Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Data mesh är en spännande ny metod för design och utveckling av dataarkitektur. Till skillnad från traditionell dataarkitektur separerar datanät ansvaret mellan funktionella datadomäner som fokuserar på att skapa dataprodukter och ett plattformsteam som fokuserar på tekniska funktioner. Den här ansvarsfördelningen måste återspeglas i din plattform. Du måste hitta en balans mellan att tillhandahålla domänagnostiska funktioner och göra det möjligt för dina domänteam att modellera, bearbeta och distribuera sina data i organisationen.
Det är inte lätt att välja rätt nivå av domänkornighet och regler för avkoppling med hjälp av plattformar. Den här artikeln innehåller flera scenarier som ger dig detaljerad vägledning.
Analys i molnskala
När du vill skapa ett datanät med Azure rekommenderar vi att du använder analys i molnskala. Det här ramverket är en distributionsbar referensarkitektur och levereras med mallar med öppen källkod och metodtips. Analysarkitekturen i molnskala har två huvudsakliga byggstenar som är grundläggande för alla distributionsalternativ:
- Landningszon för datahantering: Grunden för din dataarkitektur. Den innehåller alla viktiga funktioner för datahantering, till exempel datakatalog, dataursprung, API-katalog, hantering av huvuddata och så vidare.
- Datalandningszoner: Prenumerationer som hanterar dina analys- och AI-lösningar. De innehåller viktiga funktioner för att vara värd för en analysplattform.
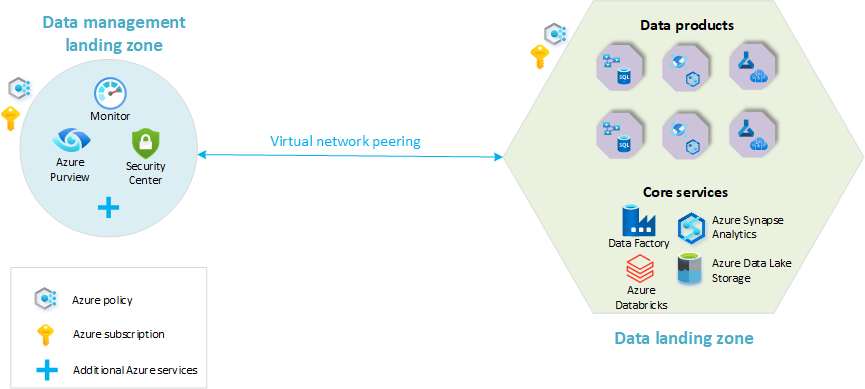
Följande diagram ger en översikt över en analysplattform i molnskala med en landningszon för datahantering och en enda datalandningszon. Alla Azure-tjänster visas inte i diagrammet. Det har förenklats för att lyfta fram huvudbegreppen i resursorganisationen i den här arkitekturen.
Det molnbaserade analysramverket är inte explicit för vilken exakt typ av dataarkitektur du måste etablera. Du kan använda den för många vanliga analyslösningar i molnskala, inklusive (företags) informationslager, datasjöar, datasjöhus och datanät. Alla exempellösningar i den här artikeln använder datanätsarkitektur.
Förstå att alla arkitekturer följer principerna för datanät: domänägarskap, data som produkt, självbetjäningsdataplattform och federerad beräkningsstyrning. Olika sökvägar kan alla leda till ett datanät. Det finns inget enskilt rätt eller fel svar. Du måste göra rätt kompromisser för din organisations behov.
Landningszon för enskilda data
Det enklaste distributionsmönstret för att skapa en datanätarkitektur omfattar en landningszon för datahantering och en datalandningszon. Dataarkitekturen i ett sådant scenario skulle se ut så här:

I den här modellen finns alla dina funktionella datadomäner i samma datalandningszon. En enda prenumeration innehåller en standarduppsättning tjänster. Resursgrupper separerar olika datadomäner och dataprodukter. Standarddatatjänster, till exempel Azure Data Lake Store och Azure Logic Apps, gäller för alla domäner.
Alla datadomäner följer principerna för datanät: data följer domänägarskapet och data behandlas som produkter. Plattformen är helt självbetjänande, även om det finns begränsade varianter av tjänster. Alla domäner bör starkt följa samma principer för datahantering.
Det här distributionsalternativet kan vara användbart för mindre företag eller greenfield-projekt som vill använda sig av datanät men inte överkomplicera saker. Den här distributionen kan också vara en startpunkt för en organisation som planerar att skapa något mer komplext. I det här fallet planerar du att expandera till flera landningszoner vid ett senare tillfälle.
Källsystemanpassade och konsumentanpassade landningszoner
I den tidigare modellen tog vi inte hänsyn till andra prenumerationer eller lokala program. Du kan ändra den tidigare modellen något genom att lägga till en källsystemjusterad landningszon för att hantera alla inkommande data. Dataregistrering är en svår process, så att ha två datalandningszoner är användbart. Onboarding är fortfarande en av de mest utmanande delarna av att använda data i stort. Registrering kräver också ofta extra verktyg för att hantera integrering, eftersom dess utmaningar skiljer sig från integreringen. Det hjälper till att skilja mellan att tillhandahålla data och använda data.

I arkitekturen till vänster om det här diagrammet underlättar tjänsterna all dataregistrering, till exempel CDC, tjänster för att hämta API:er eller datasjötjänster för dynamiskt skapande av datamängder. Tjänster på den här plattformen kan hämta data från lokala miljöer, molnmiljöer eller SaaS-leverantörer. Den här typen av plattform har vanligtvis också mer omkostnader, eftersom det finns mer koppling till underliggande operativa program. Du kanske vill behandla detta på ett annat sätt än all dataanvändning.
I arkitekturen till höger om diagrammet optimerar organisationen för förbrukning och har tjänster som fokuserar på att omvandla data till värde. Dessa tjänster kan omfatta maskininlärning, rapportering och så vidare.
Dessa arkitekturdomäner följer alla principer för datanät. Domäner äger data och får distribuera data direkt till andra domäner.
Hubb, generiska och särskilda datalandningszoner
Nästa distributionsalternativ är en annan iteration av den tidigare designen. Den här distributionen följer en styrd nättopologi: data distribueras via en central hubb, där data partitioneras per domän, logiskt isolerade och inte integrerade. Den här modellens hubb använder sin egen (domänoberoende) datalandningszon och kan ägas av ett centralt datastyrningsteam som övervakar vilka data som distribueras till vilka andra domäner. Hubben har också tjänster som underlättar registrering av data.

För domäner som kräver standardtjänster för användning, användning, analys och skapande av nya data använder du en allmän datalandningszon. Den här enskilda prenumerationen innehåller en standarduppsättning tjänster. Tillämpa även datavirtualisering eftersom de flesta av dina dataprodukter redan finns kvar i hubben och du inte behöver mer dataduplicering.
Den här distributionen tillåter "specialerbjudanden": extra landningszoner som du kan etablera när det inte går att gruppera domäner logiskt. De kan behövas när regionala eller juridiska gränser gäller, eller när dina domäner har unika och kontrasterande krav. Du kan också behöva dem i situationer där en stark global dotterbolagsstyrning tillämpas med undantag för utlandsaktiviteter.
Om din organisation behöver styra vilka data som distribueras och förbrukas av vilka domäner är hubbdistribution ett bra alternativ. Det är också ett alternativ om du hanterar tidsvarianter och icke-flyktiga problem för stora datakonsumenter. Du kan starkt standardisera dataproduktdesignen, vilket gör att dina domäner kan tidsresa och utföra ny leverans. Den här modellen är särskilt vanlig inom finansbranschen.
Funktionella och regionalt anpassade datalandningszoner
Genom att etablera flera datalandningszoner kan du gruppera funktionella domäner baserat på sammanhållning och effektivitet för att arbeta och dela data. Alla dina datalandningszoner följer samma granskning och kontroller, men du kan fortfarande ha flexibilitet och designändringar mellan olika datalandningszoner.

Fastställ de funktionella datadomäner som du vill gruppera logiskt för en delad datalandningszon. Du kan till exempel implementera samma mallar om du har regionala gränser. Ägarskap, säkerhet eller juridiska gränser kan tvinga dig att separera domäner. Flexibilitet, förändringstakten och separationen eller försäljningen av dina funktioner är också viktiga faktorer att tänka på.
Ytterligare vägledning och metodtips finns i datadomäner.
Olika landningszoner står inte ensamma. De kan ansluta till datasjöar som finns i andra zoner. På så sätt kan domäner samarbeta i hela företaget. Du kan också använda flerspråkig beständighet för att blanda olika datalagertekniker. Polyglot persistence gör att dina domäner kan läsa data direkt från andra domäner utan att duplicera data.
När du distribuerar flera datalandningszoner bör du känna till att det finns hanteringskostnader kopplade till varje datalandningszon. Du måste använda VNet-peering mellan alla datalandningszoner, du måste hantera extra privata slutpunkter och så vidare.
Att distribuera flera datalandningszoner är ett bra alternativ om dataarkitekturen är stor. Du kan lägga till fler landningszoner i arkitekturen för att hantera vanliga behov i olika domäner. Dessa extra landningszoner använder virtuellt nätverkspeering för att ansluta till både landningszonen för datahantering och alla andra landningszoner. Med peering kan du dela datauppsättningar och resurser i dina landningszoner. Genom att dela upp data mellan separata zoner kan du sprida arbetsbelastningar mellan dina Azure-prenumerationer och resurser. Den här metoden hjälper till att organiskt implementera datanätet.
Storskaligt företag som kräver olika datahanteringszoner
Stora företag som är verksamma i global skala kan ha motstridiga datahanteringskrav mellan olika delar av organisationen. Du kan distribuera flera datahanterings- och datalandningszoner tillsammans för att lösa problemet. Följande diagram visar ett exempel på den här typen av arkitektur:

Flera landningszoner för datahantering bör motivera din omkostnader och integreringskomplexitet. En annan landningszon för datahantering kan till exempel vara lämplig för situationer där organisationens (meta)data inte får ses av någon utanför organisationen.
Slutsats
Övergången till datanät är en kulturell förändring som omfattar nyanser, kompromisser och överväganden. Du kan använda analys i molnskala för att få metodtips och körbara resurser. Den här artikelns referensarkitekturer erbjuder utgångspunkter för att starta implementeringen.