Felsöka vanliga problem i Azure Cosmos DB för Apache Cassandra
GÄLLER FÖR: ![]() Kassandra
Kassandra
API:et för Cassandra i Azure Cosmos DB är ett kompatibilitetslager som ger stöd för trådprotokoll för Apache Cassandra-databasen med öppen källkod.
I den här artikeln beskrivs vanliga fel och lösningar för program som använder Azure Cosmos DB för Apache Cassandra. Om felet inte visas och du får ett fel när du kör en åtgärd som stöds i Cassandra, men felet inte finns när du använder inbyggda Apache Cassandra, skapar du en Azure-supportbegäran.
Kommentar
Som en fullständigt hanterad molnbaserad tjänst ger Azure Cosmos DB garantier för tillgänglighet, dataflöde och konsekvens för API:et för Cassandra. API:et för Cassandra underlättar även plattformsåtgärder utan underhåll och noll stilleståndstid.
Dessa garantier är inte möjliga i tidigare implementeringar av Apache Cassandra, så många av API:et för Cassandra-backend-åtgärder skiljer sig från Apache Cassandra. Vi rekommenderar särskilda inställningar och metoder för att undvika vanliga fel.
NoNodeAvailableException
Det här felet är ett undantag på den översta nivån med ett stort antal möjliga orsaker och inre undantag, varav många kan vara klientrelaterade.
Vanliga orsaker och lösningar:
Tidsgräns för inaktivitet för Azure LoadBalancers: Det här problemet kan också visas som
ClosedConnectionException. Lös problemet genom att ange inställningen keep-alive i drivrutinen (se Aktivera keep-alive för Java-drivrutinen) och öka keep-alive-inställningarna i operativsystemet eller justera tidsgränsen för inaktivitet i Azure Load Balancer.Resursöverbelastning för klientprogram: Se till att klientdatorerna har tillräckligt med resurser för att slutföra begäran.
Det går inte att ansluta till en värd
Du kan se det här felet: "Det går inte att ansluta till någon värd, schemaläggningen försöker igen om 600000 millisekunder."
Det här felet kan orsakas av SNAT-överbelastning (source network address translation) på klientsidan. Följ stegen i SNAT för utgående anslutningar för att utesluta det här problemet.
Felet kan också vara ett inaktivt timeout-problem där Azure-lastbalanseraren har fyra minuters tidsgräns för inaktivitet som standard. Se Tidsgräns för inaktivitet för lastbalanserare. Aktivera keep-alive för Java-drivrutinen och ange keepAlive intervallet för operativsystemet till mindre än fyra minuter.
Mer information om hur du hanterar undantaget finns i felsöka NoHostAvailableException .
OverloadedException (Java)
Begäranden begränsas eftersom det totala antalet förbrukade enheter för begäran är högre än antalet enheter för begäranden som du etablerade i nyckelområdet eller tabellen.
Överväg att skala dataflödet som tilldelats till ett nyckelområde eller en tabell från Azure-portalen (se Skala en Azure Cosmos DB elastiskt för Apache Cassandra-konto) eller implementera en återförsöksprincip.
För Java kan du läsa exempel på nya försök för v3.x-drivrutinen och v4.x-drivrutinen. Se även Azure Cosmos DB Cassandra-tillägg för Java.
OverloadedException trots tillräckligt dataflöde
Systemet verkar begränsa begäranden trots att tillräckligt med dataflöde har etablerats för begärandevolym eller förbrukad enhetskostnad för begäranden. Det finns två möjliga orsaker:
Åtgärder på schemanivå: API:et för Cassandra implementerar en systemdataflödesbudget för åtgärder på schemanivå (CREATE TABLE, ALTER TABLE, DROP TABLE). Den här budgeten bör räcka för schemaåtgärder i ett produktionssystem. Men om du har ett stort antal åtgärder på schemanivå kan du överskrida den här gränsen.
Eftersom budgeten inte är användarkontrollerad kan du överväga att minska antalet schemaåtgärder som du kör. Om åtgärden inte löser problemet eller om det inte är möjligt för din arbetsbelastning skapar du en Azure-supportbegäran.
Datasnedvridning: När dataflödet etableras i API:et för Cassandra delas det lika mellan fysiska partitioner och varje fysisk partition har en övre gräns. Om du har en hög mängd data som infogas eller efterfrågas från en viss partition kan det vara hastighetsbegränsat även om du etablerar en stor mängd övergripande dataflöde (enheter för begäran) för den tabellen.
Granska datamodellen och se till att du inte har för mycket skevhet som kan orsaka frekventa partitioner.
Tillfälliga anslutningsfel (Java)
Anslutningen avbryts eller överskrids oväntat.
Apache Cassandra-drivrutinerna för Java tillhandahåller två interna återanslutningsprinciper: ExponentialReconnectionPolicy och ConstantReconnectionPolicy. Standardvärdet är ExponentialReconnectionPolicy. För Azure Cosmos DB för Apache Cassandra rekommenderar ConstantReconnectionPolicy vi dock med två sekunders fördröjning.
Se dokumentationen för Java 4.x-drivrutinen, dokumentationen för Java 3.x-drivrutinen eller Konfigurera ReconnectionPolicy för Java-drivrutinsexemplen .
Fel med belastningsutjämningsprincip
Du kan ha implementerat en belastningsutjämningsprincip i v3.x av Java DataStax-drivrutinen, med kod som liknar:
cluster = Cluster.builder()
.addContactPoint(cassandraHost)
.withPort(cassandraPort)
.withCredentials(cassandraUsername, cassandraPassword)
.withPoolingOptions(new PoolingOptions() .setConnectionsPerHost(HostDistance.LOCAL, 1, 2)
.setMaxRequestsPerConnection(HostDistance.LOCAL, 32000).setMaxQueueSize(Integer.MAX_VALUE))
.withSSL(sslOptions)
.withLoadBalancingPolicy(DCAwareRoundRobinPolicy.builder().withLocalDc("West US").build())
.withQueryOptions(new QueryOptions().setConsistencyLevel(ConsistencyLevel.LOCAL_QUORUM))
.withSocketOptions(getSocketOptions())
.build();
Om värdet för withLocalDc() inte matchar kontaktpunktens datacenter kan det uppstå ett tillfälligt fel: com.datastax.driver.core.exceptions.NoHostAvailableException: All host(s) tried for query failed (no host was tried).
Implementera CosmosLoadBalancingPolicy. För att få det att fungera kan du behöva uppgradera DataStax med hjälp av följande kod:
LoadBalancingPolicy loadBalancingPolicy = new CosmosLoadBalancingPolicy.Builder().withWriteDC("West US").withReadDC("West US").build();
Antalet misslyckas för en stor tabell
När du kör select count(*) from table eller liknande för ett stort antal rader överskrider servern tidsgränsen.
Om du använder en lokal CQLSH-klient ändrar du --connect-timeout inställningarna eller --request-timeout . Se cqlsh: CQL-gränssnittet.
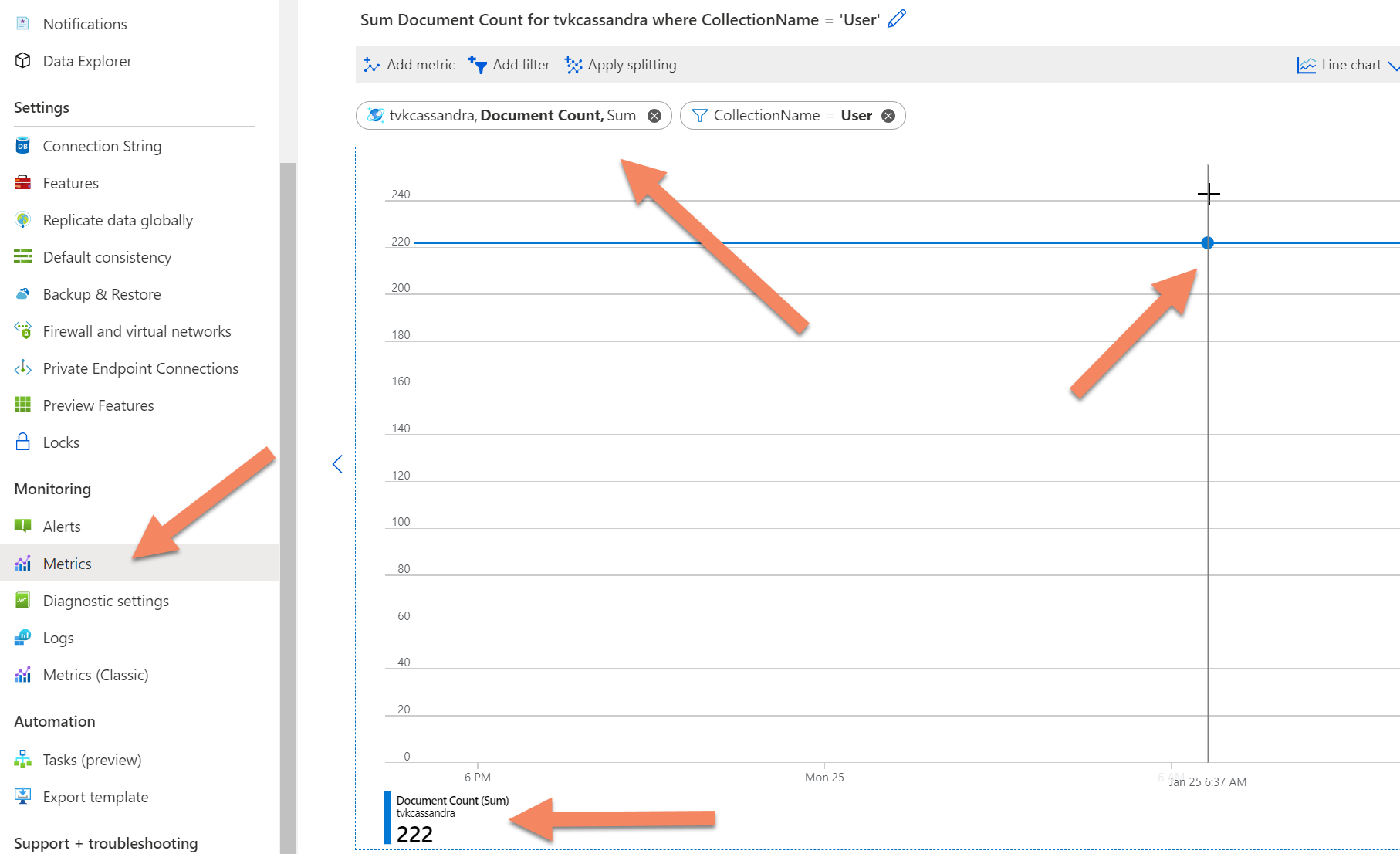
Om antalet fortfarande överskrider tidsgränsen kan du få ett antal poster från Azure Cosmos DB-backend-telemetrin genom att gå till fliken mått i Azure-portalen, välja måttet document countoch sedan lägga till ett filter för databasen eller samlingen (analogen för tabellen i Azure Cosmos DB). Du kan sedan hovra över det resulterande diagrammet för den tidpunkt då du vill ha ett antal poster.
Konfigurera ReconnectionPolicy för Java-drivrutinen
Version 3.x
För version 3.x av Java-drivrutinen konfigurerar du återanslutningsprincipen när du skapar ett klusterobjekt:
import com.datastax.driver.core.policies.ConstantReconnectionPolicy;
Cluster.builder()
.withReconnectionPolicy(new ConstantReconnectionPolicy(2000))
.build();
Version 4.x
För version 4.x av Java-drivrutinen konfigurerar du återanslutningsprincipen genom att åsidosätta inställningarna i reference.conf filen:
datastax-java-driver {
advanced {
reconnection-policy{
# The driver provides two implementations out of the box: ExponentialReconnectionPolicy and
# ConstantReconnectionPolicy. We recommend ConstantReconnectionPolicy for API for Cassandra, with
# base-delay of 2 seconds.
class = ConstantReconnectionPolicy
base-delay = 2 second
}
}
Aktivera keep-alive för Java-drivrutinen
Version 3.x
För version 3.x av Java-drivrutinen anger du keep-alive när du skapar ett klusterobjekt och kontrollerar sedan att keep-alive är aktiverat i operativsystemet:
import java.net.SocketOptions;
SocketOptions options = new SocketOptions();
options.setKeepAlive(true);
cluster = Cluster.builder().addContactPoints(contactPoints).withPort(port)
.withCredentials(cassandraUsername, cassandraPassword)
.withSocketOptions(options)
.build();
Version 4.x
För version 4.x av Java-drivrutinen anger du keep-alive genom att åsidosätta inställningarna i reference.confoch kontrollerar sedan att keep-alive är aktiverat i operativsystemet:
datastax-java-driver {
advanced {
socket{
keep-alive = true
}
}
Nästa steg
- Lär dig mer om funktioner som stöds i Azure Cosmos DB för Apache Cassandra.
- Lär dig hur du migrerar från inbyggda Apache Cassandra till Azure Cosmos DB för Apache Cassandra.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för