Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Apache Hadoop var det ursprungliga öppna källkodsbiblioteket för distribuerad bearbetning och analys av stordatauppsättningar i kluster. Hadoop-ekosystemet innehåller relaterad programvara och verktyg, inklusive Apache Hive, Apache HBase, Spark, Kafka och många andra.
Azure HDInsight är en fullständigt hanterad analystjänst med fullständigt spektrum med öppen källkod i molnet för företag. Med Apache Hadoop-klustertypen i Azure HDInsight kan du använda Apache Hadoop Distributed File System (HDFS), Apache Hadoop YARN-resurshantering och en enkel MapReduce-programmeringsmodell för att bearbeta och analysera batchdata parallellt. Hadoop-kluster i HDInsight är kompatibla med Azure Data Lake Storage Gen2.
Mer information om tillgängliga stackkomponenter med Hadoop-teknik i HDInsight finns i Komponenter och versioner som är tillgängliga med HDInsight. Mer information om Hadoop i HDInsight finns på sidan om Azure-funktioner för HDInsight.
Vad är MapReduce
Apache Hadoop MapReduce är ett programvaruramverk för att skriva jobb som bearbetar stora mängder data. Indata delas upp i oberoende segment. Varje segment bearbetas parallellt över noderna i klustret. Ett MapReduce-jobb består av två funktioner:
Mapper: Bearbetar indata, analyserar den (vanligtvis med filtrerings- och sorteringsoperationer) och genererar tupplar (nyckel/värde-par)
Reducer: Tar emot tupplar som genereras av Mapper och utför en summeringsåtgärd som skapar ett mindre, kombinerat resultat från Mapper-data.
Ett exempel på ett grundläggande ordantal för MapReduce-jobb illustreras i följande diagram:
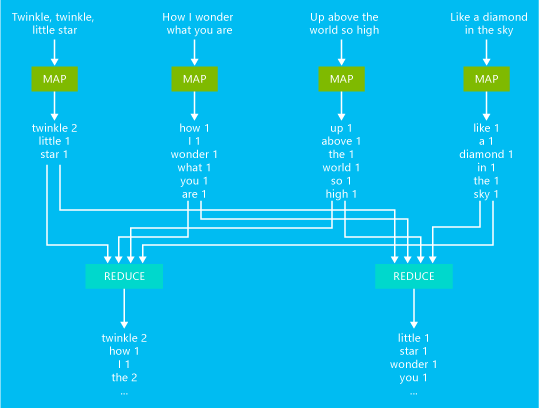
Utdata för det här jobbet är ett antal av hur många gånger varje ord inträffade i texten.
- Mapparen tar varje rad från indatatexten som indata och delar upp den i ord. Det genererar ett nyckel/värde-par varje gång ett ord förekommer och åtföljs av en etta. Utdata sorteras innan de skickas till reducer.
- Reducern summerar dessa enskilda antal för varje ord och genererar ett enda nyckel/värde-par som innehåller ordet följt av summan av dess förekomster.
MapReduce kan implementeras på olika språk. Java är den vanligaste implementeringen och används i demonstrationssyfte i det här dokumentet.
Utvecklingsspråk
Språk eller ramverk som baseras på Java och den virtuella Java-datorn kan köras direkt som ett MapReduce-jobb. Exemplet som används i det här dokumentet är ett Java MapReduce-program. Andra språk än Java, till exempel C#, Python eller fristående körbara filer, måste använda Hadoop-strömning.
Hadoop streaming kommunicerar med mapparen och reducern via STDIN och STDOUT. Mapparen och reducern läser data en rad i taget från STDIN och skriver utdata till STDOUT. Varje rad som läss eller genereras av mapparen och reducern måste vara i formatet för ett nyckel/värde-par, avgränsat med ett fliktecken:
[key]\t[value]
Mer information finns i Hadoop Streaming.
Exempel på hur du använder Hadoop-strömning med HDInsight finns i följande dokument:
Var börjar jag?
- Snabbstart: Skapa Apache Hadoop-kluster i Azure HDInsight med hjälp av Azure Portal
- Självstudie: Skicka Apache Hadoop-jobb i HDInsight
- Utveckla Java MapReduce-program för Apache Hadoop i HDInsight
- Använda Apache Hive som ett ETL-verktyg (Extract, Transform, and Load)
- Extrahera, transformera och ladda (ETL) i stor skala
- Operationalisera en pipeline för dataanalys