Hantera budgetar, kostnader och kvoter för Azure Machine Learning i organisationsskala
När du hanterar beräkningskostnader från Azure Machine Learning, i organisationsskala med många arbetsbelastningar, många team och användare, finns det många hanterings- och optimeringsutmaningar att arbeta igenom.
I den här artikeln presenterar vi metodtips för att optimera kostnader, hantera budgetar och dela kvoter med Azure Machine Learning. Informationen bygger på våra erfarenheter och lärdomar av att köra maskininlärningsteam internt på Microsoft i samarbete med våra kunder. Du lär dig att:
- Optimera beräkningsresurser för att uppfylla arbetsbelastningskraven.
- Använd ett teams budget på bästa sätt.
- Planera, hantera och dela budgetar, kostnader och kvoter i företagsskala.
Optimera beräkning för att uppfylla arbetsbelastningskraven
När du startar ett nytt maskininlärningsprojekt kan det behövas undersökande arbete för att få en bra bild av beräkningskraven. Det här avsnittet innehåller rekommendationer om hur du kan fastställa rätt SKU för virtuell dator (VM) för träning, slutsatsdragning eller som en arbetsstation att arbeta från.
Fastställa beräkningsstorleken för träning
Maskinvarukraven för din träningsarbetsbelastning kan variera från projekt till projekt. För att uppfylla dessa krav erbjuder Azure Machine Learning-beräkning olika typer av virtuella datorer:
- Generell användning: Balanserat förhållande mellan processor och minne.
- Minnesoptimerad: Högt förhållande mellan minne och PROCESSOR.
- Beräkningsoptimerad: Hög cpu-till-minneskvot.
- Beräkning med höga prestanda: Leverera prestanda i ledarskapsklass, skalbarhet och kostnadseffektivitet för olika verkliga HPC-arbetsbelastningar.
- Instanser med GPU:er: Specialiserade virtuella datorer som är avsedda för tung grafisk rendering och videoredigering, samt modellträning och slutsatsdragning (ND) med djupinlärning.
Du kanske ännu inte vet vilka dina beräkningskrav är. I det här scenariot rekommenderar vi att du börjar med något av följande kostnadseffektiva standardalternativ. De här alternativen är för enkel testning och för träningsarbetsbelastningar.
| Typ | Storlek på virtuell dator | Specifikationer |
|---|---|---|
| Processor | Standard_DS3_v2 | 4 kärnor, 14 GB RAM-minne ,28 GB lagringsutrymme |
| GPU | Standard_NC6 | 6 kärnor, 56 GB RAM-minne, 380 GB lagringsutrymme, NVIDIA Tesla K80 GPU |
För att få den bästa VM-storleken för ditt scenario kan det bestå av utvärderingsversion och fel. Här är flera aspekter att tänka på.
- Om du behöver en PROCESSOR:
- Använd en minnesoptimerad virtuell dator om du tränar på stora datauppsättningar.
- Använd en beräkningsoptimerad virtuell dator om du utför inferenser i realtid eller andra svarstidskänsliga uppgifter.
- Använd en virtuell dator med fler kärnor och RAM-minne för att påskynda träningstiderna.
- Om du behöver en GPU kan du läsa GPU-optimerade VM-storlekar för information om hur du väljer en virtuell dator.
- Om du utför distribuerad träning använder du VM-storlekar som har flera GPU:er.
- Om du utför distribuerad träning på flera noder använder du GPU:er som har NVLink-anslutningar.
Medan du väljer den VM-typ och SKU som passar bäst för din arbetsbelastning utvärderar du jämförbara VM-SKU:er som en kompromiss mellan CPU- och GPU-prestanda och priser. Ur ett kostnadshanteringsperspektiv kan ett jobb köras ganska bra på flera SKU:er.
Vissa GPU:er, till exempel NC-familjen, särskilt NC_Promo SKU:er, har liknande funktioner som andra GPU:er, till exempel låg svarstid och möjlighet att hantera flera beräkningsarbetsbelastningar parallellt. De är tillgängliga till rabatterade priser jämfört med några av de andra GPU:erna. Att välja VM-SKU:er till arbetsbelastningen kan minska kostnaderna avsevärt i slutändan.
En påminnelse om vikten av användning är att registrera dig för ett större antal GPU:er som inte nödvändigtvis körs med snabbare resultat. Kontrollera i stället att GPU:erna används fullt ut. Dubbelkolla till exempel behovet av NVIDIA CUDA. Även om det kan krävas för GPU-körning med höga prestanda kanske ditt jobb inte är beroende av det.
Fastställa beräkningsstorleken för slutsatsdragning
Beräkningskraven för slutsatsdragningsscenarier skiljer sig från träningsscenarier. Tillgängliga alternativ skiljer sig beroende på om ditt scenario kräver offline-slutsatsdragning i batch eller kräver online-slutsatsdragning i realtid.
För scenarier för slutsatsdragning i realtid bör du överväga följande förslag:
- Använd profileringsfunktioner i din modell med Azure Machine Learning för att avgöra hur mycket processor och minne du behöver allokera för modellen när du distribuerar den som en webbtjänst.
- Om du gör en slutsatsdragning i realtid men inte behöver hög tillgänglighet distribuerar du till Azure Container Instances (inget SKU-val).
- Om du gör en slutsatsdragning i realtid men behöver hög tillgänglighet distribuerar du till Azure Kubernetes Service.
- Om du använder traditionella maskininlärningsmodeller och tar emot < 10 frågor/sekund börjar du med en CPU-SKU. F-seriens SKU:er fungerar ofta bra.
- Om du använder djupinlärningsmodeller och får > 10 frågor/sekund kan du prova en NVIDIA GPU SKU (NCasT4_v3 fungerar ofta bra) med Triton.
För scenarier med batchinferens bör du överväga följande förslag:
- När du använder Azure Machine Learning-pipelines för batchinferens följer du anvisningarna i Fastställa beräkningsstorleken för träning för att välja din ursprungliga VM-storlek.
- Optimera kostnader och prestanda genom att skala horisontellt. En av de viktigaste metoderna för att optimera kostnader och prestanda är att parallellisera arbetsbelastningen med hjälp av parallella körningssteg i Azure Machine Learning. Med det här pipelinesteget kan du använda många mindre noder för att köra uppgiften parallellt, vilket gör att du kan skala vågrätt. Det finns dock en omkostnad för parallellisering. Beroende på arbetsbelastningen och graden av parallellitet som kan uppnås kan ett parallellt körningssteg vara ett alternativ.
Fastställa storleken för beräkningsinstansen
För interaktiv utveckling rekommenderas Azure Machine Learnings beräkningsinstans. Erbjudandet för beräkningsinstanser (CI) ger en enda nodberäkning som är bunden till en enskild användare och kan användas som en molnarbetsstation.
Vissa organisationer tillåter inte användning av produktionsdata på lokala arbetsstationer, har tillämpat begränsningar för arbetsstationsmiljön eller begränsar installationen av paket och beroenden i företagets IT-miljö. En beräkningsinstans kan användas som en arbetsstation för att övervinna begränsningen. Den erbjuder en säker miljö med åtkomst till produktionsdata och körs på avbildningar som levereras med populära paket och verktyg för datavetenskap som är förinstallerade.
När beräkningsinstansen körs debiteras användaren för VM-beräkning, Standard Load Balancer (inklusive regler för lb/utgående trafik och data som bearbetas), OS-disk (Premium SSD-hanterad P10-disk), temporär disk (den temporära disktypen beror på den valda VM-storleken) och den offentliga IP-adressen. För att spara kostnader rekommenderar vi att användarna överväger:
- Starta och stoppa beräkningsinstansen när den inte används.
- Arbeta med ett exempel på dina data på en beräkningsinstans och skala ut till beräkningskluster för att arbeta med hela datamängden
- Skicka experimenteringsjobb i lokalt beräkningsmålläge på beräkningsinstansen när du utvecklar eller testar, eller när du växlar till delad beräkningskapacitet när du skickar jobb i full skala. Till exempel många epoker, fullständig uppsättning data och hyperparametersökning.
Om du stoppar beräkningsinstansen stoppas faktureringen för beräkningstimmar för virtuella datorer, temporär disk och bearbetade kostnader för Standard Load Balancer-data. Observera att användaren fortfarande betalar för OS-disken och Standard Load Balancer inkluderade lb/outbound-regler även när beräkningsinstansen stoppas. Alla data som sparas på OS-disken sparas genom stopp och omstarter.
Justera den valda VM-storleken genom att övervaka beräkningsanvändningen
Du kan visa information om din användning och användning av Azure Machine Learning-beräkning via Azure Monitor. Du kan visa information om modelldistribution och -registrering, kvotinformation som aktiva och inaktiva noder, körningsinformation som avbrutna och slutförda körningar samt beräkningsanvändning för GPU- och CPU-användning.
Baserat på insikterna från övervakningsinformationen kan du planera eller justera resursanvändningen i hela teamet. Om du till exempel märker många inaktiva noder under den senaste veckan kan du arbeta med motsvarande arbetsyteägare för att uppdatera konfigurationen av beräkningsklustret för att förhindra den här extra kostnaden. Fördelarna med att analysera användningsmönstren kan hjälpa dig med prognostiseringskostnader och budgetförbättringar.
Du kan komma åt dessa mått direkt från Azure-portalen. Gå till din Azure Machine Learning-arbetsyta och välj Mått under övervakningsavsnittet på den vänstra panelen. Sedan kan du välja information om vad du vill visa, till exempel mått, sammansättning och tidsperiod. Mer information finns på sidan Övervaka Azure Machine Learning-dokumentation .
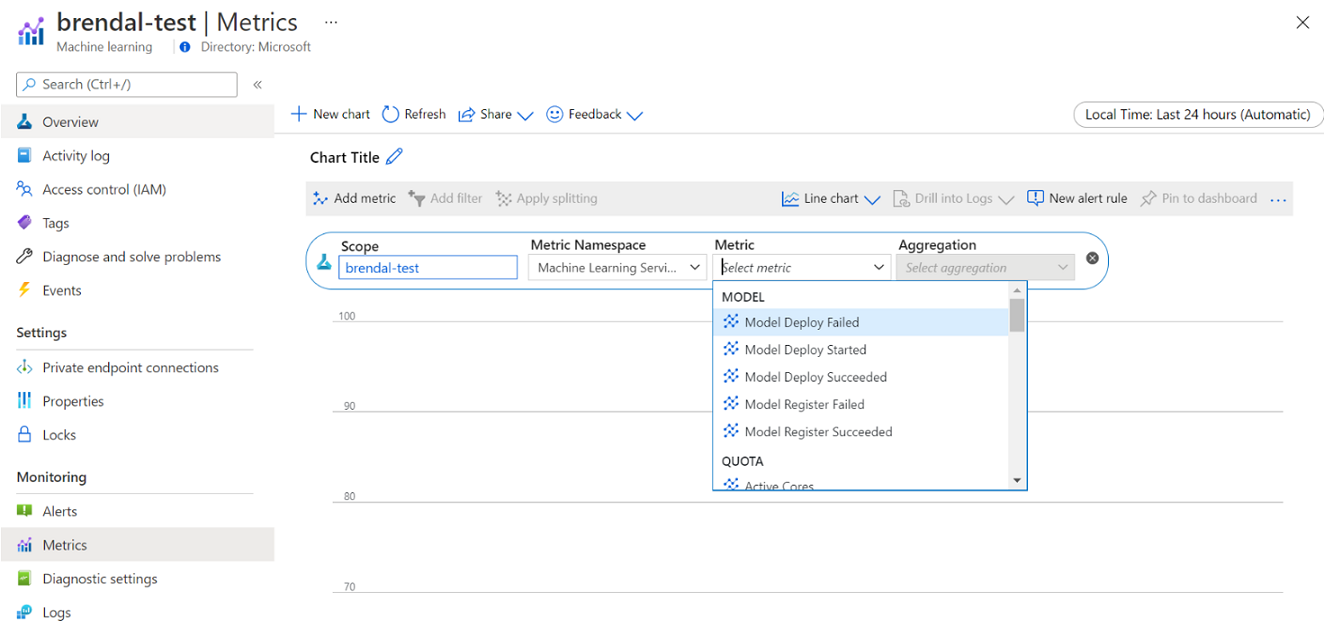
Växla mellan lokal molnberäkning med en nod och flera noder medan du utvecklar
Det finns olika beräknings- och verktygskrav under hela maskininlärningslivscykeln. Azure Machine Learning kan interageras med via ett SDK- och CLI-gränssnitt från praktiskt taget vilken arbetsstationskonfiguration som helst för att uppfylla dessa krav.
För att spara kostnader och arbeta produktivt rekommenderar vi att du:
- Klona din experimenteringskodbas lokalt med hjälp av Git och skicka jobb till molnberäkning med hjälp av Azure Machine Learning SDK eller CLI.
- Om datamängden är stor kan du överväga att hantera ett exempel på dina data på din lokala arbetsstation, samtidigt som du behåller hela datamängden på molnlagringen.
- Parametrisera din experimenteringskodbas så att du kan konfigurera dina jobb så att de körs med ett varierande antal epoker eller på datauppsättningar av olika storlekar.
- Hårdkoda inte mappsökvägen för datauppsättningen. Du kan sedan enkelt återanvända samma kodbas med olika datauppsättningar och under lokal och molnbaserad körningskontext.
- Bootstrap dina experimenteringsjobb i lokalt beräkningsmålläge när du utvecklar eller testar, eller när du växlar till en delad beräkningsklusterkapacitet när du skickar jobb i full skala.
- Om din datauppsättning är stor kan du arbeta med ett exempel på data på din lokala arbetsstation eller beräkningsinstansarbetsstation, samtidigt som du skalar till molnberäkning i Azure Machine Learning för att arbeta med din fullständiga datauppsättning.
- När det tar lång tid att köra dina jobb bör du överväga att optimera kodbasen för distribuerad träning så att du kan skala ut horisontellt.
- Utforma dina distribuerade träningsarbetsbelastningar för nodelasticitet, för att tillåta flexibel användning av beräkning med en nod och flera noder och underlätta användningen av beräkning som kan föregripas.
Kombinera beräkningstyper med hjälp av Azure Machine Learning-pipelines
När du samordnar dina arbetsflöden för maskininlärning kan du definiera en pipeline med flera steg. Varje steg i pipelinen kan köras på sin egen beräkningstyp. På så sätt kan du optimera prestanda och kostnader för att uppfylla olika beräkningskrav i hela maskininlärningslivscykeln.
Få bästa möjliga användning av ett teams budget
Beslut om budgetallokering kan vara utom kontroll över ett enskilt team, men ett team har vanligtvis befogenhet att använda sin allokerade budget efter bästa behov. Genom att byta bort jobbprioritet jämfört med prestanda och kostnad på ett klokt sätt kan ett team uppnå högre klusteranvändning, sänka den totala kostnaden och använda ett större antal beräkningstimmar från samma budget. Detta kan leda till förbättrad teamproduktivitet.
Optimera kostnaderna för delade beräkningsresurser
Nyckeln för att optimera kostnaderna för delade beräkningsresurser är att se till att de används till sin fulla kapacitet. Här följer några tips för att optimera dina delade resurskostnader:
- När du använder beräkningsinstanser aktiverar du dem bara när du har kod att köra. Stäng av dem när de inte används.
- När du använder beräkningskluster anger du det minsta antalet noder till 0 och det maximala antalet noder till ett tal som utvärderas baserat på dina budgetbegränsningar. Använd Priskalkylatorn för Azure för att beräkna kostnaden för full användning av en VM-nod i din valda VM-SKU. Autoskalning skalar ned alla beräkningsnoder när det inte finns någon som använder den. Den skalas bara upp till det antal noder som du har budget för. Du kan konfigurera automatisk skalning för att skala ned alla beräkningsnoder.
- Övervaka resursanvändningen, till exempel CPU-användning och GPU-användning när du tränar modeller. Om resurserna inte används fullt ut ändrar du koden för att bättre använda resurser eller skala ned till mindre eller billigare VM-storlekar.
- Utvärdera om du kan skapa delade beräkningsresurser för ditt team för att undvika ineffektivitet i databehandling som orsakas av klusterskalningsåtgärder.
- Optimera timeout-principer för automatisk skalning av beräkningskluster baserat på användningsstatistik.
- Använd kvoter för arbetsytor för att styra mängden beräkningsresurser som enskilda arbetsytor har åtkomst till.
Introducera schemaläggningsprioritet genom att skapa kluster för flera VM-SKU:er
Under kvot- och budgetbegränsningar måste ett team avväga körningen av jobb i tid jämfört med kostnaden för att säkerställa att viktiga jobb körs i tid och att en budget används på bästa möjliga sätt.
För bästa beräkningsanvändning rekommenderas team att skapa kluster av olika storlekar och med låg prioritet och dedikerade VM-prioriteringar. Lågprioriterade beräkningar använder överskottskapacitet i Azure och har därmed rabatterade priser. På nackdelen kan dessa datorer föregripas när en fråga med högre prioritet kommer in.
Med hjälp av kluster med varierande storlek och prioritet kan en uppfattning om schemaläggningsprioritet införas. När till exempel experiment- och produktionsjobb konkurrerar om samma NC GPU-kvot kan ett produktionsjobb ha företräde att köra över det experimentella jobbet. I så fall kör du produktionsjobbet på det dedikerade beräkningsklustret och det experimentella jobbet i beräkningsklustret med låg prioritet. När kvoten misslyckas kommer det experimentella jobbet att föregripas till förmån för produktionsjobbet.
Överväg att köra jobb på olika VM-SKU:er bredvid VM-prioritet. Det kan vara så att ett jobb tar längre tid att köra på en virtuell datorinstans med en P40 GPU än på en V100 GPU. Men eftersom V100 VM-instanser kan vara upptagna eller kvoten används fullt ut kan tiden för att slutföra P40 fortfarande vara snabbare ur ett jobbdataflödesperspektiv. Du kan också överväga att köra jobb med lägre prioritet på mindre högpresterande och billigare VM-instanser ur ett kostnadshanteringsperspektiv.
Avsluta en körning tidigt när träningen inte konvergerar
När du kontinuerligt experimenterar för att förbättra en modell mot dess baslinje kan du köra olika experimentkörningar, var och en med lite olika konfigurationer. För en körning kan du justera indatauppsättningarna. För en annan körning kan du göra en ändring av hyperparametern. Alla ändringar kan inte vara lika effektiva som de andra. Du upptäcker tidigt att en ändring inte hade den avsedda effekten på kvaliteten på din modellträning. Övervaka träningsförloppet under en körning för att identifiera om träningen inte konvergerar. Till exempel genom att logga prestandamått efter varje träningsepoker. Överväg att avsluta jobbet tidigt för att frigöra resurser och budget för en annan utvärderingsversion.
Planera, hantera och dela budgetar, kostnader och kvoter
När en organisation ökar antalet användningsfall och team för maskininlärning krävs en ökad mognad från IT och ekonomi samt samordning mellan enskilda maskininlärningsteam för att säkerställa effektiv drift. Kapacitets- och kvothantering i företagsskala blir viktiga för att hantera brist på beräkningsresurser och övervinna hanteringskostnader.
I det här avsnittet beskrivs metodtips för planering, hantering och delning av budgetar, kostnader och kvoter i företagsskala. Den baseras på lärdomar från hantering av många GPU-utbildningsresurser för maskininlärning internt på Microsoft.
Förstå resursutgifter med Azure Machine Learning
En av de största utmaningarna som administratör för planering av beräkningsbehov är att börja ny utan historisk information som baslinjeuppskattning. På ett praktiskt sätt kommer de flesta projekt att börja från en liten budget som ett första steg.
För att förstå vart budgeten är på väg är det viktigt att veta var Azure Machine Learning-kostnaderna kommer ifrån:
- Azure Machine Learning debiterar endast för beräkningsinfrastruktur som används och lägger inte till någon tilläggsavgift för beräkningskostnader.
- När en Azure Machine Learning-arbetsyta skapas finns det också några andra resurser som skapats för att aktivera Azure Machine Learning: Key Vault, Application Insights, Azure Storage och Azure Container Registry. Dessa resurser används i Azure Machine Learning och du betalar för dessa resurser.
- Det finns kostnader som är associerade med hanterad beräkning, till exempel träningskluster, beräkningsinstanser och hanterade slutpunkter för slutsatsdragning. Med dessa hanterade beräkningsresurser finns det följande infrastrukturkostnader att ta hänsyn till: virtuella datorer, virtuella nätverk, lastbalanserare, bandbredd och lagring.
Spåra utgiftsmönster och få bättre rapportering med taggning
Administratörer vill ofta kunna spåra kostnader för olika resurser i Azure Machine Learning. Taggning är en naturlig lösning på det här problemet och överensstämmer med den allmänna metod som används av Azure och många andra molntjänstleverantörer. Med stöd för taggar kan du nu se kostnadsuppdelning på beräkningsnivå, vilket ger dig åtkomst till en mer detaljerad vy för att hjälpa till med bättre kostnadsövervakning, förbättrad rapportering och större transparens.
Med taggning kan du placera anpassade taggar på dina arbetsytor och beräkningar (från Azure Resource Manager-mallar och Azure Machine Learning-studio) för att ytterligare filtrera på dessa resurser i Microsoft Cost Management baserat på dessa taggar för att observera utgiftsmönster. Den här funktionen kan användas bäst för interna debiteringsscenarier. Dessutom kan taggar vara användbara för att samla in metadata eller information som är associerad med beräkningen, till exempel ett projekt, ett team eller en viss faktureringskod. Detta gör taggning mycket fördelaktigt för att mäta hur mycket pengar du spenderar på olika resurser och därmed få djupare insikter om dina kostnads- och utgiftsmönster i team eller projekt.
Det finns också systeminmatade taggar som placeras på beräkningar som gör att du kan filtrera på sidan Kostnadsanalys med taggen "Beräkningstyp" för att se en beräkningsmässigt uppdelning av dina totala utgifter och avgöra vilken kategori av beräkningsresurser som kan tillskrivas de flesta av dina kostnader. Detta är särskilt användbart för att få mer insyn i din träning jämfört med att dra slutsatser om kostnadsmönster.
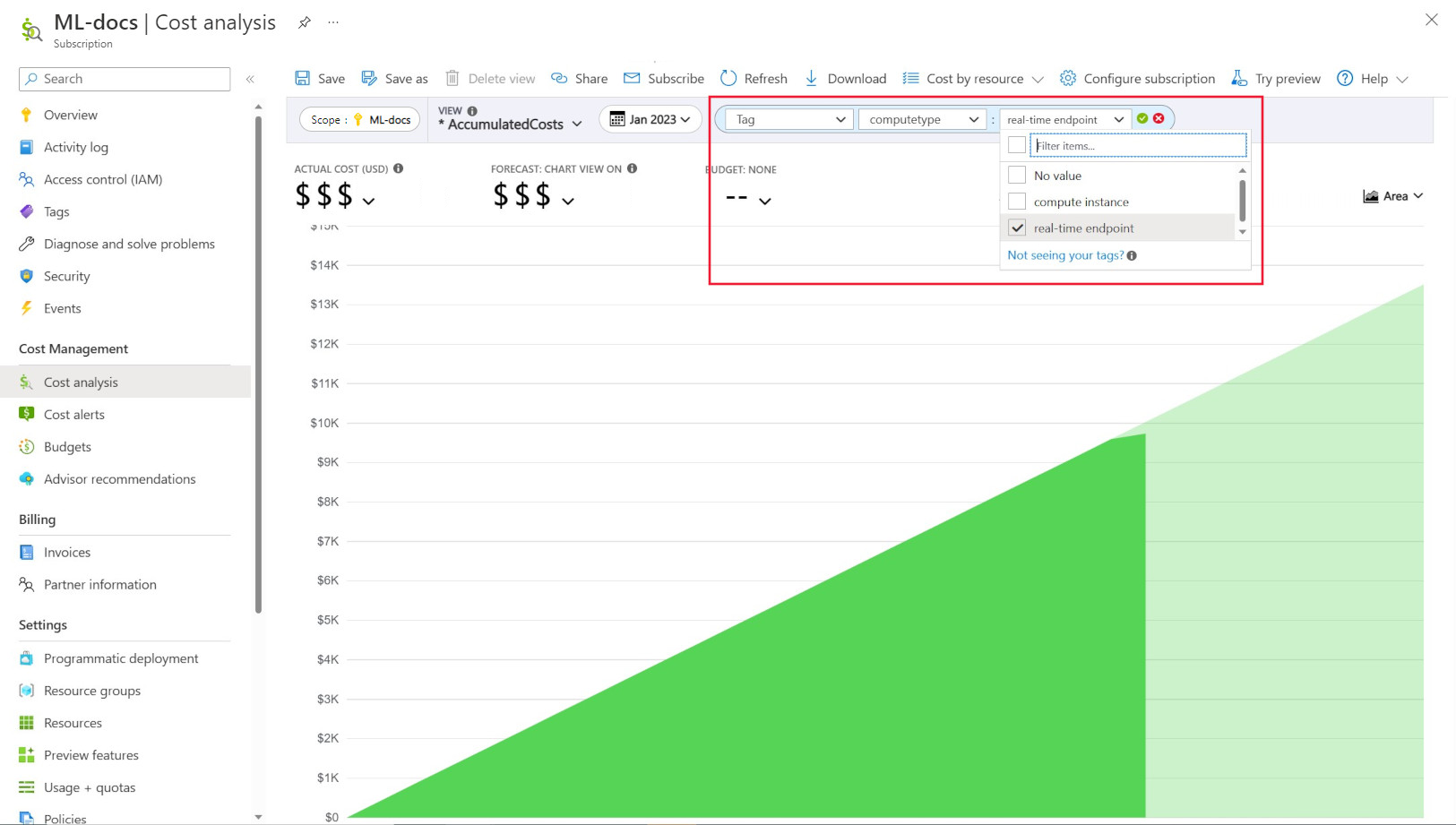
Styra och begränsa beräkningsanvändning efter princip
När du hanterar en Azure-miljö med många arbetsbelastningar kan det vara en utmaning att behålla översikten över resursutgifter. Azure Policy kan hjälpa till att styra resursutgifter genom att begränsa specifika användningsmönster i Azure-miljön.
Specifikt för Azure Machine Learning rekommenderar vi att du konfigurerar principer som endast tillåter användning av specifika VM-SKU:er. Principer kan hjälpa till att förhindra och kontrollera val av dyra virtuella datorer. Principer kan också användas för att framtvinga användning av vm-SKU:er med låg prioritet.
Allokera och hantera kvot baserat på affärsprioritet
Med Azure kan du ange gränser för kvotallokering på en prenumerations- och Azure Machine Learning-arbetsytenivå. Att begränsa vem som kan hantera kvoter via rollbaserad åtkomstkontroll i Azure (RBAC) kan bidra till att säkerställa resursutnyttjande och kostnadsförutsägelse.
Tillgängligheten för GPU-kvoten kan vara knapp i dina prenumerationer. För att säkerställa hög kvotanvändning mellan arbetsbelastningar rekommenderar vi att du övervakar om kvoten används bäst och tilldelas mellan arbetsbelastningar.
På Microsoft bestäms det regelbundet om GPU-kvoter används bäst och allokeras mellan maskininlärningsteam genom att utvärdera kapacitetsbehov mot affärsprioritet.
Checka in kapacitet i förväg
Om du har en bra uppskattning av hur mycket beräkning som ska användas under nästa år eller de närmaste åren kan du köpa Azure Reserved VM Instances till en rabatterad kostnad. Det finns köpvillkor på ett eller tre år. Eftersom Azure Reserved VM Instances rabatteras kan det finnas betydande kostnadsbesparingar jämfört med betala per användning-priser.
Azure Machine Learning stöder reserverade beräkningsinstanser. Rabatter tillämpas automatiskt mot azure machine learning-hanterad beräkning.
Hantera databevarande
Varje gång en maskininlärningspipeline körs kan mellanliggande datauppsättningar genereras vid varje pipelinesteg för datacachelagring och återanvändning. Tillväxten av data som utdata från dessa maskininlärningspipelines kan bli en smärtpunkt för en organisation som kör många maskininlärningsexperiment.
Dataexperter ägnar vanligtvis inte sin tid åt att rensa de mellanliggande datamängder som genereras. Med tiden kommer mängden data som genereras att summeras. Azure Storage har en funktion för att förbättra hanteringen av datalivscykeln. Med livscykelhantering i Azure Blob Storage kan du konfigurera allmänna principer för att flytta data som inte används till kallare lagringsnivåer och spara kostnader.
Överväganden för kostnadsoptimering för infrastruktur
Nätverk
Kostnaden för Azure-nätverk tillkommer från utgående bandbredd från Azure-datacenter. Alla inkommande data till ett Azure-datacenter är kostnadsfria. Nyckeln för att minska nätverkskostnaden är att distribuera alla dina resurser i samma datacenterregion när det är möjligt. Om du kan distribuera Azure Machine Learning-arbetsyta och beräkning i samma region som har dina data kan du få lägre kostnad och högre prestanda.
Du kanske vill ha en privat anslutning mellan ditt lokala nätverk och ditt Azure-nätverk för att ha en hybridmolnmiljö. Med ExpressRoute kan du göra det, men med tanke på de höga kostnaderna för ExpressRoute kan det vara mer kostnadseffektivt att flytta från en hybridmolnkonfiguration och flytta alla resurser till Azure-molnet.
Azure Container Registry
För Azure Container Registry är de avgörande faktorerna för kostnadsoptimering:
- Obligatoriskt dataflöde för Nedladdningar av Docker-avbildningar från containerregistret till Azure Machine Learning
- Krav för företagssäkerhetsfunktioner, till exempel Azure Private Link
För produktionsscenarier där högt dataflöde eller företagssäkerhet krävs rekommenderas Premium SKU för Azure Container Registry.
För utvecklings-/testscenarier där dataflöde och säkerhet är mindre kritiska rekommenderar vi antingen Standard SKU eller Premium SKU.
Grundläggande SKU för Azure Container Registry rekommenderas inte för Azure Machine Learning. Det rekommenderas inte på grund av dess låga dataflöde och låga lagringsutrymme, vilket snabbt kan överskridas av Azure Machine Learnings relativt stora (1+ GB) Docker-avbildningar.
Överväg att använda tillgänglighet för databehandlingstyper när du väljer Azure-regioner
När du väljer en region för din beräkning bör du ha tillgängligheten för beräkningskvoten i åtanke. Populära och större regioner som USA, östra, USA, västra och Europa, västra tenderar att ha högre standardkvotvärden och större tillgänglighet för de flesta processorer och GPU:er, jämfört med vissa andra regioner med strängare kapacitetsbegränsningar.
Läs mer
Spåra kostnader mellan affärsenheter, miljöer eller projekt med hjälp av Cloud Adoption Framework
Nästa steg
Mer information om hur du organiserar och konfigurerar Azure Machine Learning-miljöer finns i Ordna och konfigurera Azure Machine Learning-miljöer.
Mer information om metodtips för Machine Learning DevOps med Azure Machine Learning finns i Guide för Machine Learning DevOps.