Den här artikeln beskriver överväganden för att hantera data i en arkitektur för mikrotjänster. Eftersom varje mikrotjänst hanterar sina egna data är dataintegritet och datakonsekvens kritiska utmaningar.
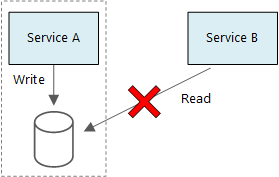
En grundläggande princip för mikrotjänster är att varje tjänst hanterar sina egna data. Två tjänster bör inte dela ett datalager. I stället ansvarar varje tjänst för sitt eget privata datalager, som andra tjänster inte kan komma åt direkt.
Anledningen till den här regeln är att undvika oavsiktlig koppling mellan tjänster, vilket kan leda till att tjänster delar samma underliggande datascheman. Om dataschemat ändras måste ändringen samordnas för varje tjänst som förlitar sig på databasen. Genom att isolera varje tjänsts datalager kan vi begränsa ändringsomfånget och bevara flexibiliteten i verkligt oberoende distributioner. En annan orsak är att varje mikrotjänst kan ha egna datamodeller, frågor eller läs-/skrivmönster. Om du använder ett delat datalager begränsas varje teams möjlighet att optimera datalagringen för deras specifika tjänst.
Den här metoden leder naturligtvis till flerspråkig persistens – användning av flera datalagringstekniker i ett enda program. En tjänst kan kräva funktionerna schema-on-read i en dokumentdatabas. En annan kan behöva referensintegriteten som tillhandahålls av en RDBMS. Varje team är fria att göra det bästa valet för sin tjänst.
Kommentar
Det går bra för tjänster att dela samma fysiska databasserver. Problemet uppstår när tjänster delar samma schema eller läser och skriver till samma uppsättning databastabeller.
Utmaningar
Vissa utmaningar uppstår i den här distribuerade metoden för att hantera data. För det första kan det finnas redundans i datalagren, där samma dataobjekt visas på flera platser. Data kan till exempel lagras som en del av en transaktion och sedan lagras någon annanstans för analys, rapportering eller arkivering. Duplicerade eller partitionerade data kan leda till problem med dataintegritet och konsekvens. När datarelationer omfattar flera tjänster kan du inte använda traditionella datahanteringstekniker för att framtvinga relationerna.
Traditionell datamodellering använder regeln "ett faktum på ett ställe". Varje entitet visas exakt en gång i schemat. Andra entiteter kan innehålla referenser till den men inte duplicera den. Den uppenbara fördelen med den traditionella metoden är att uppdateringar görs på en enda plats, vilket undviker problem med datakonsekvens. I en arkitektur för mikrotjänster måste du överväga hur uppdateringar sprids mellan tjänster och hur du hanterar eventuell konsekvens när data visas på flera platser utan stark konsekvens.
Metoder för att hantera data
Det finns ingen enskild metod som är korrekt i alla fall, men här är några allmänna riktlinjer för att hantera data i en mikrotjänstarkitektur.
Utnyttja slutlig konsekvens där det är möjligt. Förstå de platser i systemet där du behöver stark konsekvens eller ACID-transaktioner och de platser där slutlig konsekvens är acceptabel.
När du behöver starka konsekvensgarantier kan en tjänst representera sanningskällan för en viss entitet, som exponeras via ett API. Andra tjänster kan innehålla en egen kopia av data, eller en delmängd av data, som så småningom överensstämmer med huvuddata men inte betraktas som källan till sanningen. Tänk dig till exempel ett e-handelssystem med en kundtjänsttjänst och en rekommendationstjänst. Rekommendationstjänsten kan lyssna på händelser från ordertjänsten, men om en kund begär en återbetalning är det ordertjänsten, inte rekommendationstjänsten, som har hela transaktionshistoriken.
För transaktioner använder du mönster som Scheduler Agent Supervisor och Kompenserande transaktion för att hålla data konsekventa mellan flera tjänster. Du kan behöva lagra ytterligare en del data som samlar in tillståndet för en arbetsenhet som omfattar flera tjänster för att undvika partiella fel bland flera tjänster. Du kan till exempel behålla ett arbetsobjekt i en varaktig kö medan en transaktion i flera steg pågår.
Lagra endast de data som en tjänst behöver. En tjänst kanske bara behöver en delmängd information om en domänentitet. I den leveransbundna kontexten behöver vi till exempel veta vilken kund som är associerad med en viss leverans. Men vi behöver inte kundens faktureringsadress – den hanteras av den kontobundna kontexten. Att tänka noga på domänen och använda en DDD-metod kan vara till hjälp här.
Överväg om dina tjänster är sammanhängande och löst kopplade. Om två tjänster kontinuerligt utbyter information med varandra, vilket resulterar i chattiga API:er, kan du behöva rita om tjänstgränserna genom att slå samman två tjänster eller omstrukturera deras funktioner.
Använd en händelsedriven arkitekturstil. I den här arkitekturstilen publicerar en tjänst en händelse när det sker ändringar i dess offentliga modeller eller entiteter. Intresserade tjänster kan prenumerera på dessa händelser. En annan tjänst kan till exempel använda händelserna för att konstruera en materialiserad vy över de data som är lämpligare för frågor.
En tjänst som äger händelser bör publicera ett schema som kan användas för att automatisera serialisering och deserialisering av händelserna för att undvika nära koppling mellan utgivare och prenumeranter. Överväg JSON-schema eller ett ramverk som Microsoft Bond, Protobuf eller Avro.
I hög skala kan händelser bli en flaskhals i systemet, så överväg att använda sammansättning eller batchbearbetning för att minska den totala belastningen.
Exempel: Välja datalager för drone delivery-programmet
I föregående artiklar i den här serien beskrivs en tjänst för drönarleverans som ett exempel som körs. Du kan läsa mer om scenariot och motsvarande referensimplementering här. Det här exemplet är idealiskt för flygplans- och flygindustrin.
För att sammanfatta definierar det här programmet flera mikrotjänster för schemaläggning av leveranser med drönare. När en användare schemalägger en ny leverans innehåller klientbegäran information om leveransen, till exempel upphämtnings- och avlämningsplatser och om paketet, till exempel storlek och vikt. Den här informationen definierar en arbetsenhet.
De olika serverdelstjänsterna bryr sig om olika delar av informationen i begäran och har även olika läs- och skrivprofiler.
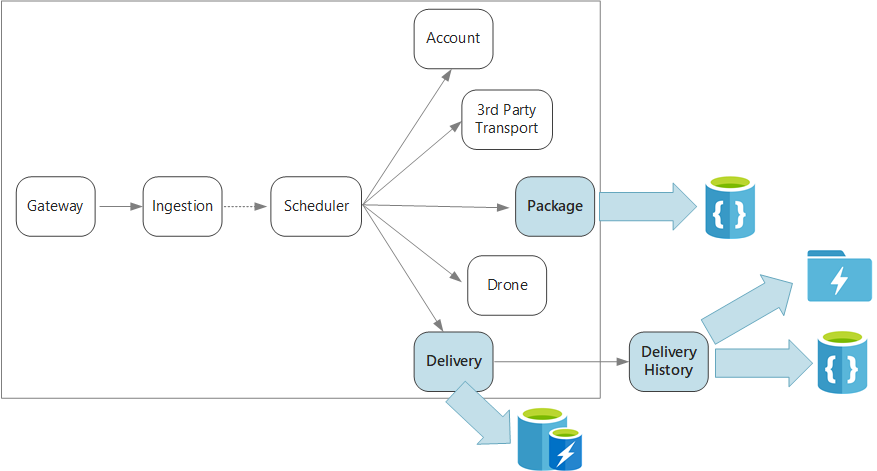
Leveranstjänst
Leveranstjänsten lagrar information om varje leverans som för närvarande är schemalagd eller pågår. Den lyssnar efter händelser från drönarna och spårar statusen för leveranser som pågår. Den skickar även domänhändelser med uppdateringar av leveransstatus.
Det förväntas att användarna ofta kontrollerar statusen för en leverans medan de väntar på sitt paket. Därför kräver leveranstjänsten ett datalager som betonar dataflödet (läsa och skriva) över långsiktig lagring. Leveranstjänsten utför inte heller några komplexa frågor eller analyser. Den hämtar helt enkelt den senaste statusen för en viss leverans. Leveranstjänstteamet valde Azure Cache for Redis för sin höga läs- och skrivprestanda. Informationen som lagras i Redis är relativt kortlivad. När en leverans är klar är leveranshistoriktjänsten postsystemet.
Leveranshistoriktjänst
Tjänsten Leveranshistorik lyssnar efter leveransstatushändelser från leveranstjänsten. Den lagrar dessa data i långsiktig lagring. Det finns två olika användningsfall för dessa historiska data, som har olika krav på datalagring.
Det första scenariot är att aggregera data för dataanalys för att optimera verksamheten eller förbättra tjänstens kvalitet. Observera att leveranshistoriktjänsten inte utför den faktiska analysen av data. Den ansvarar bara för inmatning och lagring. I det här scenariot måste lagringen optimeras för dataanalys över en stor uppsättning data med hjälp av en schema-on-read-metod för att hantera en mängd olika datakällor. Azure Data Lake Store passar bra för det här scenariot. Data Lake Store är ett Apache Hadoop-filsystem som är kompatibelt med Hadoop Distributed File System (HDFS) och är anpassat för prestanda för dataanalysscenarier.
Det andra scenariot gör det möjligt för användare att leta upp historiken för en leverans när leveransen har slutförts. Azure Data Lake är inte optimerat för det här scenariot. För optimala prestanda rekommenderar Microsoft att du lagrar tidsseriedata i Data Lake i mappar som partitionerats efter datum. (Se Justera Azure Data Lake Store för prestanda). Den strukturen är dock inte optimal för att söka efter enskilda poster efter ID. Om du inte också känner till tidsstämpeln kräver ett uppslag efter ID att hela samlingen genomsöks. Därför lagrar tjänsten Leveranshistorik även en delmängd av historiska data i Azure Cosmos DB för snabbare sökning. Posterna behöver inte stanna i Azure Cosmos DB på obestämd tid. Äldre leveranser kan arkiveras – till exempel efter en månad. Detta kan göras genom att köra en tillfällig batchprocess. Arkivering av äldre data kan minska kostnaderna för Cosmos DB och samtidigt hålla data tillgängliga för historisk rapportering från Data Lake.
Pakettjänst
Pakettjänsten lagrar information om alla paket. Lagringskraven för paketet är:
- Långtidsförvaring.
- Kunna hantera en stor mängd paket, vilket kräver högt skrivdataflöde.
- Stöd för enkla frågor efter paket-ID. Inga komplexa kopplingar eller krav för referensintegritet.
Eftersom paketdata inte är relationsbaserade är en dokumentorienterad databas lämplig och Azure Cosmos DB kan uppnå högt dataflöde med hjälp av fragmenterade samlingar. Teamet som arbetar med pakettjänsten är bekant med MEAN-stacken (MongoDB, Express.js, AngularJS och Node.js), så de väljer MongoDB-API:et för Azure Cosmos DB. Det gör att de kan utnyttja sin befintliga erfarenhet av MongoDB samtidigt som de får fördelarna med Azure Cosmos DB, som är en hanterad Azure-tjänst.
Nästa steg
Lär dig mer om designmönster som kan hjälpa dig att undvika några vanliga utmaningar i en arkitektur för mikrotjänster.