Mönster för Scheduler-agentövervakare
Samordna en uppsättning distribuerade åtgärder som en enda åtgärd. Om någon av åtgärderna misslyckas kan du prova att hantera felen transparent, eller ångra arbetet som utfördes, så att hela åtgärden utförs eller misslyckas i sin helhet. Detta kan tillföra återhämtning till ett distribuerat system genom att göra det möjligt att återställa åtgärder och testa dem igen när de misslyckats till följd av tillfälliga undantag, långvariga fel och processfel.
Kontext och problem
Ett program utför uppgifter som omfattar ett antal steg, varav vissa kan anropa fjärrtjänster eller använda fjärranslutna resurser. De enskilda stegen kan vara oberoende av varandra, men de orkestreras av den programlogik som implementerar aktiviteten.
När det är möjligt bör programmet se till att uppgiften slutförs och att eventuella fel, som kan uppstå vid åtkomst till fjärrtjänster eller fjärranslutna resurser, korrigeras. Fel kan uppstå av många olika orsaker. Exempelvis kan nätverket vara otillgängligt, kommunikationen kan ha avbrutits, en fjärrtjänst kanske inte svarar eller är i ett instabilt tillstånd eller så kan en fjärransluten resurs vara tillfälligt otillgänglig, kanske på grund av begränsningar av resursen. I många fall är felen tillfälliga och kan hanteras med hjälp av återförsöksmönstret.
Om programmet identifierar ett mer permanent fel som det inte enkelt kan återställas från, måste det kunna återställa systemet till ett stabilt tillstånd och säkerställa integriteten hos hela åtgärden.
Lösning
Mönstret för Scheduler-agentövervakaren definierar följande aktörer. Dessa aktörer samordnar stegen som utförs som en del av den totala uppgiften.
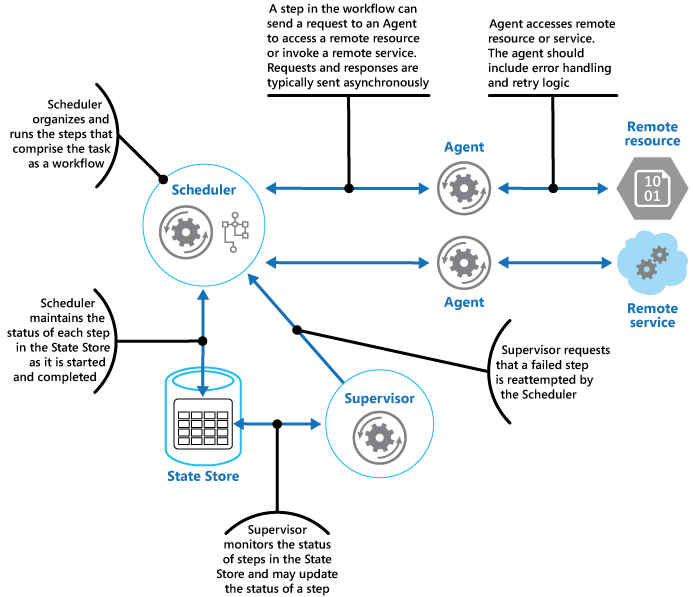
Scheduler ser till att de steg som utgör uppgiften kan utföras och samordnar stegen. De här stegen kan kombineras i en pipeline eller ett arbetsflöde. Scheduler ansvarar för att säkerställa att stegen i det här arbetsflödet utförs i rätt ordning. När varje steg utförs registrerar Scheduler arbetsflödets tillstånd, till exempel "steget har inte startats ännu", "steg körs" eller "steget har slutförts". Tillståndsinformationen bör också innehålla en övre gräns för den tid som tillåts för att steget ska slutföras, vilket kallas för "complete-by time". Om ett steg kräver åtkomst till en fjärrtjänst eller fjärransluten resurs, anropar Scheduler lämplig agent och förmedlar information om arbetet som ska utföras. Scheduler kommunicerar vanligtvis med en agent med asynkrona meddelanden för begäran/svar. Detta kan implementeras med hjälp av köer, men andra distribuerade meddelandetekniker kan också användas.
Scheduler utför en funktion som liknar processhanteraren i mönstret för processhanteraren. Det faktiska arbetsflödet definieras och implementeras vanligtvis av en arbetsflödesmotor som styrs av Scheduler. Den här metoden frikopplar affärslogiken i arbetsflödet från Scheduler.
Agenten innehåller logik som kapslar in ett anrop till en fjärrtjänst, eller åtkomst till en fjärransluten resurs som refereras av ett steg i en uppgift. Varje agent skickar vanligtvis anrop till en enskild tjänst eller resurs och implementerar lämplig felhantering och återförsökslogik (begränsas av en tidsgräns som beskrivs senare). När du implementerar logik för återförsök skickar du en stabil identifierare för alla återförsök så att fjärrtjänsten kan använda den för all dedupliceringslogik som den kan ha. Om stegen i arbetsflödet som körs av Scheduler använder flera tjänster och resurser i olika steg, kan varje steg referera till olika agenter (detta är en implementeringsdetalj för mönstret).
Övervakaren övervakar statusen för stegen i uppgiften som utförs av Scheduler. Den körs regelbundet (frekvensen är systemspecifik) och undersöker statusen för de steg som underhålls av Scheduler. Om den upptäcker att en tidsgräns har överskridits eller att något inte kunnat genomföras, ser den till att lämplig agent återställer steget eller vidtar lämplig korrigerande åtgärd (detta kan orsaka en statusändring för ett steg). Observera att återställningsåtgärderna och de korrigerande åtgärderna implementeras av Scheduler och agenterna. Övervakaren bör bara begära att dessa åtgärder ska utföras.
Scheduler, agenten och övervakaren är logiska komponenter och deras fysiska implementering beror på vilken teknik som används. Till exempel kan flera logiska agenter implementeras som en del av en enda webbtjänst.
Scheduler lagrar information om förloppet för uppgiften och tillståndet för varje steg i ett beständigt dataarkiv, som kallas tillståndslagret. Övervakaren kan använda den här informationen för att avgöra om ett steg har misslyckats. Bilden illustrerar förhållandet mellan Scheduler, agenterna, övervakaren och tillståndslagret.
Kommentar
Det här diagrammet visar en förenklad version av mönstret. I en faktisk implementering kan många instanser av Scheduler köras samtidigt, var och en som en del av en uppgift. På samma sätt kan systemet köra flera instanser av varje agent, och till och med flera övervakare. I det här fallet måste övervakarna samordna sitt arbete med varandra noggrant för att säkerställa att de inte konkurrerar om att återställa samma misslyckade steg och uppgifter. Mönstret för val av ledare är en möjlig lösning på problemet.
När programmet är redo att köra en uppgift skickar det en begäran till Scheduler. Scheduler registrerar initial tillståndsinformation om uppgiften och dess steg (till exempel ”steg ännu inte påbörjat”) i tillståndslagret och börjar sedan utföra åtgärderna som definierats av arbetsflödet. När Scheduler startar ett steg uppdateras informationen om tillståndet för det steget i tillståndslagret (till exempel ”steg körs”).
Om ett steg refererar till en fjärrtjänst eller fjärransluten resurs skickar Scheduler ett meddelande till lämplig agent. Meddelandet innehåller den information som agenten behöver förmedla till tjänsten eller för att få åtkomst till resursen, utöver slutförandetiden för åtgärden. Om agenten slutför åtgärden returneras ett svar till Scheduler. Scheduler kan sedan uppdatera tillståndsinformationen i tillståndslagret (till exempel ”steg slutfört”) och gå vidare med nästa steg. Den här processen fortsätter tills hela uppgiften har slutförts.
En agent kan implementera valfri omprövningslogik som krävs för att utföra arbetet. Men om agenten inte slutför arbetet innan slutförandeperioden löper ut, förutsätter Scheduler att åtgärden misslyckades. I det här fallet bör agenten avsluta arbetet och inte försöka returnera något till Scheduler (inte ens ett felmeddelande) och bör inte försöka göra någon typ av återställning. Orsaken till den här begränsningen är att när tidsgränsen för ett steg har överskridits eller när steget har misslyckats, kan en annan instans av agenten vara schemalagd för att köra steget som misslyckades (den här processen beskrivs senare).
Om agenten misslyckas får inte Scheduler något svar. Mönstret gör ingen skillnad på ett steg vars tidsgräns har uppnåtts och ett steg som faktiskt har misslyckats.
Om ett steg når sin tidsgräns eller misslyckas, innehåller tillståndslagret en post som anger att steget körs, men att slutförandetiden har överskridits. Övervakaren söker efter steg som liknar detta och försöker att återställa dem. En möjlig strategi är att övervakaren uppdaterar kompletteringsvärdet för att förlänga den tid som är tillgänglig för att slutföra steget och sedan skicka ett meddelande till Scheduler som identifierar det steg som har överskriden tidsgräns. Scheduler kan sedan försöka upprepa det här steget. Den här designen kräver dock att uppgifterna är idempotent. Systemet bör innehålla infrastruktur för att upprätthålla konsekvens. Mer information finns i Repeterbar infrastruktur, Skapa Azure-program för återhämtning och tillgänglighet samt beslutsguide för resurskonsekvens.
Övervakaren kan behöva förhindra att samma steg görs på nytt om det hela tiden misslyckas eller överskrider tidsgränsen. För att göra detta kan övervakaren upprätthålla ett återförsöksantal för varje steg, tillsammans med tillståndsinformationen, i tillståndsarkivet. Om antalet överskrider ett fördefinierat tröskelvärde kan övervakaren införa en strategi då den väntar en längre period innan Scheduler meddelas om att den bör försöka utföra steget igen, i hopp om att felet åtgärdas under denna period. Alternativt kan övervakaren skicka ett meddelande till Scheduler för att begära att hela uppgiften ångras genom att implementera ett mönster för kompenserande transaktion. Den här metoden är beroende av att Scheduler och agenterna tillhandahåller den information som behövs för att implementera de kompenserande åtgärderna för varje steg som slutförts.
Syftet med övervakaren är inte att övervaka Scheduler och agenterna och starta om dem om de misslyckas. Den här delen av systemet bör hanteras av den infrastruktur som dessa komponenter körs i. På liknande sätt bör övervakaren inte ha information om de faktiska affärsåtgärderna som uppgifterna som utförs av Scheduler kör (inklusive hur misslyckade uppgifter kompenseras). Detta är syftet med arbetsflödeslogiken som implementeras av Scheduler. Övervakarens enda ansvar är att avgöra om ett steg har misslyckats och antingen se till att det utförs igen eller att hela uppgiften som innehåller det felande steget ångras.
Om Scheduler startas om efter ett fel, eller om arbetsflödet som utförs av Scheduler avslutas oväntat, bör Scheduler kunna avgöra statusen för alla aktiva uppgifter som hanterades när felet uppstod och vara redo att återuppta uppgiften därifrån. Implementeringsinformationen för den här processen kommer sannolikt att vara systemspecifik. Om uppgiften inte kan återställas kan det vara nödvändigt att ångra det arbete som redan har utförts av uppgiften. Det kan också innebära att en kompenserande transaktion behöver implementeras.
Den stora fördelen med det här mönstret är att systemet kan återhämtas vid oväntade tillfälliga eller oåterkalleliga fel. Systemet kan konstrueras för att vara självåterställning. Om till exempel en agent eller Scheduler misslyckas kan en ny startas och övervakaren kan se till att uppgiften återupptas. Om övervakaren misslyckas kan en annan instans startas och ta över från den punkt då felet inträffade. Om övervakaren har schemalagts för att köras med jämna mellanrum kan en ny instans startas automatiskt efter ett fördefinierat intervall. Tillståndslagret kan replikeras för att nå en ännu högre återhämtningsnivå.
Problem och överväganden
När du bestämmer hur det här mönstret ska implementeras bör du överväga följande punkter:
Det här mönstret kan vara svårt att implementera och kräver omfattande testning av systemets alla möjliga fellägen.
Återställnings-/återförsökslogiken som implementerats av Scheduler är komplex och beroende av tillståndsinformationen som lagras i tillståndslagret. Det kan också vara nödvändigt att registrera informationen som krävs för att implementera en kompenserande transaktion i ett beständigt datalager. En kompenserande transaktion kan också misslyckas.
Hur ofta övervakaren körs är viktigt. Den bör köras tillräckligt ofta för att förhindra att misslyckade åtgärder blockerar ett program under en längre period, men den får inte köras så ofta att den blir en omkostnad.
De steg som utförs av en agent kan köras mer än en gång. Logiken som implementerar dessa steg ska vara idempotent.
När du ska använda det här mönstret
Använd det här mönstret när en process som körs i en distribuerad miljö, till exempel molnet, måste kunna stå emot kommunikationsfel och/eller driftfel.
Det här mönstret är kanske inte lämpligt för uppgifter som inte anropar fjärrtjänster eller använder fjärranslutna resurser.
Design av arbetsbelastning
En arkitekt bör utvärdera hur Scheduler Agent Supervisor-mönstret kan användas i arbetsbelastningens design för att uppfylla de mål och principer som beskrivs i grundpelarna i Azure Well-Architected Framework. Till exempel:
| Grundpelare | Så här stöder det här mönstret pelarmål |
|---|---|
| Beslut om tillförlitlighetsdesign hjälper din arbetsbelastning att bli motståndskraftig mot fel och se till att den återställs till ett fullt fungerande tillstånd när ett fel inträffar. | Det här mönstret använder hälsomått för att identifiera fel och omdirigera uppgifter till en felfri agent för att minimera effekterna av ett fel. - RE:05 Redundans - RE:07 Självåterställning |
| Prestandaeffektivitet hjälper din arbetsbelastning att effektivt uppfylla kraven genom optimeringar inom skalning, data och kod. | Det här mönstret använder prestanda- och kapacitetsmått för att identifiera aktuell användning och dirigera uppgifter till en agent som har kapacitet. Du kan också använda den för att prioritera körningen av arbete med högre prioritet framför arbete med lägre prioritet. - PE:05 Skalning och partitionering - PE:09 Kritiska flöden |
Som med alla designbeslut bör du överväga eventuella kompromisser mot målen för de andra pelarna som kan införas med det här mönstret.
Exempel
Ett webbprogram som implementerar ett e-handelssystem har distribuerats i Microsoft Azure. Användare kan köra det här programmet för att bläddra bland tillgängliga produkter och lägga order. Användargränssnittet körs som en webbroll och orderbearbetningselementen i programmet implementeras som en uppsättning arbetsroller. En del av orderbearbetningslogiken involverar åtkomst till en fjärrtjänst och den här aspekten av systemet kan ofta orsaka tillfälliga eller mer långvariga fel. Av denna anledning har utvecklarna använt mönstret för Scheduler-agentövervakaren för att implementera orderbearbetningselementen i systemet.
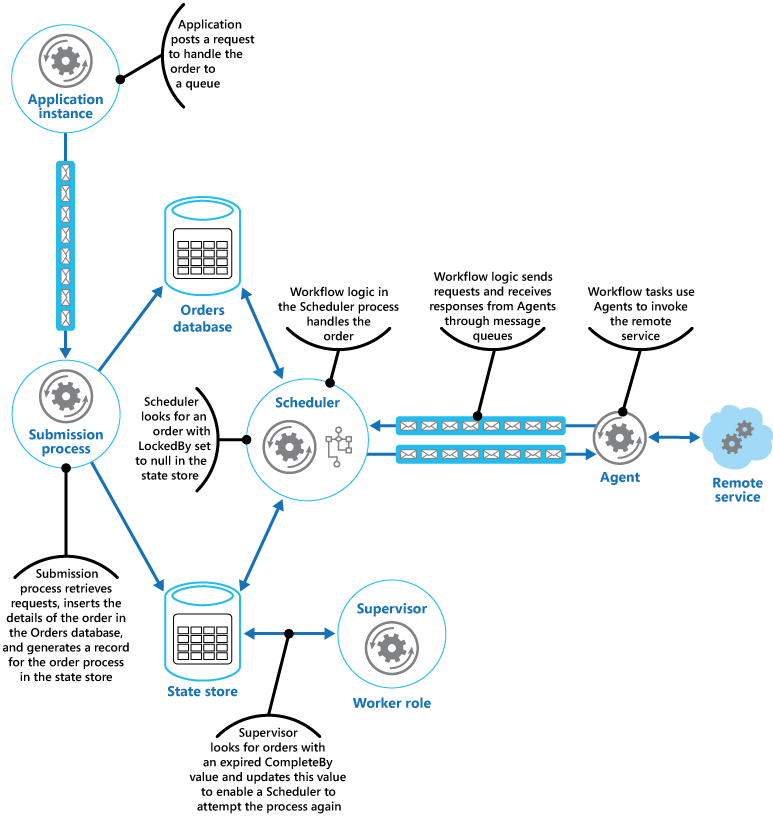
När en kund lägger en order skapar programmet ett meddelande som beskriver ordern och publicerar meddelandet i en kö. En separat överföringsprocess, som körs i en arbetsroll, hämtar meddelandet, infogar orderinformationen i orderdatabasen och skapar en post för orderbearbetningen i tillståndslagret. Observera att tillägg i orderdatabasen och tillståndslagret utförs som en del av samma åtgärd. Överföringsprocessen är utformad för att se till att båda tillägg slutförs samtidigt.
Tillståndsinformationen som överföringsprocessen skapar för ordern innehåller:
Order-ID. ID-numret för ordern i orderdatabasen.
LockedBy (Låst av). Instans-ID:t för arbetsrollen som hanterar ordern. Det kan finnas flera aktuella instanser av arbetsrollen som kör Scheduler, men varje order bör endast hanteras av en enda instans.
CompleteBy (Slutför senast). Tiden då ordern ska vara bearbetad.
ProcessState (Bearbetningstillstånd). Det aktuella tillståndet för uppgiften som hanterar ordern. Det finns möjliga tillstånd:
- Väntar. Ordern har skapats men bearbetningen har ännu inte påbörjats.
- Bearbetar. Ordern bearbetas.
- Bearbetad. Ordern har bearbetats.
- Fel. Orderbearbetningen har misslyckats.
Antal misslyckade. Antalet gånger bearbetningen har försökt utföras.
I den här tillståndsinformationen kopieras fältet OrderID från den nya orderns order-ID. Fälten LockedBy och CompleteBy är inställda på att null, fältet ProcessState är inställt på Pending, och fältet FailureCount anges till 0.
Kommentar
I det här exemplet är logiken för orderhanteringen relativt enkel och har bara ett enda steg som anropar en fjärrtjänst. I ett mer komplext scenario med flera steg skulle överföringsprocessen sannolikt omfatta flera steg, och därför skulle flera poster skapas i tillståndsarkivet – var och en som beskriver tillståndet för ett enskilt steg.
Scheduler körs också som en del av en arbetsroll och implementerar affärslogiken som hanterar ordern. En instans av Scheduler-avsökningen för nya order undersöker tillståndslagret för poster där fältet LockedBy är null och fältet ProcessState väntar. När Scheduler hittar en ny order fylls fältet LockedBy i direkt med det egna instans-ID:t, anger fältet CompleteBy till en lämplig tidpunkt och ställer in fältet ProcessState för bearbetning. Koden är avsedd att vara exklusiv och atomisk för att säkerställa att två samtidiga instanser av Scheduler inte kan försöka hantera samma order samtidigt.
Scheduler kör sedan affärsarbetsflödet för att bearbeta ordern asynkront, och förmedlar sedan värdet i fältet OrderID från tillståndslagret. Arbetsflödet som hanterar ordern hämtar information om ordern från orderdatabasen och utför sitt arbete. När ett steg i arbetsflödet för orderbearbetningen behöver anropa fjärrtjänsten, används en agent. Arbetsflödessteget kommunicerar med agenten med ett par Azure Service Bus-meddelandeköer som fungerar som en kanal för begäranden/svar. Bilden visar en översikt över lösningen.
Meddelandet som skickas till agenten från ett arbetsflödessteg beskriver ordningen och innehåller även slutförandetiden. Om agenten tar emot ett svar från fjärrtjänsten innan slutförandetiden går ut, skickar den ett svarsmeddelande via Service Bus-kön som arbetsflödet lyssnar på. När arbetsflödessteget tar emot det giltiga svarsmeddelandet slutförs bearbetningen och Scheduler anger ProcessState fältet för ordertillståndet som bearbetas. Nu har orderbearbetningen slutförts.
Om slutförandetiden löper ut innan agenten får ett svar från fjärrtjänsten avbryter agenten bara bearbetningen och avslutar hanteringen av ordern. På liknande sätt avbryts också arbetsflödet som hanterar ordern om det överskrider slutförandetiden. I båda fallen förblir ordens tillstånd i tillståndslagret ställd till Bearbetas, men slutförandetiden indikerar att tiden för bearbetning av ordern har passerat och att bearbetningen anses ha misslyckats. Observera att om agenten som har åtkomst till fjärrtjänsten, eller arbetsflödet som hanterar ordern (eller båda), avslutas oväntat, anges informationen i tillståndslagret återigen till Bearbetas och får slutligen ett slutförandetidsvärde som löpt ut.
Om agenten upptäcker ett oåterkalleligt, ej tillfälligt fel under försöken att kontakta fjärrtjänsten kan den skicka tillbaka ett felsvar till arbetsflödet. Scheduler kan ställa statusen för ordern till Fel och skapa en händelse som varnar en operatör. Operatören kan sedan försöka lösa orsaken till felet manuellt och skicka om det misslyckade bearbetningssteget igen.
Övervakaren undersöker tillståndslagret regelbundet och tittar efter order med slutförandetid som löpt ut. Om övervakaren hittar en post, ökas fältet FailureCount. Om värdet för antal fel ligger under ett angivet tröskelvärde, återställer övervakaren fältet LockedBy till null, uppdaterar fältet CompleteBy med en ny förfallotid och anger fältet ProcessState till Väntar. En instans av Scheduler kan hämta den här ordern och utföra dess bearbetning som innan. Om värdet för antal fel överskrider ett visst tröskelvärde, antas orsaken till felet inte vara tillfälligt. Övervakaren kan ställa in statusen för ordern till Fel och skapa en händelse som varnar en operatör.
I det här exemplet har övervakaren implementerats i en separat arbetsroll. Du kan använda en mängd olika strategier för att ställa in hur övervakaruppgiften ska köras, inklusive användning av tjänsten Azure Scheduler (ska inte förväxlas med komponenten Scheduler i det här mönstret). Du hittar mer information om tjänsten Azure Scheduler-tjänsten på sidan Scheduler.
Även om det inte visas i det här exemplet kan Scheduler behöva skicka information till programmet som skickade ordern om förlopp och status för ordern. Programmet och Scheduler är isolerade från varandra för att undvika eventuella beroenden mellan dem. Programmet har ingen kunskap om vilken instans av Scheduler som hanterar ordern och Scheduler har ingen information om vilken specifik programinstans som skickade ordern.
Programmet kan använda sin egen privata svarskö för att rapportera orderstatusen. Informationen om den här svarskön ingår som en del av begäran som skickades till överföringsprocessen, som skulle inkludera denna information i tillståndslagret. Scheduler skickar sedan meddelanden till kön som anger orderstatusen (begäran mottagen, order slutförd, order misslyckades och så vidare). Order-ID bör ingå i dessa meddelanden så att de kan korreleras med den ursprungliga begäran av programmet.
Nästa steg
Följande riktlinjer kan även vara relevanta när du implementerar det här mönstret:
Asynkron primer för meddelanden. Komponenterna i mönstret för Scheduler-agentövervakaren körs vanligtvis oberoende av varandra och kommunicerar asynkront. Beskriver några av de metoder som kan användas för att implementera asynkron kommunikation baserat på meddelandeköer.
Referens 6: En saga om sagor. Ett exempel som visar hur CQRS mönstret använder en processhanterare (ingår i CQRS-vägledningen).
Relaterade resurser
Följande mönster kan också vara relevanta när du implementerar det här mönstret:
Återförsöksmönster. En agent kan använda det här mönstret för att återigen försöka utföra en åtgärd transparent som använder en fjärrtjänst eller resurs som misslyckats tidigare. Använd detta när orsaken till felet väntas vara tillfälligt och möjligt att åtgärda.
Mönstret för kretsbrytare. En agent kan använda detta mönster för att hantera fel som tar olika lång tid att åtgärda vid anslutning till en fjärrtjänst eller fjärransluten resurs.
Kompenserande transaktionsmönster. Om arbetsflödet som utförs av en Scheduler inte kan slutföras, kan det vara nödvändigt att ångra allt arbete som utförts tidigare. Mönstret för kompenserande transaktion beskriver hur du kan göra detta för åtgärder som följer den slutliga konsekvensmodellen. Dessa typer av åtgärder implementeras ofta av en Scheduler som utför komplexa affärsprocesser och arbetsflöden.
Mönstret för val av ledare. Det kan vara nödvändigt att samordna åtgärderna för flera instanser av en övervakare för att förhindra att de försöker återställa samma misslyckade process. Mönstret för val av ledare beskriver hur du gör detta.
Molnarkitektur: Scheduler-Agent-Supervisor-mönstret på Clemens Vasters blogg