Samordna de åtgärder som utförs av en samling samverkande instanser i ett distribuerat program genom att välja en instans som ska ansvara för att hantera de andra. Det kan hjälpa dig att säkerställa att instanser inte står i konflikt med varandra, orsakar konkurrens om delade resurser eller oavsiktligen stör det arbete som andra instanser utför.
Kontext och problem
Ett normalt molnprogram har många åtgärder som arbetar på ett samordnat sätt. Alla dessa uppgifter kan vara instanser som kör samma kod och kräver åtkomst till samma resurser, eller så kan de arbeta tillsammans parallellt för att utföra de enskilda delarna av en komplex beräkning.
Aktivitetsinstanserna kan köras separat under en stor del av tiden, men det kan också vara nödvändigt att samordna åtgärderna för varje instans för att säkerställa att de inte står i konflikt, orsakar konkurrens om delade resurser eller oavsiktligt stör det arbete som andra uppgiftsinstanser utför.
Till exempel:
- I ett molnbaserat system som implementerar horisontell skalning kan flera instanser av samma uppgift köras samtidigt, så att varje instans betjänar olika användare. Om dessa instanser skriver till en delad resurs är det nödvändigt att samordna deras åtgärder för att förhindra att varje instans skriver över de ändringar som har gjorts av de andra.
- Om uppgifterna utför enskilda delar av en komplex beräkning parallellt måste resultaten aggregeras när alla är klara.
Uppgiftsinstanserna är peers, så det finns ingen naturlig ledare som kan fungera som koordinator eller aggregator.
Lösning
En enskild uppgiftsinstans bör väljas ut att fungera som ledare, och den här instansen bör koordinera de åtgärder som utförs av de andra underordnade uppgiftsinstanserna. Om alla uppgiftsinstanser kör samma kod kan alla fungera som ledare. Därför måste valprocessen hanteras noggrant för att förhindra att två eller flera instanser tar över ledarpositionen samtidigt.
Systemet måste tillhandahålla en stabil metod för att välja ledare. Den här metoden måste klara händelser som nätverksavbrott eller processfel. I många lösningar övervakar de underordnade uppgiftsinstanserna ledaren via någon typ av pulsslagsmetod, eller genom avsökning. Om den utsedda ledaren plötsligt slutar fungera, eller om ett nätverksfel gör att ledaren inte är tillgänglig för de underordnade uppgiftsinstanserna, måste de välja en ny ledare.
Det finns flera strategier för att välja en ledare bland en uppsättning uppgifter i en distribuerad miljö, inklusive:
- Tävla för att hämta en delad distribuerad mutex. Den första uppgiftsinstansen som hämtar mutex är ledaren. Systemet måste dock se till att om ledaren slutar att fungera eller kopplas bort från resten av systemet måste mutex frigöras för att tillåta att en annan uppgiftsinstans blir ledare. Den här strategin visas i exemplet nedan.
- Implementera en av de vanliga valalgoritmerna för ledare, till exempel Bully Algorithm, Raft Consensus Algorithm eller Ring Algorithm. Dessa algoritmer förutsätter att varje kandidat i valet har ett unikt ID och att den kan kommunicera med de andra kandidaterna på ett tillförlitligt sätt.
Problem och överväganden
Tänk på följande när du bestämmer hur du ska implementera mönstret:
- Processen med att välja en ledare ska vara motståndskraftig mot tillfälliga och permanenta fel.
- Det måste vara möjligt att identifiera när det har blivit fel på ledaren eller om den på annat sätt har blivit otillgänglig (t.ex. på grund av ett kommunikationsfel). Hur snabb identifiering som krävs beror på systemet. Vissa system kanske kan fungera en kort tid utan en ledare, medan ett tillfälligt fel åtgärdas. I andra fall kan det vara nödvändigt att identifiera ett fel hos en ledare direkt och utlösa ett nytt val.
- I ett system som implementerar horisontell autoskalning kan ledaren avslutas om systemet skalas tillbaka och stänger av några av bearbetningsresurserna.
- Med hjälp av en delad distribuerad mutex införs ett beroende till den externa tjänsten som tillhandahåller mutex. Tjänsten utgör en felkritisk systemdel. Om den av någon anledning blir otillgänglig kan systemet inte välja en ledare.
- En enkel metod är att använda en enda dedikerad process som ledare. Om det blir fel på processen kan det dock uppstå en avsevärd fördröjning när den startas om. Den fördröjning som blir resultatet kan påverka prestanda och svarstider för andra processer om de väntar på att ledaren ska samordna en åtgärd.
- Implementering av en av algoritmerna för val av ledare ger den största flexibiliteten för att anpassa och optimera koden.
- Undvik att göra ledaren till en flaskhals i systemet. Syftet med ledaren är att samordna arbetet med de underordnade uppgifterna, och det behöver inte nödvändigtvis delta i själva det här arbetet , även om det borde kunna göra det om uppgiften inte väljs som ledare.
När du ska använda det här mönstret
Använd det här mönstret när uppgifterna som finns i ett distribuerat program, t.ex. en lösning i en molnvärd, behöver samordnas noggrant och det inte finns någon naturlig ledare.
Det här mönstret är kanske inte användbart om:
- Det finns en naturlig ledare eller dedikerad process som alltid kan fungera som ledare. Det kan till exempel vara möjligt att implementera en singleton-process som samordnar uppgiftsinstanserna. Om den här processen misslyckas eller slutar fungera kan systemet stänga av och starta om den.
- Samordningen mellan uppgifter kan uppnås med hjälp av en lättare metod. Om exempelvis flera uppgiftsinstanser helt enkelt behöver samordnad åtkomst till en delad resurs är det en bättre lösning att använda optimistisk eller pessimistisk låsning för att styra åtkomsten.
- En lösning från tredje part, till exempel Apache Zookeper , kan vara en effektivare lösning.
Design av arbetsbelastning
En arkitekt bör utvärdera hur leadervalsmönstret kan användas i arbetsbelastningens design för att uppfylla de mål och principer som beskrivs i grundpelarna i Azure Well-Architected Framework. Till exempel:
| Grundpelare | Så här stöder det här mönstret pelarmål |
|---|---|
| Beslut om tillförlitlighetsdesign hjälper din arbetsbelastning att bli motståndskraftig mot fel och se till att den återställs till ett fullt fungerande tillstånd när ett fel inträffar. | Det här mönstret minskar effekten av nodfel genom att omdirigera arbetet på ett tillförlitligt sätt. Den implementerar även redundans via konsensusalgoritmer när en ledare slutar fungera. - RE:05 Redundans - RE:07 Självåterställning |
Som med alla designbeslut bör du överväga eventuella kompromisser mot målen för de andra pelarna som kan införas med det här mönstret.
Exempel
Leader Election-exemplet på GitHub visar hur du använder ett lån på en Azure Storage-blob för att tillhandahålla en mekanism för att implementera en delad, distribuerad mutex. Den här mutexen kan användas för att välja en ledare bland en grupp tillgängliga arbetsinstanser. Den första instansen för att förvärva lånet väljs till ledare och förblir ledare tills det släpper lånet eller inte kan förnya lånet. Andra arbetsinstanser kan fortsätta att övervaka bloblånet om ledaren inte längre är tillgänglig.
Ett blob-lån är ett exklusivt skrivskydd över en blob. En enda blob kan vara föremål för endast ett lån vid en viss tidpunkt. En arbetsinstans kan begära ett lån över en angiven blob och beviljas lånet om ingen annan arbetsinstans har ett lån över samma blob. Annars utlöser begäran ett undantag.
Om du vill undvika att en felad leader-instans behåller lånet på obestämd tid anger du en livslängd för lånet. Lånet blir tillgängligt när den löper ut. Men även om en instans har lånet kan den begära att lånet förnyas, och det kommer att beviljas lånet under ytterligare en tidsperiod. Leader-instansen kan kontinuerligt upprepa den här processen om den vill behålla lånet. Mer information om lån av en blob finns i Lease Blob (REST API) (Låna blob (REST API)).
Klassen BlobDistributedMutex i C#-exemplet nedan innehåller den RunTaskWhenMutexAcquired metod som gör det möjligt för en arbetsinstans att försöka skaffa ett lån över en angiven blob. Information om bloben (namn, container och lagringskonto) överförs till konstruktorn i ett BlobSettings-objekt när BlobDistributedMutex-objektet skapas (det här objektet är en enkel struct som ingår i exempelkoden). Konstruktorn accepterar också en Task som refererar till den kod som arbetsinstansen ska köra om den hämtar lånet över bloben och väljs till ledare. Tänk på att koden som hanterar de lägre detaljnivåerna för att inhämta lånet implementeras i en separat hjälparklass som heter BlobLeaseManager.
public class BlobDistributedMutex
{
...
private readonly BlobSettings blobSettings;
private readonly Func<CancellationToken, Task> taskToRunWhenLeaseAcquired;
...
public BlobDistributedMutex(BlobSettings blobSettings,
Func<CancellationToken, Task> taskToRunWhenLeaseAcquired, ... )
{
this.blobSettings = blobSettings;
this.taskToRunWhenLeaseAcquired = taskToRunWhenLeaseAcquired;
...
}
public async Task RunTaskWhenMutexAcquired(CancellationToken token)
{
var leaseManager = new BlobLeaseManager(blobSettings);
await this.RunTaskWhenBlobLeaseAcquired(leaseManager, token);
}
...
Metoden RunTaskWhenMutexAcquired i kodexemplet ovan anropar metoden RunTaskWhenBlobLeaseAcquired som visas i följande kodexempel för att faktiskt inhämta lånet. Metoden RunTaskWhenBlobLeaseAcquired körs asynkront. Om lånet har förvärvats har arbetsinstansen valts till ledare. Syftet med ombudet taskToRunWhenLeaseAcquired är att utföra det arbete som samordnar de andra arbetsinstanserna. Om lånet inte förvärvas har en annan arbetsinstans valts som ledare och den aktuella arbetsinstansen förblir underordnad. Tänk på att metoden TryAcquireLeaseOrWait är en hjälpkomponentmetod som använder BlobLeaseManager-objektet för att inhämta lånet.
private async Task RunTaskWhenBlobLeaseAcquired(
BlobLeaseManager leaseManager, CancellationToken token)
{
while (!token.IsCancellationRequested)
{
// Try to acquire the blob lease.
// Otherwise wait for a short time before trying again.
string? leaseId = await this.TryAcquireLeaseOrWait(leaseManager, token);
if (!string.IsNullOrEmpty(leaseId))
{
// Create a new linked cancellation token source so that if either the
// original token is canceled or the lease can't be renewed, the
// leader task can be canceled.
using (var leaseCts =
CancellationTokenSource.CreateLinkedTokenSource(new[] { token }))
{
// Run the leader task.
var leaderTask = this.taskToRunWhenLeaseAcquired.Invoke(leaseCts.Token);
...
}
}
}
...
}
Uppgiften som startas av ledaren körs också asynkront. När den här uppgiften körs försöker metoden RunTaskWhenBlobLeaseAcquired som visas i följande kodexempel förnya lånet regelbundet. Detta hjälper till att säkerställa att arbetsinstansen förblir ledare. I exempellösningen är fördröjningen mellan förnyelsebegäranden mindre än den tid som angetts för lånets varaktighet för att förhindra att en annan arbetsinstans väljs till ledare. Om förnyelsen misslyckas av någon anledning avbryts den ledarspecifika uppgiften.
Om lånet inte förnyas eller om aktiviteten avbryts (eventuellt till följd av att arbetsinstansen stängs av) släpps lånet. I det här läget kan den här eller en annan arbetsinstans väljas som ledare. Kodavsnittet nedan visar den här delen av processen.
private async Task RunTaskWhenBlobLeaseAcquired(
BlobLeaseManager leaseManager, CancellationToken token)
{
while (...)
{
...
if (...)
{
...
using (var leaseCts = ...)
{
...
// Keep renewing the lease in regular intervals.
// If the lease can't be renewed, then the task completes.
var renewLeaseTask =
this.KeepRenewingLease(leaseManager, leaseId, leaseCts.Token);
// When any task completes (either the leader task itself or when it
// couldn't renew the lease) then cancel the other task.
await CancelAllWhenAnyCompletes(leaderTask, renewLeaseTask, leaseCts);
}
}
}
}
...
}
Metoden KeepRenewingLease är en annan hjälpkomponentmetod som använder BlobLeaseManager-objektet för att förnya lånet. Metoden CancelAllWhenAnyCompletes avbryter de uppgifter som anges som de första två parametrarna. Följande diagram visar hur man använder BlobDistributedMutex-klassen för att välja en ledare och köra en uppgift som samordnar åtgärder.
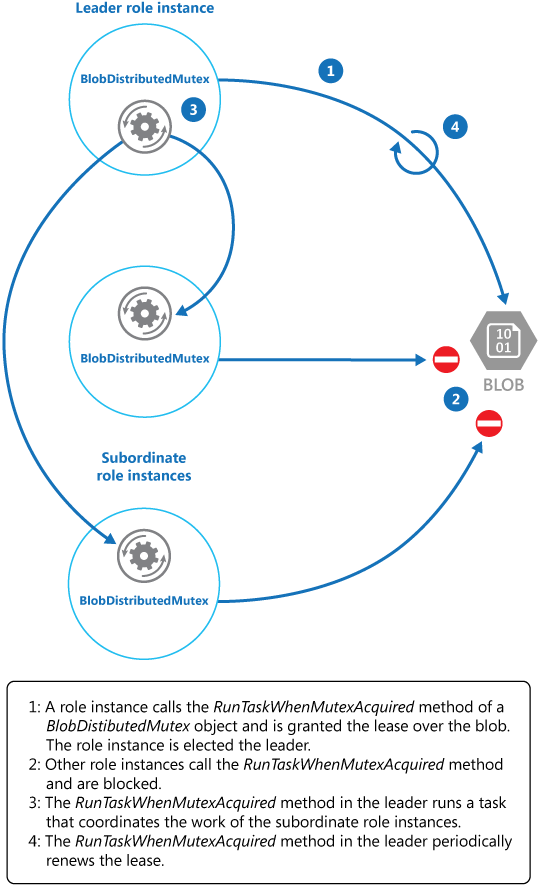
Följande kodexempel visar hur du BlobDistributedMutex använder klassen i en arbetsinstans. Den här koden hämtar ett lån över en blob med namnet MyLeaderCoordinatorTask i lånecontainern Azure Blob Storage och anger att koden som definierats i MyLeaderCoordinatorTask metoden ska köras om arbetsinstansen väljs till ledare.
// Create a BlobSettings object with the connection string or managed identity and the name of the blob to use for the lease
BlobSettings blobSettings = new BlobSettings(storageConnStr, "leases", "MyLeaderCoordinatorTask");
// Create a new BlobDistributedMutex object with the BlobSettings object and a task to run when the lease is acquired
var distributedMutex = new BlobDistributedMutex(
blobSettings, MyLeaderCoordinatorTask);
// Wait for completion of the DistributedMutex and the UI task before exiting
await distributedMutex.RunTaskWhenMutexAcquired(cancellationToken);
...
// Method that runs if the worker instance is elected the leader
private static async Task MyLeaderCoordinatorTask(CancellationToken token)
{
...
}
Tänk på följande om exempellösningen:
- Bloben är en felkritisk systemdel. Om blobtjänsten blir otillgänglig eller inte är tillgänglig kan ledaren inte förnya lånet och ingen annan arbetsinstans kan hämta lånet. I det här fallet kommer ingen arbetsinstans att kunna fungera som ledare. Blob-tjänsten har dock utformats för att vara elastisk, så det anses vara extremt osannolikt att blob-tjänsten slutar att fungera helt.
- Om uppgiften som utförs av ledaren stannar kan ledaren fortsätta att förnya lånet, vilket hindrar andra arbetsinstanser från att förvärva lånet och ta över ledarpositionen för att samordna uppgifter. I verkligheten ska ledarens hälsotillstånd kontrolleras regelbundet.
- Valprocessen är icke-deterministisk. Du kan inte göra några antaganden om vilken arbetsinstans som ska hämta bloblånet och bli ledare.
- Bloben som används som mål för blob-lånet ska inte användas i något annat syfte. Om en arbetsinstans försöker lagra data i den här blobben är dessa data inte tillgängliga om inte arbetsinstansen är ledare och innehar bloblånet.
Nästa steg
Följande riktlinjer kan även vara relevanta när du implementerar det här mönstret:
- Det här mönstret har ett nedladdningsbart exempelprogram.
- Vägledning om autoskalning. Det går att starta och stoppa instanser av uppgiftsvärdarna när belastningen på programmet varierar. Autoskalning kan hjälpa till att underhålla dataflöde och prestanda under perioder med högre belastning.
- Det aktivitetsbaserade asynkrona mönstret.
- Ett exempel som illustrerar Bully Algorithm.
- Ett exempel som illustrerar Ring Algorithm.
- Apache Curator, ett klientbibliotek för Apache ZooKeeper.
- Artikeln Lease Blob (REST API) (Låna blob (REST API)) på MSDN.