Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
För att optimera prestanda och skalbarhet är det viktigt att förstå de unika skalningsegenskaperna för Durable Functions. I den här artikeln förklarar vi hur arbetare skalas baserat på belastning och hur man kan justera de olika parametrarna.
Arbetsskalning
En grundläggande fördel med konceptet med uppgiftshubben är att antalet arbetare som bearbetar arbetsobjekt för aktivitetshubben kan justeras kontinuerligt. I synnerhet kan program lägga till fler arbetare (skala ut) om arbetet behöver bearbetas snabbare och kan ta bort arbetare (skala in) om det inte finns tillräckligt med arbete för att hålla arbetarna upptagna. Det går till och med att skala till noll om aktivitetshubben är helt inaktiv. När skalas till noll finns det inga arbetare alls. endast skalningskontrollanten och lagringen måste förbli aktiv.
Följande diagram illustrerar det här konceptet:
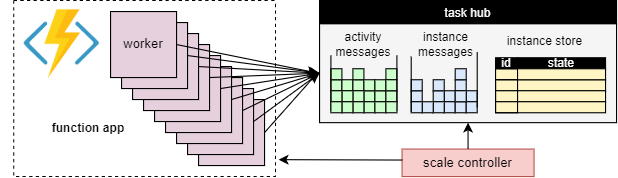
Automatisk skalning
Precis som med alla Azure Functions som körs i förbruknings- och Elastic Premium-abonnemangen har Durable Functions stöd för automatisk skalning via Skalningskontrollanten för Azure Functions. Skalningskontrollanten övervakar hur länge meddelanden och uppgifter måste vänta innan de bearbetas. Baserat på dessa svarstider kan den bestämma om du vill lägga till eller ta bort arbetare.
Kommentar
Från och med Durable Functions 2.0 kan funktionsappar konfigureras att köras inom VNET-skyddade tjänstslutpunkter i Elastic Premium-planen. I den här konfigurationen initierar Durable Functions skalningsbegäranden i stället för skalningskontrollanten. Mer information finns i Körningsskalningsövervakning.
I en premiumplan kan automatisk skalning bidra till att hålla antalet arbetare (och därmed driftskostnaderna) ungefär proportionella mot den belastning som programmet upplever.
CPU-användning
Orchestrator-funktioner kör sin logik flera gånger på grund av deras beteende för uppspelning. Det är därför viktigt att orchestrator-funktionstrådar inte utför CPU-intensiva uppgifter, utför I/O eller blockerar av någon anledning. Allt arbete som kan kräva I/O, blockering eller flera trådar bör flyttas till aktivitetsfunktioner.
Aktivitetsfunktioner har samma beteenden som vanliga köutlösta funktioner. De kan utföra I/O på ett säkert sätt, köra processorintensiva åtgärder och använda flera trådar. Eftersom aktivitetsutlösare är tillståndslösa kan de fritt skala ut till ett obundet antal virtuella datorer.
Entitetsfunktioner körs också på en enda tråd och åtgärder bearbetas en i taget. Entitetsfunktioner har dock inga begränsningar för vilken typ av kod som kan köras.
Funktionstimeouter
Aktivitets-, orchestrator- och entitetsfunktioner omfattas av samma funktionstimeouter som alla Azure Functions. Som en allmän regel behandlar Durable Functions funktionstimeouter på samma sätt som ohanterade undantag som genereras av programkoden.
Om en aktivitet till exempel överskrider tidsgränsen registreras funktionskörningen som ett fel och orkestreringshanteraren meddelas och hanterar tidsgränsen precis som andra undantag: återförsök görs om det anges av anropet eller en undantagshanterare kan köras.
Batchbearbetning av entitetsåtgärd
För att förbättra prestanda och minska kostnaderna kan ett enskilt arbetsobjekt köra en hel batch med entitetsåtgärder. I förbrukningsplaner faktureras varje batch sedan som en enda funktionskörning.
Som standard är den maximala batchstorleken 50 för förbrukningsplaner och 5 000 för alla andra planer. Den maximala batchstorleken kan också konfigureras i host.json-filen. Om den maximala batchstorleken är 1 inaktiveras batchbearbetningen effektivt.
Kommentar
Om enskilda entitetsåtgärder tar lång tid att köra kan det vara fördelaktigt att begränsa den maximala batchstorleken för att minska risken för funktionstimeouter, särskilt i förbrukningsplaner.
Cachelagring av instanser
För att bearbeta ett orkestreringsarbetsobjekt måste en arbetare vanligtvis både
- Hämta orkestreringshistoriken.
- Spela upp orchestrator-koden igen med hjälp av historiken.
Om samma arbetare bearbetar flera arbetsobjekt för samma orkestrering kan lagringsprovidern optimera den här processen genom att cachelagra historiken i arbetarminnet, vilket eliminerar det första steget. Dessutom kan den cachelagrar mellankörningsorkestratorn, vilket eliminerar det andra steget, historikreprisen också.
Den typiska effekten av cachelagring är minskad I/O mot den underliggande lagringstjänsten och övergripande förbättrat dataflöde och svarstid. Å andra sidan ökar cachelagring minnesförbrukningen för arbetaren.
Cachelagring av instanser stöds för närvarande av Azure Storage-providern och av Netherite-lagringsprovidern. Tabellen nedan innehåller en jämförelse.
| Azure Storage-provider | Netherite-lagringsprovider | MSSQL-lagringsprovider | |
|---|---|---|---|
| Cachelagring av instanser | Stöds Endast (.NET in-process worker) |
Stöds | Stöds inte |
| Standardinställningen | Inaktiverat | Aktiverat | saknas |
| Mekanism | Utökade sessioner | Instanscache | saknas |
| Dokumentation | Se Utökade sessioner | Se Instanscache | saknas |
Dricks
Cachelagring kan minska hur ofta historier spelas upp, men det kan inte eliminera repris helt och hållet. När du utvecklar orchestrators rekommenderar vi starkt att du testar dem på en konfiguration som inaktiverar cachelagring. Det här tvångsuppspelningsbeteendet kan vara användbart för att identifiera överträdelser av funktionskodsbegränsningar för orchestrator vid utveckling.
Jämförelse av cachelagringsmekanismer
Leverantörerna använder olika mekanismer för att implementera cachelagring och erbjuder olika parametrar för att konfigurera cachelagringsbeteendet.
-
Utökade sessioner, som används av Azure Storage-providern, håller orkestratorer mitt i körningen i minnet tills de är inaktiva under en tid. Parametrarna för att styra den här mekanismen är
extendedSessionsEnabledochextendedSessionIdleTimeoutInSeconds. Mer information finns i avsnittet Utökade sessioner i dokumentationen för Azure Storage-providern.
Kommentar
Utökade sessioner stöds endast i .NET in-process worker.
- Instanscachen, som används av Netherite-lagringsprovidern, behåller tillståndet för alla instanser, inklusive deras historia, i arbetarens minne, samtidigt som det totala minnet som används hålls. Om cachestorleken överskrider den gräns som konfigurerats av
InstanceCacheSizeMBavlägsnas de senast använda instansdata. OmCacheOrchestrationCursorsvärdet är true lagrar cacheminnet även mellankörningsorkestrarna tillsammans med instanstillståndet. Mer information finns i avsnittet Instanscache för Netherite Storage Provider-dokumentationen.
Kommentar
Instanscacheminnen fungerar för alla språk-SDK:er, men alternativet CacheOrchestrationCursors är endast tillgängligt för .NET in-process worker.
Samtidighetsbegränsningar
En enskild arbetsinstans kan köra flera arbetsobjekt samtidigt. Detta bidrar till att öka parallelliteten och utnyttja arbetarna mer effektivt. Men om en arbetare försöker bearbeta för många arbetsobjekt samtidigt kan det uttömma dess tillgängliga resurser, till exempel CPU-belastningen, antalet nätverksanslutningar eller det tillgängliga minnet.
För att säkerställa att en enskild arbetare inte överkommer kan det vara nödvändigt att begränsa samtidigheten per instans. Genom att begränsa antalet funktioner som körs samtidigt på varje arbetare kan vi undvika att uttömma resursgränserna för den arbetaren.
Kommentar
Samtidighetsbegränsningarna gäller endast lokalt för att begränsa vad som bearbetas per arbetare. Dessa begränsningar begränsar därför inte systemets totala dataflöde.
Dricks
I vissa fall kan begränsning av samtidighet per arbetare faktiskt öka systemets totala dataflöde. Detta kan inträffa när varje arbetare tar mindre arbete, vilket gör att skalningskontrollanten lägger till fler arbetare för att hålla jämna steg med köerna, vilket sedan ökar det totala dataflödet.
Konfiguration av begränsningar
Aktivitets-, orchestrator- och entitetsfunktionens samtidighetsgränser kan konfigureras i filen host.json . De relevanta inställningarna gäller durableTask/maxConcurrentActivityFunctions för aktivitetsfunktioner och durableTask/maxConcurrentOrchestratorFunctions för både orchestrator- och entitetsfunktioner. De här inställningarna styr det maximala antalet orkestrerings-, entitets- eller aktivitetsfunktioner som läses in i minnet på en enda arbetare.
Kommentar
Orkestreringar och entiteter läses bara in i minnet när de aktivt bearbetar händelser eller åtgärder, eller om cachelagring av instanser är aktiverat. När de har kört logiken och väntat (d.v.s. kört en await (C#) eller yield (JavaScript, Python)-instruktion i orchestrator-funktionskoden), kan de tas bort från minnet. Orkestreringar och entiteter som tas bort från minnet räknas inte mot begränsningen maxConcurrentOrchestratorFunctions . Även om miljontals orkestreringar eller entiteter är i tillståndet "Körs" räknas de bara mot begränsningsgränsen när de läses in i aktivt minne. En orkestrering som schemalägger en aktivitetsfunktion på samma sätt räknas inte mot begränsningen om orkestreringen väntar på att aktiviteten ska slutföra körningen.
Funktioner 2.0
{
"extensions": {
"durableTask": {
"maxConcurrentActivityFunctions": 10,
"maxConcurrentOrchestratorFunctions": 10
}
}
}
Functions 1.x
{
"durableTask": {
"maxConcurrentActivityFunctions": 10,
"maxConcurrentOrchestratorFunctions": 10
}
}
Språkkörningsöverväganden
Den språkkörning som du väljer kan införa strikta samtidighetsbegränsningar eller dina funktioner. Till exempel kan Durable Function-appar som skrivits i Python eller PowerShell endast ha stöd för att köra en enskild funktion i taget på en enda virtuell dator. Detta kan leda till betydande prestandaproblem om de inte redovisas noggrant. Om till exempel en orchestrator fläktar ut till 10 aktiviteter men språkkörningen begränsar samtidighet till bara en funktion, kommer 9 av de 10 aktivitetsfunktionerna att fastna i väntan på en chans att köras. Dessutom kommer dessa 9 fastnade aktiviteter inte att kunna lastbalanseras till andra arbetare eftersom Durable Functions-körningen redan har läst in dem i minnet. Detta blir särskilt problematiskt om aktivitetsfunktionerna är tidskrävande.
Om språkkörningen som du använder begränsar samtidigheten bör du uppdatera inställningarna för Durable Functions-samtidighet så att de matchar samtidighetsinställningarna för din språkkörning. Detta säkerställer att Durable Functions-körningen inte försöker köra fler funktioner samtidigt än vad som tillåts av språkkörningen, vilket gör att väntande aktiviteter kan lastbalanseras till andra virtuella datorer. Om du till exempel har en Python-app som begränsar samtidighet till 4 funktioner (den kanske bara har konfigurerats med 4 trådar i en enda språkprocess eller en tråd på 4 språkarbetsprocesser) bör du konfigurera både maxConcurrentOrchestratorFunctions och maxConcurrentActivityFunctions till 4.
Mer information och prestandarekommendationer för Python finns i Förbättra dataflödesprestanda för Python-appar i Azure Functions. De tekniker som nämns i referensdokumentationen för Python-utvecklare kan ha stor inverkan på Durable Functions-prestanda och skalbarhet.
Antal partitioner
Vissa lagringsprovidrar använder en partitioneringsmekanism och tillåter att en partitionCount parameter anges.
När du använder partitionering konkurrerar inte arbetare direkt om enskilda arbetsobjekt. I stället grupperas arbetsobjekten först i partitionCount partitioner. Dessa partitioner tilldelas sedan till arbetare. Den här partitionerade metoden för belastningsfördelning kan bidra till att minska det totala antalet lagringsåtkomster som krävs. Dessutom kan den aktivera cachelagring av instanser och förbättra lokaliteten eftersom den skapar tillhörighet: alla arbetsobjekt för samma instans bearbetas av samma arbetare.
Kommentar
Partitioneringsgränser skalas ut eftersom de flesta partitionCount arbetare kan bearbeta arbetsobjekt från en partitionerad kö.
Följande tabell visar, för varje lagringsprovider, vilka köer som partitioneras och det tillåtna intervallet och standardvärdena för parametern partitionCount .
| Azure Storage-provider | Netherite-lagringsprovider | MSSQL-lagringsprovider | |
|---|---|---|---|
| Instansmeddelanden | Partitioned | Partitioned | Inte partitionerad |
| Aktivitetsmeddelanden | Inte partitionerad | Partitioned | Inte partitionerad |
Standard partitionCount |
4 | 12 | saknas |
Maximal partitionCount |
16 | 32 | saknas |
| Dokumentation | Se Utskalning av Orchestrator | Se Överväganden för antal partitioner | saknas |
Varning
Partitionsantalet kan inte längre ändras när en aktivitetshubb har skapats. Därför är det lämpligt att ange ett tillräckligt stort värde för att hantera framtida skalningskrav för aktivitetshubbens instans.
Konfiguration av antal partitioner
Parametern partitionCount kan anges i filen host.json . Följande exempel host.json kodfragment anger durableTask/storageProvider/partitionCount egenskapen (eller durableTask/partitionCount i Durable Functions 1.x) till 3.
Durable Functions 2.x
{
"extensions": {
"durableTask": {
"storageProvider": {
"partitionCount": 3
}
}
}
}
Durable Functions 1.x
{
"extensions": {
"durableTask": {
"partitionCount": 3
}
}
}
Överväganden för att minimera svarstider för anrop
Under normala omständigheter bör begäranden om anrop (till aktiviteter, orkestrerare, entiteter osv.) bearbetas ganska snabbt. Det finns dock ingen garanti för den maximala svarstiden för någon anropsbegäran eftersom den beror på faktorer som: typen av skalningsbeteende din App Service-plan, dina samtidighetsinställningar och storleken på programmets kvarvarande uppgifter. Därför rekommenderar vi att du investerar i stresstestning för att mäta och optimera programmets svarstider.
Prestandamål
När du planerar att använda Durable Functions för ett produktionsprogram är det viktigt att tänka på prestandakraven tidigt i planeringsprocessen. Några grundläggande användningsscenarier är:
- Körning av sekventiell aktivitet: I det här scenariot beskrivs en orkestreringsfunktion som kör en serie aktivitetsfunktioner en efter en. Den liknar mest exemplet för funktionslänkning .
- Parallell aktivitetskörning: I det här scenariot beskrivs en orkestreringsfunktion som kör många aktivitetsfunktioner parallellt med mönstret-out och-in .
- Parallell svarsbearbetning: Det här scenariot är den andra halvan av mönstret-out,-in . Den fokuserar på prestanda hos fläkten. Det är viktigt att observera att till skillnad från-out görs-in av en enda orchestrator-funktionsinstans och därför bara kan köras på en enda virtuell dator.
- Extern händelsebearbetning: Det här scenariot representerar en enskild orchestrator-funktionsinstans som väntar på externa händelser, en i taget.
- Bearbetning av entitetsåtgärd: I det här scenariot testas hur snabbt en enskildräknarentitet kan bearbeta en konstant åtgärdsström.
Vi tillhandahåller dataflödesnummer för dessa scenarier i respektive dokumentation för lagringsprovidrar. Framför allt:
- Information om Azure Storage-providern finns i Prestandamål.
- Information om Netherite-lagringsprovidern finns i Grundläggande scenarier.
- information om MSSQL-lagringsprovidern finns i Referensvärden för orkestreringsdataflöde.
Dricks
Till skillnad från utspring är inaktiva fläktåtgärder begränsade till en enda virtuell dator. Om ditt program använder-out-mönstret och du är orolig för prestanda för fläktar kan du överväga att dela upp aktivitetsfunktionen i flera underorkestreringar.