Apache Kafka-migrering till Azure
Apache Kafka är ett mycket skalbart och feltolerant distribuerat meddelandesystem som implementerar en publiceringsprenumereringsarkitektur. Det används som ett inmatningslager i realtidsströmningsscenarier, till exempel Sakernas Internet och övervakningssystem för realtidsloggar. Det används också i allt högre grad som det oföränderliga tilläggsdatalagret i Kappa-arkitekturer.
Apache®, Apache Spark®, Apache Hadoop®, Apache HBase, Apache Storm®, Apache Sqoop®, Apache Kafka® och flamlogotypen är antingen registrerade varumärken eller varumärken som tillhör Apache Software Foundation i USA och/eller andra länder. Inget godkännande från Apache Software Foundation underförstås av användningen av dessa märken.
Migreringsmetod
I den här artikeln beskrivs olika strategier för migrering av Kafka till Azure:
- Migrera Kafka till Azures infrastruktur som en tjänst (IaaS)
- Migrera Kafka till Azure Event Hubs för Kafka
- Migrera Kafka på Azure HDInsight
- Använda Azure Kubernetes Service (AKS) med Kafka i HDInsight
- Använda Kafka på AKS med Strimzi-operatorn
Här är ett beslutsflödesschema för att bestämma vilken strategi som ska användas.
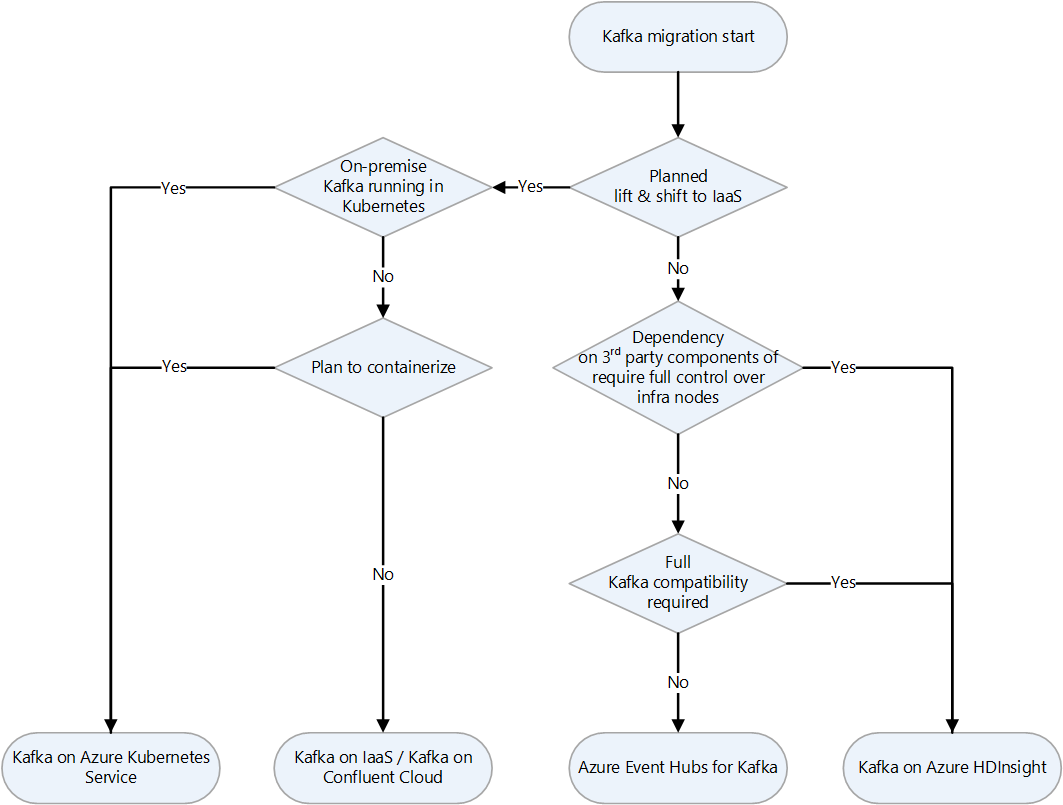
Migrera Kafka till Azure IaaS
Ett sätt att migrera Kafka till Azure IaaS finns i Kafka på virtuella Ubuntu-datorer.
Migrera Kafka till Event Hubs för Kafka
Event Hubs tillhandahåller en slutpunkt som är kompatibel med Apache Kafka-producent- och konsument-API:er. De flesta Apache Kafka-klientprogram kan använda den här slutpunkten, så du kan använda den som ett alternativ till att köra ett Kafka-kluster på Azure. Slutpunkten stöder klienter som använder API-versionerna 1.0 och senare. Mer information om den här funktionen finns i Översikt över Event Hubs för Apache Kafka.
Information om hur du migrerar dina Apache Kafka-program för att använda Event Hubs finns i Migrera till Event Hubs för Apache Kafka-ekosystem.
Funktioner i Kafka och Event Hubs
| Likheter mellan Kafka och Event Hubs | Skillnader i Kafka och Event Hubs |
|---|---|
| Använda partitioner | Plattform som en tjänst jämfört med programvara |
| Partitioner är oberoende | Partitionering |
| Använda ett markörkoncept på klientsidan | Api |
| Kan skalas till mycket höga arbetsbelastningar | Körningstid |
| Nästan identisk konceptuellt | Protokoll |
| Ingen av dem använder HTTP-protokollet för att ta emot | Hållbarhet |
| Säkerhet | |
| Strypning |
Partitioneringsskillnader
| Kafka | Event Hubs |
|---|---|
| Partitionsantalet hanterar skalning. | Dataflödesenheter hanterar skalning. |
| Du måste belastningsutjämning partitioner mellan datorer. | Belastningsutjämning är automatisk. |
| Du måste partitionera om manuellt med hjälp av dela och sammanfoga. | Ompartitionering krävs inte. |
Hållbarhetsskillnader
| Kafka | Event Hubs |
|---|---|
| Flyktig som standard | Alltid beständig |
| Replikeras efter att en bekräftelse (ACK) har tagits emot | Replikeras innan en ACK skickas |
| Beror på disk och kvorum | Tillhandahålls av lagring |
Säkerhetsskillnader
| Kafka | Event Hubs |
|---|---|
| Secure Sockets Layer (SSL) och SASL (Simple Authentication and Security Layer) | Signatur för delad åtkomst (SAS) och SASL eller PLAIN RFC 4618 |
| Filliknande åtkomstkontrollistor | Riktlinje |
| Valfri transportkryptering | Obligatorisk TLS (Transport Layer Security) |
| Användarbaserad | Tokenbaserad (obegränsad) |
Andra skillnader
| Kafka | Event Hubs |
|---|---|
| Begränsar inte | Stöder begränsning |
| Använder ett proprietärt protokoll | Använder AMQP 1.0-protokoll |
| Använder inte HTTP för att skicka | Använder HTTP send och batch send |
Migrera Kafka på HDInsight
Du kan migrera Kafka till Kafka i HDInsight. Mer information finns i Vad är Apache Kafka i HDInsight?.
Använda AKS med Kafka i HDInsight
Mer information finns i Använda AKS med Apache Kafka i HDInsight.
Använda Kafka på AKS med Strimzi-operatorn
Mer information finns i Distribuera ett Kafka-kluster på AKS med hjälp av Strimzi.
Kafka-datamigrering
Du kan använda Kafkas MirrorMaker-verktyg för att replikera ämnen från ett kluster till ett annat. Den här tekniken kan hjälpa dig att migrera data när ett Kafka-kluster har etablerats. Mer information finns i Använda MirrorMaker för att replikera Apache Kafka-ämnen med Kafka i HDInsight.
Följande migreringsmetod använder spegling:
Flytta producenter först. När du migrerar producenterna förhindrar du produktion av nya meddelanden på källan Kafka.
När källan Kafka har förbrukat alla återstående meddelanden kan du migrera konsumenterna.
Implementeringen innehåller följande steg:
Ändra Kafka-anslutningsadressen för producentklienten så att den pekar på den nya Kafka-instansen.
Starta om producentföretagens tjänster och skicka nya meddelanden till den nya Kafka-instansen.
Vänta tills data i kafka-källan har förbrukats.
Ändra Kafka-anslutningsadressen för konsumentklienten så att den pekar på den nya Kafka-instansen.
Starta om konsumentföretagens tjänster för att använda meddelanden från den nya Kafka-instansen.
Kontrollera att konsumenterna lyckas hämta data från den nya Kafka-instansen.
Övervaka Kafka-klustret
Du kan använda Azure Monitor-loggar för att analysera loggar som Apache Kafka på HDInsight genererar. Mer information finns i Analysera loggar för Apache Kafka i HDInsight.
Apache Kafka Streams API
Kafka Streams-API:et gör det möjligt att bearbeta data i nära realtid och koppla och aggregera data. Mer information finns i Introduktion till Kafka Streams: Stream Processing Made Simple – Confluent.
Microsoft och Confluent-samarbetet
Confluent tillhandahåller en molnbaserad tjänst för Apache Kafka. Microsoft och Confluent har en strategisk allians. Mer information finns i följande resurser:
- Confluent och Microsoft tillkännager strategisk allians
- Introduktion till sömlös integrering mellan Microsoft Azure och Confluent Cloud
Bidragsgivare
Microsoft ansvarar för den här artikeln. Följande deltagare skrev den här artikeln.
Huvudsakliga författare:
- Namrata Maheshwary | Senior Cloud Solution Architect
- Raja N | Direktör, kundframgång
- Hideo Takagi | Molnlösningsarkitekt
- Ram Yerrabotu | Senior Cloud Solution Architect
Övriga medarbetare:
- Ram Baskaran | Senior Cloud Solution Architect
- Jason Bouska | Senior programvarutekniker
- Eugene Chung | Senior Cloud Solution Architect
- Pawan Hosatti | Senior Cloud Solution Architect – Teknik
- Daman Kaur | Molnlösningsarkitekt
- Danny Liu | Senior Cloud Solution Architect – Teknik
- Jose Mendez Senior Cloud Solution Architect
- Ben Sadeghi | Senior Specialist
- Sunil Sattiraju | Senior Cloud Solution Architect
- Amanjeet Singh | Programhanteraren för huvudnamn
- Nagaraj Seeplapudur Venkatesan | Senior Cloud Solution Architect – Teknik
Om du vill se linkedin-profiler som inte är offentliga loggar du in på LinkedIn.
Nästa steg
Introduktion till Azure-produkter
- Introduktion till Azure Data Lake Storage
- Vad är Apache Spark i HDInsight?
- Vad är Apache Hadoop i HDInsight?
- Vad är Apache HBase i HDInsight?
- Vad är Apache Kafka i HDInsight?
- Översikt över företagssäkerhet i HDInsight
Produktreferens för Azure
- Microsoft Entra-dokumentation
- Dokumentation om Azure Cosmos DB
- Dokumentation om Azure Data Factory
- Dokumentation om Azure Databricks
- Dokumentation om Event Hubs
- Dokumentation om Azure Functions
- Dokumentation om HDInsight
- Dokumentation om Datastyrning i Microsoft Purview
- Dokumentation om Azure Stream Analytics