Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Azure DevOps Services tillhandahåller samarbetsverktyg för utveckling, till exempel högpresterande pipelines, kostnadsfria privata Git-lagringsplatser, konfigurerbara Kanban-tavlor och omfattande automatiserade och kontinuerliga testfunktioner. Azure Pipelines är en Azure DevOps-funktion som gör att du kan hantera CI/CD för att distribuera din kod med högpresterande pipelines som fungerar med valfritt språk, plattform och moln. Azure Data Explorer – Pipeline Tools är azure pipelines-uppgiften som gör att du kan skapa versionspipelines och distribuera dina databasändringar till dina Azure Data Explorer-databaser. Den är tillgänglig kostnadsfritt på Visual Studio Marketplace. Tillägget innehåller följande grundläggande uppgifter:
Azure Data Explorer-kommando – Köra administratörskommandon mot ett Azure Data Explorer-kluster
Azure Data Explorer-fråga – Kör frågor mot ett Azure Data Explorer-kluster och parsa resultatet
Frågeserverport för Azure Data Explorer – Uppgift utan agent för att styra över versioner beroende på frågeresultatet
Det här dokumentet beskriver ett enkelt exempel på hur du använder uppgiften Azure Data Explorer – Pipeline Tools för att distribuera schemaändringar till databasen. Fullständiga CI/CD-pipelines finns i Dokumentation om Azure DevOps.
Förutsättningar
- Ett Azure-abonnemang. Skapa ett kostnadsfritt Azure-konto.
- Ett Azure Data Explorer-kluster och en databas. Skapa ett kluster och en databas.
- Konfiguration av Azure Data Explorer-kluster:
- Skapa Microsoft Entra-appen genom att etablera ett Microsoft Entra-program.
- Bevilja åtkomst till din Microsoft Entra-app i Azure Data Explorer-databasen genom att hantera databasbehörigheter för Azure Data Explorer.
- Konfiguration av Azure DevOps:
- Tilläggsinstallation:
Om du är Azure DevOps-instansägare installerar du tillägget från Marketplace, annars kontaktar du din Azure DevOps-instansägare och ber dem att installera det.

Förbereda ditt innehåll för lansering
Du kan använda följande metoder för att köra administratörskommandon mot ett kluster i en uppgift:
Använd ett sökmönster för att hämta flera kommandofiler från en lokal agentmapp (byggkällor eller versionsartefakter). Alternativet enkelrad stöder flera filer med ett kommando per fil.

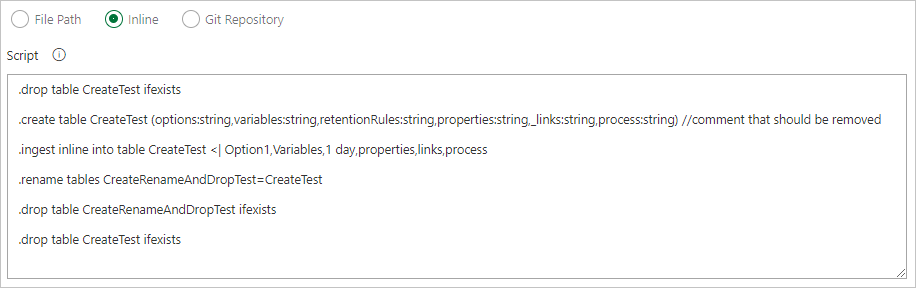
Skriv kommandon inline.
Ange en filsökväg för att hämta kommandofiler direkt från Git-källkontrollen (rekommenderas).
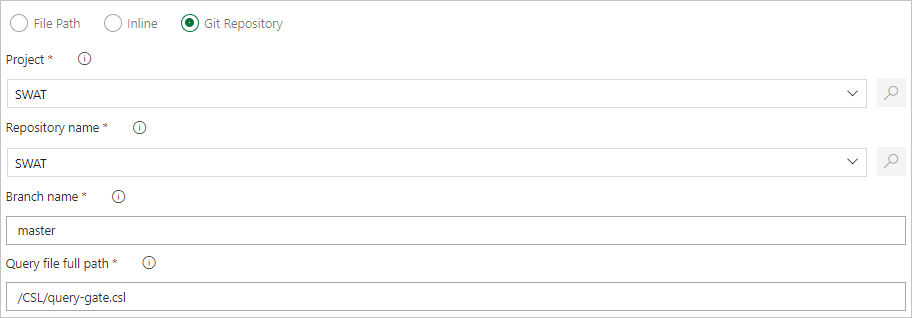
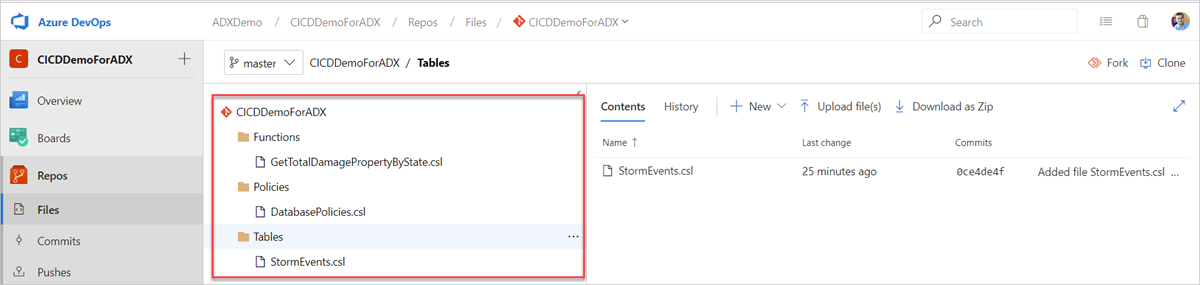
Skapa följande exempelmappar (Funktioner, principer, tabeller) på din Git-lagringsplats. Kopiera filerna från exempellagringsplatsen till respektive mappar och checka in ändringarna. Exempelfilerna tillhandahålls för att köra följande arbetsflöde.
Tips/Råd
När du skapar ett eget arbetsflöde rekommenderar vi att du gör din kod idempotent. Använd till exempel
.create-merge tablei stället för.create tableoch använd.create-or-alterfunktionen i stället för.createfunktionen.
Skapa en versionspipeline
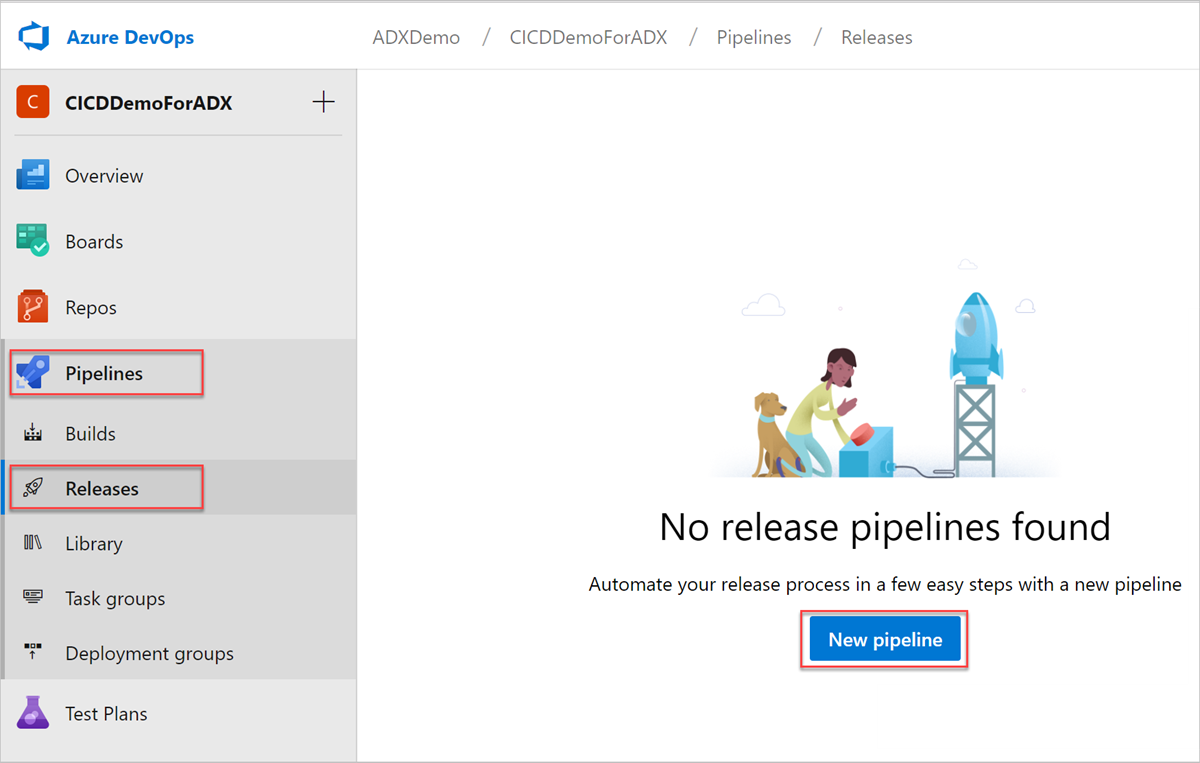
Logga in på din Azure DevOps-organisation.
Välj Pipelines>Versioner från den vänstra menyn och välj sedan Ny pipeline.
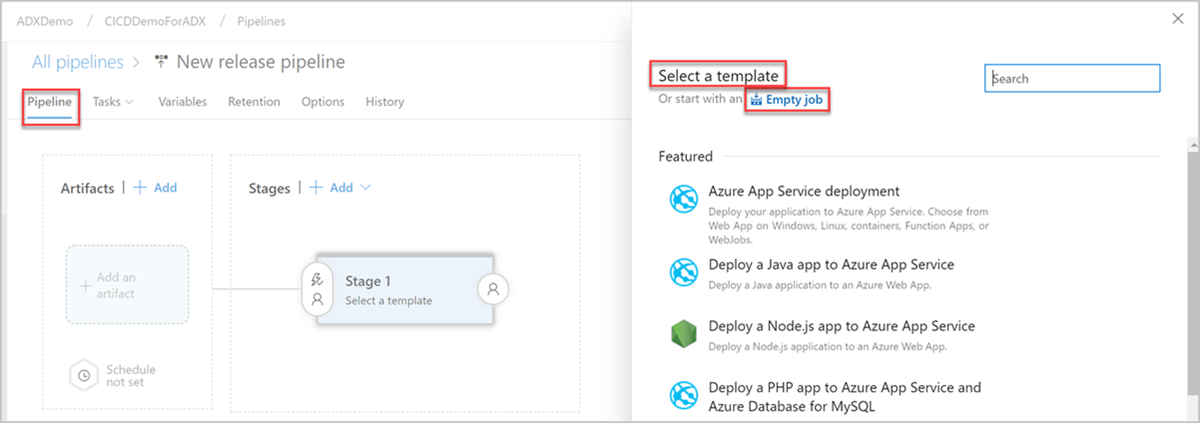
Fönstret Ny versionspipeline öppnas. På fliken Pipelines går du till fönstret Välj en mall och väljer Tomt jobb.
Välj knappen Steg . I fönstret Steg lägger du till stage-namnet och väljer sedan Spara för att spara pipelinen.
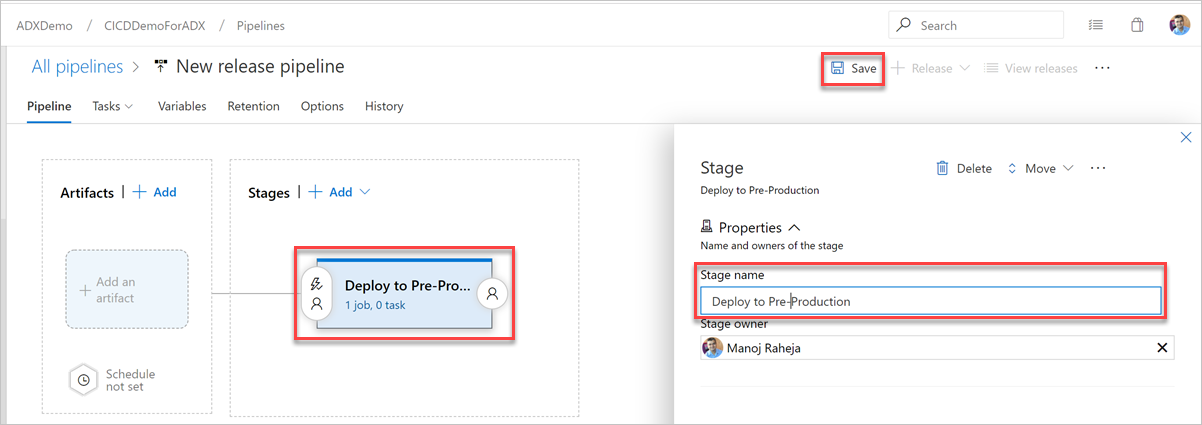
Välj knappen Lägg till en artefakt . I fönstret Lägg till en artefakt väljer du den lagringsplats där koden finns, fyller i relevant information och väljer Lägg till. Välj Spara för att spara din pipeline.
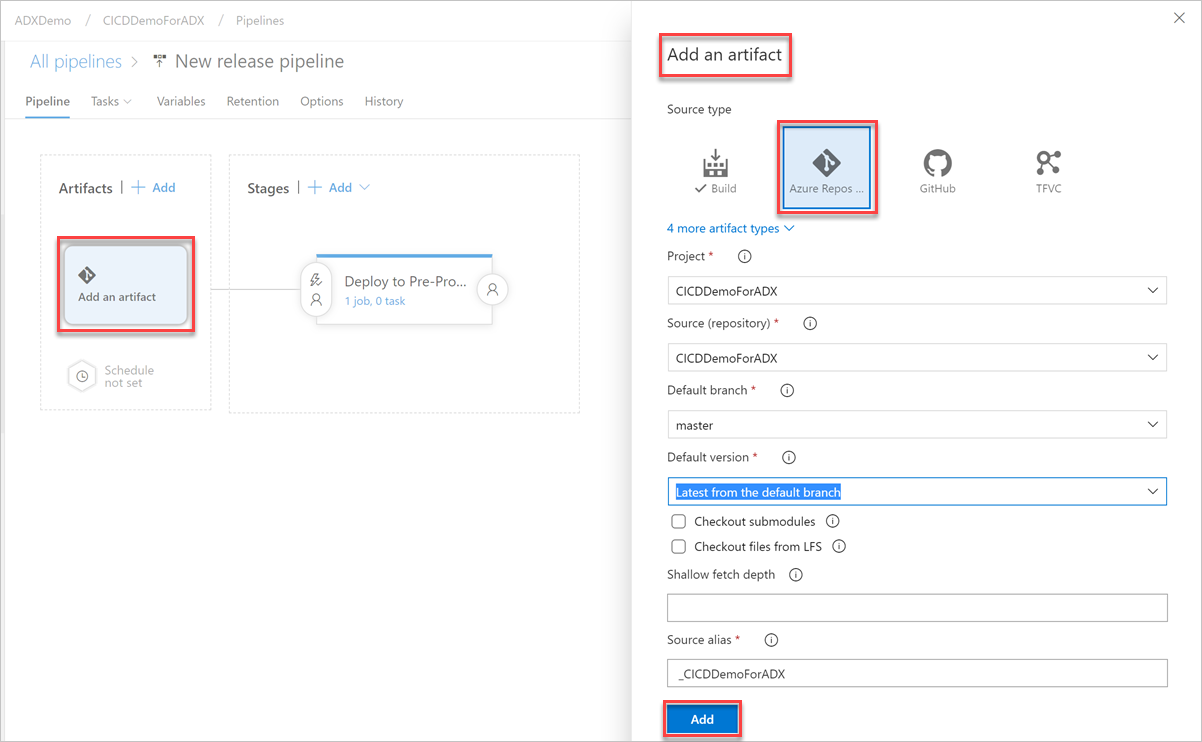
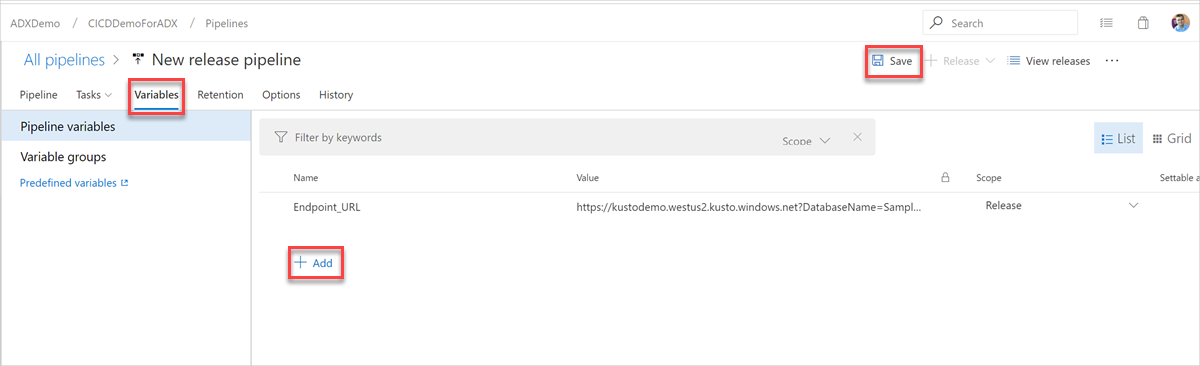
På fliken Variabler väljer du + Lägg till för att skapa en variabel för slutpunkts-URL som används i aktiviteten. Ange slutpunktens namn och värde och välj sedan Spara för att spara pipelinen.
Om du vill hitta slutpunkts-URL:en går du till översiktssidan för ditt Azure Data Explorer-kluster i Azure-portalen och kopierar kluster-URI:n. Konstruera variabelns URI i följande format
https://<ClusterURI>?DatabaseName=<DBName>. Till exempel: https://kustodocs.westus.kusto.windows.net?DatabaseName=SampleDB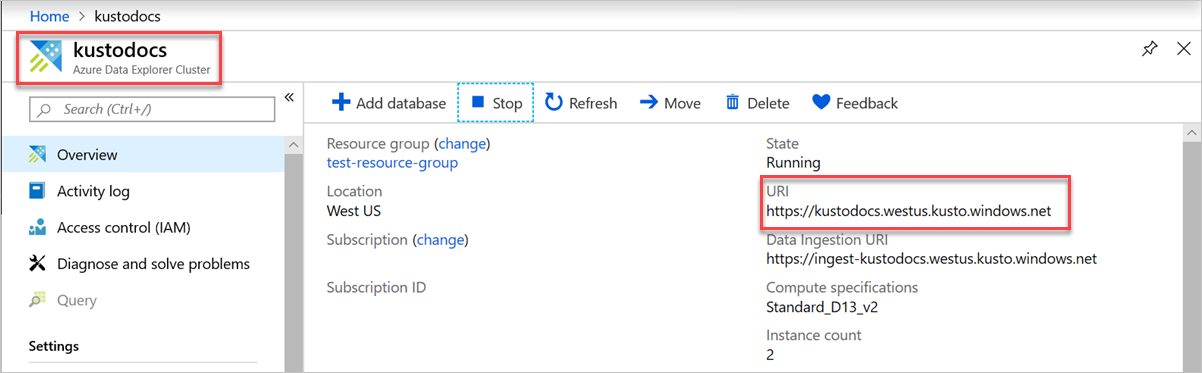
Skapa en uppgift för att distribuera mapparna
På fliken Pipeline väljer du 1 jobb, 0 uppgift för att lägga till aktiviteter.
Upprepa följande steg för att skapa kommandouppgifter för att distribuera filer från mapparna Tabeller, Funktioner och Principer :
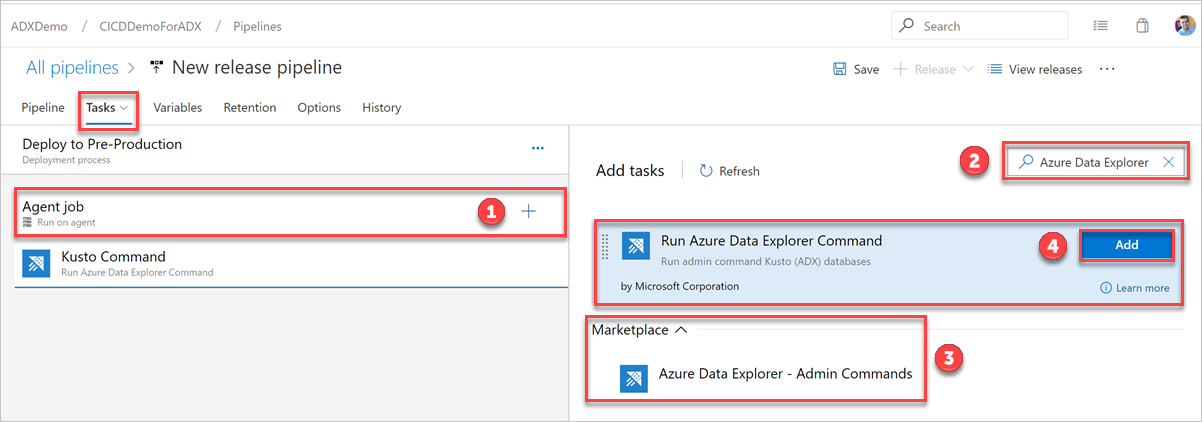
På fliken Uppgifter väljer du + efter Agentjobb och söker efter Azure Data Explorer.
Under Kör Azure Data Explorer-kommandot väljer du Lägg till.
Välj Kusto-kommandot och uppdatera uppgiften med följande information:
Visningsnamn: Aktivitetens namn. Till exempel var
Deploy <FOLDER><FOLDER>är namnet på mappen för distributionsuppgiften som du skapar.Filsökväg: För varje mapp anger du sökvägen som
*/<FOLDER>/*.cslvar<FOLDER>är den relevanta mappen för uppgiften.Slutpunkts-URL: Ange variabeln
EndPoint URLsom skapades i föregående steg.Använd tjänstslutpunkt: Välj det här alternativet.
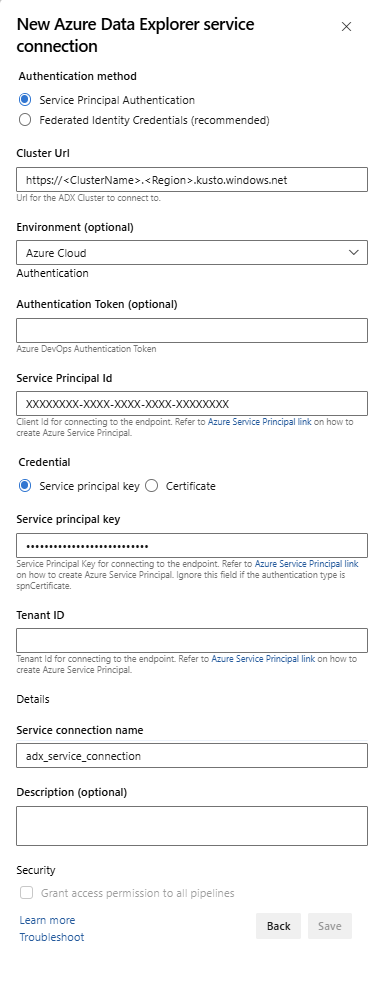
Tjänstslutpunkt: Välj en befintlig tjänstslutpunkt eller skapa en ny (+ Ny) med följande information i fönstret Lägg till Azure Data Explorer-tjänstanslutning :
Inställning Föreslaget värde Autentiseringsmetod Konfigurera federerade identitetshandlingar (FIC) (rekommenderas) eller Välj autentisering med tjänstehuvudprincip (SPA). Anslutningens namn Ange ett namn för att identifiera den här tjänstslutpunkten Kluster-URL Värdet finns i översiktsavsnittet för ditt Azure Data Explorer-kluster i Azure-portalen Tjänstens huvudnamn-ID Ange Microsoft Entra-app-ID :t (skapas som en förutsättning) Service Principal App-nyckel Ange Microsoft Entra-appnyckeln (skapad som en förutsättning) Microsoft Entra klientorganisation-ID Ange din Microsoft Entra-klient (till exempel microsoft.com eller contoso.com)
Markera kryssrutan Tillåt att alla pipelines använder den här anslutningen och välj sedan OK.
Om dina administratörskommandon är långvariga asynkrona åtgärder markerar du kryssrutan Vänta tills långa Async Admin-kommandon har slutförts . När uppgiften är aktiverad avsöker den operationens status med
.show operationstills kommandot har slutförts.
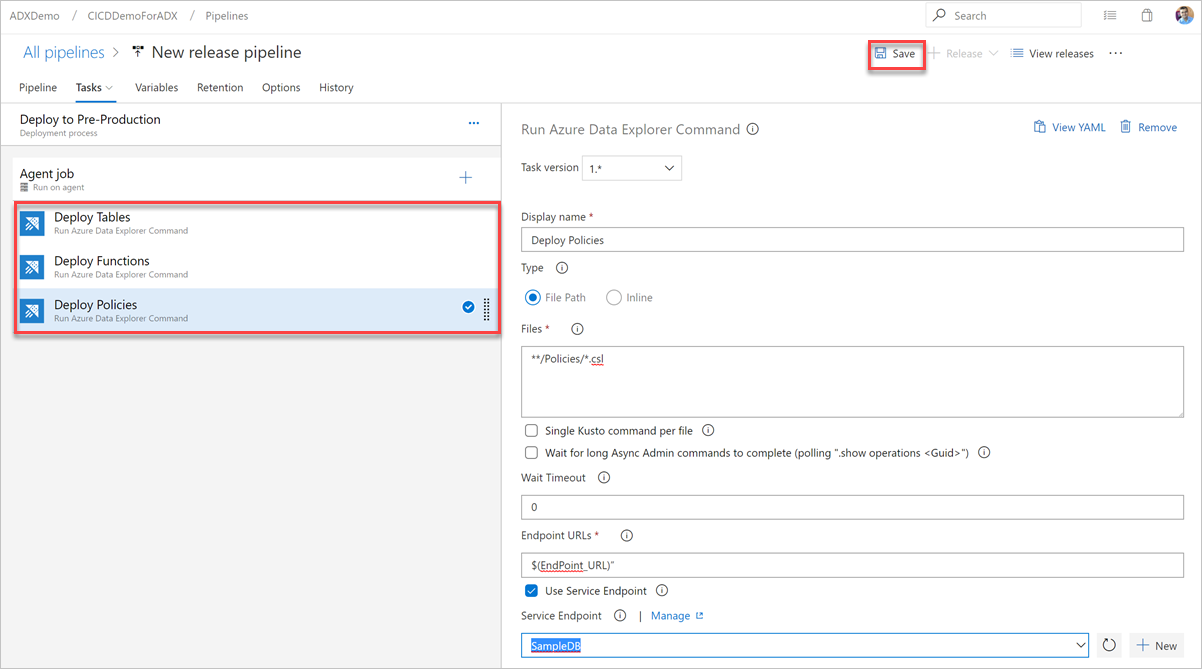
Välj Spara och kontrollera sedan att det finns tre uppgifter på fliken Uppgifter : Distribuera tabeller, Distribuera funktioner och Distribuera principer.
Skapa en frågeaktivitet
Om det behövs skapar du en uppgift för att köra en fråga mot klustret. Köra frågor i en bygg- eller versionspipeline kan användas för att verifiera en datauppsättning och få ett steg att lyckas eller misslyckas baserat på frågeresultatet. Kriterierna för uppgiftsframgång kan baseras på ett tröskelvärde för antal rader eller ett enda värde beroende på vad frågan returnerar.
På fliken Uppgifter väljer du + efter Agentjobb och söker efter Azure Data Explorer.
Under Kör Azure Data Explorer-fråga väljer du Lägg till.
Välj Kusto Query och uppdatera uppgiften med följande information:
- Visningsnamn: Aktivitetens namn. Till exempel Frågekluster.
- Typ: Välj Infogad.
- Fråga: Ange den fråga som du vill köra.
-
Slutpunkts-URL: Ange variabeln som
EndPoint URLskapades tidigare. - Använd tjänstslutpunkt: Välj det här alternativet.
- Tjänstslutpunkt: Välj en tjänstslutpunkt.
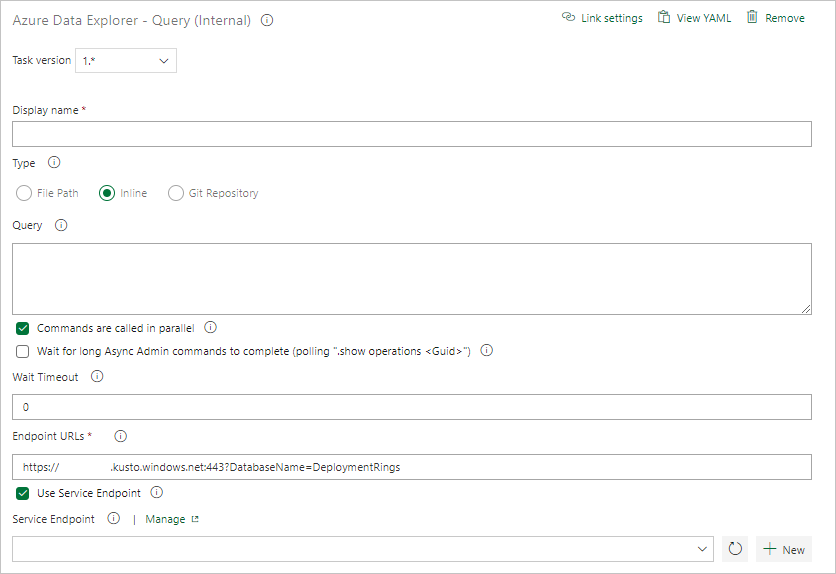
Under Aktivitetsresultat väljer du uppgiftens framgångsvillkor baserat på resultatet av din fråga enligt följande:
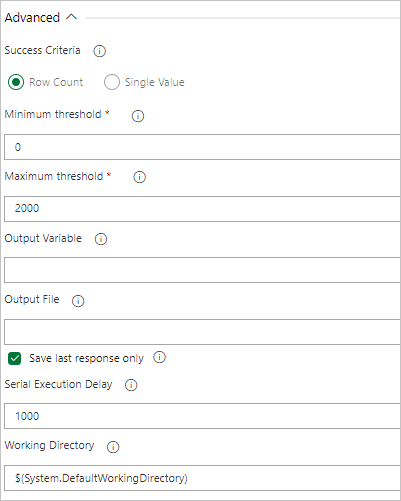
Om frågan returnerar rader väljer du Antal rader och anger de villkor som du behöver.
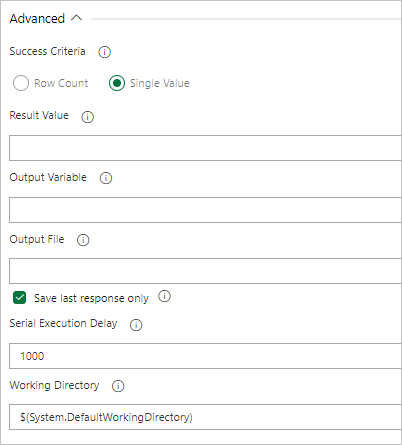
Om frågan returnerar ett värde väljer du Enskilt värde och anger det förväntade resultatet.
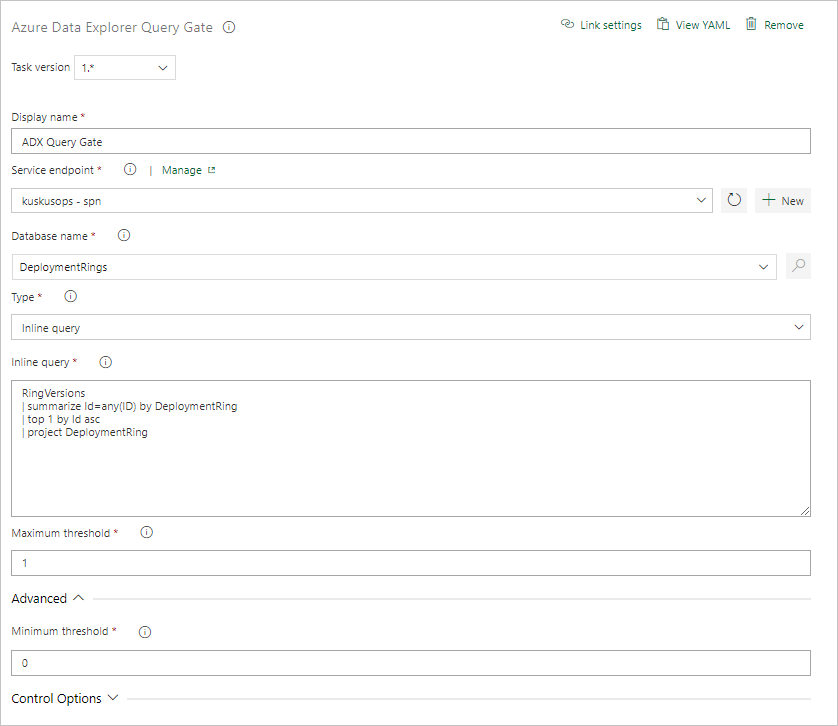
Skapa en Query Server Gate-uppgift
Om det behövs skapar du en uppgift för att köra en fråga mot ett kluster och styra versionsframstegen i väntan på antal rader i frågeresultat. Server Query Gate-uppgiften är ett agentlöst jobb, vilket innebär att frågan körs direkt på Azure DevOps Server.
På fliken Uppgifter väljer du + efter Agentlöst jobb och söker efter Azure Data Explorer.
Under Kör Azure Data Explorer Query Server Gate väljer du Lägg till.
Välj Kusto Query Server Gate och välj sedan Server Gate Test.
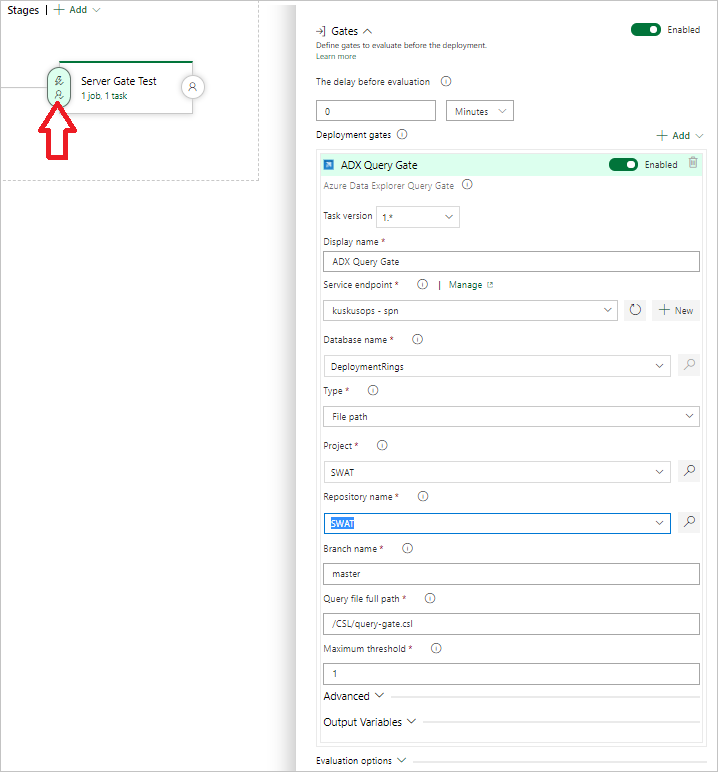
Konfigurera uppgiften med följande information:
- Visningsnamn: Namnet på porten.
- Tjänstslutpunkt: Välj en tjänstslutpunkt.
- Databasnamn: Ange databasnamnet.
- Typ: Välj Infogad fråga.
- Fråga: Ange den fråga som du vill köra.
- Maximalt tröskelvärde: Ange det maximala radantalet för frågans framgångsvillkor.
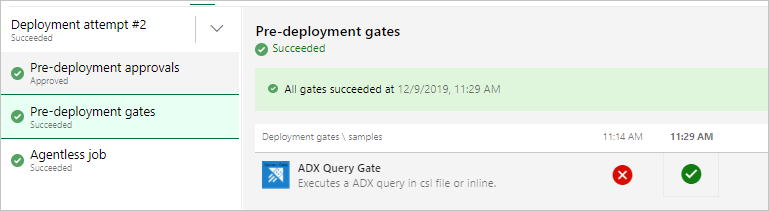
Anmärkning
Du bör se resultat som följande när du kör versionen.
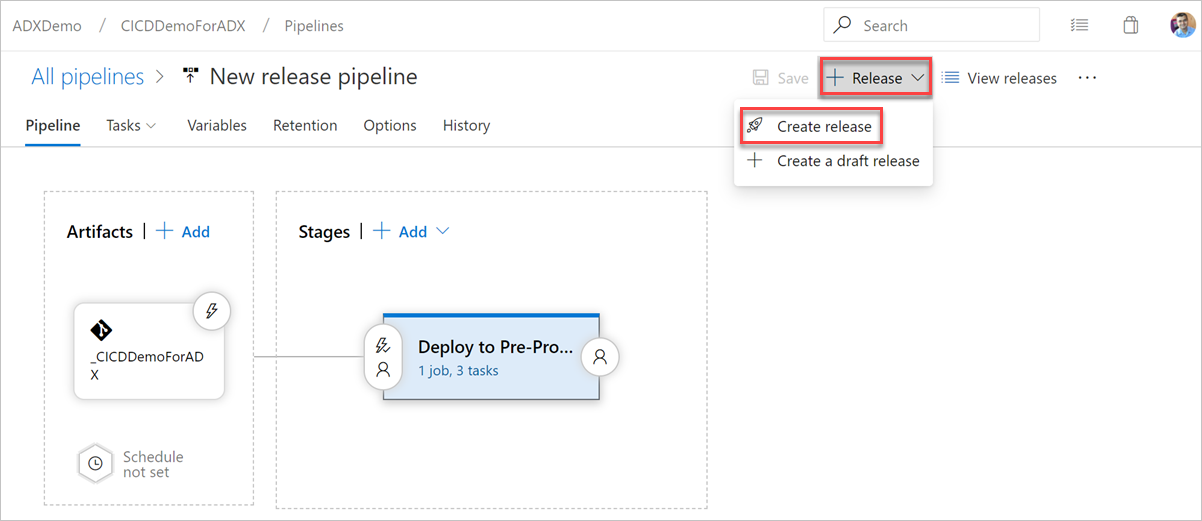
Kör utgåvan
Välj + Släpp>Skapa version för att starta en version.
På fliken Loggar kontrollerar du att distributionsstatusen har lyckats.
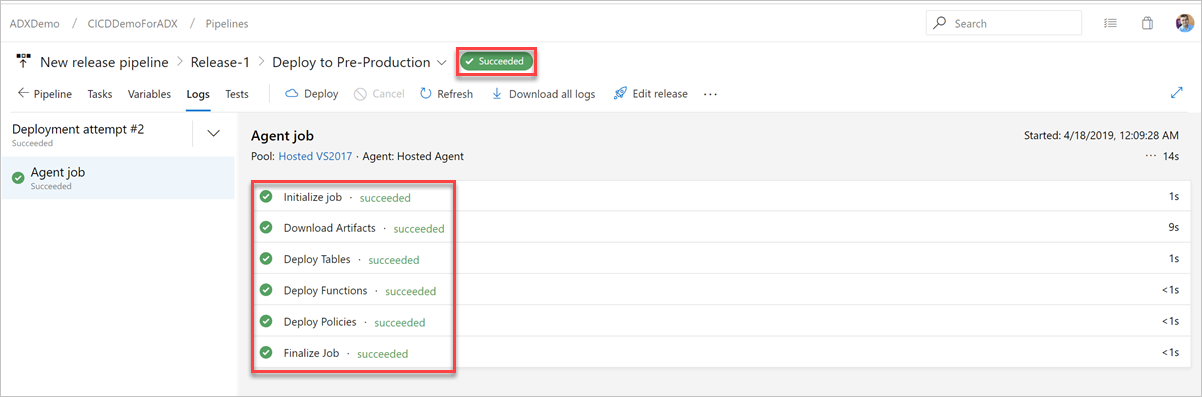
Nu är skapandet av en versionspipeline för distribution till förproduktion klar.
Stöd för nyckellös autentisering för Azure Data Explorer DevOps-uppgifter
Tillägget stöder nyckellös autentisering för Azure Data Explorer-kluster. Med nyckellös autentisering kan du autentisera till Azure Data Explorer-kluster utan att använda en nyckel. Det är säkrare och enklare att hantera.
Anmärkning
Kusto Fabric-kluster-URL:er stöds inte för WIF (Workload Identity Federation) och Hanterad identitetsautentisering.
Använda FIC-autentisering (Federated Identity Credentials) i en Azure Data Explorer-tjänstanslutning
Anmärkning
Från och med tilläggsversion 4.0.x har Azure Data Explorer Service Endpoint stöd för WIF-autentisering (Workload Identity Federation) utöver autentisering med tjänstens huvudnamn.
I DevOps-instansen går du till Project Settings>Service-anslutningar>Ny tjänstanslutning>Azure Data Explorer.
Välj Autentiseringsuppgifter för federerad identitet och ange din kluster-URL, tjänstens huvudnamn ID, klient-ID, ett namn på tjänstanslutningen och välj sedan Spara.
Öppna Microsoft Entra-appen för det angivna tjänstens huvudnamn i Azure-portalen.
Under Certifikat och hemligheter väljer du Federerade autentiseringsuppgifter.
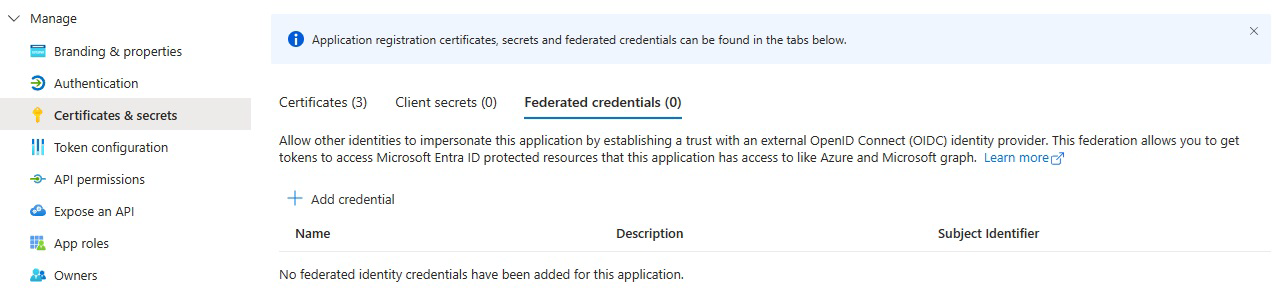
Välj Lägg till autentiseringsuppgifter och sedan för scenario med federerade autentiseringsuppgifter väljer du Annan utfärdare och fyller i inställningarna med hjälp av följande information:
Utfärdare:
<https://vstoken.dev.azure.com/{System.CollectionId}>där{System.CollectionId}är samlings-ID:t för din Azure DevOps-organisation. Du hittar samlings-ID:t på följande sätt:- I den klassiska Azure DevOps-versionspipelinen väljer du Initiera jobb. Samlings-ID:t visas i loggarna.
Ämnesidentifierare:
<sc://{DevOps_Org_name}/{Project_Name}/{Service_Connection_Name}>var{DevOps_Org_name}är Namnet på Azure DevOps-organisationen,{Project_Name}är projektnamnet och{Service_Connection_Name}är namnet på tjänstanslutningen som du skapade tidigare.Anmärkning
Om det finns utrymme i tjänstanslutningsnamnet kan du använda det med utrymmet i fältet. Till exempel:
sc://MyOrg/MyProject/My Service Connection.Namn: Ange ett namn för autentiseringsuppgifterna.
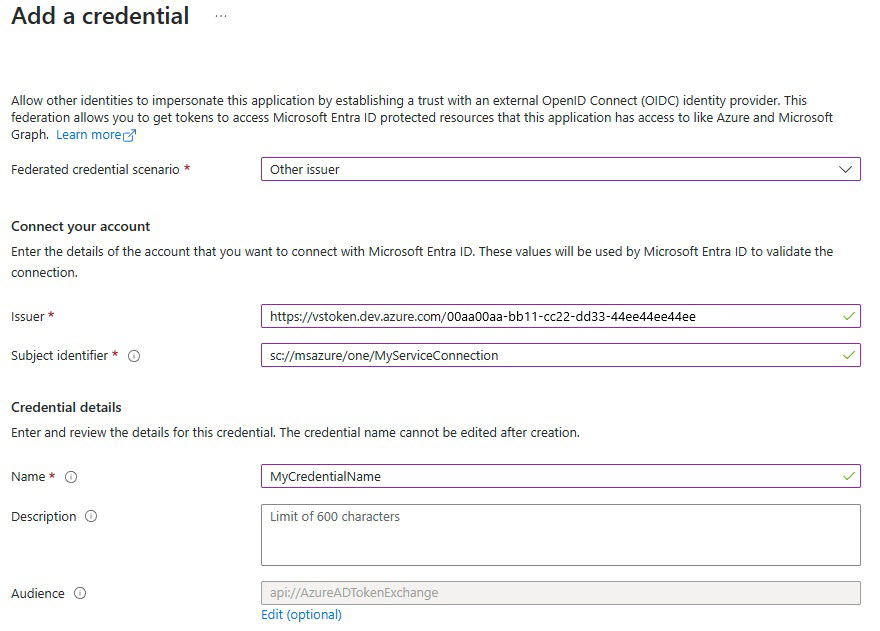
Välj Lägg till.
Använda autentiseringsuppgifter för federerad identitet eller hanterad identitet i en ARM-tjänstanslutning (Azure Resource Manager)
I DevOps-instansen går du till Project Settings>Service-anslutningar>Ny tjänstanslutning>Azure Resource Manager.
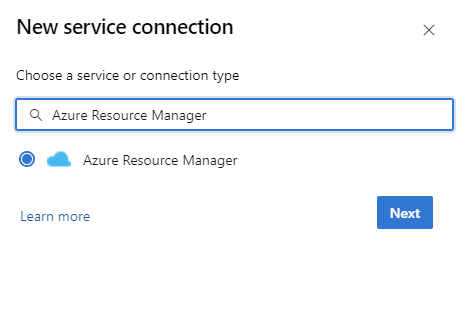
Under Autentiseringsmetod väljer du Arbetsbelastningsidentitetsfederation (automatisk) för att fortsätta. Du kan också använda alternativet manuell arbetsbelastningsidentitetsfederation (manuell) för att ange information om arbetsbelastningsidentitetsfederation eller alternativet Hanterad identitet . Läs mer om hur du konfigurerar en hanterad identitet med Hjälp av Azure Resource Management i Azure Resource Manager-tjänstanslutningar (ARM).

Fyll i nödvändig information, välj Verifiera och välj sedan Spara.
KONFIGURATION av YAML-pipeline
Du kan konfigurera uppgifter med hjälp av Azure DevOps-webbgränssnittet eller YAML-koden i pipelineschemat.
Tillägget innehåller tre pipelineuppgifter som alla är tillgängliga via YAML:
-
Azure Data Explorer-kommando (
ADXAdminCommand@5) – Kör administratörs-/kontrollkommandon mot ett ADX-kluster - Azure Data Explorer-fråga – Kör frågor mot ett ADX-kluster och parsa resultatet
- Azure Data Explorer Query Server Gate – Agentlös uppgift som styr distributioner beroende på frågeresultat
Tips/Råd
För förbättrad säkerhet använder du arbetsbelastningsidentitetsfederation eller hanterad identitetsautentisering via en Azure Resource Manager-tjänstanslutning i stället för att lagra autentiseringsuppgifter direkt i din pipeline. Dessa nyckellösa autentiseringsmetoder är rekommenderade metodtips.
Exempel på administratörskommando – inlinje kommandon
Följande exempel kör ett infogat administratörskommando med hjälp av en AZURE Resource Manager-tjänstanslutning (ARM), som stöder WIF (Workload Identity Federation) och hanterad identitetsautentisering:
steps:
- task: Azure-Kusto.ADXAdminCommands.PublishToADX.ADXAdminCommand@5
displayName: 'Run inline ADX admin command'
inputs:
clusterUri: 'https://<ClusterName>.<Region>.kusto.windows.net'
databaseName: '<DatabaseName>'
commandsSource: 'inline'
inlineCommands: |
.create-merge table MyTable (Id:int, Name:string, Timestamp:datetime)
.create-or-alter function MyFunction() { MyTable | take 10 }
azureSubscription: '<ARM Service Connection Name>'
continueOnError: true
Exempel på administratörskommando – filbaserade kommandon
Följande exempel kör administratörskommandon från filer som matchar ett globmönster med AAD-appregistreringsautentisering:
steps:
- task: Azure-Kusto.ADXAdminCommands.PublishToADX.ADXAdminCommand@5
displayName: 'Deploy schema from files'
inputs:
clusterUri: 'https://<ClusterName>.<Region>.kusto.windows.net'
databaseName: '<DatabaseName>'
commandsSource: 'files'
commandFilesPattern: '**/*.csl'
aadAppId: '$(AAD_APP_ID)'
aadAppKey: '$(AAD_APP_KEY)'
aadTenantId: '$(AAD_TENANT_ID)'
continueOnError: true
Du kan också använda **/*.kql som globmönster beroende på din namngivningskonvention för filer.
Exempel på administratörskommando – Azure Resource Manager-tjänstanslutning
I följande exempel används en Azure Resource Manager-tjänstanslutning som stöder WIF (Workload Identity Federation) och Hanterad identitet för nyckellös autentisering:
steps:
- task: Azure-Kusto.ADXAdminCommands.PublishToADX.ADXAdminCommand@5
displayName: 'Deploy schema via ARM service connection'
inputs:
clusterUri: 'https://<ClusterName>.<Region>.kusto.windows.net'
databaseName: '<DatabaseName>'
commandsSource: 'files'
commandFilesPattern: '**/*.csl'
azureSubscription: '<ARM Service Connection Name>'
continueOnError: true
condition: ne(variables['ProductVersion'], '')
Parametrar för uppgiftsinmatning
I följande tabell beskrivs de viktigaste indataparametrarna för ADXAdminCommand@5 uppgiften:
| Parameter | Beskrivning |
|---|---|
clusterUri |
Bas-URI:n för Kusto-klustret (till exempel https://<ClusterName>.<Region>.kusto.windows.net) |
databaseName |
Namnet på måldatabasen |
commandsSource |
Källan till kommandon: inline för infogade KQL-kommandon eller files för filbaserade kommandon |
inlineCommands |
Infogade KQL-kommandon som ska köras (används när commandsSource är inline) |
commandFilesPattern |
Globmönster för skriptfiler (används när commandsSource är files), till exempel **/*.csl eller **/*.kql |
aadAppId |
Microsoft Entra-appens (tjänstens huvudnamn) ID för AAD-appautentisering |
aadAppKey |
Microsoft Entra-appnyckeln/hemligheten för AAD-appautentisering |
aadTenantId |
Microsoft Entra-klient-ID för AAD-appautentisering |
azureSubscription |
Namnet på Azure Resource Manager-tjänstanslutningen för ARM-baserad autentisering (stöder WIF och hanterad identitet) |
Autentiseringsmetoder
Tillägget stöder följande autentiseringsmetoder:
-
Appregistrering i Azure Active Directory (AAD) – Använd
aadAppId,aadAppKeyochaadTenantIdför att autentisera med tjänstens huvudnamn. Lagra autentiseringdata som säkra pipelinevariabler. - Certifikatbaserad autentisering – Använd ett certifikat i stället för en appnyckel för autentisering med tjänstens huvudnamn. Lagra certifikatinformationen som säkra pipelinevariabler.
-
Hanterad identitet – Använd en Azure Resource Manager-tjänstanslutning som konfigurerats med hanterad identitet. Ställ in
azureSubscription-indata till namnet på tjänstanslutningen. -
Workload Identity Federation (WIF) – Använd en Azure Resource Manager-tjänstanslutning med Workload Identity Federation (automatisk eller manuell). Det här är den rekommenderade nyckellösa metoden. Ställ in
azureSubscription-ingången till namnet på tjänstanslutningen.
Anmärkning
WiF (Workload Identity Federation) är ett nyare tillägg till tillägget. Det möjliggör hemlighetslös autentisering och är den rekommenderade metoden för nya pipelines. Installationsinstruktioner finns i Använda federerade identitetsuppgifter eller hanterad identitet i en AZURE Resource Manager-tjänstanslutning (ARM).
Frågeexempel
steps:
- task: Azure-Kusto.PublishToADX.ADXQuery.ADXQuery@5
displayName: '<Task Display Name>'
inputs:
targetType: 'inline'
script: |
let badVer=
RunnersLogs | where Timestamp > ago(30m)
| where EventText startswith "$$runnerresult" and Source has "ShowDiagnostics"
| extend State = extract(@"Status='(.*)', Duration.*",1, EventText)
| where State == "Unhealthy"
| extend Reason = extract(@'"NotHealthyReason":"(.*)","IsAttentionRequired.*',1, EventText)
| extend Cluster = extract(@'Kusto.(Engine|DM|CM|ArmResourceProvider).(.*).ShowDiagnostics',2, Source)
| where Reason != "Merge success rate past 60min is < 90%"
| where Reason != "Ingestion success rate past 5min is < 90%"
| where Reason != "Ingestion success rate past 5min is < 90%, Merge success rate past 60min is < 90%"
| where isnotempty(Cluster)
| summarize max(Timestamp) by Cluster,Reason
| order by max_Timestamp desc
| where Reason startswith "Differe"
| summarize by Cluster
;
DimClusters | where Cluster in (badVer)
| summarize by Cluster , CmConnectionString , ServiceConnectionString ,DeploymentRing
| extend ServiceConnectionString = strcat("#connect ", ServiceConnectionString)
| where DeploymentRing == "$(DeploymentRing)"
kustoUrls: 'https://<ClusterName>.kusto.windows.net?DatabaseName=<DatabaseName>'
authType: 'kustoserviceconn'
connectedServiceName: '<connection service name>'
minThreshold: '0'
maxThreshold: '10'
continueOnError: true