Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Viktigt!
Letar du efter en databaslösning för storskaliga scenarier med ett serviceavtal på 99,999% tillgänglighetsnivå (SLA), snabb autoskalning och automatisk redundans i flera regioner? Överväg Azure Cosmos DB för NoSQL.
Vill du implementera ett OLAP-diagram (Online Analytical Processing) eller migrera ett befintligt Apache Gremlin-program? Överväg Graph i Microsoft Fabric.
Den här artikeln innehåller rekommendationer för användning av diagramdatamodeller. Dessa metodtips är viktiga för att säkerställa skalbarhet och prestanda för ett grafdatabassystem allt eftersom data utvecklas. En effektiv datamodell är särskilt viktig för storskaliga grafer.
Krav
Den process som beskrivs i den här guiden baseras på följande antaganden:
- Entiteterna i problemutrymmet identifieras. Dessa entiteter är avsedda att användas atomiskt för varje begäran. Databassystemet är med andra ord inte utformat för att hämta en enskild entitetsdata i flera frågebegäranden.
- Det finns en förståelse för läs- och skrivkraven för databassystemet. Dessa krav vägleder de optimeringar som behövs för grafdatamodellen.
- Principerna för egenskapsgrafstandarden från Apache är väl förstådda.
När behöver jag en grafdatabas?
En grafdatabaslösning kan användas optimalt om entiteterna och relationerna i en datadomän har någon av följande egenskaper:
- Entiteterna är starkt anslutna via beskrivande relationer. Fördelen i det här scenariot är att relationerna finns kvar i lagringen.
- Det finns cykliska relationer eller självreferenserade entiteter. Det här mönstret är ofta en utmaning när du använder relations- eller dokumentdatabaser.
- Det finns dynamiskt föränderliga relationer mellan entiteter. Det här mönstret gäller särskilt för hierarkiska eller trädstrukturerade data med många nivåer.
- Det finns många-till-många-relationer mellan entiteter.
- Det finns skriv- och läskrav för både entiteter och relationer.
Om ovanstående villkor uppfylls ger en grafdatabasmetod sannolikt fördelar för frågekomplexitet, skalbarhet för datamodeller och frågeprestanda.
Nästa steg är att avgöra om grafen ska användas i analys- eller transaktionssyfte. Om diagrammet är avsett att användas för tunga arbetsbelastningar för beräkning och databearbetning är det värt att utforska Cosmos DB Spark-anslutningsappen och GraphX-biblioteket.
Så här använder du grafobjekt
Egenskapsgrafstandarden från Apache definierar två typer av objekt: hörn och kanter.
Följande är metodtips för egenskaperna i grafobjekten:
| Objekt | Property | Type | Anteckningar |
|---|---|---|---|
| Hörn | ID | String | Unikt framtvingad per partition. Om ett värde inte anges vid infogning lagras ett automatiskt genererat GUID. |
| Hörn | Etikett | String | Den här egenskapen används för att definiera vilken typ av entitet som hörnet representerar. Om ett värde inte anges används ett standardvärdehörn. |
| Hörn | Egenskaper | Sträng, booleskt, numeriskt | En lista över separata egenskaper som lagras som nyckel/värde-par i varje hörn. |
| Hörn | Partitionsnyckel | Sträng, booleskt, numeriskt | Den här egenskapen definierar var brytpunkten och dess utgående kanter lagras. Läs mer om grafpartitionering. |
| Kanter | ID | String | Unikt framtvingad per partition. Genereras automatiskt som standard. Kanter behöver vanligtvis inte hämtas unikt med hjälp av ett ID. |
| Kanter | Etikett | String | Den här egenskapen används för att definiera den typ av relation som två hörn har. |
| Kanter | Egenskaper | Sträng, booleskt, numeriskt | En lista över separata egenskaper som lagras som nyckel/värde-par i varje kant. |
Kommentar
Kanter kräver inte ett partitionsnyckelvärde, eftersom värdet tilldelas automatiskt baserat på deras källhörn. Läs mer i Använda en partitionerad graf i Azure Cosmos DB.
Riktlinjer för entitets- och relationsmodellering
Följande riktlinjer hjälper dig att närma dig datamodellering för en Azure Cosmos DB för Apache Gremlin-grafdatabas . Dessa riktlinjer förutsätter att det finns en befintlig definition av en datadomän och frågor för den.
Kommentar
Följande steg visas som rekommendationer. Du bör utvärdera och testa den slutliga modellen innan du överväger den som produktionsklar. Dessutom är rekommendationerna specifika för Azure Cosmos DB:s Gremlin API-implementering.
Modelleringshörn och egenskaper
Det första steget för en diagramdatamodell är att mappa varje identifierad entitet till ett hörnobjekt. En en-till-en-mappning av alla entiteter till hörn bör vara ett första steg och kan komma att ändras.
En vanlig fallgrop är att mappa egenskaper för en enskild entitet som separata hörn. Tänk dig följande exempel, där samma entitet representeras på två olika sätt:
Hörnbaserade egenskaper: I den här metoden använder entiteten tre separata hörn och två kanter för att beskriva dess egenskaper. Även om den här metoden kan minska redundansen ökar modellens komplexitet. En ökning av modellkomplexiteten kan leda till ökad svarstid, frågekomplexitet och beräkningskostnad. Den här modellen kan också innebära utmaningar vid partitionering.
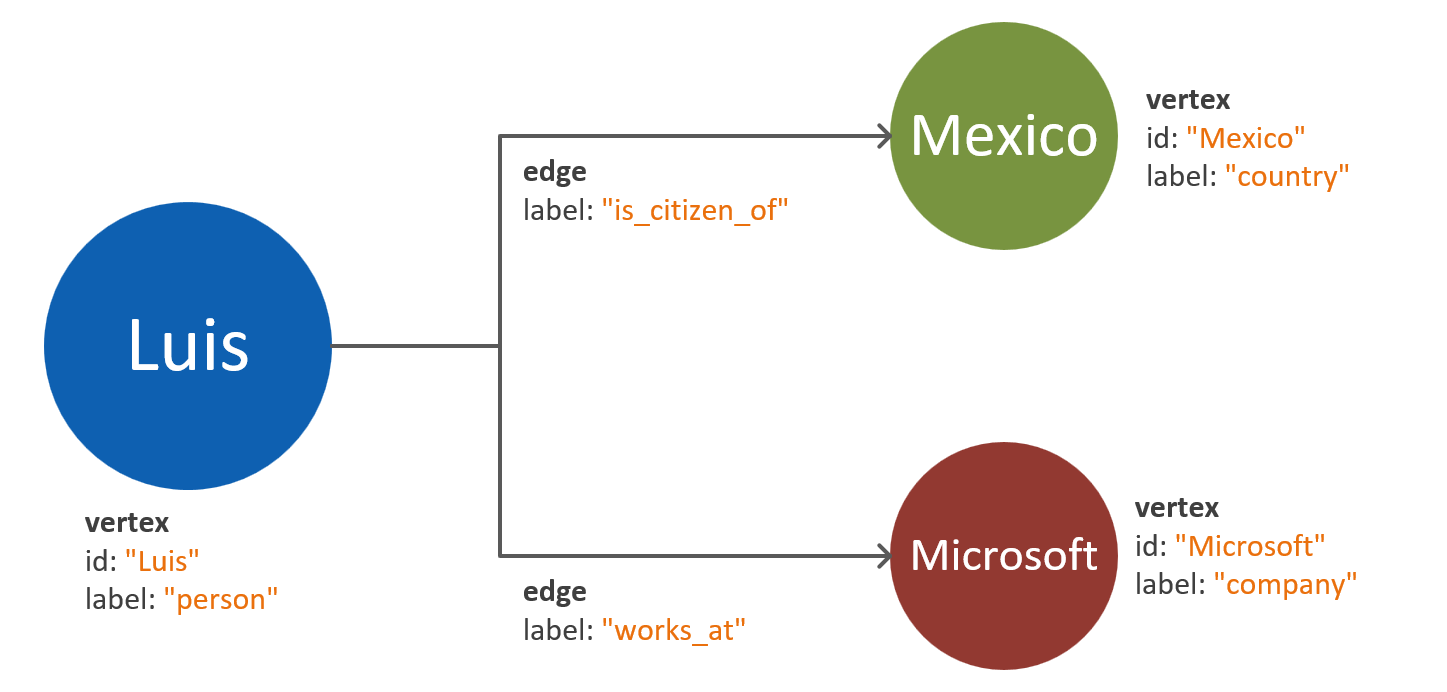
Egenskaps-inbäddade hörn: Den här metoden utnyttjar nyckel/värde-parlistan för att representera alla egenskaper för entiteten i ett hörn. Den här metoden minskar modellkomplexiteten, vilket leder till enklare frågor och mer kostnadseffektiva blädderingar.

Kommentar
Föregående diagram visar en förenklad grafmodell som bara jämför de två sätten att dela entitetsegenskaper.
Mönstret för egenskapsbäddade hörn ger vanligtvis en mer högpresterande och skalbar metod. Standardmetoden för en ny diagramdatamodell bör dras till det här mönstret.
Det finns dock scenarier där hänvisning till en egenskap kan ge fördelar. Om den refererade egenskapen till exempel uppdateras ofta. Använd ett separat hörn för att representera en egenskap som ständigt ändras för att minimera mängden skrivåtgärder som krävs för uppdateringen.
Relationsmodeller med kantriktningar
När hörnen har modellerats kan kanterna läggas till för att ange relationerna mellan dem. Den första aspekten som måste utvärderas är relationens riktning.
Kanter har en standardriktning som följs av en bläddering när du använder out() funktionerna eller outE() . Den här naturliga riktningen resulterar i en effektiv åtgärd, eftersom alla hörn lagras med sina utgående kanter.
Om du går i motsatt riktning mot en kant resulterar det alltid i en fråga mellan partitioner genom att använda in() funktionen. Läs mer om grafpartitionering. Om frekvent bläddering med in() funktionen krävs lägger du till kanter i båda riktningarna.
Du kan bestämma kantriktningen med hjälp .to() av eller .from() predikaten .addE() med Gremlin-steget. Eller genom att använda massexekutorbiblioteket för Gremlin API.
Kommentar
Kanterna har en riktning som standard.
Relationsetiketter
Om du använder beskrivande relationsetiketter kan du förbättra effektiviteten för gränsmatchningsåtgärder. Du kan använda det här mönstret på följande sätt:
- Använd icke-generiska termer för att märka en relation.
- Associera etiketten för källhörnet till etiketten för målhörnet med relationsnamnet.
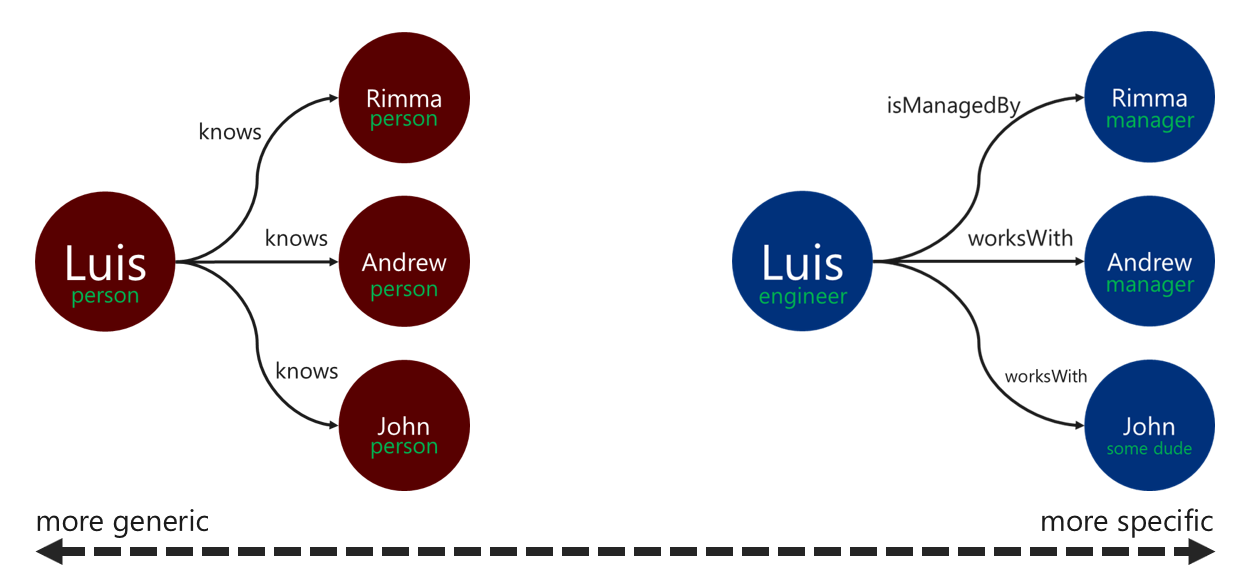
Ju mer specifik etiketten som bläddraren använder för att filtrera kanterna, desto bättre. Det här beslutet kan också ha en betydande effekt på frågekostnaden. Du kan utvärdera frågekostnaden när som helst med hjälp executionProfile av steget .