Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
GÄLLER FÖR: ![]() MongoDB
MongoDB
Den här migreringsguiden är en del av serien om migrering av databaser från MongoDB till Azure Cosmos DB API för MongoDB. De kritiska migreringsstegen är före migrering, migrering och efter migrering, enligt nedan.

Datamigrering med Azure Databricks
Azure Databricks är ett PaaS-erbjudande (plattform som en tjänst) för Apache Spark. Den erbjuder ett sätt att utföra offlinemigreringar på en storskalig datauppsättning. Du kan använda Azure Databricks för att utföra en offlinemigrering av databaser från MongoDB till Azure Cosmos DB för MongoDB.
I den här självstudien får du lära dig hur man:
Etablera ett Azure Databricks-kluster
Lägga till beroenden
Skapa och köra Notebook-filen Scala eller Python
Optimera migreringsprestanda
Felsöka hastighetsbegränsningsfel som kan observeras under migreringen
Förutsättningar
För att slutföra den här kursen behöver du:
- Slutför stegen före migreringen , till exempel att beräkna dataflödet och välja en shardnyckel.
- Skapa ett Azure Cosmos DB för MongoDB-konto.
Etablera ett Azure Databricks-kluster
Du kan följa anvisningarna för att etablera ett Azure Databricks-kluster. Vi rekommenderar att du väljer Databricks runtime version 7.6, som stöder Spark 3.0.
Lägga till beroenden
Lägg till MongoDB-anslutningsappen för Spark-biblioteket i klustret för att ansluta till både interna MongoDB- och Azure Cosmos DB för MongoDB-slutpunkter. I klustret väljer du Bibliotek>Installera ny>Maven och lägger sedan till org.mongodb.spark:mongo-spark-connector_2.12:3.0.1 Maven-koordinater.
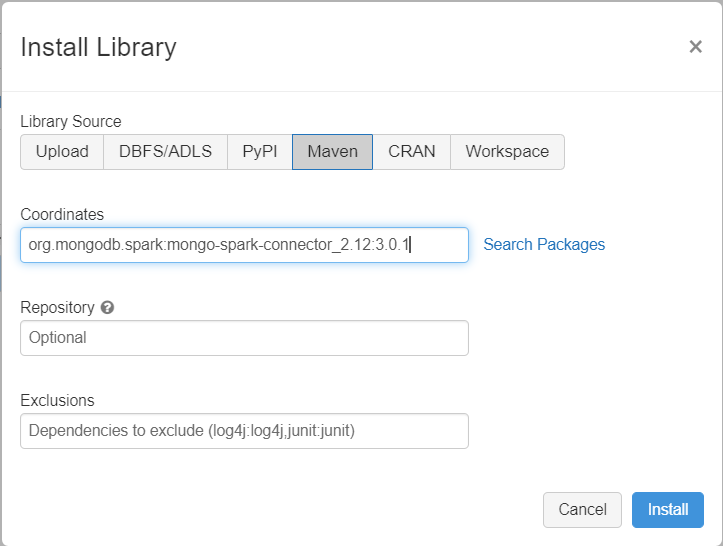
Välj Installera och starta sedan om klustret när installationen är klar.
Kommentar
Se till att du startar om Databricks-klustret när MongoDB-anslutningsappen för Spark-biblioteket har installerats.
Därefter kan du skapa en Scala- eller Python-notebook-fil för migrering.
Skapa Scala Notebook för migrering
Skapa en Scala Notebook i Databricks. Se till att ange rätt värden för variablerna innan du kör följande kod:
import com.mongodb.spark._
import com.mongodb.spark.config._
import org.apache.spark._
import org.apache.spark.sql._
var sourceConnectionString = "mongodb://<USERNAME>:<PASSWORD>@<HOST>:<PORT>/<AUTHDB>"
var sourceDb = "<DB NAME>"
var sourceCollection = "<COLLECTIONNAME>"
var targetConnectionString = "mongodb://<ACCOUNTNAME>:<PASSWORD>@<ACCOUNTNAME>.mongo.cosmos.azure.com:10255/?ssl=true&replicaSet=globaldb&retrywrites=false&maxIdleTimeMS=120000&appName=@<ACCOUNTNAME>@"
var targetDb = "<DB NAME>"
var targetCollection = "<COLLECTIONNAME>"
val readConfig = ReadConfig(Map(
"spark.mongodb.input.uri" -> sourceConnectionString,
"spark.mongodb.input.database" -> sourceDb,
"spark.mongodb.input.collection" -> sourceCollection,
))
val writeConfig = WriteConfig(Map(
"spark.mongodb.output.uri" -> targetConnectionString,
"spark.mongodb.output.database" -> targetDb,
"spark.mongodb.output.collection" -> targetCollection,
"spark.mongodb.output.maxBatchSize" -> "8000"
))
val sparkSession = SparkSession
.builder()
.appName("Data transfer using spark")
.getOrCreate()
val customRdd = MongoSpark.load(sparkSession, readConfig)
MongoSpark.save(customRdd, writeConfig)
Skapa Python-notebook-fil för migrering
Skapa en Python Notebook i Databricks. Se till att ange rätt värden för variablerna innan du kör följande kod:
from pyspark.sql import SparkSession
sourceConnectionString = "mongodb://<USERNAME>:<PASSWORD>@<HOST>:<PORT>/<AUTHDB>"
sourceDb = "<DB NAME>"
sourceCollection = "<COLLECTIONNAME>"
targetConnectionString = "mongodb://<ACCOUNTNAME>:<PASSWORD>@<ACCOUNTNAME>.mongo.cosmos.azure.com:10255/?ssl=true&replicaSet=globaldb&retrywrites=false&maxIdleTimeMS=120000&appName=@<ACCOUNTNAME>@"
targetDb = "<DB NAME>"
targetCollection = "<COLLECTIONNAME>"
my_spark = SparkSession \
.builder \
.appName("myApp") \
.getOrCreate()
df = my_spark.read.format("com.mongodb.spark.sql.DefaultSource").option("uri", sourceConnectionString).option("database", sourceDb).option("collection", sourceCollection).load()
df.write.format("mongo").mode("append").option("uri", targetConnectionString).option("maxBatchSize",2500).option("database", targetDb).option("collection", targetCollection).save()
Optimera migreringsprestanda
Migreringsprestanda kan justeras genom dessa konfigurationer:
Antal arbetare och kärnor i Spark-klustret: Fler arbetare innebär fler beräkningsshards för att utföra uppgifter.
maxBatchSize: Värdet
maxBatchSizestyr hur snabbt data sparas i Azure Cosmos DB-målsamlingen. Men om maxBatchSize är för högt för samlingens dataflöde kan det orsaka hastighetsbegränsningsfel .Du skulle behöva justera antalet arbetare och maxBatchSize, beroende på antalet utförare i Spark-klustret, potentiellt storleken (och det är därför RU-kostnaden) för varje dokument skrivs och målsamlingens dataflödesgränser.
Dricks
maxBatchSize = Insamlingsdataflöde/( RU-kostnad för 1 dokument * antal Spark-arbetare * antal CPU-kärnor per arbetare )
MongoDB Spark-partitionerare och partitionKey: Standardpartitioneraren som används är MongoDefaultPartitioner och standardpartitionKey är _id. Partitioneraren kan ändras genom att tilldela värdet
MongoSamplePartitionertill indatakonfigurationsegenskapenspark.mongodb.input.partitioner. På samma sätt kan partitionKey ändras genom att tilldela lämpligt fältnamn till indatakonfigurationsegenskapenspark.mongodb.input.partitioner.partitionKey. Höger partitionKey kan hjälpa till att undvika datasnedvridning (ett stort antal poster skrivs för samma shardnyckelvärde).Inaktivera index under dataöverföring: För stora mängder datamigrering bör du överväga att inaktivera index, särskilt jokerteckenindex i målsamlingen. Index ökar RU-kostnaden för att skriva varje dokument. Om du frigör dessa RU:er kan du förbättra dataöverföringshastigheten. Du kan aktivera indexen när data har migrerats över.
Felsöka
Timeout-fel (felkod 50)
Du kan se en 50-felkod för åtgärder mot Azure Cosmos DB for MongoDB-databasen. Följande scenarier kan orsaka timeout-fel:
- Dataflödet som allokerats till databasen är lågt: Kontrollera att målsamlingen har tillräckligt med dataflöde tilldelat till den.
- Överdriven dataförskjutning med stor datavolym. Om du har en stor mängd data att migrera till en viss tabell men har en betydande snedställning i data, kan du fortfarande uppleva hastighetsbegränsning även om du har flera enheter för begäranden etablerade i tabellen. Enheter för begärande delas lika mellan fysiska partitioner, och stora datasnedvridningar kan orsaka en flaskhals med begäranden till en enda shard. Datasnedvridning innebär ett stort antal poster för samma shardnyckelvärde.
Hastighetsbegränsning (felkod 16500)
Du kan se en 16500-felkod för åtgärder mot Azure Cosmos DB for MongoDB-databasen. Det här är hastighetsbegränsningsfel och kan observeras på äldre konton eller konton där funktionen för återförsök på serversidan är inaktiverad.
- Aktivera återförsök på serversidan: Aktivera funktionen SSR (Server Side Retry) och låt servern försöka med hastighetsbegränsade åtgärder automatiskt.
Optimering efter migrering
När du har migrerat data kan du ansluta till Azure Cosmos DB och hantera data. Du kan också följa andra steg efter migreringen, till exempel optimera indexeringsprincipen, uppdatera standardkonsekvensnivån eller konfigurera global distribution för ditt Azure Cosmos DB-konto. Mer information finns i artikeln om optimering efter migreringen.
Ytterligare resurser
- Försöker du planera kapacitet för en migrering till Azure Cosmos DB?
- Om allt du vet är antalet virtuella kärnor och servrar i ditt befintliga databaskluster läser du om att uppskatta enheter för begäranden med virtuella kärnor eller virtuella kärnor
- Om du känner till vanliga begärandefrekvenser för din aktuella databasarbetsbelastning kan du läsa om att uppskatta enheter för begäranden med azure Cosmos DB-kapacitetshanteraren