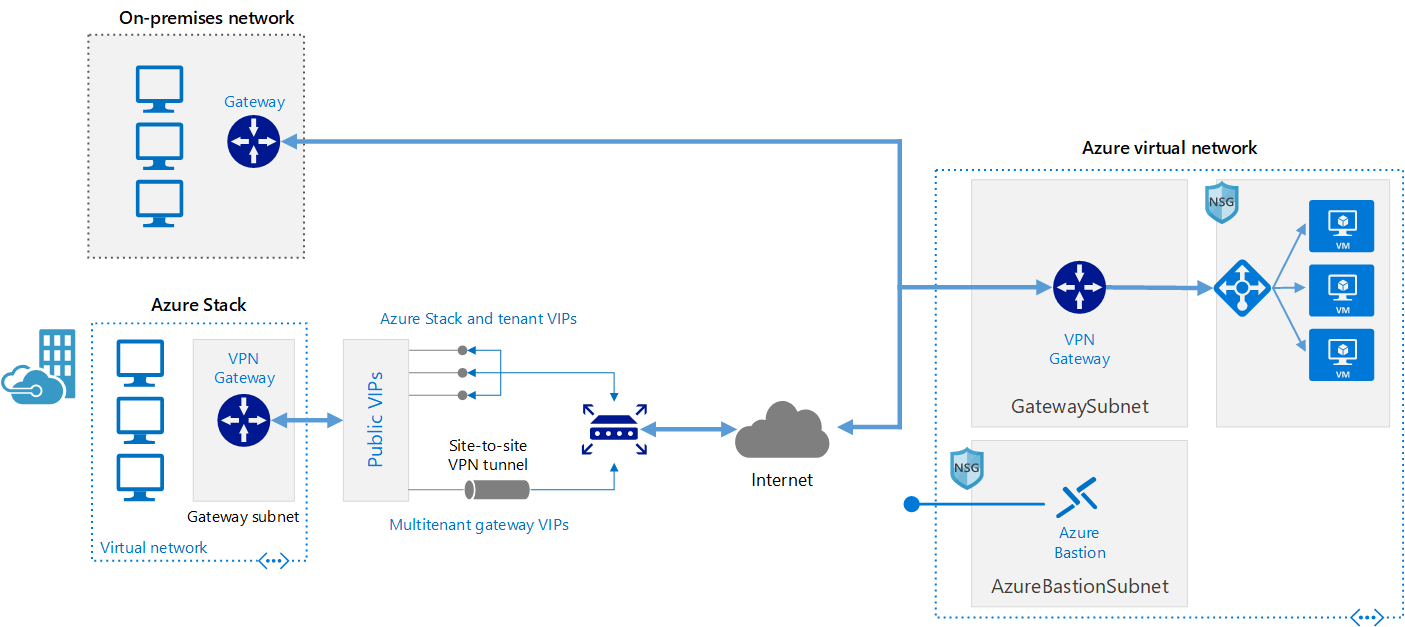
Ansluta ett lokalt nätverk till Azure med en VPN-gateway
Den här referensarkitekturen visar hur ett lokalt nätverk kan utökas till Azure, via ett VPN mellan platserna.
Den här webbläsaren stöds inte längre.
Uppgradera till Microsoft Edge för att dra nytta av de senaste funktionerna, säkerhetsuppdateringarna och teknisk support.
Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Databehandling med höga prestanda (HPC), även kallat big compute, använder ett stort antal PROCESSOR- eller GPU-baserade datorer för att lösa komplexa matematiska uppgifter.
HPC används inom många branscher för att lösa svåraste problem. Det kan vara arbetsbelastningar som:
En av de främsta skillnaderna mellan ett lokalt HPC-system och ett i molnet är möjligheten för resurser att dynamiskt läggas till och tas bort när de behövs. Med dynamisk skalning är beräkningskapaciteten inte längre en flaskhals, utan kunderna kan storleksanpassa sin infrastruktur efter verksamhetens behov.
I följande artiklar finns mer information om funktionen för dynamisk skalning.
När du vill implementera en egen HPC-lösning i Azure kontrollerar du att du har gått igenom följande avsnitt:
Det finns många infrastrukturkomponenter som krävs för att skapa ett HPC-system. Beräkning, lagring och nätverk tillhandahåller de underliggande komponenterna, oavsett hur du väljer att hantera dina HPC-arbetsbelastningar.
Azure erbjuder flera olika storlekar som är optimerade för både CPU- och GPU-intensiva arbetsbelastningar.
Virtuella datorer i N-serien har NVIDIA-grafikprocessorer för beräknings- och grafikintensiva program som artificiell intelligens (AI) och visualisering.
Storskaliga Batch- och HPC-arbetsbelastningar ställer stora krav på datalagring och åtkomst, som överskrider funktionerna i traditionella molnfilsystem. Det finns många lösningar som hanterar både hastighets- och kapacitetsbehoven för HPC-program i Azure:
Mer information om hur du jämför Lustre, GlusterFS och BeeGFS i Azure finns i e-boken Parallel Files Systems on Azure (Parallella filsystem i Azure ) och Lustre på Azure-bloggen .
Virtuella datorer av modellerna H16r, H16mr, A8 och A9 kan ansluta till ett RDMA-nätverk med hög bandbredd. Det här nätverket kan förbättra prestandan för tätt kopplade parallella program som körs under Microsoft Message Passing Interface, mer känt som MPI eller Intel MPI.
Att skapa ett HPC-system från grunden i Azure ger en betydande flexibilitet, men det är ofta mycket underhållsintensivt.
Om du har ett befintligt lokalt HPC-system som du vill ansluta till Azure finns det flera resurser som hjälper dig att komma igång.
Läs först artikeln om alternativ för att ansluta ett lokalt nätverk till Azure i dokumentationen. Därifrån hittar du ytterligare information om dessa anslutningsalternativ:
Den här referensarkitekturen visar hur ett lokalt nätverk kan utökas till Azure, via ett VPN mellan platserna.
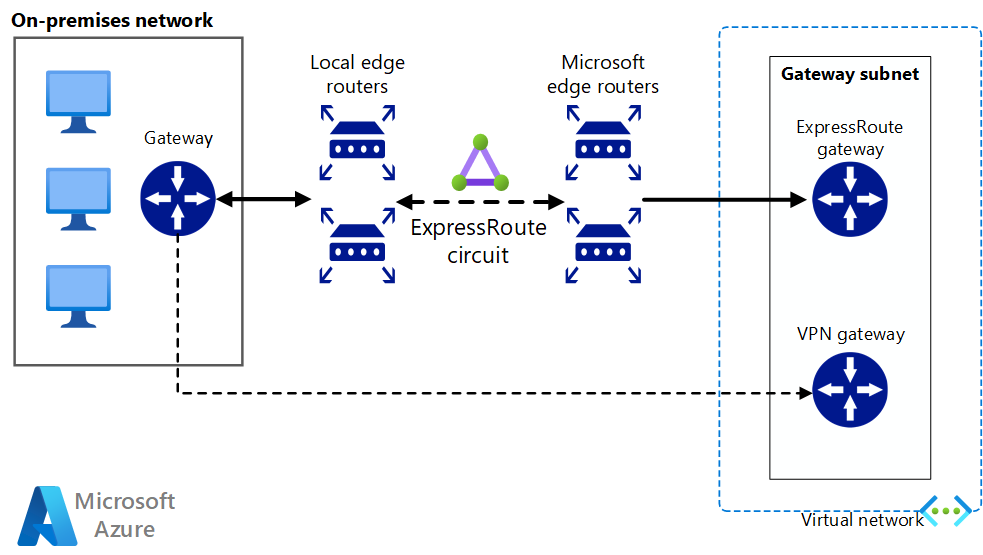
Implementera en högtillgänglig och säker nätverksarkitektur plats-till-plats som omfattar ett virtuellt Azure-nätverk och ett lokalt nätverk som är anslutna via ExpressRoute med redundansväxling via VPN-gateway.
När nätverksanslutningen har upprättats på ett säkert sätt kan du börja använda molnberäkningsresurser på begäran med bursting-funktionerna i din befintliga arbetsbelastningshanterare.
Det finns många arbetsbelastningshanterare som erbjuds på Azure Marketplace.
Azure Batch är en plattformstjänst för att köra storskaliga parallella program och HPC-program effektivt i molnet. Azure Batch schemalägger beräkningsintensivt arbete för körning i en hanterad pool med virtuella datorer. Tjänsten kan automatiskt skala beräkningsresurser efter de jobb som körs.
Leverantörer och utvecklare av SaaS kan använda SDK:erna och verktygen i Batch för att integrera HPC-program och containerarbetsbelastningar med Azure, organisera data i Azure och skapa pipelines för jobbkörning.
I Azure Batch körs alla tjänster i molnet. Följande bild visar hur arkitekturen ser ut med Azure Batch, med konfigurationer för skalbarhet och jobbschema som körs i molnet medan resultaten och rapporterna kan skickas till din lokala miljö.

Azure CycleCloud är det enklaste sättet att hantera HPC-arbetsbelastningar med valfri schemaläggare (som Slurm, Grid Engine, HPC Pack, HTCondor, LSF, PBS Pro eller Symphony) på Azure
Med CycleCloud kan du:
I det här Hybrid-exempeldiagrammet kan vi tydligt se hur dessa tjänster distribueras mellan molnet och den lokala miljön. Möjlighet att köra uppgifter inom båda arbetsbelastningar.

Följande exempeldiagram för molnbaserad modell visar hur arbetsbelastningen i molnet hanterar allt samtidigt som anslutningen till den lokala miljön bevaras.

| Funktion | Azure Batch | Azure CycleCloud |
|---|---|---|
| Schemaläggare | Batch-API:er och verktyg och kommandoradsskript i Azure Portal (molnbaserat). | Använd HPC-standardschemaläggare som Slurm, PBS Pro, LSF, Grid Engine och HTCondor eller utöka pluginprogrammen för CycleCloud-autoskalning för att arbeta med din egen schemaläggare. |
| Beräkningsresurser | Programvaru-tjänstnoder – Plattform-tjänst | Plattform som en tjänstprogramvara – Plattform som en tjänst |
| Övervaka verktyg | Azure Monitor | Azure Monitor, Grafana |
| Anpassning | Anpassade avbildningspooler, tredjepartsbilder, Batch API-åtkomst. | Använd det omfattande RESTful-API:et för att anpassa och utöka funktioner, distribuera din egen schemaläggare och stöd till befintliga arbetsbelastningshanterare |
| Integrering | Data Factory i Microsoft Fabric, Azure Data Factory, Azure CLI | Inbyggd CLI för Windows och Linux |
| Användartyp | Utvecklare | Klassiska HPC-administratörer och -användare |
| Arbetstyp | Batch, arbetsflöden | Tätt kopplat (meddelandeöverföringsgränssnitt (MPI)) |
| Windows-stöd | Ja | Varierar beroende på val av schemaläggare |
Här följer några exempel på kluster och arbetsbelastningshanterare som kan köras i Azure-infrastrukturen. Skapa fristående kluster i virtuella Azure-datorer eller utöka kapaciteten till virtuella Azure-datorer från ett lokalt kluster.
Containrar kan också användas för att hantera vissa HPC-arbetsbelastningar. Tjänster som Azure Kubernetes Service (AKS) gör det enkelt att distribuera ett hanterat Kubernetes-kluster i Azure.
Du kan hantera dina HPC-kostnader i Azure på olika sätt. Gå igenom inköpsalternativen för Azure för att hitta den metod som passar bäst för din organisation.
En översikt över säkerhetsmetoder i Azure finns i dokumentationen om Azure Security.
Förutom de nätverkskonfigurationer som är tillgängliga i avsnittet Cloud Bursting kan du implementera en hubb-/ekerkonfiguration för att isolera dina beräkningsresurser:

Hubben är ett virtuellt nätverk (VNet) i Azure som fungerar som en central anslutningspunkt till det lokala nätverket. ekrarna är virtuella nätverk som kopplas ihop med hubben och som kan användas för att isolera arbeten.
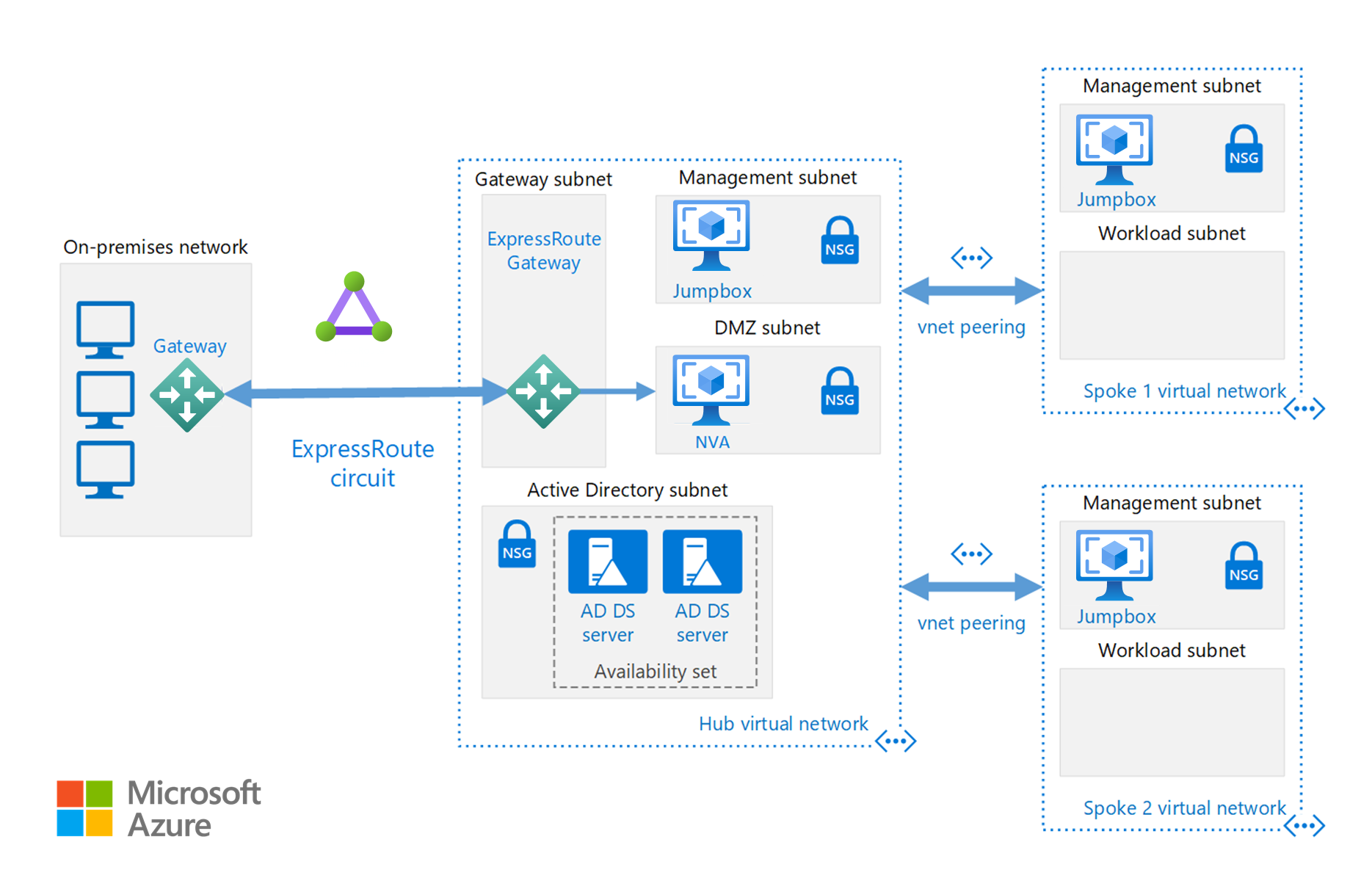
Denna referensarkitektur bygger på hub-spoke-arkitekturen för att inkludera delade tjänster i hubben som kan användas av alla ekrar.
Köra anpassade eller kommersiella HPC-program i Azure. Flera av exemplen in det här avsnittet är testade för effektiv skalning med fler virtuella datorer eller beräkningskärnor. Distributionsfärdiga lösningar finns på Azure Marketplace.
Kommentar
Fråga leverantören av kommersiella program om licensiering krävs eller om det finns andra begränsningar för körning i molnet. Alla leverantörer erbjuder inte licensiering enligt modellen Betala per användning. Du kan behöva ha en licensserver i molnet för din lösning eller ansluta till en lokal licensserver.
Kör GPU-baserade virtuella datorer i Azure i samma region som HPC-utdata för lägsta svarstid, åtkomst och för att visualisera via Azure Virtual Desktop.
De senaste meddelandena finns i följande resurser:
I de här handledningarna får du detaljer om hur du kör program på Microsoft Batch.
