för enskilda system. Den här varianten omfattar nätverkskommunikation och svarstid, vilket vanligtvis påverkar kommunikation mellan noder och mellan kluster. Nätverksinfrastrukturen eller själva systemet kan orsaka den här variationen. Därför är sannolikheten för variation mycket sannolik i stora systemkluster. I Java-program under belastning kan pauser i skräpinsamling (GC) på den virtuella Java-datorn (JVM) också påverka svarstiderna för begäranden.
Använd egenskaper i följande avsnitt för att konfigurera tidsgränser som passar systemets behov:
nifi.cluster.node.connection.timeout och nifi.cluster.node.read.timeout
Egenskapen nifi.cluster.node.connection.timeout anger hur länge du ska vänta när du öppnar en anslutning. Egenskapen nifi.cluster.node.read.timeout anger hur länge du ska vänta när du tar emot data mellan begäranden. Standardvärdet för varje egenskap är fem sekunder. Dessa egenskaper gäller för nod-till-nod-begäranden. Genom att öka dessa värden kan du lösa flera relaterade problem:
- Kopplas från av klusterkoordinatorn på grund av pulsslagsavbrott
- Det gick inte att hämta flödet från koordinatorn när klustret anslöts
- Upprätta plats-till-plats (S2S) och belastningsutjämningskommunikation
Om inte klustret har en mycket liten skalningsuppsättning, till exempel tre noder eller färre, använder du värden som är större än standardvärdena.
nifi.cluster.protocol.heartbeat.interval
Som en del av NiFi-klustringsstrategin genererar varje nod ett pulsslag för att kommunicera dess felfria status. Som standard skickar noder pulsslag var femte sekund. Om klusterkoordinatorn upptäcker att åtta pulsslag på en rad från en nod har misslyckats kopplar den bort noden. Öka det intervall som anges i nifi.cluster.protocol.heartbeat.interval egenskapen för att hantera långsamma pulsslag och förhindra att klustret kopplar från noder i onödan.
Samtidighet
Använd egenskaper i följande avsnitt för att konfigurera samtidighetsinställningar:
nifi.cluster.node.protocol.threads och nifi.cluster.node.protocol.max.threads
Egenskapen nifi.cluster.node.protocol.max.threads anger det maximala antalet trådar som ska användas för allklusterkommunikation, till exempel S2S-belastningsutjämning och UI-sammansättning. Standardvärdet för den här egenskapen är 50 trådar. För stora kluster ökar du det här värdet för att ta hänsyn till det större antalet begäranden som dessa åtgärder kräver.
Egenskapen nifi.cluster.node.protocol.threads avgör den ursprungliga storleken på trådpoolen. Standardvärdet är 10 trådar. Det här värdet är ett minimum. Den växer efter behov upp till den maximala uppsättningen i nifi.cluster.node.protocol.max.threads. nifi.cluster.node.protocol.threads Öka värdet för kluster som använder en storskalig uppsättning vid start.
nifi.cluster.node.max.concurrent.requests
Många HTTP-begäranden som REST API-anrop och UI-anrop måste replikeras till andra noder i klustret. I takt med att klustrets storlek växer replikeras allt fler begäranden. Egenskapen nifi.cluster.node.max.concurrent.requests begränsar antalet utestående begäranden. Dess värde bör överskrida den förväntade klusterstorleken. Standardvärdet är 100 samtidiga begäranden. Om du inte kör ett litet kluster med tre eller färre noder kan du förhindra misslyckade begäranden genom att öka det här värdet.
Flödesval
Använd egenskaper i följande avsnitt för att konfigurera inställningar för flödesval:
nifi.cluster.flow.election.max.candidates
NiFi använder zero-leader-klustring, vilket innebär att det inte finns någon specifik auktoritativ nod. Därför röstar noder om vilken flödesdefinition som räknas som rätt. De röstar också för att bestämma vilka noder som ska ansluta till klustret.
Som standard är egenskapen nifi.cluster.flow.election.max.candidates den maximala väntetid som nifi.cluster.flow.election.max.wait.time egenskapen anger. När det här värdet är för högt kan det ta lång tid att starta. Standardvärdet för nifi.cluster.flow.election.max.wait.time är fem minuter. Ange det maximala antalet kandidater till ett icke-tomt värde som 1 eller större för att säkerställa att väntetiden inte längre än behövs. Om du anger den här egenskapen tilldelar du den ett värde som motsvarar klusterstorleken eller någon majoritetsfraktion av den förväntade klusterstorleken. För små, statiska kluster med 10 eller färre noder anger du det här värdet till antalet noder i klustret.
nifi.cluster.flow.election.max.wait.time
I en elastisk molnmiljö påverkar tiden för etablering av värdar programmets starttid. Egenskapen nifi.cluster.flow.election.max.wait.time avgör hur länge NiFi väntar innan du bestämmer dig för ett flöde. Gör det här värdet i proportion till den totala starttiden för klustret vid dess startstorlek. Vid inledande testning är fem minuter mer än tillräckliga i alla Azure-regioner med de rekommenderade instanstyperna. Men du kan öka det här värdet om tiden för att etablera regelbundet överskrider standardvärdet.
Java
Vi rekommenderar att du använder en LTS-version av Java. Av dessa versioner är Java 11 något bättre än Java 8 eftersom Java 11 stöder en snabbare implementering av skräpinsamling. Det är dock möjligt att ha en högpresterande NiFi-distribution med hjälp av någon av versionerna.
I följande avsnitt beskrivs vanliga JVM-konfigurationer som ska användas när du kör NiFi. Ange JVM-parametrar i bootstrap-konfigurationsfilen på $NIFI_HOME/conf/bootstrap.conf.
Skräpinsamlare
Om du kör Java 11 rekommenderar vi att du använder G1-skräpinsamlaren (G1GC) i de flesta situationer. G1GC har bättre prestanda jämfört med ParallelGC eftersom G1GC minskar längden på GC-pauser. G1GC är standard i Java 11, men du kan konfigurera det explicit genom att ange följande värde i bootstrap.conf:
java.arg.13=-XX:+UseG1GC
Om du kör Java 8 ska du inte använda G1GC. Använd ParallelGC i stället. Det finns brister i Java 8-implementeringen av G1GC som hindrar dig från att använda den med de rekommenderade implementeringarna av lagringsplatsen. ParallelGC är långsammare än G1GC. Men med ParallelGC kan du fortfarande ha en högpresterande NiFi-distribution med Java 8.
Heap
En uppsättning egenskaper i bootstrap.conf filen avgör konfigurationen av NiFi JVM-heapen. För ett standardflöde konfigurerar du en heap på 32 GB med hjälp av följande inställningar:
java.arg.3=-Xmx32g
java.arg.2=-Xms32g
Om du vill välja den optimala heapstorleken som ska tillämpas på JVM-processen bör du överväga två faktorer:
- Dataflödets egenskaper
- Det sätt som NiFi använder minne i sin bearbetning
Detaljerad dokumentation finns i Apache NiFi på djupet.
Gör heapen bara så stor som behövs för att uppfylla bearbetningskraven. Den här metoden minimerar längden på GC-pauser. Allmänna överväganden för Java-skräpinsamling finns i justeringsguiden för skräpinsamling för din version av Java.
När du justerar JVM-minnesinställningarna bör du tänka på följande viktiga faktorer:
Antalet FlowFiles- eller NiFi-dataposter som är aktiva under en viss period. Det här talet inkluderar bakåttryckta eller köade FlowFiles.
Antalet attribut som definieras i FlowFiles.
Mängden minne som en processor behöver för att bearbeta ett visst innehåll.
Hur en processor bearbetar data:
- Strömma data
- Använda postorienterade processorer
- Lagra alla data i minnet samtidigt
Den här informationen är viktig. Under bearbetningen innehåller NiFi referenser och attribut för varje FlowFile i minnet. Vid högsta prestanda är mängden minne som systemet använder proportionellt mot antalet Live FlowFiles och alla attribut som de innehåller. Det här numret innehåller FlowFiles i kö. NiFi kan växla till disk. Men undvik det här alternativet eftersom det skadar prestanda.
Tänk också på grundläggande minnesanvändning för objekt. Mer specifikt gör du din hög tillräckligt stor för att lagra objekt i minnet. Tänk på de här tipsen för att konfigurera minnesinställningarna:
- Kör flödet med representativa data och minimalt bakåttryck genom att börja med inställningen
-Xmx4Goch sedan öka minnet efter behov. - Kör ditt flöde med representativa data och hög belastning genom att börja med inställningen
-Xmx4Goch sedan öka klusterstorleken konservativt efter behov. - Profilera programmet medan flödet körs med hjälp av verktyg som VisualVM och YourKit.
- Om konservativa ökningar av heap inte förbättrar prestanda avsevärt kan du överväga att ändra designen av flöden, processorer och andra aspekter av systemet.
Ytterligare JVM-parametrar
I följande tabell visas ytterligare JVM-alternativ. Den innehåller också de värden som fungerade bäst vid inledande testning. Tester observerade GC-aktivitet och minnesanvändning och använde noggrann profilering.
| Parameter | Description | JVM-standard | Rekommendation |
|---|---|---|---|
InitiatingHeapOccupancyPercent |
Mängden heap som används innan en markeringscykel utlöses. | 45 | 35 |
ParallelGCThreads |
Antalet trådar som GC använder. Det här värdet är begränsat för att begränsa den övergripande effekten på systemet. | 5/8 av antalet virtuella processorer | 8 |
ConcGCThreads |
Antalet GC-trådar som ska köras parallellt. Det här värdet ökas för att ta hänsyn till begränsade ParallelGCThreads. | 1/4 av ParallelGCThreads värdet |
4 |
G1ReservePercent |
Procentandelen reserverat minne som ska hållas ledigt. Det här värdet ökas för att undvika överbelastning i rymden, vilket hjälper till att undvika fullständig GC. | 10 | 20 |
UseStringDeduplication |
Om du vill försöka identifiera och avduplicera referenser till identiska strängar. Om du aktiverar den här funktionen kan det leda till minnesbesparingar. | - | gåva |
Konfigurera de här inställningarna genom att lägga till följande poster i NiFi bootstrap.conf:
java.arg.17=-XX:+UseStringDeduplication
java.arg.18=-XX:G1ReservePercent=20
java.arg.19=-XX:ParallelGCThreads=8
java.arg.20=-XX:ConcGCThreads=4
java.arg.21=-XX:InitiatingHeapOccupancyPercent=35
ZooKeeper
För förbättrad feltolerans kör du ZooKeeper som ett kluster. Använd den här metoden även om de flesta NiFi-distributioner lägger en relativt blygsam belastning på ZooKeeper. Aktivera klustring för ZooKeeper explicit. Som standard körs ZooKeeper i enserverläge. Detaljerad information finns i Konfiguration av klustrade (flera servrar) i ZooKeeper-administratörsguiden.
Förutom inställningarna för klustring använder du standardvärden för din ZooKeeper-konfiguration.
Om du har ett stort NiFi-kluster kan du behöva använda ett större antal ZooKeeper-servrar. För mindre klusterstorlekar räcker det med mindre VM-storlekar och Standard SSD-hanterade diskar.
Deltagare
Den här artikeln underhålls av Microsoft. Det har ursprungligen skrivits av följande medarbetare.
Huvudförfattare:
- Muazma Zahid | Huvudansvarig PM Manager
Om du vill se icke-offentliga LinkedIn-profiler loggar du in på LinkedIn.
Nästa steg
Materialet och rekommendationerna i det här dokumentet kom från flera källor:
- Experimenterande
- Metodtips för Azure
- NiFi community knowledge, best practices och dokumentation
Mer information finns i följande resurser:
- Apache NiFi-systemadministratörsguide
- Apache NiFi-e-postlistor
- Metodtips för Cloudera för att konfigurera en högpresterande NiFi-installation
- Azure Premium Storage: design för höga prestanda
- Felsök prestanda för virtuella Azure-datorer i Linux eller Windows