Köpmodell för virtuell kärna – Azure SQL Database
Gäller för:![]() Azure SQL Database
Azure SQL Database
Den här artikeln granskar köpmodellen för virtuella kärnor för Azure SQL Database.
Översikt
En virtuell kärna (virtuell kärna) representerar en logisk processor och ger dig möjlighet att välja maskinvarans fysiska egenskaper (till exempel antalet kärnor, minnet och lagringsstorleken). Den vCore-baserade inköpsmodellen ger dig flexibilitet, kontroll, transparens för individuell resursförbrukning och ett enkelt sätt att översätta lokala arbetsbelastningskrav till molnet. Den här modellen optimerar priset och låter dig välja beräknings-, minnes- och lagringsresurser baserat på dina arbetsbelastningsbehov.
I den vCore-baserade inköpsmodellen beror dina kostnader på valet och användningen av:
- Tjänstenivå
- Konfiguration av maskinvara
- Beräkningsresurser (antalet virtuella kärnor och mängden minne)
- Reserverad databaslagring
- Faktisk lagring av säkerhetskopior
Viktigt!
Beräkningsresurser, I/O och data och logglagring debiteras per databas eller elastisk pool. Lagring av säkerhetskopior debiteras per databas. Prisinformation finns på prissättningssidan för Azure SQL Database.
Jämföra köpmodeller för virtuell kärna och DTU
Köpmodellen för virtuell kärna som används av Azure SQL Database ger flera fördelar jämfört med den DTU-baserade inköpsmodellen:
- Högre beräknings-, minnes-, I/O- och lagringsgränser.
- Val av maskinvarukonfiguration för att bättre matcha beräknings- och minneskraven för arbetsbelastningen.
- Prisrabatter för Azure Hybrid-förmån (AHB).
- Större transparens i maskinvaruinformationen som driver beräkningen, vilket underlättar planeringen för migreringar från lokala distributioner.
- Priser för reserverade instanser är endast tillgängliga för köpmodellen för virtuella kärnor.
- Högre skalningskornighet med flera tillgängliga beräkningsstorlekar.
Om du vill ha hjälp med att välja mellan köpmodellerna för virtuell kärna och DTU kan du se skillnaderna mellan de virtuella kärnor och DTU-baserade köpmodellerna
Compute
Den vCore-baserade inköpsmodellen har en etablerad beräkningsnivå och en serverlös beräkningsnivå. På den etablerade beräkningsnivån återspeglar beräkningskostnaden den totala beräkningskapacitet som kontinuerligt etablerats för programmet oberoende av arbetsbelastningsaktivitet. Välj den resursallokering som bäst passar dina affärsbehov baserat på krav på virtuell kärna och minne och skala sedan upp och ned resurser efter behov av din arbetsbelastning. På den serverlösa beräkningsnivån för Azure SQL Database skalas beräkningsresurser automatiskt baserat på arbetsbelastningskapacitet och debiteras för den mängd beräkning som används per sekund.
Sammanfattningsvis:
- Även om den etablerade beräkningsnivån tillhandahåller en viss mängd beräkningsresurser som kontinuerligt etableras oberoende av arbetsbelastningsaktivitet, skalar den serverlösa beräkningsnivån beräkningsresurser baserat på arbetsbelastningsaktivitet.
- Medan den etablerade beräkningsnivån fakturerar för mängden beräkning som har etablerats till ett fast pris per timme, faktureras den serverlösa beräkningsnivån för mängden beräkning som används per sekund.
Oavsett beräkningsnivå allokeras tre ytterligare sekundära repliker med hög tillgänglighet automatiskt på tjänstnivån Affärskritisk för att ge hög återhämtning till fel och snabba redundansväxlingar. Dessa ytterligare repliker gör kostnaden ungefär 2,7 gånger högre än den är på tjänstnivån Generell användning. På samma sätt återspeglar den högre lagringskostnaden per GB på tjänstnivån Affärskritisk högre I/O-gränser och lägre svarstid för den lokala SSD-lagringen.
I Hyperskala kontrollerar kunderna antalet ytterligare repliker med hög tillgänglighet från 0 till 4 för att få den återhämtningsnivå som krävs av deras program samtidigt som kostnaderna kontrolleras.
Mer information om beräkning i Azure SQL Database finns i Beräkningsresurser (CPU och minne).
Resursgränser
Granska de tillgängliga maskinvarukonfigurationerna för resursbegränsningar för virtuella kärnor och granska sedan resursgränserna för:
Data- och logglagring
Följande faktorer påverkar mängden lagringsutrymme som används för data och loggfiler och gäller för nivåerna Generell användning och Affärskritisk.
- Varje beräkningsstorlek stöder en konfigurerbar maximal datastorlek med standardvärdet 32 GB.
- När du konfigurerar maximal datastorlek läggs automatiskt ytterligare 30 procent av den fakturerbara lagringen till för loggfilen.
- På tjänstnivån
tempdbGenerell användning använder du lokal SSD-lagring och den här lagringskostnaden ingår i priset för virtuell kärna. - På tjänstnivån
tempdbAffärskritisk delar du lokal SSD-lagring med data och loggfiler, ochtempdblagringskostnaden ingår i priset för virtuell kärna. - På nivåerna Generell användning och Affärskritisk debiteras du för den maximala lagringsstorlek som konfigurerats för en databas eller elastisk pool.
- För SQL Database kan du välja valfri maximal datastorlek mellan 1 GB och maximal lagringsstorlek som stöds i steg om 1 GB.
Följande lagringsöverväganden gäller för Hyperskala:
- Maximal datalagringsstorlek är inställd på 100 TB och kan inte konfigureras.
- Du debiteras endast för allokerad datalagring, inte för maximal datalagring.
- Du debiteras inte för logglagring.
tempdbanvänder lokal SSD-lagring och kostnaden ingår i priset för virtuell kärna. Om du vill övervaka den aktuella allokerade och använda datalagringsstorleken i SQL Database använder du azure monitor-måtten för allocated_data_storage respektive lagring.
Om du vill övervaka den aktuella allokerade och använda lagringsstorleken för enskilda data och loggfiler i en databas med hjälp av T-SQL använder du funktionen sys.database_files och funktionen FILEPROPERTY(... , "SpaceUsed").
Dricks
Under vissa omständigheter kan du behöva krympa en databas för att frigöra outnyttjat utrymme. Mer information finns i Hantera filutrymme i Azure SQL Database.
Lagring för säkerhetskopior
Lagring för databassäkerhetskopior allokeras för att stödja funktionerna för återställning till tidpunkt (PITR) och långsiktig kvarhållning (LTR) i SQL Database. Den här lagringen är separat från data- och loggfillagring och faktureras separat.
- PITR: På nivåerna Generell användning och Affärskritisk kopieras enskilda databassäkerhetskopior automatiskt till Azure Storage. Lagringsstorleken ökar dynamiskt när nya säkerhetskopior skapas. Lagringen används av fullständiga säkerhetskopior, differentiella säkerhetskopieringar och transaktionsloggar. Lagringsförbrukningen beror på ändringshastigheten för databasen och den kvarhållningsperiod som konfigurerats för säkerhetskopior. Du kan konfigurera en separat kvarhållningsperiod för varje databas mellan 1 och 35 dagar för SQL Database. En lagringsmängd för säkerhetskopiering som är lika med den konfigurerade maximala datastorleken tillhandahålls utan extra kostnad.
- LTR: Du kan också konfigurera långsiktig kvarhållning av fullständiga säkerhetskopior i upp till 10 år. Om du konfigurerar en LTR-princip lagras dessa säkerhetskopior automatiskt i Azure Blob Storage, men du kan styra hur ofta säkerhetskopiorna kopieras. För att uppfylla olika efterlevnadskrav kan du välja olika kvarhållningsperioder för veckovisa, månatliga och/eller årliga säkerhetskopieringar. Den konfiguration du väljer avgör hur mycket lagringsutrymme som används för LTR-säkerhetskopieringar. Mer information finns i Långsiktig kvarhållning av säkerhetskopior.
Information om lagring av säkerhetskopior i Hyperskala finns i Automatiserade säkerhetskopior för Hyperskala-databaser.
Tjänstnivåer
Alternativ på tjänstnivå i köpmodellen för virtuella kärnor inkluderar Generell användning, Affärskritisk och Hyperskala. Tjänstnivån avgör vanligtvis lagringstyp och prestanda, alternativ för hög tillgänglighet och haveriberedskap samt tillgängligheten för vissa funktioner, till exempel Minnesintern OLTP.
| Användningsfall | Generell användning | Affärskritisk | Hyperskala |
|---|---|---|---|
| Bäst för | De flesta företagsarbetsbelastningar. Erbjuder budgetorienterade, balanserade och skalbara beräknings- och lagringsalternativ. | Erbjuder affärsprogram den högsta motståndskraften mot fel med hjälp av flera sekundära repliker med hög tillgänglighet och ger högsta I/O-prestanda. | Det bredaste utbudet av arbetsbelastningar, inklusive de arbetsbelastningar med mycket skalbar lagring och lässkalningskrav. Ger högre motståndskraft mot fel genom att tillåta konfiguration av mer än en sekundär replik med hög tillgänglighet. |
| Beräkningsstorlek | 2 till 128 virtuella kärnor | 2 till 128 virtuella kärnor | 2 till 128 virtuella kärnor |
| Lagringstyp | Premium-fjärrlagring (per instans) | Supersnabb lokal SSD-lagring (per instans) | Frikopplad lagring med lokal SSD-cache (per beräkningsreplik) |
| Lagringsstorlek | 1 GB – 4 TB | 1 GB – 4 TB | 10 GB – 100 TB |
| IOPS | 320 IOPS per virtuell kärna med maximalt 16 000 IOPS | 4 000 IOPS per virtuell kärna med maximalt 327 680 IOPS | 327 680 IOPS med maximal lokal SSD Hyperskala är en arkitektur med flera nivåer med cachelagring på flera nivåer. Effektiv IOPS beror på arbetsbelastningen. |
| Minne/virtuell kärna | 5,1 GB | 5,1 GB | 5,1 GB eller 10,2 GB |
| Säkerhetskopior | Ett val av geo-redundant, zonredundant eller lokalt redundant lagring av säkerhetskopiering, 1–35 dagars kvarhållning (standard 7 dagar) Långsiktig kvarhållning tillgänglig upp till 10 år |
Ett val av geo-redundant, zonredundant eller lokalt redundant lagring av säkerhetskopiering, 1–35 dagars kvarhållning (standard 7 dagar) Långsiktig kvarhållning tillgänglig upp till 10 år |
Ett val av lokalt redundant lagring (LRS), zonredundant (ZRS) eller geo-redundant lagring (GRS) Kvarhållning på 1–35 dagar (7 dagar som standard) med upp till 10 års långsiktig kvarhållning tillgänglig |
| Tillgänglighet | En replik, inga skrivskyddade repliker, zonredundant hög tillgänglighet (HA) |
Tre repliker, en skrivskalningsreplik, zonredundant hög tillgänglighet (HA) |
zonredundant hög tillgänglighet (HA) |
| Priser/fakturering | vCore, reserverad lagring och lagring av säkerhetskopior debiteras. IOPS debiteras inte. |
vCore, reserverad lagring och lagring av säkerhetskopior debiteras. IOPS debiteras inte. |
vCore för varje replik och använt lagringsutrymme debiteras. IOPS debiteras inte. |
| Rabattmodeller | Reserverade instanser Azure Hybrid-förmån (inte tillgängligt för dev/test-prenumerationer) Enterprise - och Betala per användning Dev/Test-prenumerationer |
Reserverade instanser Azure Hybrid-förmån (inte tillgängligt för dev/test-prenumerationer) Enterprise - och Betala per användning Dev/Test-prenumerationer |
Azure Hybrid-förmån (inte tillgängligt för dev/test-prenumerationer) 1 Enterprise - och Betala per användning Dev/Test-prenumerationer |
1 Förenklad prissättning för SQL Database Hyperscale kommer snart. Mer information finns i prissättningsbloggen för Hyperskala.
Mer information finns i resursbegränsningar för logisk server, enskilda databaser och pooldatabaser.
Kommentar
Mer information om serviceavtalet (SLA) finns i SLA för Azure SQL Database
Generell användning
Arkitekturmodellen för tjänstnivån Generell användning baseras på en uppdelning av beräkning och lagring. Den här arkitekturmodellen förlitar sig på hög tillgänglighet och tillförlitlighet för Azure Blob Storage som transparent replikerar databasfiler och garanterar ingen dataförlust om underliggande infrastrukturfel inträffar.
Följande bild visar fyra noder i standardarkitekturmodellen med de avgränsade beräknings- och lagringsskikten.
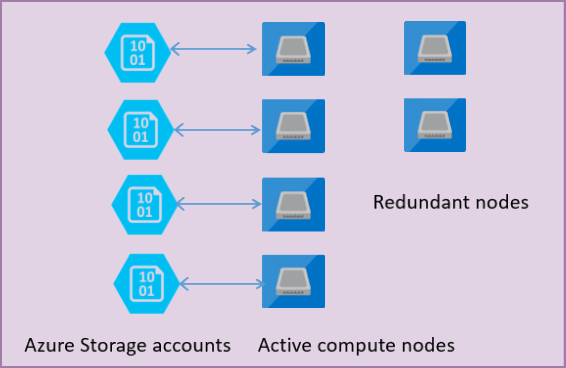
I arkitekturmodellen för tjänstnivån Generell användning finns det två lager:
- Ett tillståndslöst beräkningslager som kör
sqlservr.exeprocessen och som endast innehåller tillfälliga och cachelagrade data (till exempel plancache, buffertpool, kolumnlagringspool). Den här tillståndslösa noden drivs av Azure Service Fabric som initierar processen, kontrollerar nodens hälsotillstånd och utför redundansväxling till en annan plats om det behövs. - Ett tillståndskänsligt datalager med databasfiler (.mdf/.ldf) som lagras i Azure Blob Storage. Azure Blob Storage garanterar att inga data går förlorade för någon post som placeras i någon databasfil. Azure Storage har inbyggd datatillgänglighet/redundans som säkerställer att varje post i loggfilen eller sidan i datafilen bevaras även om processen kraschar.
När databasmotorn eller operativsystemet uppgraderas misslyckas en del av den underliggande infrastrukturen, eller om något kritiskt problem identifieras i sqlservr.exe processen flyttar Azure Service Fabric den tillståndslösa processen till en annan tillståndslös beräkningsnod. Det finns en uppsättning extra noder som väntar på att köra den nya beräkningstjänsten om en redundansväxling av den primära noden sker för att minimera redundanstiden. Data i Azure Storage-lagret påverkas inte och data-/loggfiler kopplas till den nyligen initierade processen. Den här processen garanterar 99,99 % tillgänglighet som standard och 99,995 % tillgänglighet när zonredundans är aktiverat. Det kan finnas vissa prestandaeffekter för tunga arbetsbelastningar som är under flygning på grund av övergångstid och det faktum att den nya noden börjar med kall cache.
När du ska välja den här tjänstnivån
Tjänstnivån Generell användning är standardtjänstnivån i Azure SQL Database som utformats för de flesta allmänna arbetsbelastningar. Om du behöver en fullständigt hanterad databasmotor med ett standard-SLA och lagringssvarstid mellan 5 ms och 10 ms är nivån Generell användning alternativet för dig.
Affärskritisk
Den Affärskritisk tjänstnivåmodellen baseras på ett kluster med databasmotorprocesser. Den här arkitekturmodellen förlitar sig på ett kvorum av databasmotornoder för att minimera prestandapåverkan på din arbetsbelastning, även under underhållsaktiviteter. Uppgraderingar och korrigeringar av det underliggande operativsystemet, drivrutinerna och databasmotorn sker transparent, med minimal stilleståndstid för slutanvändarna.
I Affärskritisk-modellen integreras beräkning och lagring på varje nod. Replikering av data mellan databasmotorprocesser på varje nod i ett kluster med fyra noder ger hög tillgänglighet, där varje nod använder lokalt ansluten SSD som datalagring. Följande diagram visar hur tjänstnivån Affärskritisk organiserar ett kluster med databasmotornoder i tillgänglighetsgrupprepliker.
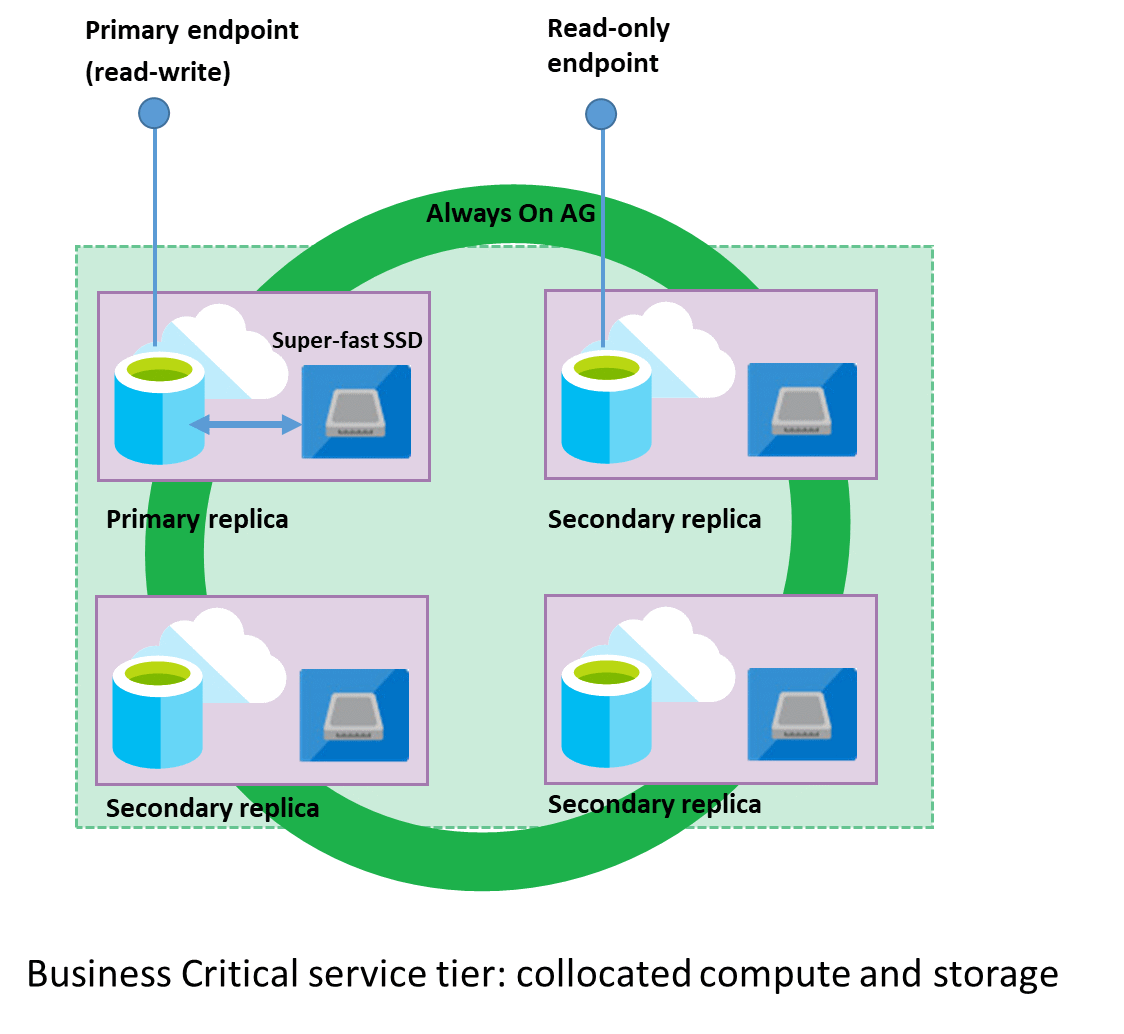
Både databasmotorprocessen och underliggande .mdf/.ldf-filer placeras på samma nod med lokalt ansluten SSD-lagring, vilket ger låg svarstid för din arbetsbelastning. Hög tillgänglighet implementeras med hjälp av teknik som liknar SQL Server AlwaysOn-tillgänglighetsgrupper. Varje databas är ett kluster med databasnoder med en primär replik som är tillgänglig för kundarbetsbelastningar och tre sekundära repliker som innehåller kopior av data. Den primära repliken skickar ständigt ändringar till de sekundära replikerna för att säkerställa att data är tillgängliga på sekundära repliker om den primära av någon anledning misslyckas. Redundans hanteras av Service Fabric och databasmotorn – en sekundär replik blir den primära och en ny sekundär replik skapas för att säkerställa att det finns tillräckligt med noder i klustret. Arbetsbelastningen omdirigeras automatiskt till den nya primära repliken.
Dessutom har Affärskritisk-klustret en inbyggd skrivskyddad utskalningsfunktion som ger en kostnadsfri skrivskyddad replik som används för att köra skrivskyddade frågor (till exempel rapporter) som inte påverkar arbetsbelastningens prestanda på din primära replik.
När du ska välja den här tjänstnivån
Tjänstnivån Affärskritisk är utformad för program som kräver svar med låg svarstid från den underliggande SSD-lagringen (1–2 ms i genomsnitt), snabbare återställning om den underliggande infrastrukturen misslyckas eller behöver avlasta rapporter, analyser och skrivskyddade frågor till den kostnadsfria läsbara sekundära repliken för den primära databasen.
De viktigaste orsakerna till varför du bör välja Affärskritisk tjänstnivå i stället för nivån Generell användning är:
- Krav på låg I/O-svarstid – arbetsbelastningar som behöver ett konsekvent snabbt svar från lagringsskiktet (1–2 millisekunder i genomsnitt) bör använda Affärskritisk nivå.
- Arbetsbelastning med rapporterings- och analysfrågor där en enda kostnadsfri sekundär skrivskyddad replik räcker.
- Högre återhämtning och snabbare återställning från fel. Om det uppstår systemfel inaktiveras databasen på den primära instansen och en av de sekundära replikerna blir omedelbart den nya primära skrivskyddade databasen som är redo att bearbeta frågor.
- Avancerat skydd mot datakorruption. Eftersom Affärskritisk-nivån använder databasrepliker i bakgrunden använder tjänsten automatisk sidreparation som är tillgänglig med speglings- och tillgänglighetsgrupper för att minimera skadade data. Om en replik inte kan läsa en sida på grund av ett dataintegritetsproblem hämtas en ny kopia av sidan från en annan replik och ersätter den olästa sidan utan dataförlust eller kundavbrott. Den här funktionen är tillgänglig på nivån Generell användning om databasen har geo-sekundär replik.
- Högre tillgänglighet – den Affärskritisk nivån i en zonkonfiguration med flera tillgängligheter ger återhämtning till zonfel och ett serviceavtal för högre tillgänglighet.
- Snabb geo-återställning – När aktiv geo-replikering konfigureras har Affärskritisk-nivån ett garanterat mål för återställningspunkt (RPO) på 5 sekunder och mål för återställningstid (RTO) på 30 sekunder i 100 % av de distribuerade timmarna.
Hyperskala
Tjänstnivån Hyperskala är lämplig för alla arbetsbelastningstyper. Dess molnbaserade arkitektur ger oberoende skalbar beräkning och lagring för att stödja den bredaste variationen av traditionella och moderna program. Beräknings- och lagringsresurser i Hyperskala överskrider avsevärt de resurser som är tillgängliga på nivåerna Generell användning och Affärskritisk.
Mer information finns i Hyperskala-tjänstnivån för Azure SQL Database.
När du ska välja den här tjänstnivån
Tjänstnivån Hyperskala tar bort många av de praktiska gränser som traditionellt sett setts i molndatabaser. Om de flesta andra databaser begränsas av de resurser som är tillgängliga i en enda nod har databaser på tjänstnivån Hyperskala inga sådana gränser. Med sin flexibla lagringsarkitektur växer en Hyperskala-databas efter behov – och du debiteras endast för den lagringskapacitet som du använder.
Utöver de avancerade skalningsfunktionerna är Hyperskala ett bra alternativ för alla arbetsbelastningar, inte bara för stora databaser. Med Hyperskala kan du:
- Uppnå hög återhämtning och snabb återställning av fel samtidigt som du kontrollerar kostnaden genom att välja antalet repliker med hög tillgänglighet från 0 till 4.
- Förbättra hög tillgänglighet genom att aktivera zonredundans för beräkning och lagring.
- Uppnå låg I/O-svarstid (i genomsnitt 1–2 millisekunder) för den ofta använda delen av databasen. För mindre databaser kan detta gälla för hela databasen.
- Implementera en mängd olika scenarier för lässkalning med namngivna repliker.
- Dra nytta av snabb skalning utan att vänta på att data ska kopieras till lokal lagring på nya noder.
- Njut av kontinuerlig säkerhetskopiering utan påverkan och snabb återställning.
- Stöd för krav på affärskontinuitet med hjälp av redundansgrupper och geo-replikering.
Konfiguration av maskinvara
Vanliga maskinvarukonfigurationer i vCore-modellen är standardserier (Gen5), Fsv2-serien och DC-serien. Hyperskala ger också ett alternativ för minnesoptimerad maskinvara i Premium-serien och Premium-serien. Maskinvarukonfiguration definierar beräknings- och minnesgränser och andra egenskaper som påverkar arbetsbelastningens prestanda.
Vissa maskinvarukonfigurationer som standardserier (Gen5) kan använda mer än en typ av processor (CPU), enligt beskrivningen i Beräkningsresurser (CPU och minne). Även om en viss databas eller elastisk pool tenderar att finnas kvar på maskinvaran med samma CPU-typ under en lång tid (vanligtvis i flera månader), finns det vissa händelser som kan leda till att en databas eller pool flyttas till maskinvara som använder en annan CPU-typ. En databas eller pool kan till exempel flyttas om du skalar upp eller ned till ett annat tjänstmål, eller om den aktuella infrastrukturen i ett datacenter närmar sig sina kapacitetsgränser, eller om den maskinvara som används för närvarande inaktiveras på grund av dess livslängd.
För vissa arbetsbelastningar kan en övergång till en annan CPU-typ ändra prestanda. SQL Database konfigurerar maskinvara med målet att tillhandahålla förutsägbara arbetsbelastningsprestanda även om CPU-typen ändras, vilket håller prestandaändringar inom ett smalt band. Men över hela spektrumet av kundarbetsbelastningar i SQL Database och när nya typer av processorer blir tillgängliga kan det ibland se mer märkbara prestandaförändringar om en databas eller pool flyttas till en annan CPU-typ.
Oavsett vilken processortyp som används förblir resursgränserna för en databas eller elastisk pool (till exempel antalet kärnor, minne, maximal data-IOPS, maximal loggfrekvens och maximalt antal samtidiga arbetare) desamma så länge databasen ligger kvar på samma tjänstmål.
Beräkningsresurser (CPU och minne)
I följande tabell jämförs beräkningsresurser i olika maskinvarukonfigurationer och beräkningsnivåer:
| Konfiguration av maskinvara | Processor | Minne |
|---|---|---|
| Standardserie (Gen5) | Etablerad beräkning - Intel® E5-2673 v4 (Broadwell) 2,3 GHz, Intel® SP-8160 (Skylake)*, Intel® 8272CL (Cascade Lake) 2,5 GHz*, Intel® Xeon Platinum 8370C (Ice Lake)*, AMD EPYC 7763v (Milan) processorer – Etablera upp till 128 virtuella kärnor (hypertrådad) Serverlös databearbetning - Intel® E5-2673 v4 (Broadwell) 2,3 GHz, Intel® SP-8160 (Skylake)*, Intel® 8272CL (Cascade Lake) 2,5 GHz*, Intel Xeon® Platinum 8370C (Ice Lake)*, AMD EPYC 7763v (Milan) processorer – Skala upp till 80 virtuella kärnor automatiskt (hypertrådad) – Förhållandet mellan minne och virtuell kärna anpassas dynamiskt till minnes- och CPU-användning baserat på efterfrågan på arbetsbelastningar och kan vara så högt som 24 GB per virtuell kärna. Vid en viss tidpunkt kan till exempel en arbetsbelastning använda och faktureras för 240 GB minne och endast 10 virtuella kärnor. |
Etablerad beräkning - 5,1 GB per virtuell kärna – Etablera upp till 625 GB Serverlös databearbetning – Skala upp till 24 GB per virtuell kärna automatiskt – Skala upp till högst 240 GB automatiskt |
| Fsv2-serien | – Intel® 8168-processorer (Skylake) - Med en ihållande full core turbo klockhastighet på 3,4 GHz och en maximal enkärnig turbo klockhastighet på 3,7 GHz. – Etablera upp till 72 virtuella kärnor (hypertrådad) |
- 1,9 GB per virtuell kärna – Etablera upp till 136 GB |
| DC-serien | – Intel® XEON E-2288G-processorer - Med Intel Software Guard-tillägget (Intel SGX) – Etablera upp till 8 virtuella kärnor (fysisk) |
4,5 GB per virtuell kärna |
* I vyn sys.dm_user_db_resource_governance dynamisk hantering visas maskinvarugenerering för databaser med Intel® SP-8160-processorer (Skylake) som Gen6, maskinvarugenerering för databaser med Intel® 8272CL (Cascade Lake) visas som Gen7 och maskinvarugenerering för databaser med Intel Xeon® Platinum 8370C (Ice Lake) eller AMD® EPYC® 7763v (Milano) visas som Gen8. För en viss beräkningsstorlek och maskinvarukonfiguration är resursgränserna desamma oavsett CPU-typ (Intel Broadwell, Skylake, Ice Lake, Cascade Lake eller AMD Milan).
Mer information finns i resursgränser för enskilda databaser och elastiska pooler.
Information om beräkningsresurser och specifikation för hyperskaladatabaser finns i Hyperskala beräkningsresurser.
Standardserie (Gen5)
- Maskinvara i Standard-serien (Gen5) tillhandahåller balanserade beräknings- och minnesresurser och är lämplig för de flesta databasarbetsbelastningar.
Standardseriemaskinvara (Gen5) är tillgänglig i alla offentliga regioner över hela världen.
Hyperskala premiumserie
- Maskinvarualternativ i Premium-serien använder den senaste processor- och minnestekniken från Intel och AMD. Premium-serien ger en ökning av beräkningsprestanda i förhållande till maskinvara i standardserien.
- Premium-serien erbjuder snabbare CPU-prestanda jämfört med Standard-serien och ett högre antal maximala virtuella kärnor.
- Det minnesoptimerade alternativet i Premium-serien ger dubbelt så mycket minne i förhållande till Standard-serien.
- Standardserier, premiumserier och premium-seriens minnesoptimerade är tillgängliga för elastiska Hyperskala-pooler (förhandsversion).
Mer information finns i bloggmeddelandet om Hyperskala Premium-serien.
Tillgängliga regioner finns i Hyperskala premiumserietillgänglighet.
Fsv2-serien
- Fsv2-serien är en beräkningsoptimerad maskinvarukonfiguration som ger låg CPU-svarstid och hög klockfrekvens för de mest CPU-krävande arbetsbelastningarna. På samma sätt som maskinvarukonfigurationer i Premium-serien i Hyperskala drivs Fsv2-serien av den senaste processor- och minnestekniken från Intel och AMD, så att kunderna kan dra nytta av den senaste maskinvaran när de använder databaser och elastiska pooler på tjänstnivån Generell användning.
- Beroende på arbetsbelastningen kan Fsv2-serien leverera mer CPU-prestanda per virtuell kärna än andra typer av maskinvara. Till exempel kan beräkningsstorleken 72 virtuella kärnor Fsv2 ge mer CPU-prestanda än 80 virtuella kärnor i Standard-serien (Gen5), till lägre kostnad.
- Fsv2 ger mindre minne och
tempdbper virtuell kärna än annan maskinvara, så arbetsbelastningar som är känsliga för dessa gränser kan fungera bättre på standardserier (Gen5).
Fsv2-serien i stöds endast på nivån Generell användning. För regioner där Fsv2-serien är tillgänglig, se Fsv2-seriens tillgänglighet.
DC-serien
- Dc-seriens maskinvara använder Intel-processorer med Software Guard-tilläggsteknik (Intel SGX).
- DC-serien krävs för Always Encrypted med säkra enklaver som kräver ett starkare säkerhetsskydd för maskinvaruenklaver, jämfört med virtualiseringsbaserade enklaver (VBS).
- DC-serien är utformad för arbetsbelastningar som bearbetar känsliga data och kräver konfidentiella frågebearbetningsfunktioner, som tillhandahålls av Always Encrypted med säkra enklaver.
- DC-seriens maskinvara tillhandahåller balanserade beräknings- och minnesresurser.
DC-serien stöds endast för etablerad beräkning (serverlös stöds inte) och stöder inte zonredundans. För regioner där DC-serien är tillgänglig, se TILLGÄNGLIGHET för DC-serien.
Azure-erbjudandetyper som stöds av DC-serien
Om du vill skapa databaser eller elastiska pooler på dc-seriens maskinvara måste prenumerationen vara en typ av betalt erbjudande, inklusive Betala per användning eller företagsavtal (EA). En fullständig lista över Azure-erbjudandetyper som stöds av DC-serien finns i aktuella erbjudanden utan utgiftsgränser.
Välj maskinvarukonfiguration
Du kan välja maskinvarukonfiguration för en databas eller elastisk pool i SQL Database när den skapas. Du kan också ändra maskinvarukonfigurationen för en befintlig databas eller elastisk pool.
Så här väljer du en maskinvarukonfiguration när du skapar en SQL Database eller pool
Detaljerad information finns i Skapa en SQL Database.
På fliken Grundläggande väljer du länken Konfigurera databas i avsnittet Beräkning + lagring och väljer sedan länken Ändra konfiguration:
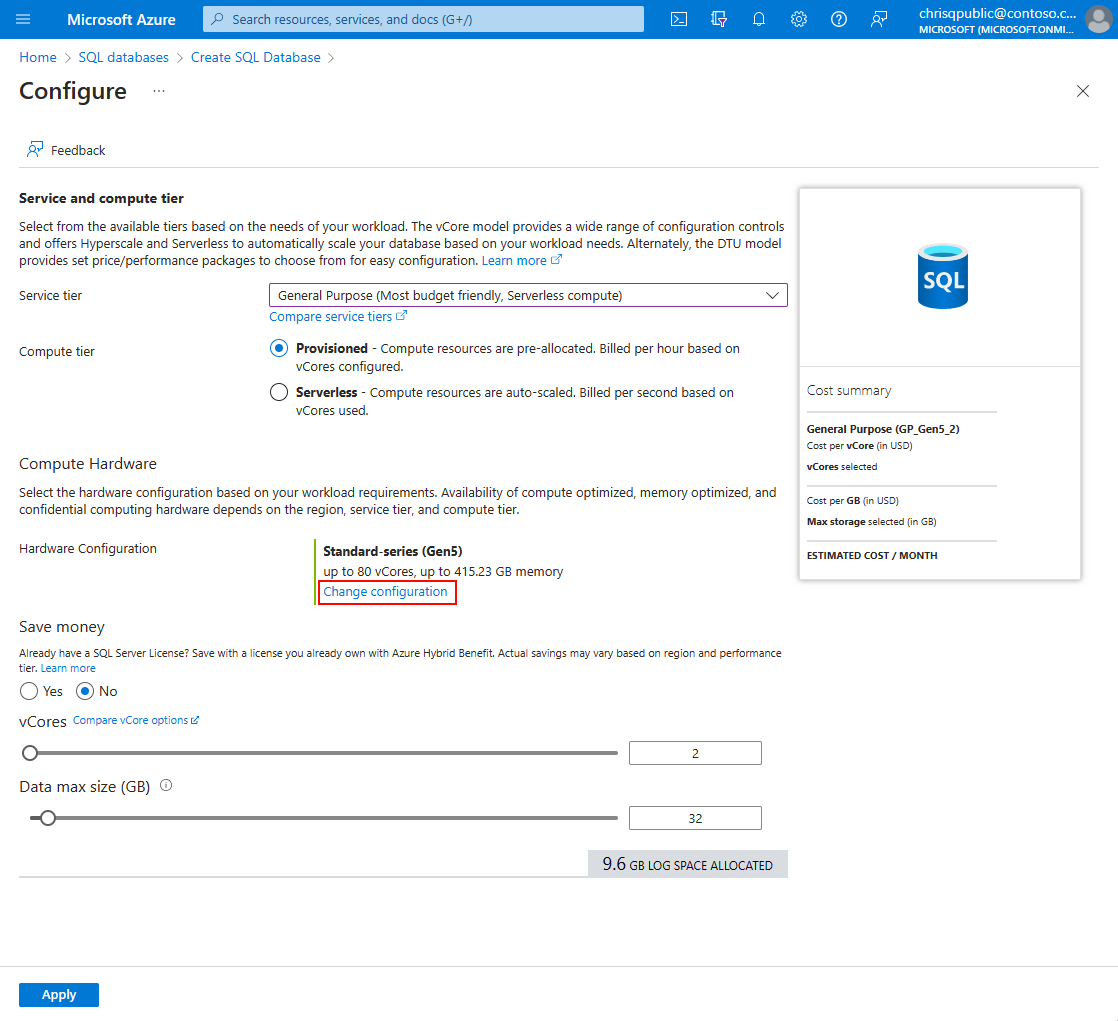
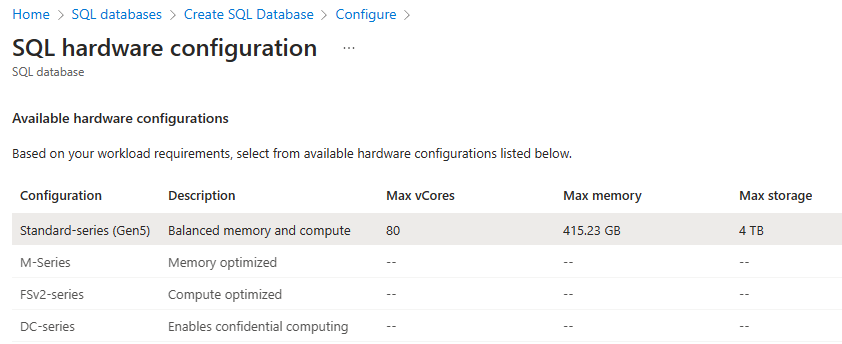
Välj önskad maskinvarukonfiguration:
Ändra maskinvarukonfigurationen för en befintlig SQL Database eller pool
För en databas går du till sidan Översikt och väljer länken Prisnivå :
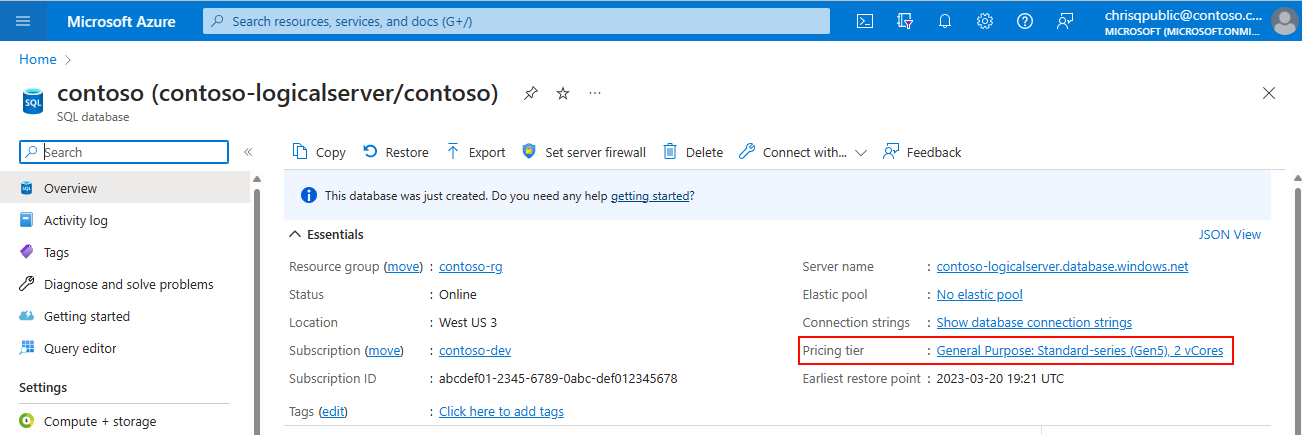
För en pool går du till sidan Översikt och väljer Konfigurera.
Följ stegen för att ändra konfigurationen och välj maskinvarukonfiguration enligt beskrivningen i föregående steg.
Maskinvarutillgänglighet
Information om tidigare generations maskinvara finns i Föregående generations maskinvarutillgänglighet.
Standardserie (Gen5)
Standardseriemaskinvara (Gen5) är tillgänglig i alla offentliga regioner över hela världen.
Hyperskala premiumserie
Minnesoptimerad maskinvara i Premium-serien och Premium-serien är tillgänglig för enskilda databaser och elastiska pooler i följande regioner:
- Australien, östra
- Brasilien, södra
- Kanada, centrala **
- Indien, centrala
- Central US
- Asien, östra
- USA, östra **
- USA, östra 2
- Frankrike, centrala
- Tyskland, västra centrala
- Indien, syd
- Japan, östra
- Japan, västra *
- Norra centrala USA
- Europa, norra **
- Sydostasien
- USA, södra centrala
- Södra Storbritannien
- Västra centrala USA
- Europa, västra **
- USA, västra 1
- Västra USA 2
- USA, västra 3 **
* Minnesoptimerad maskinvara i Premium-serien är för närvarande inte tillgänglig.
** Innehåller stöd för zonredundans.
Fsv2-serien
Fsv2-serien är tillgänglig i följande regioner:
- Australien, centrala
- Australien, centrala 2
- Australien, östra
- Australien, sydöstra
- Brasilien, södra
- Kanada, centrala
- Asien, östra
- East US
- Frankrike, centrala
- Indien, centrala
- Sydkorea, centrala
- Sydkorea, södra
- Europa, norra
- Sydafrika, norra
- Sydostasien
- Storbritannien, södra
- Storbritannien, västra
- Europa, västra
- Västra USA 2
DC-serien
DC-serien är tillgänglig i följande regioner:
- Kanada, centrala
- East US
- Europa, norra
- Storbritannien, södra
- Europa, västra
- USA, västra
- Sydostasien
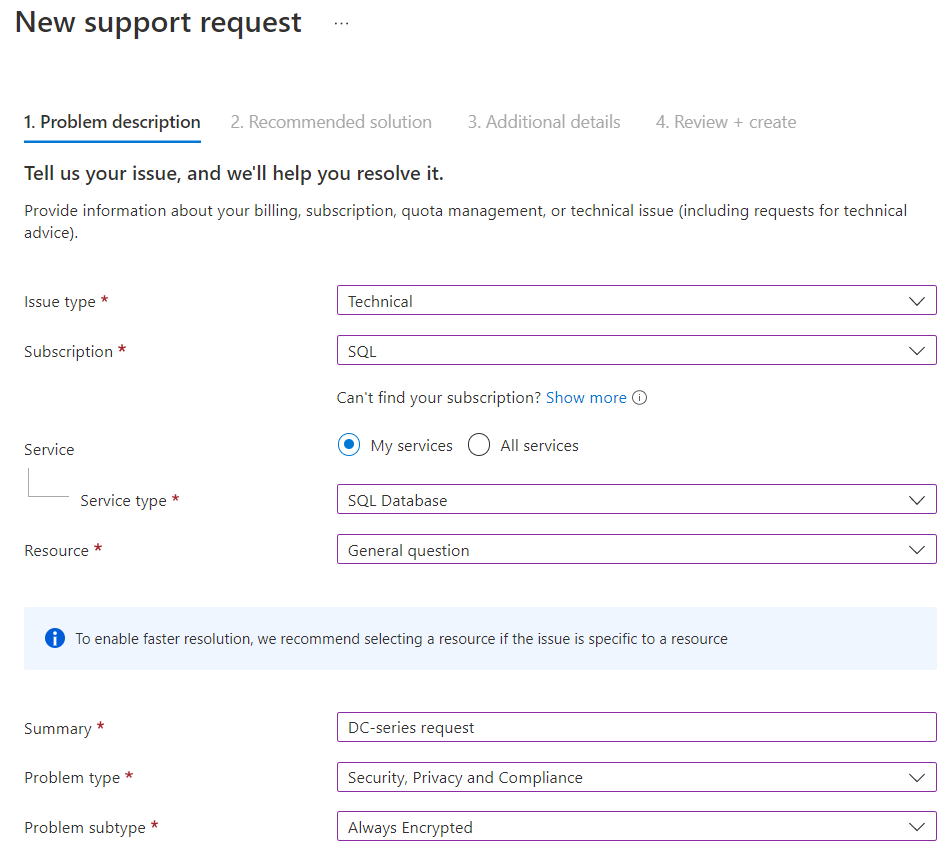
Om du behöver DC-serien i en region som för närvarande inte stöds skickar du en supportbegäran. På sidan Grundläggande anger du följande:
- Som Typ av problem väljer du Teknisk.
- Ange önskad prenumeration för maskinvaran. Välj Nästa.
- Som Tjänsttyp väljer du SQL Database.
- För Resurs väljer du Allmän fråga.
- För Sammanfattning anger du önskad maskinvarutillgänglighet och region.
- För Problemtyp väljer du Säkerhet, Privat och Efterlevnad.
- För Problemundertyp väljer du Always Encrypted.
Tidigare generations maskinvara
Gen4
Gen4-maskinvaran har dragits tillbaka och är inte tillgänglig för etablering, uppskalning eller nedskalning. Migrera databasen till en maskinvarugenerering som stöds för ett bredare utbud av skalbarhet för virtuella kärnor och lagring, accelererat nätverk, bästa I/O-prestanda och minimal svarstid. Granska maskinvarualternativ för enskilda databaser och maskinvarualternativ för elastiska pooler. Mer information finns i Support har upphört för Gen 4-maskinvara i Azure SQL Database.
Relaterat innehåll
- Prissättningssida för Azure SQL Database
- Resursbegränsningar för enskilda databaser med hjälp av vCore-inköpsmodellen
- Resursbegränsningar för elastiska pooler med hjälp av vCore-inköpsmodellen
Gå vidare
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för