Översikt över affärskontinuitet och haveriberedskap
Affärskontinuitet och haveriberedskap i Azure Data Explorer gör det möjligt för ditt företag att fortsätta arbeta vid ett avbrott. Den här artikeln beskriver tillgänglighet (inom regionen) och haveriberedskap. Den beskriver inbyggda funktioner och arkitekturöverväganden för en motståndskraftig Azure-Data Explorer distribution. Den beskriver återställning från mänskliga fel, hög tillgänglighet, följt av flera konfigurationer för haveriberedskap. Dessa konfigurationer beror på återhämtningskrav som mål för återställningspunkt (RPO) och mål för återställningstid (RTO), nödvändigt arbete och kostnad.
Minimera avbrottshändelser
- Mänskligt fel
- Hög tillgänglighet för Azure Data Explorer
- Avbrott i en Azure-tillgänglighetszon
- Avbrott i ett Azure-datacenter
- Avbrott i en Azure-region
Mänskligt fel
Mänskliga misstag är oundvikliga. Användare kan oavsiktligt ta bort ett kluster, en databas eller en tabell.
Oavsiktlig borttagning av kluster eller databas
Oavsiktlig borttagning av kluster eller databas är en oåterkallelig åtgärd. Som Azure-Data Explorer resursägare kan du förhindra dataförlust genom att aktivera funktionen för borttagningslås, som är tillgänglig på Azure-resursnivå.
Oavsiktlig borttagning av tabell
Användare med behörighet som tabelladministratör eller högre kan ta bort tabeller. Om någon av dessa användare av misstag tar bort en tabell kan du återställa den .undo drop table med hjälp av kommandot . För att det här kommandot ska lyckas måste du först aktivera återställningsegenskapen i kvarhållningsprincipen.
Oavsiktlig borttagning av extern tabell
Externa tabeller är Kusto-frågeschemaentiteter som refererar till data som lagras utanför databasen. Borttagning av en extern tabell tar bara bort tabellmetadata. Du kan återställa den genom att köra kommandot för att skapa tabellen igen. Använd funktionen för mjuk borttagning för att skydda mot oavsiktlig borttagning eller överskrivning av en fil/blob under en användarkonfigurerad tidsperiod.
Hög tillgänglighet för Azure Data Explorer
Hög tillgänglighet avser feltoleransen för Azure Data Explorer, dess komponenter och underliggande beroenden i en Azure-region. Den här feltoleransen undviker enskilda felpunkter (SPOF) i implementeringen. I Azure Data Explorer innehåller hög tillgänglighet beständighetslagret, beräkningsskiktet och en konfiguration med ledande följare.
Beständighetslager
Azure Data Explorer använder Azure Storage som ett beständigt beständighetslager. Azure Storage ger automatiskt feltolerans, med standardinställningen som erbjuder lokalt redundant lagring (LRS) i ett datacenter. Tre repliker sparas. Om en replik går förlorad när den används distribueras en annan utan avbrott. Ytterligare återhämtning är möjlig med zonredundant lagring (ZRS) som placerar repliker intelligent i azures regionala tillgänglighetszoner för maximal feltolerans till en extra kostnad. ZRS-aktiverad lagring konfigureras automatiskt när Azure Data Explorer-klustret distribueras till Tillgänglighetszoner.
Beräkningsskikt
Azure Data Explorer är en distribuerad databehandlingsplattform och kan ha två till många noder beroende på skalnings- och nodrolltyp. Vid etableringstillfället väljer du tillgänglighetszoner för att distribuera noddistributionen mellan zoner för maximal återhämtning inom regionen. Ett fel i tillgänglighetszonen resulterar inte i ett fullständigt avbrott, utan prestandaförsämring fram till återställningen av zonen.
Konfiguration av Leader-follower-kluster
Azure Data Explorer tillhandahåller en valfri uppföljningsfunktion för ett ledarkluster som ska följas av andra följarkluster för skrivskyddad åtkomst till ledarens data och metadata. Ändringar i ledaren, till exempel create, appendoch drop synkroniseras automatiskt till följaren. Ledarna kan sträcka sig över Azure-regioner, men de följande klustren bör finnas i samma region(er) som ledare. Om leaderklustret ligger nere eller om databaser eller tabeller tas bort av misstag förlorar de följande klustren åtkomst tills åtkomsten återställs i ledaren.
Avbrott i en Azure-tillgänglighetszon
Azure-tillgänglighetszoner är unika fysiska platser i samma Azure-region. De kan skydda ett Azure Data Explorer klusters beräkning och data från partiella regionfel. Zonfel är ett tillgänglighetsscenario eftersom det är inom regionen.
Fäst ett Azure Data Explorer-kluster i samma zon som andra anslutna Azure-resurser. Mer information om hur du aktiverar tillgänglighetszoner finns i Skapa ett kluster.
Anteckning
Distribution till tillgänglighetszoner är möjlig när du skapar ett kluster eller kan migreras senare.
Avbrott i ett Azure-datacenter
Azure-tillgänglighetszoner medför en kostnad och vissa kunder väljer att distribuera utan zonindelad redundans. Med en sådan Azure-Data Explorer distribution resulterar ett avbrott i Azure-datacentret i klusteravbrott. Hantering av ett avbrott i Ett Azure-datacenter är därför identiskt med ett avbrott i En Azure-region.
Avbrott i en Azure-region
Azure Data Explorer ger inte automatiskt skydd mot avbrott i en hel Azure-region. För att minimera påverkan på verksamheten vid ett sådant avbrott kan flera Azure-Data Explorer kluster i länkade Azure-regioner. Baserat på ditt mål för återställningstid (RTO), mål för återställningspunkt (RPO) samt överväganden för arbete och kostnader finns det flera konfigurationer för haveriberedskap. Kostnads- och prestandaoptimeringar är möjliga med Azure Advisor-rekommendationer och konfiguration av autoskalning .
Konfigurationer för haveriberedskap
Det här avsnittet beskriver flera konfigurationer för haveriberedskap beroende på återhämtningskrav (RPO och RTO), nödvändig ansträngning och kostnad.
Mål för återställningstid (RTO) avser den tid det tar att återställa efter ett avbrott. Till exempel innebär RTO på 2 timmar att programmet måste vara igång inom två timmar efter ett avbrott. Mål för återställningspunkt (RPO) avser det tidsintervall som kan passera under ett avbrott innan mängden data som förlorats under den perioden är större än det tillåtna tröskelvärdet. Om RPO till exempel är 24 timmar och ett program har data från och med 15 år sedan ligger de fortfarande inom parametrarna för det överenskomna återställningspunktobjektet.
Inmatnings-, bearbetnings- och kureringsprocesser behöver noggrann design i förväg när du planerar för haveriberedskap. Inmatning refererar till data som är integrerade i Azure Data Explorer från olika källor. Bearbetning refererar till transformeringar och liknande aktiviteter, kuration refererar till materialiserade vyer, exporter till datasjön och så vidare.
Följande är populära konfigurationer för haveriberedskap och var och en beskrivs i detalj nedan.
- Konfiguration av aktiv-aktiv-aktiv (alltid på)
- Aktiv-aktiv-konfiguration
- Väntelägeskonfiguration för aktiv-het
- Konfiguration av dataåterställningskluster på begäran
Aktiv-aktiv-aktiv-konfiguration
Den här konfigurationen kallas även "always-on". För kritiska programdistributioner utan tolerans för avbrott bör du använda flera Azure Data Explorer-kluster i länkade Azure-regioner. Konfigurera inmatning, bearbetning och härdning parallellt med alla kluster. Kluster-SKU:n måste vara densamma i flera regioner. Azure ser till att uppdateringar distribueras och fördelas mellan länkade Azure-regioner. Ett avbrott i En Azure-region orsakar inte ett programstopp. Du kan uppleva viss fördröjning eller prestandaförsämring.
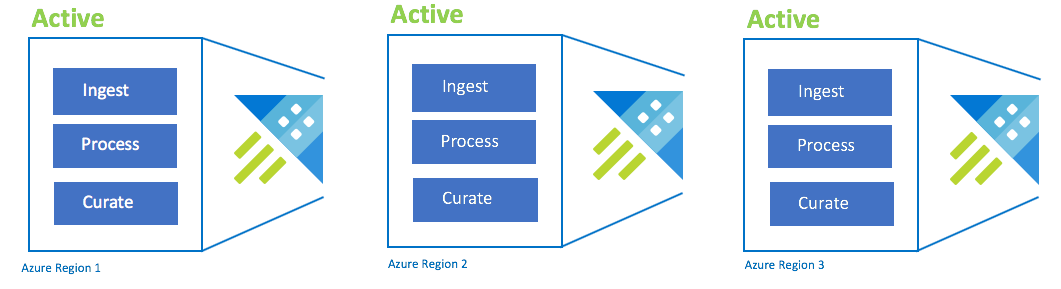
| Konfiguration | RPO | RTO | Projektet | Kostnad |
|---|---|---|---|---|
| Aktiv-aktiv-aktiv-n | 0 timmar | 0 timmar | Lägre | Högsta |
Active-Active konfiguration
Den här konfigurationen är identisk med konfigurationen aktiv-aktiv-aktiv, men omfattar bara två länkade Azure-regioner. Konfigurera dubbel inmatning, bearbetning och härdning. Användarna dirigeras till närmaste region. Kluster-SKU:n måste vara densamma i flera regioner.
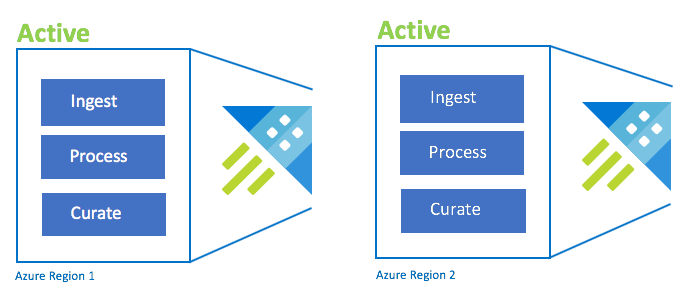
| Konfiguration | RPO | RTO | Projektet | Kostnad |
|---|---|---|---|---|
| Aktiv-aktiv | 0 timmar | 0 timmar | Lägre | Högt |
konfiguration av Active-Hot vänteläge
Den Active-Hot konfigurationen liknar active-active-konfigurationen vid dubbel inmatning, bearbetning och härdning. Väntelägesklustret är online för inmatning, process och kuration, men det är inte tillgängligt för frågor. Standby-klustret behöver inte finnas i samma SKU som det primära klustret. Det kan vara av en mindre SKU och skala, vilket kan leda till att den blir mindre högpresterande. I ett katastrofscenario omdirigeras användarna till väntelägesklustret, som kan skalas upp för att öka prestandan.
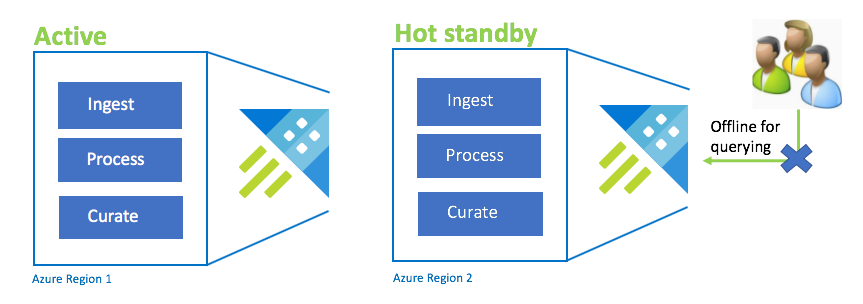
| Konfiguration | RPO | RTO | Projektet | Kostnad |
|---|---|---|---|---|
| Aktiv-het vänteläge | 0 timmar | Låg | Medel | Medel |
Konfiguration av dataåterställning på begäran
Den här lösningen erbjuder minst återhämtning (högsta RPO och RTO), är den lägsta i kostnad och högsta i arbete. I den här konfigurationen finns det inget dataåterställningskluster. Konfigurera kontinuerlig export av granskade data (såvida inte rådata och mellanliggande data också krävs) till ett lagringskonto som har konfigurerats för GRS (geo-redundant lagring). Ett dataåterställningskluster spunnits upp om det finns ett haveriberedskapsscenario. Vid den tidpunkten tillämpas DDL:er, konfiguration, principer och processer. Data matas in från lagring med inmatningsegenskapen kustoCreationTime för att överdriva den inmatningstid som är standard för systemtid.
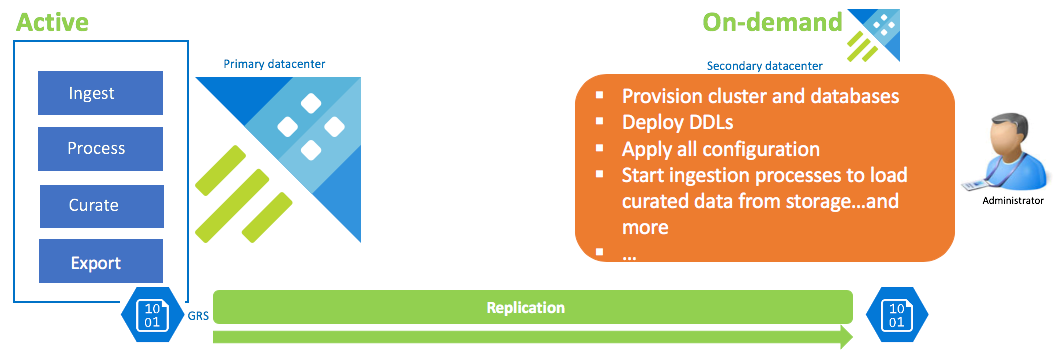
| Konfiguration | RPO | RTO | Projektet | Kostnad |
|---|---|---|---|---|
| Dataåterställningskluster på begäran | Högsta | Högsta | Högsta | Lägsta |
Sammanfattning av konfigurationsalternativ för haveriberedskap
| Konfiguration | Elasticitet | RPO | RTO | Projektet | Kostnad |
|---|---|---|---|---|---|
| Aktiv-aktiv-aktiv-n | Högsta | 0 timmar | 0 timmar | Lägre | Högsta |
| Aktiv-aktiv | Högt | 0 timmar | 0 timmar | Lägre | Högt |
| Aktiv-het vänteläge | Medel | 0 timmar | Låg | Medel | Medel |
| Dataåterställningskluster på begäran | Lägsta | Högsta | Högsta | Högsta | Lägsta |
Bästa praxis
Oavsett vilken konfiguration för haveriberedskap som väljs följer du dessa metodtips:
- Alla databasobjekt, principer och konfigurationer ska bevaras i källkontrollen så att de kan släppas till klustret från versionsautomatiseringsverktyget. Mer information finns i Azure DevOps-stöd för Azure Data Explorer.
- Utforma, utveckla och implementera valideringsrutiner för att säkerställa att alla kluster är synkroniserade ur ett dataperspektiv. Azure Data Explorer stöder korsklusteranslutningar. Ett enkelt antal eller rader mellan tabeller kan hjälpa dig att verifiera.
- Lanseringsprocedurerna bör omfatta styrningskontroller och saldon som säkerställer spegling av klustren.
- Var helt medveten om vad som krävs för att skapa ett kluster från grunden.
- Skapa en checklista med distributionsenheter. Listan är unik för dina behov, men bör innehålla: distributionsskript, inmatningsanslutningar, BI-verktyg och andra viktiga konfigurationer.
Nästa steg
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för