Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Azure
Gör så att ett program kan hantera tillfälliga fel vid försök att ansluta till en tjänst eller nätverksresurs, genom att transparent försöka utföra den misslyckade åtgärden igen. Detta kan förbättra stabiliteten i programmet.
Kontext och problem
Ett program som kommunicerar med element som körs i molnet måste kunna känna av tillfälliga problem som uppstår i den här miljön. Fel omfattar tillfällig avbruten nätverksanslutning till komponenter och tjänster, att en tjänst är tillfälligt otillgänglig eller att tidsgränser uppnås när en tjänst är upptagen.
Sådana fel brukar vara självkorrigerande, och om åtgärden som utlöste felet upprepas efter en lämplig fördröjning kan den troligtvis genomföras. En databastjänst som bearbetar ett stort antal samtidiga begäranden kan till exempel implementera en begränsningsstrategi som tillfälligt avvisar ytterligare begäranden tills dess arbetsbelastning har minskat. Ett programs åtkomstförsök till databasen kan misslyckas, men kan lyckas vid nästa försök efter en viss fördröjning.
Lösning
I molnet bör tillfälliga fel förväntas och ett program bör utformas för att hantera dem elegant och transparent. Detta minimerar de effekter som fel kan ha på de affärsuppgifter som programmet utför. Det vanligaste designmönstret att hantera är att införa en återförsöksmekanism.
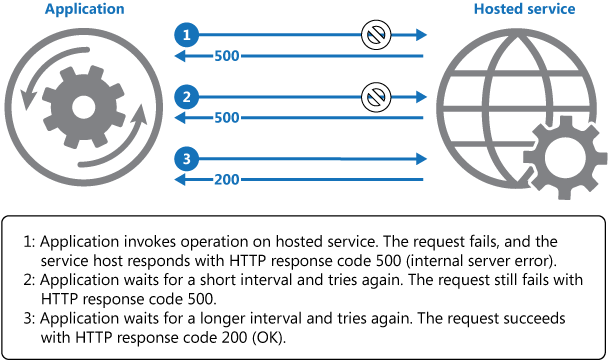
Diagrammet ovan visar hur du anropar en åtgärd i en värdbaserad tjänst med hjälp av en återförsöksmekanism. Om begäran misslyckas efter ett fördefinierat antal försök, bör programmet hantera felet som ett undantag och utföra tillämpliga åtgärder.
Kommentar
På grund av den vanliga typen av tillfälliga fel är inbyggda återförsöksmekanismer nu tillgängliga i många klientbibliotek och molntjänster, med viss konfigurerbarhet för antalet maximala återförsök, fördröjningen mellan återförsök och andra parametrar. Microsoft Entity Framework- tillhandahåller möjligheter att försöka igen misslyckade databasåtgärder.
Återförsöksstrategier
Om ett program upptäcker ett fel när en begäran skickas till en fjärrtjänst kan det hantera felet med följande åtgärder:
Avbryta. Om det indikeras att felet inte är tillfälligt eller troligen inte kommer att lyckas om försöket upprepas, bör programmet avbryta åtgärden och rapportera undantaget.
Försök igen omedelbart. Om det specifika fel som rapporteras är ovanligt eller ovanligt, till exempel om ett nätverkspaket blir skadat när det skickades, kan det bästa sättet vara att omedelbart försöka begära igen.
Försöka igen efter en kort stund. Om felet orsakas av en av de vanligare anslutningarna eller upptagna felen kan nätverket eller tjänsten behöva en kort period medan anslutningsproblemen korrigeras eller kvarvarande arbete rensas, så programmatiskt fördröjning av återförsöket är en bra strategi. I många fall bör perioden mellan återförsök väljas för att sprida begäranden från flera instanser av programmet så jämnt som möjligt för att minska risken för att en upptagen tjänst fortsätter att överbelastas.
Om en begäran fortfarande misslyckas kan programmet vänta innan ett nytt försök görs. Om det behövs kan processen upprepas med längre perioder mellan återförsöken, tills högsta antal försök för begäran har gjorts. Fördröjningen kan ökas stegvis eller exponentiellt, beroende på vilken typ av fel det handlar om och sannolikheten för att det korrigeras under denna period.
I programmet ska alla försök att komma åt en fjärrtjänst ingå i kod som implementerar en återförsöksprincip, och som matchar en av strategierna som anges ovan. Begäranden som skickas till olika tjänster kan behöva följa olika principer.
Information om fel och misslyckade åtgärder ska loggas i ett program. Den här informationen är användbar för operatorerna. Med detta sagt är det bäst att logga tidiga fel som informationsposter och endast fel vid det sista omförsöket som ett verkligt fel för att undvika översvämningsoperatorer med aviseringar om åtgärder där efterföljande försök lyckades. Här är ett exempel på hur den här loggningsmodellen skulle se ut.
Om en tjänst ofta är otillgänglig eller upptagen brukar det bero på att dess resurser är slut. Du kan minska frekvensen för sådana fel genom att skala tjänsten. Anta att en databastjänst ständigt överbelastas. Då kan det vara ett alternativ att partitionera databasen så att belastningen fördelas på flera servrar.
Problem och överväganden
När du bestämmer hur det här mönstret ska implementeras bör du överväga följande punkter.
Påverkan på prestanda
Återförsöksprincipen ska anpassas efter verksamhetsbehoven för programmet och typen av fel. För vissa icke-kritiska åtgärder är det bättre att misslyckas snabbt i stället för att försöka igen flera gånger och påverka programmets dataflöde. I ett interaktivt webbprogram som har åtkomst till en fjärrtjänst är det till exempel bättre att misslyckas efter ett mindre antal återförsök med bara en kort fördröjning mellan återförsök och visar ett lämpligt meddelande för användaren (till exempel "försök igen senare"). För batchprogram kan det vara lämpligare att öka antalet återförsök med fördröjningar som ökar exponentiellt mellan försöken.
En aggressiv återförsöksprincip med minimal fördröjning mellan försöken och ett stort antal återförsök kan ha negativ inverkan på en belastad tjänst som nästan har nått sin kapacitet. En sådan återförsöksprincip kan också påverka svarstiden för programmet om det försöker utföra en åtgärd som misslyckas upprepade gånger.
Om en begäran fortfarande misslyckas efter ett stort antal återförsök är det bättre för programmet att förhindra att ytterligare begäranden går till samma resurs och rapporterar ett fel omedelbart. När perioden upphör kan programmet prova med en eller två begäranden för att fastställa om dessa genomförs. Mer information om den här strategin finns i Mönster för kretsbrytare.
Idempotens
Fastställ om åtgärden är idempotent. Om så är fallet går det bra att försöka igen. Om så inte är fallet kan återförsök medföra att åtgärden körs mer än en gång, med oväntade sidoeffekter. En tjänst kan till exempel ta emot en begäran och bearbeta den, men inte skicka ett svar. I sådana fall kan återförsökslogiken kanske skicka begäran igen, förutsatt att den första inte mottogs.
Undantagstyp
En begäran till en tjänst kan misslyckas av olika orsaker som ger upphov till olika undantag beroende på felets art. Vissa undantag indikerar ett fel som kan lösas snabbt, medan andra indikerar att felet är mer långvarigt. Det är bra om återförsöksprincipens tid mellan återförsök justeras utifrån typen av undantag.
Transaktionskonsekvens
Ta med i beräkningen hur återförsök för en åtgärd som är en del av en transaktion påverkar hela transaktionskonsekvensen. Finjustera återförsöksprincipen för transaktionsåtgärder för största möjlighet att lyckas och minska behovet av att ångra alla transaktionsstegen.
Allmän vägledning
Se till att all återförsökskod testas fullständigt mot olika feltillstånd. Kontrollera att det inte allvarligt påverkar programmets prestanda eller tillförlitlighet, orsakar överdriven belastning på tjänster och resurser eller genererar konkurrensförhållanden eller flaskhalsar.
Implementera endast återförsökslogik där hela sammanhanget för en misslyckad åtgärd har tolkats. Anta att en aktivitet som innehåller en återförsöksprincip anropar en annan aktivitet som också innehåller en återförsöksprincip. Det här extra återförsökslagret kan lägga till långa fördröjningar i bearbetningen. Det kan vara bättre att konfigurera aktiviteten på lägre nivå så att den misslyckas snabbt och rapporterar felorsaken till aktiviteten bakom anropet. Aktiviteten på högre nivå kan sedan hantera felet utifrån sin egen princip.
Logga alla anslutningsfel som orsakar ett nytt försök så att underliggande problem med programmet, tjänsterna eller resurserna kan identifieras.
Undersök de fel som är mest sannolika för en tjänst eller en resurs för att ta reda på om de förväntas vara långvariga eller permanenta. Om så är fallet är det bättre att felet hanteras som ett undantag. Programmet kan rapportera eller logga undantaget, och sedan fortsätta genom att anropa en annan tjänst (om en sådan finns) eller genom att tillhandahålla försämrad funktionalitet. Mer information om att identifiera och hantera långvariga fel finns på sidan om kretsbrytarmönstret.
När du ska använda det här mönstret
Använd det här mönstret om det uppstår tillfälliga fel i ett program när det interagerar med en fjärrtjänst eller ansluter till en fjärresurs. Dessa fel förväntas vara kortvariga och när ett återförsök görs för en begäran som misslyckats kan det ge ett lyckat resultat.
Det här mönstret är kanske inte användbart om:
- Ett fel troligtvis är långvarigt, eftersom detta kan påverka svarstiden för ett program. Programmet förlorar tid och resurser på att försöka upprepa en begäran som troligen kommer att misslyckas.
- Misslyckanden som inte beror på tillfälliga fel hanteras, till exempel interna undantag orsakade av fel i affärslogiken i ett program.
- Det är ett alternativ till att åtgärda skalningsproblem i ett system. Om det ofta uppstår upptaget-fel i ett program, brukar det vara en indikering på att tjänsten eller resursen ifråga bör skalas upp.
Design av arbetsbelastning
En arkitekt bör utvärdera hur återförsöksmönstret kan användas i arbetsbelastningens design för att uppfylla de mål och principer som beskrivs i grundpelarna i Azure Well-Architected Framework. Till exempel:
| Grundpelare | Så här stöder det här mönstret pelarmål |
|---|---|
| Beslut om tillförlitlighetsdesign hjälper din arbetsbelastning att bli motståndskraftig mot fel och se till att den återställs till ett fullt fungerande tillstånd när ett fel inträffar. | Att minimera tillfälliga fel i ett distribuerat system är en kärnteknik för att förbättra en arbetsbelastnings motståndskraft. - RE:07 Självbevarande - RE:07 Tillfälliga fel |
Som med alla designbeslut bör du överväga eventuella kompromisser mot målen för de andra pelarna som kan införas med det här mönstret.
Exempel
Se guiden Implementera en återförsöksprincip med .NET för ett detaljerat exempel med hjälp av Azure SDK med inbyggt återförsöksmekanismstöd.
Nästa steg
Innan du skriver anpassad logik för återförsök bör du överväga att använda ett allmänt ramverk som Polly för .NET eller Resilience4j för Java.
När du bearbetar kommandon som ändrar affärsdata bör du vara medveten om att återförsök kan leda till att åtgärden utförs två gånger, vilket kan vara problematiskt om åtgärden liknar att debitera en kunds kreditkort. Med hjälp av Idempotence-mönstret som beskrivs i det här blogginlägget kan du hantera dessa situationer.
Relaterade resurser
Tillförlitligt webbappmönster visar hur du tillämpar återförsöksmönstret på webbprogram som konvergerar i molnet.
För de flesta Azure-tjänster innehåller klient-SDK:erna inbyggd logik för återförsök.
Mönstret för kretsbrytare. Om ett fel förväntas vara långvarigt kan det vara lämpligare att implementera kretsbrytarmönstret. Genom att kombinera mönster för återförsök och kretsbrytare finns en omfattande metod för att hantera fel.