Översikt över elastiska pooler i Hyperskala i Azure SQL Database
Gäller för:![]() Azure SQL Database
Azure SQL Database
Den här artikeln innehåller en översikt över elastiska Hyperskala-pooler i Azure SQL Database.
En elastisk Azure SQL Database-pool gör det möjligt för SaaS-utvecklare (software-as-a-service) att optimera förhållandet mellan pris och prestanda för en grupp databaser inom en föreskriven budget samtidigt som de levererar prestandaelasticitet för varje databas. Elastiska Azure SQL Database-pooler med hyperskala introducerar en delad resursmodell för Hyperskala-databaser.
Exempel för att skapa, skala eller flytta databaser till en elastisk Hyperskala-pool med hjälp av Azure CLI eller PowerShell finns i Arbeta med elastiska hyperskalapooler med hjälp av kommandoradsverktyg
Kommentar
Elastiska pooler för Hyperskala är för närvarande i förhandsversion.
Översikt
Distribuera hyperskaladatabasen till en elastisk pool för att dela resurser mellan databaser i poolen och optimera kostnaden för att ha flera databaser med olika användningsmönster.
Scenarier för att använda en elastisk pool med dina Hyperskala-databaser:
- När du behöver skala upp eller ned de beräkningsresurser som allokerats till den elastiska poolen på ett förutsägbart sätt, oberoende av mängden allokerad lagring.
- När du vill skala ut de beräkningsresurser som allokerats till den elastiska poolen genom att lägga till en eller flera skrivbara repliker.
- Om du vill använda högt transaktionsloggflöde för skrivintensiva arbetsbelastningar, även med lägre beräkningsresurser.
Om du migrerar icke-Hyperskala-databaser till en elastisk hyperskala-pool uppgraderas databaserna till tjänstnivån Hyperskala.
Arkitektur
Traditionellt består arkitekturen för en fristående Hyperskala-databas av tre huvudsakliga oberoende komponenter: Compute, Storage ("Page Servers") och loggen ("Log Service"). När du skapar en elastisk pool för dina Hyperskala-databaser delar databaserna i poolen beräknings- och loggresurser. Om du väljer att konfigurera hög tillgänglighet skapas dessutom varje pool med hög tillgänglighet med en motsvarande och oberoende uppsättning beräknings- och loggresurser.
Följande beskriver arkitekturen för en elastisk pool för Hyperskala-databaser:
- En elastisk hyperskalapool består av en primär pool som är värd för primära Hyperskala-databaser och, om den konfigureras, upp till fyra ytterligare pooler med hög tillgänglighet.
- Primära Hyperskala-databaser som finns i den primära elastiska poolen delar beräkningsprocessen för SQL Server-databasmotorn (sqlservr.exe), virtuella kärnor, minne och SSD-cache.
- Om du konfigurerar hög tillgänglighet för den primära poolen skapas ytterligare pooler med hög tillgänglighet som innehåller skrivskyddade databasrepliker för databaserna i den primära poolen. Varje primär pool kan ha högst fyra replikpooler med hög tillgänglighet. Varje pool med hög tillgänglighet delar beräknings-, SSD-cache- och minnesresurser för alla sekundära skrivskyddade databaser i poolen.
- Hyperskala-databaser i den primära elastiska poolen delar alla samma loggtjänst. Eftersom databaser i poolerna med hög tillgänglighet inte har någon skrivarbetsbelastning använder de inte loggtjänsten.
- Varje Hyperskala-databas har en egen uppsättning sidservrar och dessa sidservrar delas mellan den primära databasen i den primära poolen och alla sekundära replikdatabaser i poolen med hög tillgänglighet.
- Geo-replikerade sekundära Hyperskala-databaser kan placeras i en annan elastisk pool.
- Om du anger
ApplicationIntent=ReadOnlyi databasen anslutningssträng dirigeras du till en skrivskyddad replikdatabas i en av poolerna med hög tillgänglighet.
Följande diagram visar arkitekturen för en elastisk pool för Hyperskala-databaser:
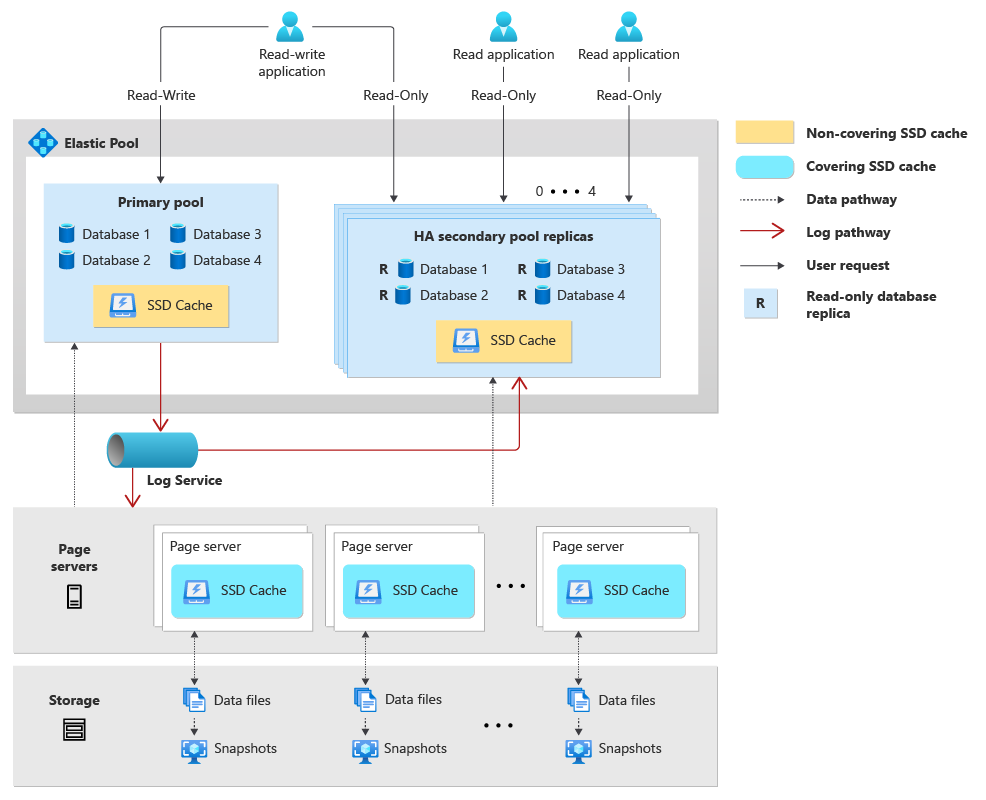
Hantera elastiska pooldatabaser i Hyperskala
Du kan använda samma kommandon för att hantera dina pooldatabaser i Hyperskala som pooldatabaser på de andra tjänstnivåerna. Se bara till att ange Hyperscale för utgåvan när du skapar din elastiska Hyperskala-pool.
Den enda skillnaden är möjligheten att ändra antalet H/A-repliker (hög tillgänglighet) för en befintlig elastisk Hyperskala-pool. Så här gör du:
- Använd parametern
HighAvailabilityReplicaCountför kommandot Azure PowerShell Set-AzSqlElasticPool . - Använd parametern
--ha-replicasför azure CLI az sql elastic-pool update-kommandot .
Du kan använda följande klientverktyg för att hantera dina Hyperskala-databaser i en elastisk pool:
- Azure PowerShell: Az.Sql.3.11.0 eller senare. PowerShell AzureRM.Sql stöds inte.
- Azure CLI: Az version 2.40.0 eller senare.
- Transact-SQL (T-SQL) börjar med: SQL Server Management Studio (SSMS) v18.12.1 eller Azure Data Studio v1.39.1.
Migrera icke-Hyperskala-databaser till elastiska Hyperskala-pooler
När du migrerar en databas till Hyperskala kan du lägga till databasen i en befintlig elastisk hyperskalapool. För dessa migreringar måste den elastiska hyperskalapoolen finnas på samma logiska server som källdatabasen.
När du migrerar databaser till elastiska Hyperskala-pooler bör du vara medveten om det maximala antalet databaser per elastisk Hyperskala-pool.
Migrera icke-Hyperskala-databaser till elastiska Hyperskala-pooler med T-SQL
Du kan använda T-SQL-kommandon för att migrera flera databaser för generell användning och lägga till dem i en befintlig elastisk Hyperskala-pool med namnet hsep1:
ALTER DATABASE gpepdb1 MODIFY (SERVICE_OBJECTIVE = ELASTIC_POOL(NAME = [hsep1]))
ALTER DATABASE gpepdb2 MODIFY (SERVICE_OBJECTIVE = ELASTIC_POOL(NAME = [hsep1]))
ALTER DATABASE gpepdb3 MODIFY (SERVICE_OBJECTIVE = ELASTIC_POOL(NAME = [hsep1]))
ALTER DATABASE gpepdb4 MODIFY (SERVICE_OBJECTIVE = ELASTIC_POOL(NAME = [hsep1]))
I det här exemplet begär du implicit en migrering från Generell användning till Hyperskala genom att ange att målet SERVICE_OBJECTIVE är en elastisk hyperskalapool. Vart och ett av ovanstående kommandon börjar migrera respektive databas för generell användning till Hyperskala. Dessa ALTER DATABASE kommandon returnerar snabbt och väntar inte på att migreringen ska slutföras. I exemplet som visas skulle du ha fyra sådana migreringar från Generell användning till Hyperskala som körs parallellt.
Du kan fråga sys.dm_operation_status dynamisk hanteringsvy för att övervaka statusen för dessa bakgrundsmigreringsåtgärder.
Migrera icke-Hyperskala-databaser till elastiska Hyperskala-pooler med hjälp av PowerShell
Du kan använda PowerShell-kommandon för att migrera flera databaser för generell användning och lägga till dem i en befintlig elastisk Hyperskala-pool med namnet hsep1. Följande exempelskript utför till exempel följande steg:
- Använd cmdleten Get-AzSqlElasticPoolDatabase för att lista alla databaser i den elastiska poolen Generell användning med namnet
gpep1. - Cmdleten
Where-Objectfiltrerar listan till endast de databasnamn som börjar medgpepdb. - För varje databas startar Cmdleten Set-AzSqlDatabase en migrering. I det här fallet begär du implicit en migrering till tjänstnivån Hyperskala genom att ange den elastiska hyperskala-målpoolen med namnet
hsep1.- Parametern
-AsJobgör att var och en av begärandenSet-AzSqlDatabasekan köras parallellt. Om du föredrar att köra migreringarna en i taget kan du ta bort parametern-AsJob.
- Parametern
$dbs = Get-AzSqlElasticPoolDatabase -ResourceGroupName "myResourceGroup" -ServerName "mylogicalserver" -ElasticPoolName "gpep1"
$dbs | Where-Object { $_.DatabaseName -like "gpepdb*" } | % { Set-AzSqlDatabase -ResourceGroupName "myResourceGroup" -ServerName "mylogicalserver" -DatabaseName ($_.DatabaseName) -ElasticPoolName "hsep1" -AsJob }
Förutom vyn sys.dm_operation_status dynamisk hantering kan du använda PowerShell-cmdleten Get-AzSqlDatabaseActivity för att övervaka statusen för dessa bakgrundsmigreringsåtgärder.
Resursgränser
Följande visar de gränser som stöds för att arbeta med Hyperskala-databaser i elastiska pooler:
- Maskinvarugenerering som stöds: Standard-serien (Gen5), premium-serien och premium-serien minnesoptimerad.
- Maximalt antal virtuella kärnor per pool: 80 eller 128 virtuella kärnor, beroende på servicenivåmålet.
- Maximal datastorlek som stöds per databas: 100 TB.
- Maximal total datastorlek som stöds mellan databaser i poolen: 100 TB.
- Maximalt dataflöde för transaktionsloggar som stöds per databas: 100 MB.
- Maximalt dataflöde för transaktionsloggar som stöds mellan databaser i poolen: 131,25 MB/sekund.
- Varje elastisk Hyperskala-pool kan ha upp till 25 databaser.
Mer information finns i resursgränserna för elastiska Hyperskala-pooler för standardserier, premiumserier och premiumserieminne optimerade.
Kommentar
Prestandaprofiler, funktioner som stöds och publicerade gränser kan komma att ändras medan funktionen är i förhandsversion. Därför är det bäst att verifiera ditt användningsfall med regelbunden funktions-, prestanda- och skalningstestning av arbetsbelastningar.
Begränsningar
Tänk på följande begränsningar finns:
- Det går inte att ändra en befintlig elastisk pool som inte är hyperskala till Hyperskala-utgåvan. Migreringsavsnittet innehåller några alternativ som du kan använda.
- Det går inte att ändra utgåvan av en elastisk hyperskala-pool till en icke-Hyperskala-utgåva.
- För att kunna ångra migreringen av en berättigad databas, som finns i en elastisk Hyperskala-pool, måste den först tas bort från den elastiska hyperskalapoolen. Den fristående Hyperskala-databasen kan sedan ångras migreras till en fristående databas för generell användning.
- Underhåll av databaser i en pool utförs och underhållsperioder konfigureras på poolnivå. Det går för närvarande inte att konfigurera ett underhållsperiod för elastiska Hyperskala-pooler.
- Zonredundans är för närvarande inte tillgängligt för elastiska Hyperskala-pooler. Om du försöker lägga till en zonredundant Hyperskala-databas i en elastisk Hyperskala-pool resulterar det i ett fel.
- Det går inte att lägga till en namngiven replik i en elastisk hyperskala-pool. Försök att lägga till en namngiven replik av en Hyperskala-databas i en elastisk hyperskalapool resulterar i ett
UnsupportedReplicationOperationfel. Skapa i stället den namngivna repliken som en enda Hyperskala-databas.
Kända problem
| Problem | Rekommendation |
|---|---|
Om du försöker skapa en ny elastisk Hyperskala-pool från PowerShell med den angivna parametern -ZoneRedundant får du en vag One or more errors occurred. Om du kör PowerShell-kommandot med respektive -Verbose parametrar och -Debug angivna parametrar får du det faktiska felet: Provisioning of zone redundant database/pool is not supported for your current request. |
För närvarande stöds inte skapandet av elastiska Hyperskala-pooler med angiven zonredundans. |
I sällsynta fall kan du få felet 45122 - This Hyperscale database cannot be added into an elastic pool at this time. In case of any questions, please contact Microsoft supportnär du försöker flytta/återställa/kopiera en Hyperskala-databas till en elastisk pool. |
Den här begränsningen beror på implementeringsspecifik information. Om det här felet blockerar dig skapar du en supportincident och begär hjälp. |
Relaterat innehåll
- Arbeta med elastiska Hyperskala-pooler med hjälp av kommandoradsverktyg
- Priser för elastisk pool
- Skala elastiska poolresurser i Azure SQL Database
- Använda PowerShell för att övervaka och skala en elastisk pool i Azure SQL Database
- SaaS-databastenhetsmönster för flera klientorganisationer
- Introduktion till en SaaS-app med flera klienter som använder mönstret databas per klientorganisation med Azure SQL Database
- Resurshantering i kompakta elastiska pooler
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för