Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Azure Storage
Skapa index över fälten i datalager som ofta refereras i frågor. Det här mönstret kan ge bättre frågeprestanda eftersom program snabbare kan hitta data som ska hämtas från ett datalager.
Kontext och problem
I många datalager ordnas data i en samling entiteter med den primära nyckeln. Ett program kan använda den här nyckel för att hitta och hämta data. Bilden visar ett exempel på ett datalager som innehåller kundinformation. Den primära nyckeln här är Kund-ID. Bilden visar kundinformation som ordnats efter den primära nyckeln (Kund-ID).
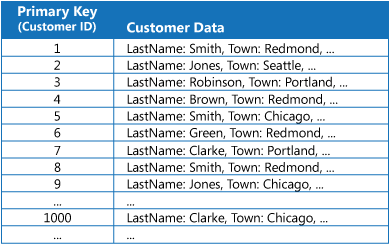
Även om den primära nyckeln är värdefull för frågor som hämtar data baserat på nyckelns värde, kanske ett program inte kan använda den primära nyckeln om det behöver hämta data baserat på ett annat fält. I kundexemplet kan ett program inte använda den primära nyckeln, Kund-ID, för att hämta kunder om det efterfrågar data enbart genom att referera till värdet för något annat attribut, till exempel den stad där kunden finns. För att kunna köra en sådan fråga kanske programmet måste hämta och undersöka alla kundposter, vilket kan ta lång tid.
Många relationsdatabaser för hanteringssystem har stöd för sekundära index. Ett sekundärt index är en separat datastruktur som är ordnad efter ett eller flera icke-primära (sekundära) nyckelfält, och det visar var data för varje indexerat värde lagras. Objekten i ett sekundärt index sorteras vanligtvis efter värdet för de sekundära nycklarna för att möjliggöra snabb datasökning. Sådana index underhålls vanligtvis automatiskt av databashanteringssystemet.
Du kan skapa så många sekundärindex som du behöver som stöd för de olika frågor som körs från ditt program. Exempel: i kundtabell i en relationsdatabas där Kund-ID är den primära nyckeln är det bra att lägga till ett sekundärt index över fältet för stad, om programmet ofta söker efter kunder enligt den stad där de bor.
Även om sekundära index är vanliga i relationssystem ger vissa NoSQL-datalager som används av molnprogram inte någon motsvarande funktion.
Lösning
Om datalagret inte har stöd för sekundära index kan du emulera dem manuellt genom att skapa egna indextabeller. I en indextabell ordnas data efter en angiven nyckel. Det finns tre vanliga strategier som används för att strukturera en indextabell, beroende på hur många sekundära index som behövs och vilken typ av frågor som körs av ett program.
Den första strategin är att alla data dupliceras i varje indextabell men ordnas efter olika nycklar (fullständig denormalisering). Nästa figur visar indextabeller där samma kundinformation ordnas efter Stad och Efternamn.
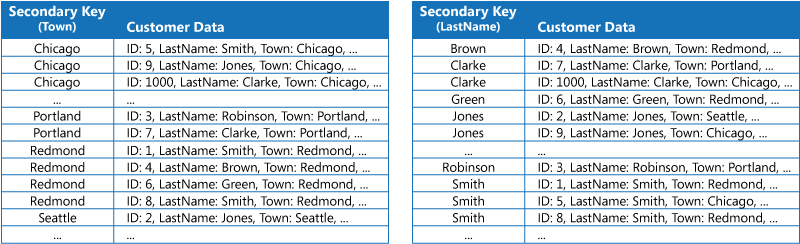
Den här strategin är lämplig om data är relativt statiska jämfört med antalet gånger som de efterfrågas med varje nyckel. Med mer dynamiska data blir bearbetningskostnaden för underhåll av varje indextabell för stor för att den här metoden ska vara användbar. Om datavolymen är hög är dessutom mängden utrymme som krävs för att lagra duplicerade data betydande.
Den andra strategin är att skapa normaliserade indextabeller som ordnas efter olika nycklar och refererar till den ursprungliga informationen med hjälp av den primära nyckeln i stället för att duplicera den, enligt följande bild. Den ursprungliga informationen kallas en faktatabell.
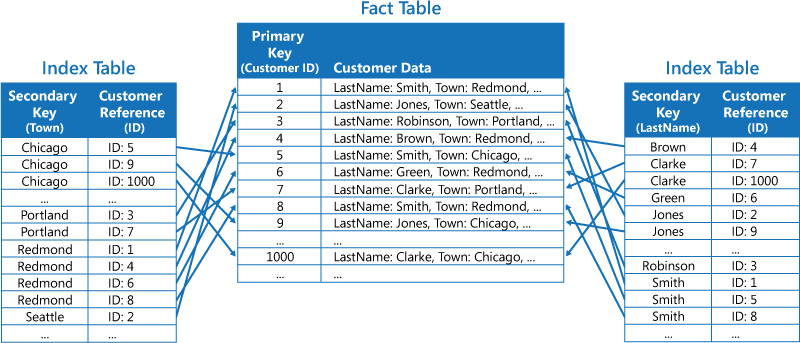
Den här metoden sparar utrymme och minskar kostnaderna för att underhålla dubblettdata. Nackdelen är att programmet måste utföra två sökåtgärder för att hitta data med en sekundär nyckel. Det måste hitta den primära nyckeln för informationen i indextabellen och sedan använda den primära nyckeln för att söka efter data i faktatabellen.
Den tredje strategin är att skapa delvis normaliserade indextabeller som ordnas efter olika nycklar som duplicerar fält som hämtas ofta. Faktatabellen refereras för åtkomst till mindre ofta använda fält. Nästa figur visar hur ofta använda data dupliceras i varje indextabell.
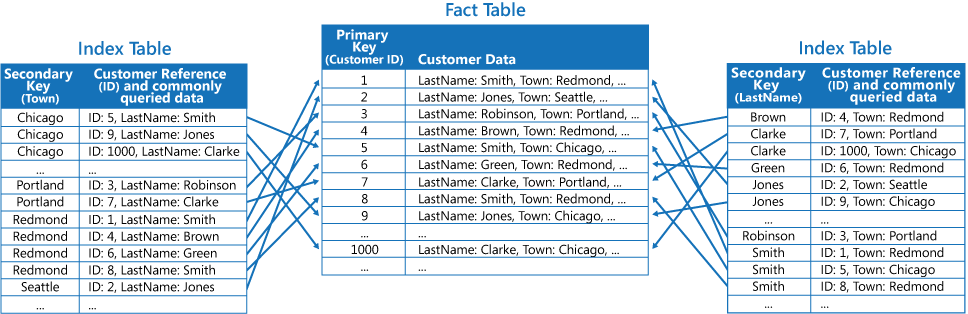
Med den här strategin kan du få en balans mellan de två första metoderna. Data för vanliga frågor kan hämtas snabbt med hjälp av en enkel sökning, medan det krävs mindre utrymme och underhåll eftersom hela datauppsättningen inte behöver dupliceras.
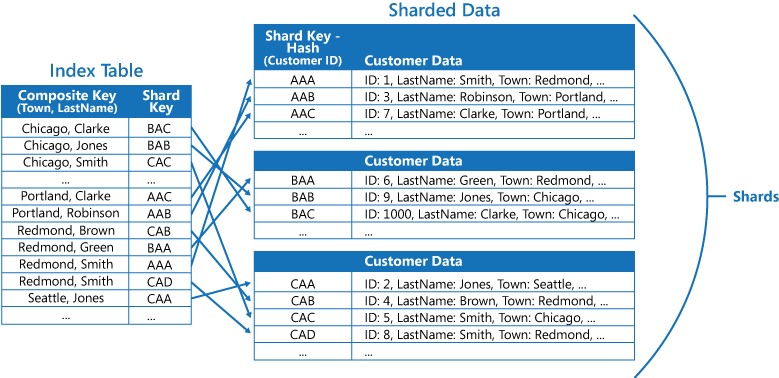
Om ett program ofta frågar efter data genom att ange en kombination av värden (till exempel "Hitta alla kunder som bor i Redmond och som har ett efternamn på Smith" kan du implementera nycklarna till objekten i indextabellen som en sammanlänkning av attributet Town och attributet LastName. Nästa figur visar en indextabell baserad på sammansatta nycklar. Nycklarna sorteras efter Stad och sedan efter Efternamn för poster som har samma värde för Stad.

Med indextabeller kan det gå snabbare att utföra frågeåtgärder på shardade data, och de är särskilt användbara där shardnyckeln är hash-kodad. Nästa figur visar ett exempel där shardnyckeln är hash-kodad för Kund-ID. Indextabellen kan ordna data efter det värde som inte är hash-kodat (Stad och Efternamn) och ange den hash-kodade shardnyckeln som sökdata. Detta kan göra att programmet slipper beräkna hash-kodade nycklar flera gånger (en kostsam åtgärd) om det behöver hämta data som ligger inom ett intervall, eller om det behöver hämta data enligt den nyckel som inte är hash-kodad. En fråga som "Hitta alla kunder som bor i Redmond" kan till exempel snabbt lösas genom att hitta matchande objekt i indextabellen, där alla lagras i ett sammanhängande block. Följ sedan referenserna till kundinformationen med shardnycklarna i indextabellen.
Problem och överväganden
Tänk på följande när du bestämmer hur du ska implementera mönstret:
Kostnaderna för att upprätthålla sekundära index kan bli höga. Du måste analysera och förstå de frågor som används i ditt program. Skapa indextabeller endast när de sannolikt kommer att användas regelbundet. Skapa inte spekulativa indextabeller som stöd för frågor som ett program inte kör, eller bara kör ibland.
Dataduplicering i en indextabell kan öka lagringskostnaderna kraftigt, och det krävs också mer kraft att underhålla fler datakopior.
Om du vill implementera en indextabell som en normaliserad struktur som refererar till ursprungsdata krävs ett program som kör två sökåtgärder för att hitta data. Den första åtgärden söker igenom indextabellen för att hämta den primära nyckeln. Den andra åtgärden använder den primära nyckeln för att hämta data.
Om ett system innehåller ett antal indextabeller över stora datamängder kan det vara svårt att upprätthålla konsekvens mellan indextabeller och ursprungliga data. Det kan gå att utforma programmet kring den slutliga konsekvensmodellen. Exempel: Om ett program ska infoga, uppdatera eller ta bort data kan ett meddelande skickas till en kö, och en separat uppgift kan utföra åtgärden och underhålla de indextabeller som refererar till dessa data asynkront. Mer information om hur du hanterar slutlig datakonsekvens finns i introduktionen till datakonsekvens.
Dricks
Lagringstabeller i Microsoft Azure har stöd för transaktionella uppdateringar vid ändringar i data som lagras i samma partition (kallas entitetsgrupptransaktioner). Om du kan lagra data för en faktatabell och en eller flera indextabeller i samma partition, kan du använda den här funktionen för att säkerställa konsekvens.
Själva indextabellerna kan också vara partitionerade eller shardade.
När du ska använda det här mönstret
Använd det här mönstret för att förbättra frågeprestanda när ett program ofta behöver hämta data med hjälp av en annan nyckel än den primära nycken (eller shardnyckeln).
Det här mönstret är kanske inte användbart om:
- Data är temporära. Indextabeller kan snabbt bli inaktuella, vilket gör hanteringen ineffektiv eller gör att det olönsamt att underhålla indextabellen.
- Ett fält som markeras som sekundär nyckel för en indextabell är icke-skiljande och kan bara ha en liten uppsättning värden (till exempel kön).
- Datavärdenas balans för ett markerat fält som sekundär nyckel för en indextabell är förvrängd. Om till exempel 90 % av posterna innehåller samma värde i ett fält, kan det medföra mer kostnader att skapa och underhålla en indextabell för att söka efter data utifrån detta fält än att söka igenom data. Men om frågor ofta riktas mot värden som ligger i återstående 10 % kan det vara bra att använda detta index. Du bör förstå de frågor som körs av ditt program och hur ofta de körs ditt program fungerar och hur ofta de utförs.
Design av arbetsbelastning
En arkitekt bör utvärdera hur indextabellmönstret kan användas i arbetsbelastningens design för att uppfylla de mål och principer som beskrivs i grundpelarna i Azure Well-Architected Framework. Till exempel:
| Grundpelare | Så här stöder det här mönstret pelarmål |
|---|---|
| Beslut om tillförlitlighetsdesign hjälper din arbetsbelastning att bli motståndskraftig mot fel och se till att den återställs till ett fullt fungerande tillstånd när ett fel inträffar. | Eftersom klienter pekas på sin shard, partition eller slutpunkt via en sökningsprocess kan du använda det här mönstret för att underlätta en redundansväxlingsmetod för dataåtkomst. - RE:06 Datapartitionering - RE:09 Haveriberedskap |
| Prestandaeffektivitet hjälper din arbetsbelastning att effektivt uppfylla kraven genom optimeringar inom skalning, data och kod. | Klienter pekar på sin shard, partition eller slutpunkt, som kan aktivera dynamisk datapartitionering för prestandaoptimering. - PE:05 Skalning och partitionering - PE:08 Dataprestanda |
Som med alla designbeslut bör du överväga eventuella kompromisser mot målen för de andra pelarna som kan införas med det här mönstret.
Exempel
Azure-lagringstabeller tillhandahåller ett mycket skalbart nyckel/värde-datalager för program som körs i molnet. Programmen lagrar och hämtar datavärden genom att en nyckel anges. Datavärdena kan innehålla flera fält, men dataobjektens struktur är inte synliga för tabellagring. Den typen av lagring hanterar bara dataobjekt som en matris med ett antal byte.
Lagringstabeller i Azure har även stöd för horisontell partitionering. Nyckeln för horisontell partitionering innehåller två element: en partitionsnyckel och en radnyckel. Objekt med samma partitionsnyckel lagras i samma partition (shard), och objekten lagras i radordning inom en partition. Tabellagringen är optimerad för körning av frågor som hämtar data inom ett sammanhängande intervall med radnyckelvärden inom en partition. Om du bygger molnprogram som lagrar information i Azure-tabeller bör du ha detta i åtanke när du strukturerar dina data.
Tänk dig till exempel att du har ett program som lagrar information om filmer. Programmet frågar ofta efter filmer efter genre (action, dokumentär, historisk, komedi, drama o.s.v.). Du kan skapa en Azure-tabell med partitioner för varje genre genom att använda genre som partitionsnyckel och ange filmtitel som radnyckel, som i nästa figur.
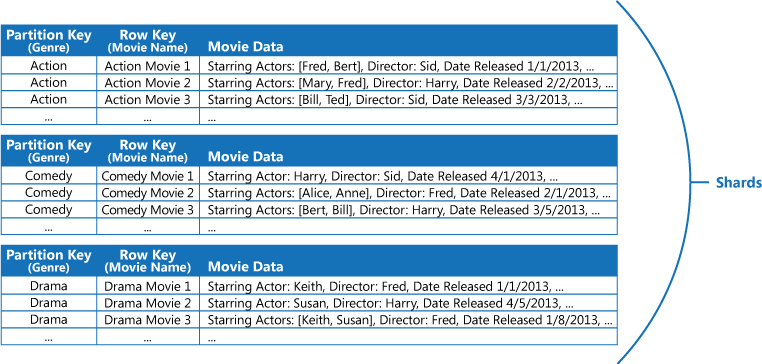
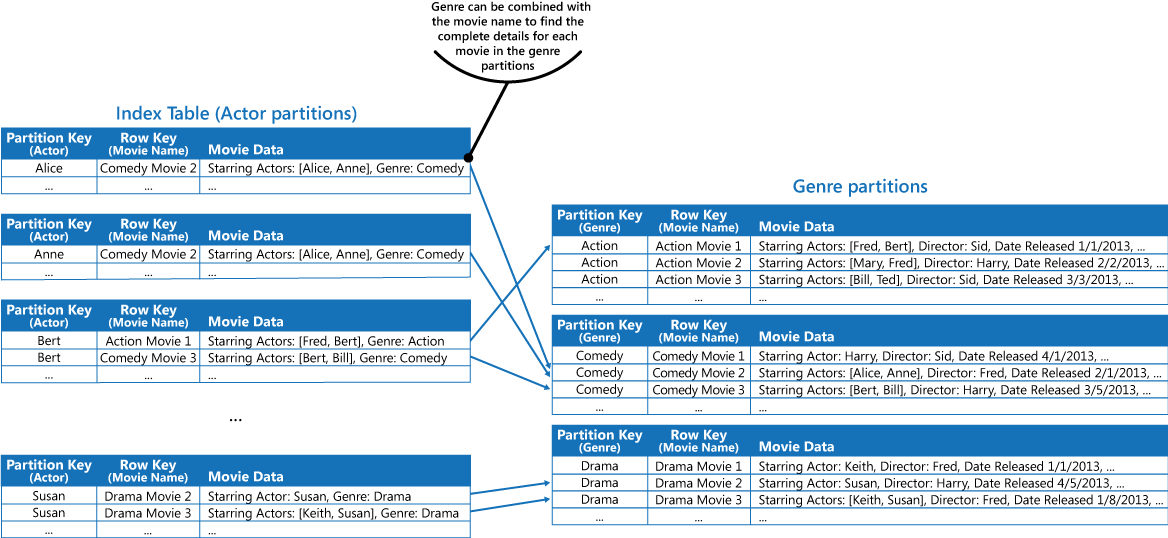
Den här metoden är mindre effektiv om programmet även måste söka efter filmer efter skådespelare. I så fall kan du skapa en separat Azure-tabell som fungerar som en indextabell. Partitionsnyckeln är skådespelaren och radnyckeln är filmens titel. Informationen för varje skådespelare lagras i separata partitioner. Om det finns flera huvudrollsskådespelare i en film, visas filmen i flera olika partitioner.
Du kan duplicera filminformationen i de värdena som finns i varje partition genom att använda den första metoden som beskrivs i avsnittet Lösning ovan. Det är troligt att varje film kommer att replikeras flera gånger (en gång för varje skådespelare), så det kan vara mer effektivt att delvis denormalisera informationen för att stödja de vanligaste frågorna (t.ex. namn på övriga skådespelare) och göra det möjligt för ett program att hämta återstående information genom att inkludera den partitionsnyckel som behövs för att hitta hela informationen i genrepartitionerna. Den här metoden beskrivs i det tredje alternativet i avsnittet Lösning. Nästa figur visar den här metoden.
Nästa steg
- Datakonsekvensprimer. Indextabeller måste underhållas när indexerade data ändras. I molnet kanske det inte möjligt eller lämpligt att utföra åtgärder där index uppdateras i samma transaktion där data ändras. I så fall är det bättre att använda en metod för slutlig konsekvens. Ger information om problem med slutlig konsekvens.
Relaterade resurser
Följande mönster kan också vara relevanta när du implementerar det här mönstret:
- Mönster för horisontell partitionering. Indextabellmönstret används ofta tillsammans med data som har partitionerats horisontellt (shards). Mönstret för horisontell partitionering ger mer information om hur du kan dela upp ett datalager i en uppsättning horisontella partitioner (shards).
- Mönster för materialiserad vy. I stället för att indexera data som stöd för frågor som sammanfattar data kan det vara mer effektivt att skapa en materialiserad datavy. Beskriver hur du kan använda effektiva sammanfattningsfrågor genom att generera förifyllda datavyer.